主要包括虚拟内存和物理内存、进程内存空间、用户态和内核态的内存映射。
分段机制
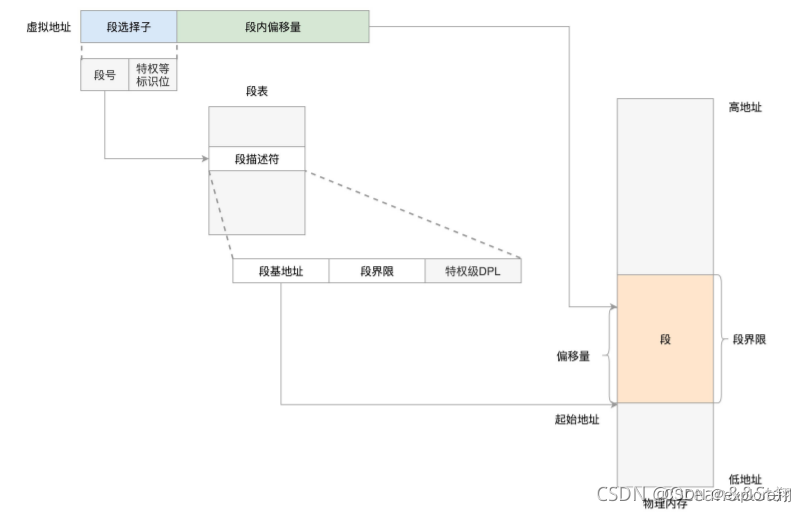
分段机制比较符合逻辑,比如可以把程序分成代码段、全局变量段、堆栈段等。
分段的虚拟地址主要包含段选择因子和段内偏移。段选择子就保存在段寄存器中,段选择子中有一个段号,可以用作段表的索引,段表里面保存的是这个段的基地址、段的界限、特权等级等。
所以物理地址=段基址+偏移。
其实linux倾向于另外一种从虚拟地址到物理地址的转换方式,叫做分页(paging)(效率高)
对于物理内存,操作系统把它分成一块一块大小相同的页,这样更方便管理。比如有的内存页长时间不用了,可以暂时写到硬盘上,称为换出;一旦需要的时候,再加载进来,叫做换入。这样可以扩大可用物理内存的大小,提高物理内存的利用率(换入换出技术)
这个换入和换出都是以页为单位的。页面的大小一般为4KB。为了能够定位和访问每个页,需要有个页表,保存每个页的起始地址,在加上在页内的偏移量,组成线性地址,就能对内存中的每个位置进行访问了
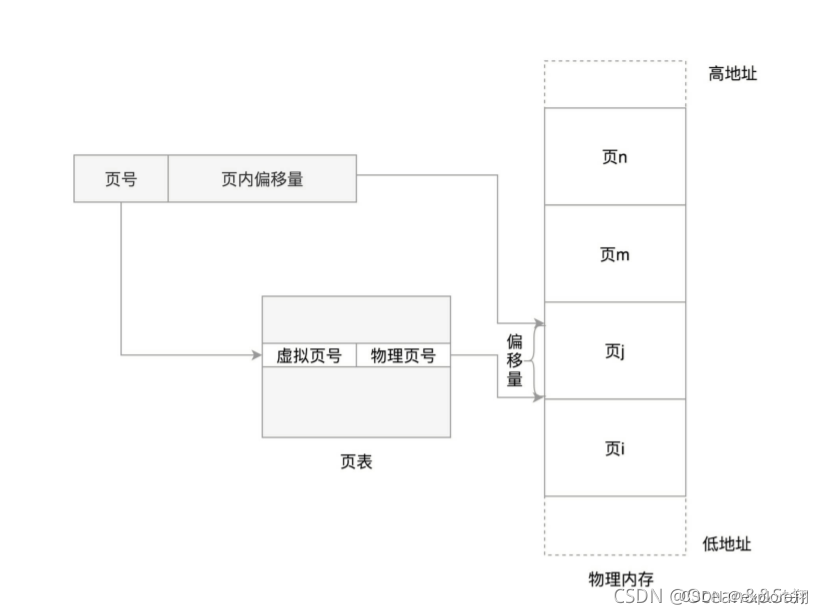
同样的,物理地址=页号+偏移量。(页号会映射到块号)
内存管理系统主要做了下面三件事情:
第一,虚拟内存空间的管理,将虚拟内存分为大小相等的页
第二,物理内存的管理,将物理内存分为大小相等的页
第三,内存映射,将虚拟内存和物理内存映射起来可以转换,并且在内存紧张的时候可以换出到硬盘中
进程的虚拟内存空间
进程的虚拟地址空间,其实就是从task_struct出发来看。
这里面有一个struct mm_struct结构来管理内存:
struct mm_struct mm;
在struct mm_struct里面,有这样一个成员变量:
unsigned long task_size; / size of task vm space */
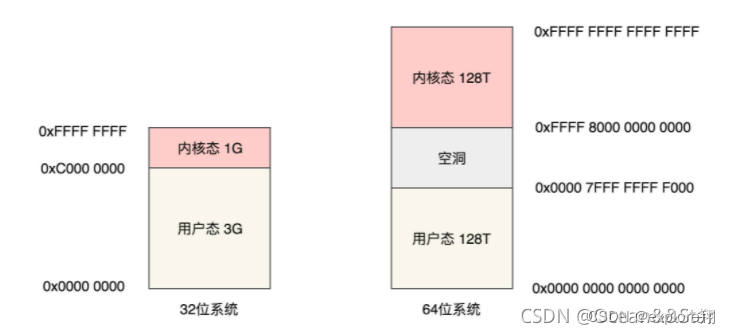
整个虚拟内存空间要一分为二,一部分是用户态地址空间,一部分是内核态地址空间,这这两部分的分界线在哪里呢?这就要task_size来定义。
源码里是利用宏定义了,#ifdef CONFIG_X86_32如果是32位系统,默认用户态是3G,内核态是1G
如果是64位系统 #define TASK_SIZE_MAX ((1UL << 47) - PAGE_SIZE)其实只用了48位。用户态和内核态都是128T。
接下来要了解mm_struct主要有哪些东西用来管理内存。
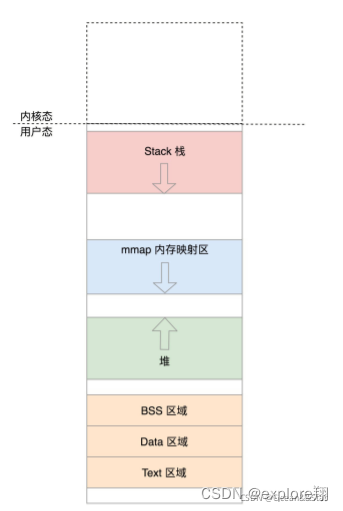
