文章目录
- 前言
- MySQL——运维篇
- 一、日志
- 1.日志-错误日志
- 2.日志-二进制日志
- 3.日志-查询日志
- 4.日志-慢查询日志
- 二、主从复制
- 1.主从复制-概述
- 2.主从复制-原理
- 3.主从复制-搭建
- 3.1.主从复制-搭建-主库配置
- 3.2.主从复制-搭建-从库配置
- 3.2.主从复制-搭建-测试
- 三、分库分表
- 1.分库分表-介绍
- 1.1.分库分表-介绍
- 1.2.分库分表-介绍-拆分方式
- 2.分库分表-MyCat概述
- 2.1.分库分表-MyCat概述-安装
- 2.2.分库分表-MyCat概述-核心概念
- 3.分库分表-MyCat入门
- 3.1分库分表-MyCat入门
- 3.2.分库分表-MyCat入门-测试
- 4.分库分表-MyCat配置
- 5.分库分表-MyCat分片
- 5.1.分库分表-MyCat分片-垂直分库
- 5.2.分库分表-MyCat分片-垂直分库-测试
- 5.3.分库分表-MyCat分片-水平分表
- 6.分库分表-分片规则
- 6.1.分库分表-分片规则-范围分片
- 6.2.分库分表-分片规则-取模分片
- 6.3.分库分表-分片规则-一致性hash算法
- 6.4.分库分表-分片规则-枚举分片
- 6.5.分库分表-分片规则-应用指定算法
- 6.6.分库分表-分片规则-固定hash算法
- 6.7.分库分表-分片规则-字符串hash解析
- 6.8.分库分表-分片规则-按天分片
- 6.9.分库分表-分片规则-按自然月分片
- 7.分库分表-MyCat管理与监控
- 7.1.分库分表-MyCat管理与监控-原理
- 7.2.分库分表-MyCat管理工具
- 7.3.分库分表-MyCat监控1
- 四、读写分离
- 1.读写分离-介绍
- 2.读写分离-一主一从准备
- 3.读写分离-一主一从读写分离
- 4.读写分离-双主双从介绍
- 5.读写分离-双主双从搭建
- 6.读写分离-双主双从读写分离
此文档来源于网络,如有侵权,请联系删除!
前言
MySQL是一个关系型数据库管理系统。MySQL 是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件之一。MySQL所使用的 SQL 语言是用于访问数据库的最常用标准化语言。MySQL体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,一般中小型和大型网站的开发都选择 MySQL 作为网站数据库。
SQL是结构化查询语言(Structured Query Language)的英文首字母,它是一种专门用来与数据库通信的语言。
MySQL——运维篇
一、日志
1.日志-错误日志
-
错误日志
错误日志是 MySQL 中最重要的日志之一,它记录了当 mysgld 启动和停止时,以及服务器在运行过程中发生任何严重错误时的相关信息。当数据库出现任何故障导致无法正常使用时,建议首先查看此日志。
该日志是默认开启的,默认存放目录 /var/log/,默认的日志文件名为 mysqld.log 。
查看日志位置
show variables like '%log error%';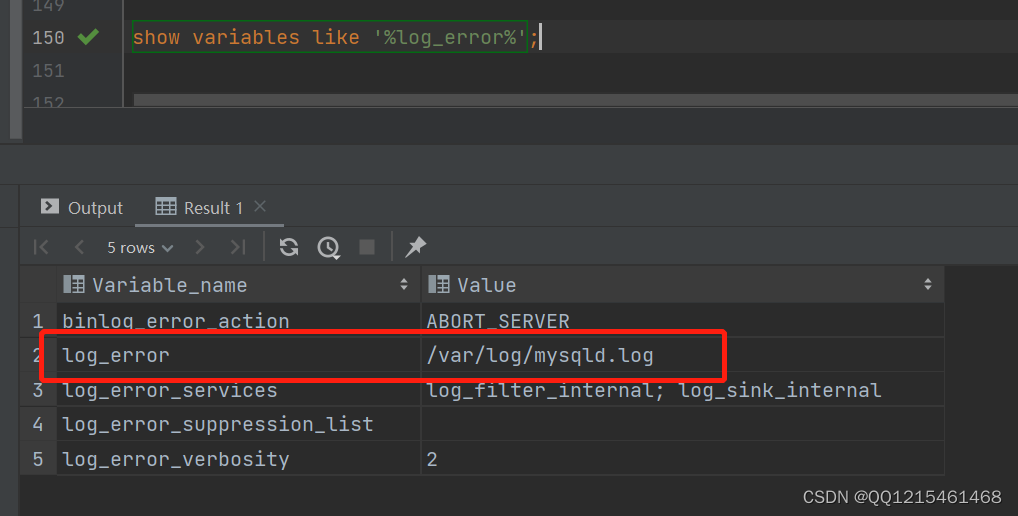
2.日志-二进制日志
-
二进制日志
介绍二进制日志(BINLOG)记录了所有的 DDL(数据定义语言)语和 DML(数据操纵语言)语句,但不包括数据查询(SELECT、SHOW)语句。
作用
①.灾难时的数据恢复;
②.MySQL的主从复制。在MySQL8版本中,默认二进制日志是开启着的,Linux系统日志存放在/var/lib/mysql路径下。涉及到的参数如下:
show variables like '%log_bin%';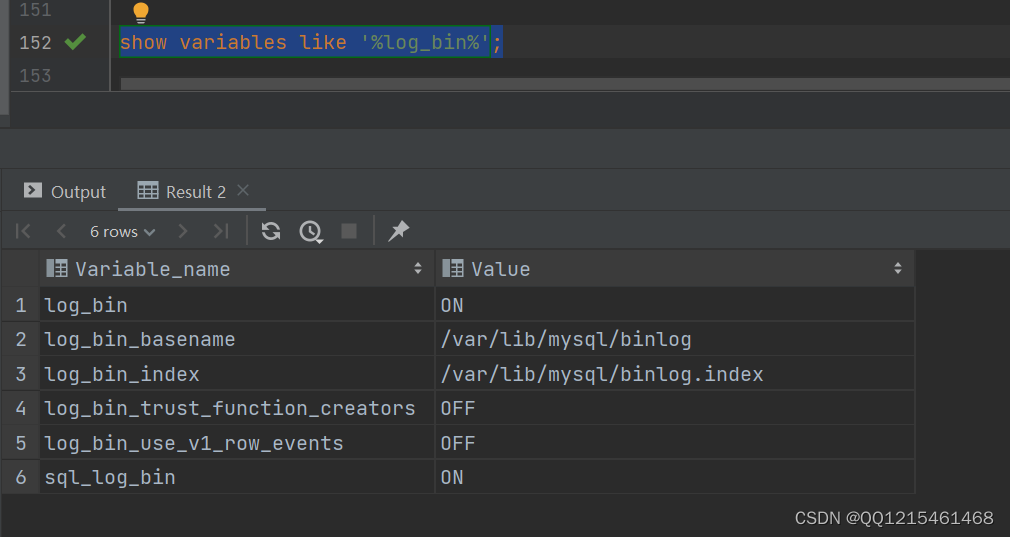
日志格式
MySQL服务器中提供了多种格式来记录二进制日志,具体格式及特点如下:
日志格式 含义 STATEMENT 基于SQL语句的日志记录,记录的是SQL语句,对数据进行修改的SQL都会记录在日志文件中。 ROW 基于行的日志记录,记录的是每一行的数据变更。(默认) MIXED 混合了STATEMENT和ROW两种格式,默认采用STATEMENT,在某些特殊情况下会自动切换为ROW进行记录。 show variables like '%binlog_format%';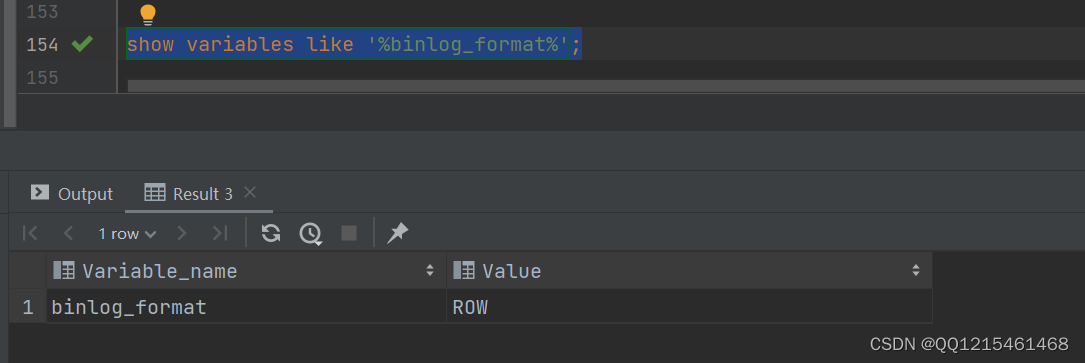
日志查看
由于日志是以二进制方式存储的,不能直接读取,需要通过二进制日志查询工具 mysqlbinlog 来查看,具体语法:
mysqlbinlog [参数选项] log-files 参数选项: -d 指定数据库名称,只列出指定的数据库相关操作。 -o 忽略掉日志中的前n行命令。 -v 将行事件(数据变更)重构为SQL语句。 -w 将行事件(数据变更)重构为SQL语句,并输出注释信息。
将日志格式修改为STATEMENT
#编辑配置文件 vim /etc/my.cnf
#添加参数(:wq保存退出) binlog_format=STATEMENT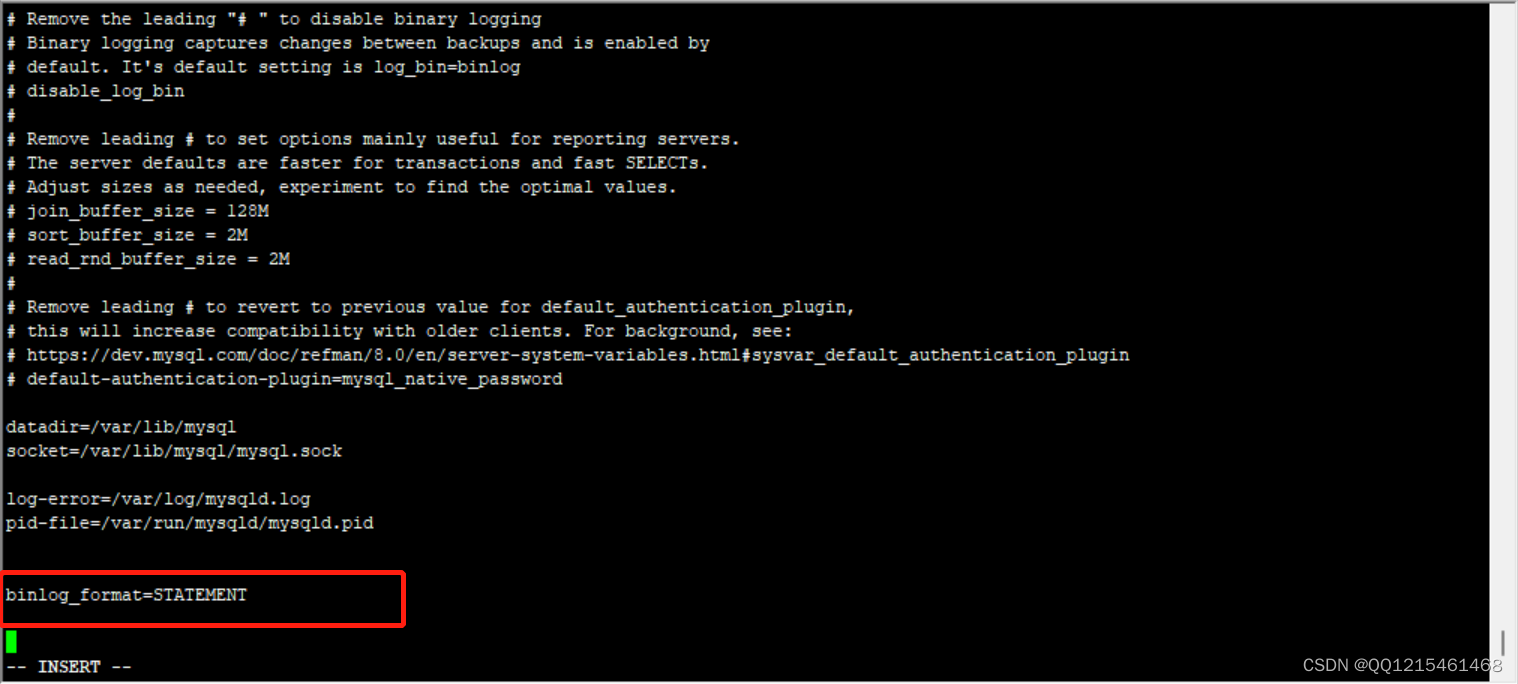
#重启数据库服务 systemctl restart mysqld
#查看日志格式 show variables like '%binlog_format%';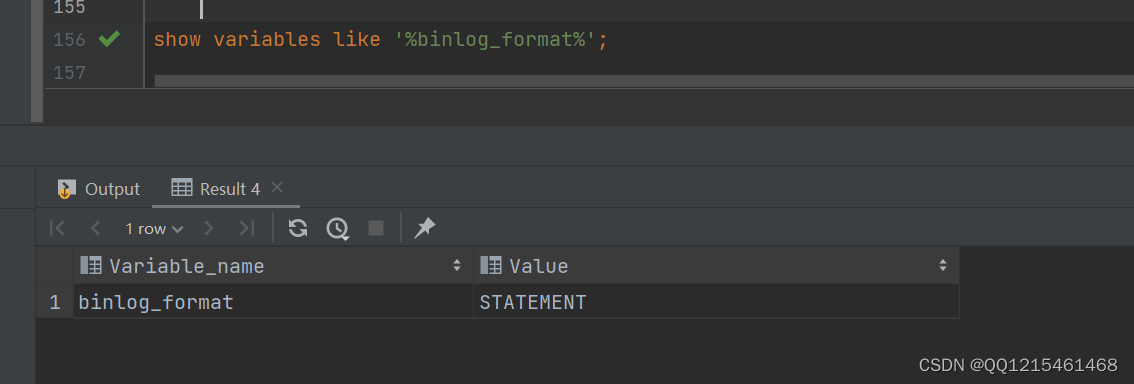
日志删除
对于比较繁忙的业务系统,每天生成的binlog数据巨大,如果长时间不清除,将会占用大量磁盘空间。可以通过以下几种方式清理日志:
指令 含义 reset master 删除全部binlog日志,删除之后,日志编号,将从 binlog.000001重新开始 purge master logs to ‘binlog.******’ 删除******编号之前的所有日志 purge master logs before ‘yyyy-mm-dd hh24:mi:ss’ 删除日志为"yyyy-mm-dd hh24:mi:ss"之前产生的所有日志 也可以在mysql的配置文件中配置二进制日志的过期时间,设置了之后,二进制日志过期会自动删除
#默认为2592000秒=30天 show variables like '%binlog_expire_logs_seconds%';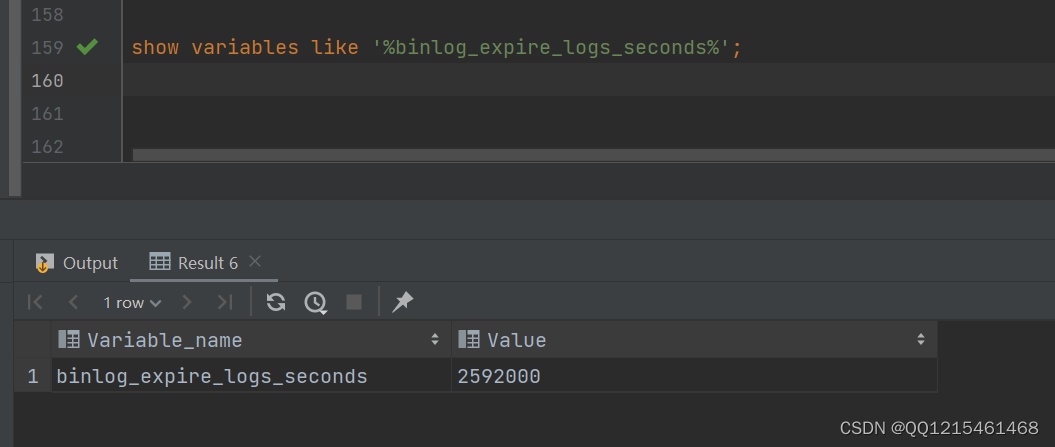
例子reset master;
例子#删除binlog.000008之前二进制日志文件 purge master logs to 'binlog.000008';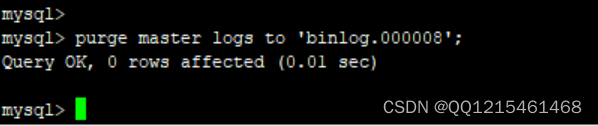
3.日志-查询日志
-
查询日志
查询日志中记录了客户端的所有操作语句,而二进制日志不包含查询数据的SQL语句。默认情况下,查询日志是未开启的。如果需要开启查询日志,可以设置以下配置:
show variables like '%general%';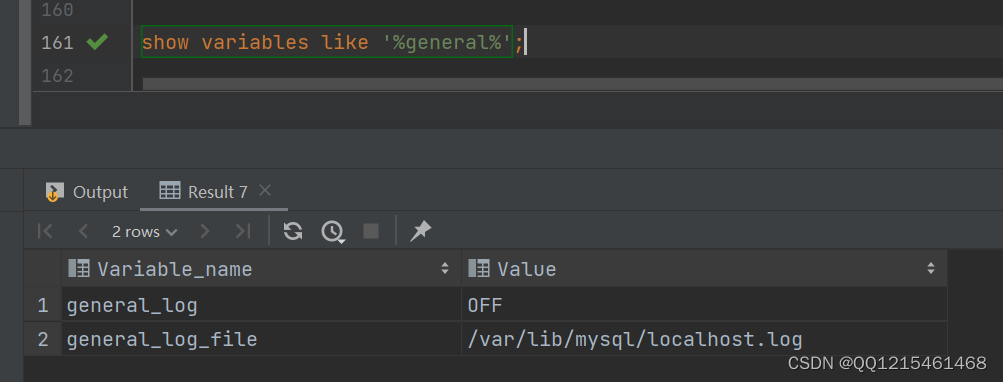
修改MySQL的配置文件 /etc/my.cnf 文件,添加如下内容:
#该选项用来开启查询日志,可选值:0 或者1;0代表关闭,1代表开启 general_log=1 #设置日志的文件名,如果没有指定,默认的文件名为 host_name.log general_log_file=mysql_query.log示例#修改配置文件 vim /etc/my.cnf
#开启查询日志 general_log=1 #设置日志的文件名为host_name.log general_log_file=/var/lib/mysql/mysql_query.log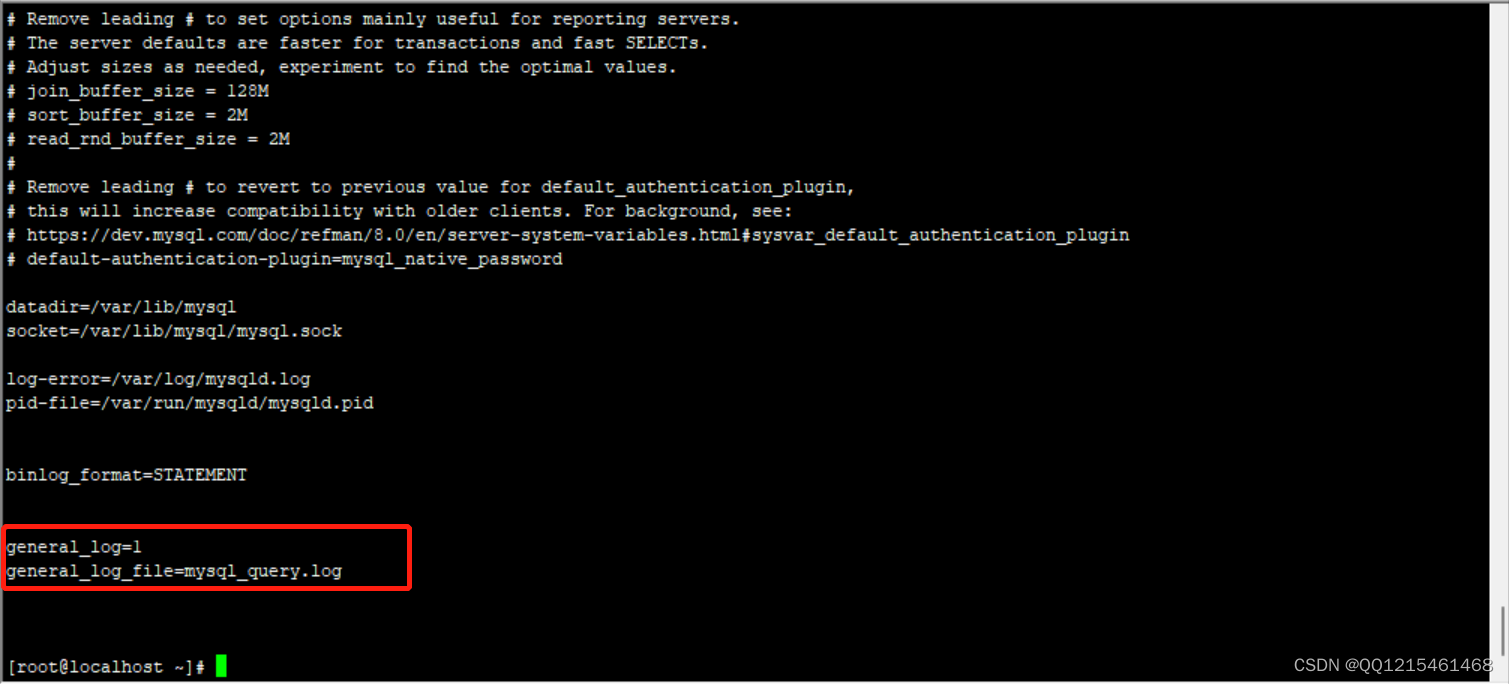
#重启数据库服务 systemctl restart mysqld
#查看查询日志相关配置(修改完成) show variables like '%general%';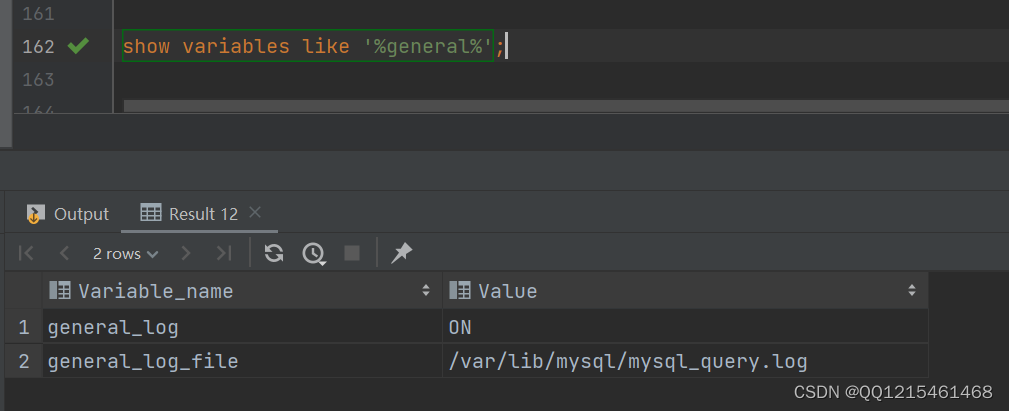
#查看/var/lib/mysql目录下的文件信息(mysql_query.log文件已生成) ll /var/lib/mysql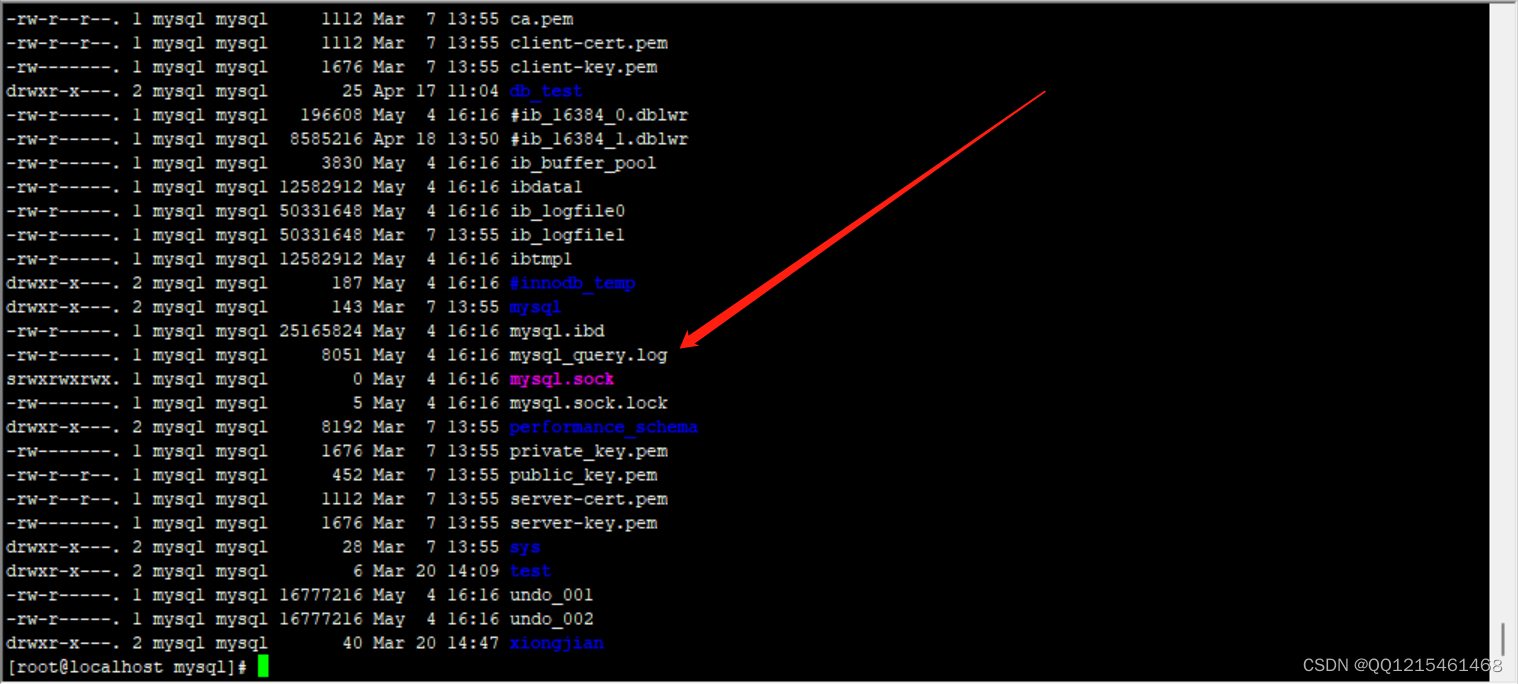
查询日志记录了所有增删改查以及DDL语句(日志文件比较大)
4.日志-慢查询日志
-
慢查询日志
慢查询日志记录了所有执行时间超过参数 long_query_time 设置值并且扫描记记录数不小于 min_examined_row_limit的所有的SQL语句的日志,默认未开启。long_query_time 默认为 10 秒,最小为0,精度可以到微秒。
#查看慢查询日志相关参数配置 show variables like '%slow_query_log%';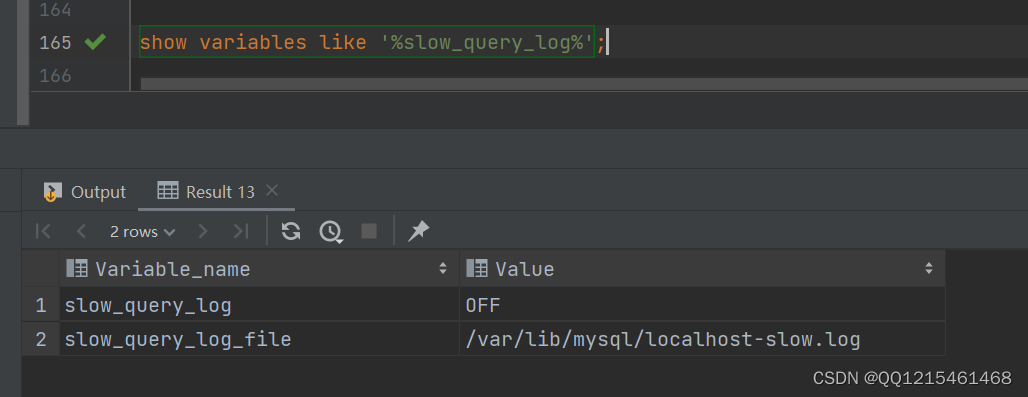
#查看慢查询日志执行时间参数 show variables like '%long_query_time%';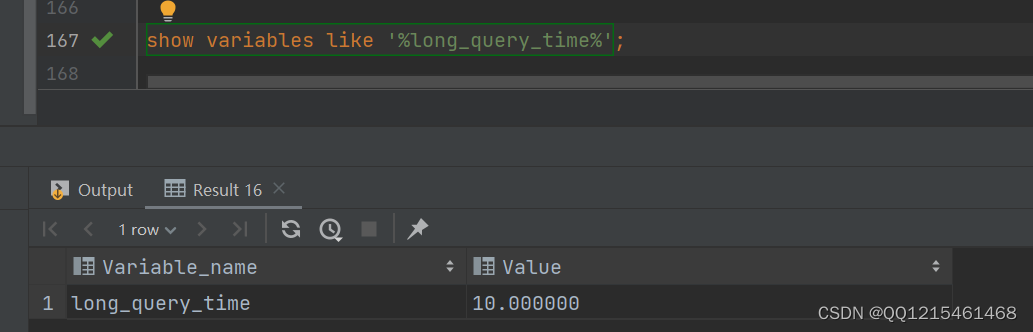
开启慢查询日志
#开启慢查询日志 slow_query_log=1 #执行时间参数 long_query_time=2示例#修改数据库配置文件 vim /etc/my.cnf
#开启慢查询日志 slow_query_log=1 #设置执行时间参数为2秒 long_query_time=2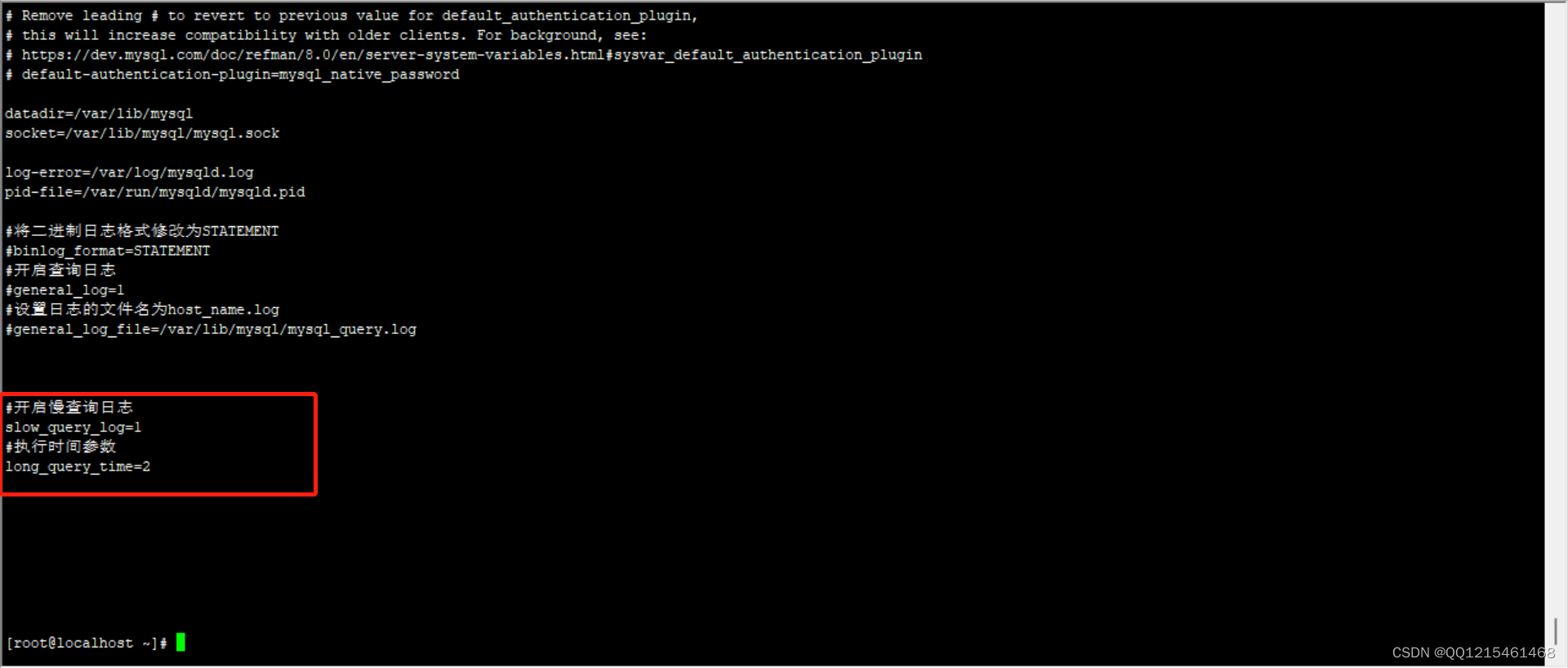
#重启数据库服务 systemctl restart mysqld
#查看慢查询日志执行时间参数 show variables like '%long_query_time%';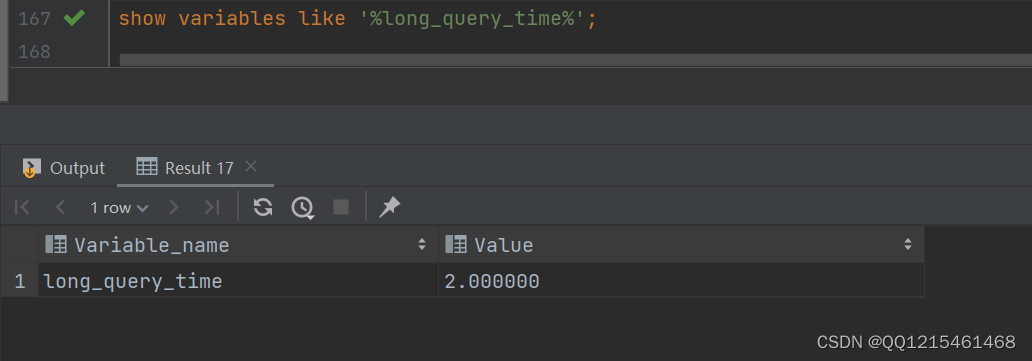
#查看慢查询日志相关参数配置 show variables like '%slow_query_log%';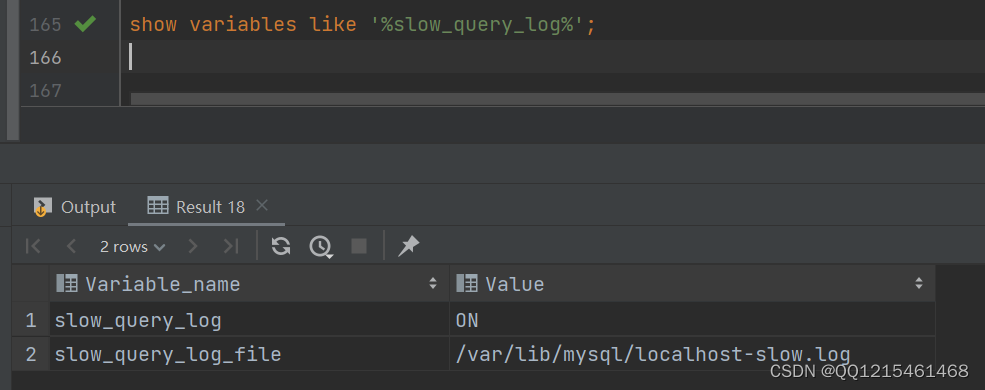
#查看/var/lib/mysql目录下的慢日志文件 ll /var/lib/mysql/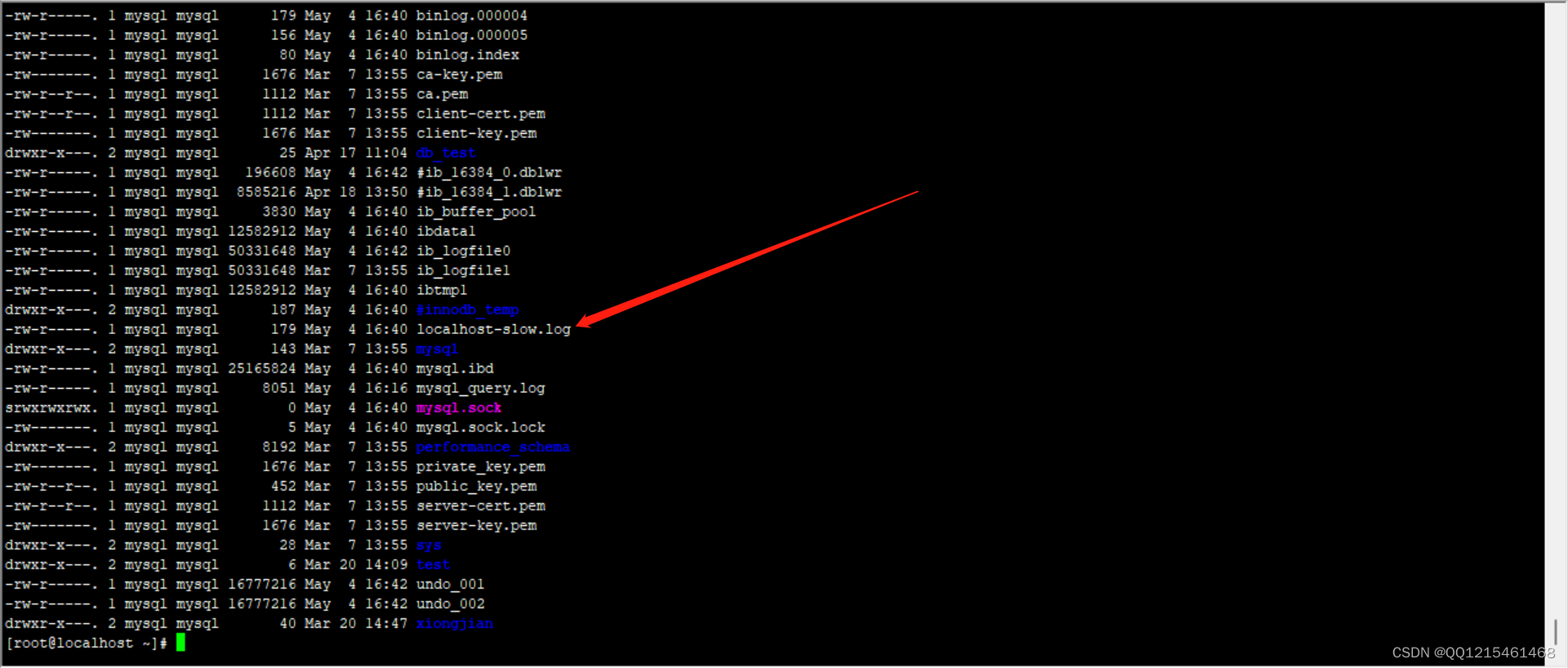
默认情况下,不会记录管理语句,也不会记录不使用索引进行查找的查询。可以使用log_slow_admin_statements和更改此行为log_queries_not_using_indexes,如下所述。
#记录执行较慢的管理语句 log_slow_admin_statements=1 #记录执行较慢的未使用索引的语句 log_queries_not_using_indexes=1
二、主从复制
1.主从复制-概述
-
概述
主从复制是指将主数据库的DDL和 DML操作通过二进制日志传到从库服务器中,然后在从库上对这些日志重新执行(也叫重做),从而使得从库和主库的数据保持同步。
MySQL支持一台主库同时向多台从库进行复制,从库同时也可以作为其他从服务器的主库,实现链状复制。
MySQL复制的优点主要包含以下三个方面:
①主库出现问题,可以快速切换到从库提供服务。
②实现读写分离,降低主库的访问压力。
③可以在从库中执行备份,以避免备份期间影响主库服务
2.主从复制-原理
-
原理
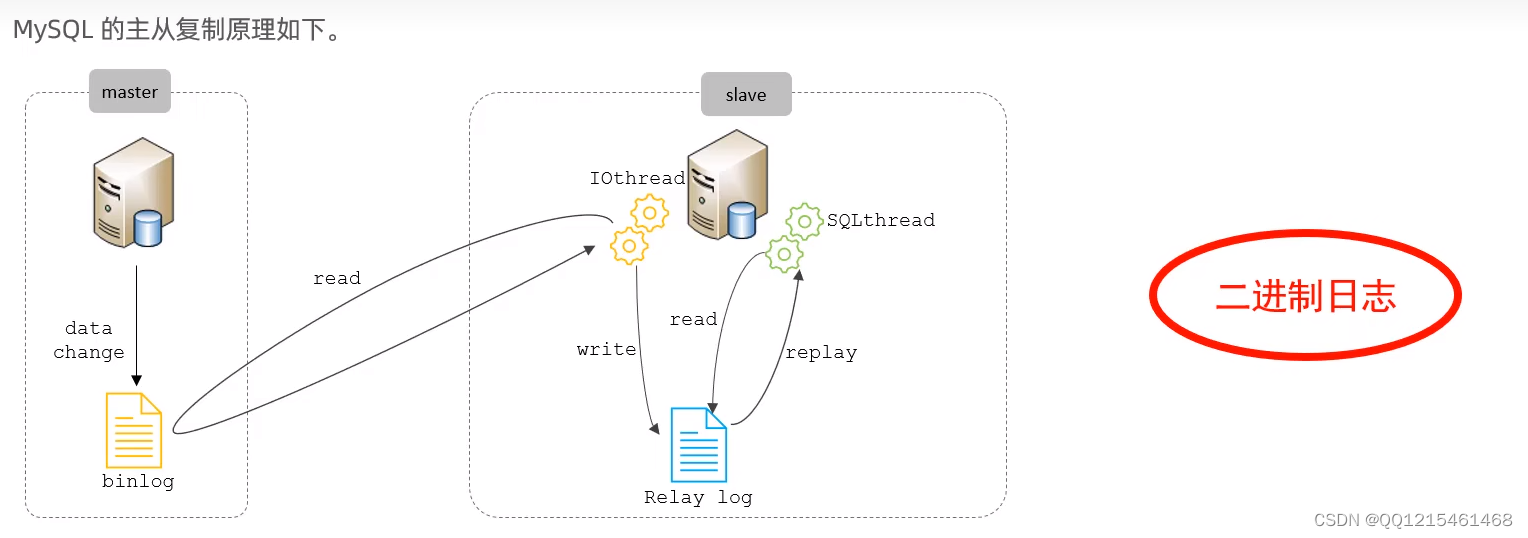
复制分成三步:(master代表是主库,slave代表从库)
①Master 主库在事务提交时,会把数据变更记录在二进制日志文件 Binlog 中。
②从库读取主库的二进制日志文件 Binlog,写入到从库的中继日志 Relay Log。
③slave重做中继日志中的事件,将改变反映它自己的数据。
3.主从复制-搭建
3.1.主从复制-搭建-主库配置
-
主库配置

