Perf Event 子系统
Perf 是内置于 Linux 内核源码树中的性能剖析(profiling)工具。它基于事件采样的原理,以性能事件为基础,支持针对处理器相关性能指标与操作系统相关性能指标的性能剖析。可用于性能瓶颈的查找与热点代码的定位。
本文将详细介绍 Linux Perf 的工作模式、Perf Events 的分类、Perf Tool 工具集以及火焰图的相关内容。
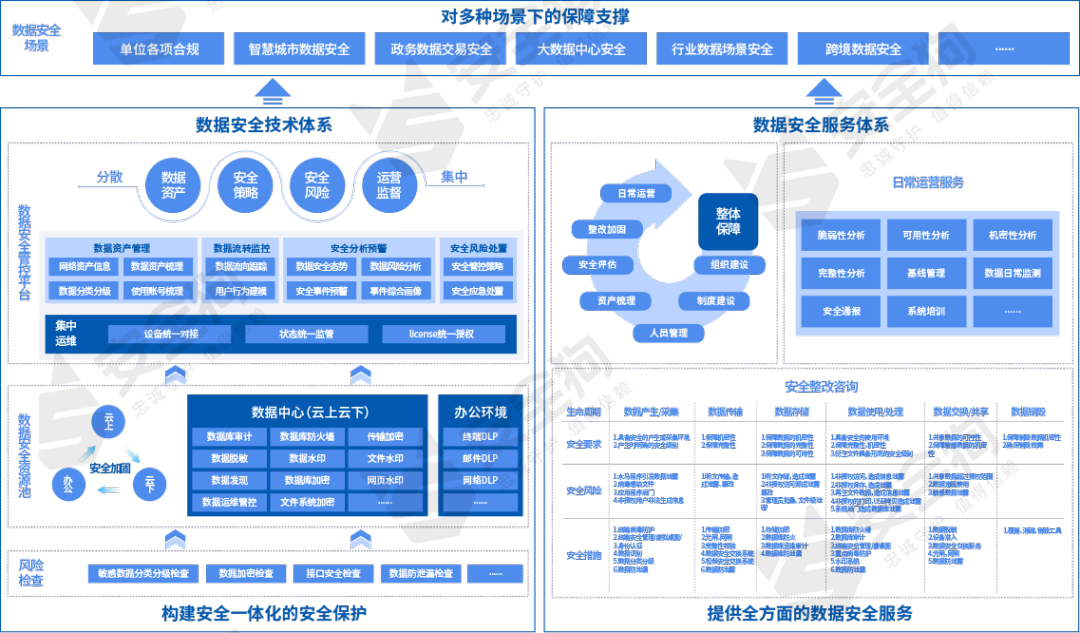
下图展示了Perf的整体架构。

Linux Perf 共由两部分组成:
- Perf Tools:用户态的 Perf Tools 为用户提供了一系列丰富的工具集用于收集、分析性能数据。
- Perf Event Subsystem:Perf Event 子系统是内核众多子系统中的一员,其主要功能是和 Perf Tool 共同完成数据采集的工作。另外,Linux Hard Lockup Detector 也是通过 Perf Event 子系统来实现的。
Perf 工作模式
1. Couting Mode
Counting Mode 将会精确统计一段时间内 CPU 相关硬件计数器数值的变化。为了统计用户感兴趣的事件,Perf Tool 将设置性能控制相关的寄存器。这些寄存器的值将在监控周期结束后被读出。典型工具:Perf Stat。

2. Sampling Mode
Sampling Mode 将以定期采样方式获取性能数据。PMU 计数器将为某些特定事件配置溢出周期。当计数器溢出时,相关数据,如 IP、通用寄存器、EFLAG 将会被捕捉到。典型工具:Perf Record。


