背景
周末看系统架构的时候,看到一致性要求时,回忆了一下 Kafka 的消息一致性保障机制,顺便复习了一下 Kafka 的基础信息。
消息文件目录
Kafka 的消息存储目录是由 server.properties 文件的 log.dirs=/tmp/kafka-logs 设置的,这个是默认值。
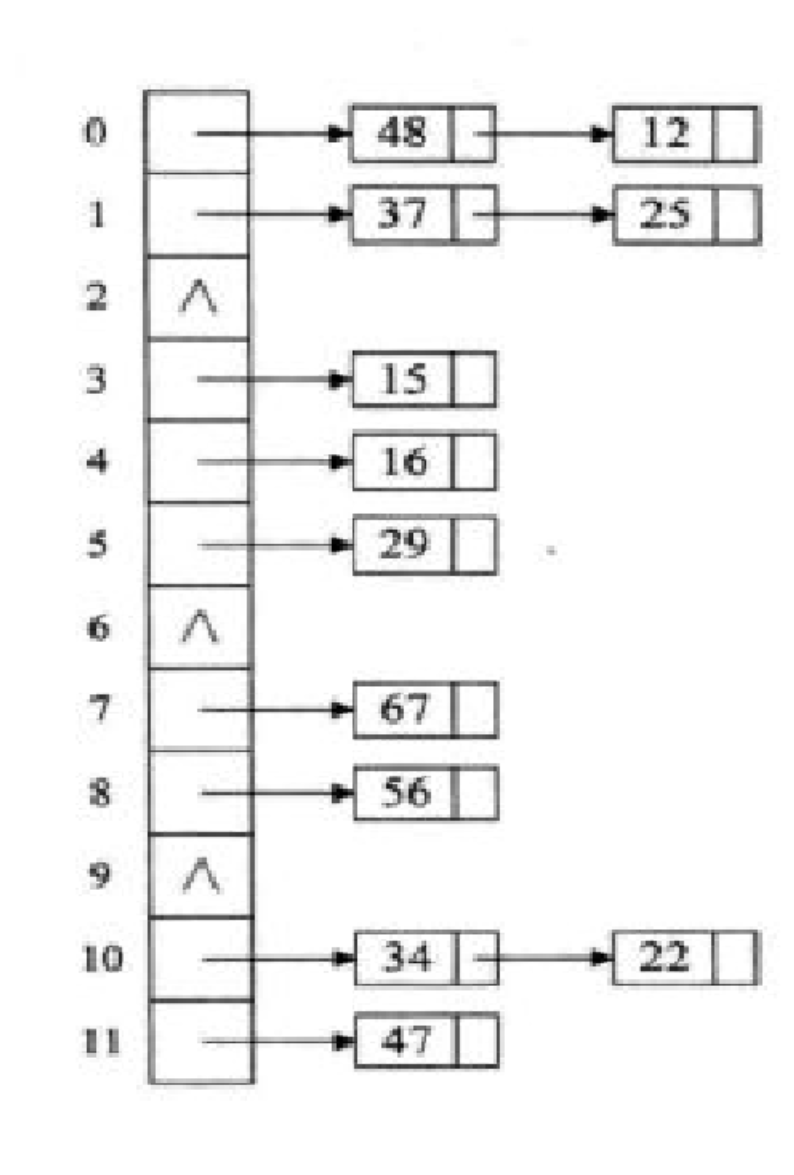
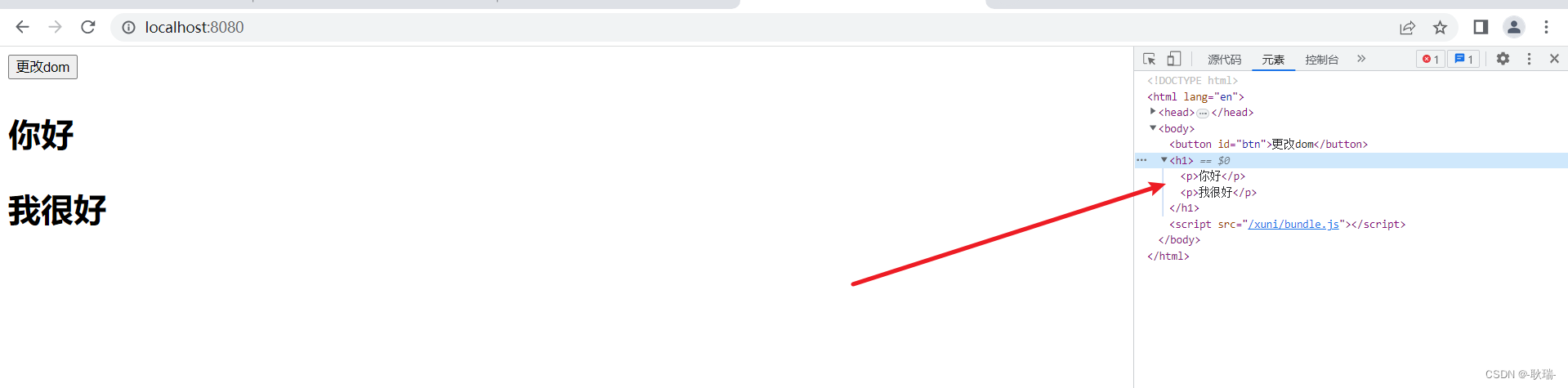
进入这个目录查看结构,子目录的命名规律「 topic名称-分区编号」,找到了一张很直观的图:
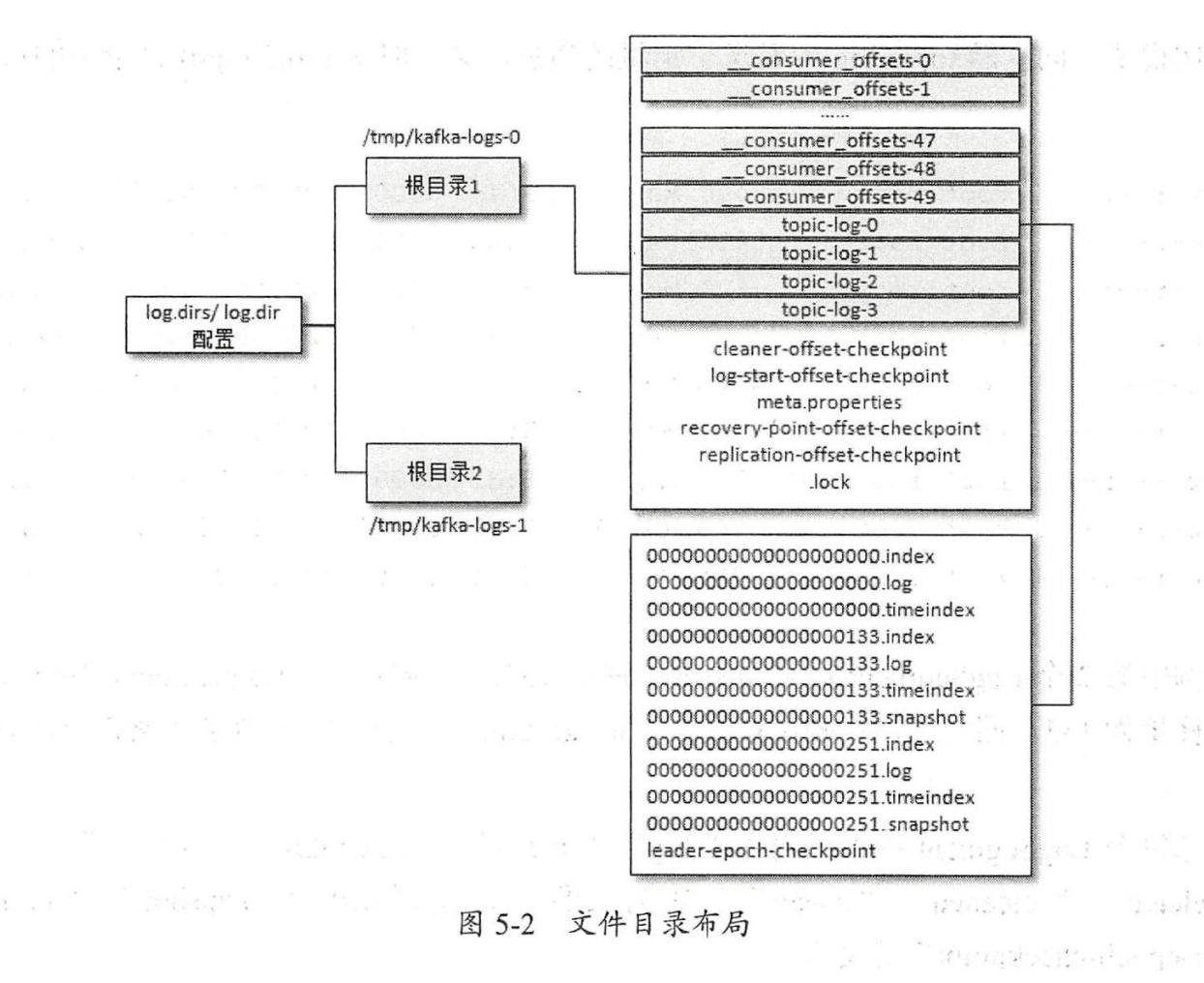
「此图来自网络」
文件类型:
.index偏移量索引文件,稀疏矩阵,用于快速查找消息。.log日志数据,顺序保存消息数据的文件。.timeindex,时间索引文件。partition.metadata分区元数据leader-epoch-checkpoint
.log 日志文件
存储消息数据的文件,导入日志内容命令如下:
