文章目录
- Redis持久化
- 🙎♂️面试官:什么是Redis持久化?
- AOF日志
- AOF日志原理
- 🙎♂️面试官:AOF日志是怎么工作的/AOF写入磁盘的流程?
- 🙎♂️面试官: 刚刚说到了Redis先执行写入的命令,后写入AOF日志,你知道为什么要这样做吗?
- 写回机制
- 🙎♂️面试官:其实你上面说到的这些都与AOF写回机制有关,你了解AOF的写回机制吗?
- 重写机制
- 🙎♂️面试官:其实为了防止AOF日志越来越大,导致磁盘I/O缓慢,Redis也提供了AOF重写机制,可以简单说一说吗?
- 🙎♂️面试官:说一下重写机制的好处吧
- 🙎♂️面试官:你刚刚说到要用一个新的AOF文件,思考过为什么要用新AOF文件吗?
- AOF后台重写
- 🙎♂️面试官:重写过程为什么在后台子进程中?
- 🙎♂️面试官: 子进程的数据副本是怎么来的?
- AOF重写缓冲区
- 🙎♂️面试官:重写 AOF 日志过程中,如果主进程修改了已经存在 key-value,此时这个 key-value 数据在子进程的内存数据就跟主进程的内存数据不一致了,这时要怎么办呢?
- 🙎♂️面试官:重写AOF使用的是后台进程,永远都不会阻塞主进程吗?
- RDB快照
- 了解RDB
- 🙎♂️面试官:说一说什么是RDB快照?
- 🙎♂️面试官:如何使用RDB?
- 🙎♂️面试官:RDB快照的缺点?
- 🙎♂️面试官:执行bgsave时,Redis可以修改数据吗?
- 写时复制
- 🙎♂️面试官:写时复制技术的流程?
- 🙎♂️面试官:发生了写时复制,RDB如何保存数据?
- 混合持久化
- 🙎♂️面试官: 为什么提出混合持久化?
- 🙎♂️面试官: 混合持久化的流程?
- 大Key
- 🙎♂️面试官: 大Key对持久化的影响?
- 🙎♂️面试官:如何避免大Key的影响?
- 🙎♂️面试官:大Key的其他影响?

Redis持久化
🙎♂️面试官:什么是Redis持久化?
🙋♂答:
Redis的数据都是存储在内存中的,当Redis重启后,内存中的数据就会丢失,但是Redis实现了数据持久化的方式。主要通过AOF日志和RDB日志来实现。
AOF日志
AOF日志(Append Only File,追加写文件):将所有写操作命令记录到日志中。
AOF日志原理
🙎♂️面试官:AOF日志是怎么工作的/AOF写入磁盘的流程?
🙋♂答:
- 当Redis执行完写入的命令后,会将命令追加到server.aof_buf缓冲区中。
- 通过write() 系统调用,将 aof_buf 缓冲区的数据写入到 AOF 文件,当应用程序向文件中写入数据时,内核会先将数据复制在内核缓冲区Page Cache中,具体何时写回,主要由写回机制来决定。
🙎♂️面试官: 刚刚说到了Redis先执行写入的命令,后写入AOF日志,你知道为什么要这样做吗?
🙋♂答:
- 避免额外的检查开销,保证记录在 AOF 日志里的命令都是可执行并且正确的。
- 不会阻塞当前写操作命令的执行,因为当写操作命令执行成功后,才会将命令记录到 AOF 日志。
- 当然也存在风险,我的数据还没有写回磁盘,服务器挂掉了,数据就丢失了。同时因为要写回到磁盘,与磁盘进行I/O时,有可能会阻塞下一次的写操作。
写回机制
🙎♂️面试官:其实你上面说到的这些都与AOF写回机制有关,你了解AOF的写回机制吗?
🙋♂答:
AOF的写回机制定义了内核缓冲区的数据何时刷回到磁盘的问题。Redis提供了三种写回机制。
- Always,每次执行写操作命令后,都将AOF日志同步到硬盘。
- Always 策略可以最大程度保证数据不丢失,但是影响主进程的性能;
- Everysec,每次执行写操作命令后,先将命令写入到 AOF 文件的内核缓冲区,然后每隔一秒将缓冲区里的内容写回到硬盘;
- Everysec 策略,如果上一秒的写操作命令日志没有写回到硬盘,发生了宕机,这一秒内的数据自然也会丢失。
- No,意味着不由 Redis 控制写回硬盘的时机,转交给操作系统控制写回的时机。自身永远不会调用
fsync()函数。- 如果想要应用程序向文件写入数据后,能立马将数据同步到硬盘,就可以调用
fsync()函数,这样内核就会将内核缓冲区的数据直接写入到硬盘,等到硬盘写操作完成后,该函数才会返回。其实这三种写回机制就在控制fsync()函数的调用时机。
- 如果想要应用程序向文件写入数据后,能立马将数据同步到硬盘,就可以调用
重写机制
🙎♂️面试官:其实为了防止AOF日志越来越大,导致磁盘I/O缓慢,Redis也提供了AOF重写机制,可以简单说一说吗?
