2023 中国开源未来发展峰会于 5 月 13 日成功举办。在大会开源原生商业分论坛,Kyligence 解决方案架构高级总监张小龙发表《云原生大数据底座演进 》主题演讲,向与会嘉宾介绍了他对开源发展的见解,数据底座向云原生湖仓一体架构演进的趋势,以及 Kyligence 湖仓引擎能够在构建下一代云原生数据底座发挥重要价值,通过提升计算性能,大幅度降低计算成本,以下是演讲内容:

大家好,本次演讲内容包含三个部分:
第一部分的内容,是基于个人经历、以及所见所闻产生的思考,来谈谈我对发展开源的一些观点。
第二部分的内容,是谈一谈为什么我认为基础关键核心技术将获得新的发展机遇。
最后一部分,是围绕新的发展机遇,介绍行业上数据底座的演进趋势,以及我们公司的一些实践情况。

在第一部分——开源之我见,我以 Kyligence 公司的过往经历作为论据,进而提出三个观点:

第一个观点是:开源软件技术及其商业化是驱动各领域数字化变革的重要力量。
首先介绍下 Apache Kylin 和 Kyligence。
Apache Kylin™是一个开源的、分布式的分析型数据仓库。
跬智信息(Kyligence)是由 Apache Kylin 创始团队于 2016 年创办,是领先的大数据分析和指标平台供应商。
大家看到众多企业 Logo,目前全球有超过1500多家企业使用 Apache Kylin 和 Kyligence 商业产品,解决数字运营和分析决策等方面的痛点。企业的丰富实践在不断地驱动开源和商业化发展,同时开源和商业化也在驱动更多的领域实现数字化变革。
Apache Kylin 和 Kyligence 发展较为成熟,不过这也仅仅是无数开源和开源商业化力量之一,开源和其背后的商业化是驱动各领域数字化变革的重要力量,大力发展这些力量有十分重大的意义和价值。

第二个观点是:开源软件生态繁荣依托数字经济蓬勃发展带来的溢出效应。
因为,数字经济包含了数字产业化和产业数字化两部分。
首先,通过数字产业化来储备高水平的技术和数量众多的人才,行业发展从零和博弈走向协同发展,这是发展好开源的基本条件。
进而,数字产业化产生的技术和人才,会在产业数字化过程中发挥巨大作用。传统行业的数字化转型可以通过使用开源项目,支持商业化来加快转型的步伐,同时为开源注入可持续发展的动力。
从这条时间线来观察 Apache Kylin 和 Kyligence 的发展历程,我认为可以很好证明这个观点,2015 年之前, Kylin 项目在 ebay 发展进而贡献到 Apache 基金会,这是数字产业化的过程,而后恰逢产业数字化高速推进,传统行业数字化转型支持了 Kyligence 的商业发展,也为它注入了动力和活力,使它能够进一步为产业数字化贡献力量,从 2016 年开始 Kyligence 成为了推动开源 Kylin 演进的重要力量,而后又贡献了 Byzer 和 Gluten 两个开源项目。我认为,影响开源生态繁荣程度的根本,是数字经济和商业环境的发展水平,大家需要坚持长期主义,坚持合作与共赢。

第三个观点是:开源软件生态创造社会价值,尤其需要依靠长期有计划有组织的投入。
Github 每年会基于托管的开源项目做调查分析,最近一次的结论值得关注。报告提到,大型开源项目几乎都是由科技公司进行领导和维护,其中多数项目是关键基础技术,例如框架、编译器、编程语言。而贡献者数量最大的开源项目背后几乎都有商业支持。
还是以 Kyligence 为例,Kyligence 目前领导的 Apache Kylin 之外的两个项目也取得了不错的成绩。
Byzer 是面向 Data 和 AI 的低代码开发平台,因为提供商业支持,金融业的开源贡献者也深度参与其中,项目目前应用在金融业等行业的生产业务中。
Gluten 是向量化计算引擎,它的目标是力求做到,相比原生 Spark,其计算性能提升数倍。因为 Apache Spark 是大数据领域应用极其广泛的开源分布式计算引擎之一,因此 Gluten 致力于通过性能的提升以及结合云计算的弹性,提升现有 Spark 用户的 IT 算力投资汇报率,为用户节省成本。

