💭前言:通过之前对顺序表和链表的实现,我们可以发现在增删查改某些操作上两者的效率前言有所差异,本篇文章将总结二者的异同。
顺序表的实现
http://t.csdn.cn/Lxyg2单链表的实现
存储空间
📚顺序表通过数组来实现的,所以在物理存储空间上是连续的。链表是通过指针域找到下一个节点的,所以在物理存储空间上一般不连续,逻辑结构上是连续的。
随机访问
📚数组支持下标访问,所以可以在O(1)时间复杂度下访问顺序表的任意位置,链表不支持随机访问,像访问中间的任意节点必须从头开始遍历,时间复杂度为O(1)。
插入删除节点
📚数组删除除最后一个元素外的任意元素或在最后一个元素后面插入元素时都需要挪动数据,因此顺序表删除、插入元素的时间复杂度为O(n);🔍 在已知删除、插入元素地址时,链表可以仅通过O(1)的时间复杂度删除、插入元素。
缓存命中率
来自百度百科的解释:始端用户访问加速节点时,如果该节点有缓存住了要被访问的数据时就叫做命中,如果没有的话需要回原服务器取,就是没有命中。取数据的过程与用户访问是同步进行的,所以即使是重新取的新数据,用户也不会感觉到有延时。 命中率=命中数/(命中数+没有命中数), 缓存命中率是判断加速效果好坏的重要因素之一。
对于没有硬件基础的人来说想要理解上面这句话并不容易,因此我将用我自己的理解来解释缓存命中率。
在此之前我们需要了解计算机存储器的结构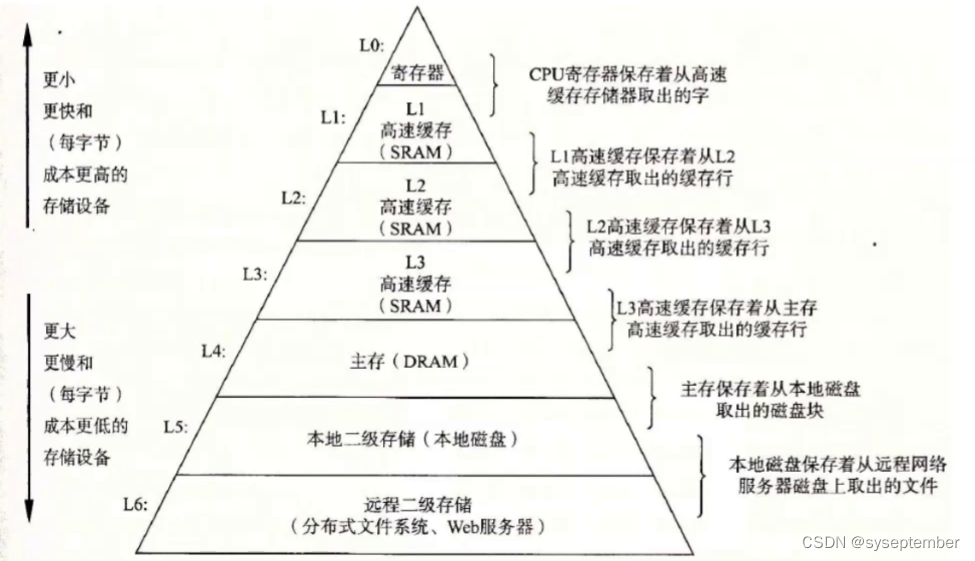
我们较为熟悉的存储器是磁盘和主存,🔍两个的区别在于主存中只有在通电的状态下才会存储数据,而磁盘里的数据可以永久保存。🔍另外一个区别是从主存中读取数据比从磁盘读取数据据要更快。程序定义的变量是在主存中的,但是CPU读取数据时并不会直接从主存里面读取数据,而是将数据加载到高速缓存或者寄存器中(取决于读取数据的大小),🔑原因在于CPU读取数据的速度很快,而主存相对CPU来说加载数据太慢了,因此读取数据时会先将数据加载到更快的存储器中再被CPU读取。
💬验证从寄存器中读取数据
int i = 1;
00081F75 mov dword ptr [i],1
i++;
00081F7C mov eax,dword ptr [i]
00081F7F add eax,1
00081F82 mov dword ptr [i],eax ❕当数据更大时会将数据加载到告诉缓存中,CPU从告诉缓存中读取数据。
❓如果要经常访问和修改数据,下面两种数据结构使用哪种更合适?
