如果爬虫做完的话都会发现每个文件要么保存到csv或者是其他格式的文件中,这样做多少会有些麻烦,所以需要将这些内容保存起来方便自己管理和查看内容。
相对于flask而言Django有着相对成熟的一个后台管理系统配合上其他一些插件就可以做到即插即用的效果而不用自己再去花时间去做其他。
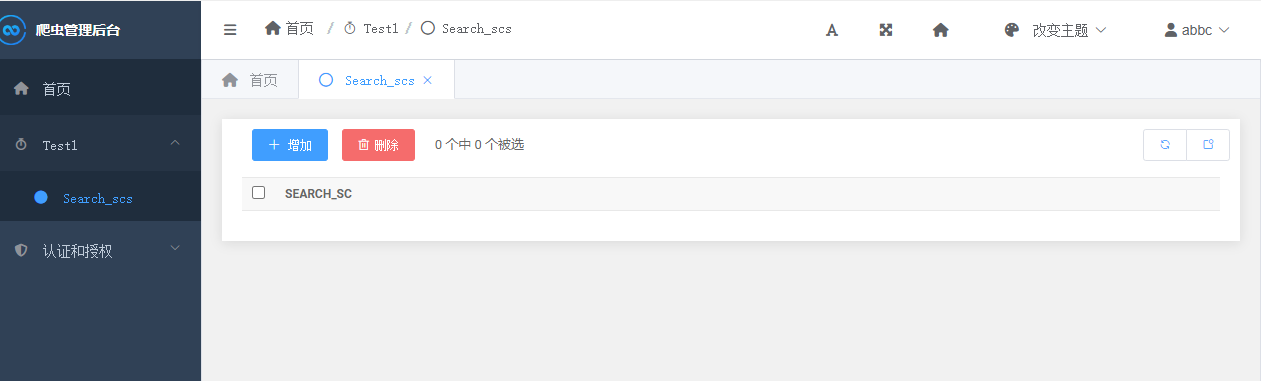
后台系统搭建好是这个样子。
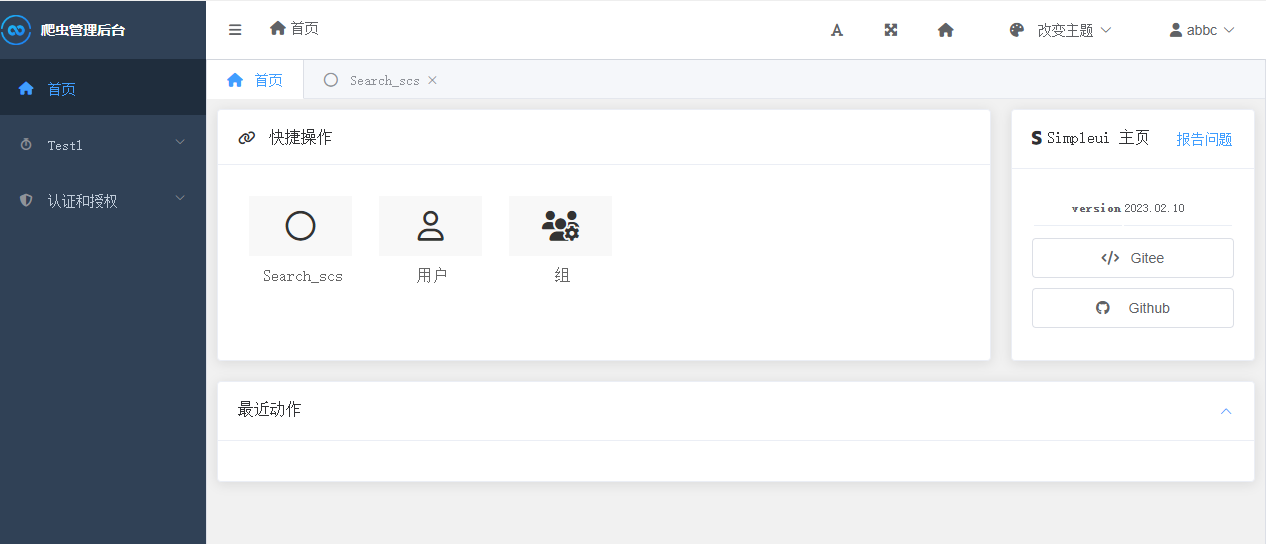
本篇采用Django作为后台管理系统,将从零开始手把手搭建自己的爬虫后台。
源码已上传有需要可以直接下载
Django爬虫后台管理系统
Python爬虫进阶1
- 1.Django搭建
- 2.设计模型
- 3.后台管理
- 4.连接mysql数据库
- 5.用simpleui装饰后台
- 6.selenium爬虫后存入数据库中
- 7.Django新增导入导出功能
1.Django搭建
先在cmd中给python安装好Django
pip3 install django
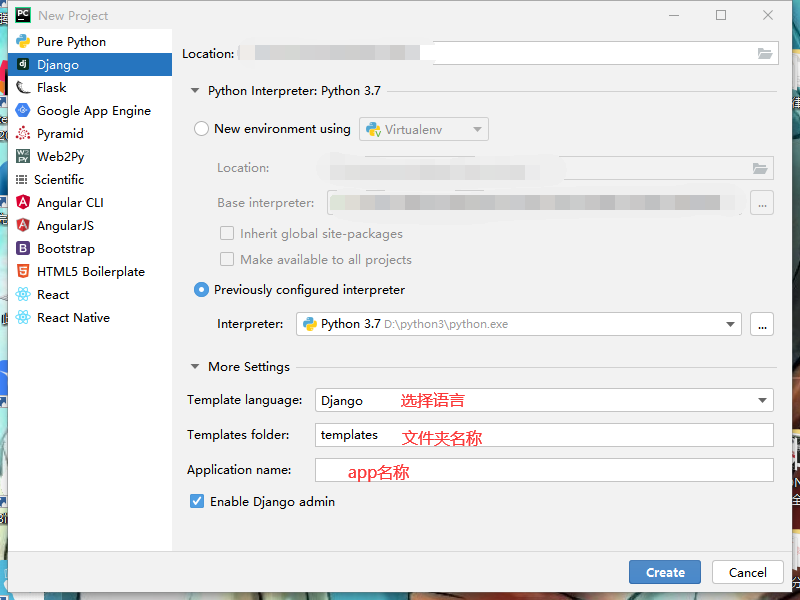
然后点击pychram点击New Project

然后点击Django
选择默认的python3.7版本即可,appname输入你自己的默认app名称即可创建默认的目录
全部处理好后点击create即可创建Django
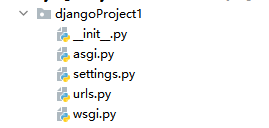
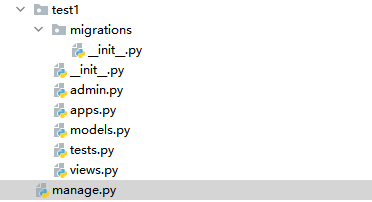
创建好Django项目之后会出现默认的目录
目录结构就是
manage是项目入口指定配置文件路径
init是空文件,被当做包使用
url是配置项目url的文件,指引页面路径
wsgi是web服务器的入口
