文章目录
- 九、消息业务的核心之消息可达性、一致性、幂等性、实时性
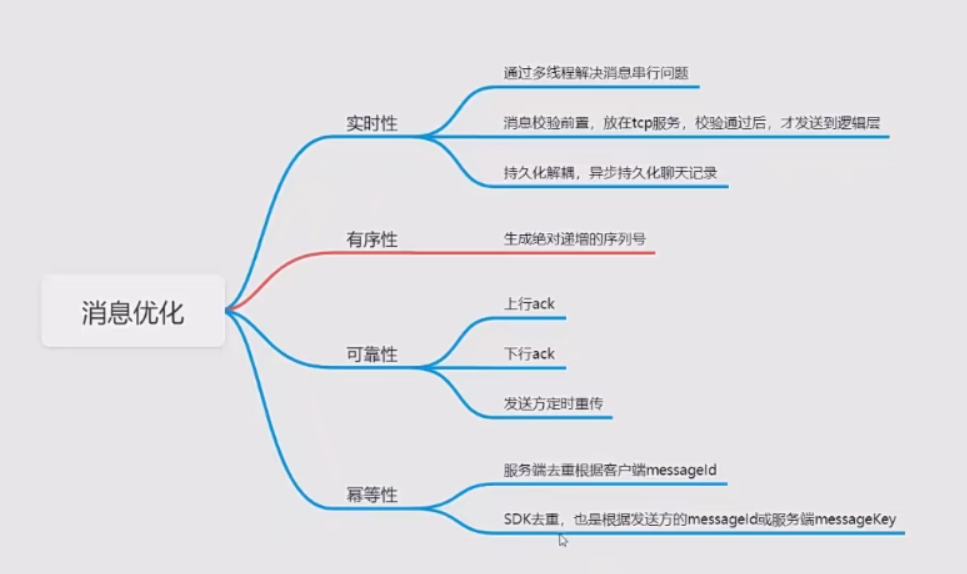
- 1、消息实时性—利用多线程解决消息串行的问题,提高处理效率
- 2、消息实时性—校验逻辑前置由tcp通过feign接口提前校验
- 3、消息实时性—利用mq异步持久化消息
- 4、用了TCP就不会丢包、丢消息了吗?
- 5、单人消息可靠性—双重ACK保证上下行消息可靠
- 6、单人消息有序性—消息并行可能导致消息乱序
- 7、单人消息幂等性—保证消息不重复
- 8、群聊消息实时性—消息并行、持久化解耦、前置校验
- 9、群聊消息有序性—消息并行可能导致消息乱序
- 10、群聊消息消息幂等性—保证消息不重复
- 11、详解消息已读等的实现方案
- 12、构建聊天会话—消息已读功能实现
- 13、离线消息—离线消息设计和实现
- 十、揭秘QQ、微信数据同步的演进
- 1、剖析qq和微信背后数据同步的完整过程
- 2、如何将好友关系链、会话、群组全量拉取改为增量拉取
- 3、手把手带你实现增量同步接口
- 4、获取某个用户的req
- 5、如何实现增量拉取离线消息
项目源代码
九、消息业务的核心之消息可达性、一致性、幂等性、实时性
- 实时性:发送的消息很快的发送到对方(苹果手机的微信)
- 有序性:发送的消息按照发送的消息顺序到达对方
- 可靠性:发送的消息一定要到达对方
- 幂等性:发送的一条消息要保证到对方只收到这一条消息的一份,而不是多份
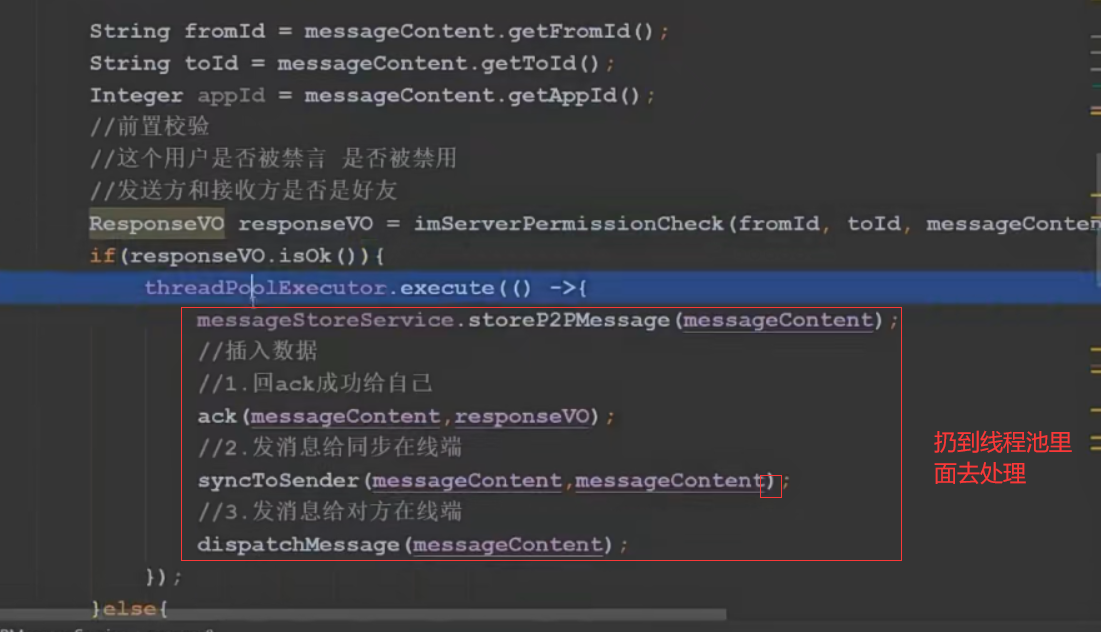
1、消息实时性—利用多线程解决消息串行的问题,提高处理效率
也就是整个流程目前是串行的,执行完这一个,才去执行下一个,可以引入线程池去解决串行的问题,可以参考我的另一篇文章 JUC快速入门
private final ThreadPoolExecutor threadPoolExecutor;
{
final AtomicInteger atomicInteger = new AtomicInteger(0);
threadPoolExecutor
= new ThreadPoolExecutor(8, 8,
60, TimeUnit.SECONDS, new LinkedBlockingQueue<>(1000),
new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
Thread thread = new Thread(r);
thread.setDaemon(true);
