一、概述
使用canal + rabbitMQ 实现 MySQL 和 Elasticsearch 的数据同步
图解:
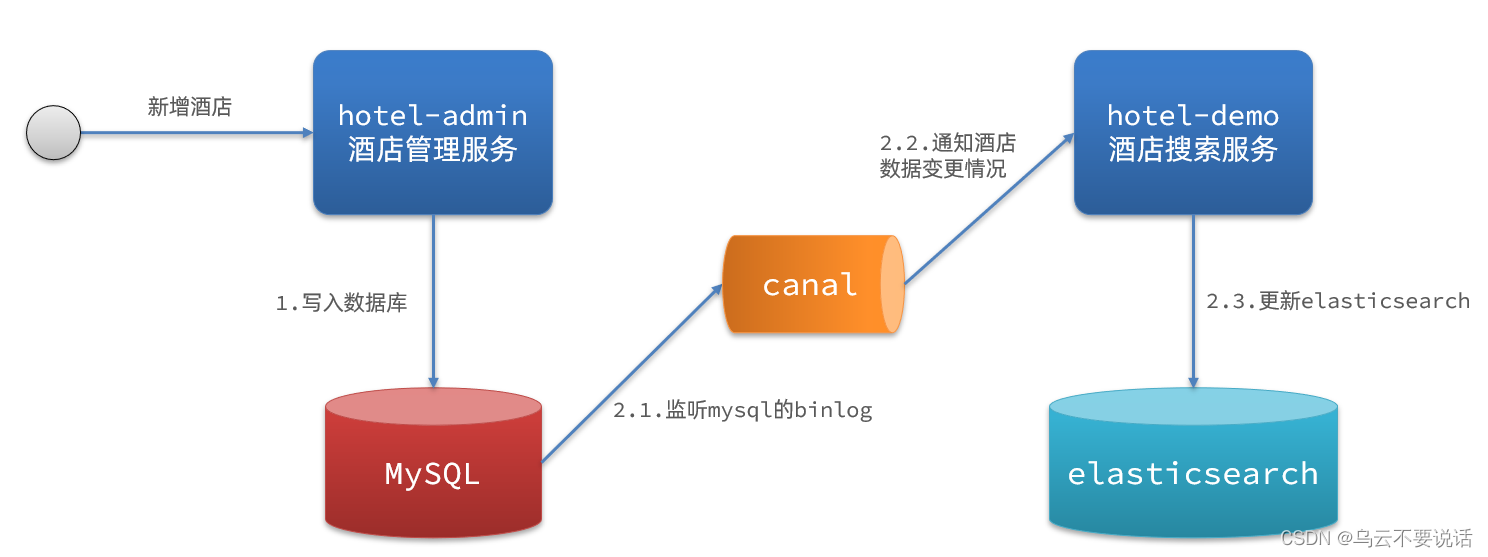
流程如下:
-
给mysql开启binlog功能
-
mysql完成增、删、改操作都会记录在binlog中
-
canal监听binlog变化并发送消息到MQ,项目接收消息并实时更新elasticsearch中的内容
二、什么是数据同步
elasticsearch中的数据来自于mysql数据库,因此mysql数据发生改变时,elasticsearch也必须跟着改变,这个就是elasticsearch与mysql之间的数据同步。
思路分析:
常见的数据同步方案有三种:
-
同步调用
-
异步通知
-
监听binlog
三、认识Canal
canal-github仓库
Canal介绍:Canal 是用 Java 开发的基于数据库增量日志解析,提供增量数据订阅&消费的中间件(数据库同步需要阿里的 Otter 中间件,基于 Canal)。
Canal背景:阿里巴巴 B2B 公司,因为业务的特性,卖家主要集中在国内,买家主要集中在国外,所以衍生出了同步杭州和美国异地机房的需求,从 2010 年开始,阿里系公司开始逐步的尝试基于数据库的日志解析,获取增量变更进行同步,由此衍生出了增量订阅&消费的业务。
Canal原理:自己伪装成 Slave,假装从 Master 复制数据,实际上就是主从复制的一个流程(通过增量复制来不断的进行订阅消费数据)
主从复制原理
- Master 主库将改变记录,写到二进制日志(Binary Log)中;
- Slave 从库向 MySQL Master 发送 dump 协议,将 Master 主库的 binary log events 拷贝到它的中继日志(relay log);
- Slave 从库读取并重做中继日志中的事件,将改变的数据同步到自己的数据库。
binlog的分类:statement、row、mixed。在canal配合mysql时,mysql需要配置binlog模式为row(推荐)。
- statement:记录每一次执行写操作的sql语句,但是可能会产生数据不一致,例如sql语句update tt set create_date=now(),其中就有now()函数,若是其他从结点进行同步就会出现问题。
- row:记录每次操作后每行记录的变化,直接记录的是数据,能够保持数据的一致性,缺点就是比较占空间。
- mixed:statement 的升级版,默认实质还是statement,对于uuid()、auto_increment会使用row模式处理,还算是比较智能,但是极个别情况还是会造成数据不一致,并且由于默认依旧是statement,实际上就是sql+数据形式。
常用场景:
1、异地数据库的同步。
2、更新缓存。(例如以往的对应某些数据库表字段会设置缓存,处理更新数据库时的字段对缓存进行更新,在高并发的情况下会造成数据一致性问题,此时可以使用canal)
3、抓取数据更新,来进行实时数据分析。
四、安装配置Canal
当前安装的MySQL版本:8.0.33,Canal版本是最新版
Docker的安装可见:Docker --- 简介、安装
4.1、准备
对于自建 MySQL , 需要先开启 Binlog 写入功能,配置 binlog-format 为 ROW 模式,my.cnf 中配置如下
[mysqld]
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复授权 canal 链接 MySQL 账号具有作为 MySQL slave 的权限, 如果已有账户可直接 grant