1.修改配置文件/etc/my.cnf
#mysql服务ID,保证整个集群环境中唯一,取值范围: 1 - 2的32次方 - 1,默认为1 server-id=1 #是否只读,1 代表只读,0 代表读写 read-only=0 #忽略的数据,指不需要同步的数据库 #binlog-ignore-db=mysql #指定同步的数据库 #binlog-do-db=db012.重启MySQL服务
systemctl restart mysqld3.登录MySQL,创建远程连接的账号,并授予主从复制权限
#创建test用户,并设置密码,该用户可以在任意主机连接该MySQL服务 create user 'test'@'%' identified with mysql_native_password by 'Root@123456'; #为'test'@'%'用户分配主从复制权限 grant replication slave on *.* to 'test'@'%';> 4.通过指令,查看二进制日志坐标show master status;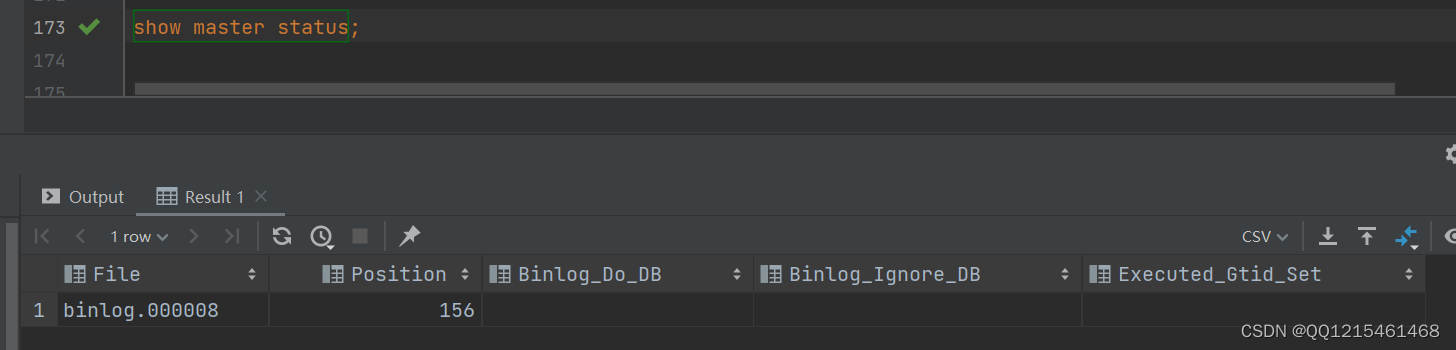
字段含义说明
File:从哪个日志文件开始推送日志文件
Position:从哪个位置开始推送日志
Binlog_Do_DB:指定不需要同步的数据库
3.2.主从复制-搭建-从库配置
-
从库配置
1.修改配置文件/etc/my.cnf
#mysql服务ID,保证整个集群环境中唯一,取值范围: 1 - 2的32次方 - 1,和主库不一样即可 server-id=2 #是否只读,1 代表只读,0 代表读写 read-only=12.重启MySQL服务
systemctl restart mysqld3.登录MySQL,设置主库配置(
在从库中执行下面SQL语句)change replication source to source_host = 'xxx.xxx.xxx.xxx',source_user = 'xxx',source_password = 'xxx',source_log_file = 'xxx',source_log_pos = xxx;例子change replication source to source_host = '192.168.200.200',source_user = 'test',source_password = 'Root@123456',source_log_file = 'binlog.000008',source_log_pos = 156;上述是8.0.23中的语法。如果MySQL是8.0.23之前的版本,执行如下SQL:
change master to master_host = 'xxx.xxx.xxx.xxx',master_user = 'xxx',master_password = 'xxx',master_log_file = 'xxx',master_log_pos = xxx;参数名 含义 8.0.23之前 SOURCE_HOST 主库IP地址 MASTER_HOST SOURCE_USER 连接主库的用户名 MASTER_USER SOURCE_PASSWORD 连接主库的密码 MASTER_PASSWORD SOURCE_LOG_FILE binlog日志文件名 MASTER_LOG_FILE SOURCE_LOG_POS binlog日志文件位置 MASTER_LOG_POS 4.开启同步操作
start replica; #8.0.22之后 start slave; #8.0.22之前5.查看主从同步状态
show replica status; #8.0.22之后 show slave status; #8.0.22之前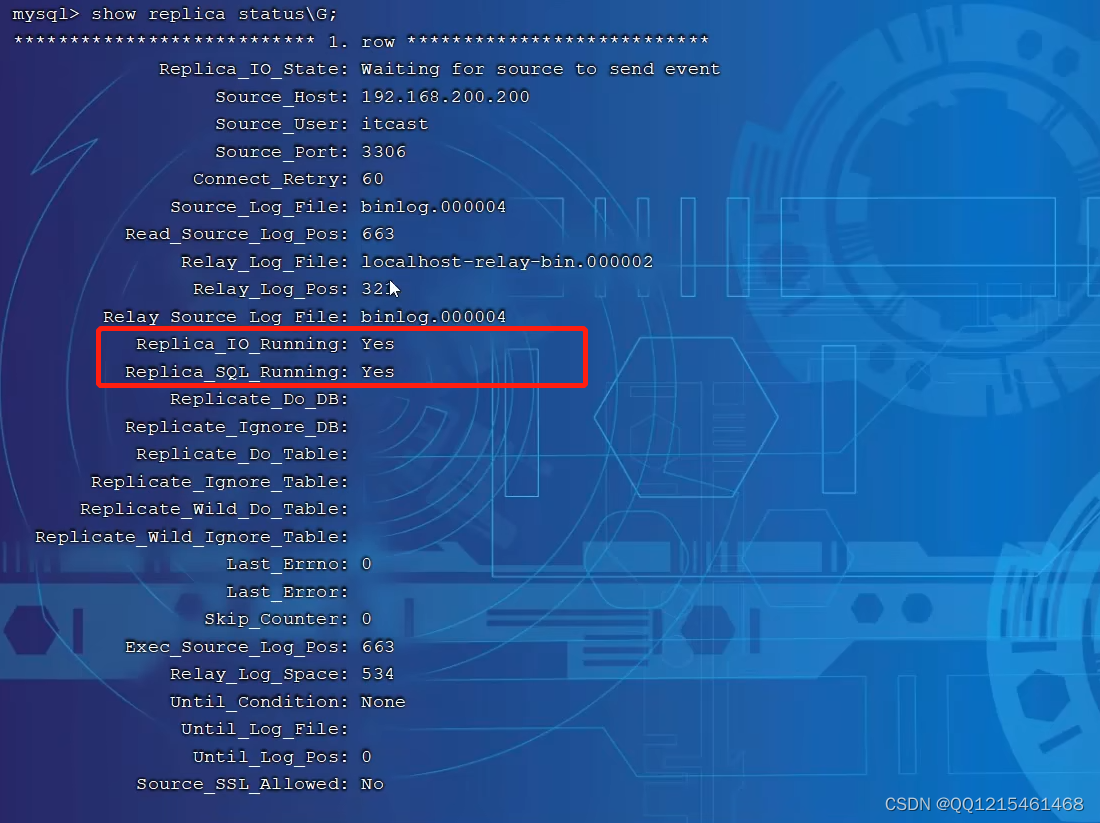
3.2.主从复制-搭建-测试
-
测试
1.在主库上创建数据库、表,并插入数据
2.在从库中查询数据,验证主从是否同步
三、分库分表
1.分库分表-介绍
1.1.分库分表-介绍
-
介绍
问题分析随着互联网及移动互联网的发展,应用系统的数据量也是成指数式增长,若采用单数据库进行数据存储,存在以下性能瓶颈:
①IO瓶颈:热点数据太多,数据库缓存不足,产生大量磁盘IO,效率较低。请求数据太多,带宽不够,网络IO瓶颈。
②CPU瓶颈:排序、分组、连接查询、聚合统计等SQL会耗费大量的CPU资源,请求数太多,CPU出现瓶颈。分库分表的中心思想都是将数据分散存储,使得单一数据库/表的数据量变小来缓解单一数据库的性能问题,从而达到提升数据库性能的目的。
1.2.分库分表-介绍-拆分方式
-
拆分方式
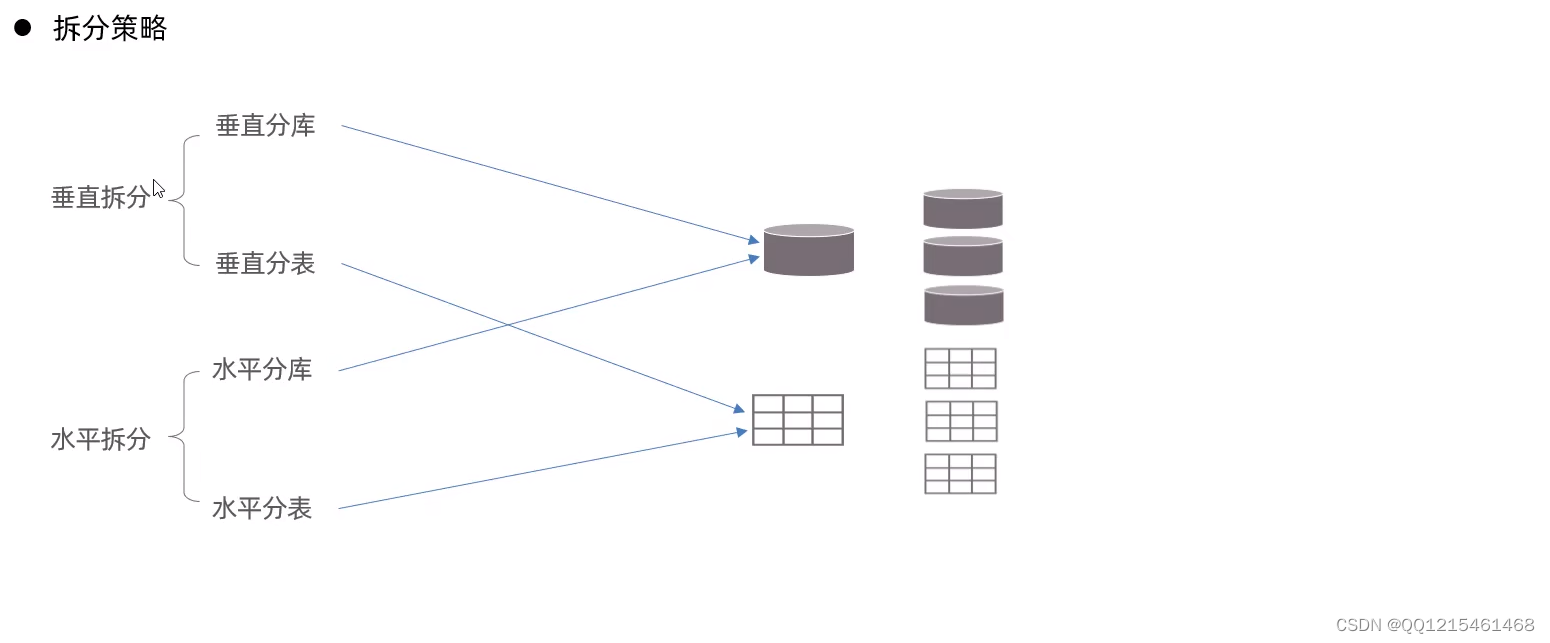
-
垂直拆分
垂直拆分-垂直分库
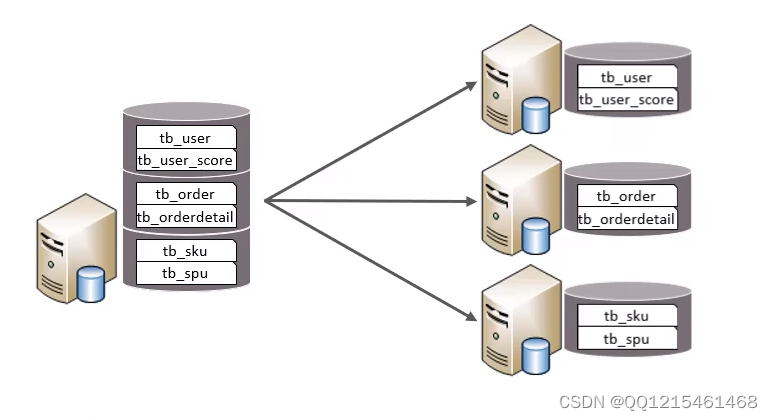
垂直分库:以表为依据,根据业务将不同表拆分到不同库中。特点
①每个库的表结构都不一样。
②每个库的数据也不一样。
③所有库的并集是全量数据。垂直拆分-垂直分表
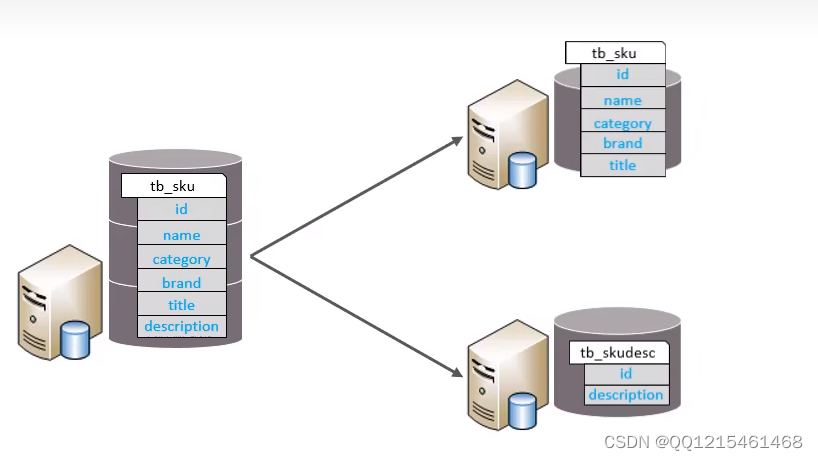
垂直分表:以字段为依据,根据字段属性将不同字段拆分到不同表中。特点
①每个表的结构都不一样。
②每个表的数据也不一样,一般通过一列(主键/外键)关联。
③所有表的并集是全量数据。 -
水平拆分
水平拆分-水平分库
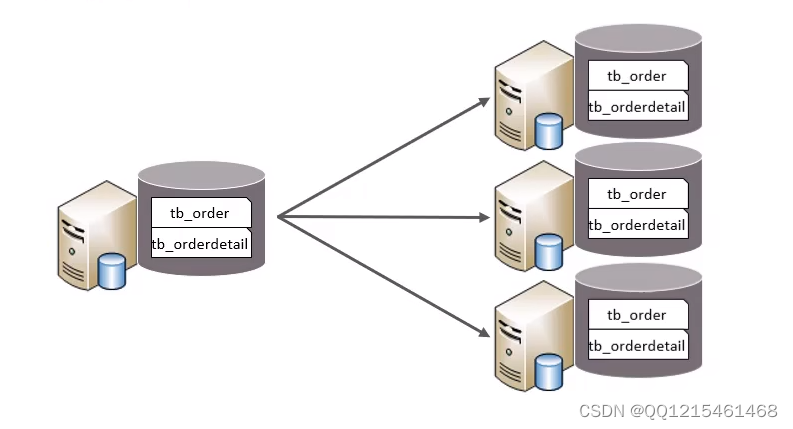
水平分库:以字段为依据,按照一定策略,将一个库的数据拆分到多个库中。特点
①每个库的表结构都一样。
②每个库的数据都不一样。
③所有库的并集是全量数据。水平拆分-水平分表
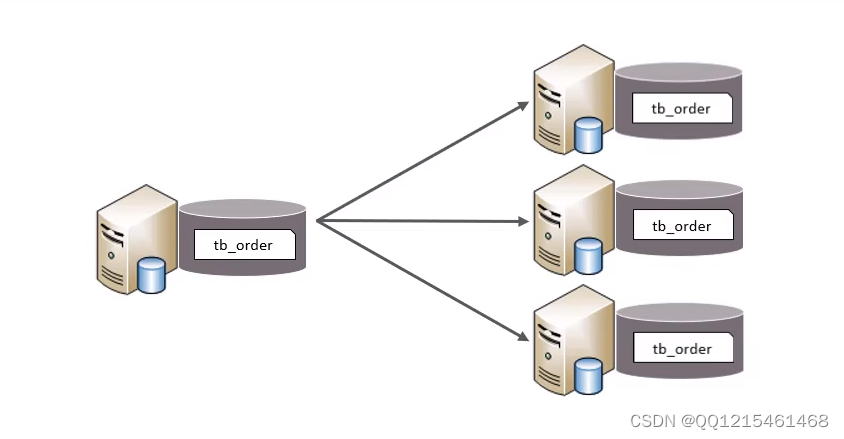
水平分表:以字段为依据,按照一定策略,将一个表的数据拆分到多个表中。特点
①每个表的表结构都一样。
②每个表的数据都不一样。
③所有表的并集是全量数据。 -
实现技术