用户态虚拟空间里面有几类数据,比如代码、全局变量、堆、栈、内存映射区等。在struct mm_struct里面,有下面这些变量定义了这些区域的统计信息和位置:
total_vm:总共映射的页的数目。我们知道,这么大的虚拟地址空间,不可能都有真实的内存对应,所以这里是映射的数目。当内存吃紧的时候,有些页可以换出到硬盘上,有的页因为比较重要,不能换出。locked_vm就是被锁定不能换出,pinned_vm是不能换出,也不能移动。
以及数据的起始位置和页的数目,以及栈、代码的。
mmap_base 表示虚拟地址空间中用于内存映射的起始地址。一般情况下,这个空间是从高地址到低地址增长的和栈一样。
malloc申请内存的时候,就是通过mmap 在这里映射一块区域到物理内存(小于128K的还是brk在堆里分配的)
加载动态链接库so文件,也是在这个区域里面,映射一块区域到so文件。
除了位置信息外,struct mm_struct里面还有一个专门的结构vm_area_struct,来描述这些区域的属性:
struct vm_area_struct mmap; / list of VMAs */
struct rb_root mm_rb;
这里面是一个单链表,用于将这些区域串起来。其实指的是代码,数据,BSS,堆栈内存映射这些区域。
每个节点会有指向上下区域的指针,以及区域的开始位置和结束位置,以及一个实体(红黑树,代表mm_struct的实体)
另外还有一个红黑树,可以快速查找一个内存区域,并且在需要改变的时候,能够快速修改。每个节点都是一个mm_struct。 (我们已经知道了,红黑树不仅用于mm_struct实体,还用于实现CFS调度的实体)
还有一些内存映射的,包括到物理内存和文件的。
那这些vm_area_struct 是如何和上面的内存区域管理的呢?
这个事情是在load_elf_binary里面实现的。(load_elf_binary可以用于加载内核、启动第一个用户态进程、exec运行一个二进制程序)当exec运行一个二进制程序时,除了解析ELF的格式之外,另一个重要的事情就是建立内存映射
总结:内存管理,即进程的内存空间布局是有一个mm_struct结构的,里面包含了每个区域的起始位置和页的数目(堆栈数据代码内存映射等)。以及管理这些区域的链表结构,和红黑树。用于快速找到并且方便修改这些区域。实现各个区域的分配就是load_elf_binary函数实现的。通过给定的起始位置分配空间。链表可以方便地找到上下的区域以及删除增加,红黑树可以方便找到区域的实体。
映射完毕后,什么情况下会修改呢?
第一种情况是函数的调用,涉及到函数栈的改变,主要改变栈顶指针
第二种情况是通过malloc申请一个堆内存,当然底层要么执行brk,要么执行mmap。
brk是怎么做的呢?