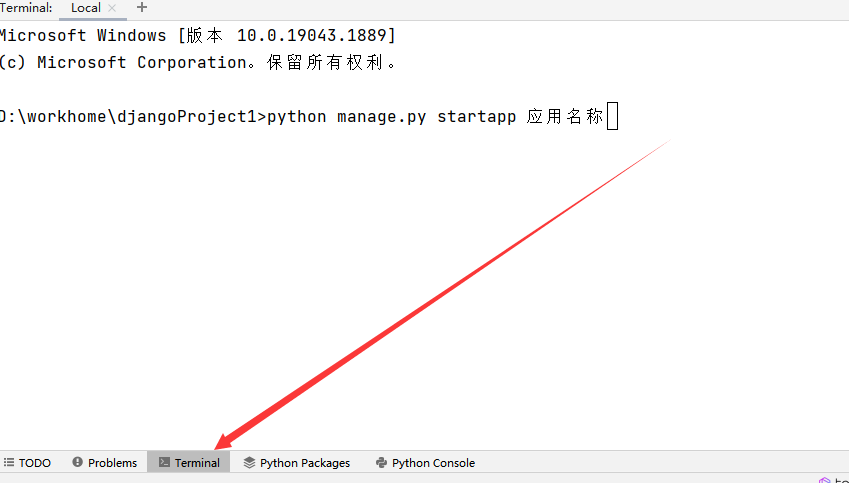
之后如果一开始没有创建应用名称那么就需要在pycharm的底部点击terminal终端上创建一个app应用名称
创建好之后如下
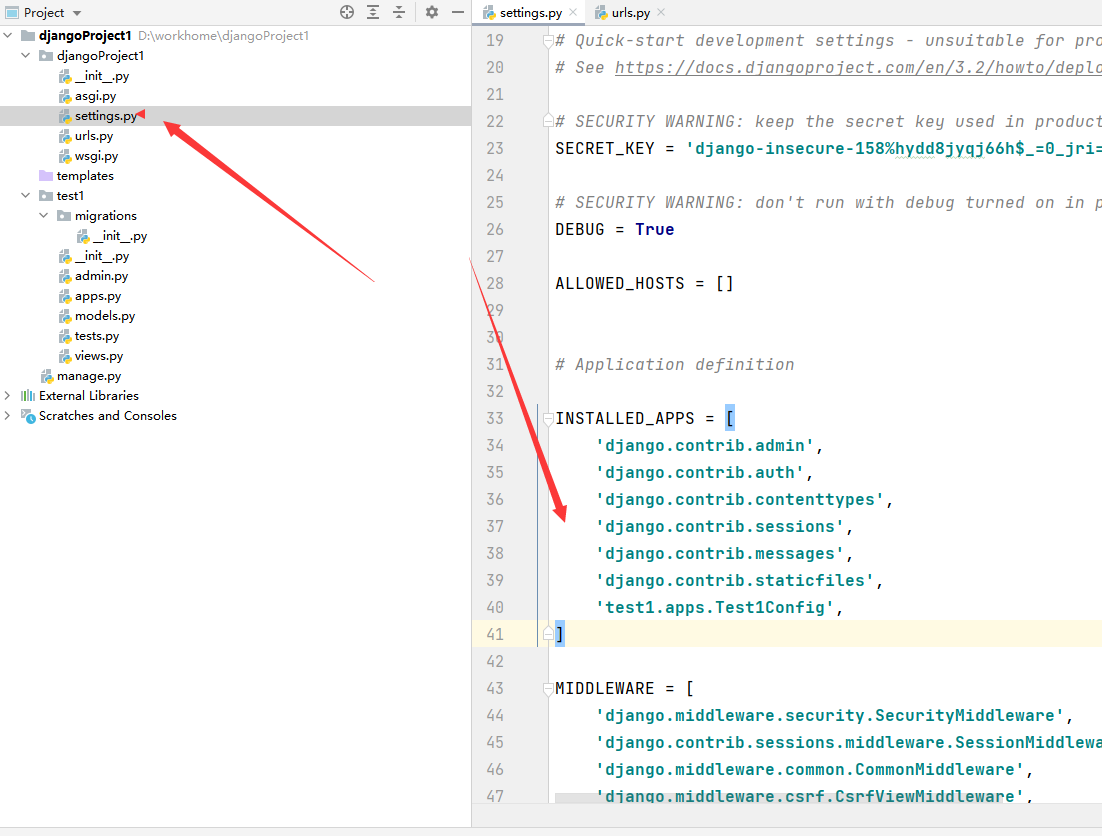
然后创建好应用后要在setting中检查有无安装成功
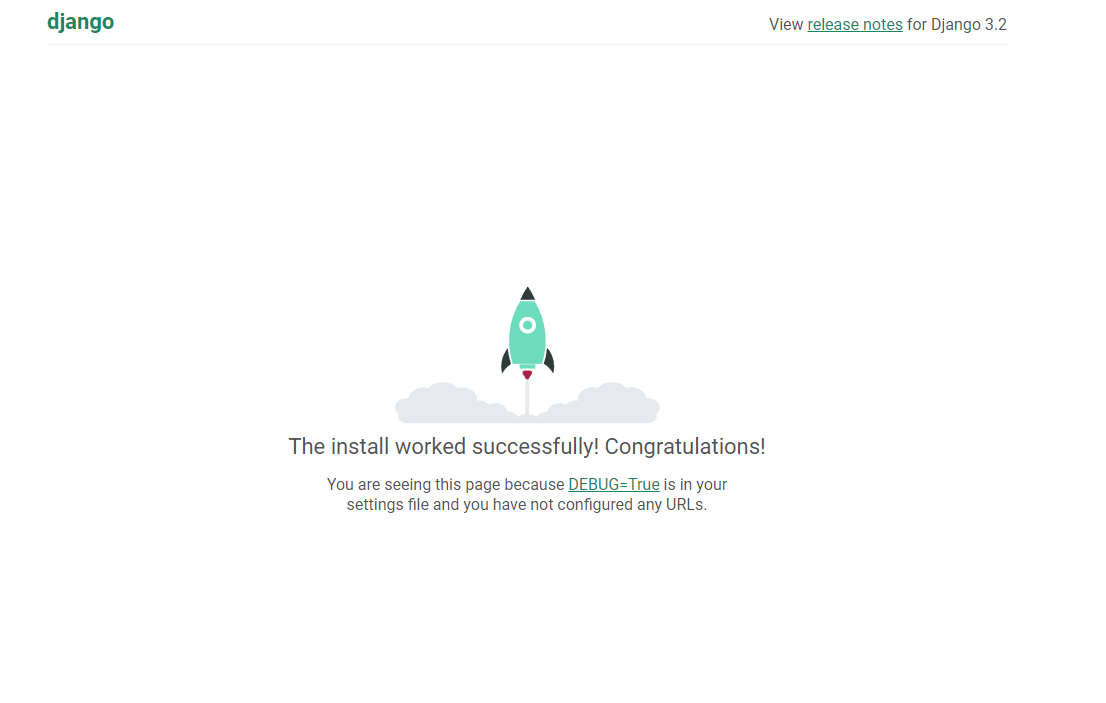
然后点击开始启动服务器

出现这个页面就代表成功

2.设计模型
Django中拥有ORM框架所以我们只要对模型进行设计后既可调用数据库中的数据显示到页面中
所以可以设计一张表结构:
爬虫信息表
表名:Search_sc
内容:content_sc
来源:url_sc
日期:time_sc
from django.db import models
class Search_sc(models.Model):
content_sc = models.CharField(max_length=300)
url_sc = models.CharField(max_length=300)
time_sc = models.CharField(max_length=100)
def __str__(self):
return "%d" % self.pk
创建好模型之后进行数据迁移
打开terminal终端
python manage.py makemigrations
执行迁移命令
python manage.py migrate


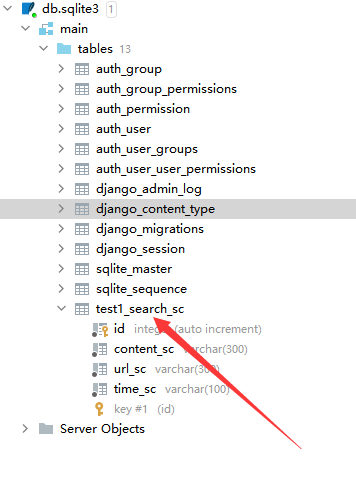
这时候默认的Django数据库是sqlit3,只要在sqlit3数据库中出现当前表格就表示显示成功
3.后台管理
后台管理可以对数据和用户进行相应的管理,需要创建一个管理员
python manage.py createsuperuser