第二部分,国家提出了建设数字中国大战略,在这个背景之下,我特别关注数据技术会获得哪些新的发展机遇,在这部分与大家共同探讨。
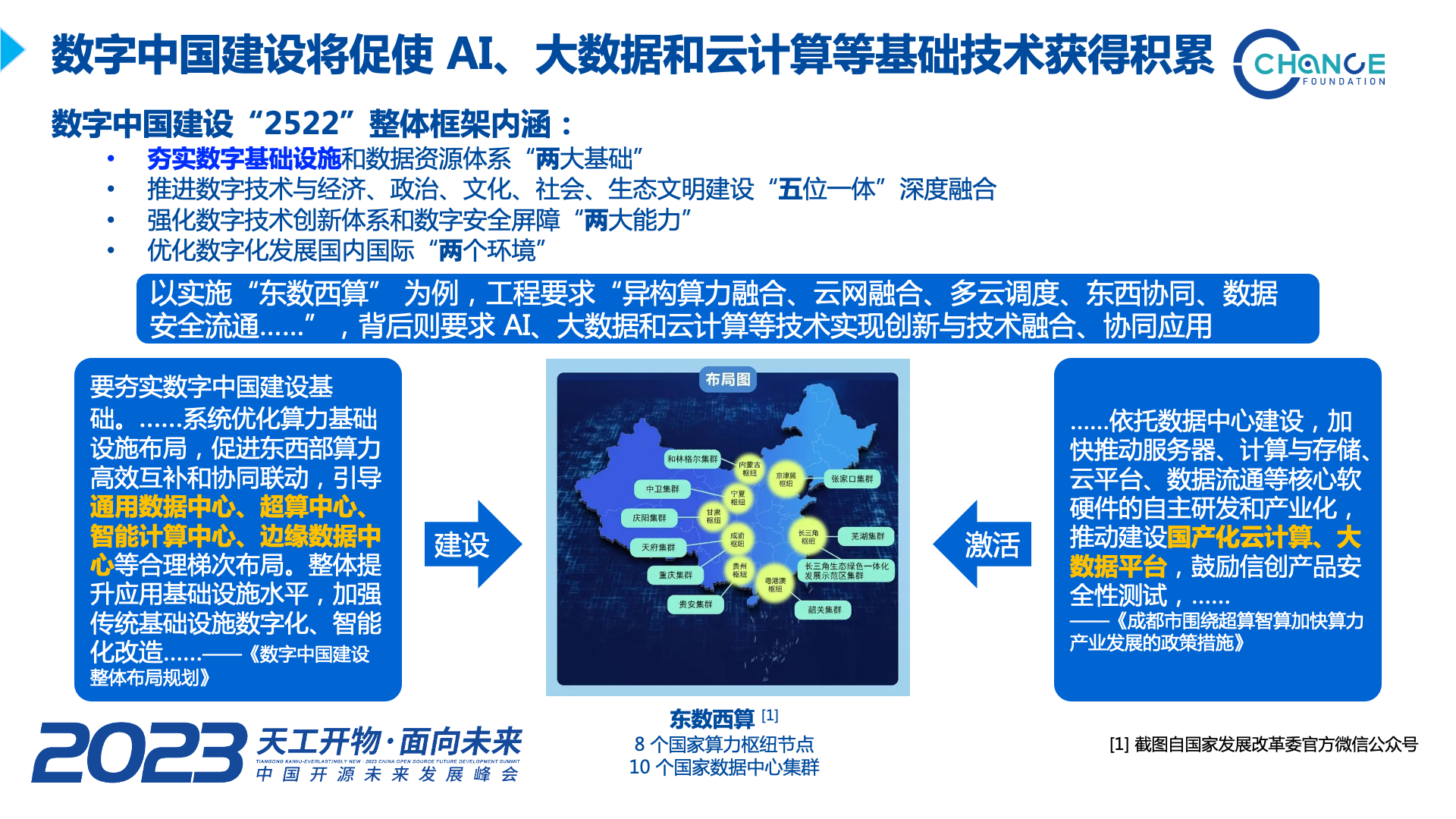
数字中国建设规划宏大、系统且全面,我认为其中对基础关键技术发展促进最大的方面,是来自“2522”框架中“两大基础”之一,夯实数字基础设施这个重要策略。以这几年大力发展的“东数西算”工程为例,它布局规划了众多的通用数据中心、超算中心、智能计算中心、边缘数据中心,并且提出了“异构算力融合、云网融合、多云调度、东西协同、数据安全流通……”等一系列的发展要求,这显而易见会促使人工智能、大数据和云计算等基础技术的创新,将他们进行融合、协同应用是未来的重要发展方向。
在“东数西算” 工程中,全国有 8 个国家算力枢纽节点,包含 10 个国家数据中心集群。重庆集群和成渝枢纽是其中重要的算力力量,重庆地区相关产业将获得非常好的发展机会。
而从近期一些地方发布的算力产业发展政策措施可以看出,以服务器、计算与存储、云平台、数据流通等核心软硬件为基础的国产化云计算、大数据平台发展将进入快车道,这将进一步促进人工智能、大数据和云计算等基础技术的创新发展,是非常难得的发展机遇。