首先要做的第一个事情,将原来的堆顶和现在的堆顶,都按照页对齐地址,然后比较大小。如果两者相同,说明这次增加的堆的量很小,还在一个页里面,不需要另行分配页,直接调到set_brk那里,设置mm->brk为新的brk就可以了;
如果发现新旧堆顶不在一个页里面,就说明要跨页。如果发现新堆顶小于旧堆顶,这说明不是新分配内存了,而是释放内存了,释放的还不小,至少释放了一页,于是调用do_dupmap将这一页的内存映射去掉
如果是分配内存,就要看红黑树了。找到的是原来堆顶所在的vm_area_struct的下一个vm_area_struct,看当前的堆顶和下一个vm_area_struct之间还能不能分配一个完整的页(其实也就是堆和内存映射区之间还有多少剩余空间)如果不能,没办法只好直接退出返回,内存空间都被占满了
如果还有空间,就调用do_brk进一步分配堆空间,从旧堆顶开始,分配计算出的新旧堆顶之间的页数
在 do_brk 中,调用 find_vma_links 找到将来的 vm_area_struct 节点在红黑树的位置,找到它的父节点、前序节点。
接下来调用 vma_merge,看这个新节点是否能够和现有树中的节点合并。
如果地址是连着的,能够合并,则不用创建新的 vm_area_struct 了,直接跳到 out,更新统计值即可;
如果不能合并,则创建新的 vm_area_struct,既加到 anon_vma_chain 链表中,也加到红黑树中。
(总结brk:不仅仅就是堆顶上移在堆分配一块内存。首先要看新旧堆顶是否在一页里面,在的话不需要分配页,返回新的堆顶即可;如果跨页的话,就要考虑两个区域之间是否有足够的空间了,没有分配就失败了,有的话计算分配的页数,还要看看是不是可以合并区域,如果连着的直接合并了,不是的话还要创建区域加到链表和红黑树中。
实际上为了避免这个问题,malloc分配大的空间都是用mmap形式的,直接拿走一块内存,用完必须回收;而brk只分配小内存,并且分配的并不就是实际的比如1字节会分配100字节,用完放在缓存池中下次用,因此就避免了频繁地系统调用;mmap避免了内存碎片的产生。
可以体会到区域实体不仅仅是数据代码段等了,比如brk可能涉及到内存释放回收的碎片以及内存对齐等,分配的空间并不连续,就需要新增加区域节点,这就是链表和红黑树存在的意义了。可以快速找到区域以及更新区域内容。
还可以体会到linux进程实际上是结合了段页式的内存管理,首先虚拟内存的基本寻址是页的形式,通过页表将页号转换为块号+虚拟地址找到物理地址。而mm_strcut进程的内存管理数据结构分的一些区域是按照段分的,段里面包含了页号。
)
内存态虚拟空间的布局
内核态的虚拟空间和某一个进程没有关系,所有仅通过系统调用进入到内核之后,看到的虚拟地址空间都是一样的。
内核前1M空间已经被BIOS那些初始化程序占了;
32位的内核态虚拟地址空间一共就1G,占绝大部分前896M,我们称为直接映射区。绝大多数都放在这里面,比如我们常说的task_struct,mm_struct涉及到进程调度内存管理的数据结构就放在这里,以及页表也会放在这里。
另外,内核也有内核栈的空间,前面说了,当系统调用进入内核态就需要内核栈,内核栈的特色就是thread_info是为了存储体系结构相关的信息(task_struct通用的),以及还有一块内存存放用户态的CPU上下文信息用于恢复现场的。
另外,还有内核映射区vmalloc,相当于内核的堆和内存映射;以及固定映射满足特定需求。
总结(内核虚拟空间:初始化程序、896M的直接映射区,存放用户的页表、进程管理结构等、vmalloc、特殊区)
有一点需要辨析:页表放在哪里?
页表放在内核的直接映射区毋庸置疑,因为它不能随意更改的,否则自己乱映射起不到保护隔离作用了。
特别的是,内核也有自己的页表,比如初始化程序的页表,内核malloc的页表等,这些放在它们自己的内核区域。进程切换的时候只会切换用户的页表,内核页表不变。(也就是调度,找到下一个task_struct)
那么页表每次查询需要陷入内核吗?
并不是的。设计者早就想到这一点了,如果每次虚拟内存到物理内存转换都要进入内核也太低效率了。
所以这个地址翻译工作是硬件完成的,不需要代码参与,没有性能损失。
那么页表项增加删除会进入内核吗?