然后创建好用户之后用下面地址进行登录
http://127.0.0.1:8000/admin
用你之前创建好的用户名和密码进行登录即可
然后我们进入管理后台就是如下图所示
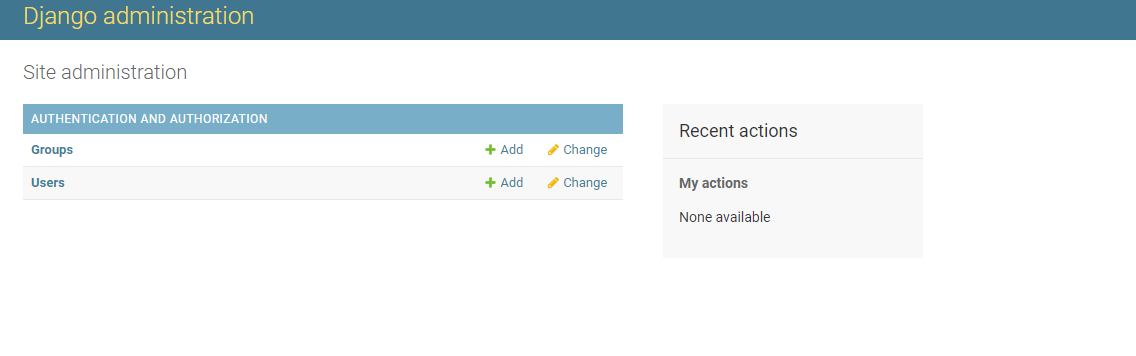
这时候没有看到我们的模型因为还没有注册需要再admin.py中进行注册一下
from django.contrib import admin
from .models import Search_sc
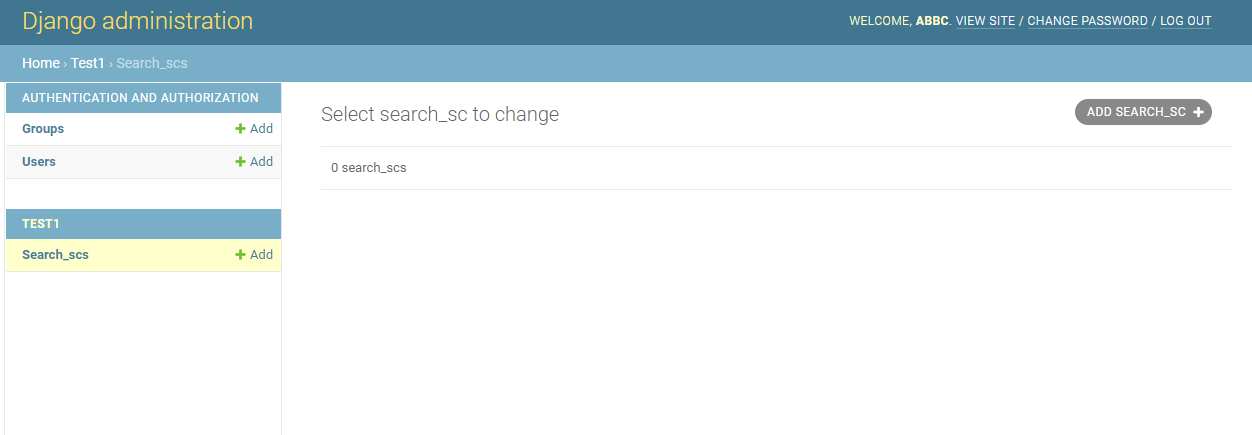
admin.site.register(Search_sc)
然后再次登录Django后台就可以看到这个页面
4.连接mysql数据库
上面数据建模已经完成下面就进行连接mysql数据库的操作,先创建一个数据库然后用navicat进行连接
然后修改settings.py文件
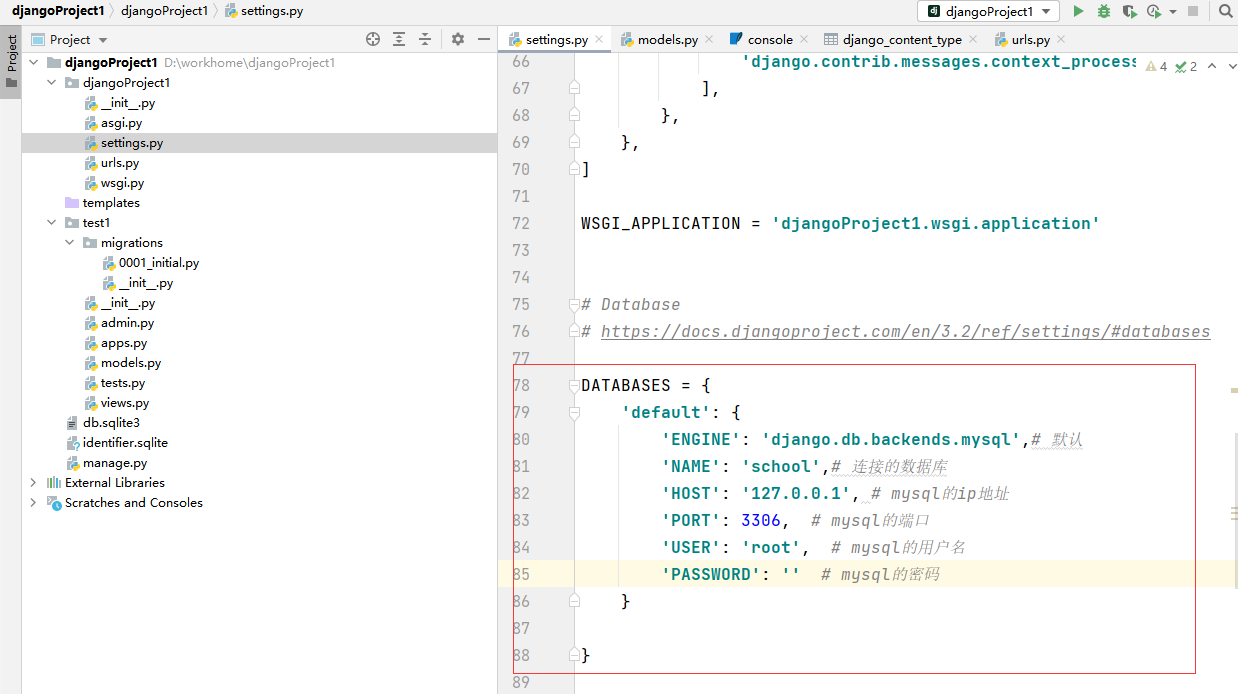
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',# 默认
'NAME': 'school',# 连接的数据库
'HOST': '127.0.0.1', # mysql的ip地址
'PORT': 3306, # mysql的端口
'USER': 'root', # mysql的用户名
'PASSWORD': '' # mysql的密码
}
}
先安装pymysql,
pip3 install pymysql
由于更换了数据库所以init引擎也要进行相应更换在init中进行相应的修改
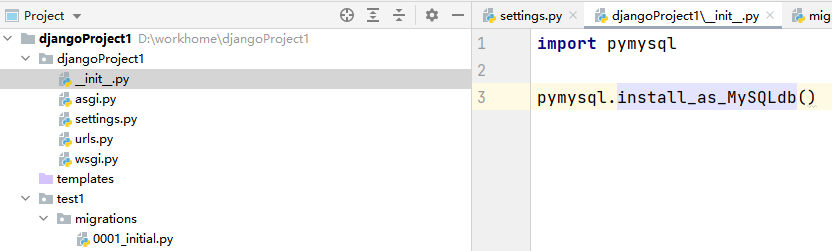
import pymysql
pymysql.install_as_MySQLdb()
然后再进行数据库迁移
python manage.py makemigrations