Perf Events分类

Couting 事件
# CPU counter statistics for the specified command:
perf stat command
# CPU counter statistics for the specified PID, until Ctrl-C:
perf stat -p PID
# CPU counter statistics for the entire system, for 5 seconds:
perf stat -a sleep 5
# Various basic CPU statistics, system wide, for 10 seconds:
perf stat -e cycles,instructions,cache-references,cache-misses,bus-cycles -a sleep 10
# Various CPU level 1 data cache statistics for the specified command:
perf stat -e L1-dcache-loads,L1-dcache-load-misses,L1-dcache-stores command
# Various CPU data TLB statistics for the specified command:
perf stat -e dTLB-loads,dTLB-load-misses,dTLB-prefetch-misses command
# Various CPU last level cache statistics for the specified command:
perf stat -e LLC-loads,LLC-load-misses,LLC-stores,LLC-prefetches command
# Count syscalls per-second system-wide:
perf stat -e raw_syscalls:sys_enter -I 1000 -a
# Count system calls by type for the specified PID, until Ctrl-C:
perf stat -e 'syscalls:sys_enter_*' -p PID
# Count system calls by type for the entire system, for 5 seconds:
perf stat -e 'syscalls:sys_enter_*' -a sleep 5
# Count scheduler events for the specified PID, until Ctrl-C:
perf stat -e 'sched:*' -p PID
# Count scheduler events for the specified PID, for 10 seconds:
perf stat -e 'sched:*' -p PID sleep 10
# Count ext4 events for the entire system, for 10 seconds:
perf stat -e 'ext4:*' -a sleep 10
# Count block device I/O events for the entire system, for 10 seconds:
perf stat -e 'block:*' -a sleep 10
Profiling 事件
# Sample on-CPU functions for the specified command, at 99 Hertz:
perf record -F 99 command
# Sample on-CPU functions for the specified PID, at 99 Hertz, until Ctrl-C:
perf record -F 99 -p PID
# Sample on-CPU functions for the specified PID, at 99 Hertz, for 10 seconds:
perf record -F 99 -p PID sleep 10
# Sample CPU stack traces (via frame pointers) for the specified PID, at 99 Hertz, for 10 seconds:
perf record -F 99 -p PID -g -- sleep 10
# Sample CPU stack traces for the entire system, at 99 Hertz, for 10 seconds (< Linux 4.11):
perf record -F 99 -ag -- sleep 10
# Sample CPU stack traces for the entire system, at 99 Hertz, for 10 seconds (>= Linux 4.11):
perf record -F 99 -g -- sleep 10
# If the previous command didn't work, try forcing perf to use the cpu-clock event:
perf record -F 99 -e cpu-clock -ag -- sleep 10
# Sample CPU stack traces, once every 10,000 Level 1 data cache misses, for 5 seconds:
perf record -e L1-dcache-load-misses -c 10000 -ag -- sleep 5
# Sample CPU stack traces, once every 100 last level cache misses, for 5 seconds:
perf record -e LLC-load-misses -c 100 -ag -- sleep 5
# Sample on-CPU kernel instructions, for 5 seconds:
perf record -e cycles:k -a -- sleep 5
# Sample on-CPU user instructions, for 5 seconds:
perf record -e cycles:u -a -- sleep 5
Static Tracing 事件
# Trace new processes, until Ctrl-C:
perf record -e sched:sched_process_exec -a
# Sample context-switches, until Ctrl-C:
perf record -e context-switches -a
# Trace all context-switches, until Ctrl-C:
perf record -e context-switches -c 1 -a
# Trace all context-switches via sched tracepoint, until Ctrl-C:
perf record -e sched:sched_switch -a
# Sample context-switches with stack traces, until Ctrl-C:
perf record -e context-switches -ag
# Sample context-switches with stack traces, for 10 seconds:
perf record -e context-switches -ag -- sleep 10
# Sample CS, stack traces, and with timestamps (< Linux 3.17, -T now default):
perf record -e context-switches -ag -T
# Sample CPU migrations, for 10 seconds:
perf record -e migrations -a -- sleep 10
# Trace all connect()s with stack traces (outbound connections), until Ctrl-C:
perf record -e syscalls:sys_enter_connect -ag
# Trace all accepts()s with stack traces (inbound connections), until Ctrl-C:
perf record -e syscalls:sys_enter_accept* -ag
# Trace all block device (disk I/O) requests with stack traces, until Ctrl-C:
perf record -e block:block_rq_insert -ag