这是会的。起到保护作用嘛,为了安全。但其实malloc/free函数其实已经封装了一层了。free不会立即回收内存而是放在缓存池中,malloc(1)也不会仅仅分配1字节,而是多分一点。就是为了频繁的系统调用;
TLB块表就是在内存中的,很快。页表是在物理内存也就是外存的。
总结一下:
虚拟内存作用就是:多任务系统,起到进程隔离作用;另外就是换入换出技术扩大逻辑内存;
每个进程都会有自己的task_struct,存放在内核空间中。这个结构体信息很多,包括了调度,内存管理,文件文件系统管理,统计信息,pid亲缘信息,权限管理,信号处理,内核栈等等。
对于内存来说的话,mm_struct会记录每个区域的信息(链表+红黑树),进程都会有自己的页表,存放在内核空间中,所以说fork一个进程,就是fork它的任务结构体并赋值,其中包含页表;
进程切换时,就是找到另一个任务结构体执行,其中用户的页表也要切换了。这会导致cache不热了,命中率变低。
物理内存管理
物理内存的组织方式
最经典的内存使用方式:CPU是通过总线去访问内存的
平坦内存模型(最经典的模型):
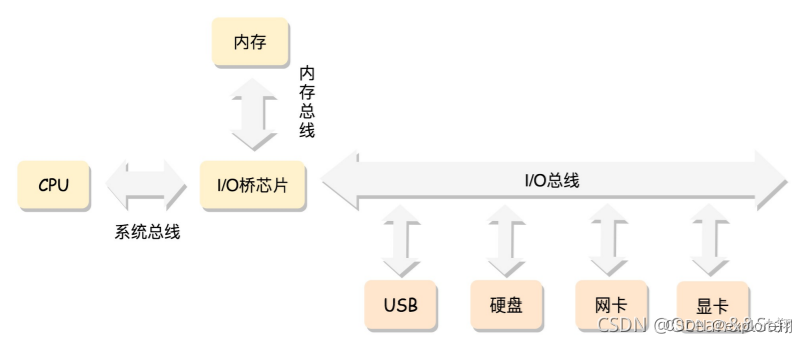
内存是由连续的一页一页的块组成的。我们可以从0开始对物理页进程编号,这样每个物理页都会有个页号。所有的内存条组成一大块内存,在总线的另一侧,所有的CPU访问内存都要过总线,而且距离是一样的,这种模式叫做SMP(Symmetric multiprocessing),即对称多处理器。
当然,缺点是,总线会成为瓶颈,因为数据都要走它
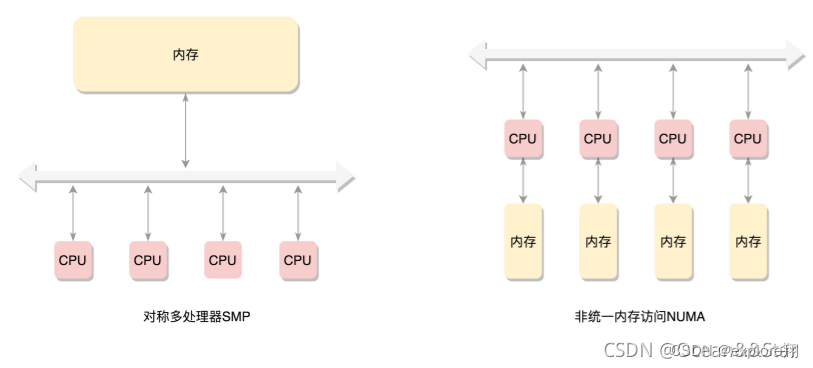
为了提高性能和可扩展性,后来有了一种更高级的模式,NUMA(Non-uniform memory access),非一致性内存访问:每个CPU都有自己的本地内存,CPU访问本地内存不用过总线,因而速度快很多,每个CPU核内存在一起,称为一个NUMA节点。但是,在本地内存不足的情况下,每个CPU都可以去另外的NUMA节点申请内存,这个时候访问延时就会比较长。
后来内存技术牛了,可以支持热插播了。这个时候,不连续成为常态,于是就有了稀疏内存模型
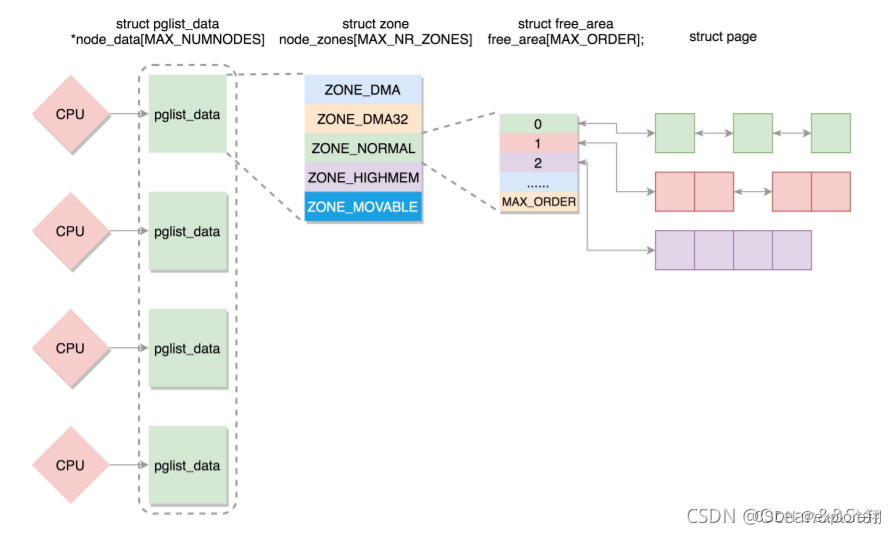
如果有多个CPU,就有多个节点。每个节点用struct pglist_data表示,放在一个数组里面
每个节点分为多个区域,每个区域用struct zone表示,也放在一个数组里面
每个区域分为多个页。为了方便分配,空闲页放在struct free_area 里面,使用伙伴系统进行管理和分配,每一页用struct page表示.