python manage.py migrate
迁移成功之后在Navicat中就可以看到mysql中被迁移成功后的数据
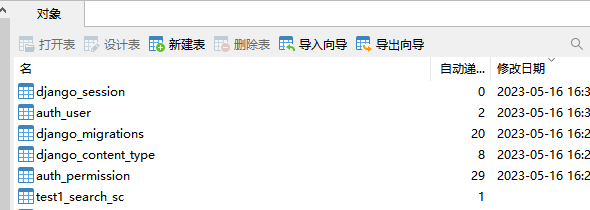
这个就是我一开始创建的模型表

5.用simpleui装饰后台
由于目前来看我们这些后台管理系统并不好看,所以我们需要加装一些插件把后台系统变得好看一些,所以要添加simpleui插件。
先用pip安装插件
pip3 install django-simpleui
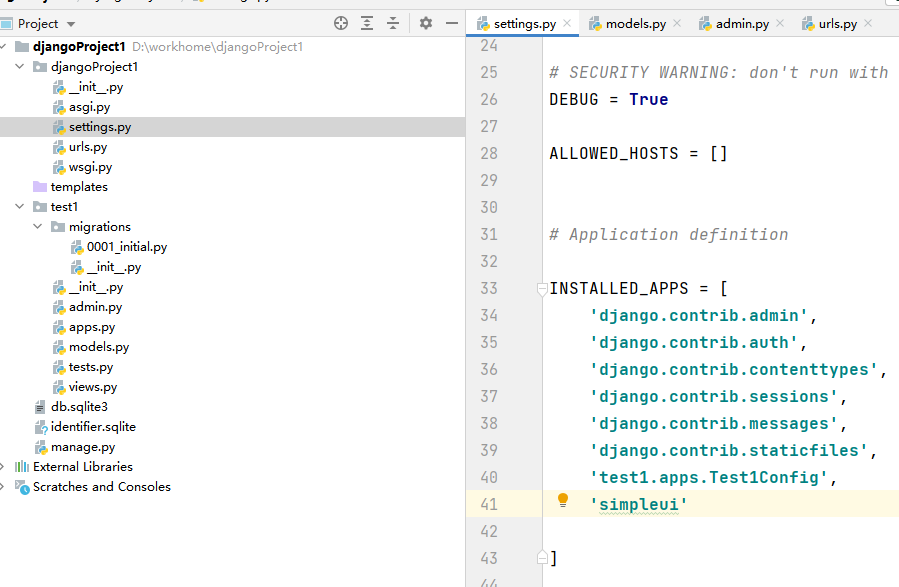
将simpleui添加到setting中
INSTALLED_APPS = [
'simpleui',
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'test1.apps.Test1Config',
]
# 更改默认语言为中文
LANGUAGE_CODE = 'zh-hans'
#修改时区
TIME_ZONE = 'Asia/Shanghai'
# 隐藏右侧SimpleUI广告链接和使用分析
SIMPLEUI_HOME_INFO = False
SIMPLEUI_ANALYSIS = False
修改后登录后台管理系统就会发现进行相应的变化
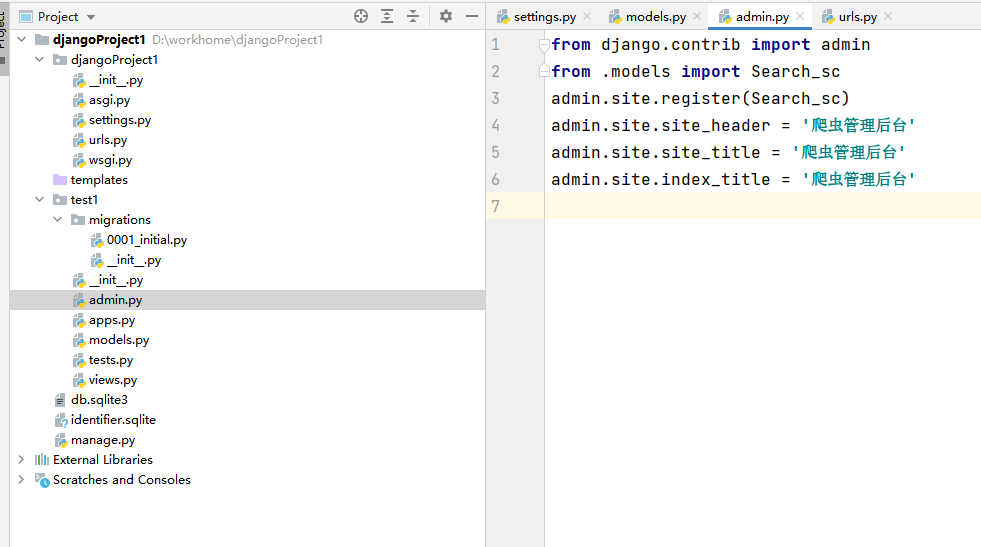
然后对后台的标题和名称进行修改在admin.py中进行修改
from django.contrib import admin
from .models import Search_sc
admin.site.register(Search_sc)
admin.site.site_header = '爬虫管理后台'
admin.site.site_title = '爬虫管理后台'