# Trace all block device issues and completions (has timestamps), until Ctrl-C:
perf record -e block:block_rq_issue -e block:block_rq_complete -a
# Trace all block completions, of size at least 100 Kbytes, until Ctrl-C:
perf record -e block:block_rq_complete --filter 'nr_sector > 200'
# Trace all block completions, synchronous writes only, until Ctrl-C:
perf record -e block:block_rq_complete --filter 'rwbs == "WS"'
# Trace all block completions, all types of writes, until Ctrl-C:
perf record -e block:block_rq_complete --filter 'rwbs ~ "*W*"'
# Sample minor faults (RSS growth) with stack traces, until Ctrl-C:
perf record -e minor-faults -ag
# Trace all minor faults with stack traces, until Ctrl-C:
perf record -e minor-faults -c 1 -ag
# Sample page faults with stack traces, until Ctrl-C:
perf record -e page-faults -ag
# Trace all ext4 calls, and write to a non-ext4 location, until Ctrl-C:
perf record -e 'ext4:*' -o /tmp/perf.data -a
# Trace kswapd wakeup events, until Ctrl-C:
perf record -e vmscan:mm_vmscan_wakeup_kswapd -ag
# Add Node.js USDT probes (Linux 4.10+):
perf buildid-cache --add `which node`
# Trace the node http__server__request USDT event (Linux 4.10+):
perf record -e sdt_node:http__server__request -a
Dynamic Tracing 事件
# Add a tracepoint for the kernel tcp_sendmsg() function entry ("--add" is optional):
perf probe --add tcp_sendmsg
# Remove the tcp_sendmsg() tracepoint (or use "--del"):
perf probe -d tcp_sendmsg
# Add a tracepoint for the kernel tcp_sendmsg() function return:
perf probe 'tcp_sendmsg%return'
# Show available variables for the kernel tcp_sendmsg() function (needs debuginfo):
perf probe -V tcp_sendmsg
# Show available variables for the kernel tcp_sendmsg() function, plus external vars (needs debuginfo):
perf probe -V tcp_sendmsg --externs
# Show available line probes for tcp_sendmsg() (needs debuginfo):
perf probe -L tcp_sendmsg
# Show available variables for tcp_sendmsg() at line number 81 (needs debuginfo):
perf probe -V tcp_sendmsg:81
# Add a tracepoint for tcp_sendmsg(), with three entry argument registers (platform specific):
perf probe 'tcp_sendmsg %ax %dx %cx'
# Add a tracepoint for tcp_sendmsg(), with an alias ("bytes") for the %cx register (platform specific):
perf probe 'tcp_sendmsg bytes=%cx'
# Trace previously created probe when the bytes (alias) variable is greater than 100:
perf record -e probe:tcp_sendmsg --filter 'bytes > 100'
# Add a tracepoint for tcp_sendmsg() return, and capture the return value:
perf probe 'tcp_sendmsg%return $retval'
# Add a tracepoint for tcp_sendmsg(), and "size" entry argument (reliable, but needs debuginfo):
perf probe 'tcp_sendmsg size'
# Add a tracepoint for tcp_sendmsg(), with size and socket state (needs debuginfo):
perf probe 'tcp_sendmsg size sk->__sk_common.skc_state'
# Tell me how on Earth you would do this, but don't actually do it (needs debuginfo):
perf probe -nv 'tcp_sendmsg size sk->__sk_common.skc_state'
# Trace previous probe when size is non-zero, and state is not TCP_ESTABLISHED(1) (needs debuginfo):
perf record -e probe:tcp_sendmsg --filter 'size > 0 && skc_state != 1' -a
# Add a tracepoint for tcp_sendmsg() line 81 with local variable seglen (needs debuginfo):
perf probe 'tcp_sendmsg:81 seglen'
# Add a tracepoint for do_sys_open() with the filename as a string (needs debuginfo):
perf probe 'do_sys_open filename:string'
# Add a tracepoint for myfunc() return, and include the retval as a string:
perf probe 'myfunc%return +0($retval):string'
# Add a tracepoint for the user-level malloc() function from libc:
perf probe -x /lib64/libc.so.6 malloc
# Add a tracepoint for this user-level static probe (USDT, aka SDT event):
perf probe -x /usr/lib64/libpthread-2.24.so %sdt_libpthread:mutex_entry
# List currently available dynamic probes:
资料直通车:Linux内核源码技术学习路线+视频教程内核源码
学习直通车:Linux内核源码内存调优文件系统进程管理设备驱动/网络协议栈
Perf Tool 工具集介绍
Perf Tool 是一个用户态工具集,包含了 22 种子工具集,下表具体介绍每种工具的基本功能:


