ViLT论文精读笔记
- 0.摘要
- 1.引言
- 2.背景知识(小综述)
- 2.1对VLP模型分类
- 2.2模态的融合
- 2.3融合前特征的抽取
- 3.模型方法
- 3.1预训练目标函数:
- 3.1.1 Image Text Matching:
- 3.1.2 Masked Language Modeling
- 3.1.3 Masked Image Modeling
- 3.2Whole Word Masking:
- 3.3 Image Augmentation
- 4.实验部分
- 4.1数据集:4million数据集
- 4.2实验结果:
- 4.2.1分类任务:
- 4.2.2retrieval任务
- 5.结论
- 6.未来工作
0.摘要
目前的VLP(Vision-and-Language Pre-training)方法严重依赖于图像特征提取过程,其中大部分涉及区域监督(如目标检测)和卷积体系结构(如ResNet)
所以产生两个问题
- 效率/速度方面:简单地提取输入特征比多模态融合需要更多的计算
- 表达方面:当用预训练好的模型抽特征,这个模型大概率不是最优解,深度学习往往是端到端。
ViLT改善了以上2个问题
1.引言
为了输入VLP模型,我们希望图像像素变成离散的具有语义很高的特征形式从而和语言方面相符合。
在Vit出来之前,都是去做一个目标检测器的模型,这也很符合下游任务的vqa,visual grond 这些都和物体有很强烈的依赖性。
之后也有人采取了一些选择一些网络所学习到的特征图,来减小上述方法带来的巨大消耗,例如PIxed-bert
以上的方法还是避免不了一个问提:
在学术实验中,具有较重的视觉嵌入器的缺点往往被忽略,因为区域特征通常在训练时预先缓存,以减轻特征提取的负担。然而,这些限制在现实世界的应用程序中仍然很明显,因为在实际生活的查询必须经历一个缓慢的提取过程。