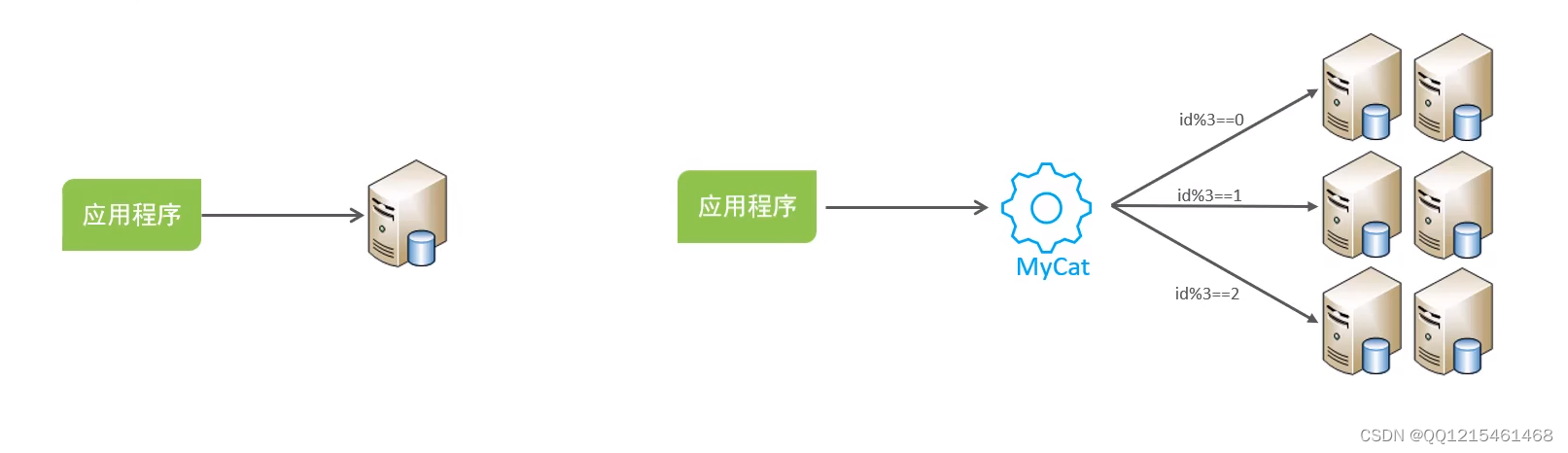
shardingJDBC:基于AOP原理,在应用程序中对本地执行的SQL进行拦截,解析、改写、路由处理。需要自行编码配置实现,只支持java语言,性能较高。MyCat:数据库分库分表中间件,不用调整代码即可实现分库分表,支持多种语言,性能不及前者。
2.分库分表-MyCat概述
-
介绍
MyCat是开源的、活跃的、基于Java语言编写的MySQL
数据库中间件。可以像使用MySQL一样来使用MyCat,对于开发人员来说根本感觉
不到MyCat的存在。优势
①性能可靠稳定
②强大的技术团队
③体系完善
④ 社区活跃
2.1.分库分表-MyCat概述-安装
-
MyCat下载
下载地址:http://www.mycat.org.cn/ 点击前往
网盘下载链接:https://pan.baidu.com/s/1xcylGdwv_k7nACh1ab_9dQ?pwd=xjv5
提取码:xjv5

MyCat是采用java语言开发的开源的数据库中间件,支持Windows和Linux运环境,下面介绍MyCat的Linux中的环境搭建。我们需要在准备好的服务器中安装如下软件。
①MySQL
②JDK
③MyCat服务器 安装软件 说明 192.168.200.210 JDK、MyCat MyCat中间件服务器 192.168.200.210 MySQL 分片服务器 192.168.200.213 MySQL 分片服务器 192.168.200.214 MySQL 分片服务器 -
安装JDK与MyCat
安装JDK
1.上传JDK安装包到Linux服务器

2.将jdk-8u171-linux-x64.tar.gz安装包解压到/usr/local/目录下
tar -zxvf jdk-8u171-linux-x64.tar.gz -C /usr/local/
3.查看/usr/local/目录下的解压后的jdk文件夹
ll /usr/local/
4.配置JDK环境变量
#1.编辑profile文件 vim /etc/profile #2.配置环境变量 JAVA_HOME=/usr/local/jdk1.8.0_171 PATH=$JAVA_HOME/bin:$PATH #3.重新加载profile配置文件(全局变量刷新) source /etc/profile #4.查看jdk版本(安装完成) java -version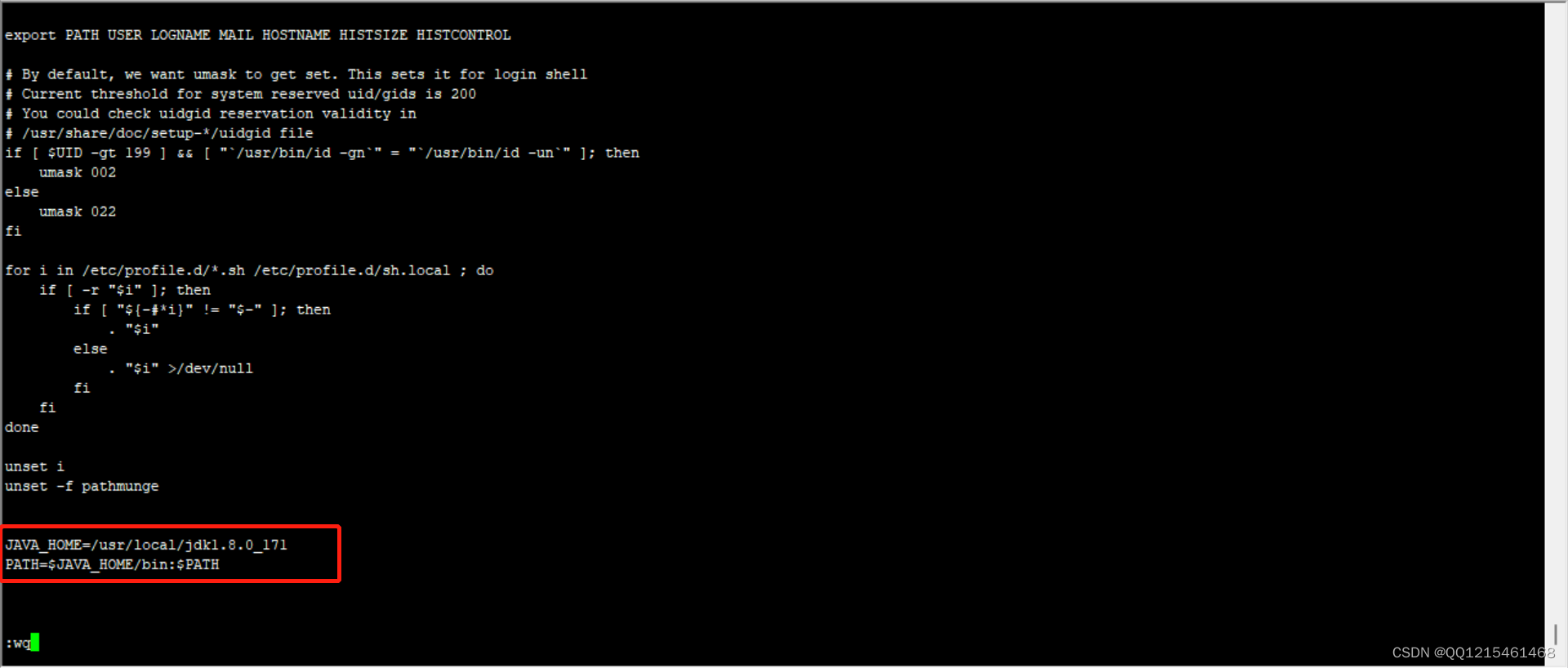


安装MyCat
1.上传MyCat安装包到Linux服务器

2.将Mycat-server-1.6.7.3-release-20210913163959-linux.tar.gz安装包解压到/usr/local/目录下
在这里插入代码片
3.查看/usr/local/目录下的解压后的MyCat文件夹
ll /usr/local/
-
MyCat目录结构

目录名 存放内容 bin 存放可执行文件,用于启动停止MyCat conf 存放MyCat的配置文件 lib 存放MyCat的项目依赖包(jar) logs 存放MyCat的日志文件 更换MySQL数据库连接驱动包
数据库连接驱动包网盘下载链接:https://pan.baidu.com/s/191zIAN1N7ZTFNLxuanfqjw?pwd=xjv5
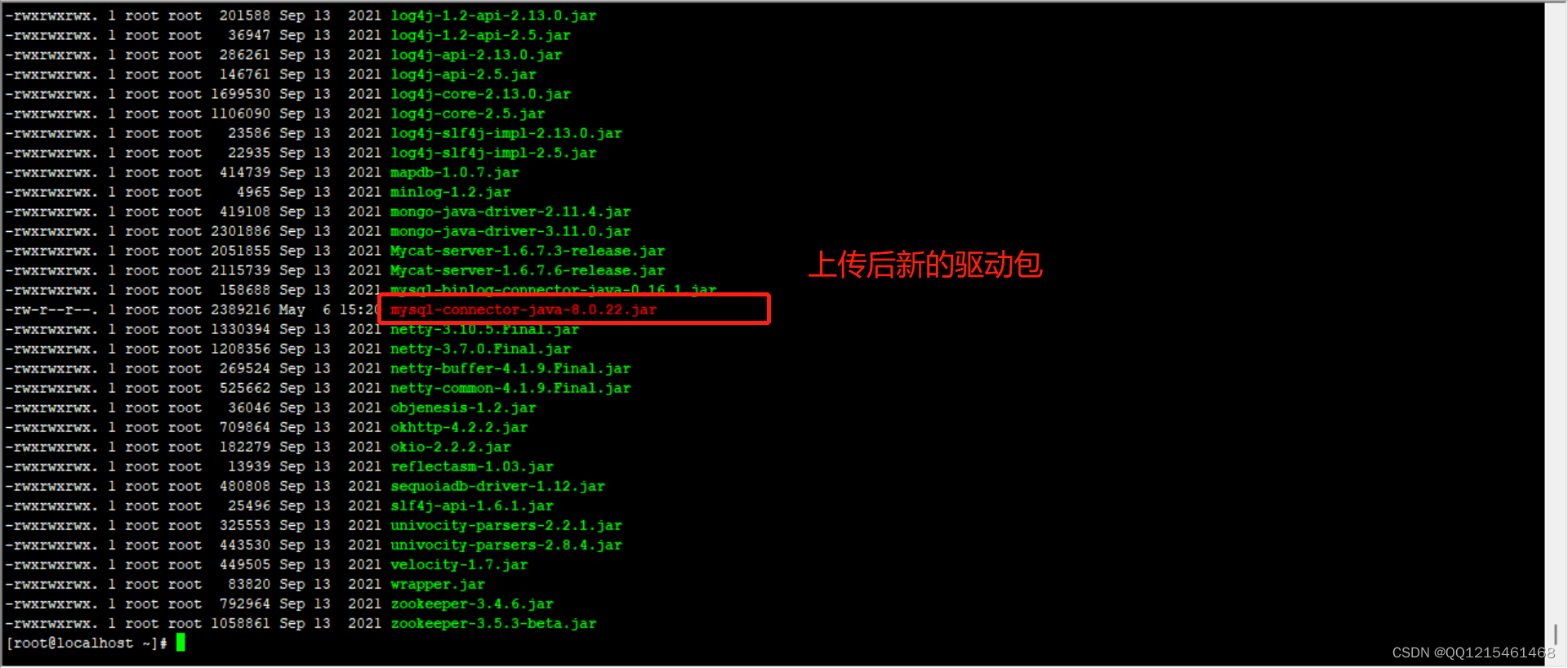
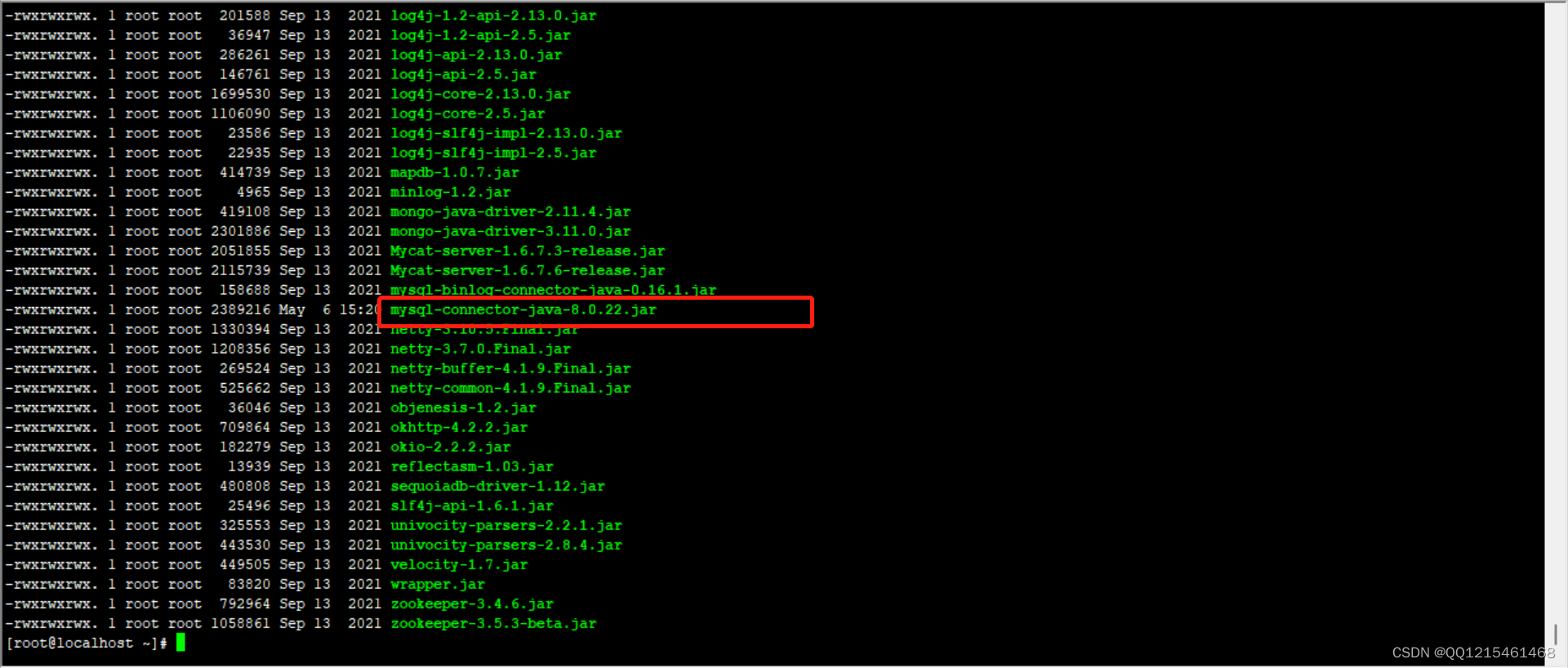
提取码:xjv5#1.查看/usr/local/mycat/lib/目录下的jar包 ll /usr/local/mycat/lib/ #2.删除/usr/local/mycat/lib/目录下的mysql-connector-java-5.1.35.jar包 rm -rf /usr/local/mycat/lib/mysql-connector-java-5.1.35.jar #3.上传新的mysql数据库连接驱动包 #4.查看/usr/local/mycat/lib/目录下的jar包 ll /usr/local/mycat/lib/ #5.给新的mysql数据库连接驱动包授权 chmod 777 /usr/local/mycat/lib/mysql-connector-java-8.0.22.jar #6.查看/usr/local/mycat/lib/目录下的jar包 ll /usr/local/mycat/lib/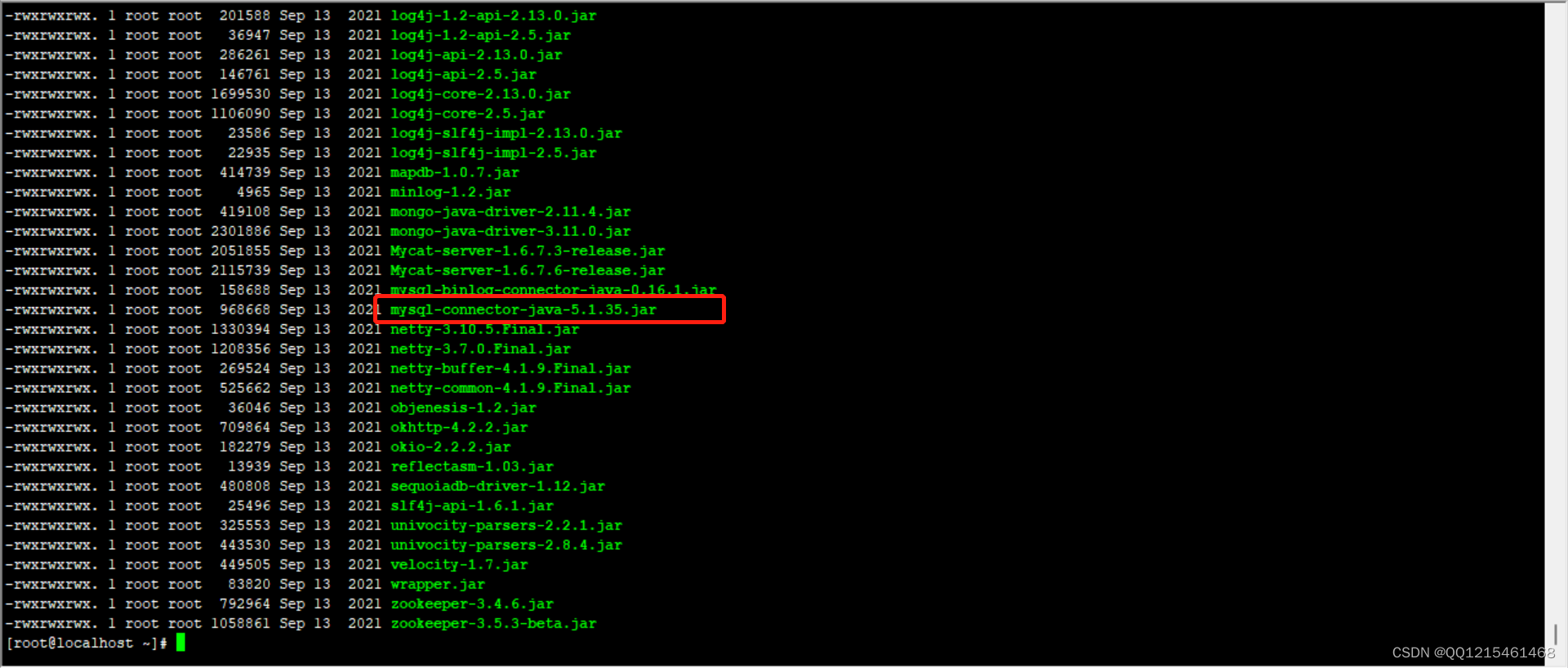

2.2.分库分表-MyCat概述-核心概念
- 核心概念
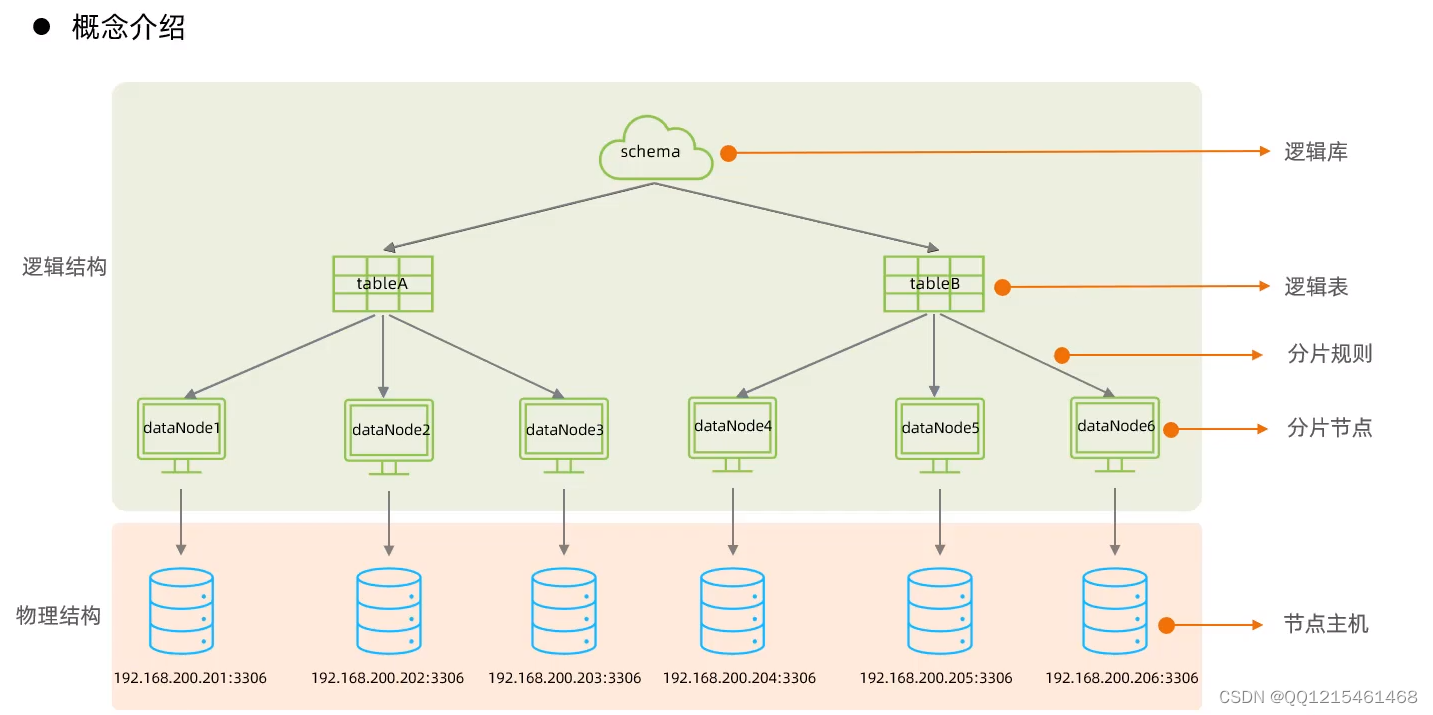
3.分库分表-MyCat入门
3.1分库分表-MyCat入门
-
MyCat入门
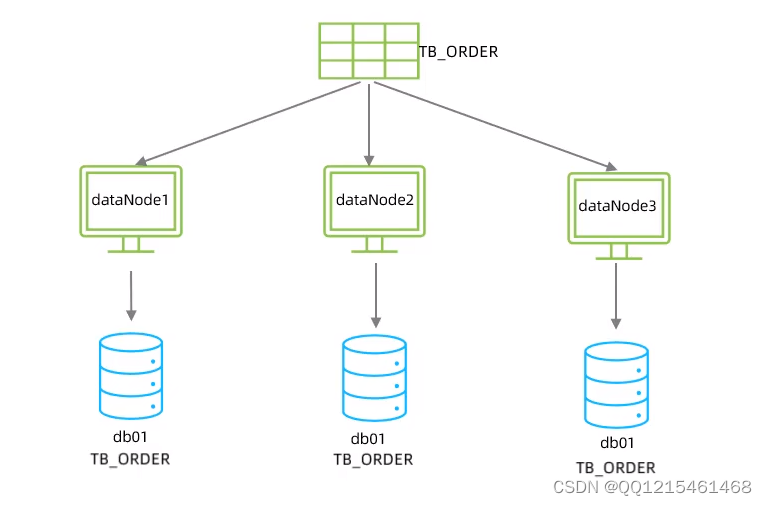
需求
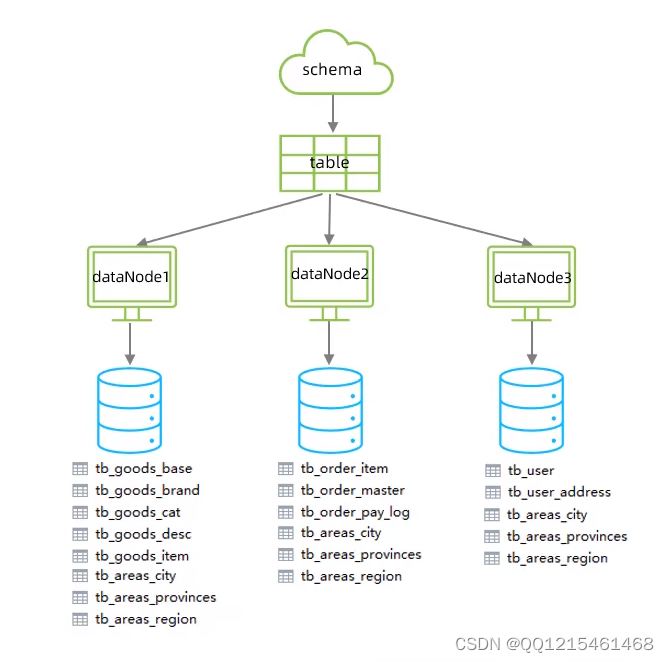
由于tb_order 表中数据量很大,磁盘IO及容量都到达了瓶颈,现在需要对tb_order 表进行数据分片,分为三个数据节点,每一个节点主机位于不同的服务器上,具体的结构,参考下图:
环境准备
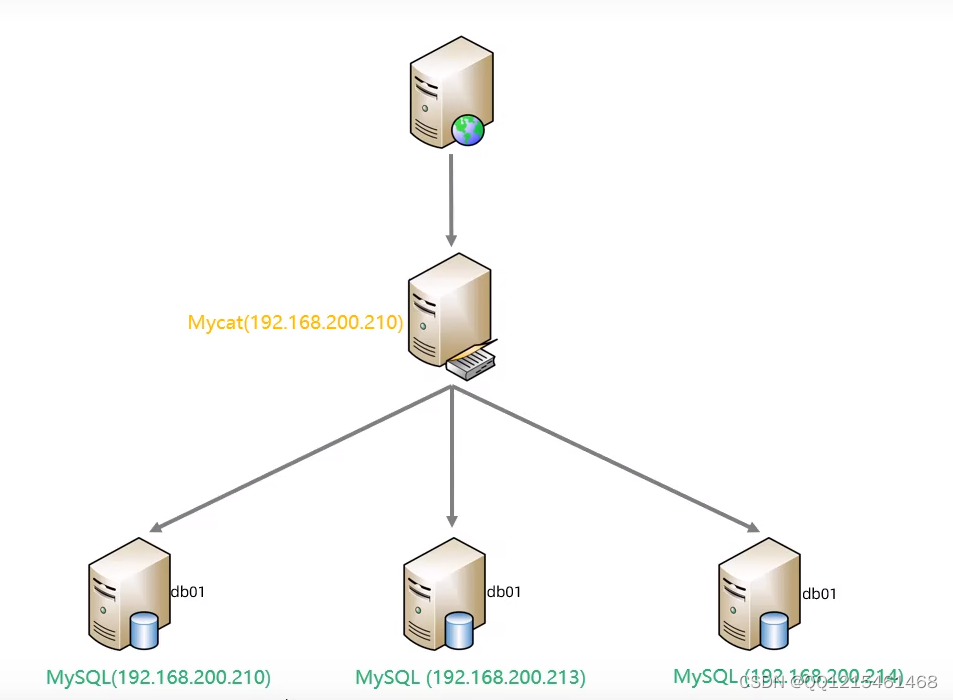
一.关闭防火墙
1.查看防火墙是否开启
#active (running)代表防火墙处于开启状态 systemctl status firewalld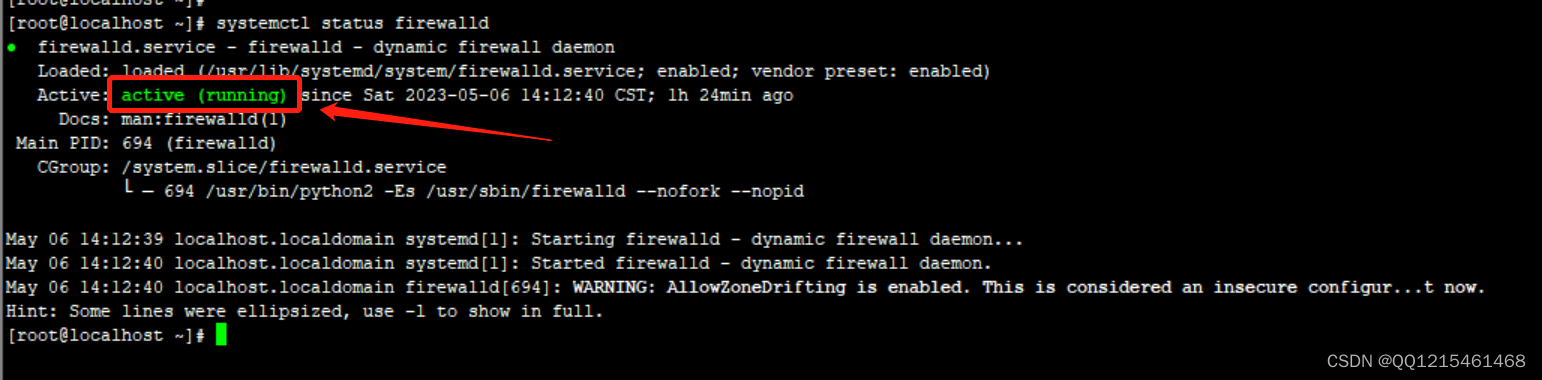
2.关闭防火墙
systemctl stop firewalld
3.查看防火墙是否开启
#inactive (dead)代表防火墙处于关闭状态 systemctl status firewalld
4.分别在三台服务器上创建一个名为db01的数据库
create database db01;
确保三台服务器防火墙都处于关闭状态,如果不想关闭防火墙,可以开放所有对应的端口号。
-
分片配置(schema.xml)
二.schema.xml配置文件信息修改