thread.setName("message-process-thread-" + atomicInteger.getAndIncrement());
return thread;
}
});
}
用静态代码块初始化线程池
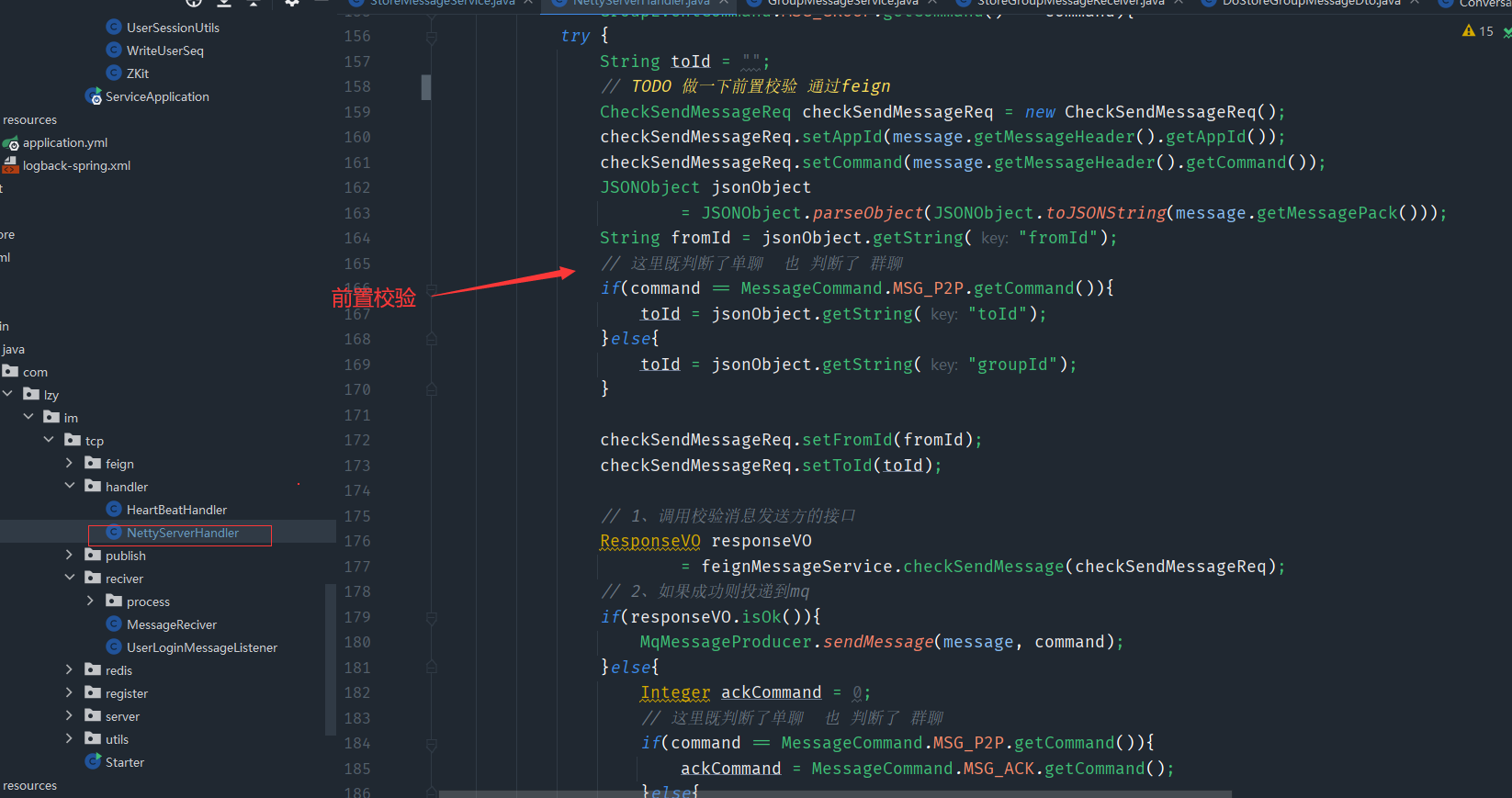
2、消息实时性—校验逻辑前置由tcp通过feign接口提前校验
前置校验,会校验禁言和好友关系,群组关系等,要进行数据库查询,而且如果这个校验没有通过的话,还会浪费rabbitmq的资源,这时候如果能把前置校验提到tcp层,那么我们逻辑层收到的消息类的mq都是合法的直接进行操作,避免浪费mq的资源,这里可以使用feign这个基于HTTP 的REST API 进行通信,或者也可以使用rpc,在tcp层调用service的方法进行前置校验即可。
<!-- feign调用依赖 -->
<dependency>
<groupId>com.netflix.feign</groupId>
<artifactId>feign-core</artifactId>
</dependency>
<dependency>
<groupId>com.netflix.feign</groupId>
<artifactId>feign-jackson</artifactId>
</dependency>
tcp层调用feign的配置
public interface FeignMessageService {
@Headers({"Content-Type: application/json", "Accept: application/json"})
@RequestLine("POST /message/checkSend")
public ResponseVO checkSendMessage(CheckSendMessageReq checkSendMessageReq);
}
这个是逻辑层的接口
@RequestMapping("/checkSend")
public ResponseVO checkSend(@RequestBody CheckSendMessageReq req){
return p2PMessageService.imeServerPermissionCheck(req.getFromId(), req.getToId(), req.getAppId());
}
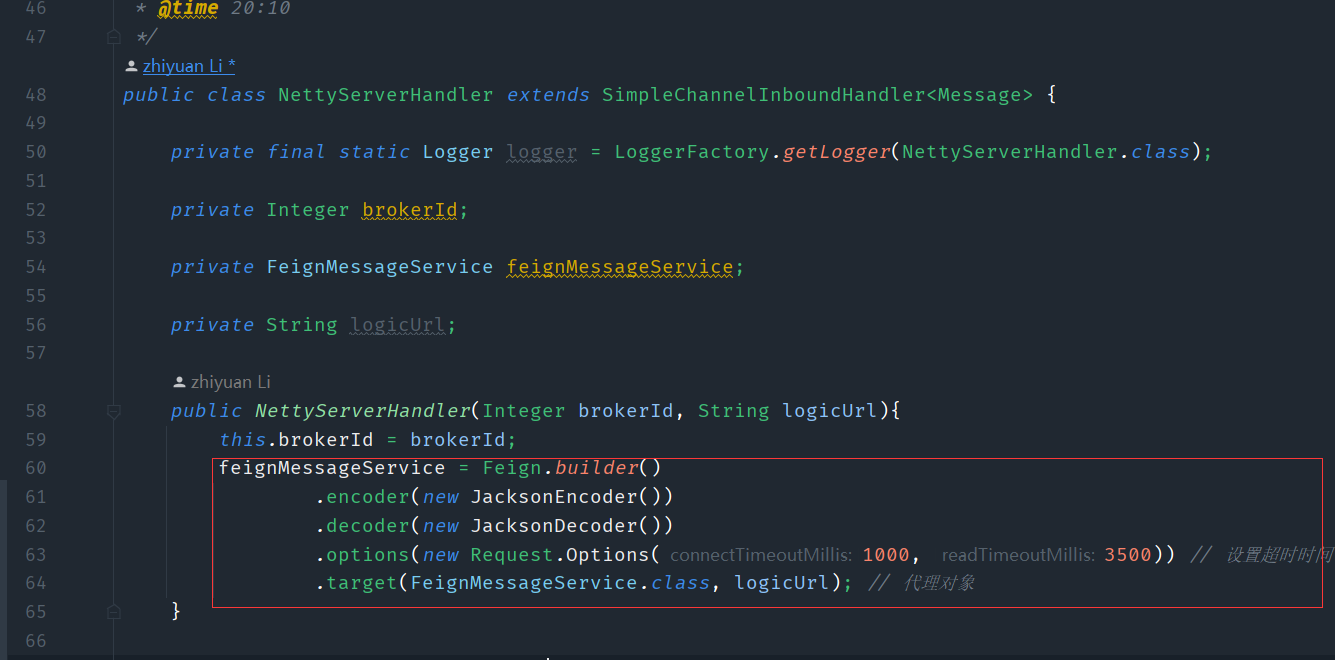
初始化feign