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
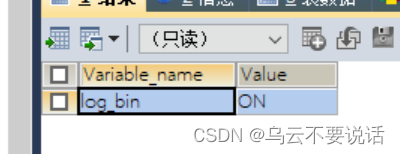
FLUSH PRIVILEGES;注意:一定要查看bin-log是否已经开启,下面的命令我们可以去进行一个查看当前mysql的信息:
# 查看binlog日志是否开启
show variables like 'log_%';
# 查看主结点当前状态
show master status
4.2、Docker快速安装Canal
Canal下载地址
tar压缩包安装:官方文档
Docker安装的官方文档:Canal Docker QuickStart
1、拉取Canal的镜像文件:
docker pull canal/canal-server:latest2、启动 canal 镜像
docker run --name canal -d canal/canal-server:latest3、创建映射文件
mkdir /usr/local/canal
cd /usr/local/canal
touch canal.properties instance.properties4、将容器内的配置文件复制到刚创建好的文件里
docker cp canal:/home/admin/canal-server/conf/canal.properties /usr/local/canal/canal.properties
docker cp canal:/home/admin/canal-server/conf/example/instance.properties /usr/local/canal/instance.properties5、关闭容器并移除容器
docker rm -f canal6、修改外部配置文件 instance.properties

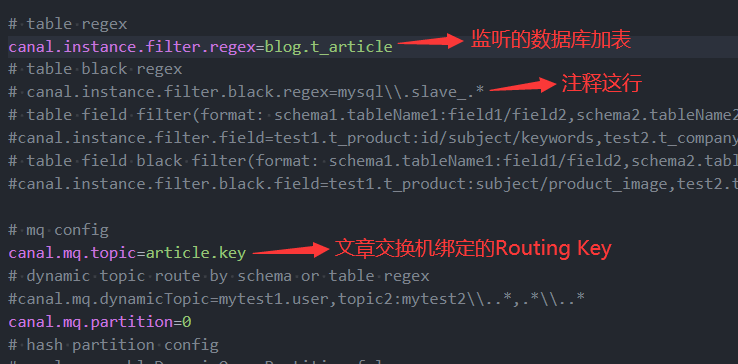
7、修改外部配置文件 canal.properties
找到以下这行将
tcp改成rabbitMQ# tcp, kafka, rocketMQ, rabbitMQ, pulsarMQ canal.serverMode = rabbitMQ
接着找到以下这几行
################################################## ######### RabbitMQ ############# ################################################## rabbitmq.host = 你的ip rabbitmq.virtual.host = / rabbitmq.exchange = article.topic # 交换机名称 rabbitmq.username = rabbitmq用户名 rabbitmq.password = rabbitmq密码 rabbitmq.deliveryMode = topic # exchange的模式笔记:
- 在 RabbitMQ 中,消息的发送需要指定目标队列或者交换机。如果你只绑定了一个消息队列到交换机上,那么在发送消息时可以不指定队列名称,而是将消息直接发送到该交换机,消息将会被路由到该交换机所绑定的唯一队列中。
- 因此,发送消息时可以不填写消息队列名称,但需要指定交换机的名称和消息的路由键。如果消息的路由键与交换机所绑定的队列的路由键匹配,那么消息将会被成功路由到该队列中。如果消息的路由键与交换机所绑定的队列的路由键不匹配,那么消息将会被丢弃。
- 需要注意的是,如果你在发送消息时指定了不存在的交换机名称,或者指定了与交换机类型不匹配的交换机名称,那么消息将会发送失败。
8、执行命令启动canal容器
