pip install kafka- python
pip install loguru
pip install msgpack
# - * - coding: utf- 8 - * -
import json
import json
import msgpack
from loguru import logger
from kafka import KafkaProducer
from kafka. errors import KafkaError
def kfk_produce_1 ( ) :
"" "
发送 json 格式数据
: return :
"" "
producer = KafkaProducer (
bootstrap_servers= '192.168.85.109:9092' ,
value_serializer= lambda v: json. dumps ( v) . encode ( 'utf-8' )
)
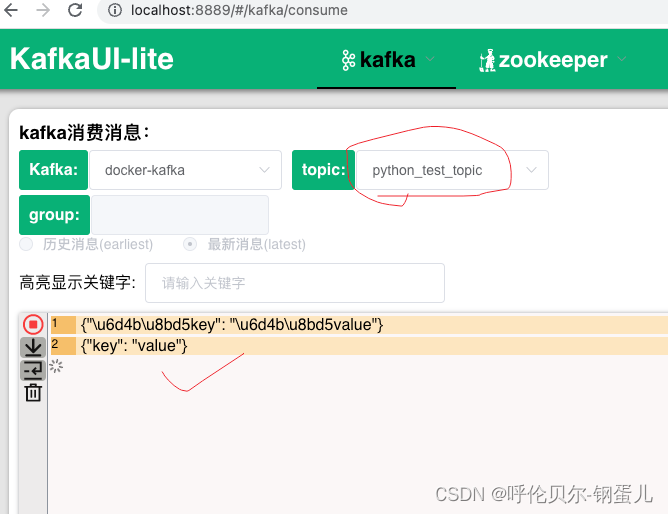
producer. send ( 'python_test_topic' , { 'key' : 'value' } )
kfk_produce_1 ( )