关于2D车道线检测算法的总结主要分为两类:一类基于语义分割来做,一类基于anchor和关键点来做。还有基于曲线方程来做的,但是落地的话还是上面两种为主。
一、基于语义分割的车道线检测算法
1.LaneNet
论文创新点:
1.将车道线检测看作一个实例分割问题,在网络里除了语义分割头,还有一个embedding头用来聚类实例的。
2.通过embedding向量和聚类的后处理,使得模型可以检测很多车道线(没有先验个数限制)。

模型结构
backbone+2个head,一个是语义分割头,一个是聚类头。根据语义分割得到哪些像素是车道线,然后再根据聚类头的向量,使用聚类算法对车道线像素进行实例化。得到实例化后进行拟合。论文里使用的聚类算法是meanshift,后续开源代码里有用DBSCAN的,但是他们的耗时都很多,无法满足上车需求。
LOSS的使用
为了均衡正负样本比例,语义分割loss使用的加权交叉熵损失计算。
聚类分支loss使用的var loss和dist loss组成,var使得同类之间靠拢,dist使得不同类的中心相互远离彼此。
2.SCNN
传统的网络是在层与层之间进行卷积,长宽同样的进行信息聚集,并没有很好的利用车道线的形状先验。本论文提出了Spatial CNN,其在一层特征图上按照上下左右的方向有顺序的进行切片卷积,从而使网络可以更好地提取车道线特征。
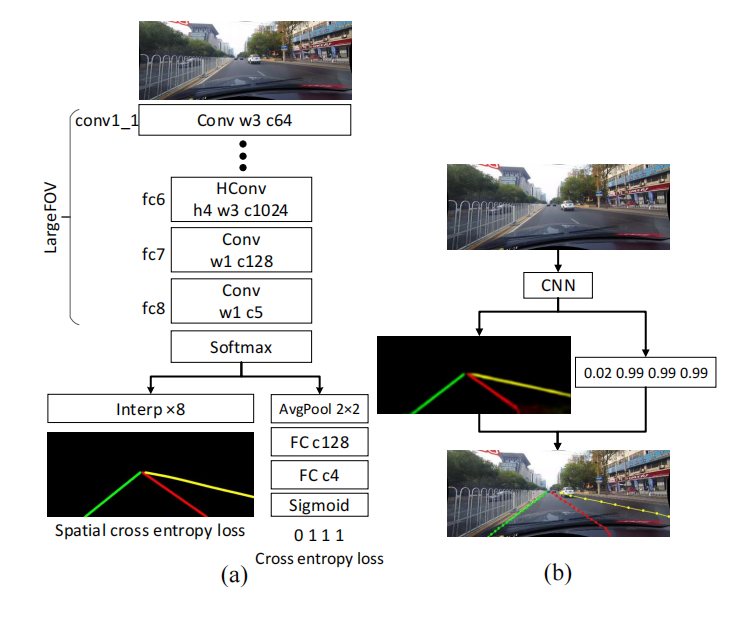
上图中(a)是训练流程,(b)是推理流程。看到论文里假设最多有四条车道线。对于存在值大于0.5的每个车道标记,我们每隔20行搜索相应的概率图,以获得响应最高的位置。然后通过三次样条函数连接这些位置,这是最终的预测。
代码分析
def message_passing_forward(self, x):
self.message_passing = nn.ModuleList()
# 从上到下,使用 1*8的卷积。
self.message_passing.add_module('up_down', nn.Conv2d(128, 128, (1, ms_ks), padding=(0, ms_ks // 2), bias=False))
# 从下到上也是 1*8
self.message_passing.add_module('down_up', nn.Conv2d(128, 128, (1, ms_ks), padding=(0, ms_ks // 2), bias=False))
self.message_passing.add_module('left_right',
nn.Conv2d(128, 128, (ms_ks, 1), padding=(ms_ks // 2, 0), bias=False))
self.message_passing.add_module('right_left',
nn.Conv2d(128, 128, (ms_ks, 1), padding=(ms_ks // 2, 0), bias=False))
Vertical = [True, True, False, False]
Reverse = [False, True, False, True]
# 对四个方向进行遍历
for ms_conv, v, r in zip(self.message_passing, Vertical, Reverse):
x = self.message_passing_once(x, ms_conv, v, r)
return x
def message_passing_once(self, x, conv, vertical=True, reverse=False):
"""
Argument:
----------
x: input tensor
vertical: vertical message passing or horizontal
reverse: False for up-down or left-right, True for down-up or right-left
"""
nB, C, H, W = x.shape
if vertical: #如果是竖直方向,则沿着H进行切片
# 得到一个长为H的数组,里面的元素维度[B, C, 1, W]
slices = [x[:, :, i:(i + 1), :] for i in range(H)]
dim = 2
else: #如果是横向,则沿着W进行切片,得到一个长为W的数组,里面的元素维度[B, C, H, 1]
slices = [x[:, :, :, i:(i + 1)] for i in range(W)]
