来源:投稿 作者:王同学
编辑:学姐
在过去的十年中,深度学习技术在计算机视觉领域中的应用逐年增加。其中当属「行人检测」和「车辆检测」最为火爆,其原因之一就是「预训练模型」的「可复用性」。
由于深度学习技术在这些应用场景上取得的卓越效果,企业现在已经开始使用深度学习来解决自己的问题。
但是,如果可用的预训练模型不适合你的应用场景,这时你们会怎么解决呢?
一个预先训练的模型能够检测到苹果,但它肯定不能区分“好苹果”和“烂苹果”,因为它从未“被教过”这样做。
那么如果遇到了这种情况「你会怎么做呢?」
“获得大量的好苹果和烂苹果的图像,并训练一个自定义检测模型!”

在创建一个好的自定义检测模型时,一个常见的挑战就是「数据问题」。深度学习模型需要大量的数据来训练它们的算法——正如我们在MaskRCNN、YOLO和UNet等模型中看到的那样,这些模型都是在现有的大型数据集COCO和ImageNet上训练得到的。
如何获取用于训练自定义检测模型的数据?
在这篇文章中,我们将探讨收集数据集来训练自定义检测模型的5种方法。
1. 公开可用的开放标记数据集
如果你比较幸运,你可能会在互联网上获得你想要的已标记数据集。以下是几个可供你选择的计算机视觉领域图像数据集。
-
「ImageNet」
ImageNet是一个计算机视觉系统识别项目, 是目前世界上图像识别最大的数据库。ImageNet是美国斯坦福的计算机科学家模拟人类的识别系统建立的。能够从图片识别物体。ImageNet数据集文档详细,有专门的团队维护,使用非常方便,在计算机视觉领域研究论文中应用非常广,几乎成为了目前深度学习图像领域算法性能检验的“标准”数据集。ImageNet中目前共有 14,197,122幅图像,总共分为21,841个类别,通常我们所说的 ImageNet 数据集其实是指 ISLVRC2012 比赛用的子数据集,其中 train 有1,281,167 张照片和标签,共1000类,大概每类1300张图片,val 有50,000副图像,每类50 个数据,test 有 100,000副图片,每类100个数据。

-
「MS COCO」
COCO数据集是微软团队发布的一个可以用来图像recognition+segmentation+captioning 数据集,该数据集收集了大量包含常见物体的日常场景图片,并提供像素级的实例标注以更精确地评估检测和分割算法的效果,致力于推动场景理解的研究进展。依托这一数据集,每年举办一次比赛,现已涵盖检测、分割、关键点识别、注释等机器视觉的中心任务,是继ImageNet Chanllenge以来最有影响力的学术竞赛之一。
COCO的检测任务共含有80个类,在2014年发布的数据规模分train/val/test分别为80k/40k/40k,学术界较为通用的划分是使用train和35k的val子集作为训练集(trainval35k),使用剩余的val作为测试集(minival),同时向官方的evaluation server提交结果(test-dev)。除此之外,COCO官方也保留一部分test数据作为比赛的评测集。
-
「Google Open Image」

Open Image是谷歌团队发布的数据集。 它包含了190万张图片上600个物体类别的16M个边界框,使其成为现有的最大的带有物体位置注释的数据集。这些方框主要是由专业注释者手工绘制的,以确保准确性和一致性。这些图像非常多样化,通常包含有多个物体的复杂场景(平均每张图像8.3个)。
-
「MNIST 手写数据集」
「MNIST 手写数据集:」该数据集总共有 70,000 张手写数字图像,是 NIST 提供的更大数据集的子集。数字已进行大小规范化,并在固定大小的图像中居中。

-
「DOTA」
DOTA是遥感航空图像检测的常用数据集,包含
2806张航空图像,尺寸大约为4k×4k,包含15个类别共计188282个实例,其中14个主类,small vehicle和large vehicle都是vehicle的子类。其标注方式为四点确定的任意形状和方向的四边形。航空图像区别于传统数据集,有其自己的特点,如:尺度变化性更大;密集的小物体检测;检测目标的不确定性。数据划分为1/6验证集,1/3测试集,1/2训练集。目前发布了训练集和验证集,图像尺寸从800×800到4000×4000不等。

2. 爬取网络图像
另一种选择是在网络上进行图像搜索,并手动选择图像进行下载。由于需要大量数据,因此此方法效率不高。
值得注意的是,网络上的图像可能受版权保护。记得在使用图像之前检查图像的版权。
或者你可以写一个程序来爬取网络并下载你想要的图像。同样需要注意检查每个图像的版权。

3. 拍摄
如果找不到所需物体的图像,可以通过拍照来收集它们。这可以手动完成,即通过自己拍摄每张图像或通过雇用其他人为你拍摄。
收集真实世界图像的另一种方法是在你的场景中安装编程的摄像机,以便自动收集图像。

4. 数据增强
我们知道深度学习模型需要大量的数据。当你只有一个小数据集时,可能不足以训练一个好的模型。在这种情况下,你可以使用数据增强来生成更多训练数据。
几何变换(如翻转、裁剪、旋转和平移)是一些常用的数据增强技术。应用图像数据增强不仅可以通过创建变体来扩展数据集,还可以减少过拟合。

左边是狗的原始图像,右边是水平翻转的图像
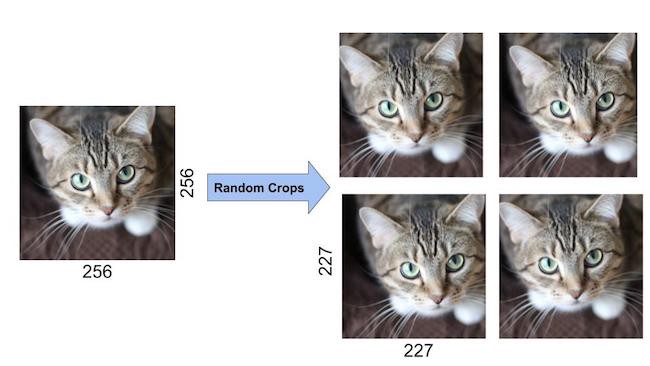
猫的原始和随机裁剪图像

猫的原始和旋转图像

网球的原始和翻译图像
5. 数据生成
有时可能无法获得真实数据。在这种情况下,可以生成合成数据来训练自定义检测模型。由于其成本相对较低,合成数据生成的使用在机器学习中一直在不断增加。
生成对抗网络 (GAN) 是用于合成数据生成的众多技术之一。GAN是一种生成建模技术,其中从数据集创建人工实例的方式保留了原始集的相似特征。

总结
收集训练数据集是训练你自定义检测模型的第一步。在这篇文章中,我们研究了用于收集图像数据的一些技术,包括搜索开源数据集、爬取网络、手动拍摄或使用程序拍摄、使用数据增强技术以及生成合成数据集。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“深度学习”获取经典书籍PDF+课程
码字不易,欢迎大家点赞评论收藏!