整体就是节点-区域-页
页是组成物理内存的基本单位,其数据结构是struct page。这是一个特别复杂的结构,里面有很多union。这里之所以用了union,是因为一个物理页面使用模式有很多种。
第一种模式,要用就用一整页。这一整页的内存
或者直接和虚拟地址空间建立映射关系,我们把这种叫做匿名页(anonymous page)
或者用于关联一个文件,然后再和虚拟地址空间建立映射关系,这样的文件,我们称为内存映射文件(Memory-mapped File)
第二种模式,仅需分配小块内存。
有时候,我们不需要一下子分配这么多的内存,比如分配一个task_struct结构。linux系统采用了一种被称为slab allocator的技术。它的基本原理是从内存管理模块申请一整块页,然后划分成多个小块的存储池,用复杂的队列来维护这些小块的状态。也正是因为 slab allocator 对于队列的维护过于复杂,后来就有了一种不使用队列的分配器。
页的分配
上面我们讲了物理内存的组织,从节点到区域到页到小块。接下来,我们来看物理内存的分配。
对于要分配比较大的内存,比如到分配页级别的,可以使用伙伴系统(buddy system):
linux中内存管理的“页”大小为4KB。把所有的空闲页分组为11个页块链表,每个块链表分别包含很多个大小的页块,有1、2、4、8、16、32、128、256、512和1024个连续页的页块。最大可以申请1024个连续页,对应4MB大小的连续内存。每个页块的第一个页的物理地址是该页块大小的整数倍。
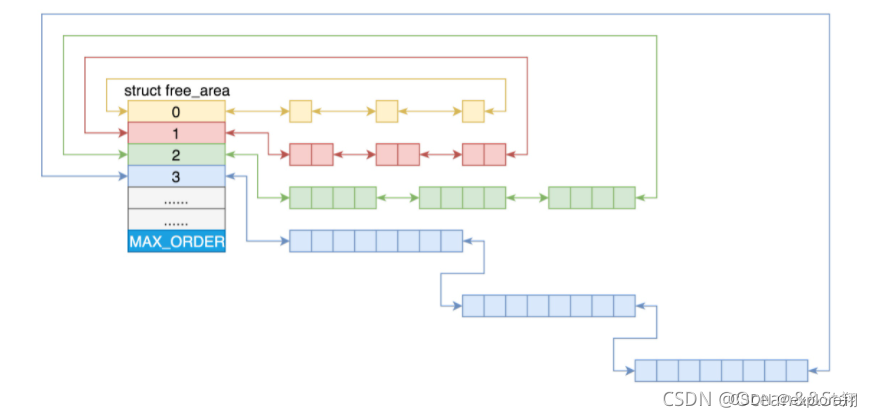
第 i 个页块链表中,页块中页的数目为 2^i。比如,要请求一个128个页的页块时,先检查128个页的页块链表是否有空闲块。如果没有,则查256个页的页块链表;如果有空闲块的话,则将256个页的页块分成两份,一份使用,一份插入到128个页的页块链表中。如果还是没有,就查512个页的页块链表;如果有的话,就分裂为128、128、256三个页块,一个128的使用,剩余两个插入到对应页块链表(伙伴系统的意思就是劫富济贫)
如果遇到小的对象,会使用slub分配器进行分配。接下来将分析其原理。原理过于复杂
页面换出
什么情况下会触发页面换出呢?