Perf List
Perf List:查看当前软硬件平台支持的性能事件列表,性能事件的属性。
- u: 仅统计用户空间程序触发的性能事件
- k: 仅统计内核触发的性能事件
- h: 仅统计 Hypervisor 触发的性能事件
- G: 在 KVM 虚拟机中,仅统计 Guest 系统触发的性能事件
- H: 仅统计 Host 系统触发的性能事件
- p: 精度级别
Perf Stat
Perf Stat:分析性能。
perf stat -p $pid -d # 进程级别统计
perf stat -a -d sleep 5 # 系统整体统计
perf stat -p $pid -e 'syscalls:sys_enter' sleep 10 #分析进程调用系统调用的情形
Perf Top
Perf Top:实时显示系统/进程的性能统计信息, 默认性能事件为 cycles ( CPU 周期数 )。与 Linux top tool 功能类似。
perf top -p $pid -g # 进程级别
perf top -g # 系统整体
Perf Record
Perf Record:记录一段时间内系统/进程的性能事件, 默认性能事件为 cycles ( CPU 周期数 )。
perf record -p $pid -g -e cycles -e cs #进程采样
perf record -a -g -e cycles -e cs #系统整体采样
Perf Script
读取 Perf Record 结果。
-i, --input <file> input file name
-G, --hide-call-graph
When printing symbols do not display call chain
-F, --fields <str> comma separated output fields prepend with 'type:'. Valid types: hw,sw,trace,raw. Fields: comm,tid,pid,time,cpu,event,trace,ip,sym,dso,addr,symoff,period
-a, --all-cpus system-wide collection from all CPUs
-S, --symbols <symbol[,symbol...]>
only consider these symbols
-C, --cpu <cpu> list of cpus to profile
-c, --comms <comm[,comm...]>
only display events for these comms
--pid <pid[,pid...]>
only consider symbols in these pids
--tid <tid[,tid...]>
only consider symbols in these tids
--time <str> Time span of interest (start,stop)
--show-kernel-path
Show the path of [kernel.kallsyms]
--show-task-events
Show the fork/comm/exit events
--show-mmap-events
Show the mmap events
--per-event-dump Dump trace output to files named by the monitored events
Perf Script 输出样式
$ perf script
...
swapper 0 [000] 222998.934740: 1 cycles:
7fff81062eaa native_write_msr_safe ([kernel.kallsyms])
7fff8100ae75 __intel_pmu_enable_all.isra.12 ([kernel.kallsyms])
7fff8100aef0 intel_pmu_enable_all ([kernel.kallsyms])
7fff810077bc x86_pmu_enable ([kernel.kallsyms])
7fff81172817 perf_pmu_enable ([kernel.kallsyms])
7fff81173701 ctx_resched ([kernel.kallsyms])
7fff81173870 __perf_event_enable ([kernel.kallsyms])
7fff8116dfdc event_function ([kernel.kallsyms])
7fff8116eaa4 remote_function ([kernel.kallsyms])
7fff810fbb5d flush_smp_call_function_queue ([kernel.kallsyms])
7fff810fc233 generic_smp_call_function_single_interrupt ([kernel.kallsyms])
7fff810505c7 smp_call_function_single_interrupt ([kernel.kallsyms])
7fff8169a41d call_function_single_interrupt ([kernel.kallsyms])
7fff810367bf default_idle ([kernel.kallsyms])
7fff81037106 arch_cpu_idle ([kernel.kallsyms])
7fff810ea2a5 cpu_startup_entry ([kernel.kallsyms])
7fff81676fe7 rest_init ([kernel.kallsyms])
7fff81b0c05a start_kernel ([kernel.kallsyms])
7fff81b0b5ee x86_64_start_reservations ([kernel.kallsyms])
7fff81b0b742 x86_64_start_kernel ([kernel.kallsyms])
...
火焰图
火焰图是一种剖析软件运行状态的工具,它能够快速的将频繁执行的代码路径以图式的形式展现给用户。根据 Brendan Gregg 先生的介绍,常用的火焰图包括以下 5 种:
- CPU
- Memory
- Off-CPU
- Hot/Cold
- Differential
本文只着重介绍了 CPU 和 Off-CPU 火焰图,若读者对另三种火焰图感兴趣可参看 Brendan Gregg 先生的博客。
CPU 火焰图
CPU 火焰图反映了一段时间内用户程序在 CPU 上运行的热点,其绘制原理是对 Perf 采集到的 samples 进行解析,对函数调用栈进行归纳合并,以柱状图的形式呈现给系统管理员。
图片描述