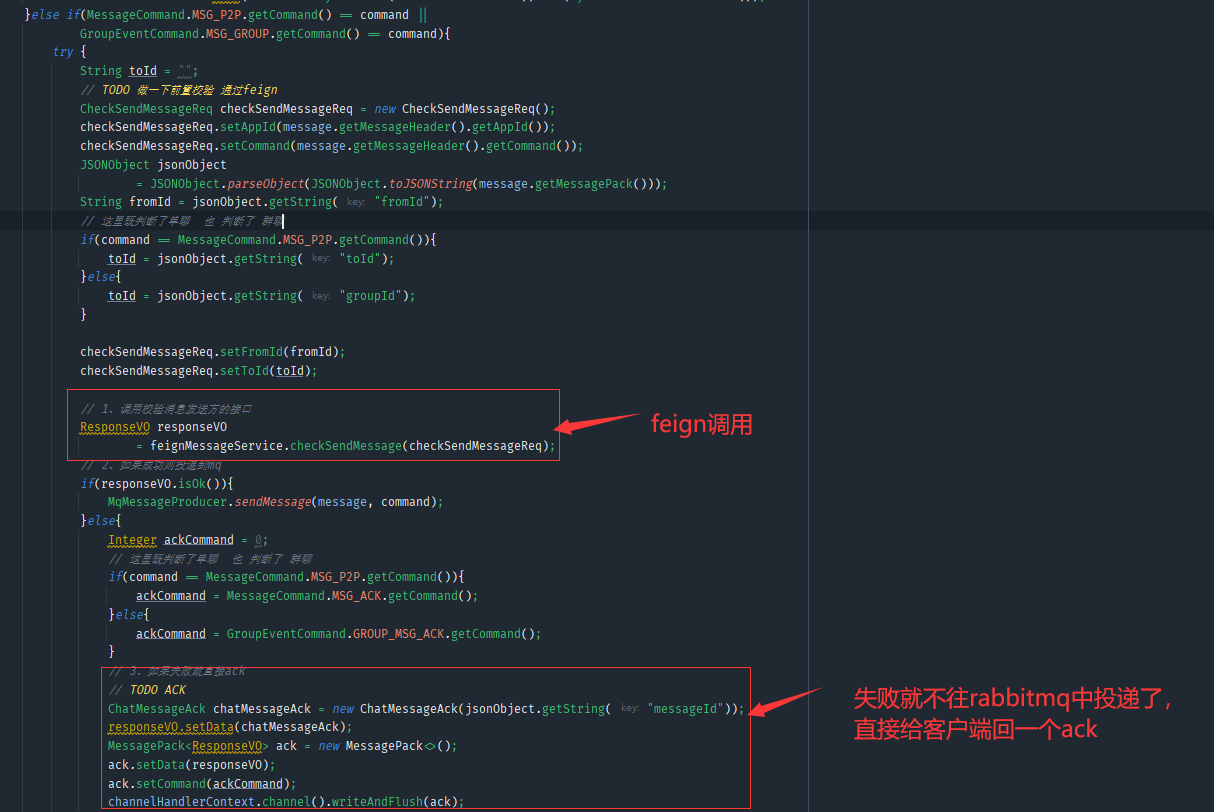
然后就可以把service层单聊和群聊的process中的前置校验给去掉了,已经在tcp层做好了
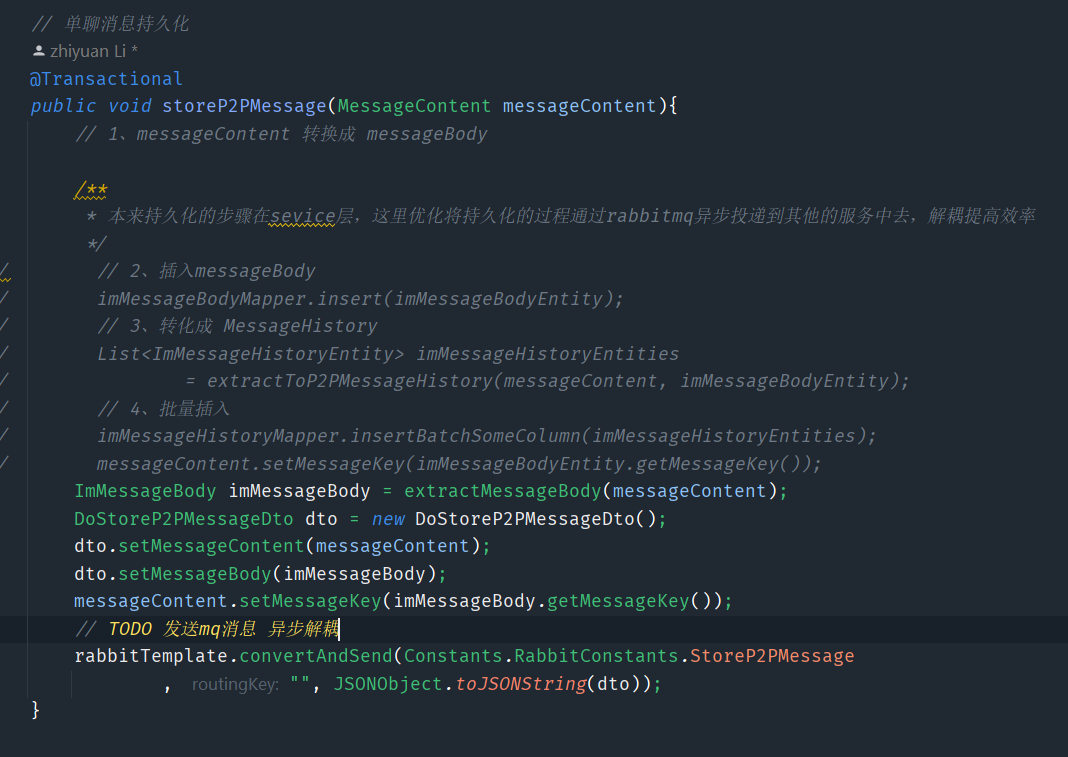
3、消息实时性—利用mq异步持久化消息
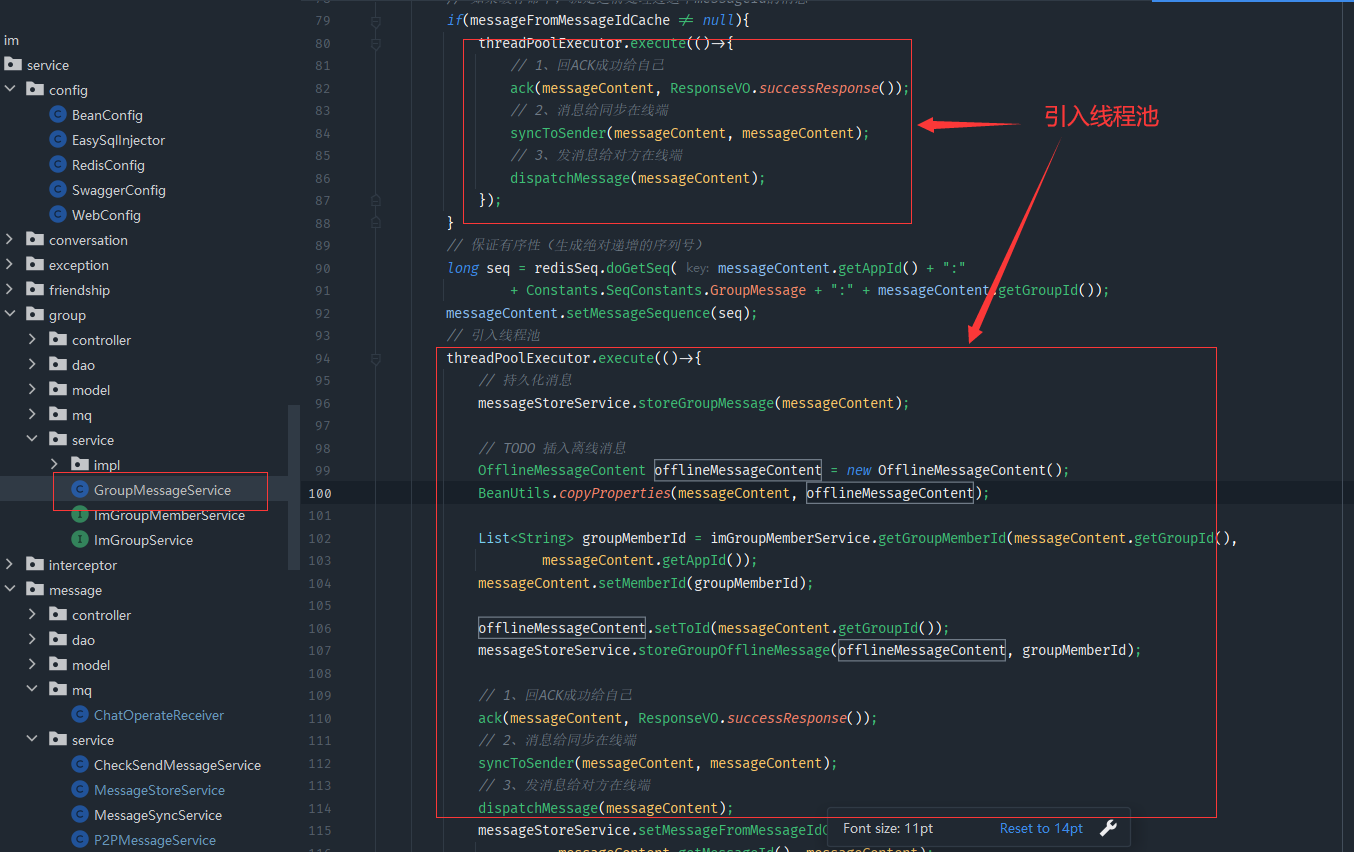
突然想到了实时性也就是尽量让im服务处理的效率更快,所以如果将单独的存储服务通过mq异步解耦出去的话,也会优化很大一部分的

4、用了TCP就不会丢包、丢消息了吗?
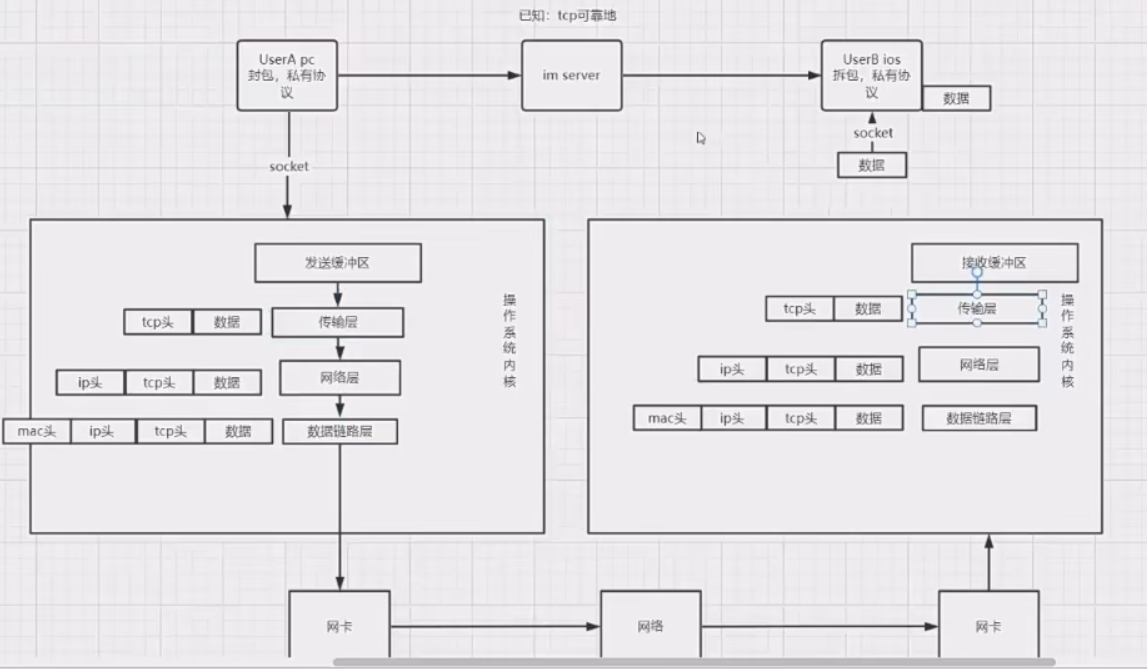
- tcp是保证传输层到传输层之间是可靠的,到达对方的接收缓冲区是可靠的,但是到接收缓冲区到上层的时候,就不保证是不是可靠的,如果上层是一个手机,数据从接收缓冲区出去,但是手机关机了,这个数据就算丢了
- 还有如果我们发送完一条消息以后,消息需要持久化到本地,这时手机没电了,这个持久化的数据就可能不会被存储起来了
- 所以说我们还要自己完善一下消息的可靠性
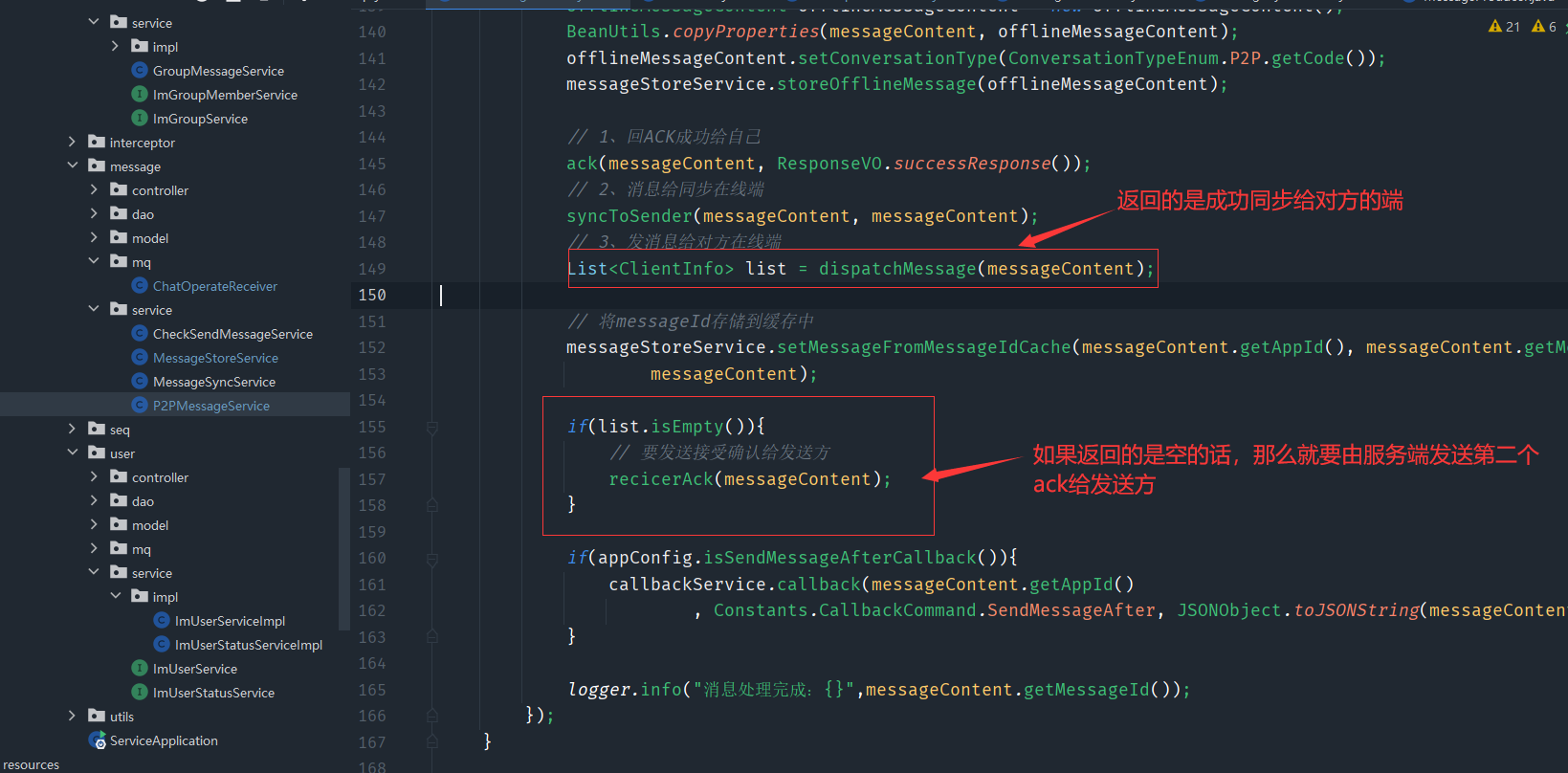
5、单人消息可靠性—双重ACK保证上下行消息可靠
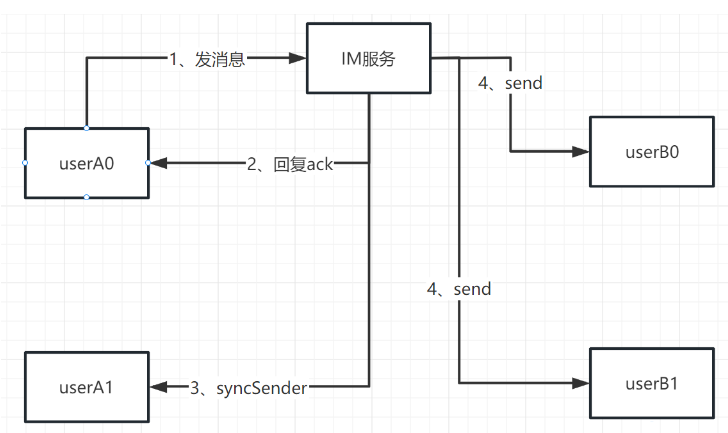
这时之前的单发的逻辑
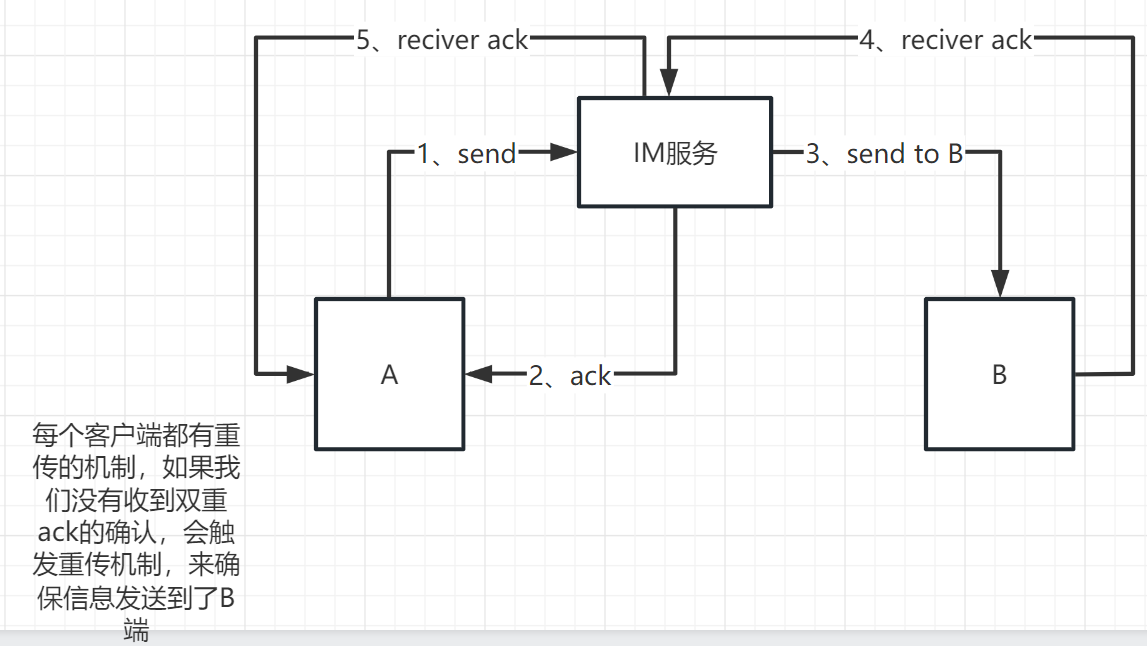
双重ack的逻辑
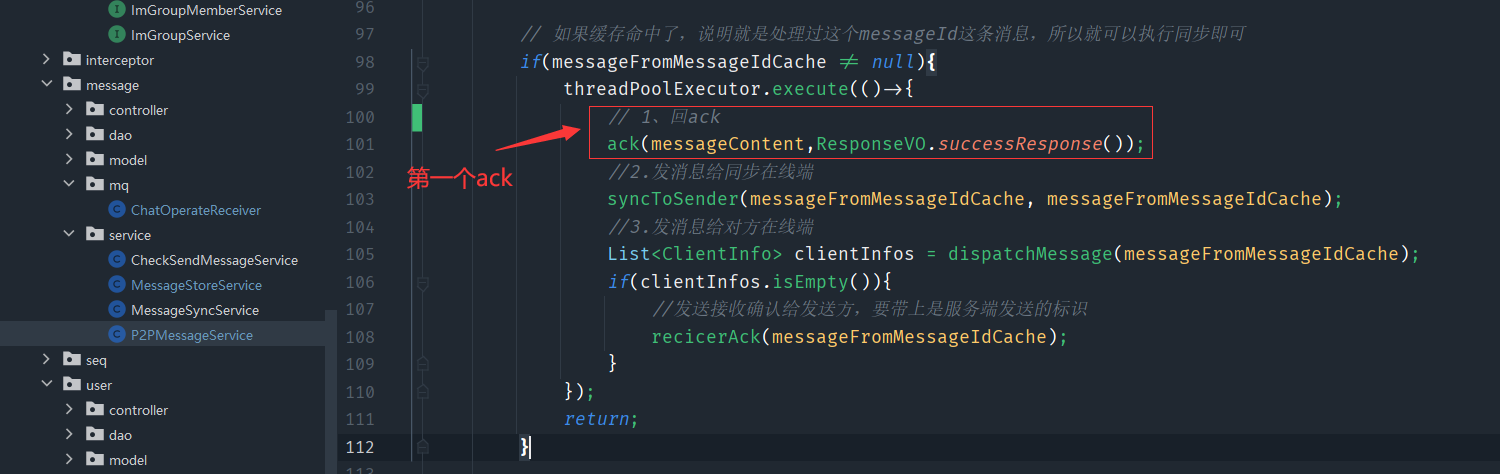
然后im服务把消息同步到我端和对方端,对方客户端收到了之后,就会发起一个MSG_RECIVE_ACK的请求,这就是第二个ack,当imserver收到这个请求的时候
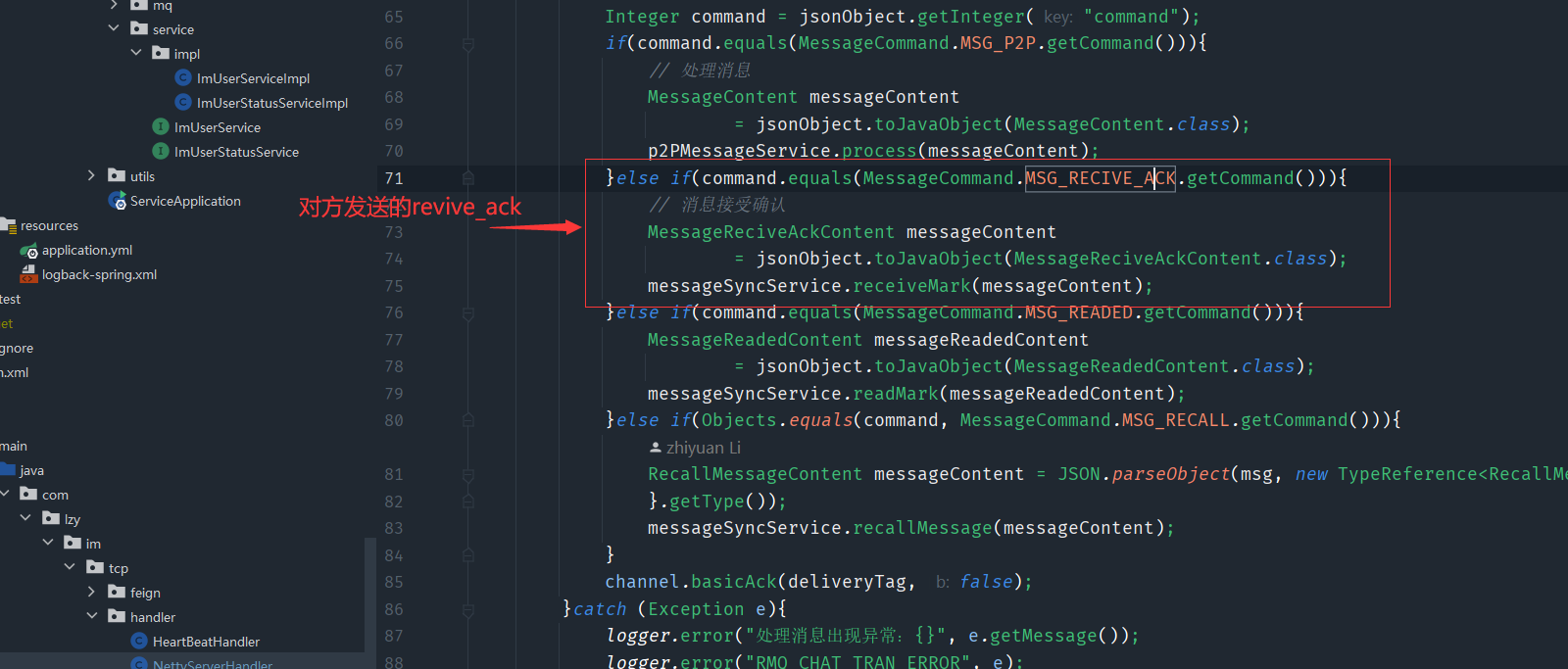
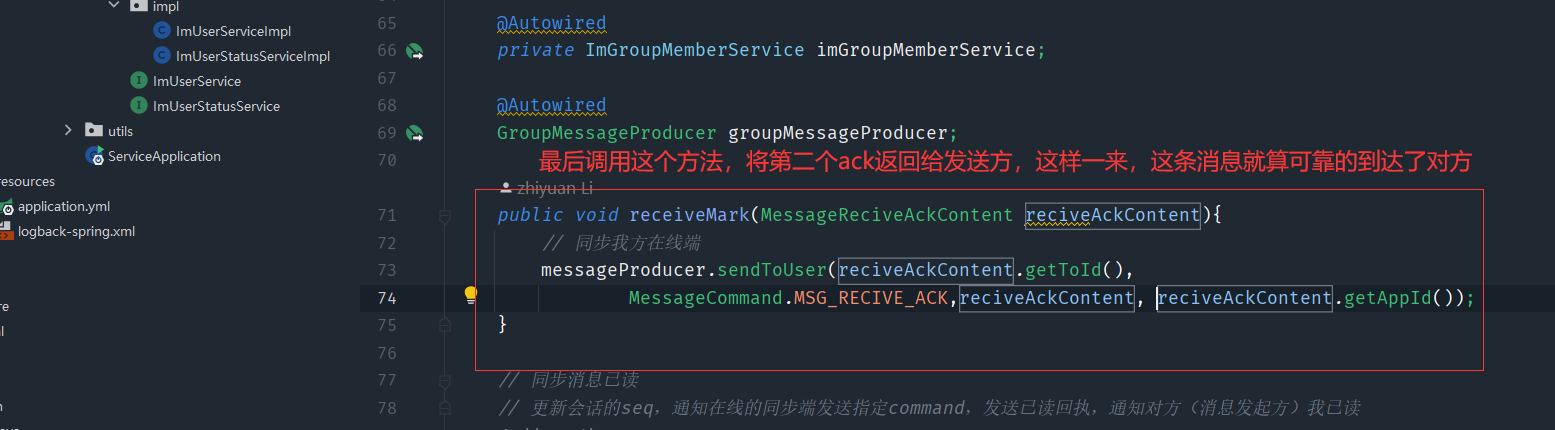
这样大致就是实现过程,但是这只是对方在线的状态,如果对方没有在线的话
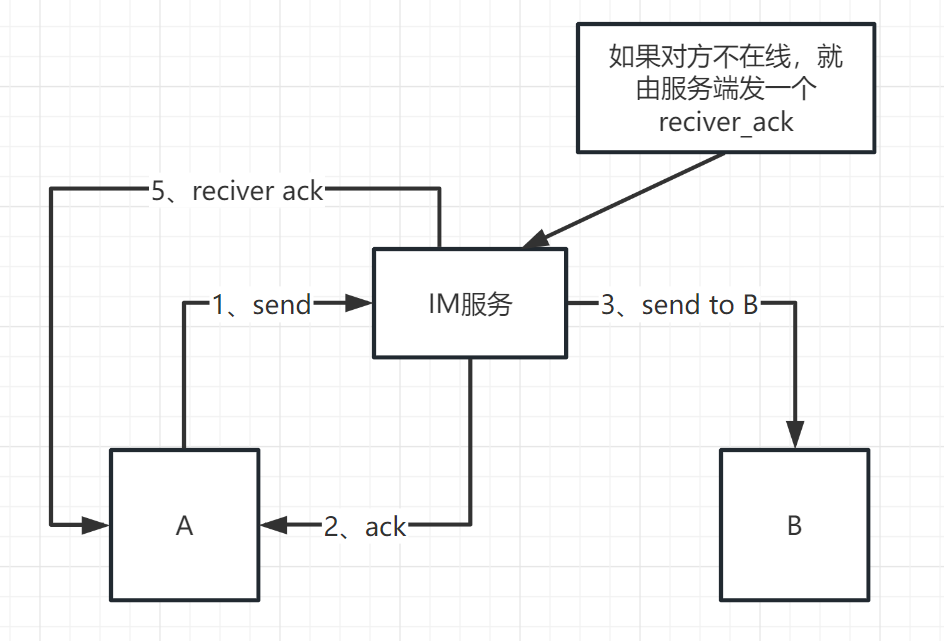
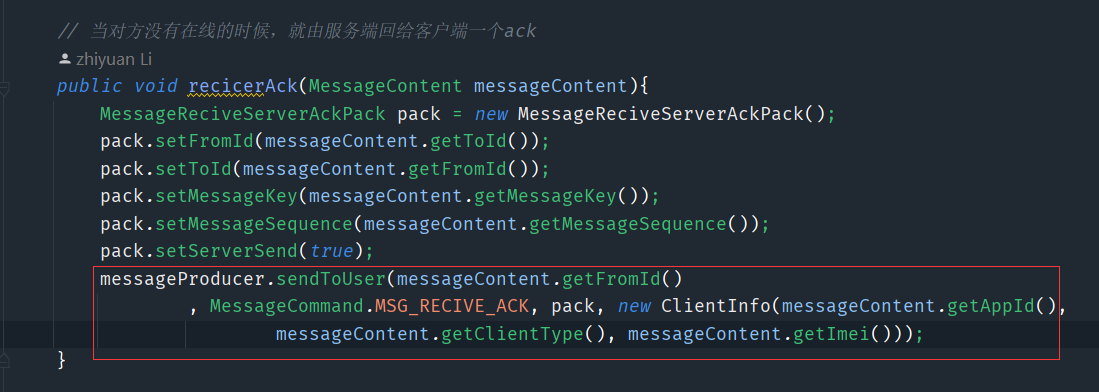
6、单人消息有序性—消息并行可能导致消息乱序
串行执行不会导致消息乱序,但是对于高并发的场景,串行的效率是在是太低了,所以不得不使用并行的方式,所以要寻找一种方案来解决乱序
方案:
- 发送时间作为排序的标准,但是客户端的时间是可以自己去修改的,这也就导致了不确定性
