本篇博客会讲解力扣“232. 用栈实现队列”的解题思路,这是题目链接。
先来审题:
以下是输出示例:

以下是提示和进阶:

栈是一种后进先出的数据结构,而队列是一种先进先出的数据结构,如何用栈实现队列呢?
整体的思路是,使用2个栈,分别是pushst和popst。考虑模拟实现队列后,入队列和出队列分别应该如何操作:
- 入队列:直接把数据插入到pushst中。
- 出队列:若popst为空,则把pushst中的所有的数据都转移到popst中,popst再出栈;若popst非空,则直接popst出栈。
稍微模拟以下:先入[1 2 3 4 5]。
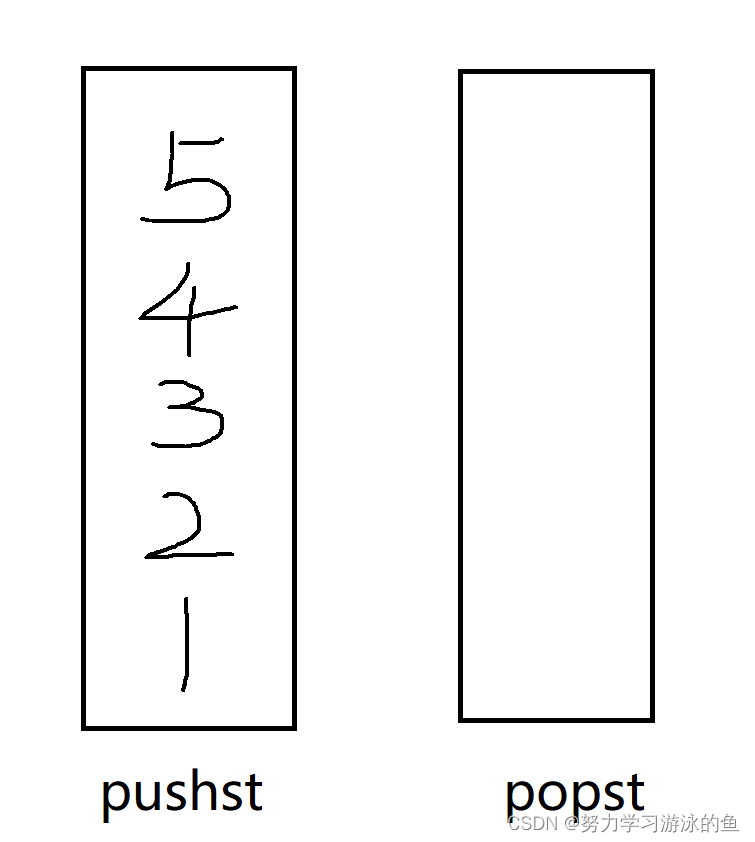
接着出队列。此时应该出1,但是1在pushst的最底下怎么办?我们的思路是:把数据转移过去。每次取pushst栈顶的元素,插入到popst中,pushst再出栈,直到pushst为空。先转移5:
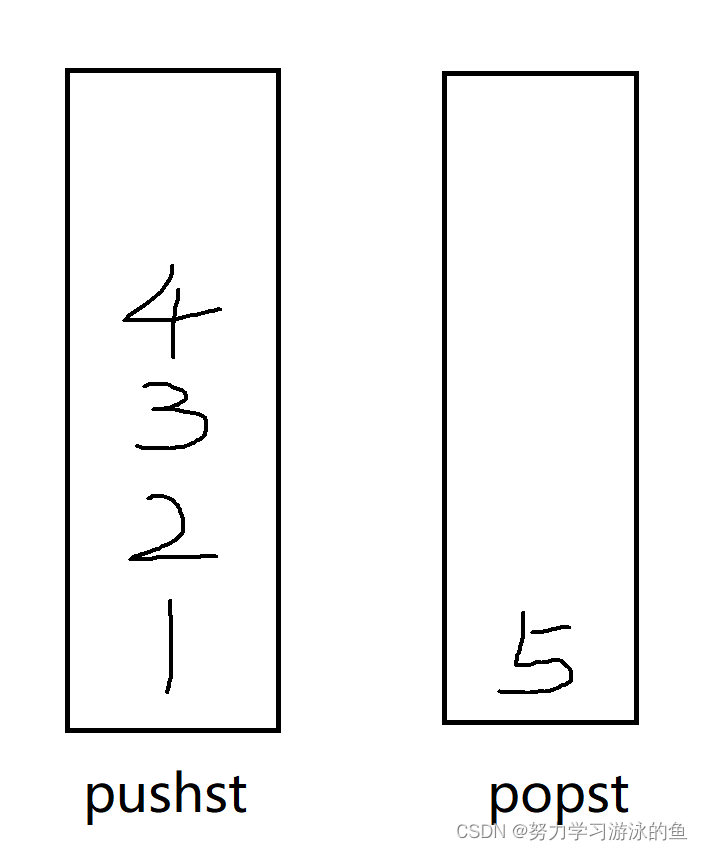
转移4:
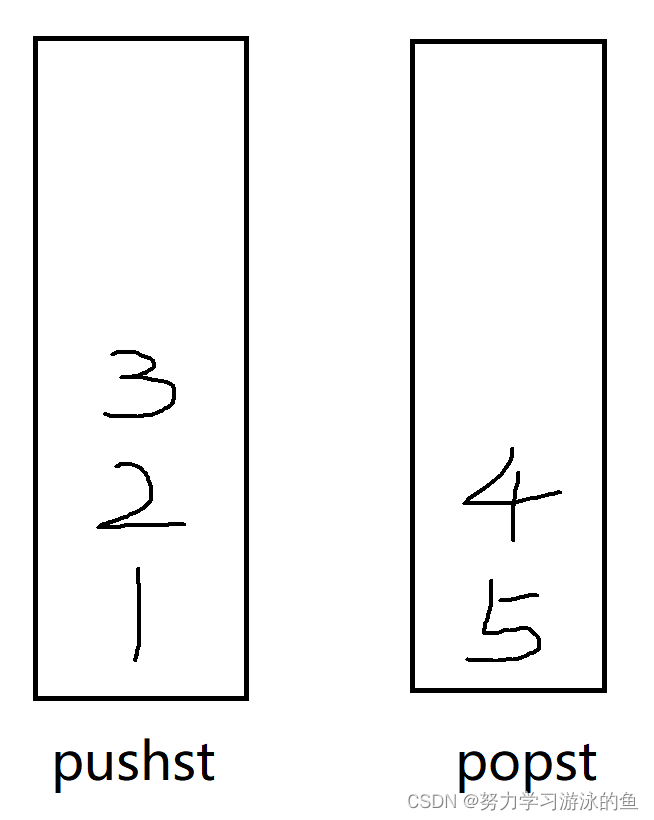
以此类推,把所有数据都转移过去:
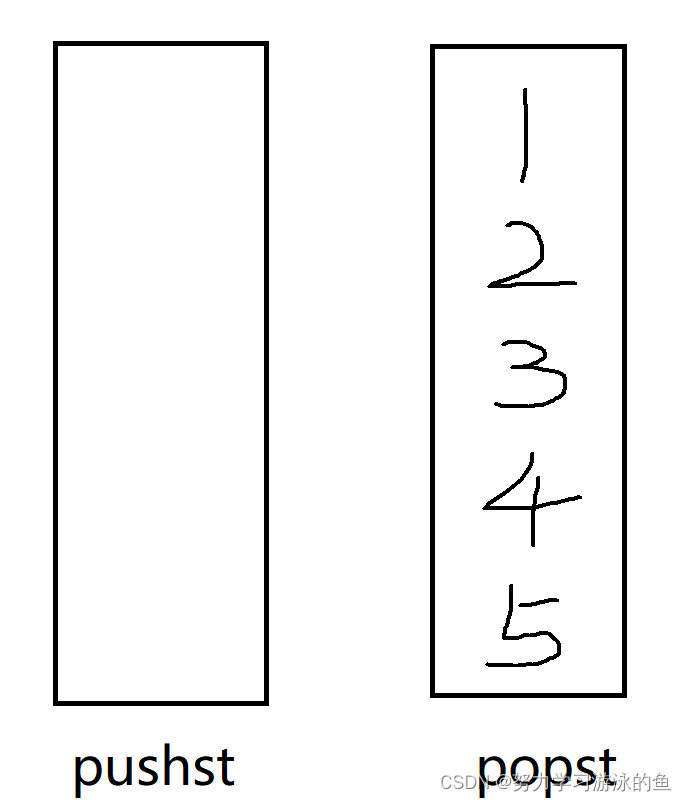
1就跑到popst的最顶上了,此时删除1就是出队列。

如果还要继续出队列呢?popst继续出栈即可,2就被删除了。
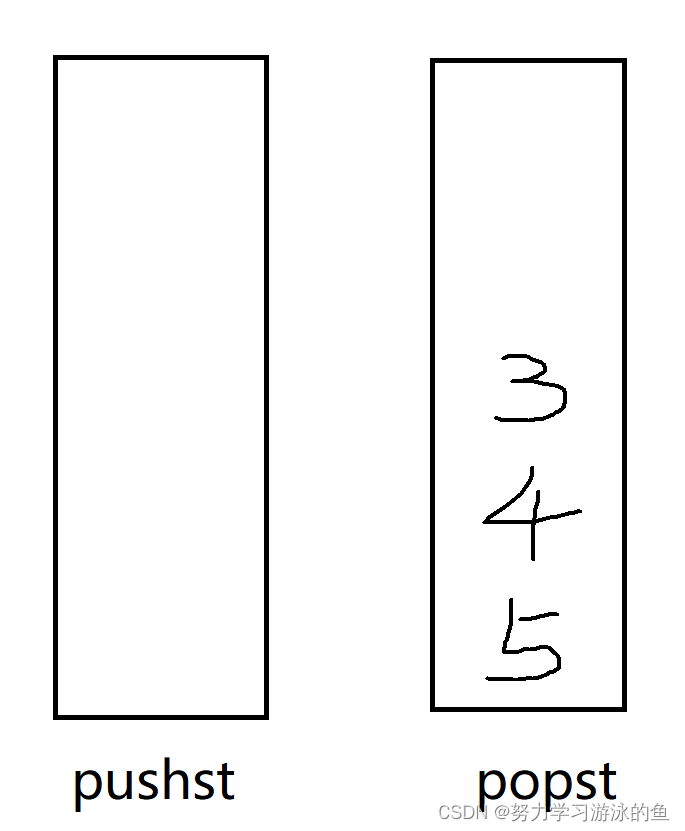
接着,假设[6 7 8]入队列,插入到pushst中:
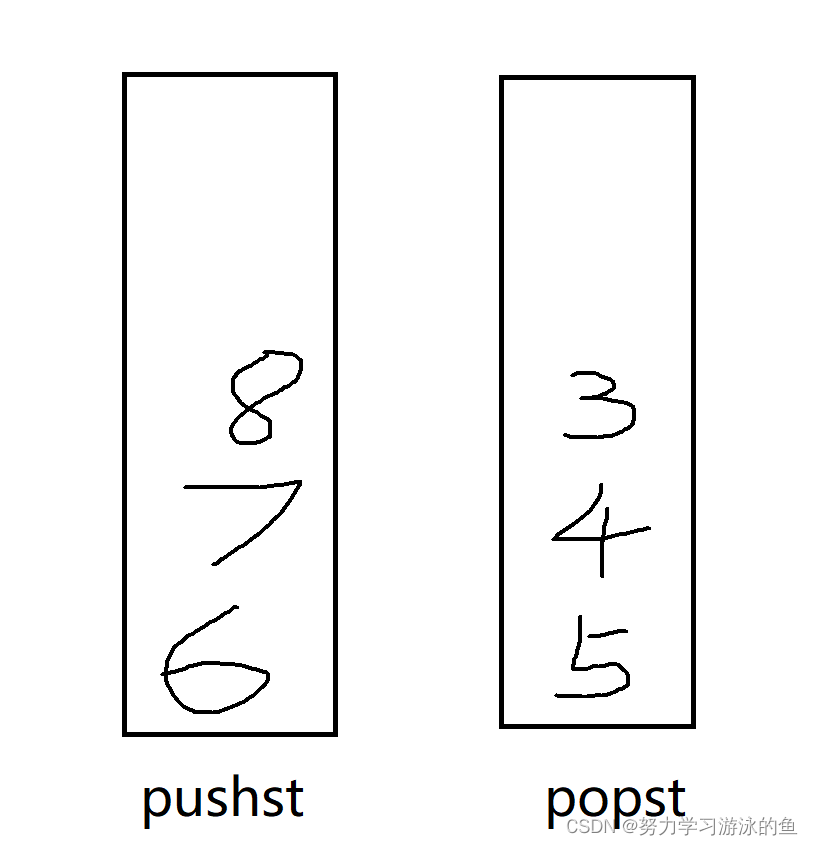
接着出队列,由于popst不为空,直接popst出栈,把3删了:
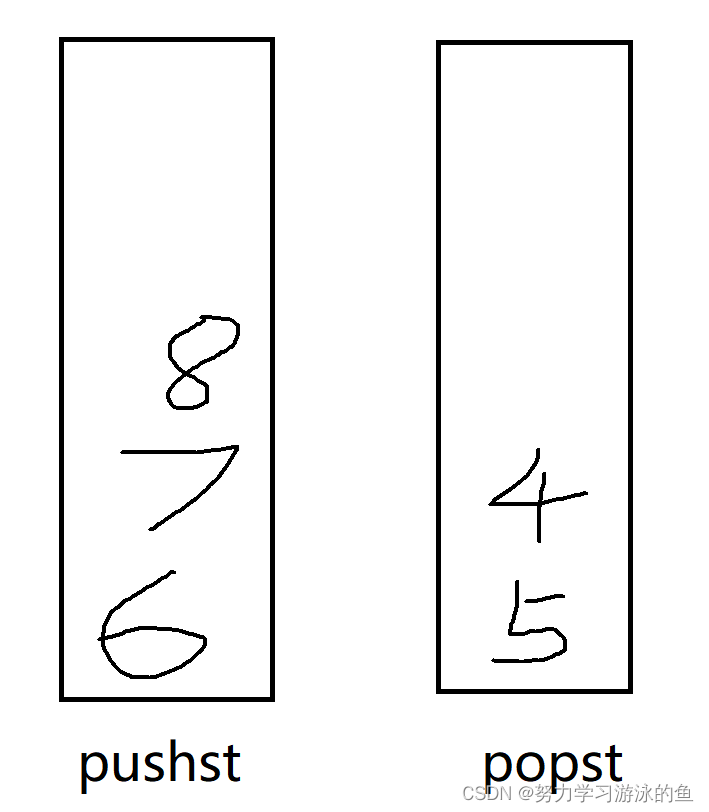
若继续出队列2次,就popst出栈2次,4、5就被删除了:
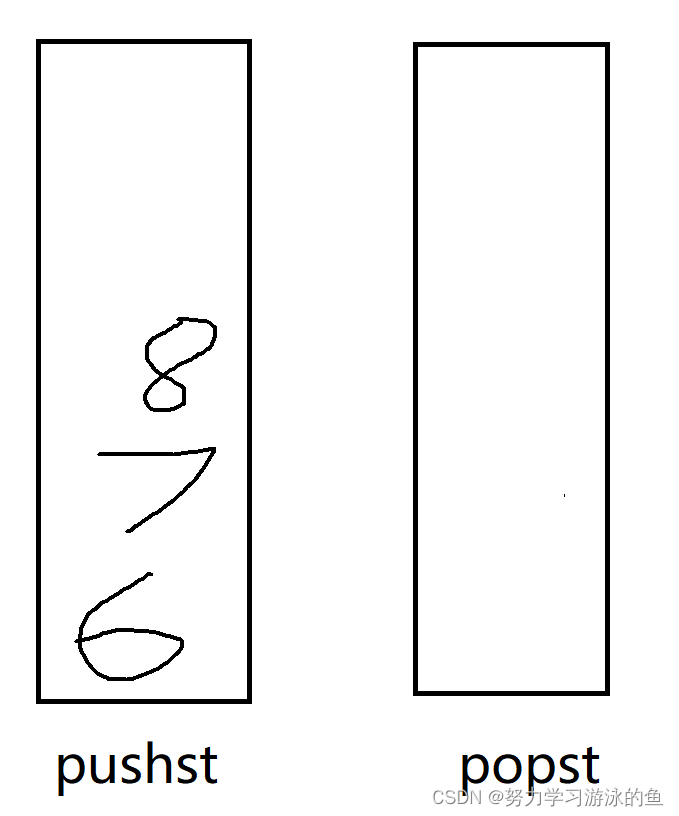
此时若继续出队列,由于popst已经为空,就需要把pushst中的数据全部转移到popst中,重复上面的步骤就行了。
下面开始实现代码:
先实现一个栈,由于本题的重点不是栈的实现,这里直接上代码。关于如何使用C语言实现栈,我会在另外一篇博客中单独讲解。