🙋♂答:
“ 重写 ”其实存在一些歧义,重写机制并不是针对原有的AOF文件进行修改,而是针对数据库中键的当前值。
当 AOF 文件的大小超过所设定的阈值后,Redis 就会启用 AOF 重写机制。AOF 重写机制是在重写时,读取当前数据库中的所有键值对,然后将每一个键值对用一条命令记录到「新的 AOF 文件」,等到全部记录完后,就将新的 AOF 文件替换掉现有的 AOF 文件。
🙎♂️面试官:说一下重写机制的好处吧
🙋♂答:
重写机制记录的是当前键值对的状态,即使某个键值对被多条命令修改,最终都是一条命令,这样就减少了AOF文件中的命令数量。
🙎♂️面试官:你刚刚说到要用一个新的AOF文件,思考过为什么要用新AOF文件吗?
🙋♂答:
主要是为了防止重写失败的情况。
如果不使用新的AOF文件,重写失败,会对原文件造成污染。
如果使用新的AOF文件,重写失败,直接删除该文件即可。
AOF后台重写
🙎♂️面试官:重写过程为什么在后台子进程中?
🙋♂答:
Redis中AOF重写过程是由后台子进程bgrewriteaof(background rewrite of Append-Only File)来完成的。
好处有两点:
- 其一是使用后台子进程不阻塞主进程;
- 其二是子进程带有父进程的数据副本,当父子进程任意一方修改了该共享内存,就会发生「写时复制」,于是父子进程就有了独立的数据副本,就不用加锁来保证数据安全,并且不会降低效率。
🙎♂️面试官: 子进程的数据副本是怎么来的?
🙋♂答:
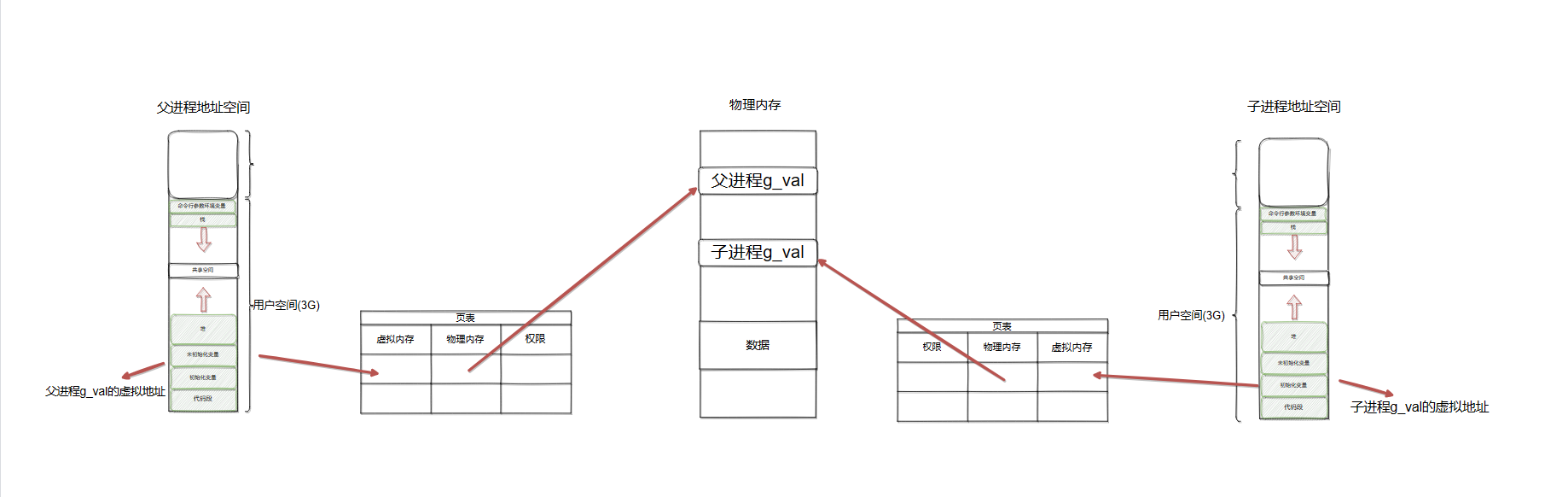
主进程在通过 fork() 系统调用生成 bgrewriteaof 子进程时,操作系统会把主进程的页表复制一份给子进程,这个页表记录着虚拟地址和物理地址映射关系,而不会复制物理内存,也就是说,两者的虚拟空间不同,但其对应的物理空间是同一个。
这样一来,子进程就共享了父进程的物理内存数据了,这样能够节约物理内存资源,页表对应的页表项的属性会标记该物理内存的权限为只读。
AOF重写缓冲区
🙎♂️面试官:重写 AOF 日志过程中,如果主进程修改了已经存在 key-value,此时这个 key-value 数据在子进程的内存数据就跟主进程的内存数据不一致了,这时要怎么办呢?