查看/usr/local/mycat/conf/目录下的文件
ll /usr/local/mycat/conf/
便于方便修改配置文件我这边使用了Notepad++中的NppFTP插件
关于Notepad++下载安装NppFTP插件可以参考下面连接:https://blog.csdn.net/weixin_44904239/article/details/130551833 点击前往
-
使用Notepad++中的NppFTP插件修改配置文件
NppFTP插件使用1.打开Notepad++,显示NppFTP窗口
2.设置配置文件
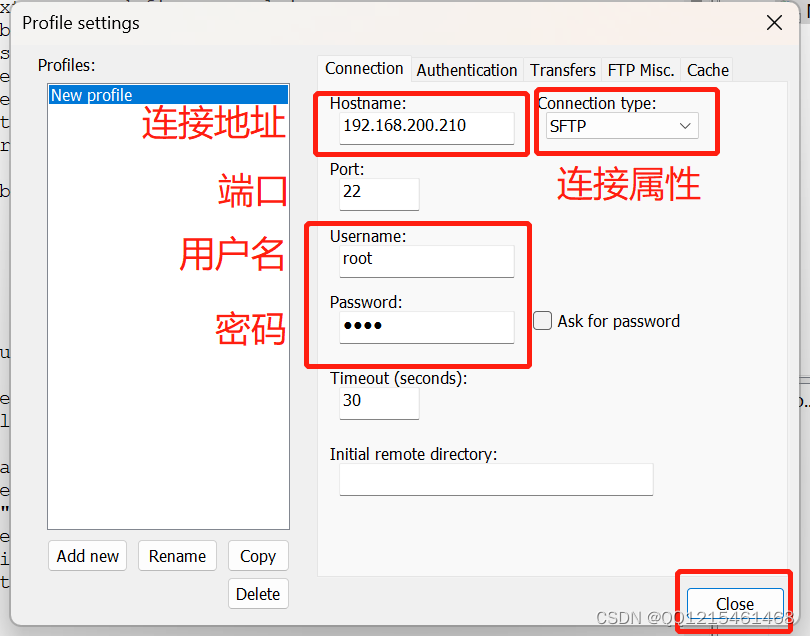
3.添加
4.配置文件配置
5.连接成功
6.连接上以后看不到目录点击下刷新按钮就行
7.点击/usr/local/mycat/conf/目录下的schema.xml文件
8.修改schema.xml配置文件信息如下:
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <schema name="DB01" checkSQLschema="true" sqlMaxLimit="100"> <table name="TB_ORDER" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" /> </schema> <dataNode name="dn1" dataHost="dhost1" database="db01" /> <dataNode name="dn2" dataHost="dhost2" database="db01" /> <dataNode name="dn3" dataHost="dhost3" database="db01" /> <dataHost name="dhost1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="master" url="jdbc:mysql://192.168.200.210:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234" /> </dataHost> <dataHost name="dhost2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="master" url="jdbc:mysql://192.168.200.213:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234" /> </dataHost> <dataHost name="dhost3" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="master" url="jdbc:mysql://192.168.200.214:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234" /> </dataHost> </mycat:schema>三.servse.xml配置文件信息修改

1.点击/usr/local/mycat/conf/目录下的servse.xml文件
2.修改servse.xml配置文件信息如下:(部分主要配置信息展示)
<user name="root" defaultAccount="true"> <property name="password">123456</property> <property name="schemas">DB01</property> <!-- 表级 DML 权限设置 --> <!-- <privileges check="false"> <schema name="TESTDB" dml="0110" > <table name="tb01" dml="0000"></table> <table name="tb02" dml="1111"></table> </schema> </privileges> --> </user> <user name="user"> <property name="password">123456</property> <property name="schemas">DB01</property> <property name="readOnly">true</property> </user>
3.2.分库分表-MyCat入门-测试
-
测试
切换到MyCat的安装目录,执行如下指令,启动MyCat:
#启动MyCat bin/mycat start #停止MyCat bin/mycat stopMyCat启动之后,占用端口号8066。一、启动MyCat
1.切换到/usr/local/mycat/目录cd /usr/local/mycat/
2.启动MyCatbin/mycat start
3.启动完毕后,可以查看logs目录下的启动日志,查看MyCat是否启动完成tail -f logs/wrapper.log #如下图所示表示MyCat启动成功
通过如下指令,就可以连接并登录MyCat
(这里的用户名和密码就是来自servse.xml配置文件里所配置的用户名和密码)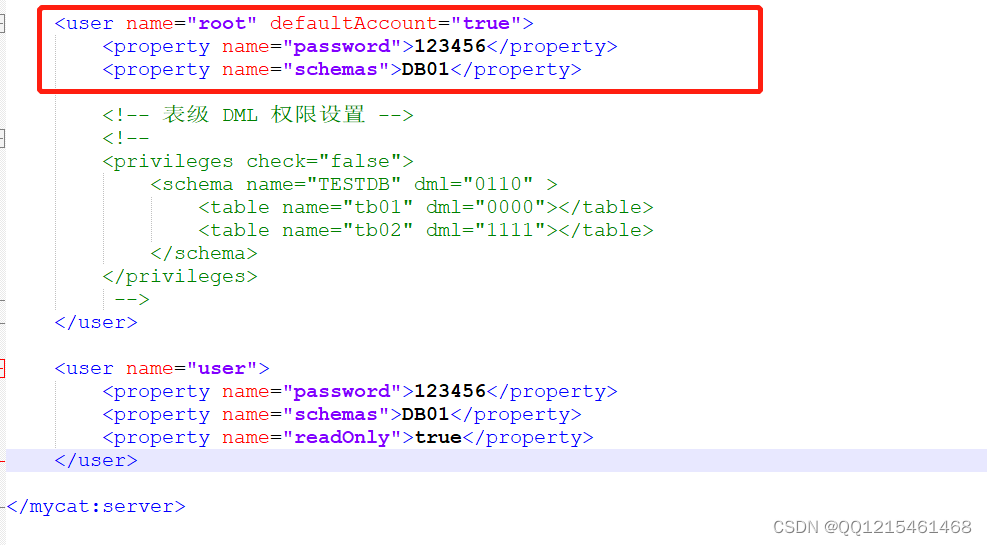
#登录连接MyCat mysql -h 192.168.200.210 -P 8066 -uroot -p123456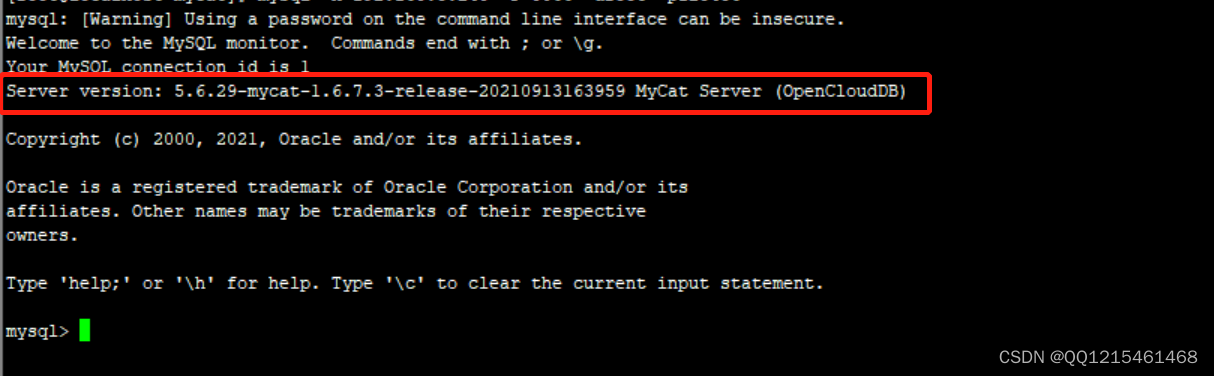
查看数据库(这里只有一个数据库,这个数据库来自schema.xml配置文件)
show databases;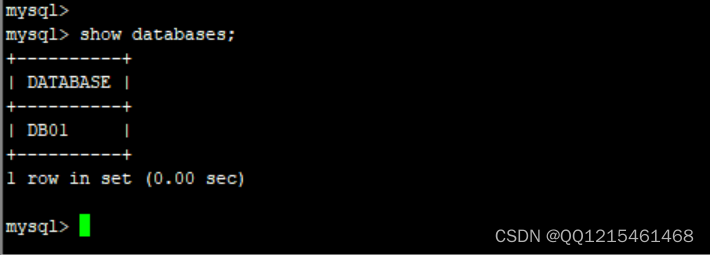
切换到DB01数据库use DB01;
查看表(这个tb_order表MySQL数据库没有,只有MyCat有)show tables;
二、创建表结构
创建表结构CREATE TABLE TB_ORDER( id BIGINT(20) NOT NULL , titleVARCHAR(100) NOT NULL , PRIMARY KEY(id) )ENGINE=INNODB DEFAULT CHARSET=utf8;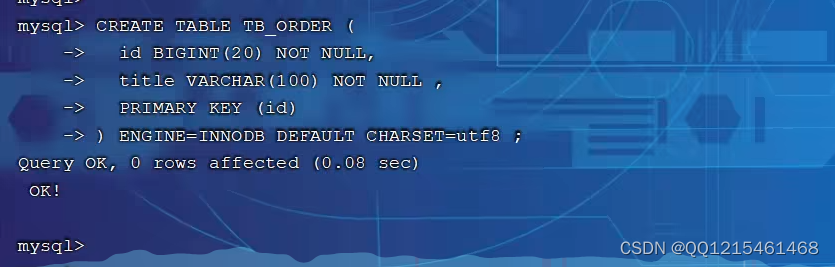
当在MyCat中创建了TB_ORDER逻辑表,则数据库表结构中对应的真实表TB_ORDER就已经创建了。此时三个数据库都都已经有了TB_ORDER表。三、插入数据
往TB_ORDER表中插入数据insert into tb_order(id, titile) values (1,'goods1'); insert into tb_order(id, titile) values (2,'goods2'); insert into tb_order(id, titile) values (3,'goods3');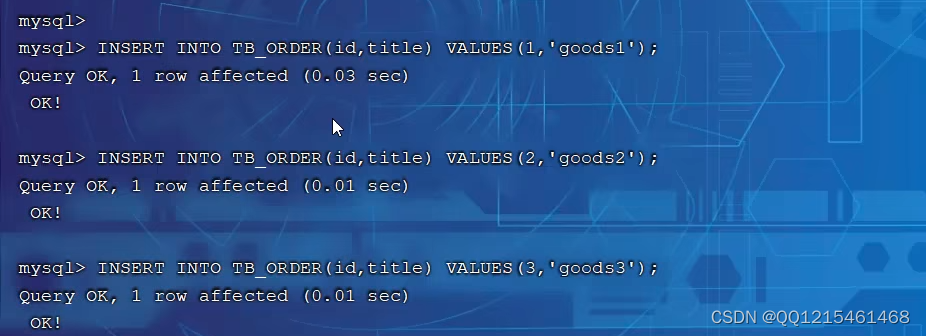
此时数据只会在真实数据库192.168.200.201中,而192.168.200.213和192.168.200.214数据中是没有的
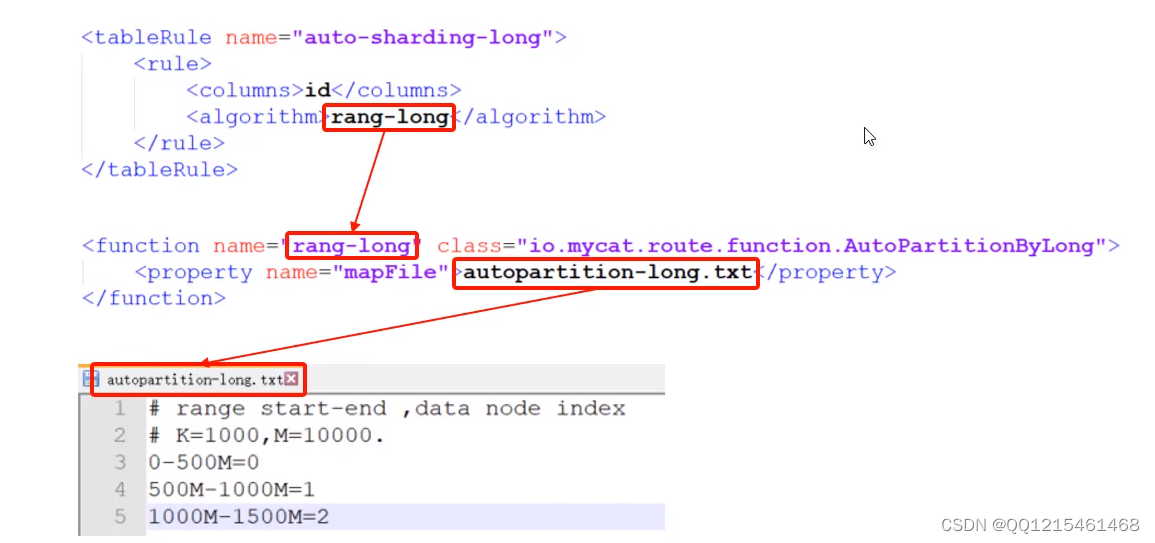
往MyCat的TB_ORDER表中插入数据的分布规则取决于schema.xml配置文件中的 rule="auto-sharding-long"分片规则
rule="auto-sharding-long"这个分片规则引用了MyCat中分片定义的rule.xml文件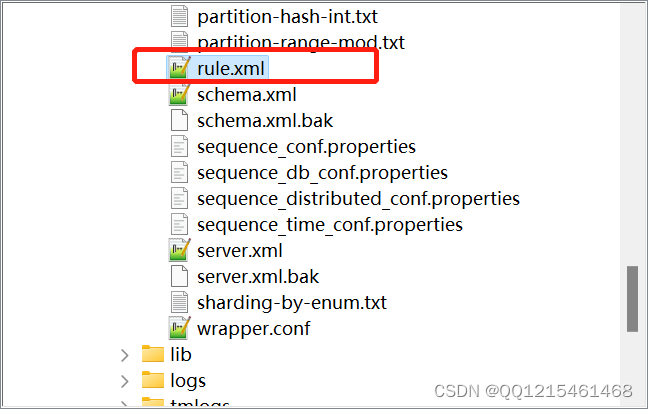

rang-long引用了auto-sharding-long.txt文件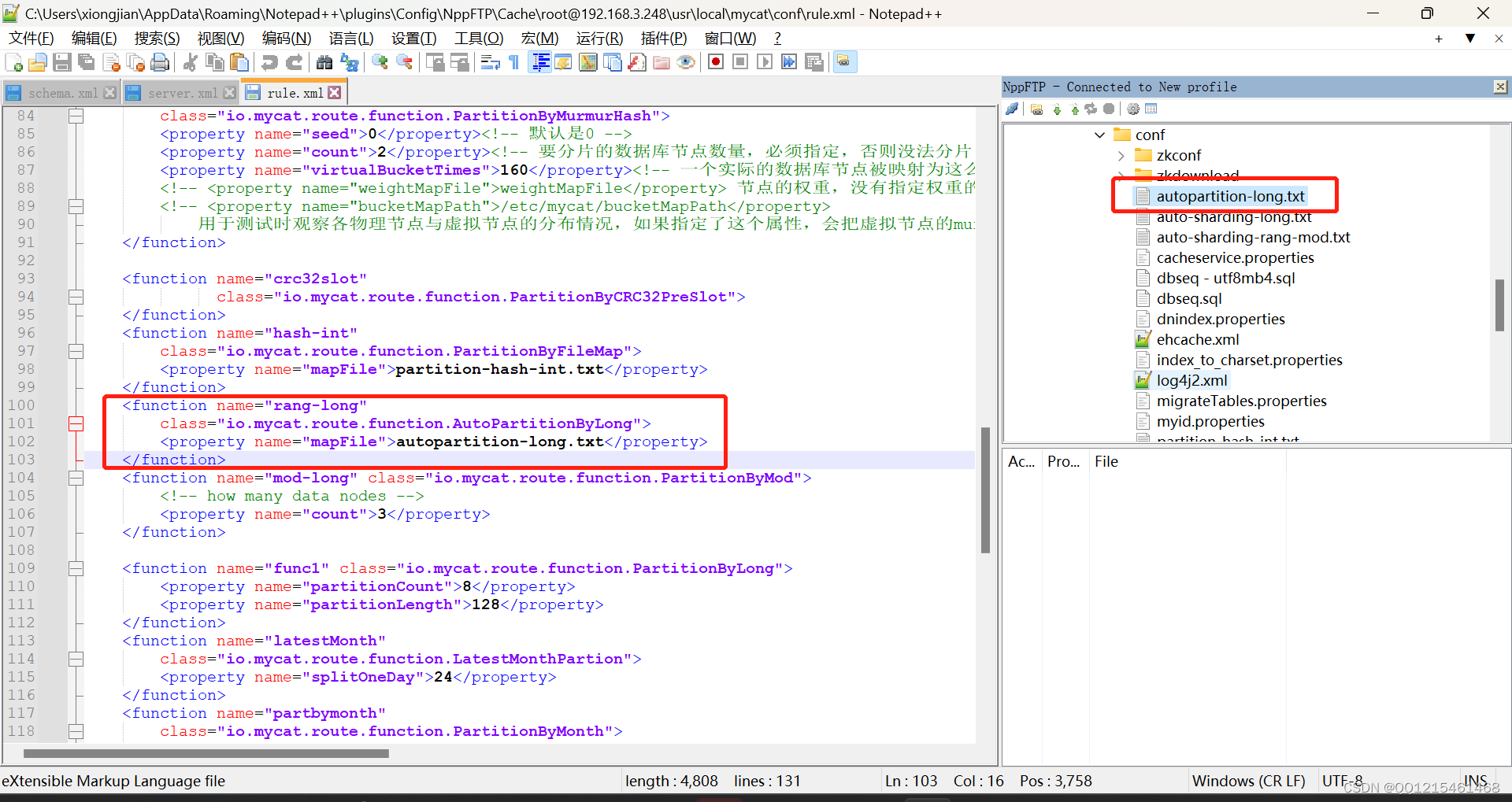
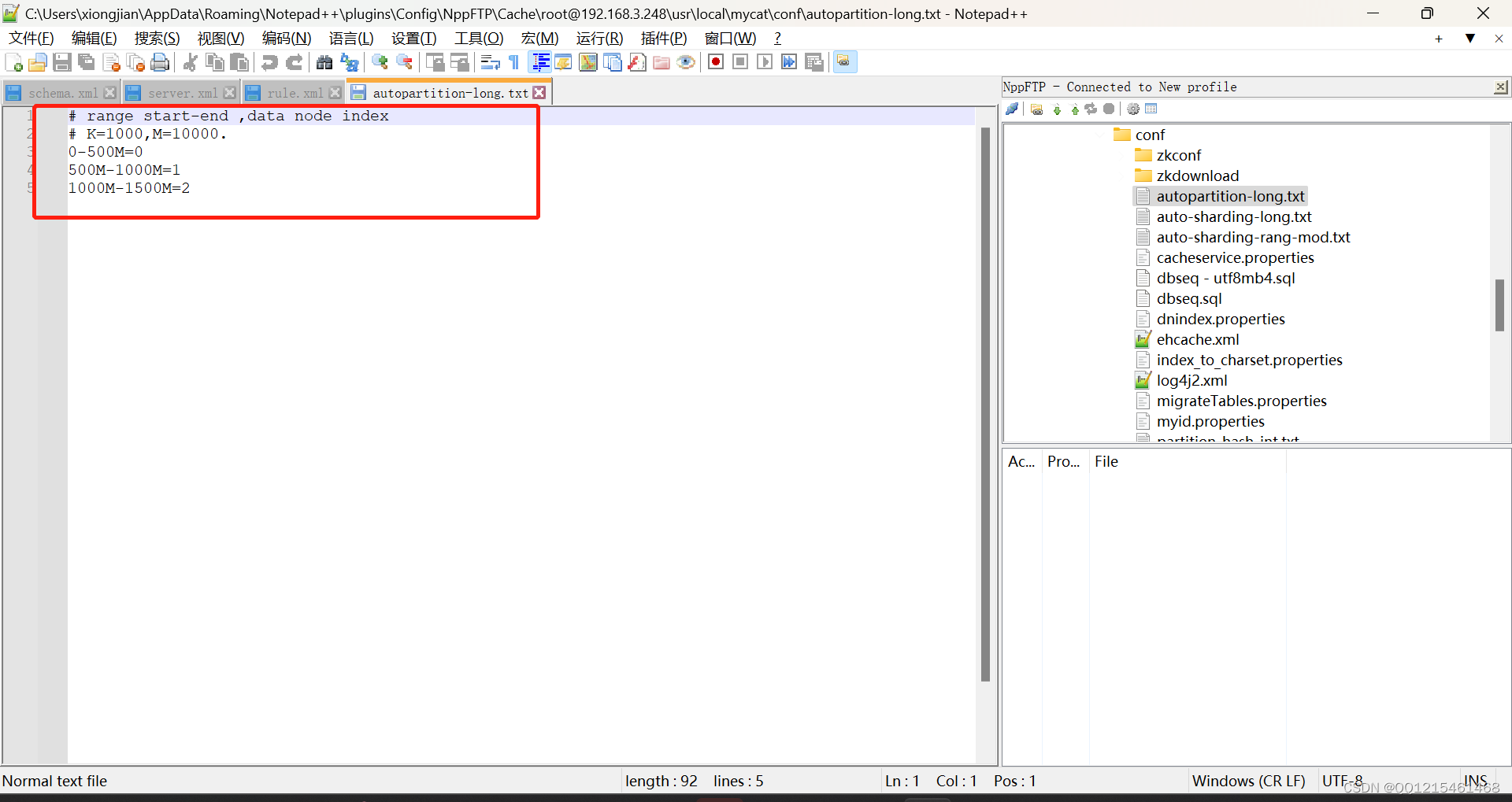
# range start-end ,data node index # K=1000,M=10000. 0-500M=0 #表示id在0-500万的数据放在第一个节点 500M-1000M=1 #表示id在500万-1000万的数据放在第二个节点 1000M-1500M=2 #表示id在1000万-1500万的数据放在第三个节点例子往TB_ORDER表中插入id在500万-1000万的数据insert into tb_order(id, titile) values (5000001,'goods5000001');
此时数据会在192.168.200.213数据库上往TB_ORDER表中插入id在1000万-1500万的数据insert into tb_order(id, titile) values (10000001,'goods10000001');
此时数据会在192.168.200.214数据库上往TB_ORDER表中插入id大于1500万的数据insert into tb_order(id, titile) values (15000001,'goods15000001');
此时MyCat报错:不能找到一个有效的数据节点,如果超过id大于1500万的数据可以在auto-sharding-long.txt文件中进行配置
4.分库分表-MyCat配置
-
MyCat配置
一、schema.xmlschema.xml作为MyCat中最重要的配置文件之一,涵盖了MyCat的逻辑库、逻辑表、分片规则、分片节点及数据源的配置。
主要包含以下三组标签
①schema标签
②datanode标签
③datahost标签schema标签

schema 标签用于定义 MyCat实例中的逻辑库,一个MyCat实例中,可以有多个逻辑库,可以通过 schema 标签来划分不同的逻辑库。MyCat中的逻辑库的概念,等同于MySOL中的database概念,需要操作某个逻辑库下的表时,也需要切换逻辑库(use xxx)。
核心属性
属性名 作用 name 指定自定义的逻辑库库名 checkSQLschema 在SQL语句操作时指定了数据库名称,执行时是否自动去除; true: 自动去除,false: 不自动除 sqlMaxLimit 如果未指定limit进行查询,列表查询模式查询多少条记录 schema标签(table)

table 标签定义了MyCat中逻辑库schema下的逻辑表,所有需要拆分的表都需要在table标签中定义。
核心属性
属性名 作用 name 定义逻辑表表名,在该逻辑库下唯一 dataNode 定义逻辑表所属的dataNode,该属性需要与dataNode标签中name对应; 多个dataNode逗号分隔 rule 分片规则的名字,分片规则名字是在rule.xml中定义的 primarykey 逻辑表对应真实表的主键 type 逻辑表的类型,目前逻辑表只有全局表和普通表,如果未配置,就是普通表;全局表,配置为 global datanode标签

dataNode标签中定义了MyCat中的数据节点,也就是我们通常说的数据分片。一个dataNode标签就是一个独立的数据分片。
核心属性
属性名 作用 name 定义数据节点名称 dataHost 数据库实例主机名称,引用自 dataHost 标签中name属性 database 定义分片所属数据库 datahost标签

该标签在MyCat逻辑库中作为底层标签存在,直接定义了具体的数据库实例、读写分离、心跳语句。
核心属性
属性名 作用 name 唯一标识,供上层标签使用 maxCon/minCon 最大连接数/最小连接数 balance 负载均衡策略,取值 0,1,2,3 writeType 写操作分发方式(0:写操作转发到第一个writeHost,第一个挂了,切换到第二个;1:写操作随机分发到配置的writeHost) dbDriver 数据库驱动,支持native、jdbc 
二、rule.xmlrule.xml中定义所有拆分表的规则,在使用过程中可以灵活的使用分片算法,或者对同一个分片算法使用不同的参数,它让分片过程可配置化。主要包含两类标签: tableRule、Function。
三、server.xmlserver.xml配置问年包含了MyCat的系统配置信息,主要有两个重要的标签:system、user。
system标签

<property name="nonePasswordLogin">0</property> <!-- 0为需要密码登陆、1为不需要密码登陆 ,默认为0,设置为1则需要指定默认账户--> <property name="useSqlStat">0</property> <!-- 1为开启实时统计、0为关闭 -->