可以想象,最常见的情况就是,分配内存的时候,发现没有地方了,就试图回收一下。
另外一种情况是,作为内存管理系统应该主动去做的,而不能等真的出了事情再做,这就是内核线程kswapd。这个内核线程,在系统初始化的时候就被创建。这样它会进入一个无限循环,直到系统停止。在这个循环中,如果内存使用没有那么紧张,拿它就可以放心sleep;如果内存紧张了,就要去检查一下内存,看看是否需要换出一些内存页。
这里面有个lru列表,从下面的定义,我们可以想象,所有的页面都被挂载LRU列表中,LRU就是 Least Recent Use,也就是最近最少使用。也就是说,这个列表里面会按照活跃程度进行排序,这样就很容易把不怎么用的内存页拿出来做处理。
内存页一共分两类,一类是匿名页,和虚拟地址进行管理;一类是内存映射,不但和虚拟地址空间管理,还和文件管理管理。
它的每一类都有两个列表,一共是active,一共是inactive。active就是比较活跃的,inactive就是不怎么活跃的。这里面的页会变化,过一段时间,活跃的可能变成不活跃的,不活跃的可能变成活跃的。如果要换出内存,那就是从不活跃列表中找出最不活跃的,换出到硬盘上。
这里涉及到LRU算法的缓存污染和预读失效的问题。
缓存污染就是一次读大量数据 ,但是只是这一次访问,如果LRU需要从头到尾移动花很长时间。linux操作系统用的就是活跃和非活跃的LRU,一开始在非活跃的,满足一定条件才到活跃列表。mysql类似的,redis用的是lfu代替lru.
用户态内存映射
每一个进程都有一个列表vm_area_struct,指向虚拟地址空间的不同的内存块,这个编码的名字叫做mmap
struct mm_struct {
struct vm_area_struct mmap; / list of VMAs */
…
}
其实内存映射不仅仅是物理内存和虚拟内存之间的映射,还包含将文件中的内容映射到虚拟内存空间。这个时候,访问内存空间就能够访问到文件里面的数据。而仅有物理内存和虚拟内存的映射,是一种特殊情况。
如果我们要申请小块堆内存,就用brk。
如果我们要申请大块堆内存,就用mmap。这里的mmap就是映射内存空间到物理内存
如果一个进程想映射一个文件到自己的虚拟内存空间,也有用mmap系统调用。这个时候mmap是映射内存空间到物理内存再到文件。
mmap系统调用做了什么?
调用get_unmapped_area 找到一个没有映射的区域:在表示虚拟内存区域的vm_area_struct 红黑树上找到相应的位置
调用mmap_region映射这个区域:先看看能不能和前一个合并Merge,不行的话就创建一个新的vm_area_struct对象,设置起始和结束位置,将它加入队列。如果是映射到文件的话就是调用file op相关函数,这一刻文件和内存开始发生关系了。这里我们将vm_area_struct 的内存操作设置为文件系统操作,也就是说,读写内存就是读写文件系统
最终,vma_link函数将新创建的vm_area_struct挂在了mm_struct里面的红黑树上。
vma_link还做了另外一件事情,就是__vma_link_file。对于打开的文件,会有一个结构 struct file 来表示。它有个成员指向 struct address_space 结构,这里面有棵变量名为 i_mmap 的红黑树,vm_area_struct 就挂在这棵树上。也就是建立文件到内存的映射。