- 雪花算法:用生成的key去做排序,生成的key是趋势递增的,不是绝对递增的,在一定的场景下,他还是可能导致消息的乱序
- 服务端可以用一些手段生成绝对递增的序列号,比如使用redis,但是比较依赖redis的可用性
这里采用的是第三种方案
封装一个Redis的工具类
@Service
public class RedisSeq {
@Autowired
StringRedisTemplate stringRedisTemplate;
public long doGetSeq(String key){
return stringRedisTemplate.opsForValue().increment(key);
}
}
每次调用这个都会有固定的原子性加一
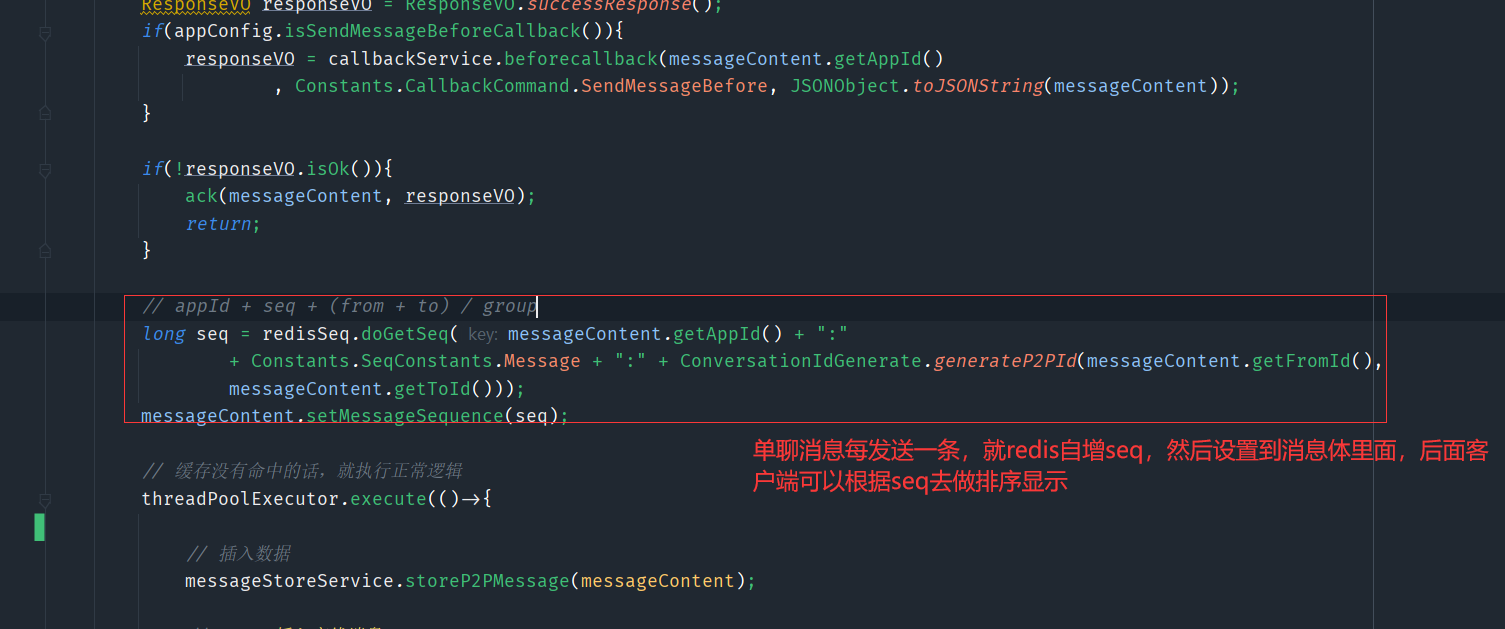
也就是说只要消息经过了im服务端,就都会获得一个绝对自增的seq做为排序的条件,无论是发送还是存储(没有写全,这里就说个大致的意思)
7、单人消息幂等性—保证消息不重复
因为有重传的机制,所以有可能有网络延迟导致没有收到双重ack,会导致消息重传,最后导致接收方可能收到多条相同的消息,并且相同的消息我们可能会在imserver处理两次(比如说持久化,这样就很不好了),我们要处理这个问题
方案
-
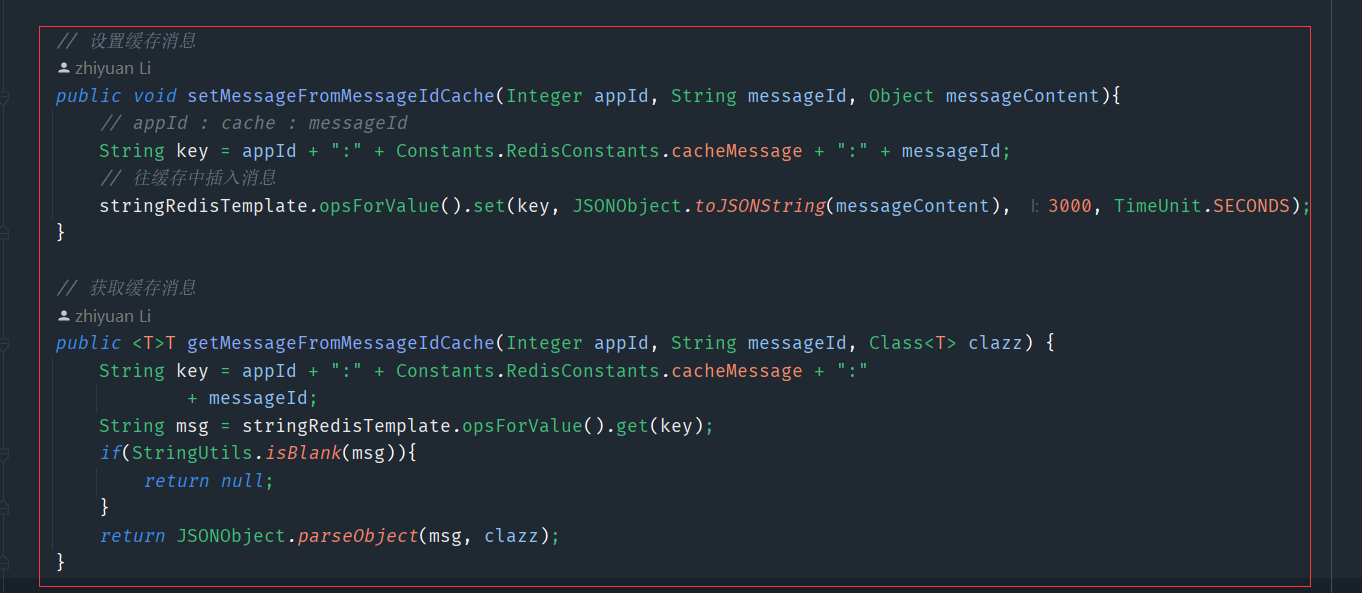
im服务端搞点文章,比如第一次处理该消息的时候,可以将它缓存到redis中(设置过期时间),当第二次处理的时候,可以从redis寻找这个消息,如果找到了就说明处理过了,所以就不二次持久化了,只用去同步消息即可
-
我们也可以在客户端做一些改造,比如说重传的消息都会是同一个messageId(可以当做上面那个查询redis的依据),客户端收到多条messageId的消息,可以过滤掉重复的,只显示一条消息即可
-
如果说一条消息,重传了一定的时间段后,还没有收到ack的话,就可以将它放弃了(就像微信没有网络,最后出现一个红色的感叹号),当我们再手动点击红色的感叹号,sdk就会生成一个新的id和旧的消息体,再次去发送

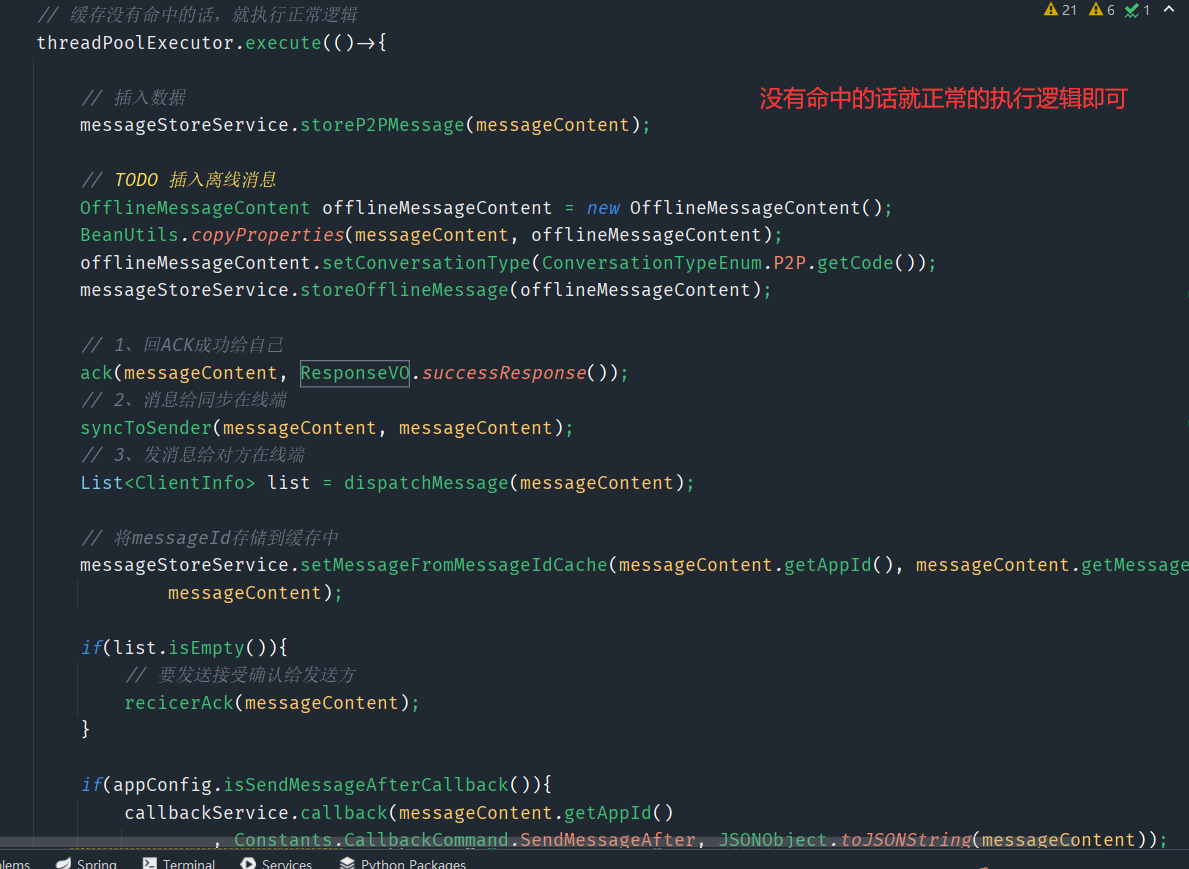
单聊优化总结
8、群聊消息实时性—消息并行、持久化解耦、前置校验
像单聊一样,把这些东西再重复的做一遍

9、群聊消息有序性—消息并行可能导致消息乱序
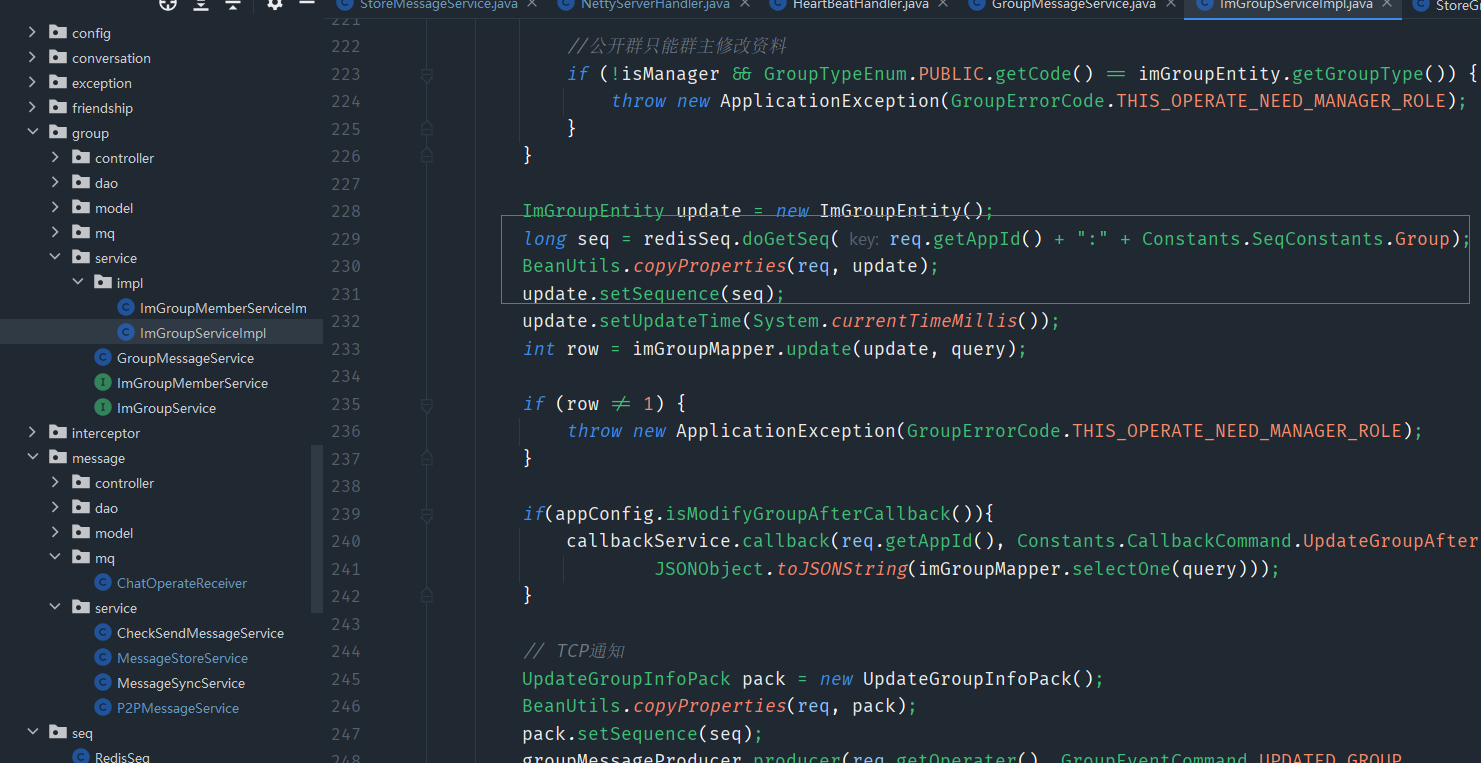
10、群聊消息消息幂等性—保证消息不重复