// 支持动态增长的栈
typedef int STDataType;
typedef struct Stack
{
STDataType* a;
int top; // 栈顶
int capacity; // 容量
}Stack;
// 初始化栈
void StackInit(Stack* ps);
// 入栈
void StackPush(Stack* ps, STDataType data);
// 出栈
void StackPop(Stack* ps);
// 获取栈顶元素
STDataType StackTop(Stack* ps);
// 获取栈中有效元素个数
int StackSize(Stack* ps);
// 检测栈是否为空
bool StackEmpty(Stack* ps);
// 销毁栈
void StackDestroy(Stack* ps);
void StackInit(Stack* ps)
{
assert(ps);
// 开辟4个空间
ps->a = (STDataType*)malloc(sizeof(STDataType) * 4);
if (ps->a == NULL)
{
perror("malloc fail");
return;
}
// 初始化
ps->top = 0;
ps->capacity = 4;
}
void StackPush(Stack* ps, STDataType data)
{
assert(ps);
// 检查容量
if (ps->top == ps->capacity)
{
// 扩容2倍
STDataType* tmp = (STDataType*)realloc(ps->a, sizeof(STDataType) * ps->capacity * 2);
if (tmp == NULL)
{
perror("realloc fail");
return;
}
// 扩容成功
ps->a = tmp;
ps->capacity *= 2;
}
// 数据压栈
ps->a[ps->top++] = data;
}
void StackPop(Stack* ps)
{
assert(ps);
// 检查非空
assert(!StackEmpty(ps));
ps->top--;
}