5.分库分表-MyCat分片
5.1.分库分表-MyCat分片-垂直分库
-
垂直分库
场景在业务系统中,涉及以下表结构,但是由于用户与订单每天都会产生大量的数据,单台服务器的数据存储及处理能力是有限的,可以对数据
库表进行拆分,原有的数据库表如下。
准备
①如图所示准备三台Linux服务器(ip为:192.168.200.210、192.168.200.213、192.168.200.214)可以根据自己的实际情况进行准备。
②三台服务器上都安装MySQL,在192.168.200.210服务器上安装MyCat。
③三台服务器关闭防火墙或者开放对应的端口。
④分别在三台MySQL中创建数据库 shopping。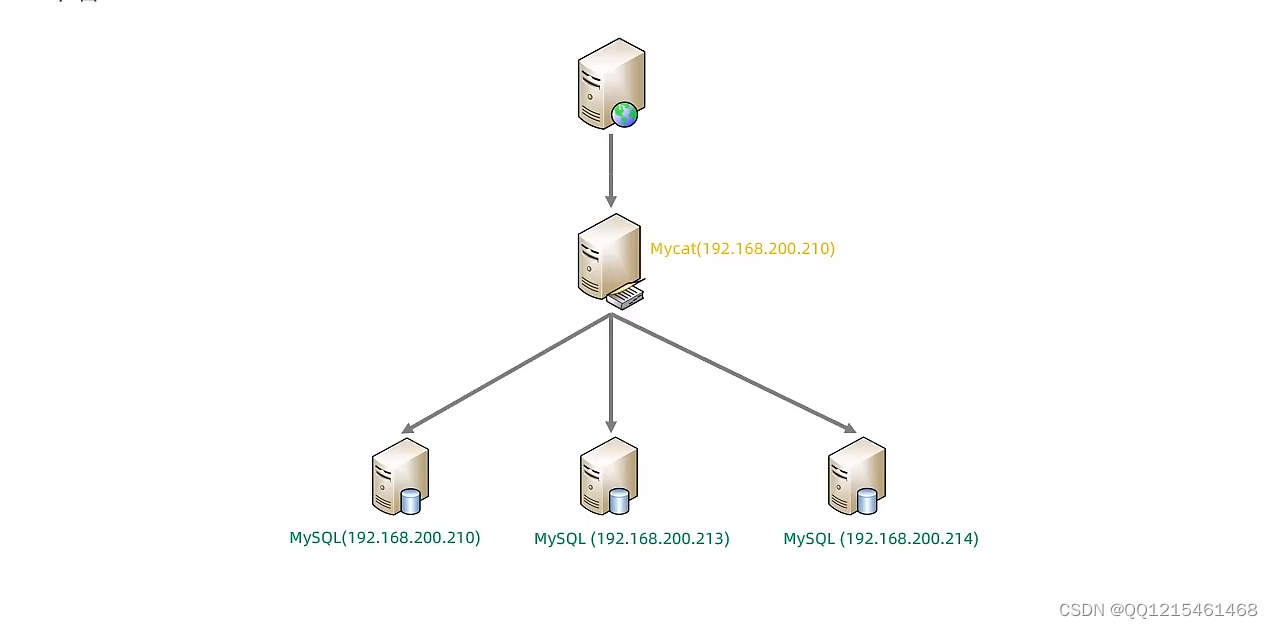
schema.xml文件配置如下:<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <schema name="SHOPPING" checkSQLschema="true" sqlMaxLimit="100"> <table name="tb_goods_base" dataNode="dn1" primaryKey="id" /> <table name="tb_goods_brand" dataNode="dn1" primaryKey="id" /> <table name="tb_goods_cat" dataNode="dn1" primaryKey="id" /> <table name="tb_goods_desc" dataNode="dn1" primaryKey="id" /> <table name="tb_goods_item" dataNode="dn1" primaryKey="goods_id" /> <table name="tb_order_item" dataNode="dn2" primaryKey="id" /> <table name="tb_order_master" dataNode="dn2" primaryKey="order_id" /> <table name="tb_order_pay_log" dataNode="dn2" primaryKey="out_trade_no" /> <table name="tb_user" dataNode="dn3" primaryKey="id" /> <table name="tb_user_address" dataNode="dn3" primaryKey="id" /> <table name="tb_areas_provinces" dataNode="dn3" primaryKey="id" /> <table name="tb_areas_city" dataNode="dn3" primaryKey="id" /> <table name="tb_areas_region" dataNode="dn3" primaryKey="id" /> </schema> <dataNode name="dn1" dataHost="dhost1" database="shopping" /> <dataNode name="dn2" dataHost="dhost2" database="shopping" /> <dataNode name="dn3" dataHost="dhost3" database="shopping" /> <dataHost name="dhost1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="master" url="jdbc:mysql://192.168.3.248:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234" /> </dataHost> <!-- --> <dataHost name="dhost2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="master" url="jdbc:mysql://192.168.200.213:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234" /> </dataHost> <dataHost name="dhost3" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="master" url="jdbc:mysql://192.168.200.214:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234" /> </dataHost> </mycat:schema>server.xml文件配置如下:<user name="root" defaultAccount="true"> <property name="password">123456</property> <property name="schemas">SHOPPING</property> <!-- 表级 DML 权限设置 --> <!-- <privileges check="false"> <schema name="TESTDB" dml="0110" > <table name="tb01" dml="0000"></table> <table name="tb02" dml="1111"></table> </schema> </privileges> --> </user> <user name="user"> <property name="password">123456</property> <property name="schemas">SHOPPING</property> <property name="readOnly">true</property> </user>
5.2.分库分表-MyCat分片-垂直分库-测试
-
垂直分库-测试
1.切换到/usr/local/mycat/目录cd /usr/local/mycat/2.停止MyCatbin/mycat stop
3.启动MyCatbin/mycat start
4.启动完毕后,可以查看logs目录下的启动日志,查看MyCat是否启动完成tail -f logs/wrapper.log #如下图所示表示MyCat启动成功5.登录MyCatmysql -h 192.168.200.210 -P 8066 -uroot -p123456
6.查看数据库、表信息#查看数据库 show databases;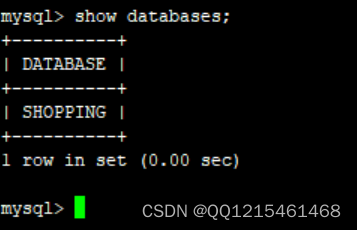
#切换到SHOPPING数据库 use SHOPPING;
#查看表 show tables;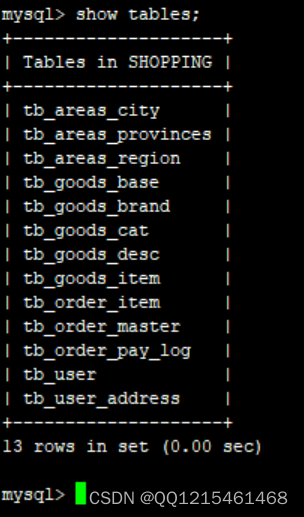
7.上传shopping-table.sql表结构文件与shopping-insert.sql数据文件由于文件内容过多无法展示,需要自行下载:
链接:https://pan.baidu.com/s/11Om-w1Oty0jO98GIL8dK3w?pwd=xjv5 点击前往
提取码:xjv5上传文件到/root目录下
8.执行shopping-table.sql表结构文件与shopping-insert.sql数据文件#执行shopping-table.sql文件 source /root/shopping-table.sql
查看三个数据库可以发现(根据schema.xml配置文件的配置进行了实现)192.168.200.210的数据库中存放了 tb_goods_base、tb_goods_brand、tb_goods_cat、tb_goods_desc、tb_goods_item这五张表
192.168.200.213的数据库中存放了 tb_order_item、tb_order_master、tb_order_pay_log这三张表;
192.168.200.214的数据库中存放了 tb_user、tb_user_address、tb_areas_provinces、tb_areas_city、tb_areas_region这五张表
#执行shopping-insert.sql文件 source /root/shopping-insert.sql
查看三个数据库内的表可以发现有数据了 -
全局表配置
例子1查询用户的收件人及收件人地址信息(包含省、市、区)。
查询成功select ua.user_id,ua.contact,p.province,c.city,r.area,ua.address from tb_user_address ua,tb_areas_city c,tb_areas_provinces p,tb_areas_region r where ua.province_id = p.provinceid and ua.city_id = c.cityid and ua.town_id = r.areaid;
此查询语句只涉及了一个分片所以查询成功
例子2查询每一笔订单及订单的收件地址信息(包含省、市、区)。
SELECT order_id,payment,receiver,province,city,area FROM tb_order_master o,tb_areas_provinces p,tb_areas_city c,tb_areas_region r WHERE o.receiver_province = p.provinceid AND o.receiver_city = c.cityid AND o.receiver_region = r.areaid;查询报错
此查询语句涉及多个分片所以查询报错,为了解决这个问题需要进行全局表配置
全局表配置
对于省、市、区/县表tb_areas_provinces,tb_areas_city,tb_areas_region,是属于数据字典表,在多个业务模块中都可能会遇到,可以将其设置为全局表,利于业务操作。
1.修改MyCat—schema.xml文件配置schema.xml文件配置如下:<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <schema name="SHOPPING" checkSQLschema="true" sqlMaxLimit="100"> <table name="tb_goods_base" dataNode="dn1" primaryKey="id" /> <table name="tb_goods_brand" dataNode="dn1" primaryKey="id" /> <table name="tb_goods_cat" dataNode="dn1" primaryKey="id" /> <table name="tb_goods_desc" dataNode="dn1" primaryKey="id" /> <table name="tb_goods_item" dataNode="dn1" primaryKey="goods_id" /> <table name="tb_order_item" dataNode="dn2" primaryKey="id" /> <table name="tb_order_master" dataNode="dn2" primaryKey="order_id" /> <table name="tb_order_pay_log" dataNode="dn2" primaryKey="out_trade_no" /> <table name="tb_user" dataNode="dn3" primaryKey="id" /> <table name="tb_user_address" dataNode="dn3" primaryKey="id" /> <table name="tb_areas_provinces" dataNode="dn1,dn2,dn3" primaryKey="id" type="global" /> <table name="tb_areas_city" dataNode="dn1,dn2,dn3" primaryKey="id" type="global" /> <table name="tb_areas_region" dataNode="dn1,dn2,dn3" primaryKey="id" type="global" /> </schema> <dataNode name="dn1" dataHost="dhost1" database="shopping" /> <dataNode name="dn2" dataHost="dhost2" database="shopping" /> <dataNode name="dn3" dataHost="dhost3" database="shopping" /> <dataHost name="dhost1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="master" url="jdbc:mysql://192.168.3.248:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234" /> </dataHost> <!-- --> <dataHost name="dhost2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="master" url="jdbc:mysql://192.168.200.213:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234" /> </dataHost> <dataHost name="dhost3" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="master" url="jdbc:mysql://192.168.200.214:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234" /> </dataHost> </mycat:schema>2.测试①停止MyCat
②清空三台数据库shopping数据库中的表
③启动MyCat
④重新导入表结构及数据查询用户的收件人及收件人地址信息(包含省、市、区)。
查询成功
查询每一笔订单及订单的收件地址信息(包含省、市、区)。查询成功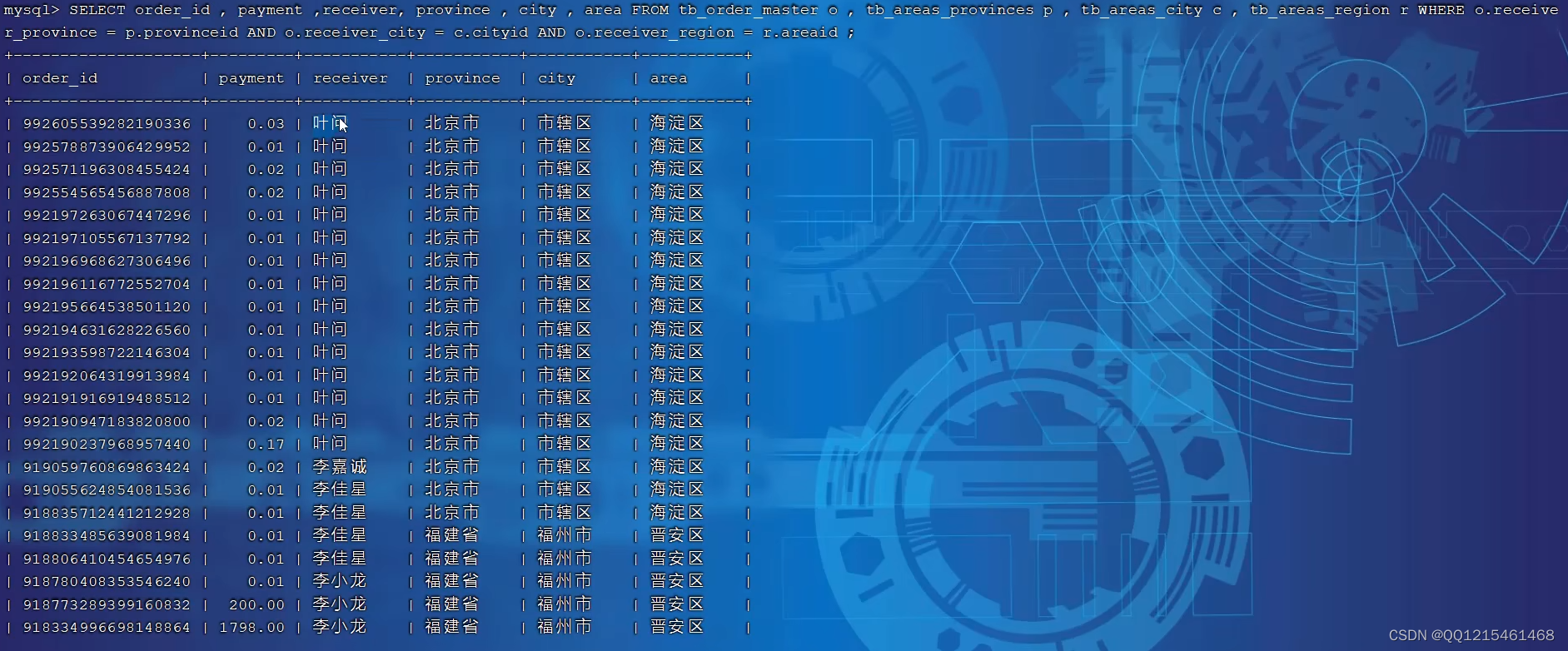
5.3.分库分表-MyCat分片-水平分表
-
水平分表
场景
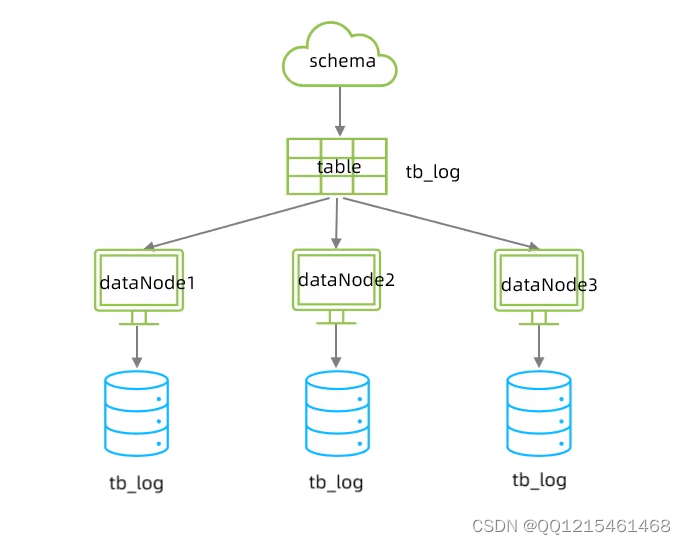
在业务系统中,有一张表(日志表),业务系统每天都会产生大量的日志数据,单台服务器的数据存储及处理能力是有限的,可以对数据库表进行拆分。
准备①如图所示准备三台Linux服务器(ip为:192.168.200.210、192.168.200.213、192.168.200.214)可以根据自己的实际情况进行准备。
②三台服务器上都安装MySQL,在192.168.200.210服务器上安装MyCat。
③三台服务器关闭防火墙或者开放对应的端口。
④分别在三台MySQL中创建数据库 itcast。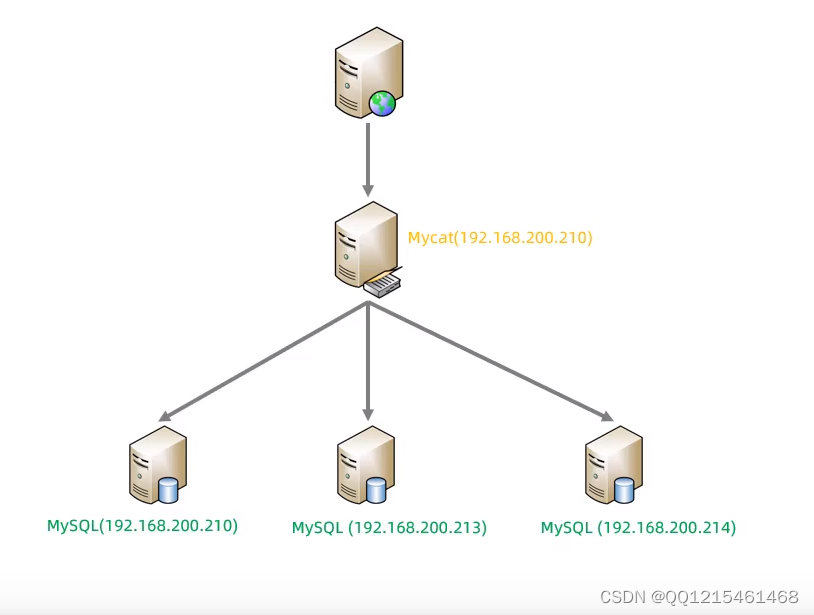
1.MyCat—schema.xml文件配置
schema.xml文件配置如下:(部分主要配置信息展示)<schema name="ITCAST" checkSQLschema="true" sqlMaxLimit="100"> <table name="tb_los" dataNode="dn4,dn5,dn6" primaryKey="id" rule="mod-long" /> </schema> <dataNode name="dn4" dataHost="dhost1" database="itcast" /> <dataNode name="dn5" dataHost="dhost2" database="itcast" /> <dataNode name="dn6" dataHost="dhost3" database="itcast" />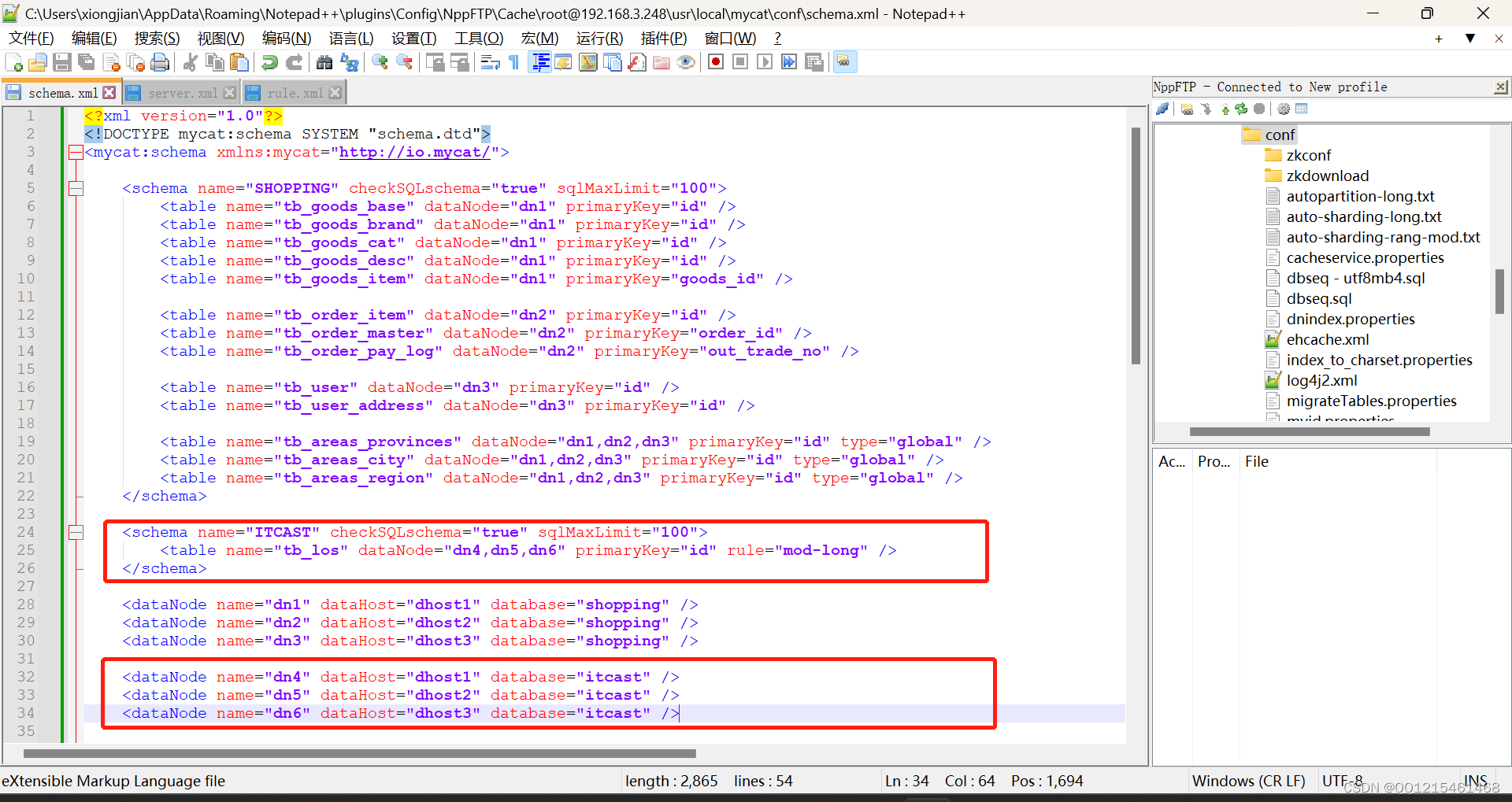
2.MyCat—server.xml文件配置
server.xml文件配置如下:(部分主要配置信息展示)<user name="root" defaultAccount="true"> <property name="password">123456</property> <property name="schemas">SHOPPING,ITCAST</property> <!-- 表级 DML 权限设置 --> <!-- <privileges check="false"> <schema name="TESTDB" dml="0110" > <table name="tb01" dml="0000"></table> <table name="tb02" dml="1111"></table> </schema> </privileges> --> </user> <user name="user"> <property name="password">123456</property> <property name="schemas">SHOPPING</property> <property name="readOnly">true</property> </user>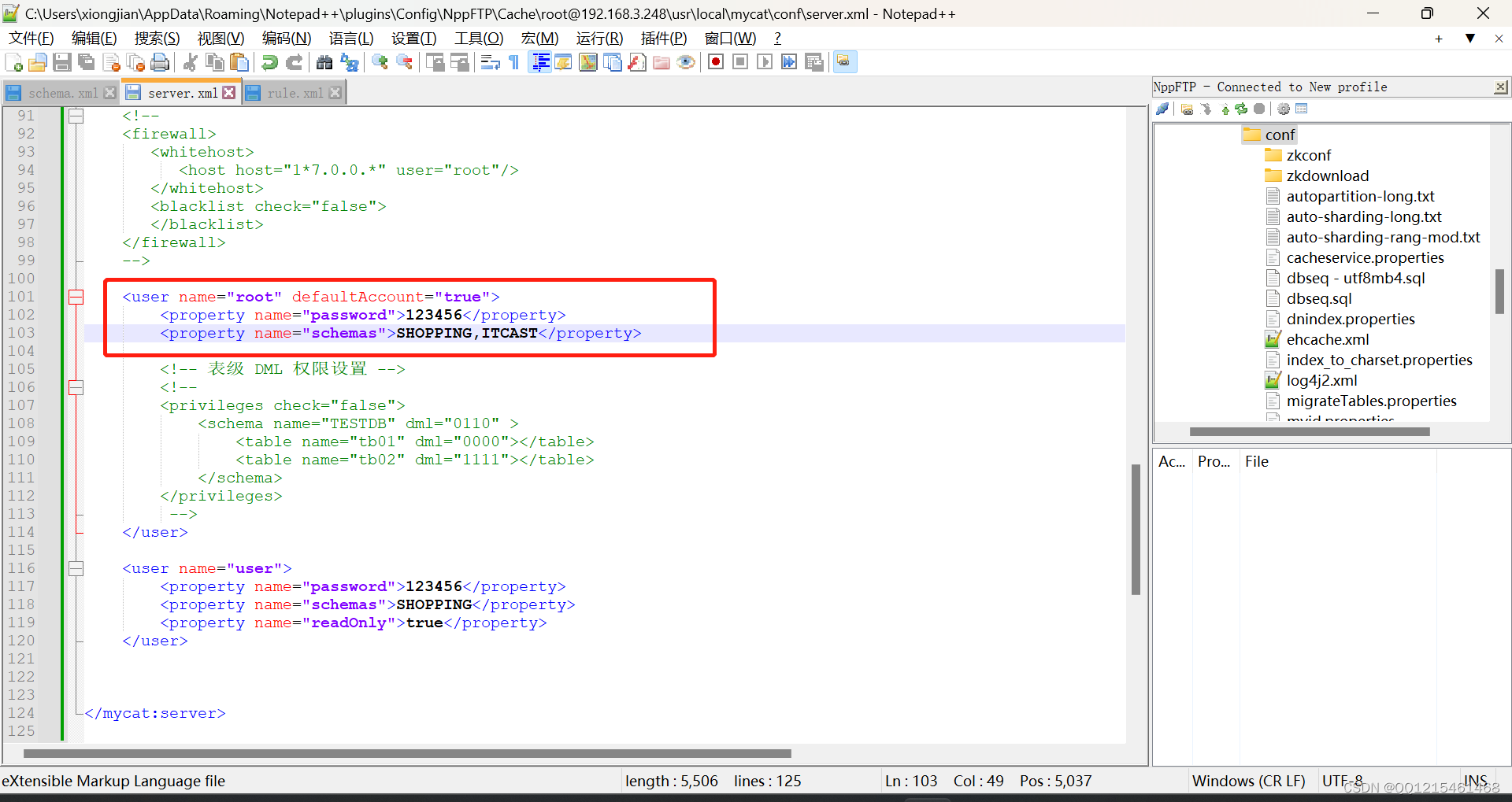
3.MyCat启动
1.进入到MyCat的安装目录#切换到/usr/local/mycat/目录 cd /usr/local/mycat/
2.启动MyCat(若MyCat处于启动状态需要停止MyCat在重新启动)#启动MyCat bin/mycat start #停止MyCat bin/mycat stop
3.查看logs目录下的启动日志,查看MyCat是否启动完成(如下图所示表示MyCat启动成功)#查看wrapper.log日志内容 tail -f logs/wrapper.log
4.MyCat登录
1.登录MyCatmysql -h 192.168.200.210 -P 8066 -uroot -p123456
2.查看数据库、表等相关信息#查看数据库(schema.xml配置文件中定义的数据库已存在) show databases;
#切换到SHOPPING数据库 use ITCAST;
#查看表(schema.xml配置文件中定义的虚拟表已存在) show tables;
5.创建表结构及数据导入
创建表结构CREATE TABLE tb_log ( id bigint(20) NOT NULL COMMENT 'ID', model_name varchar(200) DEFAULT NULL COMMENT '模块名', model_value varchar(200) DEFAULT NULL COMMENT '模块值', return_value varchar(200) DEFAULT NULL COMMENT '返回值', return_class varchar(200) DEFAULT NULL COMMENT '返回值类型', operate_user varchar(20) DEFAULT NULL COMMENT '操作用户', operate_time varchar(20) DEFAULT NULL COMMENT '操作时间', param_and_value varchar(500) DEFAULT NULL COMMENT '请求参数名及参数值', operate_class varchar(200) DEFAULT NULL COMMENT '操作类', operate_method varchar(200) DEFAULT NULL COMMENT '操作方法', cost_time bigint(20) DEFAULT NULL COMMENT '执行方法耗时, 单位 ms', source int(1) DEFAULT NULL COMMENT '来源 : 1 PC , 2 Android , 3 IOS', PRIMARY KEY (id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
查看三个数据库可以发现表和表结构都有了
添加数据INSERT INTO tb_log (id, model_name, model_value, return_value, return_class, operate_user, operate_time, param_and_value, operate_class, operate_method, cost_time,source) VALUES('1','user','insert','success','java.lang.String','10001','2022-01-06 18:12:28','{\"age\":\"20\",\"name\":\"Tom\",\"gender\":\"1\"}','cn.itcast.controller.UserController','insert','10',1); INSERT INTO tb_log (id, model_name, model_value, return_value, return_class, operate_user, operate_time, param_and_value, operate_class, operate_method, cost_time,source) VALUES('2','user','insert','success','java.lang.String','10001','2022-01-06 18:12:27','{\"age\":\"20\",\"name\":\"Tom\",\"gender\":\"1\"}','cn.itcast.controller.UserController','insert','23',1); INSERT INTO tb_log (id, model_name, model_value, return_value, return_class, operate_user, operate_time, param_and_value, operate_class, operate_method, cost_time,source) VALUES('3','user','update','success','java.lang.String','10001','2022-01-06 18:16:45','{\"age\":\"20\",\"name\":\"Tom\",\"gender\":\"1\"}','cn.itcast.controller.UserController','update','34',1); INSERT INTO tb_log (id, model_name, model_value, return_value, return_class, operate_user, operate_time, param_and_value, operate_class, operate_method, cost_time,source) VALUES('4','user','update','success','java.lang.String','10001','2022-01-06 18:16:45','{\"age\":\"20\",\"name\":\"Tom\",\"gender\":\"1\"}','cn.itcast.controller.UserController','update','13',2); INSERT INTO tb_log (id, model_name, model_value, return_value, return_class, operate_user, operate_time, param_and_value, operate_class, operate_method, cost_time,source) VALUES('5','user','insert','success','java.lang.String','10001','2022-01-06 18:30:31','{\"age\":\"200\",\"name\":\"TomCat\",\"gender\":\"0\"}','cn.itcast.controller.UserController','insert','29',3); INSERT INTO tb_log (id, model_name, model_value, return_value, return_class, operate_user, operate_time, param_and_value, operate_class, operate_method, cost_time,source) VALUES('6','user','find','success','java.lang.String','10001','2022-01-06 18:30:31','{\"age\":\"200\",\"name\":\"TomCat\",\"gender\":\"0\"}','cn.itcast.controller.UserController','find','29',2);查看三个数据库内的tb_log表发现有数据了,数据的分布规则是 id模以3的结果为0的数据分布在第一个节点,id模以3的结果为1的数据分布在第二个节点,id模以3的结果为2的数据分布在第三个节点
6.分库分表-分片规则
6.1.分库分表-分片规则-范围分片
-
范围分片
根据指定的字段及其配置的范围与数据节点的对应情况,来决定该数据属于哪一个分片。
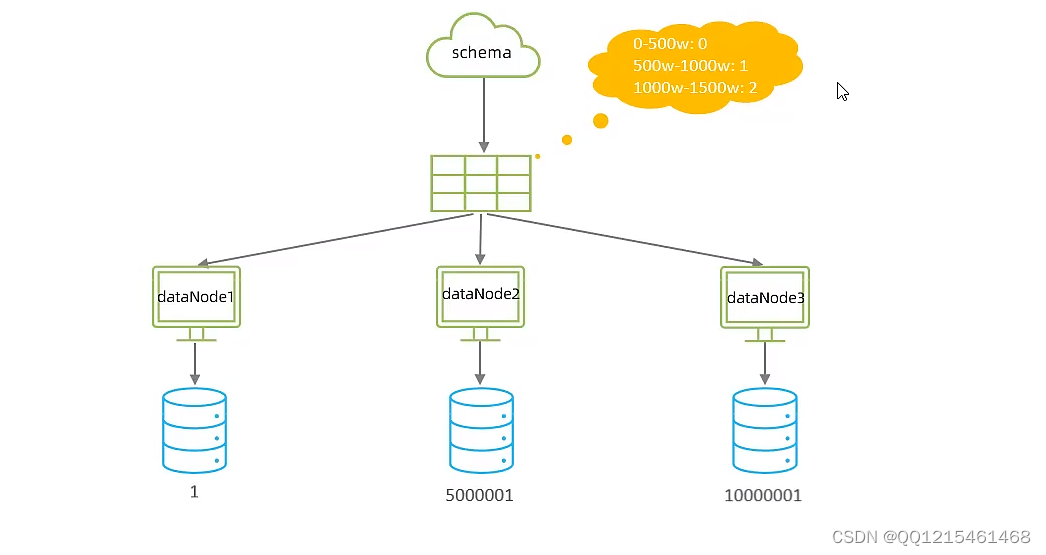