admin.site.index_title = '爬虫管理后台'
侧边栏可通过apps.py进行修改
from django.apps import AppConfig
class Test1Config(AppConfig):
default_auto_field = 'django.db.models.BigAutoField'
name = 'test1'
verbose_name = '爬虫信息管理'
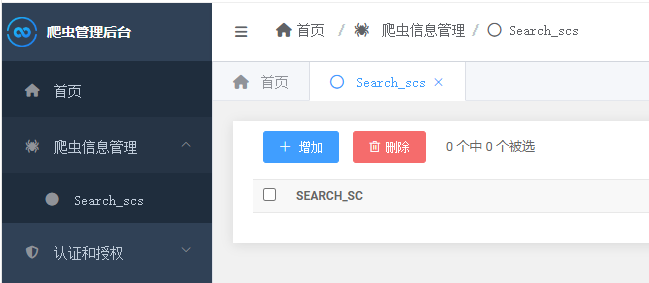
由于models中显示是英文所以需要将models改变成中文使用verbos_name,对models.py进行修改
from django.db import models
class Search_sc(models.Model):
content_sc = models.CharField(max_length=300)
url_sc = models.CharField(max_length=300)
time_sc = models.CharField(max_length=100)
class Meta:
verbose_name = "爬虫详细信息"
verbose_name_plural = "爬虫详细信息"
def __str__(self):
return "%d" % self.pk
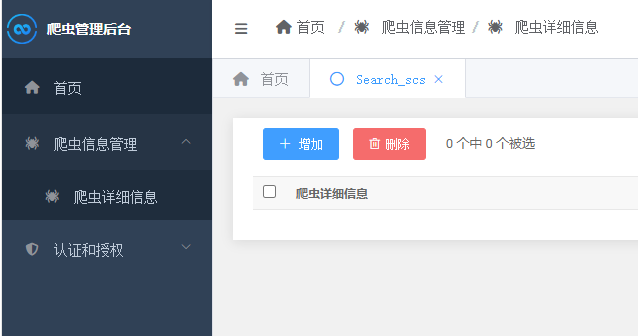
更多simpleui使用可参考这篇文章:
Django实战: 手把手教你配置Django SimpleUI打造美丽后台(多图)
全部修改后的样子比之前好看很多
6.selenium爬虫后存入数据库中
后台搭建好之后我们就需要使用selenium进行爬虫然后存入mysql数据库中再把数据展示到Django后台管理系统中
目前我的selenium已经配置好如果没有配置好的需要先去配置一下selenium我用的是最新的版本