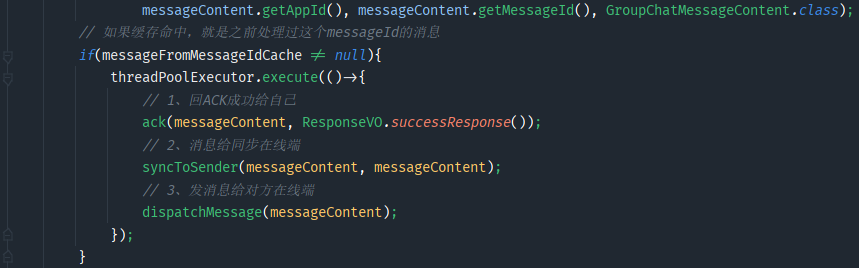
和单聊的都差不多的思路,这个也就是加一个缓存,大部分还是要在sdk做修改
11、详解消息已读等的实现方案
是否实现已读功能还是基于你的业务
方案
- 写扩散:我们的消息索引数据有很多份,我们可以给每条消息索引加上一条字段,是否已读的字段,当我们进入聊天界面的时候,可以给服务端上报,将已读的messagekey上报给服务端,服务端根据已读的messagekey修改消息的已读的状态
- 读扩散:用一个值来记录群成员读到了哪条消息,这个值前面的消息都算已读,有两个地方可以加上这个值,一个是群成员表,将最后一条消息的seq设置到对应群成员的字段上,还有一种方案,将这个值和会话绑定,比如说群里面有500个成员,就有500个会话,构建一个会话的概念,每一个会话都有自己的一个值来记录已读到哪条数据了,用一张表记录用户和用户之间的已读的消息篇序
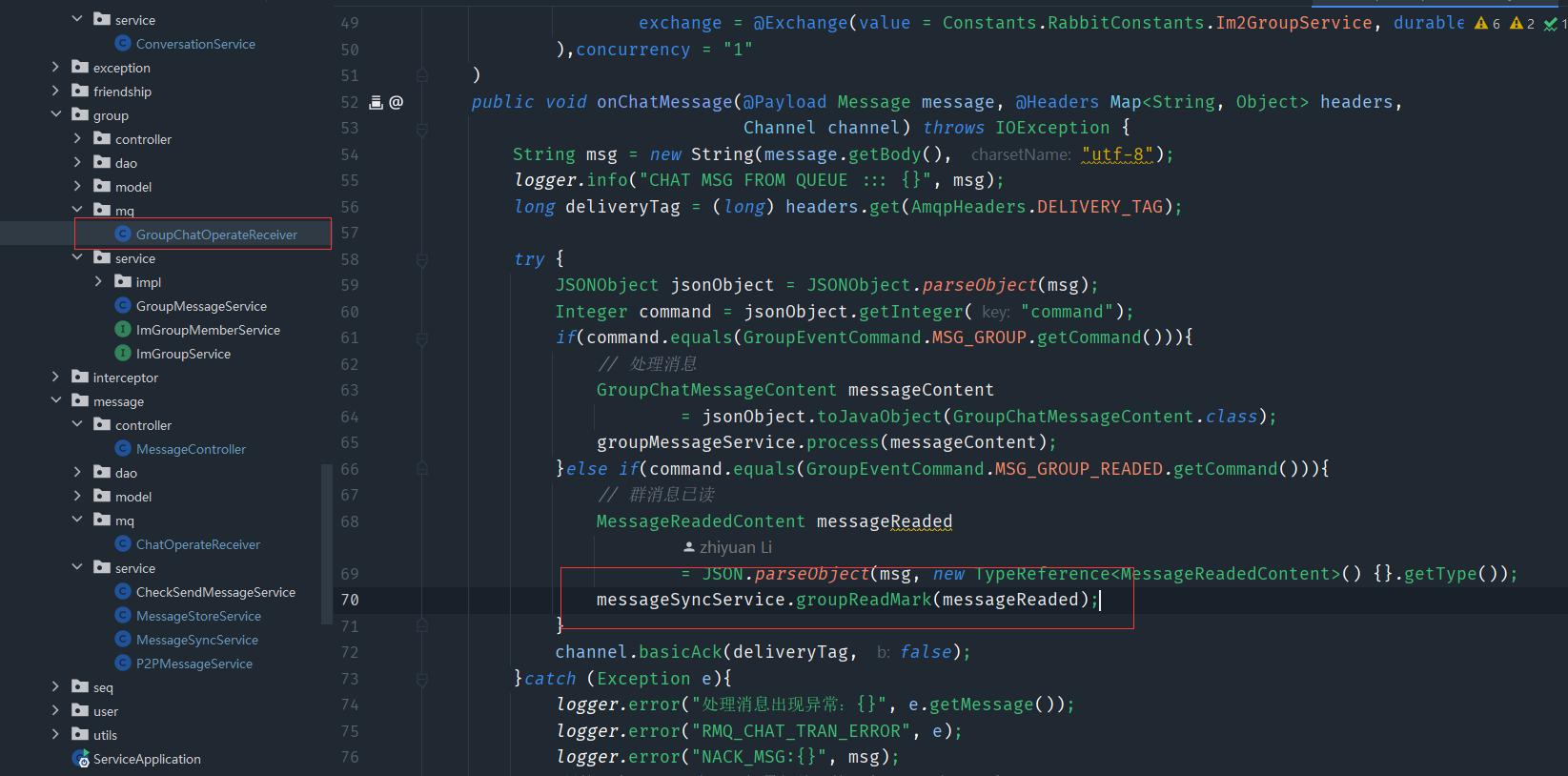
12、构建聊天会话—消息已读功能实现
当对方读取了这条消息后,我们要接收到已读的这条命令,然后做出对应的处理
- 更新会话的seq
- 同步我方的端
- 并且给原发送端发送已读回执
@Service
public class WriteUserSeq {
// redis
// uid friend group conversation
@Autowired
private RedisTemplate redisTemplate;
// 修改消息的seq值
public void writeUserSeq(Integer appId, String userId, String type, Long seq){
String key = appId + ":" + Constants.RedisConstants.SeqPrefix + ":" + userId;
redisTemplate.opsForHash().put(key, type, seq);
}
}
修改redis中存储已读消息的seq的工具类
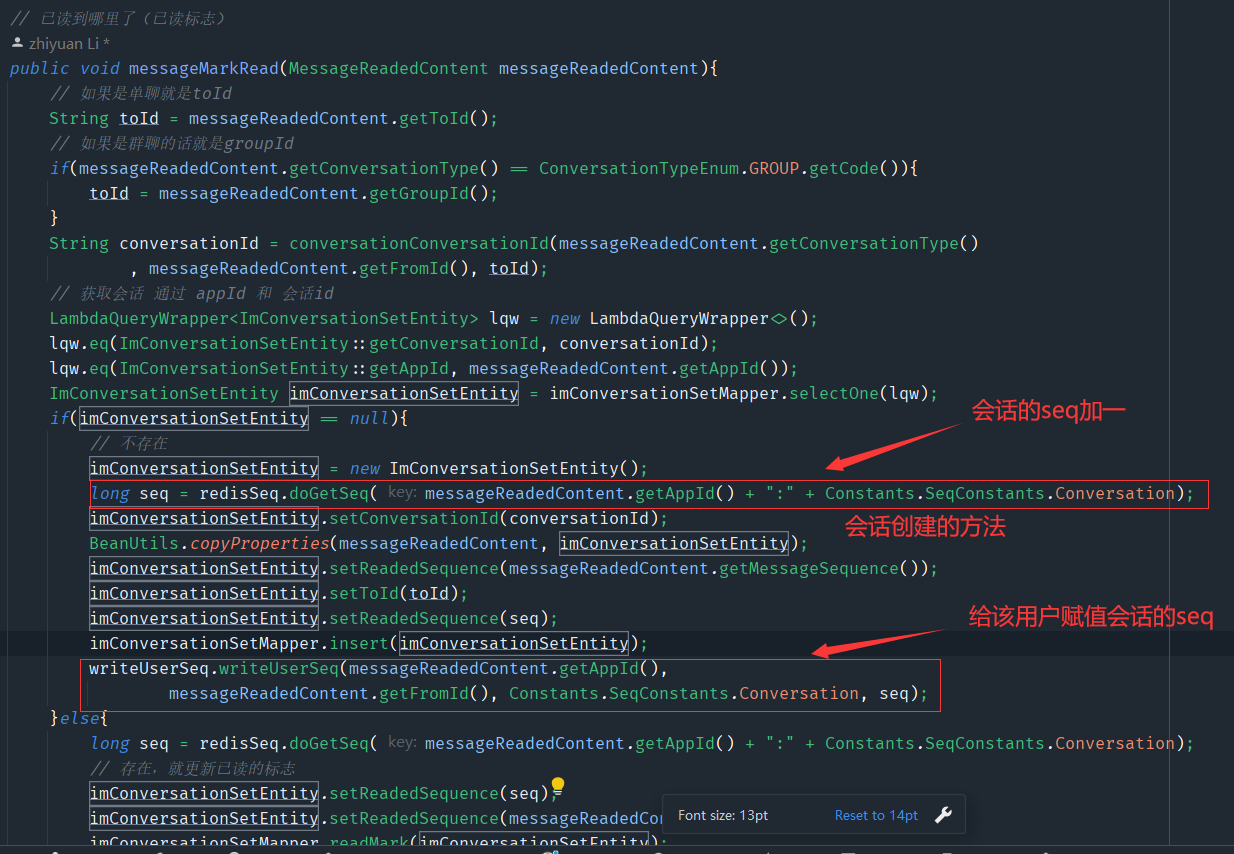
public void messageMarkRead(MessageReadedContent messageReadedContent){
// 如果是单聊就是toId
String toId = messageReadedContent.getToId();
// 如果是群聊的话就是groupId