# range start-end ,data node index # K=1000,M=10000. 0-500M=0 #表示id在0-500万的数据放在第一个节点 500M-1000M=1 #表示id在500万-1000万的数据放在第二个节点 1000M-1500M=2 #表示id在1000万-1500万的数据放在第三个节点
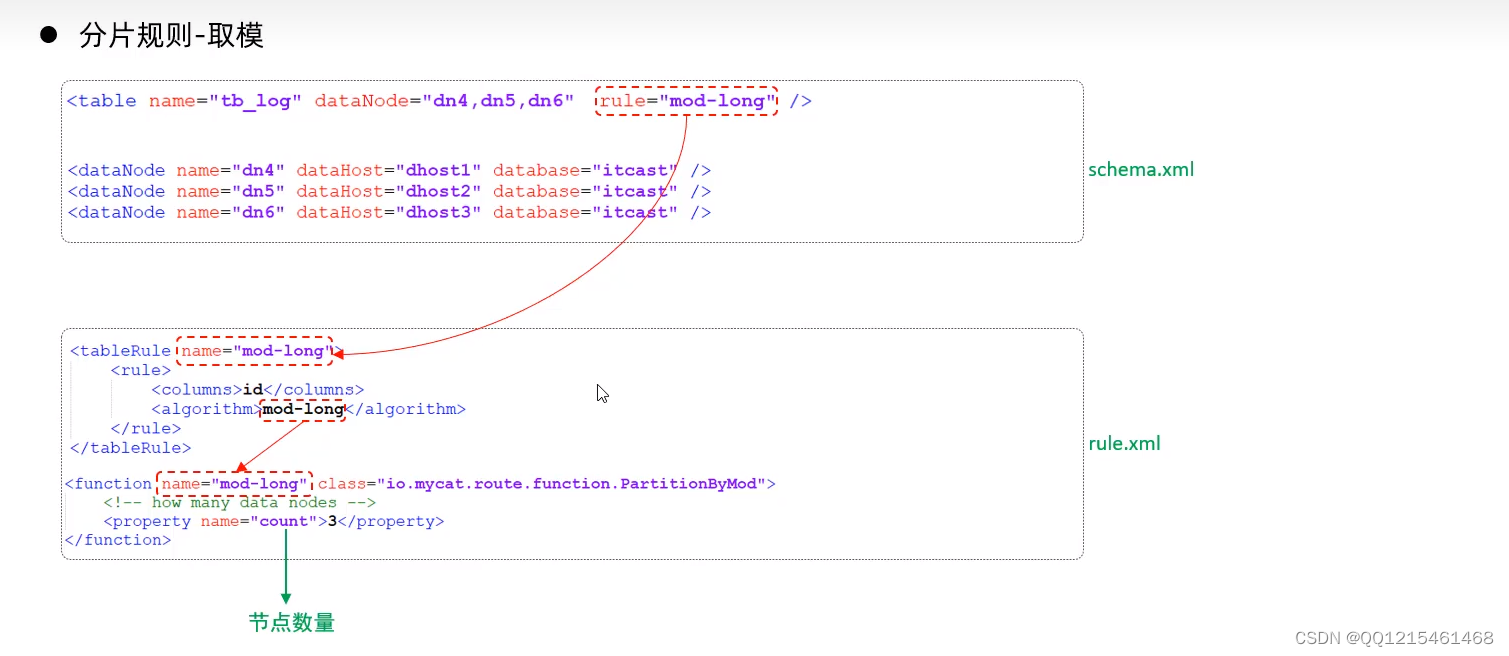
6.2.分库分表-分片规则-取模分片
-
取模分片
根据指定的字段值与节点数量进行求模运算,根据运算结果,来决定该数据属于哪一个分片。
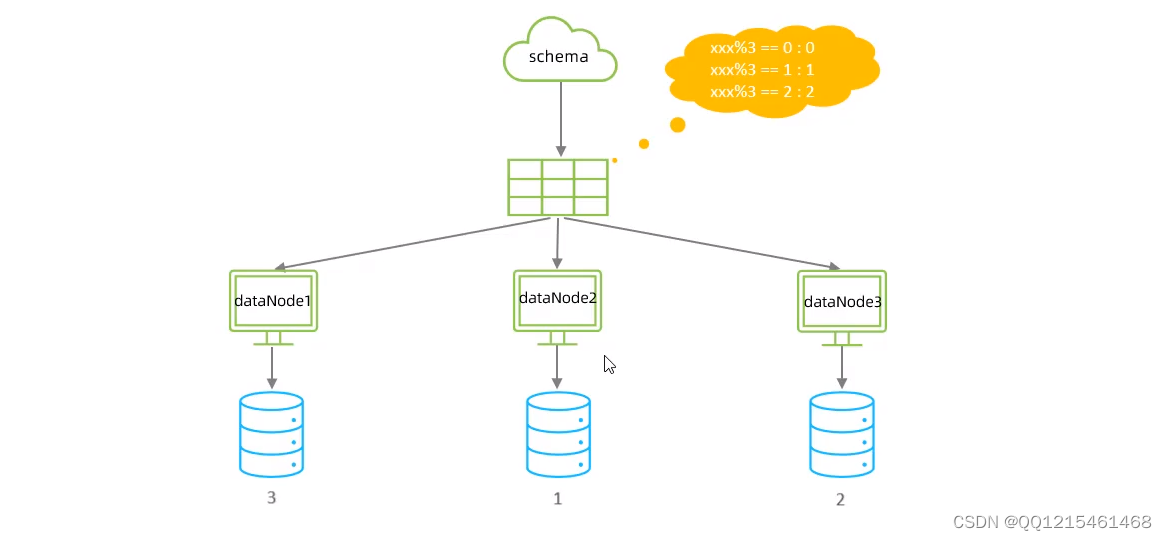
6.3.分库分表-分片规则-一致性hash算法
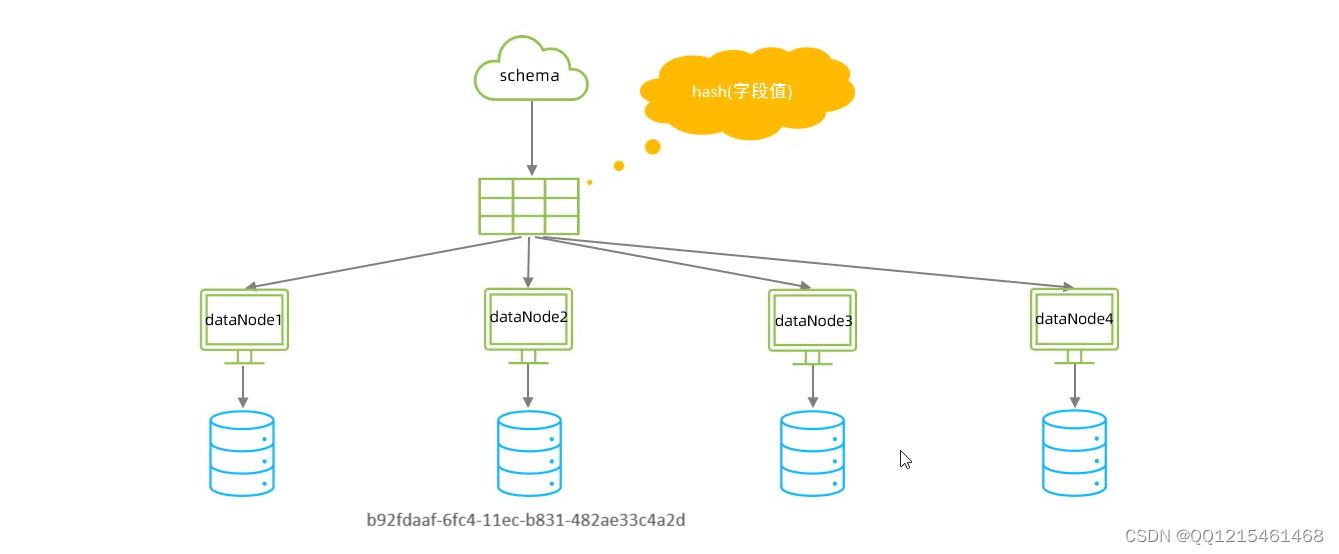
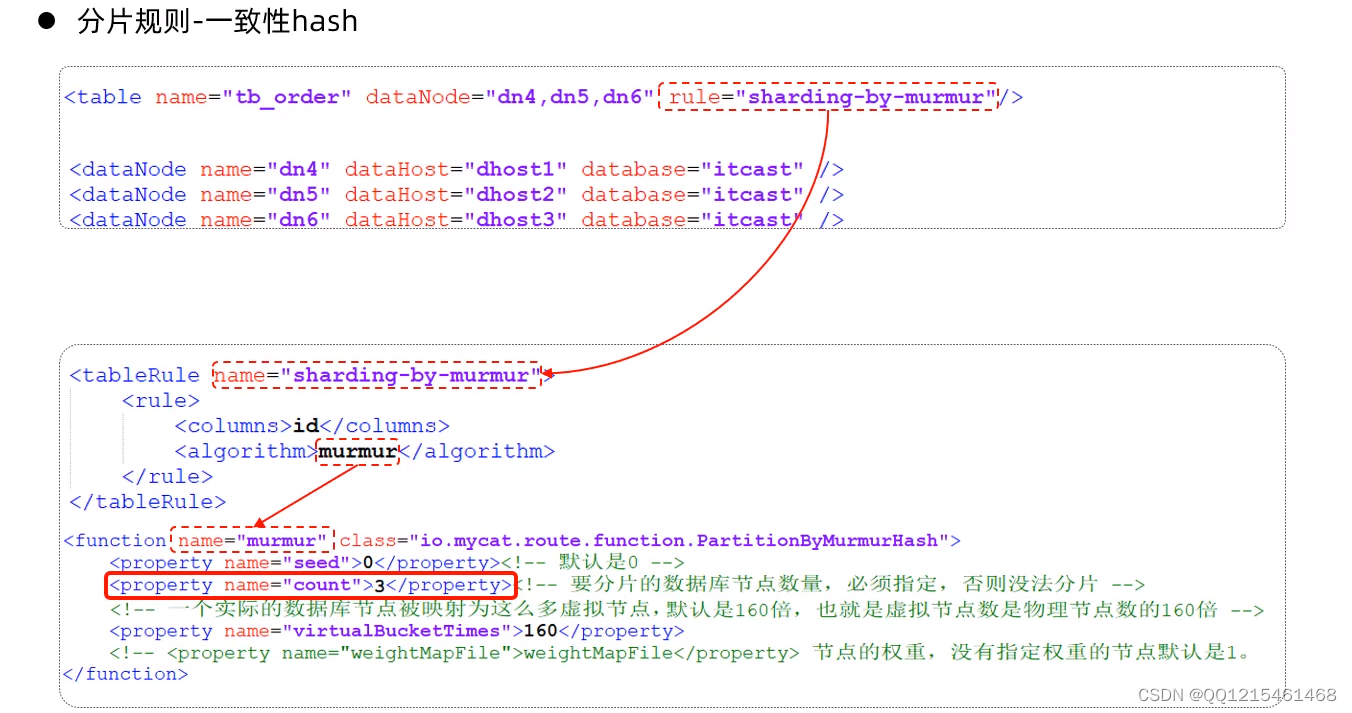
-
一致性hash算法
所谓一致性哈希,相同的哈希因子计算值总是被划分到相同的分区表中,不会因为分区节点的增加而改变原来数据的分区位置。
6.4.分库分表-分片规则-枚举分片
-
枚举分片
通过在配置文件中配置可能的枚举值,指定数据分布到不同数据节点上,本规则适用于按照省份、性别、状态拆分数据等业务。
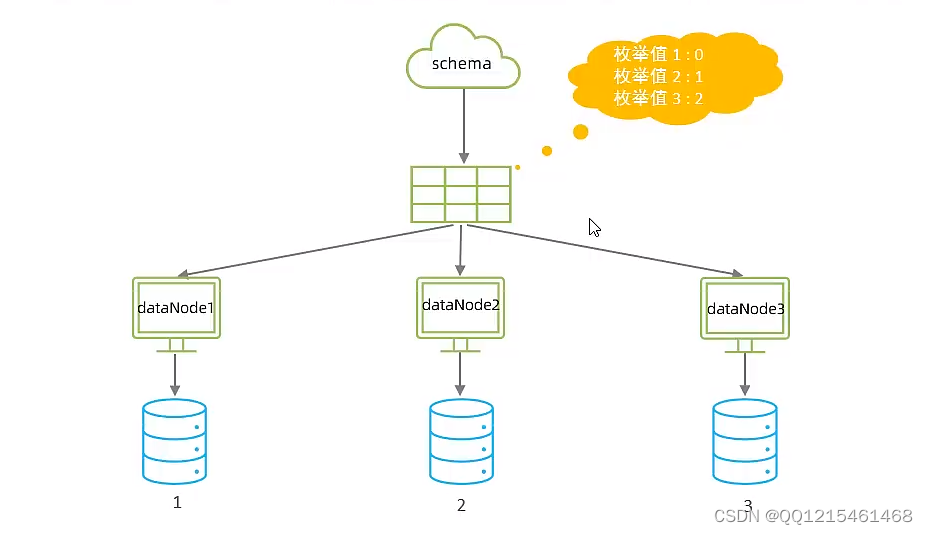
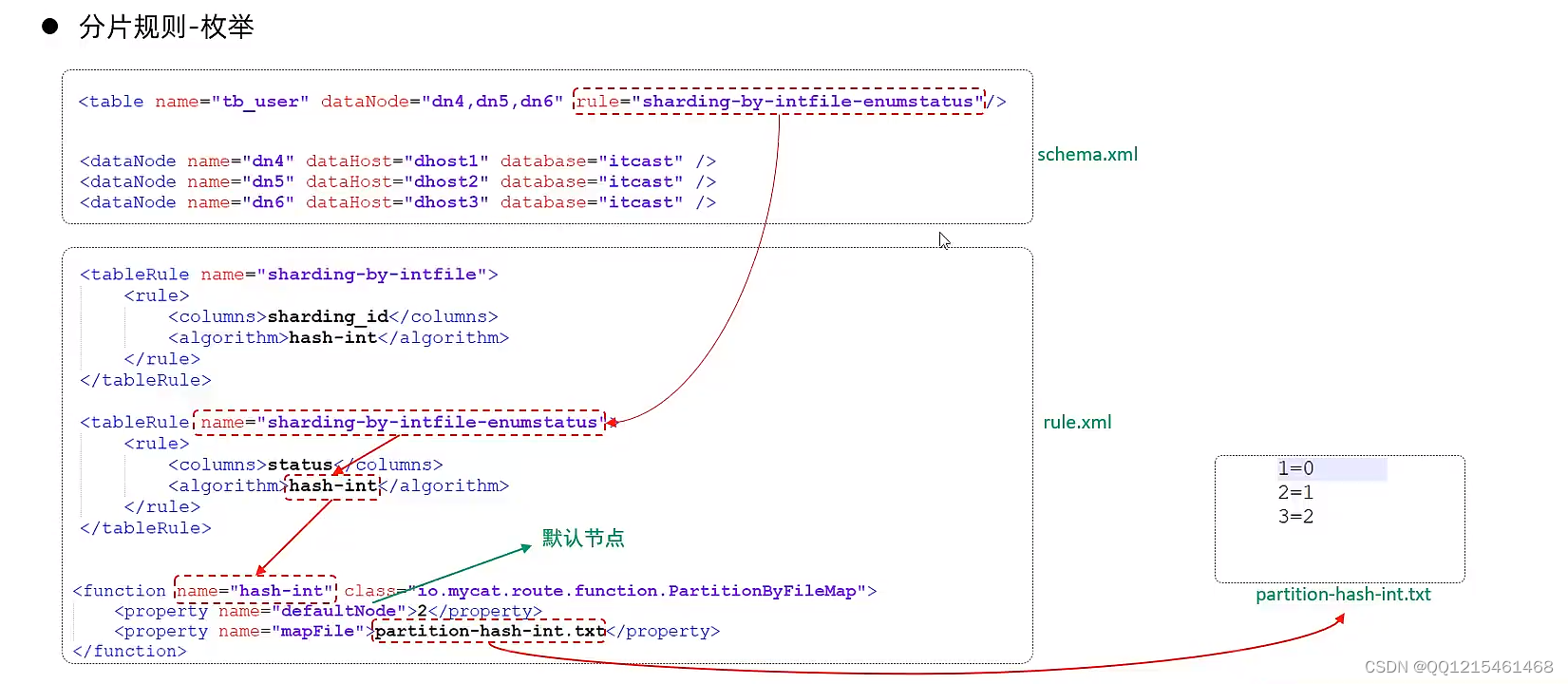
为了不影响默认的分片规则,这里创建了一个分片规则。默认节点是为了避免匹配规则中无法匹配的数据,默认放到第几个节点的数据库中,避免报错。
6.5.分库分表-分片规则-应用指定算法
-
应用指定算法
运行阶段由应用自主决定路由到哪个分片,直接根据字符子串(必须是数字)计算分片号。


6.6.分库分表-分片规则-固定hash算法
-
固定hash算法
该算法类似于十进制的求模运算,但是为二进制的操作,例如,取 id 的二进制低 10 位 与 1111111111 进行位 & 运算。
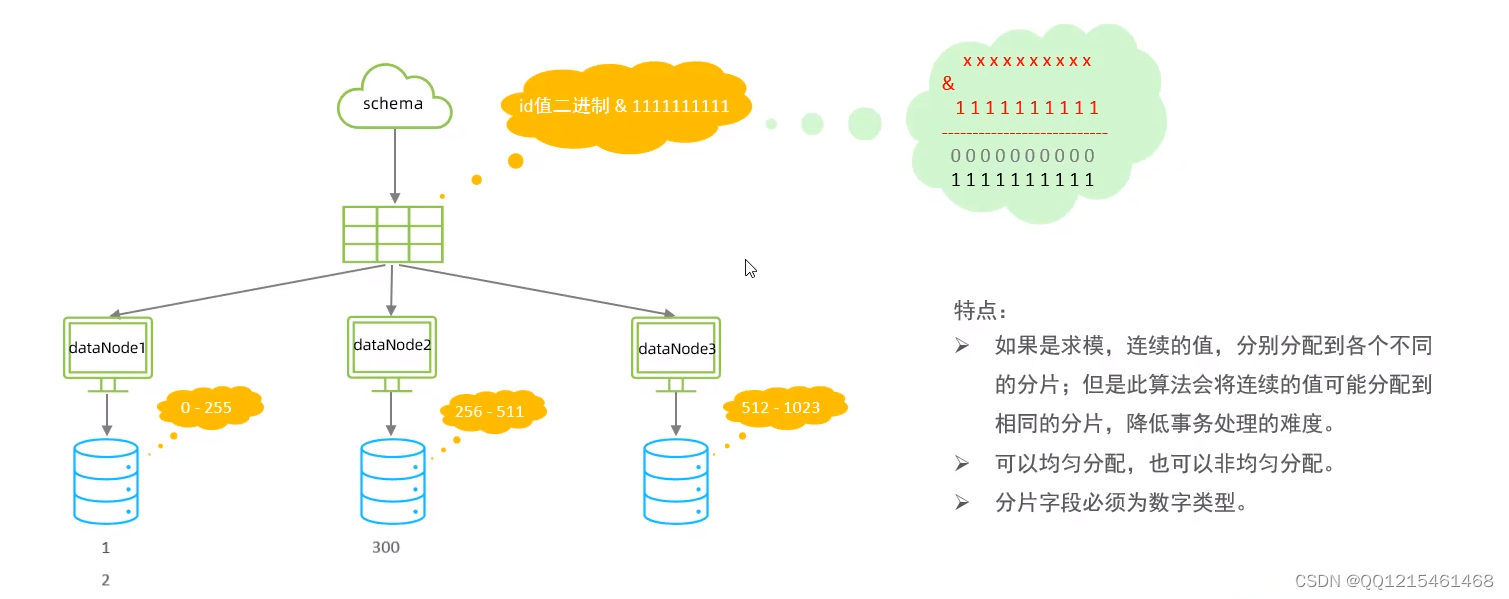
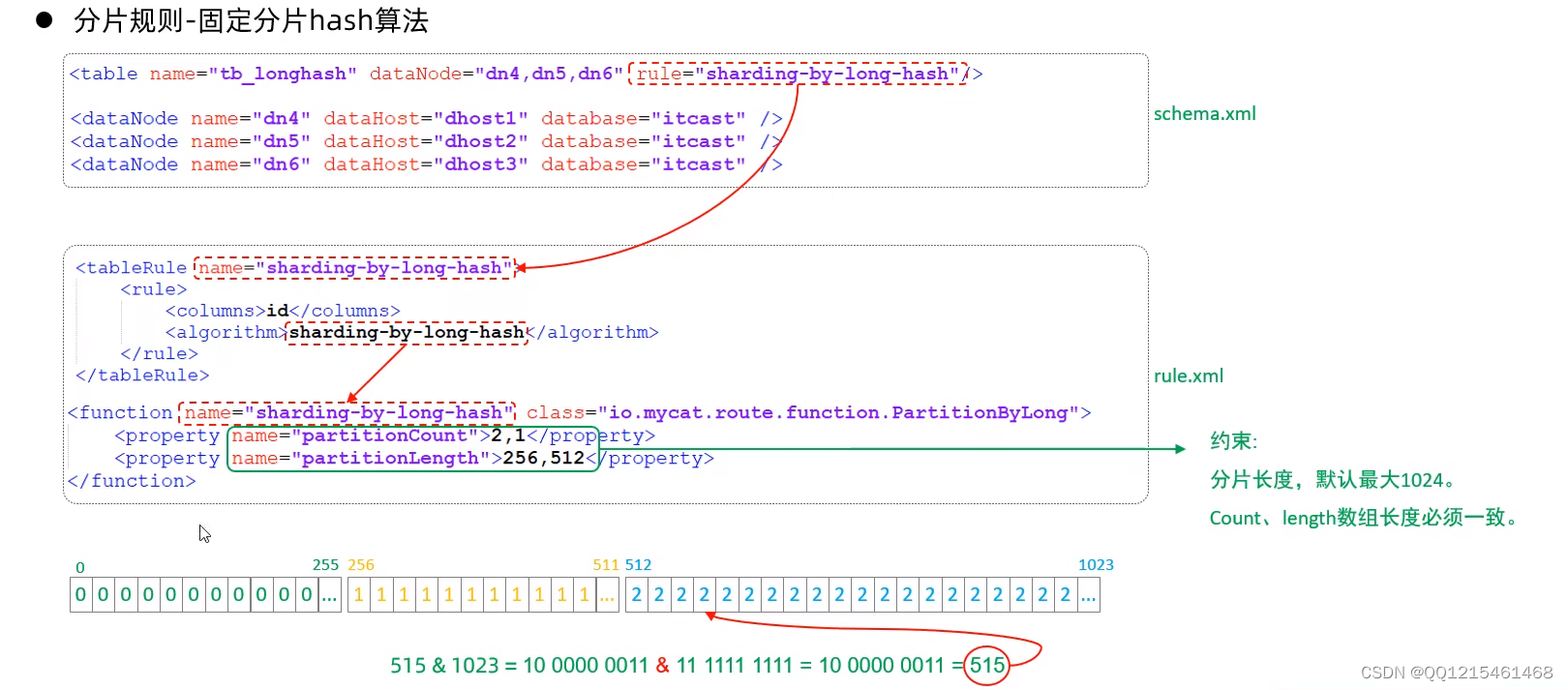
6.7.分库分表-分片规则-字符串hash解析
-
字符串hash解析
截取字符串中的指定位置的子字符串,进行hash算法,算出分片。
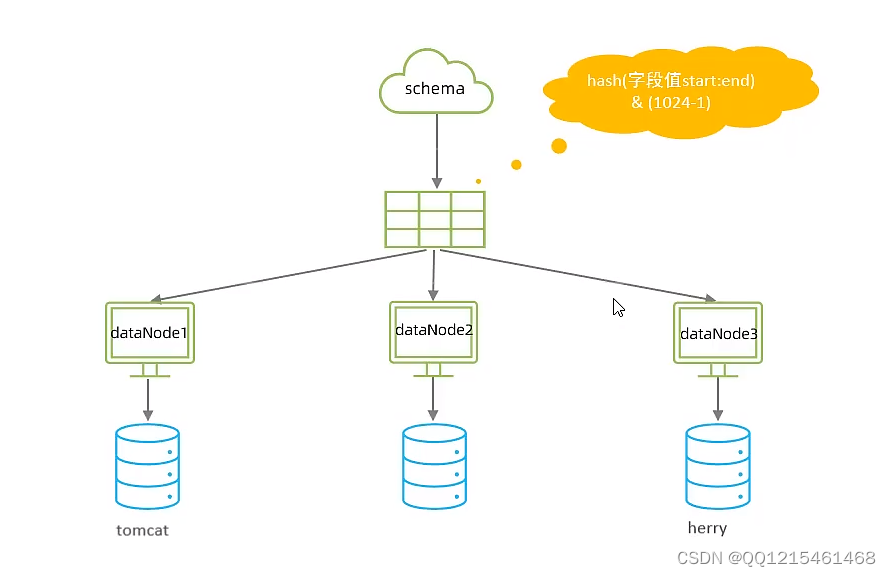
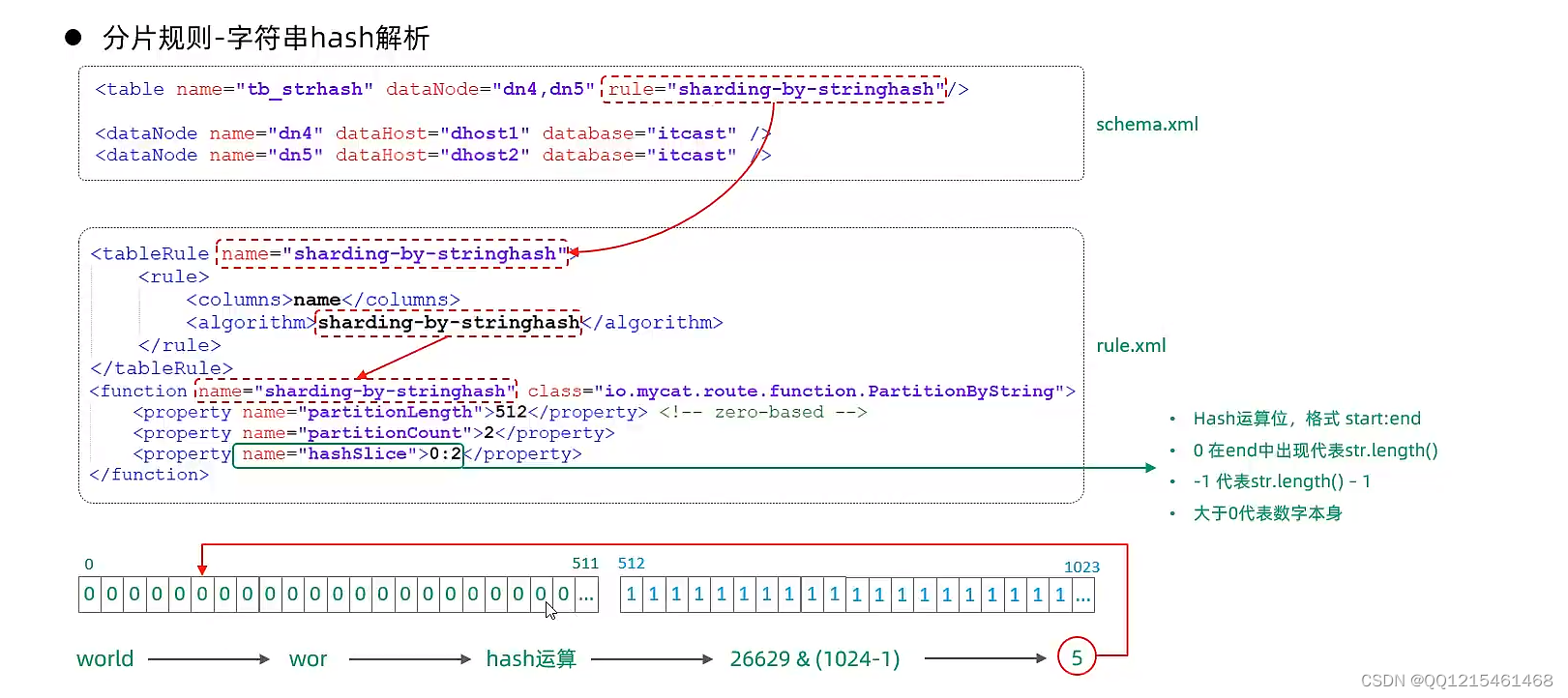
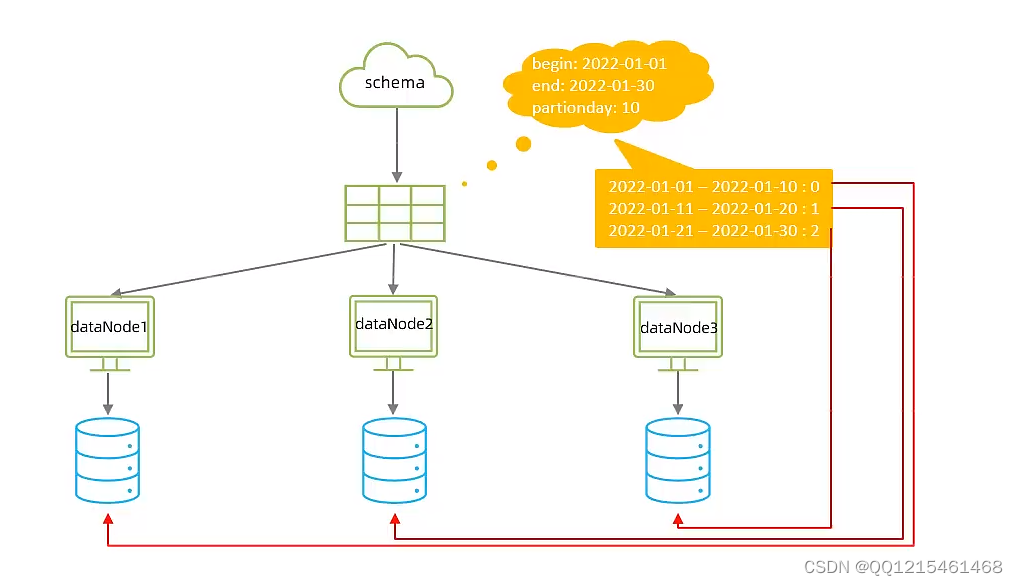
6.8.分库分表-分片规则-按天分片
- 按天分片

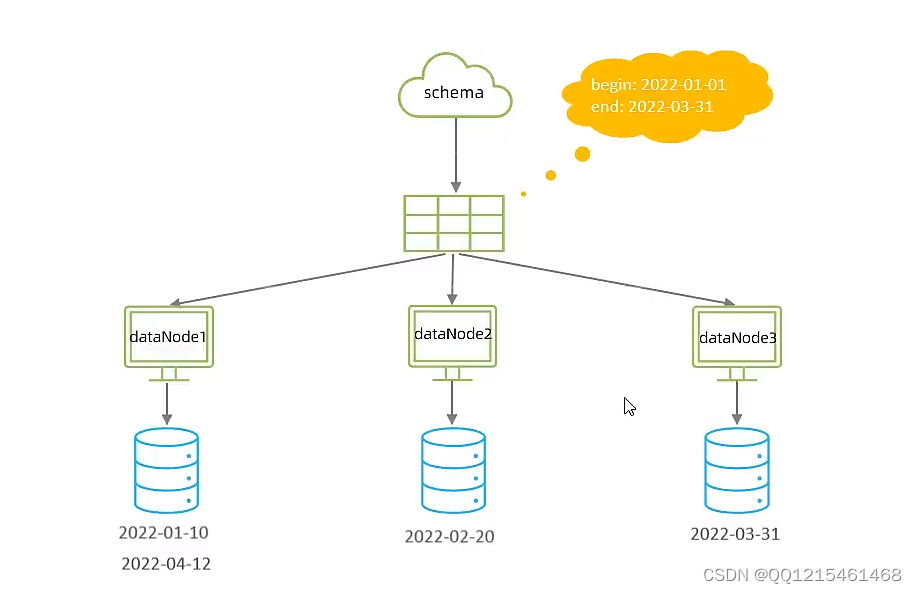
6.9.分库分表-分片规则-按自然月分片
-
按自然月分片
使用场景为按照月份来分片,每个自然月为一个分片。