🙋♂答:
为了解决这种数据不一致问题,Redis 设置了一个 AOF 重写缓冲区,这个缓冲区在创建 bgrewriteaof 子进程之后开始使用。
在重写 AOF 期间,当 Redis 执行完一个写命令之后,它会同时将这个写命令写入到 「AOF 缓冲区」和 「AOF 重写缓冲区」。
当子进程完成 AOF 重写工作后,会向主进程发送一条信号【信号是进程间通讯的一种方式,且是异步的】
主进程收到该信号后,会调用一个信号处理函数,该函数主要做以下工作:
- 将 AOF 重写缓冲区中的所有内容追加到新的 AOF 的文件中,使得新旧两个 AOF 文件所保存的数据库状态一致;
- 新的 AOF 的文件进行改名,覆盖现有的 AOF 文件。
信号函数执行完后,主进程就可以继续像往常一样处理命令了。
🙎♂️面试官:重写AOF使用的是后台进程,永远都不会阻塞主进程吗?
🙋♂答:
重写AOF中有三个阶段会导致阻塞父进程:
- 后台重写阶段
- 创建子进程,由于要复制父进程的页表等数据结构,阻塞的时间跟页表的大小有关,页表越大,阻塞的时间也越长;
- 完成AOF重写后,会向主进程发送一条信号,主进程调用信号处理函数,该信号的信号处理函数阻塞主进程。
- 后台重写的写时复制阶段
- 创建完子进程后,如果子进程或者父进程修改了共享数据,就会发生写时复制,这期间会拷贝物理内存,如果内存越大,自然阻塞的时间也越长;
- 如果这个阶段修改的是一个 bigkey,也就是数据量比较大的 key-value 的时候,这时复制的物理内存数据的过程就会比较耗时,有阻塞主进程的风险。
- 创建完子进程后,如果子进程或者父进程修改了共享数据,就会发生写时复制,这期间会拷贝物理内存,如果内存越大,自然阻塞的时间也越长;
RDB快照
了解RDB
🙎♂️面试官:说一说什么是RDB快照?
🙋♂答:
RDB快照记录某一瞬间的内存数据,记录实际的数据。在恢复数据时,比AOF的效率更高。
🙎♂️面试官:如何使用RDB?
🙋♂答:
Redis 提供了两个命令来生成 RDB 文件,分别是 save 和 bgsave,他们的区别就在于是否在「主线程」里执行:
- 执行了 save 命令,就会在主线程生成 RDB 文件,由于和执行操作命令在同一个线程,所以如果写入 RDB 文件的时间太长,会阻塞主线程;
- 执行了 bgsave (background save)命令,会创建一个子进程来生成 RDB 文件,这样可以避免主线程的阻塞;
🙎♂️面试官:RDB快照的缺点?
🙋♂答:
Redis 的快照是全量快照,也就是说每次执行快照,都是把内存中的「所有数据」都记录到磁盘中,所以执行快照是一个比较重的操作,意味着不能频繁保存,否则可能会对Redis性能产生影响。
不能频繁保存,意味着发生故障时,丢失的数据会比AOF持久化的方式更多。
🙎♂️面试官:执行bgsave时,Redis可以修改数据吗?
🙋♂答:
执行 bgsave 过程中,Redis 依然可以继续处理操作命令的,也就是数据是能被修改的。
关键的技术就在于写时复制技术(Copy-On-Write, COW)。
写时复制
🙎♂️面试官:写时复制技术的流程?
🙋♂答:
执行 bgsave 命令的时候,会通过 fork() 创建子进程,此时子进程和父进程是共享同一片内存数据的,因为创建子进程的时候,会复制父进程的页表,但是页表指向的物理内存还是一个。
如果主线程(父进程)要修改共享数据里的某一块数据(比如键值对 A)时,就会发生写时复制,于是这块数据的物理内存就会被复制一份(键值对 A'),然后主线程在这个数据副本(键值对 A')进行修改操作。与此同时,bgsave 子进程可以继续把原来的数据(键值对 A)写入到 RDB 文件。
这样,因为只复制了页表,可以加快子进程的创建速度,避免阻塞主进程。
🙎♂️面试官:发生了写时复制,RDB如何保存数据?
