实际开发中我们可能根据需求需要将MapReduce的运行结果生成多个不同的文件,比如上一个案例【MapReduce计算广州2022年每月最高温度】,我们需要将前半年和后半年的数据分开写到两个文件中。
默认分区
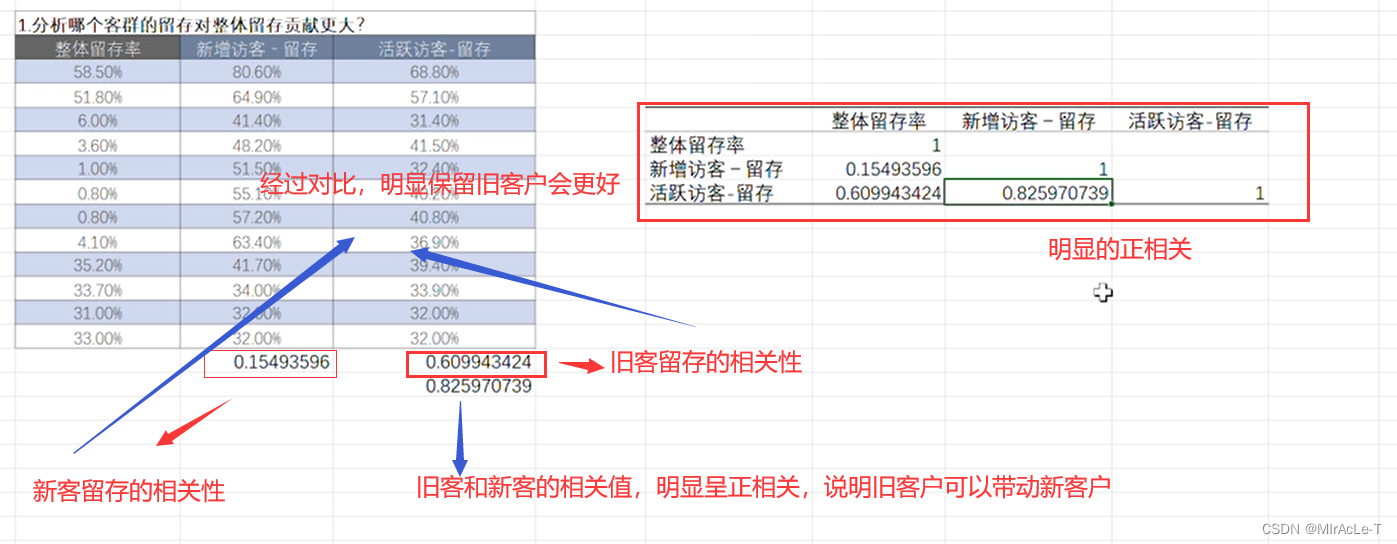
默认MapReduce只能写出一个文件: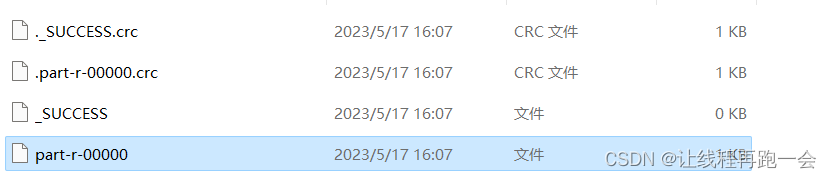
因为我们在提交job的时候未设置reduceTask的个数,所以默认reduceTask的个数为1,结果也就只能输出一个文件,下面是数据写入文件时,默认调用的HashPartitioner类的getPartition方法:
public int getPartition(K key, V value, int numReduceTasks) {
return (key.hashCode() & 2147483647) % numReduceTasks;
}因为reduceTask数量为1,任何数1取余结果为0,所以文件只有一个且文件名位 "part-r-00000"
自定义分区
1.继承Partitioner类
像HashPartitioner类一样继承Partitioner类
2.指定泛型
因为分区出现在map方法之后,所以两个泛型参数分别为map方法输出的key和value的类型
3.继承getPartition方法
- 继承后需要重写分区逻辑,也就是说如何根据输入的键或值来确定该行数据的分区。
- 设置自定义分区后,因为我们的输入格式是默认的TextInputFormat,所以每行数据都会通过getPartitioner方法来选择分区。
public class MyPartitioner extends Partitioner<Text, IntWritable> {
@Override
public int getPartition(Text text, IntWritable intWritable, int partitioner) {
//text 是月份
String month = text.toString();
int month_num = Integer.parseInt(month);
//注意:分区号必须从0开始!
if (month_num<=6) //前半年的数据放到分区0
partitioner = 0;
else //后半年的数据放到分区1
partitioner = 1;
return partitioner;//返回分区号
}
}4.在job中设置分区
- 我们不仅要指定分区的类型还要指定reduceTask的数量,因为我们最后是根据分区的数量来分配给不同的reduceTask去执行。
这里我们只需要增加下面的语句即可,其余部分代码不需要改动。
//绑定自定义分区
job.setPartitionerClass(MyPartitioner.class);
//设置reduceTask个数
job.setNumReduceTasks(2);输出结果
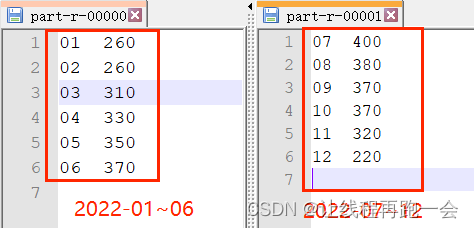
注意点-reduceTask的数量
reduceTask数量 > 分区的数量
这种情况会造成CPU资源的浪费,因为会多开启 reduceTask ,它没有任务还空占大约1G内存。
1< reduceTask数量< 分区的数量
会抛出异常,因为有多余的分区剩下来没有reduceTask拉取处理。
reduceTask数量 =1
自定义分区失效,按照默认的分区规则(HashPartitioner的getPartitioner方法)执行,仍然只生成一个结果文件。
分区号必须从0开始
向下面这段代码一样,共划分了5个分区(0~4),结果会有5个结果文件产生。
if (条件1)
partitioner = 0; //分区0
else if(条件2)
partitioner = 1; //分区1
else if(条件3)
partitioner = 2; //分区2
else if(条件4)
partitioner = 3; //分区3
else
partitioner = 4; //分区4