STDataType StackTop(Stack* ps)
{
assert(ps);
// 检查非空
assert(!StackEmpty(ps));
return ps->a[ps->top - 1];
}
int StackSize(Stack* ps)
{
assert(ps);
return ps->top;
}
bool StackEmpty(Stack* ps)
{
assert(ps);
return ps->top == 0;
}
void StackDestroy(Stack* ps)
{
assert(ps);
// 释放空间
free(ps->a);
ps->top = 0;
ps->capacity = 0;
}
下面实现MyQueue。结构的定义是2个栈:
typedef struct {
Stack pushst;
Stack popst;
} MyQueue;
初始化时,对2个栈分别初始化即可。
MyQueue* myQueueCreate() {
MyQueue* obj = (MyQueue*)malloc(sizeof(MyQueue));
if (obj == NULL)
{
perror("malloc fail");
return NULL;
}
// 初始化2个栈
StackInit(&obj->pushst);
StackInit(&obj->popst);
return obj;
}
入队列时,只需对pushst入栈。
void myQueuePush(MyQueue* obj, int x) {
StackPush(&obj->pushst, x);
}
接下来实现peek函数,即取队头的数据。取法非常简单,若popst为空,就把pushst中的数据全部转移到popst中,否则直接取popst的栈顶元素。严谨起见,最好断言一下队列非空。
int myQueuePeek(MyQueue* obj) {
assert(!myQueueEmpty(obj));
if (StackEmpty(&obj->popst))
{
// popst为空,把pushst中的数据插入到popst中
while (!StackEmpty(&obj->pushst))
{
// 转移数据
StackPush(&obj->popst, StackTop(&obj->pushst));