if(messageReadedContent.getConversationType() == ConversationTypeEnum.GROUP.getCode()){
toId = messageReadedContent.getGroupId();
}
String conversationId = conversationConversationId(messageReadedContent.getConversationType()
, messageReadedContent.getFromId(), toId);
// 获取会话 通过 appId 和 会话id
LambdaQueryWrapper<ImConversationSetEntity> lqw = new LambdaQueryWrapper<>();
lqw.eq(ImConversationSetEntity::getConversationId, conversationId);
lqw.eq(ImConversationSetEntity::getAppId, messageReadedContent.getAppId());
ImConversationSetEntity imConversationSetEntity = imConversationSetMapper.selectOne(lqw);
if(imConversationSetEntity == null){
// 不存在
imConversationSetEntity = new ImConversationSetEntity();
long seq = redisSeq.doGetSeq(messageReadedContent.getAppId() + ":" + Constants.SeqConstants.Conversation);
imConversationSetEntity.setConversationId(conversationId);
BeanUtils.copyProperties(messageReadedContent, imConversationSetEntity);
imConversationSetEntity.setReadedSequence(messageReadedContent.getMessageSequence());
imConversationSetEntity.setToId(toId);
imConversationSetEntity.setReadedSequence(seq);
imConversationSetMapper.insert(imConversationSetEntity);
writeUserSeq.writeUserSeq(messageReadedContent.getAppId(),
messageReadedContent.getFromId(), Constants.SeqConstants.Conversation, seq);
}else{
long seq = redisSeq.doGetSeq(messageReadedContent.getAppId() + ":" + Constants.SeqConstants.Conversation);
// 存在,就更新已读的标志
imConversationSetEntity.setReadedSequence(seq);
imConversationSetEntity.setReadedSequence(messageReadedContent.getMessageSequence());
imConversationSetMapper.readMark(imConversationSetEntity);
writeUserSeq.writeUserSeq(messageReadedContent.getAppId(),
messageReadedContent.getFromId(),Constants.SeqConstants.Conversation, seq);
}
}
这就是第一步更新会话的seq
// 同步消息已读
// 更新会话的seq,通知在线的同步端发送指定command,发送已读回执,通知对方(消息发起方)我已读
public void readMark(MessageReadedContent messageReadedContent) {
// 更新会话已读的位置
conversationService.messageMarkRead(messageReadedContent);
MessageReadedPack messageReadedPack = new MessageReadedPack();
BeanUtils.copyProperties(messageReadedContent, messageReadedPack);
// 把已读消息同步到自己的其他端
syncToSender(messageReadedPack, messageReadedContent, MessageCommand.MSG_READED_NOTIFY);