ViLT受启发于vit,就是vit在多模态领域上的应用,以下是三种方式的对比:
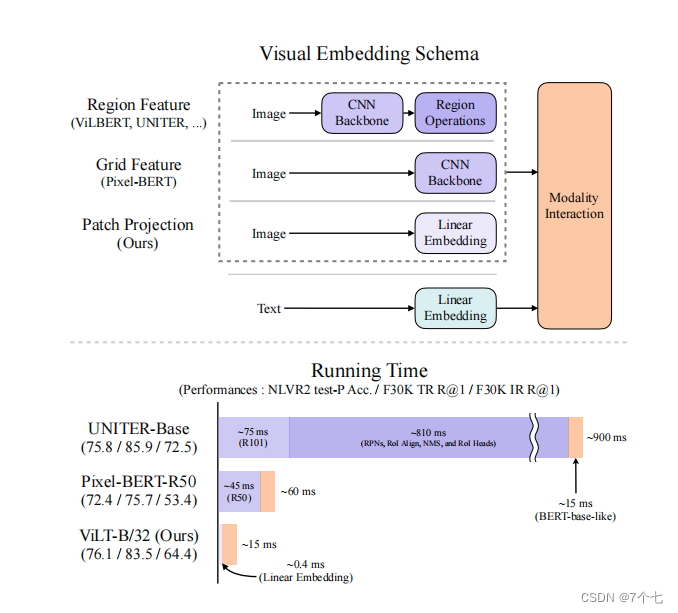
模型有3个贡献:
- 简单,消耗时间少
- 第一次在不使用区域特征或深度卷积视觉嵌入器的情况下,在VLP任务上取得了胜任的性能。
- 整个单词掩蔽和图像增强,因为在多模态任务中数据增强是一个很麻烦的事情。
2.背景知识(小综述)
2.1对VLP模型分类
分类标准:
- 两种模式在专用参数和/或计算方面是否具有均匀的表达水平
- 这两种模式是否在一个深度网络中相互作用。
分成一下4类

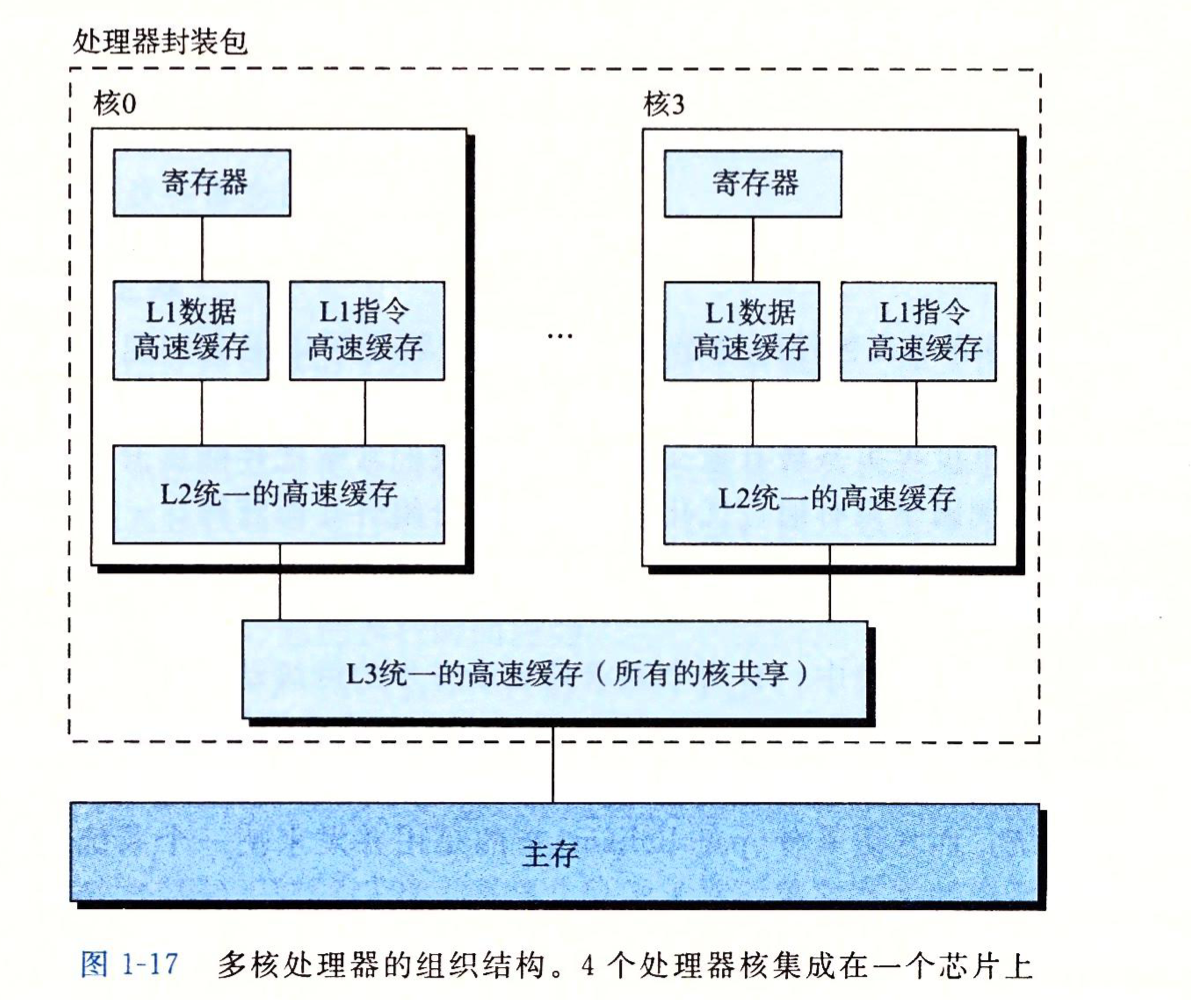
- 使用单独的嵌入器来处理图像和文本,而前者要重得多。然后,它们用简单的点积或浅层注意层表示两种模式的嵌入特征的相似性。
- 每个模式使用单独但同样昂贵的transform嵌入,例如clip
- 与具有浅交互的模型不同,最近属于图2c下的VLP模型使用transform来建模图像和文本特征的交互
- ViLT是图2d类型的第一个模型,其中原始像素的嵌入层是浅的,计算上像文本一样轻。因此,这种体系结构将大部分的计算集中在建模模态交互上
2.2模态的融合
- single-stream:图像特征和文本特征contact放入transform里,ViLT就是这样。
- dual-stream:2个模型各自对各自的模态进行处理,充分挖掘这个模态的信息,在后面的某一个时间点进行一个融合。
2.3融合前特征的抽取
主要将视觉方面的:
-
方法一:区域特征:
- Backbone:抽取特征
- rpn网络抽取roi后做一次NMS
- Roi-head
-
方法二:除了用目标检测方法外,ResNets等卷积神经网络的输出特征网格也可以作为视觉和语言预训练的视觉特征,这种方法虽然比方法一消耗小,但是性能却降低了
-
方法三:ViLT方法即The patch projection embedding