StackPop(&obj->pushst);
}
}
return StackTop(&obj->popst);
}
根据前面的讲解,pop的思路就是peek后(此时popst非空,若空,pushst中的数据就会被全部转移到popst中),popst再出栈。严谨起见,记得断言队列非空。
int myQueuePop(MyQueue* obj) {
assert(!myQueueEmpty(obj));
int ret = myQueuePeek(obj);
// 此时popst不为空
StackPop(&obj->popst);
return ret;
}
若2个栈都为空,则队列为空。
bool myQueueEmpty(MyQueue* obj) {
return StackEmpty(&obj->pushst) && StackEmpty(&obj->popst);
}
销毁时,分别销毁2个栈,再销毁整体。
void myQueueFree(MyQueue* obj) {
// 销毁2个栈
StackDestroy(&obj->pushst);
StackDestroy(&obj->popst);
free(obj);
obj = NULL;
}
以下是完整的代码:
// 支持动态增长的栈
typedef int STDataType;
typedef struct Stack
{
STDataType* a;
int top; // 栈顶
int capacity; // 容量
}Stack;
// 初始化栈
void StackInit(Stack* ps);
// 入栈
void StackPush(Stack* ps, STDataType data);
// 出栈
void StackPop(Stack* ps);
// 获取栈顶元素
STDataType StackTop(Stack* ps);
// 获取栈中有效元素个数
int StackSize(Stack* ps);
// 检测栈是否为空
bool StackEmpty(Stack* ps);
// 销毁栈
void StackDestroy(Stack* ps);
void StackInit(Stack* ps)
{
assert(ps);