可是现在还没有和物理内存发生任何关系,还是在虚拟内存里面折腾啊?
是的,这个时候,内存管理并不直接分配物理内存,因为物理内存相对于虚拟地址空间太宝贵了,只有等到真正用的那一刻才会开始分配。malloc分配的是虚拟内存。
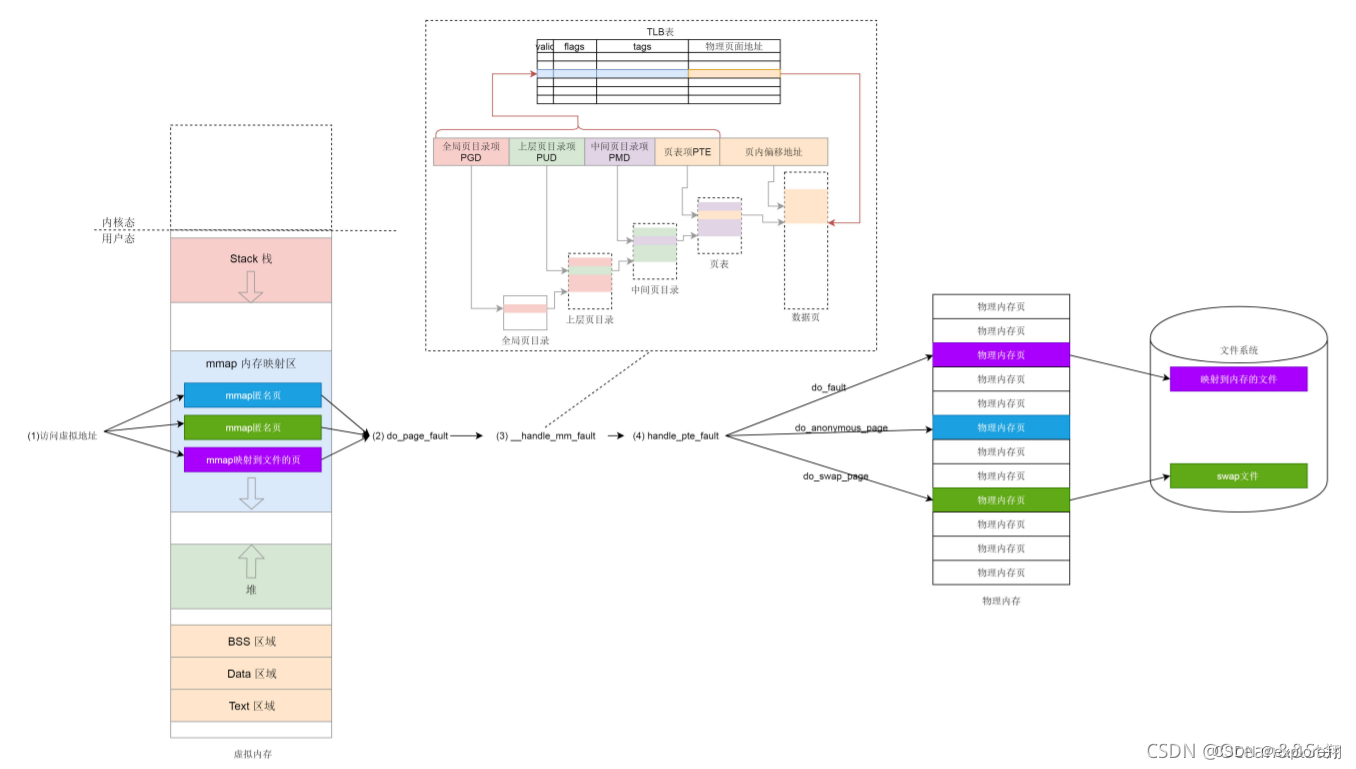
缺页异常
一旦开始访问虚拟内存的某个地址,如果发现,并没有对应的物理页,就会触发缺页中断,调用do_page_fault
在__do_page_fault里面,先要判断缺页中断是否发生在内核。如果发生在内核则调用vmalloc_fault,在内核里面,vmalloc区域需要内核页表映射到物理页;
如果发生在用户空间里面,找到你访问的那个地址所在的区域vm_area_struct,然后调用handle_mm_fault来映射这个区域;如何实现虚拟到物理的映射呢?
这个函数里,我们看到了熟悉的PGD、P4G、PUD、PMD、PTE,这就是页表中四级页表的概念
pgd_t 用于全局页目录项,pud_t 用于上层页目录项,pmd_t 用于中间页目录项,pte_t 用于直接页表项。
每个进程都有独立的地址空间,为了这个进程独立完成映射,每个进程都有独立的进程页表,这个页表的最顶层的pgd存放在task_struct中的mm_struct的pgd变量里面。
我们在fork的时候,memcpy父进程的task_struct,就要复制mm_strcut的pgd变量。mm_init调用mm_alloc_pgd,分配全局页目录页。pgd_alloc里面除了分配PDG之外,还做了很重要的一个事情,就是调用pgd_ctor,复制一下内核页表。
当这个进程被调用到某个CPU上运行的时候。也就是会出发缺页中断了。这里面会调用load_new_mm_cr3。cr3是CPU的一个寄存器,它会指向当前进程的顶级pgd。如果CPU的指令要访问进程的虚拟内存,它就会自动从cr3里面得到pgd在物理内存的地址,然后根据里面的页表解析虚拟内存的地址为物理内存,从而访问真正的物理内存上的数据。(这就是为什么说地址翻译是硬件完成的,转换过程不用进入内核态的)
第一次才会缺页异常,所以__handle_mm_fault 调用 pud_alloc 和 pmd_alloc,来创建相应的页目录项,最后调用 handle_pte_fault 来创建页表项。下一次访问就不会产生缺页异常了。
页表项的创建分成三种情况:第一就是pte出现过说明原来页面在物理内存中,后来换出到硬盘了,现在应该换回来,调用的是do_swap_page。(swap分区就是存这些页的,先看看swap文件有没有缓存页,没有再从硬盘调入)
第二就是pte没有出现过,应该映射到一个物理内存页,在这里调用的是 do_anonymous_page。(先通弄过pte_alloc分配一个页表项,并最终调用__alloc_pages_nodemask,这个函数就是伙伴系统的核心函数,专门用来分配物理页面的)
如果是映射到文件,调用的就是 do_fault(先看物理内存有有没有文件页表的缓存,没有将文件内容读到内存中,这里还涉及到内核虚拟地址的临时映射比较麻烦)
内核态的内存映射
内核态的内存映射机制,主要包含如下几个部分:
内核态内存映射函数vmalloc、kmap_atomic是如何工作的
内核态页表是放在哪里的,如何工作的?swapper_pg_dir 是怎么回事;
出现内核态缺页异常该怎么办?