was introduced by ViT (Dosovitskiy et al., 2020) for image
classification tasks
光vit在这里应用这篇文章的创新点还在于数据增强方面,下文会提到。
3.模型方法
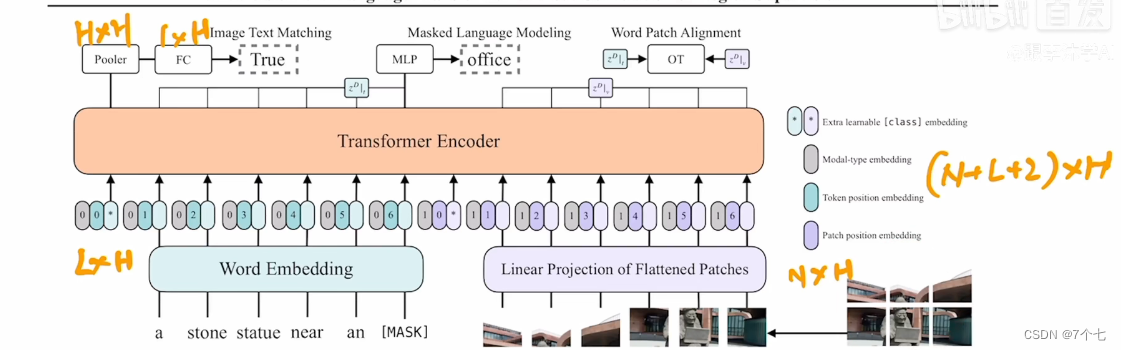
3.1预训练目标函数:
3.1.1 Image Text Matching:
本来文字和图片是配对的,现故意用0.5的概率用不同的图像随机替换匹配的图像,然后把这些放入模型进行训练,也就是个二分类问题:图像和文本是否匹配?
除此以外作者还加了另一种损失函数,word patch alignment: optimal transports
3.1.2 Masked Language Modeling
bert完形填空
3.1.3 Masked Image Modeling
注:当时mae还没有出来,所以这篇论文只是对Language 模型进行了掩码,后来就有人写了ViLBERT
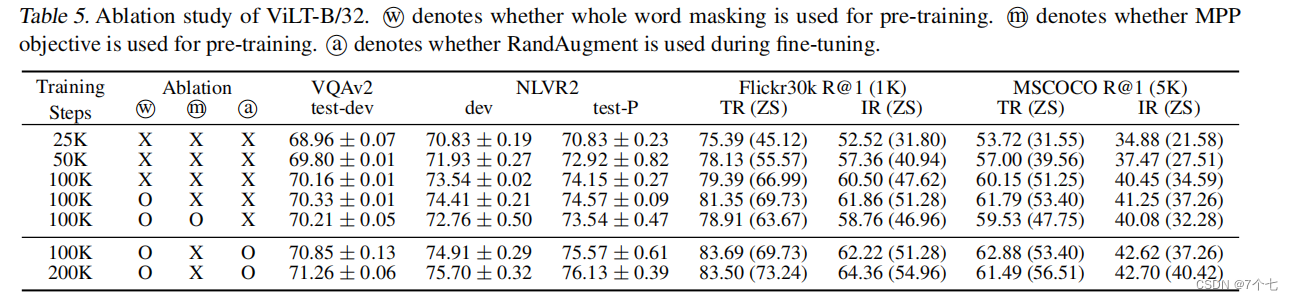
3.2Whole Word Masking:
我们假设,为了充分利用来自其他形态的信息,整个单词mask对VLP尤为重要。例如,单词“giraffe”通过预训练模型bert-base-uncased或者bpe编成三个token[“gi”,“##raf”,“##fe”]。如果不是所有的token都被mask,比如[“gi”、“[mask”、“##fe”],模型可能只依赖附近的两种token[“gi”,“##fe”]来预测隐藏的“##raf”,而不是使用图像中的信息。
所以在训练前,我们用0.15的掩码概率掩蔽整个单词。
3.3 Image Augmentation