// 开辟4个空间
ps->a = (STDataType*)malloc(sizeof(STDataType) * 4);
if (ps->a == NULL)
{
perror("malloc fail");
return;
}
// 初始化
ps->top = 0;
ps->capacity = 4;
}
void StackPush(Stack* ps, STDataType data)
{
assert(ps);
// 检查容量
if (ps->top == ps->capacity)
{
// 扩容2倍
STDataType* tmp = (STDataType*)realloc(ps->a, sizeof(STDataType) * ps->capacity * 2);
if (tmp == NULL)
{
perror("realloc fail");
return;
}
// 扩容成功
ps->a = tmp;
ps->capacity *= 2;
}
// 数据压栈
ps->a[ps->top++] = data;
}
void StackPop(Stack* ps)
{
assert(ps);
// 检查非空
assert(!StackEmpty(ps));
ps->top--;
}
STDataType StackTop(Stack* ps)
{
assert(ps);
// 检查非空
assert(!StackEmpty(ps));
return ps->a[ps->top - 1];
}
int StackSize(Stack* ps)
{
assert(ps);
return ps->top;
}
bool StackEmpty(Stack* ps)
{
assert(ps);
return ps->top == 0;
}
void StackDestroy(Stack* ps)
{
assert(ps);
// 释放空间
free(ps->a);
ps->top = 0;
ps->capacity = 0;
}
typedef struct {
Stack pushst;
Stack popst;
} MyQueue;
MyQueue* myQueueCreate() {
MyQueue* obj = (MyQueue*)malloc(sizeof(MyQueue));