面对上述机遇,我们认为大数据、人工智能与云原生技术的结合,是迎接上述机遇的良好抓手,第三部分与大家分享我们相关的实践经验。
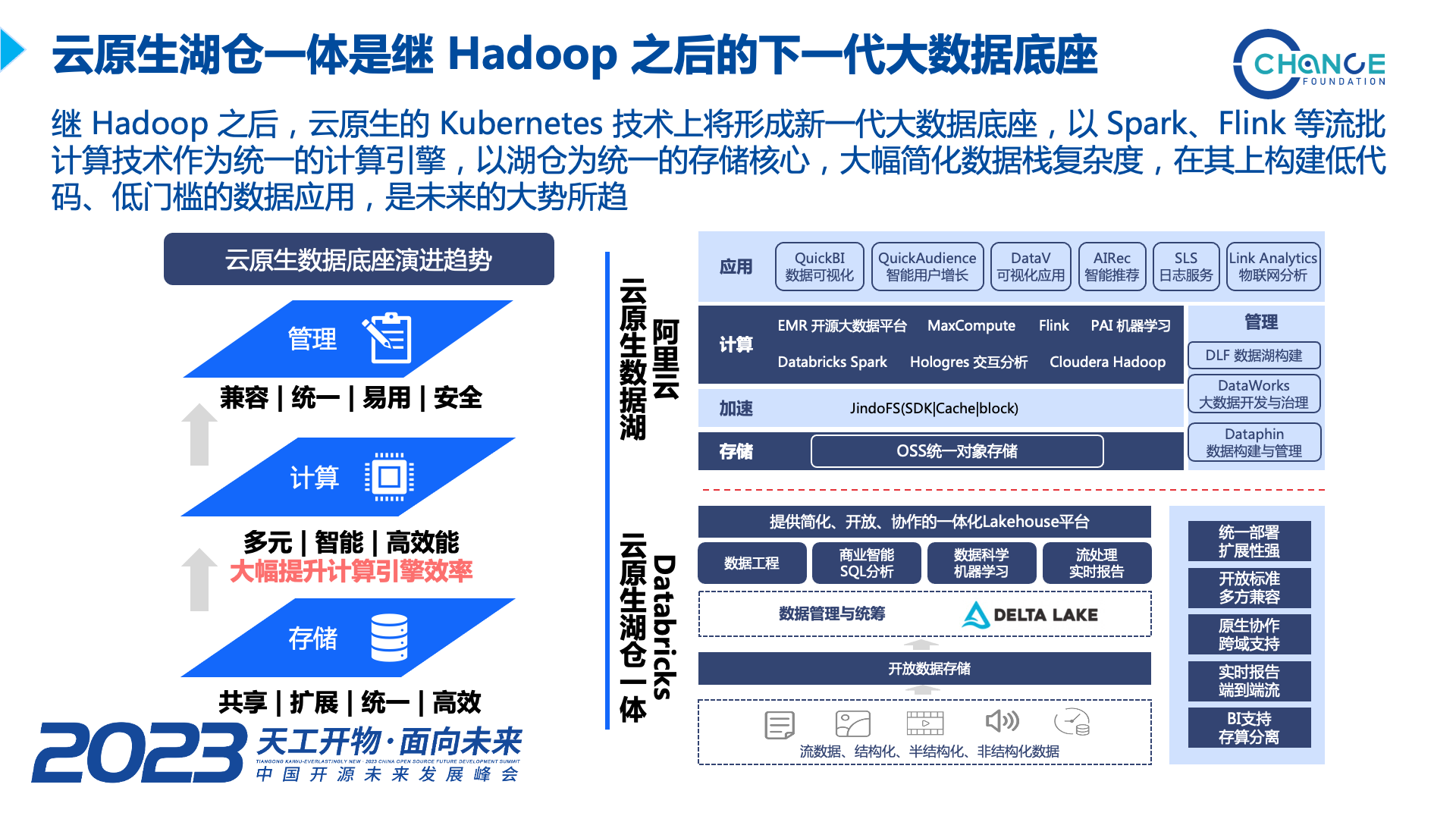
我们看到,国内外的头部企业,如阿里云和 Databricks,不约而同在推动云原生架构的数据湖和湖仓一体发展,再结合 Kyligence 的实践经验,我们认为继Hadoop 之后,在云原生的 Kubernetes 技术上将形成新一代大数据底座,以 Spark、Flink 等流批计算技术作为统一的计算引擎,以湖仓为统一的存储核心,大幅简化数据栈复杂度,在其上构建低代码、低门槛的数据应用,是未来的大势所趋。