Caching visual features限制了基于区域特征的VLP模型的使用图像增强,我们在微调过程中应用 RandAugment(Cubuk et al., 2020),使用了其所有的原始策略,除了两种策略:颜色倒置,因为文本通常也包含颜色信息,以及裁剪,因为它可以清除分散在整个图像中的小而重要的物体。
4.实验部分
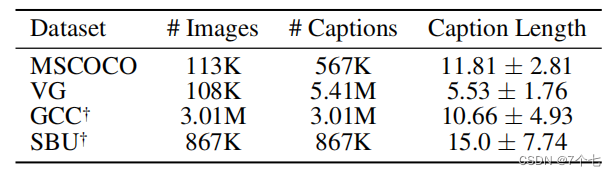
4.1数据集:4million数据集
4.2实验结果:
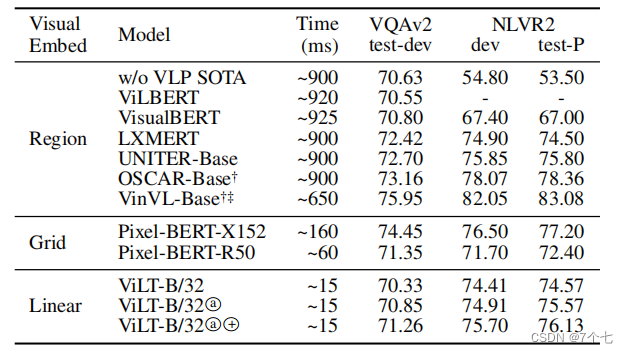
4.2.1分类任务:
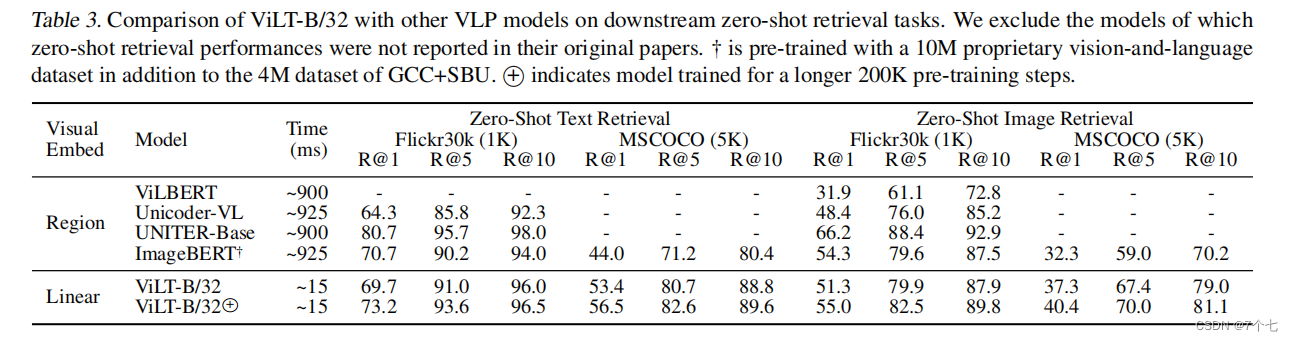
4.2.2retrieval任务
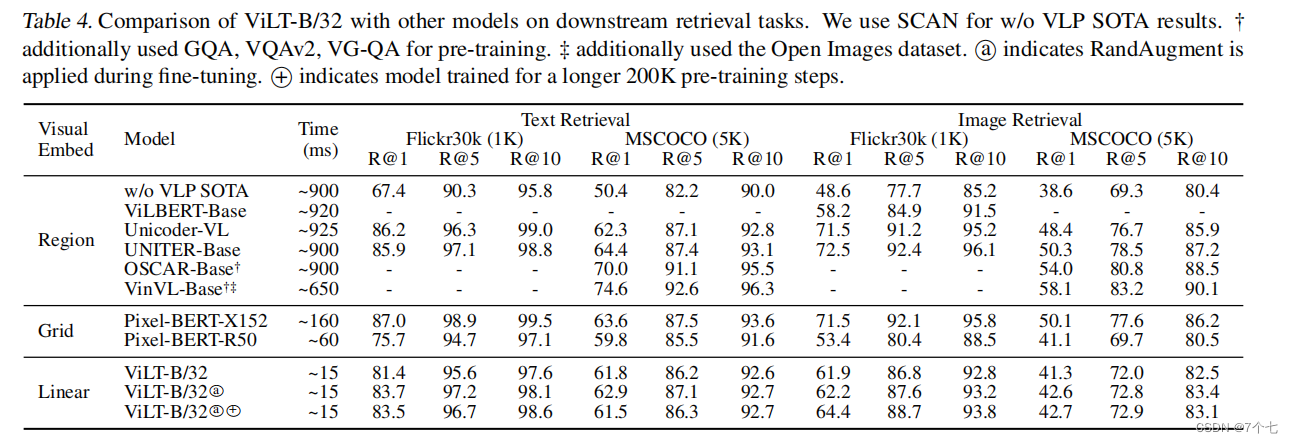
5.结论
we present a minimal VLP architecture,Vision-and-Langauge Transformer (ViLT). ViLT is competent to competitors which are heavily equipped with convolutional visual embedding networks (e.g., Faster R-CNN
and ResNets).
Although remarkable as it is, ViLT-B/32 is more of a proof of concept that efficient VLP models free of convolution and region supervision can still be competent.
6.未来工作
- 可扩展性 我们将训练更大的模型留给未来的工作,因为匹配的视觉和语言数据集仍然稀缺。
- Masked Modeling for Visual Inputs. 这个后面有人利用mae模型做了
- 数据增强策略