if (obj == NULL)
{
perror("malloc fail");
return NULL;
}
// 初始化2个栈
StackInit(&obj->pushst);
StackInit(&obj->popst);
return obj;
}
void myQueuePush(MyQueue* obj, int x) {
StackPush(&obj->pushst, x);
}
bool myQueueEmpty(MyQueue* obj);
int myQueuePop(MyQueue* obj) {
assert(!myQueueEmpty(obj));
int ret = myQueuePeek(obj);
// 此时popst不为空
StackPop(&obj->popst);
return ret;
}
int myQueuePeek(MyQueue* obj) {
assert(!myQueueEmpty(obj));
if (StackEmpty(&obj->popst))
{
// popst为空,把pushst中的数据插入到popst中
while (!StackEmpty(&obj->pushst))
{
// 转移数据
StackPush(&obj->popst, StackTop(&obj->pushst));
StackPop(&obj->pushst);
}
}
return StackTop(&obj->popst);
}
bool myQueueEmpty(MyQueue* obj) {
return StackEmpty(&obj->pushst) && StackEmpty(&obj->popst);
}
void myQueueFree(MyQueue* obj) {
// 销毁2个栈
StackDestroy(&obj->pushst);
StackDestroy(&obj->popst);
free(obj);
obj = NULL;
}
通过喽。
总结
用栈实现队列的思路:
- 使用2个栈,分别是pushst和popst。
- 入队列:pushst入栈。
- 出队列:若popst未空,则先转移数据,保证popst中有数据。接着,popst出栈。
感谢大家的阅读!