./kafka-run-class.sh kafka.tools.DumpLogSegments --files /tmp/kafka-logs/xxx-topic-0/00000000000000000000.log
得到内容如下:
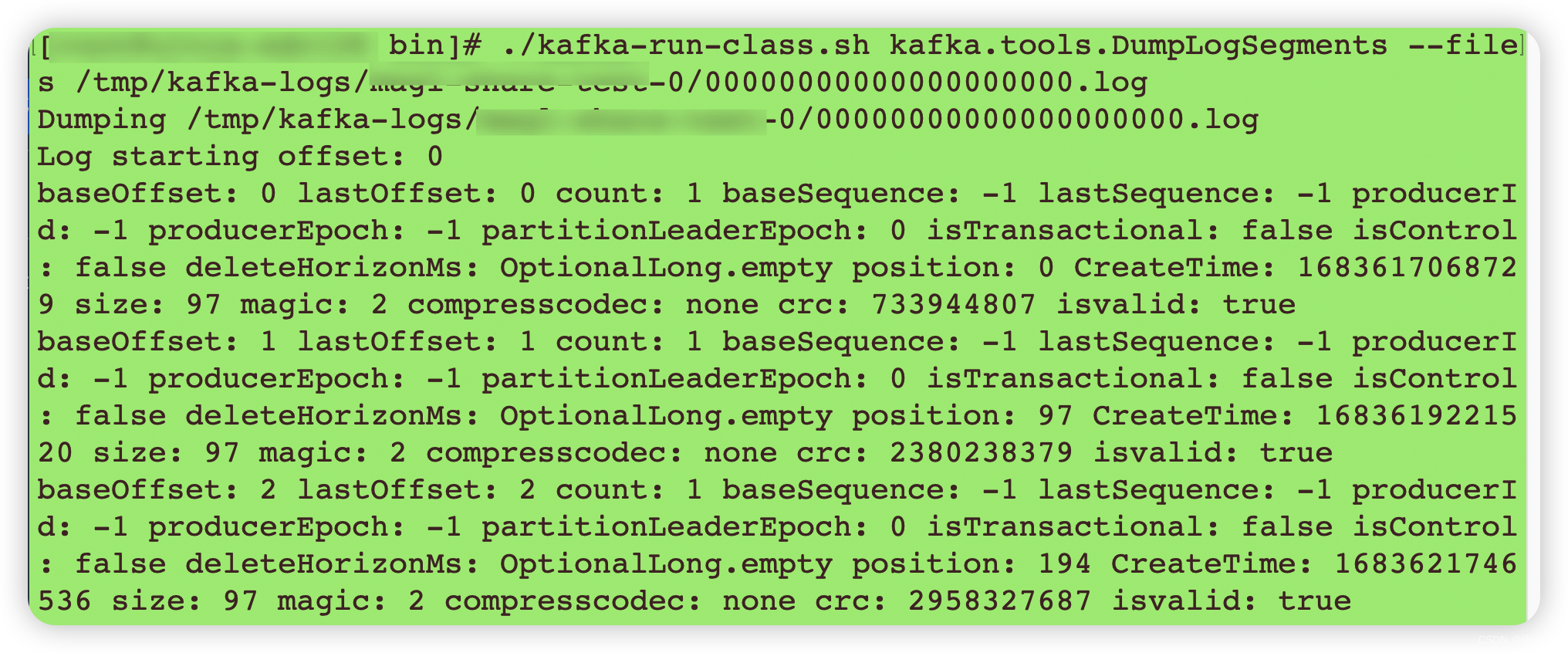
查看一条日志信息:
baseOffset: 60724
lastOffset: 60738
count: 15
baseSequence: -1
lastSequence: -1
producerId: -1
producerEpoch: -1
partitionLeaderEpoch: 0
isTransactional: false
isControl: false
deleteHorizonMs: OptionalLong.empty
position: 14774767
CreateTime: 1683957996854
size: 3691
magic: 2
compresscodec: none