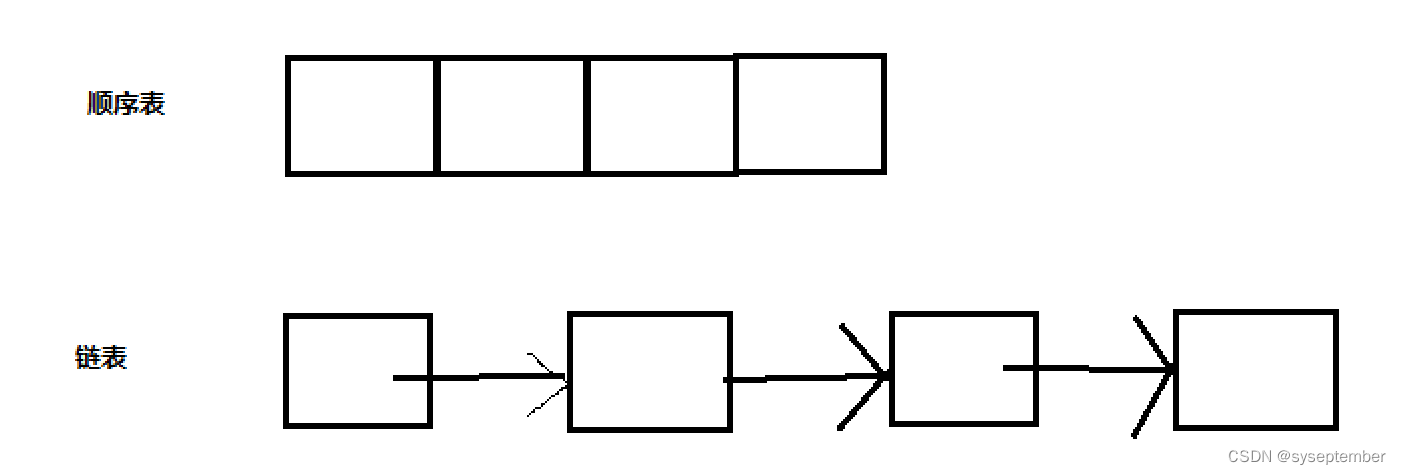
💡答案:顺序表更好。
🔑解析:CPU读取数据时会查看数据是否在缓存中。①如果数据不在缓存中,称为缓存不命中,则会先加载数据到缓存中,再访问该数据;②如果数据在缓存中,称为缓存命中,直接访问该数据。
❕接下来就是顺序表更适合的本质原因了----①由于硬件的设计,当将数据加载到缓存和将当前数据与当前数据后面几个字节(与CPU字节长度有关)一起加载到缓存中所需要的成本是一样的。②当将当前数据加载到缓存中时,计算机会认为你有很大概率访问紧接当前数据的数据。出于这2个原因,在加载当前数据时也会将当前数据后面的字节一并加载到缓存中。🔍顺序表存储的数据是连续的,第一次访问数据时发现当前数据不在缓存中会将当前数据和后面的几个字节一并加载到缓存中,访问第二个数据时发现该数据已经或有部分被加载到缓存中,则可以直接访问,提高效率;🔍链表存储的数据不是连续的,第一次访问数据时会将当前数据和后面几个字节一并加载进缓存中,访问下一个数据时由于数据不是连续存储所以访问的数据大概率没有被加载到缓存中,需要重新加载,这会导致访问速率下降,并且每次加载时会将加载数据后面的字节一并加载,这个数据不是我们想要的,会造成缓存污染。
🔺总结:当需要频繁访问数据时,使用顺序表可以提高缓存命中率,减少缓存污染。
使用场景
🔍如果需要频繁的访问数据和尾插尾删数据或高效存储数据建议使用顺序表。🔍如果需要频繁任意位置插入或者删除建议使用链表。