为顺应这样的趋势,Kyligence 推出了湖仓引擎,它采用向量化计算技术,兼容 Spark 生态应用,成为支撑湖仓平台运行的高性能、敏捷、弹性、开放的引擎。
用户目前可以在 Kubernetes 容器云部署试用这项技术,能够体验到,向量化 Spark 计算性能相比原生Spark 提升1 倍,计算成本下降 50%。
这项技术正在处于开放试用体验阶段,我们已经有一些企业用户尝试拿它来降低公有云上离线计算成本,或者去提升 Hadoop 集群的计算性能,在一些场景收获了不错的效果。
接下来我播放一段 5 分钟的 Demo 视频,带大家来了解:1. 如何部署湖仓引擎;2. 如何与原生 Spark 对比性能;3. 用户如何用新的引擎执行自定义 SQL,查询或处理自定义的数据;4. 用户如何快速添加自定义版本计算引擎,与湖仓引擎做成本对照。

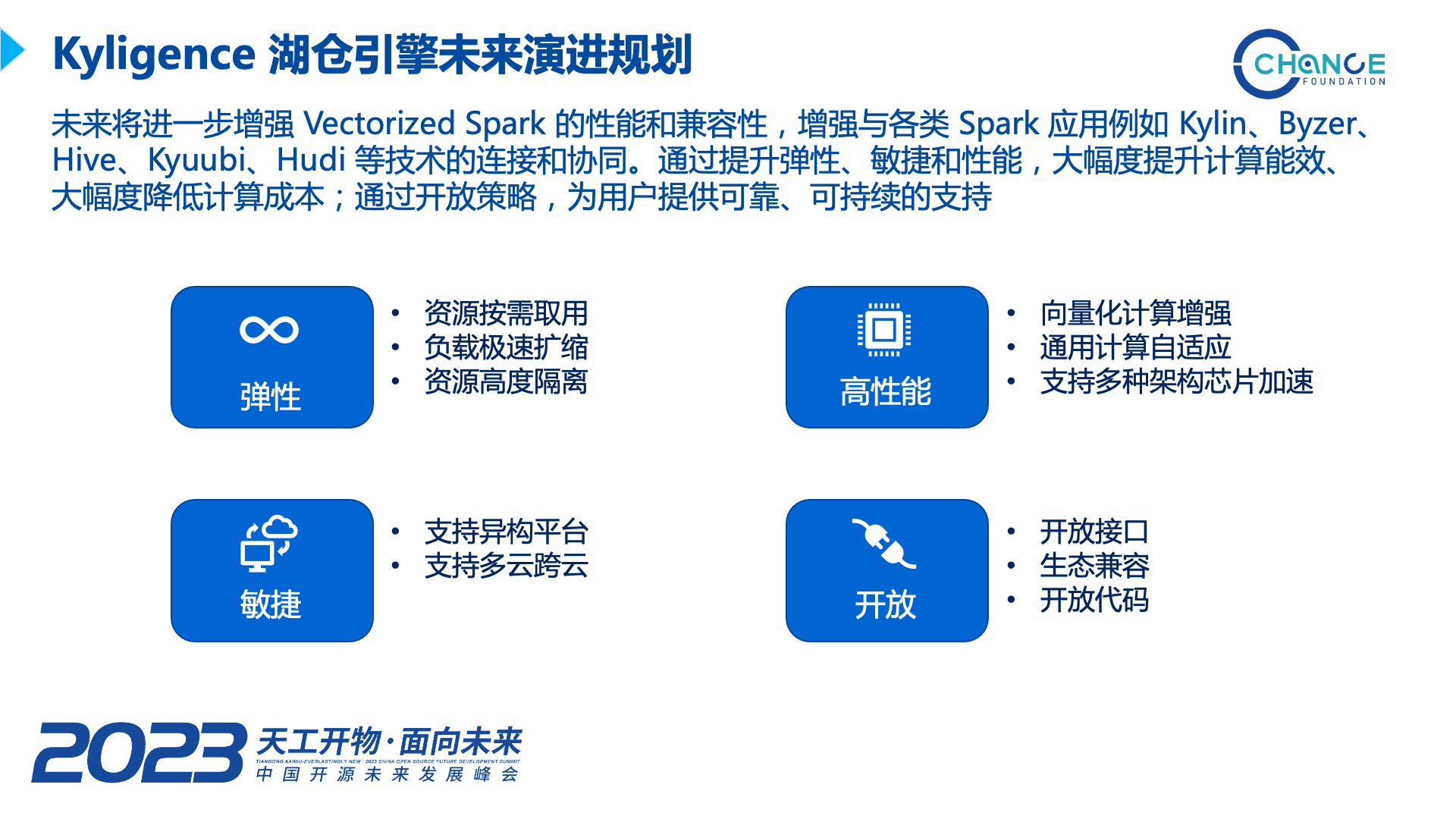