crc: 2858034430
isvalid: true
这里的 position 就是 .index 的文件中的 position 的值。
.index 索引文件
使用 Kafka 的命令导出索引文件如下:
./kafka-run-class.sh kafka.tools.DumpLogSegments --files /tmp/kafka-logs/xxx-topic-0/00000000000000000000.index
得到结果如下:
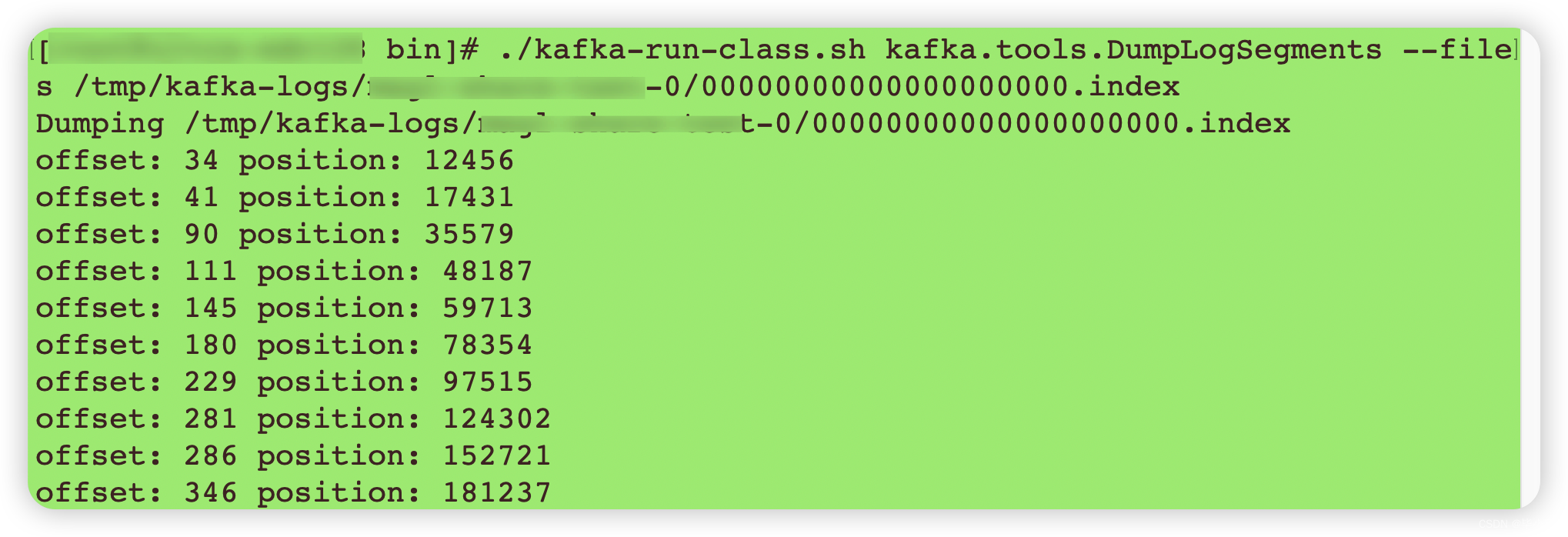
基本格式:
- offset : 占 8 Byte 的消息编号,它可以唯一确定每条消息在 parition 内的位置;
- position :日志文件中的物理地址。
索引文件存储了消息的存偏移量 offset 和 .log 日志文件中的实际物理位置 position 的映射关系,每个条目可以唯一确定该分区日志文件的一条消息,主要作用是查找消息。根据偏移量进行二分查找,就可以确定具体某条消息。
partition.metadata
分区元文件的内容参考:

总结
Kafka 高效数据存储的几设计思想:
- 主题存储分为多个分区,每个分区又分为多个段,避免了大文件;
- 偏移量索引文件使用稀疏矩阵存储相对偏移量和日志物理位置的映射关系,提高了消息查找效率,同时又减少了磁盘 IO ;
- 日志消息追加直接对日志数据文件的顺序写入,极大提高了磁盘 IO 效率。
说实话,Kafka 原理看了很多次,每次都感觉理解了,但过一段时间又都忘记了。这次对着 Kafka 部署目录,再整理一下数据存储的基础知识,争取能够多记忆一段时间,尤其是第一个 Kafka 数据文件目录的图,很清晰。
参考文档
- https://blog.csdn.net/qq_43692950/article/details/125032063
- https://blog.csdn.net/weixin_46378680/article/details/124530198
- https://blog.csdn.net/shufangreal/article/details/111832196