dim = 3
if reverse:
slices = slices[::-1]
out = [slices[0]] #第一个切片不操作
for i in range(1, len(slices)):
out.append(slices[i] + F.relu(conv(out[i - 1]))) #当前切片 等于当前值+前一个切片卷积完的结果
if reverse:
out = out[::-1]
return torch.cat(out, dim=dim)通过代码分析我们看到,其对切片进行遍历,当前切片的特征是由前一层切片卷积后+当前切片的原始特征得到的,所以是顺序执行的,这样的计算非常耗时。于是引出下一篇文章RESA。
3.RESA
(91条消息) RESA车道线路沿检测_CVplayer111的博客-CSDN博客
这个代码里RESA采用的并行计算,所有切片同时+前面的切片卷积激活结果。这样直接x[...,idx,.]就行,不用像SCNN里生成切片数组。一个一个顺序进行。同时还提出了双边上采样结构,upsample双线性插值得到粗粒度特征,转置卷积得到细粒度特征。
4.LaneAF
(91条消息) LaneAF论文解读和代码讲解_CVplayer111的博客-CSDN博客
将传统聚类后处理去掉,根据模型预测的方向向量来实例化像素点,生成的一维HAF进行行像素分类,然后根据二维的VAF进行不同行之间的关联。
二、基于anchor和关键点的车道线检测算法
1. UFSA
首先论文分析了当前基于语义分割算法的痛点,每个点都预测分辨率太大,耗时严重导致速度慢,同时其感受野有限,只有局部的感受野,对于车道线模糊,遮挡问题不好。
论文将车道线检测问题转化为Row anchors上的分类问题,Row anchors是预定的行位置,论文里是18个行anchor。每一行都被划分为许多单元格,车道线检测就变为在行anchor上选择单元格。
其中h表示行数,w表示每行多少个网格,都是人为设定的。远小于原图像的H*W,所以计算效率大大提升。比如我们设定网络可以检测c个车道线,那么语义分割的复杂度是 (c+1)*H*W,而我们的是(w+1)*c*h.
损失函数方面,加入了结构损失,用相邻行差值来约束车道线的光滑性,用二阶差分来约束车道线是直线。 
网络结构如图所示,加入了语义分割的辅助分支,在推理的时候去掉,主要为了实现主干网络全局和局部信息的聚合。骨干网络后加入FC层,然后再reshape成h*w的形状进行预测。
算法缺陷:只能预测固定的数量车道线,同时只能检测纵向的车道线,其他方向就不行,因为结构损失约束。
2.FOLOLane
是一种基于关键点检测的方法,将车道线检测看作局部的几何建模。论文指出以往的聚类后处理使得推理非常复杂,同时像素级的曲线拟合是冗余的和有噪声的。
图片经过CNN处理,得到四个特征图,一个heatmap用来预测关键点出现的概率,其余三个用来预测当前点,上面的,下面的三个关键点的x偏移。在训练时,将每个车道线标注的点插值成连续的像素点,使用未归一化的高斯核对这些点周围的像素点处理。计算focalloss时,只有等于1的才是正样本。此时把图像沿着高度方向等间距画线,距离为固定值y,,等分线与刚才插值得到的像素点的交点称为关键点,对于这个关键点来说,模型预测三个偏移值,一个是这个关键点的偏移,另外两个是与其间隔y的两个点的偏移。已知当前关键点,就可以求出上下两个关键点。上下关键点偏移的loss计算是:
相当于根据P关键点的坐标+与其预测的间隔y的两个关键点偏移,得到这两个点的预测坐标,求预测坐标与GT坐标的x偏移。对于当前点的x偏移loss公式如下: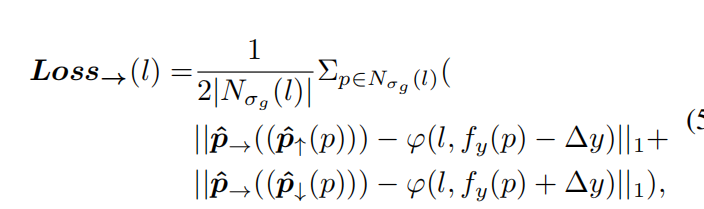
这个我不太懂啥意思,到时候看代码。
有了上面的预测结果,如何来解码全局的车道线结构。论文中给了两种方法,一种是精细的计算方法,耗时,一种是简单的计算方法。我主要介绍简单的计算方法。
1.先以等间距y画好线,所有线上具有最高响应的点组成current key_point
2.根据三个偏移计算相关点
3.current key_point集合内部建立相关性,根据当前行关键点预测的上下行的关键点与上下行的current key_point求距离,离的最近就是关联的。
4.从具有最多current key_point的行开始,根据3建立相关性,不断的向两边关联,组成一个group,然后再根据x横向偏移对关键点的x坐标进行修正。






![[笔记]初识Burpsuit](https://img-blog.csdnimg.cn/65663eae445a4635ba70dad540104f5a.png)