和用户态页表不同,在系统初始化的时候,我们就要创建内核页表了。接下来是初始化内核页表,在系统启动的时候 start_kernel 会调用 setup_arch。
vmalloc是内核的动态映射,因为内核只有896MB直接映射,动态申请大块内存的话就会用。
kmap_atomic是临时映射,上面说的文件的映射就会用到内核的临时映射了。
内核地址映射的模型
32位的进程虚拟内存空间,3GB是用户的,1GB是内核的。如果都是直接映射的话,那么内核也就只能访问1GB的物理内存,如果安装了8GB的物理内存,7GB内核无法访问。所以不能全部是直接映射。
所以x86分成了三个部分:
DMA,NORMAL,HIGHMEM.
DMA占0-16MB:用于设备的自动访问,IO不用CPU,解放CPU;
NORMAL:直接映射区,比如存放task_strcut这种;
HIGHMEM:所谓的高端内存(896-1024MB)借助124MB的内存实现映射所有的物理内存。
(其实就是借用一段地址空间,建立临时映射,用完后释放)如果有人一直不释放怎么办?
高端内存其实分成三部分:
VMALLOC部分; KMAP部分, FIX部分
VMALLOC就是用来实现动态映射的;
FIX部分:用于临时映射的kmap_atomic
KMAP部分实现永久映射,主要放的是内核的全局页表(swapper_pg_dir),不同进程都是一样的,对应用户空间的就是PGD全局页表,通过CR3寄存器指向。
现在总结一下;
第一:就是进程虚拟内存的管理。段页结合。 因为进程的虚拟地址空间按照段来分区域的,但是最小的单位是页。有一个mm_stcuct管理,其中最重要的就是vm_area_struct结构,包含了一个链表和红黑树,每个区域都会在红黑树有个实体,然后放在链表上。为了实现快速的查找和更改。
第二就是:物理内存的组织。包括NUMA架构,分成节点区域页。物理内存分配:大的就用伙伴系统(多级链表),小的有slab alloctor。 物理内存的换入换出,当内存不够就kswapd内核线程换出一些内存页,经典的LRU算法,活跃不活跃来解决缓存污染的问题。
第三就是虚拟地址到物理地址的映射。页表来完成。具体的就有很多了。
能够更改进程内存映射的只有两个操作,要么是函数调用会使栈指针上移;一个就是Malloc动态分配内存了。(页表翻译不需要陷入内核,但是新增加页表项是需要的,因为malloc实际上封装了一层,一次多分配一些,并且free不立即回收,避免频繁地缺页中断。)
malloc分配小内存用的brk,总结brk:不仅仅就是堆顶上移在堆分配一块内存。首先要看新旧堆顶是否在一页里面,在的话不需要分配页,返回新的堆顶即可;如果跨页的话,就要考虑两个区域之间是否有足够的空间了,没有分配就失败了,有的话计算分配的页数,还要看看是不是可以合并区域,如果连着的直接合并了,不是的话还要创建区域加到链表和红黑树中。
分配大内存就要用mmap内存映射了。
首先调用unmapparea查看没有映射的区域,实际就是在红黑树找;
找到之后看看能不能和前一个合并,不行就新建一个,挂到红黑树上;
思想和brk差不多其实;
这些都只是虚拟地址;
然后一旦使用了进程,当这个进程被调用到某个CPU上运行的时候。也就是会出发缺页中断了。这里面会调用load_new_mm_cr3。cr3是CPU的一个寄存器,它会指向当前进程的顶级pgd。如果CPU的指令要访问进程的虚拟内存,它就会自动从cr3里面得到pgd在物理内存的地址,然后根据里面的页表解析虚拟内存的地址为物理内存,从而访问真正的物理内存上的数据。
因为只有第一次才会有缺页中断,所以访问后__handle_mm_fault 调用 pud_alloc 和 pmd_alloc,来创建相应的页目录项,最后调用 handle_pte_fault 来创建页表项。下一次访问就不会产生缺页异常了。
页表项创建也分成三种,具体的看前面。
linux页表分成四级,每个进程的全局页表是不一样的,所以进程切换的时候,PGD也不一样。但是内核的全局页表(swapper_pg_dir)一样的(内核初始化程序等的页表),存放在持久映射区。
PGD下面有PUD,PMD,PTE。通过CR3寄存器就可以找到对应的物理块号。
MMU实际上就是先找TLB,没有再找CR3,没有就缺页异常了。
同时,malloc也会先分配虚拟地址,使用的时候进入MMU缺页异常,进行处理。
第四就是内核的空间布局和内核的内存映射分类了。