# 启动canal服务
# -i:让容器的标准输入保持打开(特别特别重要,注意不要是-d,一定要加上i)
docker run --name canal \
-p 11111:11111 \
-v /usr/local/canal/instance.properties:/home/admin/canal-server/conf/example/instance.properties \
-v /usr/local/canal/canal.properties:/home/admin/canal-server/conf/canal.properties \
-id canal/canal-server:latest启动完canal之后,去查看canal实例的日志内容,判断是否已经成功连接到mysql:
# 进入到docker容器
docker exec -it canal /bin/bash
# 打开日志文件
cd canal-server/logs/example/
# 查看日志文件的最后100行内容
tail -100 example.log
下面是连接成功的情况:

如果出现数据库连接异常
- 仔细查看用户名、密码是否正确
- 配置文件中设置的MySQL的IP以及端口号是否正确
4.3、测试
配置完成后,进行数据库CRUD操作,查看RabbitMQ中是否有消息发送成功

项目中编写消费者类用于接收处理消息进行ES的增删改
/**
* 文章消费者
*
* @author DarkClouds
* @date 2023/05/18
*/
@Component
@RequiredArgsConstructor
public class ArticleConsumer {
private final ElasticsearchService elasticsearchService;
@RabbitListener(bindings = {
@QueueBinding(
value = @Queue(value = ARTICLE_QUEUE, durable = "true", autoDelete = "false"),
exchange = @Exchange(value = ARTICLE_EXCHANGE, type = ExchangeTypes.TOPIC),
key = ARTICLE_KEY
)})
public void listenSaveArticle(Message message) {
String data = new String(message.getBody(), StandardCharsets.UTF_8);
CanalDTO canalDTO = JSONUtil.toBean(JSONUtil.toJsonStr(data), CanalDTO.class);
if (canalDTO.getIsDdl()) {
return;
}
ArticleSearchVO article = JSONUtil.toBean(JSONUtil.toJsonStr(canalDTO.getData().get(0)), ArticleSearchVO.class);
switch (canalDTO.getType()) {
case INSERT:
elasticsearchService.addArticle(article);
case UPDATE:
elasticsearchService.updateArticle(article);
break;
case DELETE:
elasticsearchService.deleteArticle(article.getId());
break;
default:
break;
}
}
}