如果不了解selenium可以去看这一篇文章
selenium用法详解【从入门到实战】【Python爬虫】【4万字】
import time
import pymysql
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from apscheduler.schedulers.blocking import BlockingScheduler
from selenium.webdriver import Chrome, ChromeOptions
conn = pymysql.connect(host='localhost', # host属性
port=3306, # 端口号
user='', # 用户名
password='', # 此处填登录数据库的密码
db='', # 数据库名
charset='utf8'
)
opt = ChromeOptions() # 创建Chrome参数对象
opt.headless = True # 把Chrome设置成可视化无界面模式,windows/Linux 皆可
# Chrome浏览器
driver = webdriver.Chrome()
driver.get("")#新闻网站
def index():
# 设置等待5秒,避免爬虫时被封禁
driver.implicitly_wait(5)
# 找到外框的获取里面所有的li标签
content = driver.find_element(By.XPATH,'/html/body/div[7]/div[1]/div[2]/ul/li[1]/span/a').text
url = driver.find_element(By.XPATH,'/html/body/div[7]/div[1]/div[2]/ul/li[1]/span/a').get_attribute('href')
time_cf=driver.find_element(By.XPATH, '/html/body/div[7]/div[1]/div[2]/ul/li[1]/span/span').text
cursor = conn.cursor()
# 插入数据,insert into 表(列名,列名,列名)values(值,值,值)这个值主要就是对应的你获取到的值
sql = 'insert into test1_search_sc(content_sc,url_sc,time_sc) values(%s,%s,%s);'
# 对获取到的数据进行排序如果有重复的则进行筛除
data_list=[content,url,time_cf]
list2 = sorted(list(set(data_list)), key=data_list.index)
try:
# 插入数据
cursor.execute(sql,list2)
# 连接数据
conn.commit()
print('插入数据成功')
except Exception as e:
print('插入数据失败')
conn.rollback()
time.sleep(5)
conn.close()
if __name__ == "__main__":
index()
然后进行爬虫就会看到数据已经存入数据库当中

然后进入我们的爬虫后台就会看到相应的数据在这里显示出来
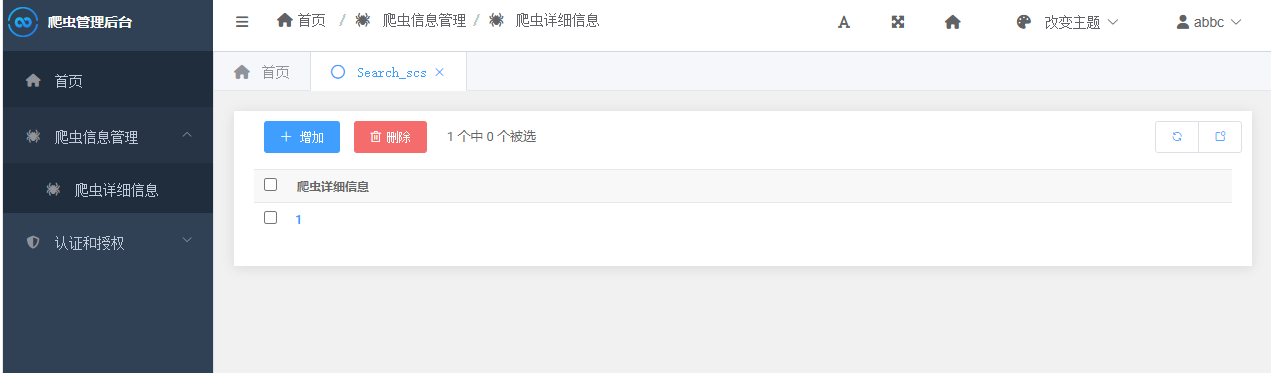
点击可进行修改的操作,但是目前来看如果后期数据量多还需要一个上传和下载的功能
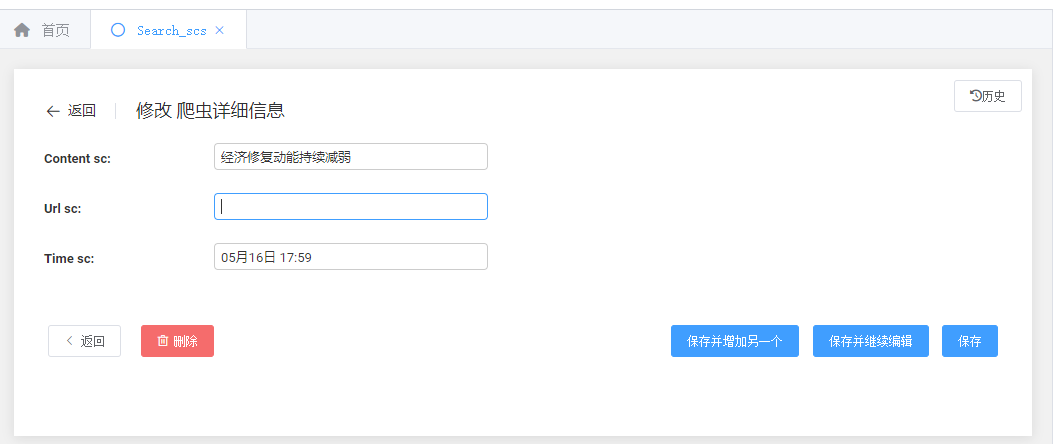
7.Django新增导入导出功能
需要安装Django-import-export
pip3 install django-import-export