每个长方块代表了函数调用栈中的一个函数,即为一层堆栈的内容。Y 轴显示堆栈的深度。顶层方块表示 CPU 上正在运行的函数。下面的函数即为它的祖先。X 轴的宽度代表被采集的 sample 的数量,越宽表示采集到的越多。
绘制原理
火焰图的绘制需要 Perf Tool 以及一些 Perl 脚本的辅助。
采集样本 通过 Perf Record 收集 CPU 热点样本原始文件。解析样本 通过 Perf Script 解析样本原始文件,得到样本对应的堆栈。绘制火焰图 统计堆栈中函数出现的频率,并以此绘制火焰图。
Off-CPU 火焰图
On CPU 火焰图可反映某时刻 CPU 的运行热点,然而它却留下了 Off-CPU 的问题:某些程序为何进入睡眠状态?睡眠时长有多久?
下图是一张 Off-CPU 时间图, 展示了一个由于系统调用而被阻塞的应用线程的运行情况。

从图中我们可以看出应用线程长时间被阻塞在 Off-CPU 状态,而这段时间则无法通过 On-CPU 火焰图反映。
Brendan Gregg 共总结了 4 种类型的 Off-CPU 火焰图:
1、I/O 火焰图
File I/O 或 block device I/O 的时间消耗。


2、Off-CPU 火焰图
分析线程睡眠路径的火焰图。

3、Wakeup 火焰图
分析线程被阻塞源头的火焰图。

4、Chain 火焰图
结合了 Off-CPU 和 Wakeup 火焰图,详细记录了线程的睡眠原因及唤醒条件。注意:Chain 火焰图性能开销巨大,慎用!