未来我们计划进一步增强向量化 Spark 引擎的性能和兼容性,加强与各类 Spark 应用的连接和协同。与云原生技术充分结合,提升引擎的弹性、敏捷性和性能,大幅度提升计算能效、大幅度降低计算成本;并通过开放的策略,为用户提供可靠、可持续的支持。
- 在弹性方面,将做到资源按需取用,负载极速扩缩,资源高度隔离;
- 在高性能方面,将使向量化计算的算子进一步得到增强,兼容通用计算平台,支持利用多种架构芯片来进行计算加速;
- 在敏捷方面,将支持运行在异地异构的计算平台,支持多云跨云;
- 在开放方面,我们将始终开放接口标准,并且始终兼容 Spark 标准接口,与 Spark 生态中其他技术做好融合,承接好国产化、信创建设要求,在与企业商业合作的同时,开放核心源代码,支持企业对核心基础技术做到自主可控,确保软件供应链的可靠可信。
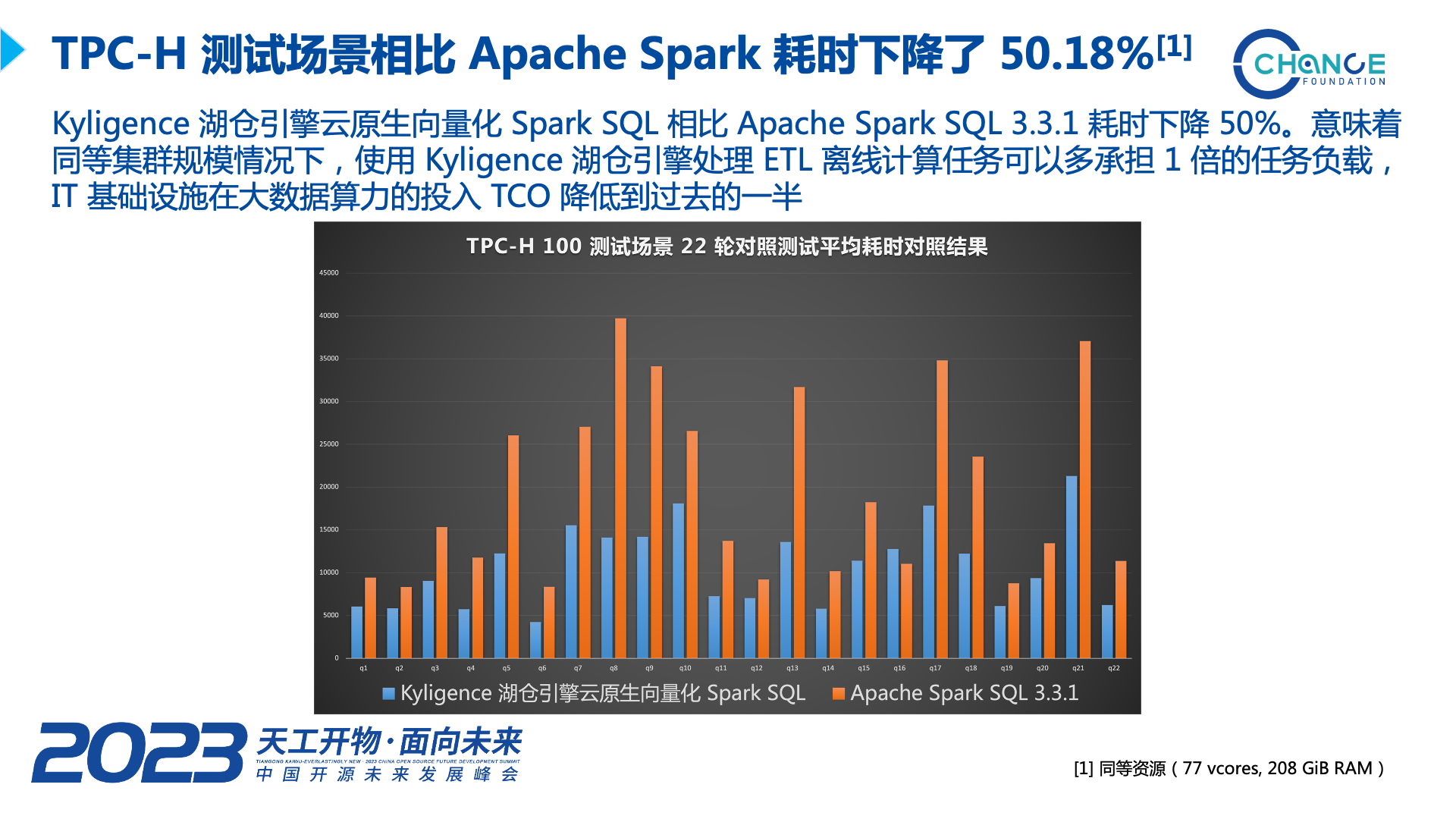
接下来把 Kyligence 湖仓引擎与 Apache Spark 在 TPC-H 场景下测试报告分享给大家,可以看到向量化的 Spark 引擎通过性能提升,节省了一半的计算资源,为用户降低了 50% 的使用成本。自从决定对他提供商业化支持后,Kyligence 正在加倍投入资源,使这项技术以更快的速度进步。我们希望有更多的原本使用 Spark 作为计算引擎的用户,能尝试使用 Kyligence 湖仓引擎来获得更低的使用成本,更好的使用体验,邀请大家一起推动这项新技术进步、产生价值。
大家可以扫屏幕上的二维码,关注 Kyligence ,加入湖仓引擎试用交流群,或者添加我个人的微信做进一步交流,我今天的分享就到这里,谢谢大家!

再次感谢大会主办方邀请,我们愿意与各位一起,为中国开源事业的可持续发展,为数字中国建设添砖加瓦。
有兴趣免费试用 Kyligence 湖仓引擎的听众请扫码或者点击链接填写相关信息。提交后,我们将会发送Kyligence 湖仓引擎的免费试用链接到您的邮箱。





![【算法学习系列】03 - 由[1-5]等概率随机实现[2-10]等概率随机](https://img-blog.csdnimg.cn/b38795eb6ab44f54afdd7e5fa6bbd2de.png)