7.分库分表-MyCat管理与监控
7.1.分库分表-MyCat管理与监控-原理
-
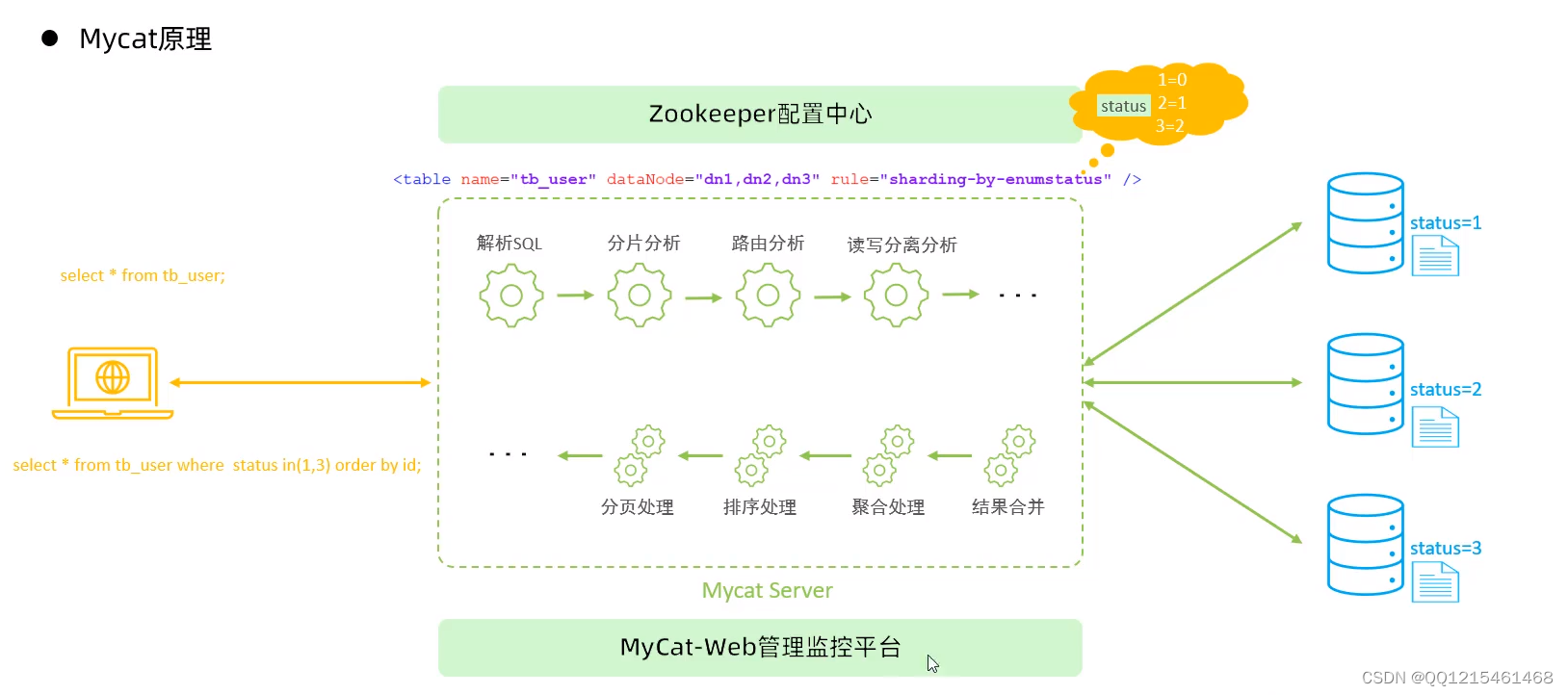
原理
7.2.分库分表-MyCat管理工具
-
MyCat管理工具
Mycat默认开通了2个端口,可以在server.xml中进行修改
8066 数据访问端口,即进行DML和DDL 操作。
9066 数据库管理端口,即Mycat 服务管理控制功能,用于管理Mycat的整个集群状态。#登录 mysql -h 192.168.200.210 -P 9066 -uroot -p123456命令 含义 show @@help 查看Mycat管理工具帮助文档 show @@version 查看Mycat的版本 reload @@config 重新加载Mycat的配置文件 show @@datasource 查看Mycat的数据源信息 show @@datanode 查看MyCat现有的分片节点信息 show @@threadpool 查看Mvcat的线程池信息 show @@sgl 查看执行的SQL show @@sgl.sum 查看执行的SQL统计
7.3.分库分表-MyCat监控1
-
MyCat监控
-
Mycat-eye
Mycat-eye介绍Mycat-web(Mycat-eye)是对mycat-server提供监控服务,功能不局限于对mycat-server使用。他通过DBC连接对Mycat、 Mysql监控,监控远程服务器(目前仅限于linux系统)的cpu、内存、网络、磁盘。
Mycat-eye运行过程中需要依赖zookeeper,因此需要先安装zookeeper。 -
Zookeeper与MyCat-web安装
Zookeeper与MyCat-web安装包网盘下载地址:
链接:https://pan.baidu.com/s/1t5YMeHzSExHcfKqse1kjag?pwd=xjv5 点击前往
提取码:xjv5Zookeeper安装1.上传Zookeeper安装包

2.将Zookeeper安装包解压到/usr/local/目录下tar -zxvf zookeeper-3.4.6.tar.gz -C /usr/local/
3.切换到/usr/local/zookeeper-3.4.6/目录下cd /usr/local/zookeeper-3.4.6/
4.创建一个名为data的文件夹#创建data文件夹 mkdir data #进入到data目录下 cd data #查看当前目录(复制目录) pwd


5.切换到/usr/local/zookeeper-3.4.6/conf/目录下
cd /usr/local/zookeeper-3.4.6/conf/
6.将zoo_sample.cfg文件重命名为zoo.cfg
mv zoo_sample.cfg zoo.cfg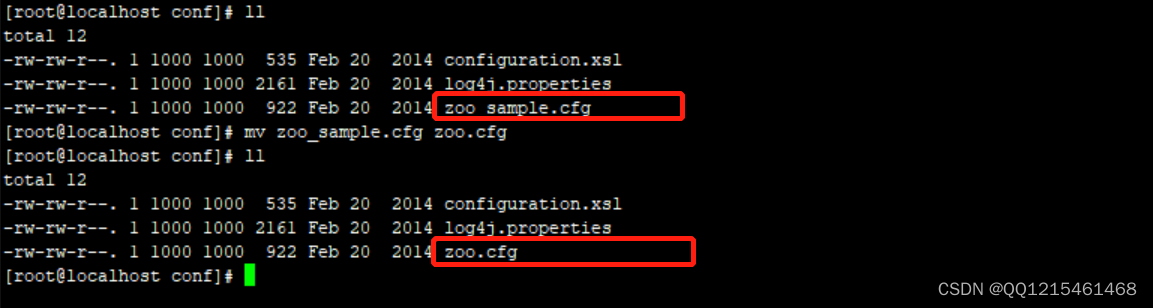
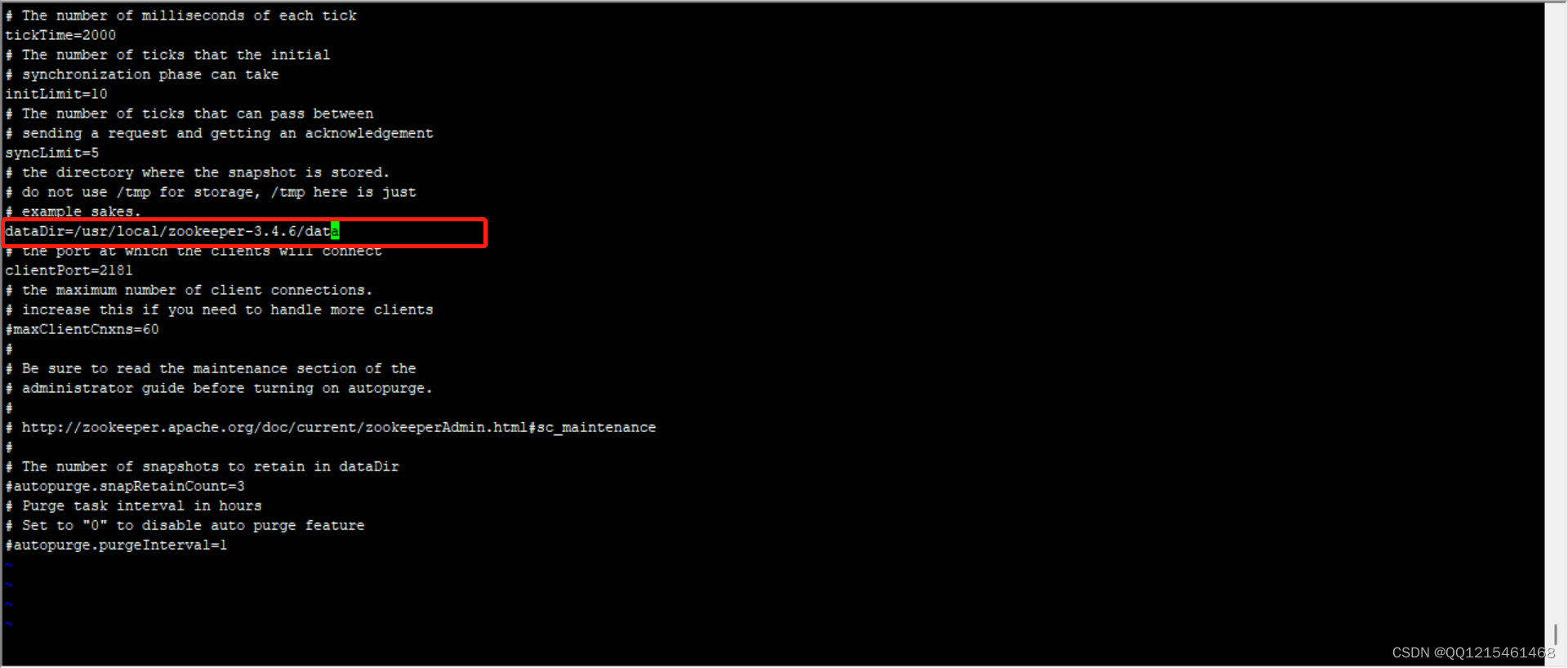
7.编辑zoo.cfg文件,修改dataDir=/usr/local/zookeeper-3.4.6/data
#编辑zoo.cfg文件 vim zoo.cfg #修改dataDir=/usr/local/zookeeper-3.4.6/data dataDir=/usr/local/zookeeper-3.4.6/data #保存退出
8.启动zookeeper
#切换到/usr/local/zookeeper-3.4.6/目录下(cd .. #返回上一级目录) cd /usr/local/zookeeper-3.4.6/ #启动zookeeper bin/zkServer.sh start #查看zookeeper的启动状态(Mode: standalone 表示启动成功) bin/zkServer.sh status


MyCat-web安装1.上传MyCat-web安装包

2.将MyCat-web安装包解压到/usr/local/目录下tar -zxvf Mycat-web.tar.gz -C /usr/local/
3.启动MyCat-web#切换到/usr/local/mycat-web/目录下 cd /usr/local/mycat-web/ #启动MyCat-web(如图所示启动成功) sh start.sh

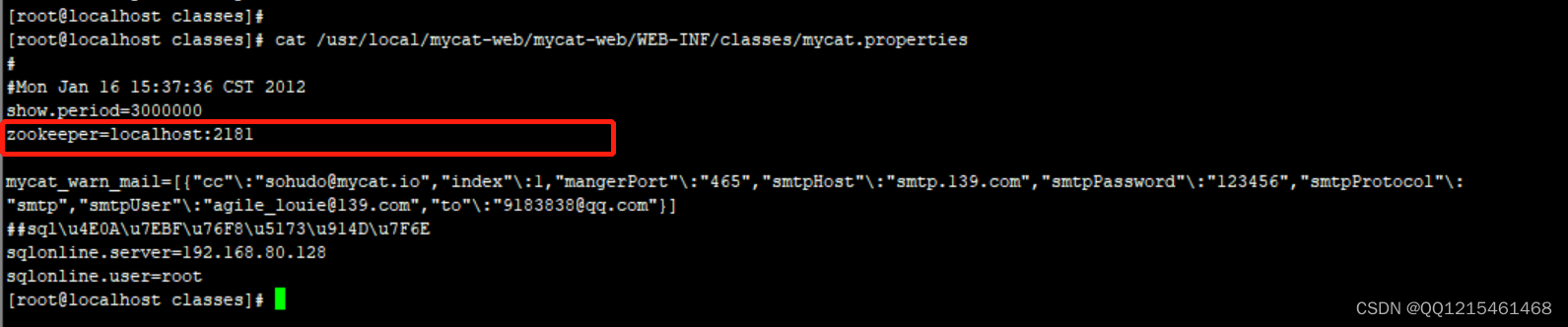
注意如果zookeeper和MyCat-web没有安装在同一台服务器上,需要修改/usr/local/mycat-web/mycat-web/WEB-INF/classes/目录下的mycat.properties配置文件,将zookeeper=localhost:2181中的localhost修改为对应服务器的IP地址
4.访问MyCat-web
#浏览器访问MyCat-web安装所在的服务器地址 http://192.168.3.248:8082/mycat/
5.配置MyCat-web
开启Mycat的实时统计功能(server.xml)