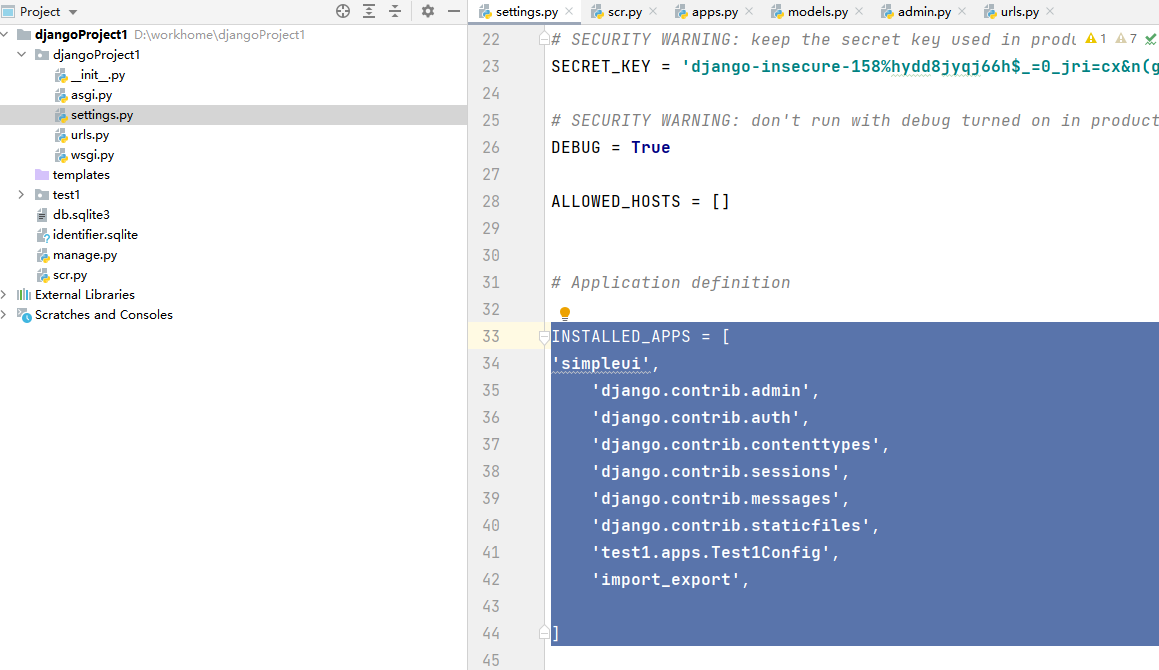
然后在settings.py中注册一下
INSTALLED_APPS = [
'simpleui',
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'test1.apps.Test1Config',
'import_export',
]
#新增导入导出为TRUE
IMPORT_EXPORT_USE_TRANSACTIONS = True
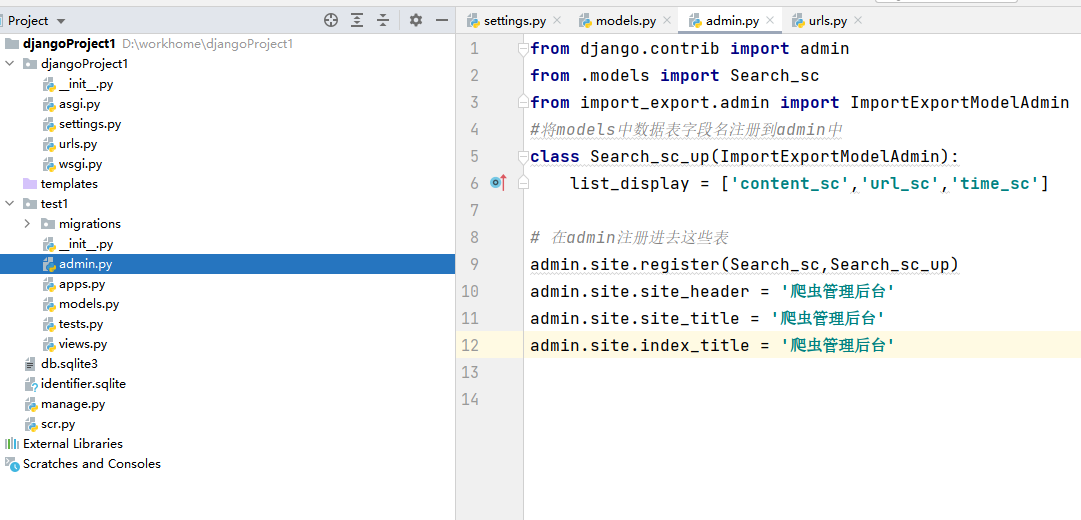
然后在admin.py中新增功能,并让表中继承插件
from django.contrib import admin
from .models import Search_sc
from import_export.admin import ImportExportModelAdmin
#将models中数据表字段名注册到admin中
class Search_sc_up(ImportExportModelAdmin):
list_display = ['content_sc','url_sc','time_sc']
# 在admin注册进去这些表
admin.site.register(Search_sc,Search_sc_up)
admin.site.site_header = '爬虫管理后台'
admin.site.site_title = '爬虫管理后台'
admin.site.index_title = '爬虫管理后台'
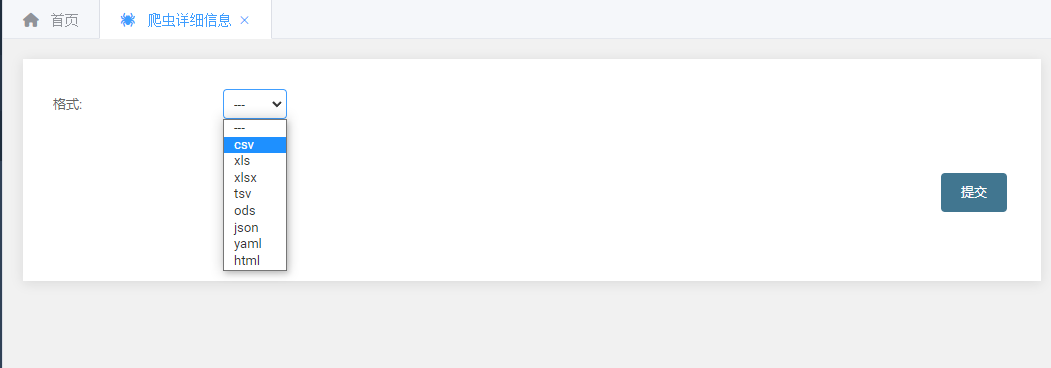
全部做好后重启Django服务器,既可看到新增了导入和导出的功能
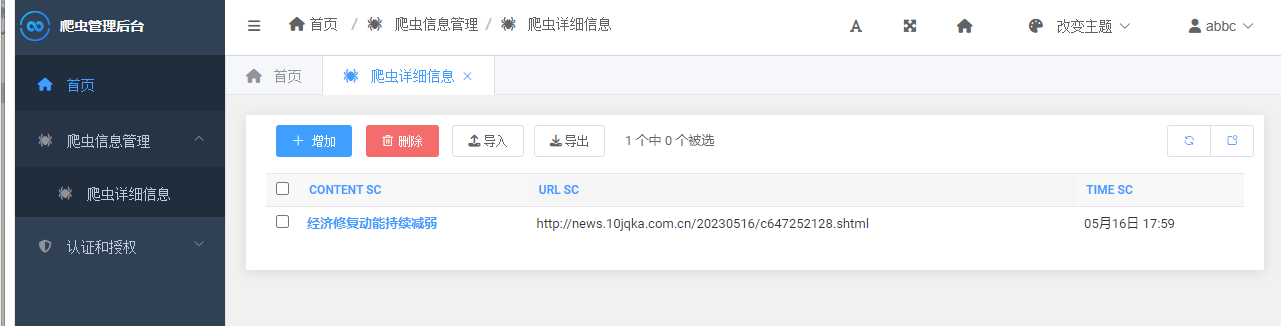
可根据以下这些格式进行导入导出