大家好,我是微学AI,今天给大家介绍一下自然语言处理实战项目7-利用层次聚类方法做文本的排重,从大量的文本中找出相似文本。随着互联网技术的不断发展,越来越多的数据被广泛地应用在各个领域中。而文本数据是其中之一,文本排重是对这些数据进行加工的一个重要的环节。为了减少计算资源的浪费,缩短运行时间,利用层次聚类算法实现文本排重是一个不错的选择。
我们工作中会遇到描述相似的句子,但是直接找重复的,又因为他们不是完全相同而无法直接找到,而已不是模糊匹配那种,因为有的文本表述是少了某些字的,我们要找到这些相似的句子。
一、层次聚类算法
层次聚类算法是一种基于距离度量的聚类方法。它的核心思想是对所有的数据点进行两两之间的距离计算,然后将距离最小的两个点合并成一个新的点,直到所有数据点都被合并到同一个簇中。最终,聚类结果映射为一棵层级树状图,我们可以通过树状图来查看不同簇之间的层次关系。
层次聚类算法有两种形式:凝聚型聚类和分裂型聚类。凝聚型聚类从单个数据点开始,逐步合并不同的数据点,直到整个数据集合被合并成一个大的簇。分裂型聚类从一个大的簇开始,将数据点分成两个或多个较小的簇。
层次聚类算法的优点是可以处理任意类型的数据,并且能够构建出清晰明了的层级关系。相比于其他聚类算法,它不需要预先指定簇的数量,并且可以灵活调整参数来控制聚类的粒度。
但层次聚类算法也有一些缺陷,它的时间复杂度高,尤其是在处理大数据集时。此外,基于距离度量的聚类算法还需要进行数据归一化和距离度量的选择,这些都直接影响到聚类效果。
二、层次聚类算法的步骤
层次聚类算法是一种基于对象间距离的聚类方法。该算法将数据对象以类的景观组织在起来,将所有的聚集分成不同的组或类,成为一个层级树状结构。
步骤如下:
1、将所有数据对象视为单独一个类;
2、计算所有类之间的距离并再次组合;
3、重复直至所有对象都被组合成一个单独的类。
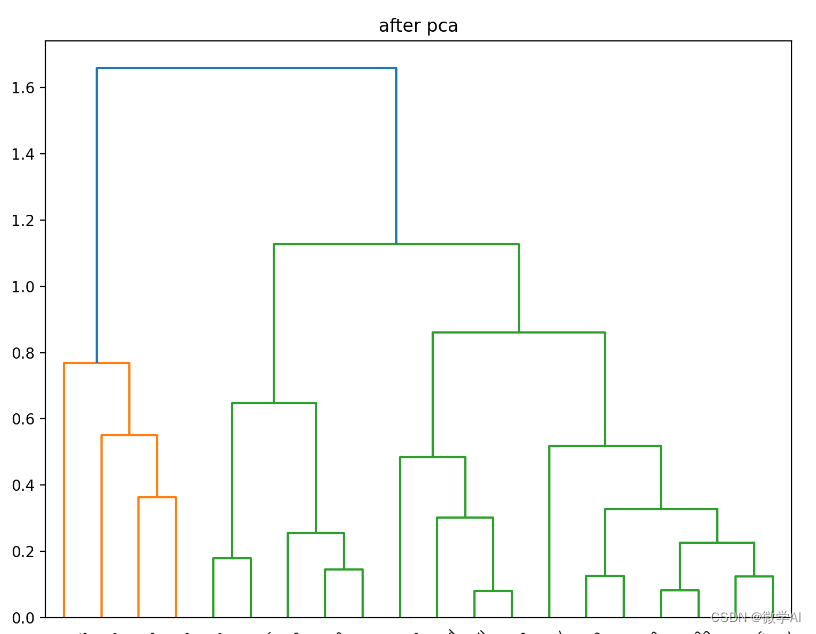
三、层次聚类算法实现文本排重
数据说明,我建立一个文本数据:test.csv
text
你好,很高兴认识你
我也很高兴认识你
层次聚类算法原理是什么
文本排重是对这些数据进行加工的一个重要的环节
层次聚类算法原理
层次聚类算法是一种基于对象间距离的聚类方法
将所有数据对象视为单独一个类
计算所有类之间的距离并再次组合
为了更好地理解层次聚类算法的应用
我们在此提供一个简单的中文数据样本
所有数据对象看作单独的一个
找到表格中的相似句子
代码和目录结构以供参考
所有数据对象看作单独一个类
中国与中亚五国的合作成功密码
美国OpenAI发表GPT4
层次聚类算法其实是一种基于对象间距离的聚类方法层次聚类算法实现:
# 必要的库
import pandas as pd
import numpy as np
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
from scipy.linalg import norm
from sklearn.metrics.pairwise import cosine_similarity
from scipy.cluster.hierarchy import linkage, fcluster
from collections import defaultdict
# 设置常量
MAX_DF = 0.8 # 移除文档频率高于max_df的词语
MIN_DF = 0.01 # 将出现在少于min_df文档中的词语移除
STOP_WORDS = [line.strip() for line in open('stop_words.txt', encoding = 'utf-8').readlines()]
# 数据载入
data = pd.read_csv('test.csv', encoding = 'utf-8')
texts = data['text'].tolist()
# 分词
texts_fenci = []
for text in texts:
words = jieba.cut(text)
text_fenci = ''
for word in words:
if word not in STOP_WORDS:
text_fenci += word + ' '
texts_fenci.append(text_fenci)
# 文本向量化转换
vectorizer = TfidfVectorizer(max_df = MAX_DF, min_df = MIN_DF)
tf_idf = vectorizer.fit_transform(texts_fenci)
# 计算余弦距离
tf_idf_norm = tf_idf.toarray() / np.linalg.norm(tf_idf.toarray(), axis = -1).reshape(-1, 1)
cos_dist = cosine_similarity(tf_idf_norm)
# 层次聚类
linkage_matrix = linkage(cos_dist, method='ward', metric='euclidean')
clusters = fcluster(linkage_matrix,t=0.2,criterion='distance')
# 相似句子标注
cluster_dict = defaultdict(list)
for i, label in enumerate(clusters):
cluster_dict[label].append(i)
for _ , idx in cluster_dict.items():
if len(idx) > 1:
print('相似句子为:', end = ' ')
for i in idx:
print(texts[i], end = ' ')
print('\n')运行结果:
相似句子为: 层次聚类算法是一种基于对象间距离的聚类方法 层次聚类算法其实是一种基于对象间距离的聚类方法
相似句子为: 所有数据对象看作单独的一个 所有数据对象看作单独一个类 代码中我们可以控制clusters = fcluster(linkage_matrix,t=0.2,criterion='distance')中t=0.2的值,这里越小说明层次分的越细,越多分的越少,就会把不太相似的也分到一起。