在Mycat监控界面配置服务地址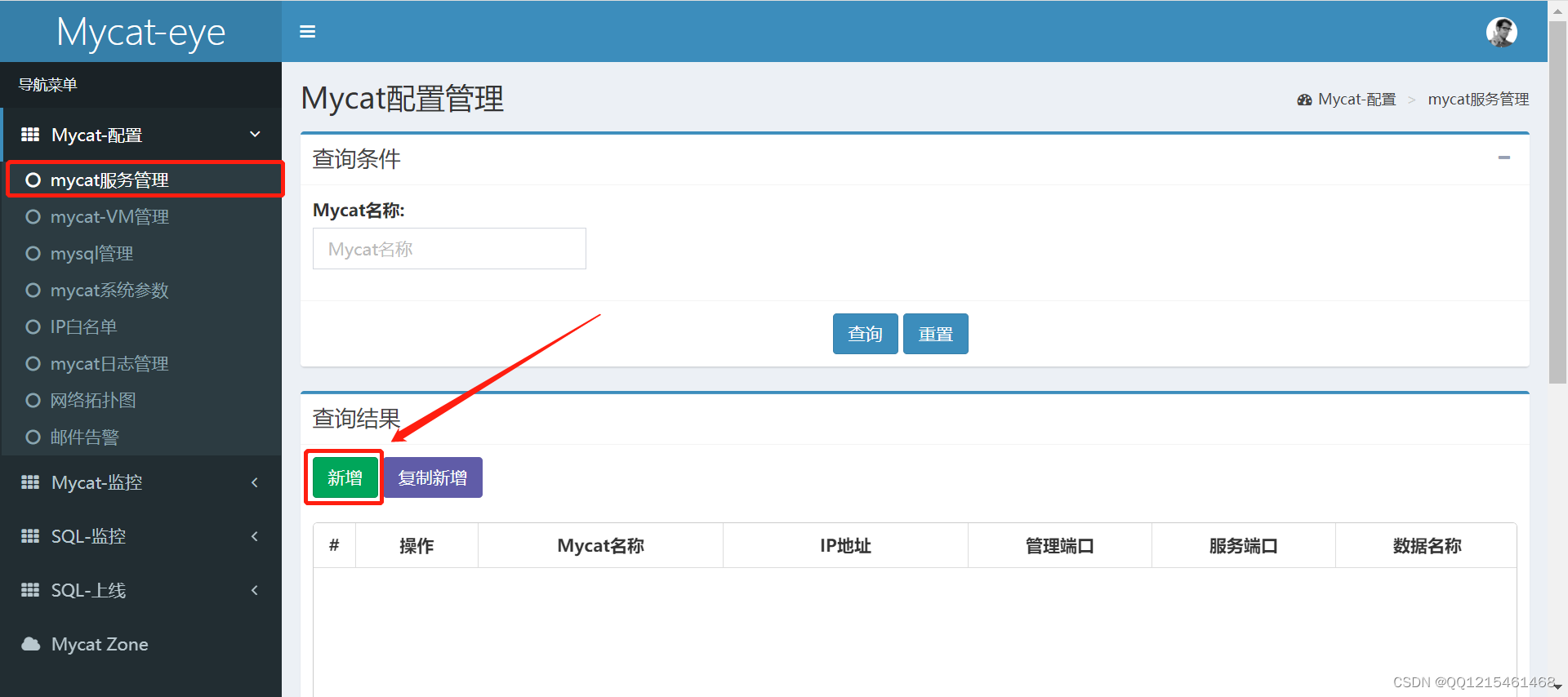
录入信息-保存
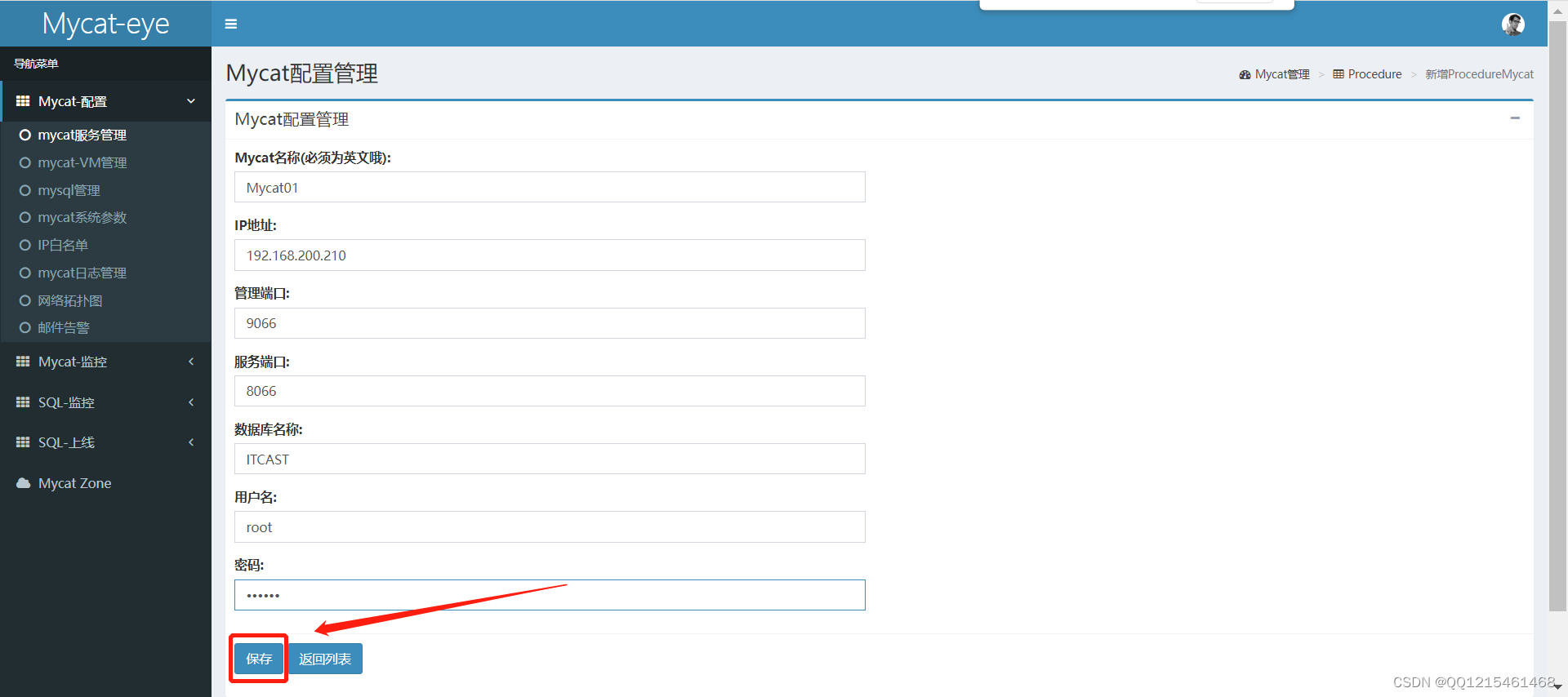
保存完成点击返回列表即可看到刚才配置好的信息
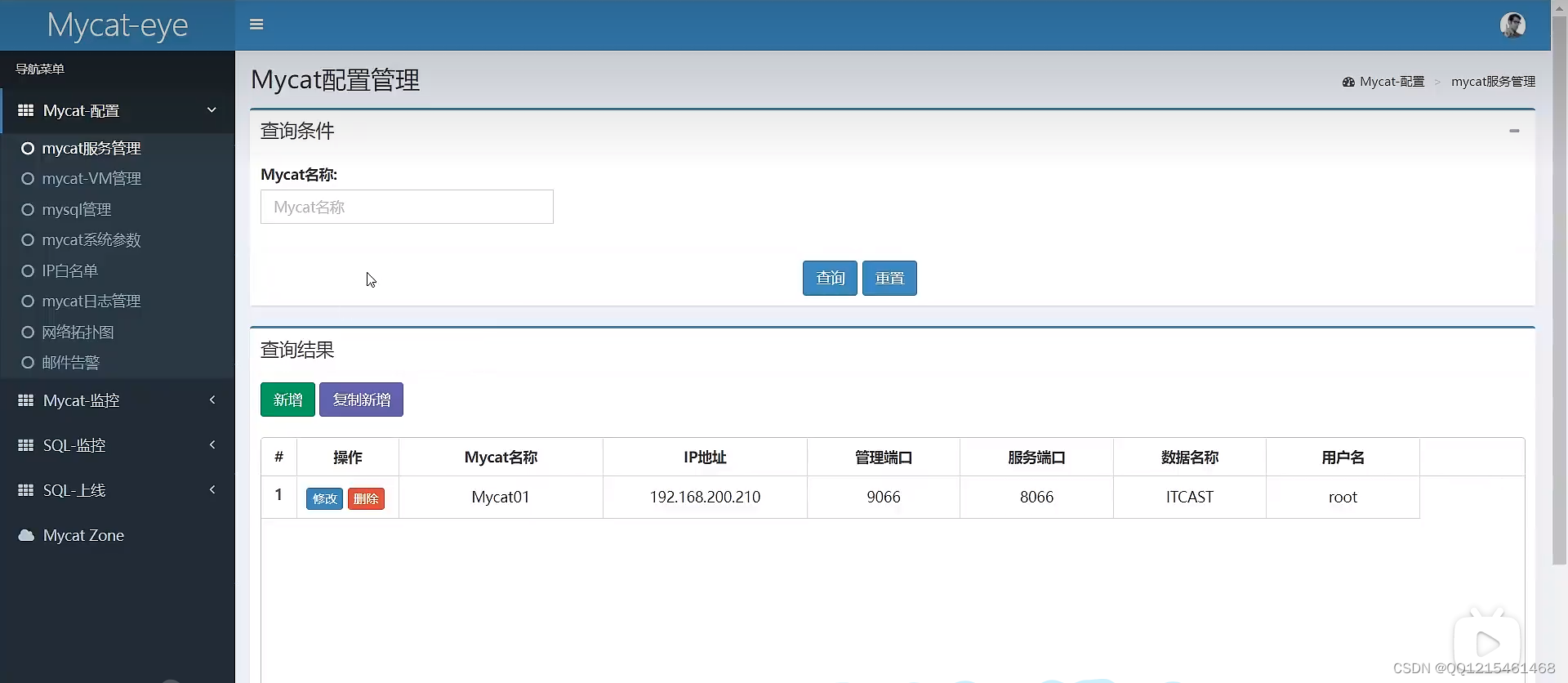
-
Mycat-eye主要信息展示
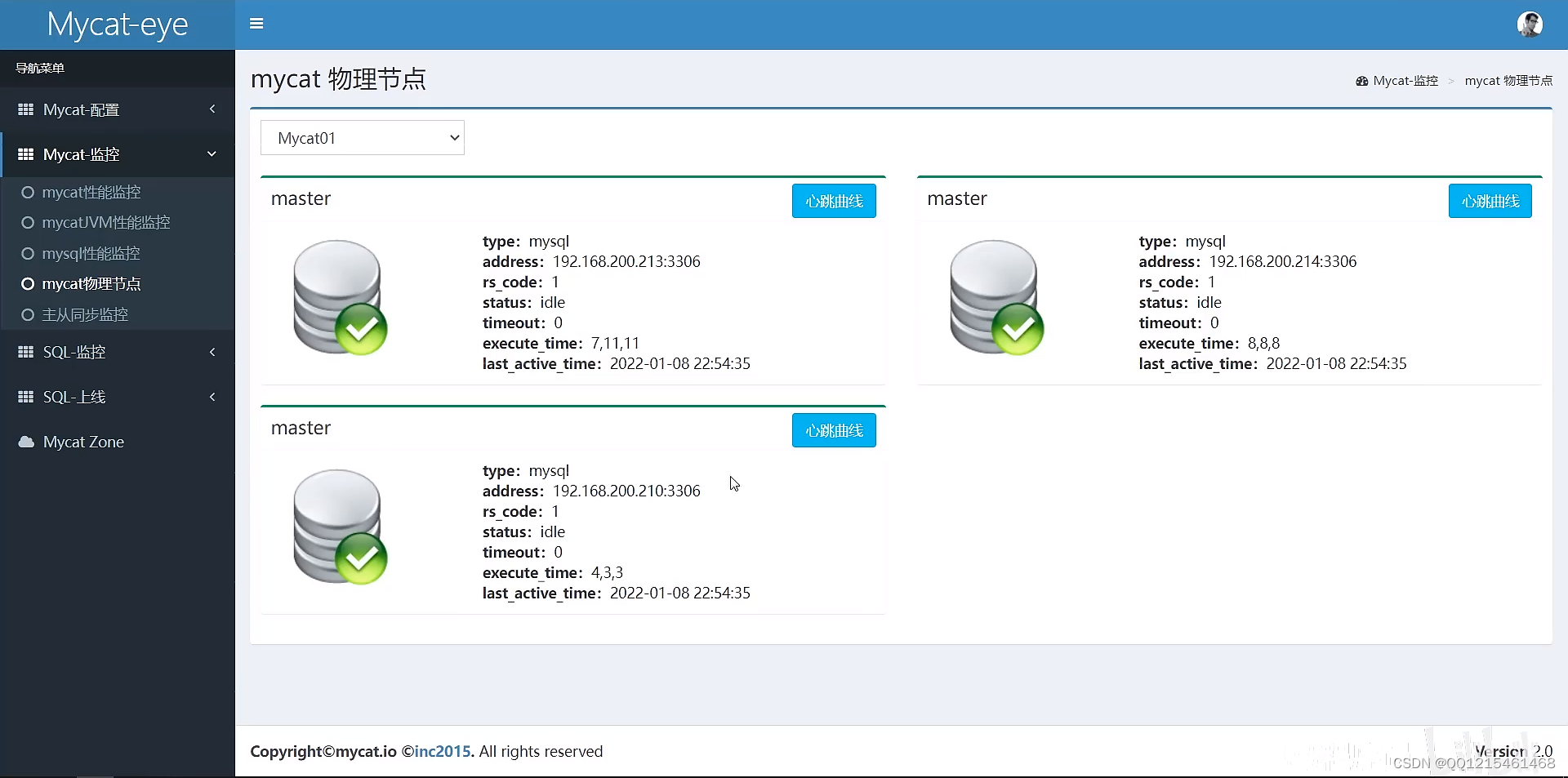
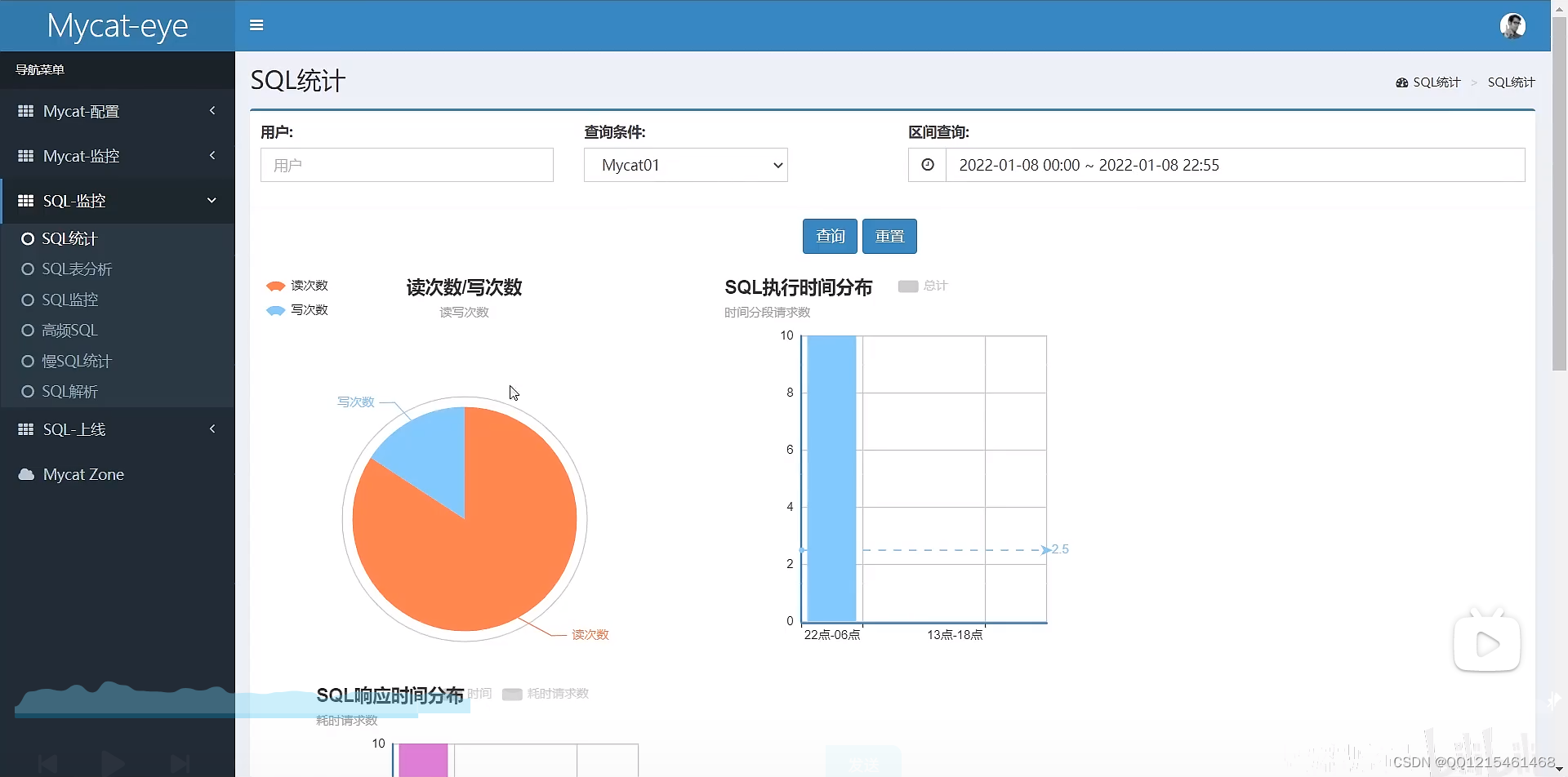
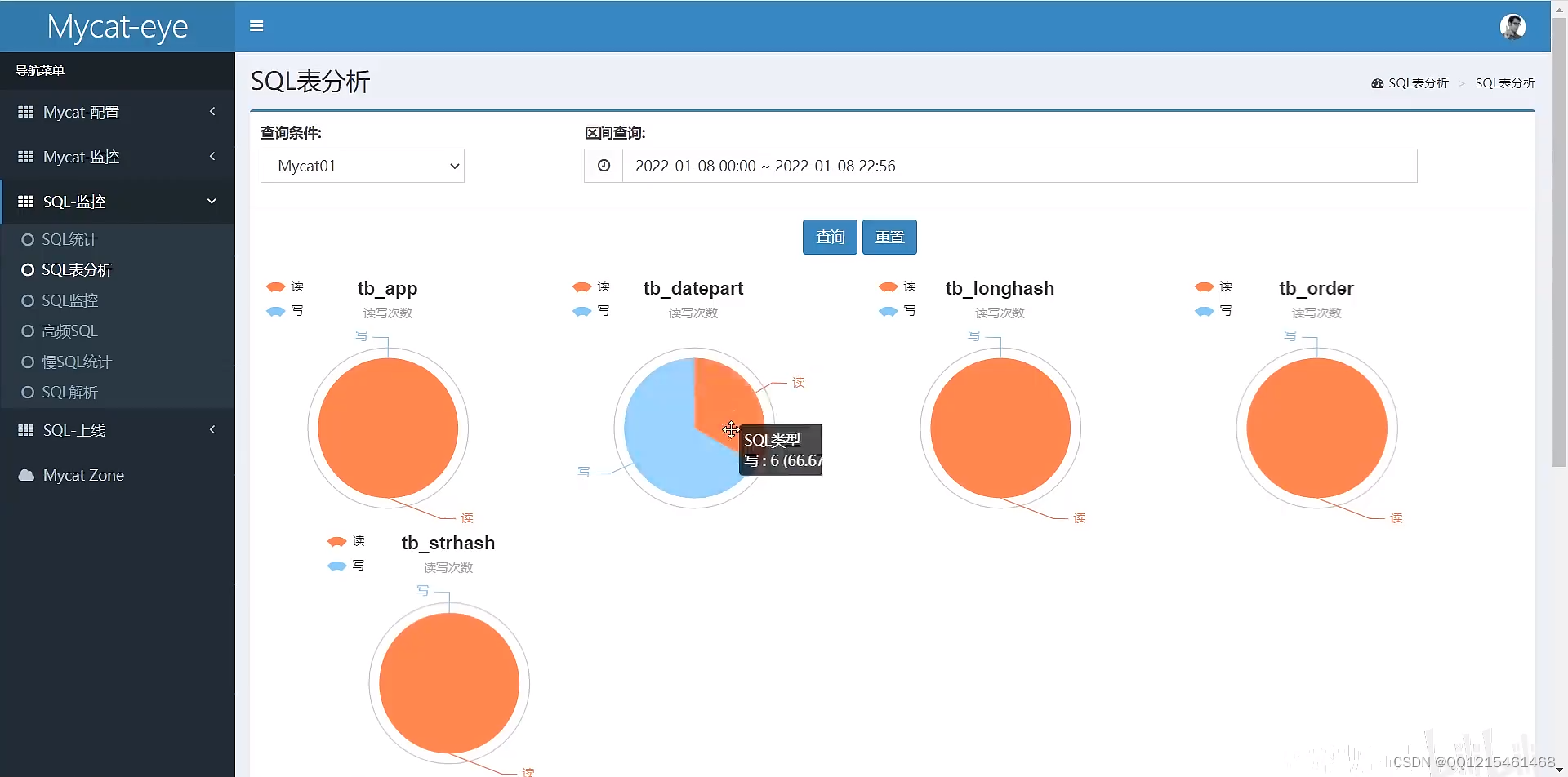
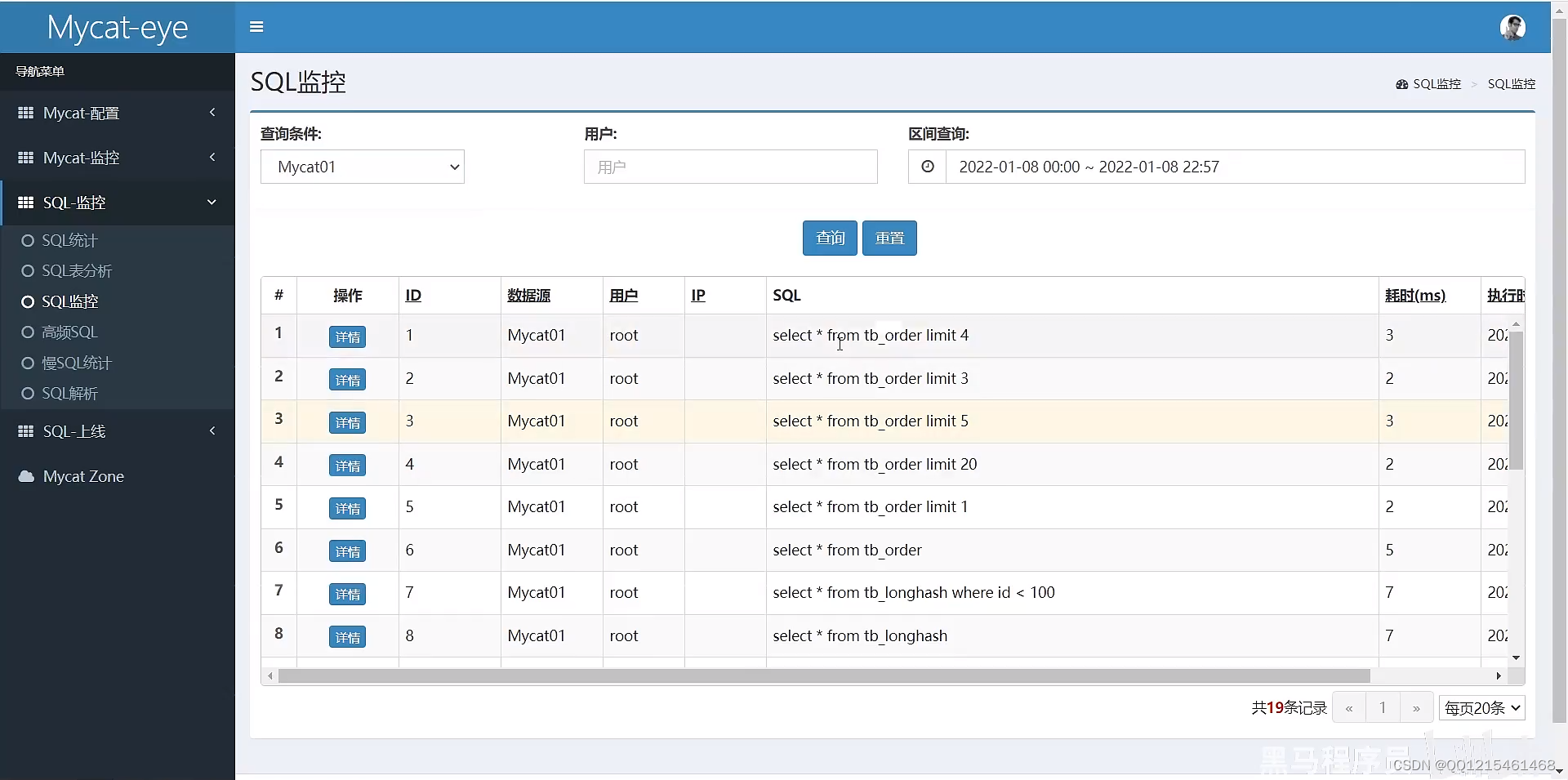
四、读写分离
1.读写分离-介绍
-
介绍
读写分离,简单地说是把对数据库的读和写操作分开,以对应不同的数据库服务器。主数据库提供写操作,从数据库提供读操作,这样能有效地减轻单台数据库的压力。
通过MyCat即可轻易实现上述功能,不仅可以支持MySOL,也可以支持Oracle和SQL Server。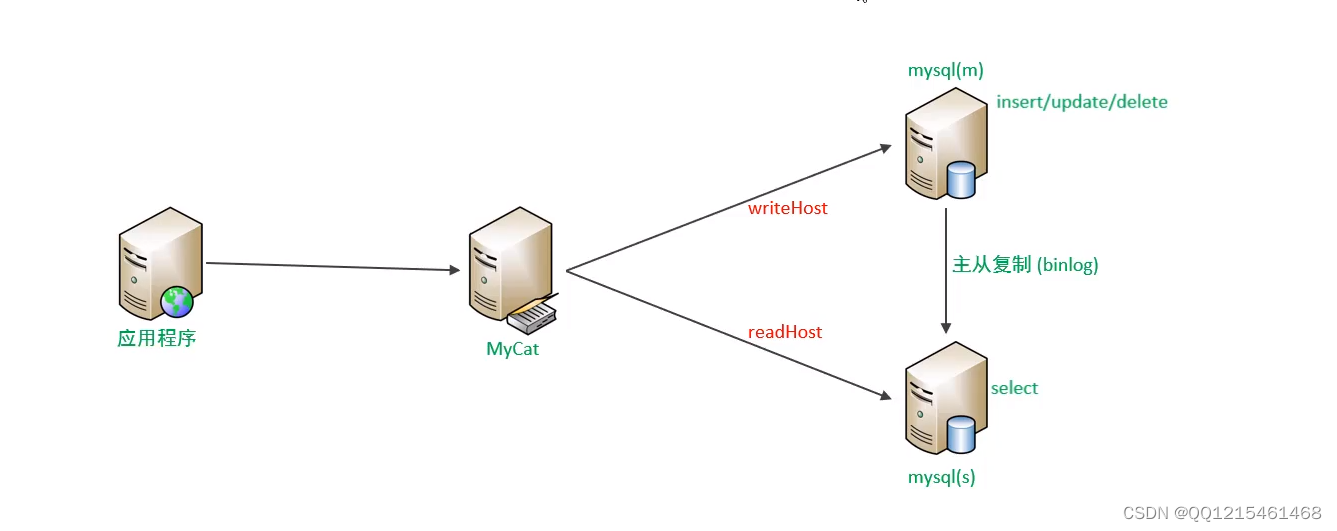
2.读写分离-一主一从准备
-
一主一从准备
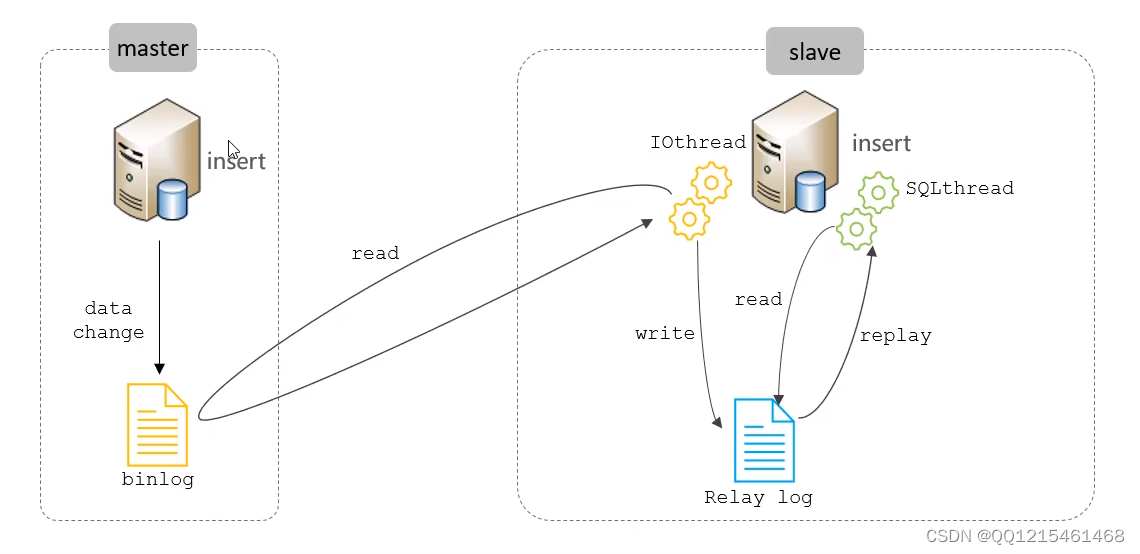
原理
MySQL的主从复制,是基于二进制日志(binlog)实现的。
环境准备主机 角色 用户名 密码 192.168.3.211 master root 1234 192.168.3.212 slave root 1234 主从复制的搭建,可以参考前面讲解的步骤操作#登录从库 mysql -uroot -p1234 #查看当前从库的状态(Slave_IO_Running和Slave_SQL_Running为Yes说明当前主从复制是正常的) show slave status\G;
3.读写分离-一主一从读写分离
-
一主一从读写分离
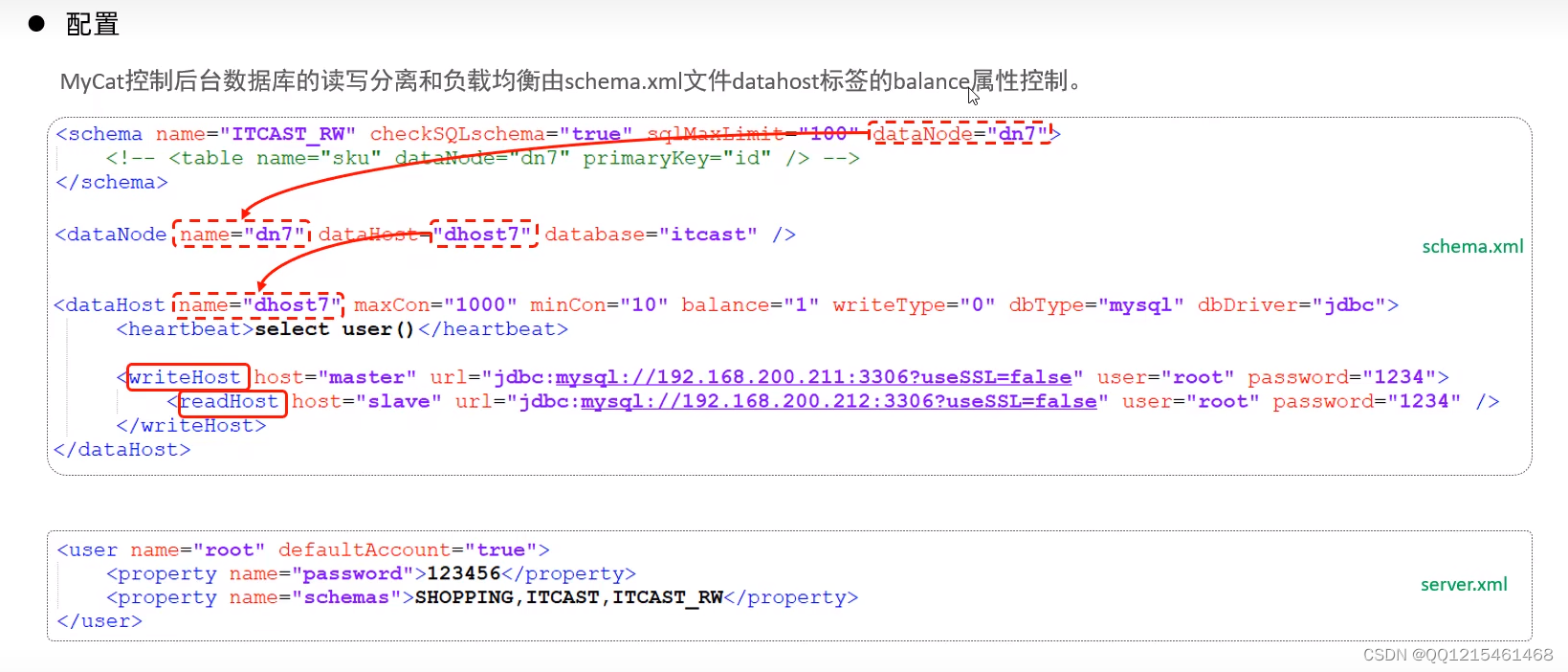
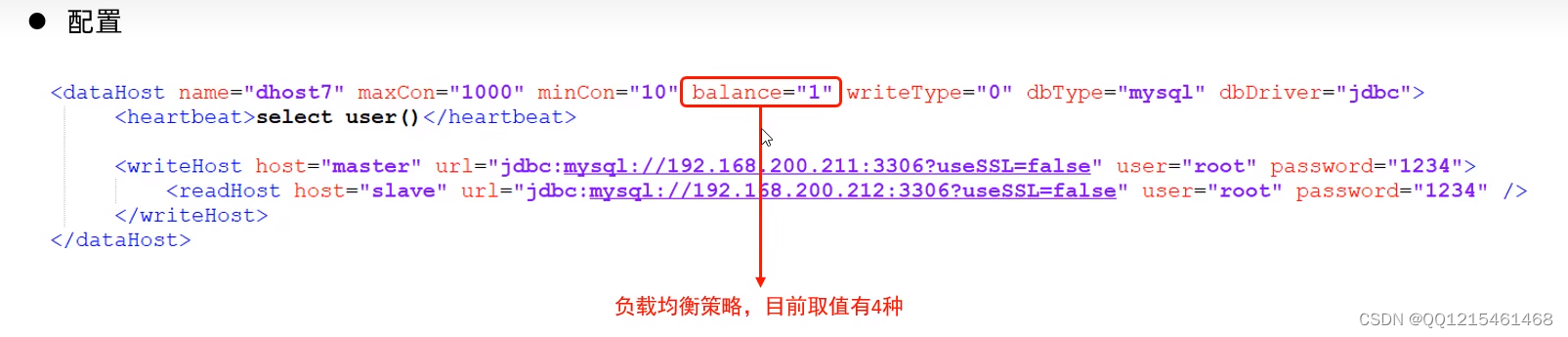
参数值 含义 0 不开启读写分离机制,所有读操作都发送到当前可用的writeHost上 1 全部的readHost与备用的writeHost 都参与select 语句的负载均衡(主要针对于双主双从模式) 2 所有的读写操作都随机在writeHost,readHost上分发 3 所有的读请求随机分发到writeHost对应的readHost上执行,writeHost不负担读压力 schema.xml配置文件(部分主要配置)<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <schema name="ITCAST_RW" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn7"> </schema> <dataNode name="dn7" dataHost="dhost7" database="itcast" /> <dataHost name="dhost3" maxCon="1000" minCon="10" balance="3" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="master" url="jdbc:mysql://192.168.200.211:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234"> <readHost host="slave" url="jdbc:mysql://192.168.200.212:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234"> </readHost> </writeHost> </dataHost> </mycat:schema>server.xml配置文件(部分主要配置)<user name="root" defaultAccount="true"> <property name="password">123456</property> <property name="schemas">ITCAST_RW</property> </user>连接Mycat,并在Mycat中执行DML、DQL查看是否能够进行读写分离。
问题:主节点Master宕机之后,业务系统就只能够读,而不能写入数据了
4.读写分离-双主双从介绍
-
双主双从介绍
一个主机 Master1 用于处理所有写请求,它的从机 Slave1 和另一台主机 Master2还有它的从机 Slave2 负责所有读请求。当Master1主机宕机后,Master2 主机负责写请求,Master1、Master2 互为备机。架构图如下:
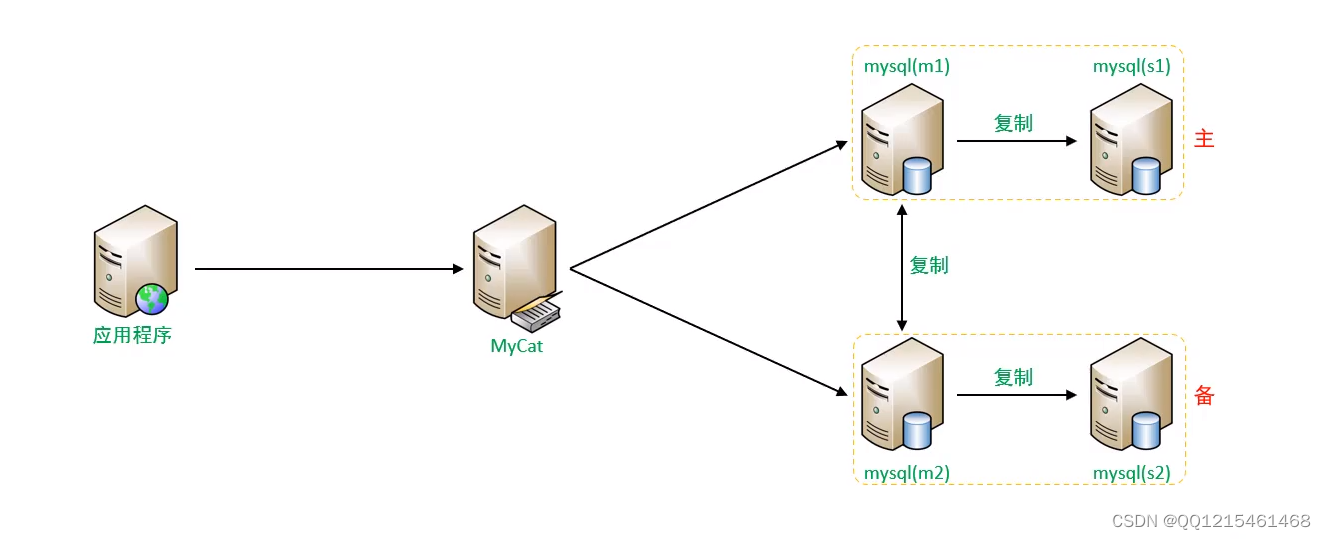
5.读写分离-双主双从搭建
-
双主双从搭建
主备工作我们需要准备5台服务器,具体的服务器及软件安装情况如下:
编号 IP 预装软件 角色 1 192.168.200.210 MyCat、MySQL MyCat中间件服务器 2 192.168.200.211 MySQL Master1 3 192.168.200.212 MySQL Slave1 4 192.168.200.213 MySQL Master2 5 192.168.200.214 MySQL Slave2 关闭以上所有服务器的防火墙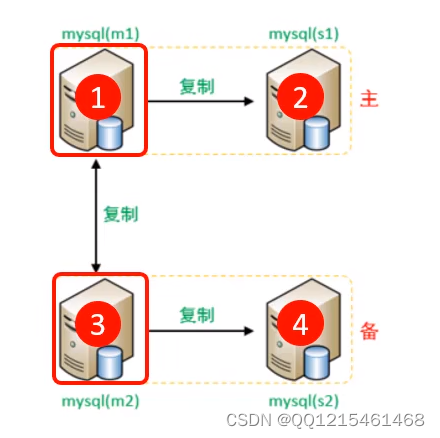
双主双从搭建一、主库配置(Master1-192.168.200.211)
1.修改配置文件 /etc/my.cnf
#mysql服务ID,保证整个集群环境中唯一,取值范围: 1 - 2的32次方-1,默认为1 server-id=1 #指定同步的数据库 binlog-do-db=db01 binlog-do-db=db02 binlog-do-db=db03 #在作为从数据库的时候,有写入操作也要更新二进制日志文件 log-slave-updates2.重启MySQL服务
systemctl restart mysqld二、主库配置(Master2-192.168.200.213)
1.修改配置文件 /etc/my.cnf
#mysql服务ID,保证整个集群环境中唯一,取值范围: 1 - 2的32次方-1,默认为1 server-id=3 #指定同步的数据库 binlog-do-db=db01 binlog-do-db=db02 binlog-do-db=db03 #在作为从数据库的时候,有写入操作也要更新二进制日志文件 log-slave-updates2.重启MySQL服务
systemctl restart mysqld三、两台主库创建账户并授权
1.创建账户并授权
#创建itcast用户,并设置密码,该用户可在任意主机连接该MySQL服务 CREATE USER 'itcast'@'%' IDENTIFIED WITH mysql_native_password BY 'Root@123456'; #为itcast用户分配主从复制权限 GRANT REPLICATION SLAVE ON *.* TO 'itcast'@'%';2.通过指令,查看两台主库的二进制日志坐标
show master status;四、从库配置(Slave1-192.168.200.212)
1.修改配置文件 /etc/my.cnf
#mysql服务ID,保证整个集群环境中唯一,取值范围: 1 - 2的32次方-1,默认为1 server-id=22.重启MySQL服务
systemctl restart mysqld五、从库配置(Slave1-192.168.200.214)
1.修改配置文件 /etc/my.cnf
#mysql服务ID,保证整个集群环境中唯一,取值范围: 1 - 2的32次方-1,默认为1 server-id=42.重启MySQL服务
systemctl restart mysqld六、两台从库配置关联的主库
CHANGE MASTER TO MASTER_HOST='',MASTER_USER='',MASTER_PASSWORD='',MASTER_LOG_FILE='',MASTER_LOG_POS='';例子CHANGE MASTER TO MASTER_HOST='192.168.200.211',MASTER_USER='itcast',MASTER_PASSWORD='Root@123456',MASTER_LOG_FILE='binlog.000001',MASTER_LOG_POS='156';需要注意slave1对应的是master1,slave2对应的是master2。MASTER_LOG_FILE='binlog.000001',MASTER_LOG_POS='156'这两个参数可以通过主库执行show master status;命令进行查看启动两台从库主从复制,查看从库状态
start slave; show slave status\G;七、两台主库相互复制
Master2 复制 Master1,Master1 复制 Master2
CHANGE MASTER TO MASTER_HOST='',MASTER_USER='',MASTER_PASSWORD='',MASTER_LOG_FILE='',MASTER_LOG_POS='';启动两台从库主从复制,查看从库状态
start slave; show slave status\G;八、测试
分别在两台主库Master1、Master2上执行DDL、DML语句,查看涉及到的数据库服务器的数据同步情况。
6.读写分离-双主双从读写分离
-
双主双从读写分离
配置
MyCat控制后台数据库的读写分离和负载均衡由schema.xml文件datahost标签的balance属性控制,通过writeType及switchType来完成失败自动切换的。
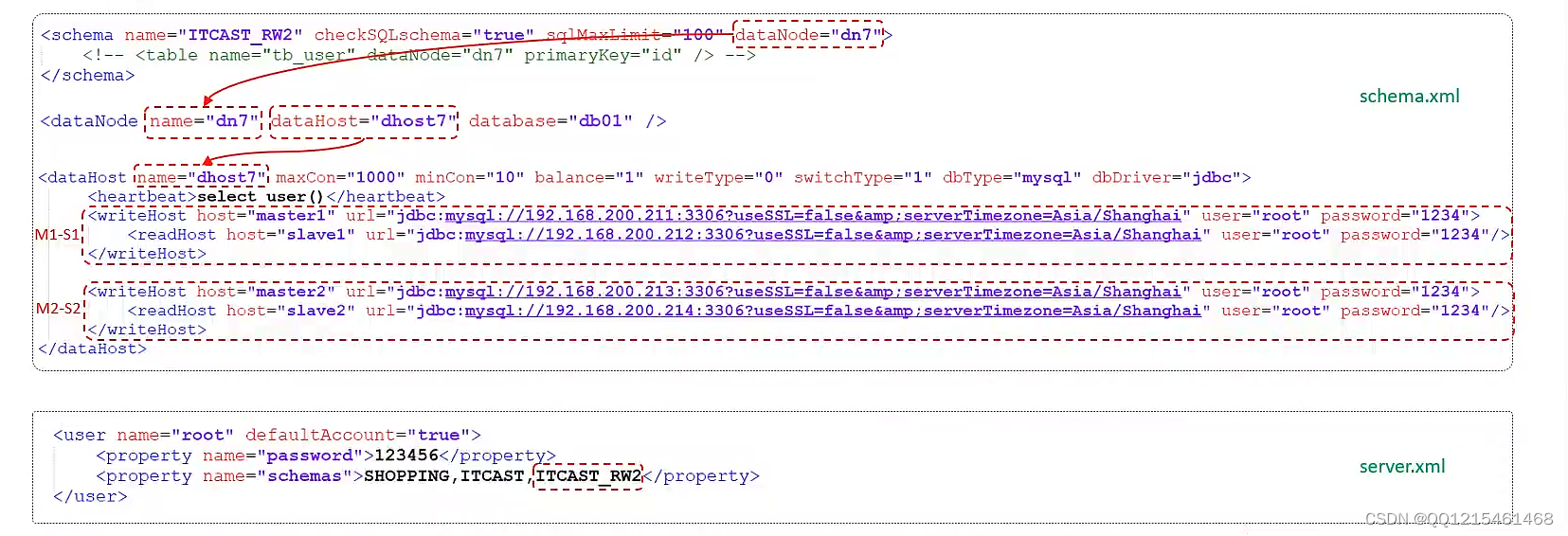

balance="1"代表全部的 readHost 与 stand by writeHost 参与 select 语句的负载均衡,简单的说,当双主双从模式(M1->S1, M2->S2,并 M1 与 M2 互为主备),正常情况下,M2,S1,S2 都参与 select 语句的负载均衡;writeType
0:写操作都转发到第1台writeHost,writeHost1挂了,会切换到writeHost2上;
1:所有的写操作都随机地发送到配置的writeHost上;switchType
-1:不自动切换
1:自动切换schema.xml配置文件(部分主要配置)<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <schema name="ITCAST_RW2" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn7"></schema> <dataNode name="dn7" dataHost="dhost7" database="db01" /> <dataHost name="dhost3" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="master1" url="jdbc:mysql://192.168.200.211:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234"> <readHost host="slave1" url="jdbc:mysql://192.168.200.212:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234"></readHost> </writeHost> <writeHost host="master2" url="jdbc:mysql://192.168.200.213:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234"> <readHost host="slave2" url="jdbc:mysql://192.168.200.214:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234"></readHost> </writeHost> </dataHost> </mycat:schema>server.xml配置文件(部分主要配置)<user name="root" defaultAccount="true"> <property name="password">123456</property> <property name="schemas">ITCAST_RW2</property> </user>测试
登录MyCat,测试查询及更新操作,判定是否能够进行读写分离,以及读写分离的策略是否正确。
当主库挂掉一个之后,是否能够自动切换。

此文档来源于网络,如有侵权,请联系删除!