🙋♂答:
bgsave 快照过程中,如果主线程修改了共享数据,发生了写时复制后,RDB 快照保存的是原本的内存数据,而主线程刚修改的数据,是没办法在这一时间写入 RDB 文件的,只能交由下一次的 bgsave 快照。
所以 Redis 在使用 bgsave 快照过程中,如果主线程修改了内存数据,不管是否是共享的内存数据,RDB 快照都无法写入主线程刚修改的数据,因为此时主线程(父进程)的内存数据和子进程的内存数据已经分离了,子进程写入到 RDB 文件的内存数据只能是原本的内存数据。
如果系统恰好在 RDB 快照文件创建完毕后崩溃了,那么 Redis 将会丢失主线程在快照期间修改的数据。
有一种极端情况,就是所有的共享内存都被修改,则此时的内存占用是原先的 2 倍。
所以,针对写操作多的场景,我们要留意下快照过程中内存的变化,防止内存被占满了。
混合持久化
🙎♂️面试官: 为什么提出混合持久化?
🙋♂答:
尽管 RDB 比 AOF 的数据恢复速度快,但是快照的频率不好把握:
- 如果频率太低,两次快照间一旦服务器发生宕机,就可能会比较多的数据丢失;
- 如果频率太高,频繁写入磁盘和创建子进程会带来额外的性能开销。
可以将 RDB 和 AOF 合体使用,这个方法是在 Redis 4.0 提出的,该方法叫混合使用 AOF 日志和内存快照,也叫混合持久化。
🙎♂️面试官: 混合持久化的流程?
🙋♂答:
混合持久化工作在 AOF 日志重写过程。
-
fork()出来的重写子进程会先将与主线程共享的内存数据以 RDB 方式写入到 AOF 文件。 -
后台子进程重写AOF期间,主线程执行的写操作命令以AOF格式写入到AOF文件中。
-
写入完成后通知主进程将新的含有 RDB 格式和 AOF 格式的 AOF 文件替换旧的的 AOF 文件。
也就是说,使用了混合持久化,AOF 文件的前半部分是 RDB 格式的全量数据,后半部分是 AOF 格式的增量数据。
这样的好处在于,重启 Redis 加载数据的时候,由于前半部分是 RDB 内容,这样加载的时候速度会很快。【RDB快照的优点】
加载完 RDB 的内容后,才会加载后半部分的 AOF 内容,这里的内容是 Redis 后台子进程重写 AOF 期间,主线程处理的操作命令,可以使得数据更少的丢失。【AOF的优点】
大Key
🙎♂️面试官: 大Key对持久化的影响?
🙋♂答:
对于AOF写回策略的影响:
- 当使用 Always 策略的时候,如果写入是一个大 Key,主线程在执行 fsync() 函数的时候,阻塞的时间会比较久,因为当写入的数据量很大的时候,数据同步到硬盘这个过程是很耗时的。
对于AOF重写机制的影响:
- 当 AOF 日志写入了很多的大 Key,AOF 日志文件的大小会很大,那么很快就会触发 AOF 重写机制。
- AOF重写机制和RDB快照中,在通过
fork()函数创建子进程的时候,虽然不会复制父进程的物理内存,但是内核会把父进程的页表复制一份给子进程,如果页表很大,那么这个复制过程是会很耗时的,那么在执行 fork 函数的时候就会发生阻塞现象。
对于写时复制机制的影响:
- 如果创建完子进程后,父进程对共享内存中的大 Key 进行了修改,那么内核就会发生写时复制,会把物理内存复制一份,由于大 Key 占用的物理内存是比较大的,那么在复制物理内存这一过程中,也是比较耗时的,于是父进程(主线程)就会发生阻塞。
🙎♂️面试官:如何避免大Key的影响?
🙋♂答:
最好在设计阶段,就把大 key 拆分成一个一个小 key。
或者,定时检查 Redis 是否存在大 key ,如果该大 key 是可以删除的,不要使用 DEL 命令删除,因为该命令删除过程会阻塞主线程,而是用 unlink 命令(Redis 4.0+)删除大 key,因为该命令的删除过程是异步的,不会阻塞主线程。
🙎♂️面试官:大Key的其他影响?
🙋♂答:
-
客户端超时阻塞。 由于 Redis 执行命令是单线程处理,然后在操作大 key 时会比较耗时,那么就会阻塞 Redis,从客户端这一视角看,就是很久很久都没有响应。
-
引发网络阻塞。 每次获取大 key 产生的网络流量较大,如果一个 key 的大小是 1 MB,每秒访问量为 1000,那么每秒会产生 1000MB 的流量,这对于普通千兆网卡的服务器来说是灾难性的。
-
阻塞工作线程。 如果使用 del 删除大 key 时,会阻塞工作线程,这样就没办法处理后续的命令。
-
内存分布不均。 集群模型在 slot 分片均匀情况下,会出现数据和查询倾斜情况,部分有大 key 的 Redis 节点占用内存多,QPS 也会比较大。
完。
参考来源:Redis设计与实现、小林Coding等博客。