Off-CPU 火焰图绘制原理
通过 Off-CPU 火焰图,我们可以轻松地了解系统中任何进程的睡眠过程。其原理是利用 Perf Static Tracer 抓取一些进程调度的相关事件,并利用 Perf Inject 将这些事件合并,最终得到诱发进程睡眠的调用流程以及睡眠时间。
相关 Tracepoints 介绍
1、sched : sched_switch
记录了某进程引发调度器调度的执行流程,即产生进程切换的原因。产生进程切换的原因可能存在多种:
- 时间片耗尽
- 等待资源,如 I/O
- 等待锁释放
- 主动放弃 CPU
2、sched : sched_stat_sleep
由于主动放弃 CPU 而进入睡眠的等待事件。它记录了进程处于睡眠状态的时间。
3、sched : sched_stat_iowait
由于磁盘或网络 I/O 而引发的等待事件。它记录了进程因为等待 I/O 资源而进入 D 状态的时间。
4、sched : sched_stat_blocked
由于等待内核锁而引发的等待事件。它记录了进程等待锁释放而进入 D 状态的时间。
5、sched : sched_stat_wait
这个事件记录了进程在就绪队列中等待执行的时间。
实例介绍
下面这个例子介绍了如何统计系统中进入 S 状态的进程的睡眠时长及原因。
root@node10:/home$ echo 1 >/proc/sys/kernel/sched_schedstats
root@node10:/home$ perf record -e sched:sched_stat_sleep -e sched:sched_switch -a -g -o perf.data.raw sleep 1
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.430 MB perf.data.raw (1031 samples) ]
root@node10:/home$ perf inject -s -v -i perf.data.raw -o perf.data
build id event received for [kernel.kallsyms]: f63207ec0e8d394d5a860306746f9064bfd0290a
symsrc__init: cannot get elf header.
Looking at the vmlinux_path (7 entries long)
Using /proc/kcore for kernel object code
Using /proc/kallsyms for symbols
通过追踪 sched_switch 事件获取相关进程切换的调用栈;通过追踪 sched_stat_sleep 事件获取进程的睡眠时间,最后利用 Perf Inject 合并两个事件即可。下面我们看看合并的过程:
1、首先查看合并前的事件:
root@node10:/home$ perf script -i perf.data.raw -F comm,pid,tid,cpu,time,period,event,ip,sym,dso,trace
...
client 2344/2345 [007] 342165.258739: 1 sched:sched_switch: prev_comm=client prev_pid=2345 prev_prio=120 prev_state=S ==> next_comm=swapper/7 next_pid=0 next_prio=120
7fff8168dbb0 __schedule ([kernel.kallsyms])
7fff8168e069 schedule ([kernel.kallsyms])
7fff8168d0f2 schedule_hrtimeout_range_clock ([kernel.kallsyms])
7fff8168d1a3 schedule_hrtimeout_range ([kernel.kallsyms])
7fff81215215 poll_schedule_timeout ([kernel.kallsyms])
7fff81215b91 do_select ([kernel.kallsyms])
7fff81215e5b core_sys_select ([kernel.kallsyms])
7fff812162af sys_pselect6 ([kernel.kallsyms])
7fff81699089 system_call_fastpath ([kernel.kallsyms])
1cc4e3 runtime.usleep (/usr/local/gundam/gundam_client/client)
1aac33 runtime.sysmon (/usr/local/gundam/gundam_client/client)
1373300000500 [unknown] ([unknown])
58b000003d98f0f [unknown] ([unknown])
...
swapper 0/0 [007] 342165.260097: 1358063 sched:sched_stat_sleep: comm=client pid=2345 delay=1358063 [ns]
7fff810d2a40 enqueue_entity ([kernel.kallsyms])
7fff810d2f59 enqueue_task_fair ([kernel.kallsyms])
7fff810bf481 enqueue_task ([kernel.kallsyms])
7fff810c3dc3 activate_task ([kernel.kallsyms])
7fff810c4103 ttwu_do_activate.constprop.91 ([kernel.kallsyms])
7fff810c72e9 try_to_wake_up ([kernel.kallsyms])
7fff810c7483 wake_up_process ([kernel.kallsyms])
7fff810b6662 hrtimer_wakeup ([kernel.kallsyms])
7fff810b6d72 __hrtimer_run_queues ([kernel.kallsyms])
7fff810b7310 hrtimer_interrupt ([kernel.kallsyms])
7fff81052fd7 local_apic_timer_interrupt ([kernel.kallsyms])
7fff8169b78f smp_apic_timer_interrupt ([kernel.kallsyms])
7fff81699cdd apic_timer_interrupt ([kernel.kallsyms])
7fff81516a69 cpuidle_idle_call ([kernel.kallsyms])
7fff810370ee arch_cpu_idle ([kernel.kallsyms])
7fff810ea2a5 cpu_startup_entry ([kernel.kallsyms])
7fff8105107a start_secondary ([kernel.kallsyms])
...
2、合并后的事件:
root@node10:/home$ perf script -i perf.data -F comm,pid,tid,cpu,time,period,event,ip,sym,dso,trace
...
client 2344/2345 [007] 342165.260097: 1358063 sched:sched_switch: prev_comm=client prev_pid=2345 prev_prio=120 prev_state=S ==> next_comm=swapper/7 next_pid=0 next_prio=120
7fff8168dbb0 __schedule ([kernel.kallsyms])
7fff8168e069 schedule ([kernel.kallsyms])
7fff8168d0f2 schedule_hrtimeout_range_clock ([kernel.kallsyms])
7fff8168d1a3 schedule_hrtimeout_range ([kernel.kallsyms])
7fff81215215 poll_schedule_timeout ([kernel.kallsyms])
7fff81215b91 do_select ([kernel.kallsyms])
7fff81215e5b core_sys_select ([kernel.kallsyms])
7fff812162af sys_pselect6 ([kernel.kallsyms])
7fff81699089 system_call_fastpath ([kernel.kallsyms])
1cc4e3 runtime.usleep (/usr/local/gundam/gundam_client/client)
1aac33 runtime.sysmon (/usr/local/gundam/gundam_client/client)
1373300000500 [unknown] ([unknown])
58b000003d98f0f [unknown] ([unknown])
...
总结
本文首先介绍了 Linux Perf Event 子系统的整体架构,接着为读者展示了 Perf 的两种工作模式及各种类别的 Perf Events,之后详细介绍了 Perf Tool 的多种子工具集,最后为读者展示了 Bredan Gregg 先生引入的各种火焰图及其绘制原理。通过阅读本文,读者将会对 Linux Perf 有更为深入的理解。