文章目录
- 前言
- 映射
- 哈希冲突
- 开放寻址法
- 思路分析
- 结构分析
- 函数实现
- 插入
- 删除
- 寻找
- 结语
前言
大家好久不见,今天来讲解一下哈希表的基本原理并使用开放寻址法实现简单哈希表。
映射
哈希表的实现思路就是将一组数据映射成另外一组可以直接查找的数据,假如有一组数据
10,11,17,13 ,18
我们可以将这些数据通过一定的映射规则映射到一个数组里:
假如数组只有五个元素,我们可以采用 key % 5 的方式寻找映射。
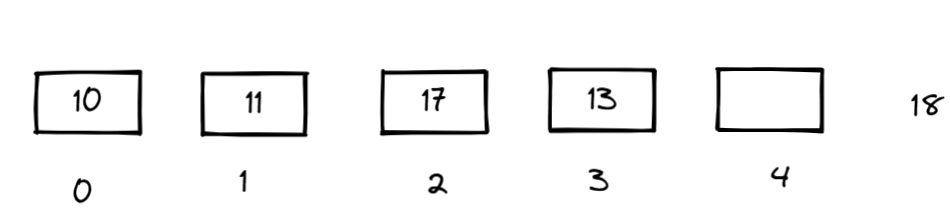
当我们寻找这个数的时候就按照同样的方式直接在数组下索引即可,这就是哈希的思想,可以大大提高查找的速度。
哈希冲突
通过上面的例子,五个元素的数组并没有装满,18和11都占用了同一个坑位,这种现象叫做哈希冲突,根据映射法则,哈希冲突是必然会出现的,因此我们要设法解决这种冲突。
开放寻址法
解决哈希冲突的第一种方法,开放寻址法的解决方案是线性探测,即如果一个映射的坑位被占,就将这个数据向后放,这种方法代码实现比较简单,但容易发生踩踏,如图:
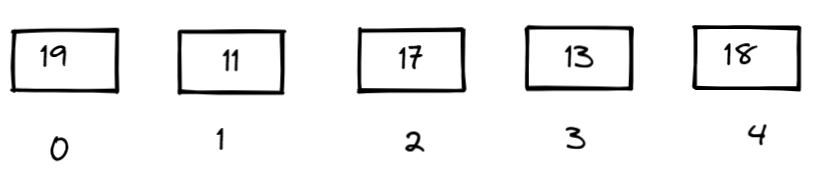
假如18因为与13哈希冲突,我们按照线性探测将她放在4的坑位上,当我们要放16的时候,本应放在4号坑位上却因为踩踏智能放在0号位,这样的方式其实并不理想。
简单实现(只实现哈希表,后面会使用链地址法封装unmap系列):
思路分析
开放寻址法即如果被映射的位置已经有了元素,我们就向后寻找第一个没有元素的位置,这里需要注意由于这个向后寻找元素的特点,删除一个元素,我们就不能单纯的置空,否则就有可能找不到元素。
结构分析
通过上面分析,我们需要三个状态表示每个节点的状态,这里采用枚举的方式来实现:
enum States
{
EXIST,
DELETE,
EMPTY
};
那么每一个哈希节点就要至少包含两个元素:
1、数据
2、状态
template<class K,class V>
struct HashDate
{
pair<K, V> _kv;
States _st;
};
我们可以用一个存放哈希表节点的数组构造这个哈希表。同时需要一个_n充当负载因子,表示哈希表占用的情况。
template<class K,class V>
class HashTable
{
public:
private:
vector<HashDate<K, V>> _tables;
size_t _n = 0;
};
函数实现
插入
插入操作中,有几个细节需要注意:
1、扩容,因为哈希表扩容后对应的映射会更改(size会变),需要重新映射,因此和插入的主逻辑是一致的,我们可以采用开一个新vector,复用insert的逻辑,最后交换两个表即可。
2、线性探测,在探测的时候如果走到数组的最后,需要修正到起点
bool insert(const pair<K,V> kv)
{
if (find(kv.first)) return false;
//Expansion
if (_tables.size() == 0 || _n*10 / _tables.size() > 7)
{
size_t newsize = _tables.size() == 0 ? 10 : 2 * _tables.size();
HashTable<K, V> newht;
newht._tables.resize(newsize);
for (auto data : _tables)
{
if (data._st == EXIST)
{
newht.insert(data._kv);
}
}
//swap(_tables, newht._tables);
_tables.swap(newht._tables);
}
//Insert
size_t hashi = kv.first % _tables.size();
//check
size_t i = 1;
size_t index = hashi;
while (_tables[index]._st == EXIST)
{
index = hashi + i;
++i;
index %= _tables.size();
}
_tables[index]._kv = kv;
_tables[index]._st = EXIST;
_n++;
return true;
}
删除
通过key我们找到要删除节点的指针,通过修改他的状态为DELETE表示这个节点已经被删除了,这里也要说明一下如果设置为了EMPTY,下一个数据在线性探测的时候就可能找不到,这也是为什么我们需要设置三个节点状态。
bool erase(const K& key)
{
HashDate<K, V>* ret = find(key);
if (ret)
{
ret->_st = DELETE;
_n--;
return true;
}
return flase;
}
寻找
上面的两个操作都使用到了find寻找操作,其实在这种实现方式里,寻找操作也比较简单,我们只需要计算出key,接着向后面进行线性探测即可。
HashDate<K, V>* find(const K& key)
{
if (_tables.size() == 0) return false;
size_t hashi = key % _tables.size();
//线性探测
size_t i = 1;
size_t index = hashi;
while (_tables[index]._st != EMPTY)
{
if (_tables[index]._st == EXIST &&
_tables[index]._kv.first == key)
{
return &(_tables[index]);
}
index = hashi + i;
i++;
index %= _tables.size();
if (index == hashi)
{
break;
}
}
return nullptr;
}
结语
开放寻址法代码比较简单,但很容易发生踩踏事件,这也导致他不如 另一种方法——链地址法常用,下一篇文章我会着重讲解链地址法,同时用其实现unordered_map和unordered_set的封装。
我们下次再见~











![[ACTF新生赛2020]fungame 题解](https://img-blog.csdnimg.cn/a5bf1a1923ea4466874edbddfb10fc15.png)