// 发送给原消息发送端
messageProducer.sendToUser(messageReadedContent.getToId(), MessageCommand.MSG_READED_RECEIPT,
messageReadedPack, messageReadedContent.getAppId());
}
// 把已读消息同步到自己的其他端
public void syncToSender(MessageReadedPack pack, MessageReadedContent messageReadedContent, Command command){
// 发送给自己的其它端
messageProducer.sendToUserExceptClient(pack.getFromId(),
command, pack, messageReadedContent);
}
然后是第二步第三步,同步我方,和回执
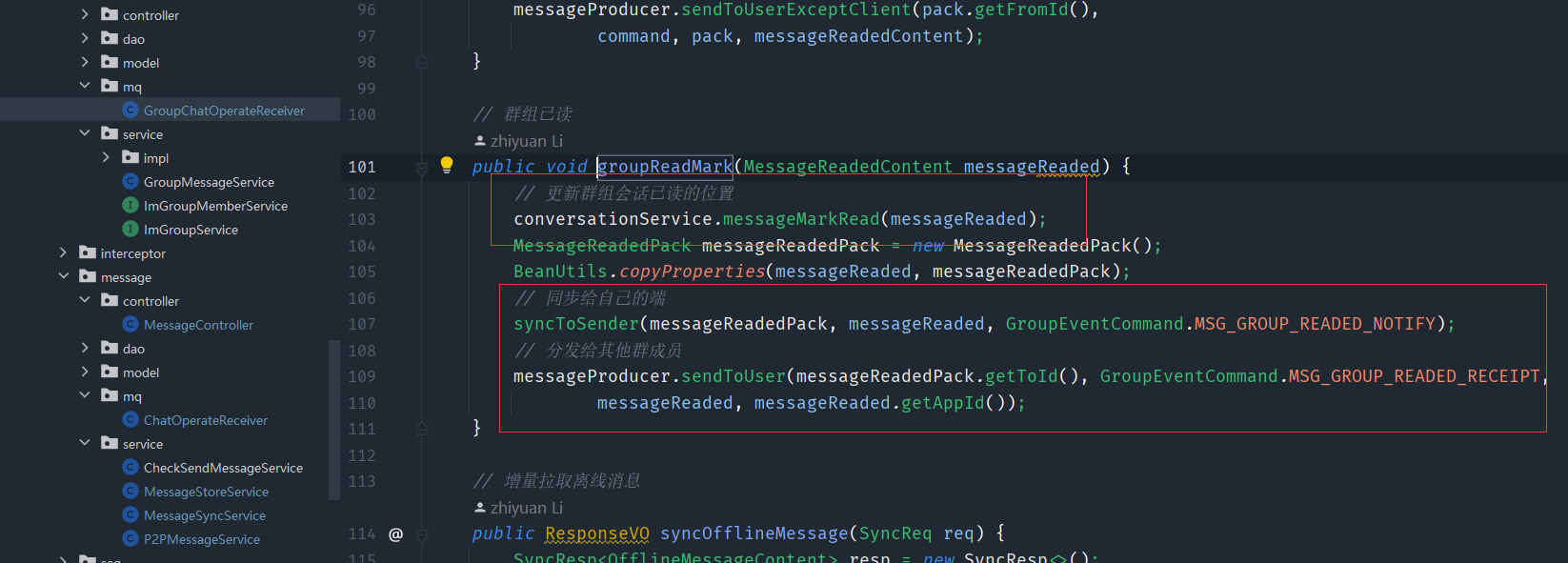
群组也是一样的道理
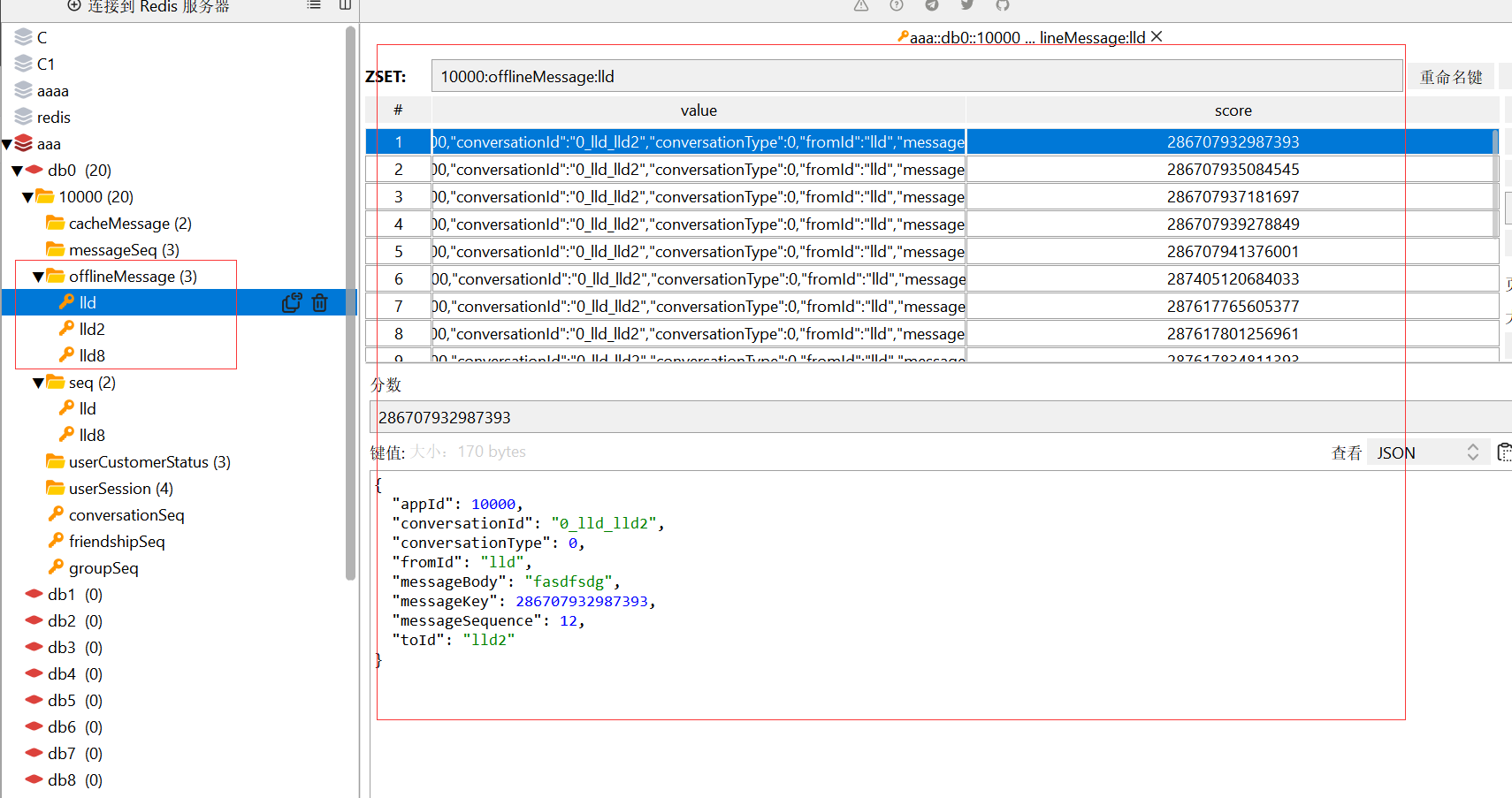
13、离线消息—离线消息设计和实现
把每条消息都放到离线消息里面,当用户上线后去里面去拉取离线消息,所以这里在处理单聊消息和群聊消息这里,就可以将离线消息也给存储了
// 存储单人离线消息(Redis)
// 存储策略是数量
public void storeOfflineMessage(OfflineMessageContent offlineMessageContent){
// 找到fromId的队列
String fromKey = offlineMessageContent.getAppId() + ":"
+ Constants.RedisConstants.OfflineMessage + ":" + offlineMessageContent.getFromId();
// 找到toId的队列
String toKey = offlineMessageContent.getAppId() + ":"
+ Constants.RedisConstants.OfflineMessage + ":" + offlineMessageContent.getToId();
ZSetOperations<String, String> operations = stringRedisTemplate.opsForZSet();
// 判断 队列中的数据 是否 超过设定值
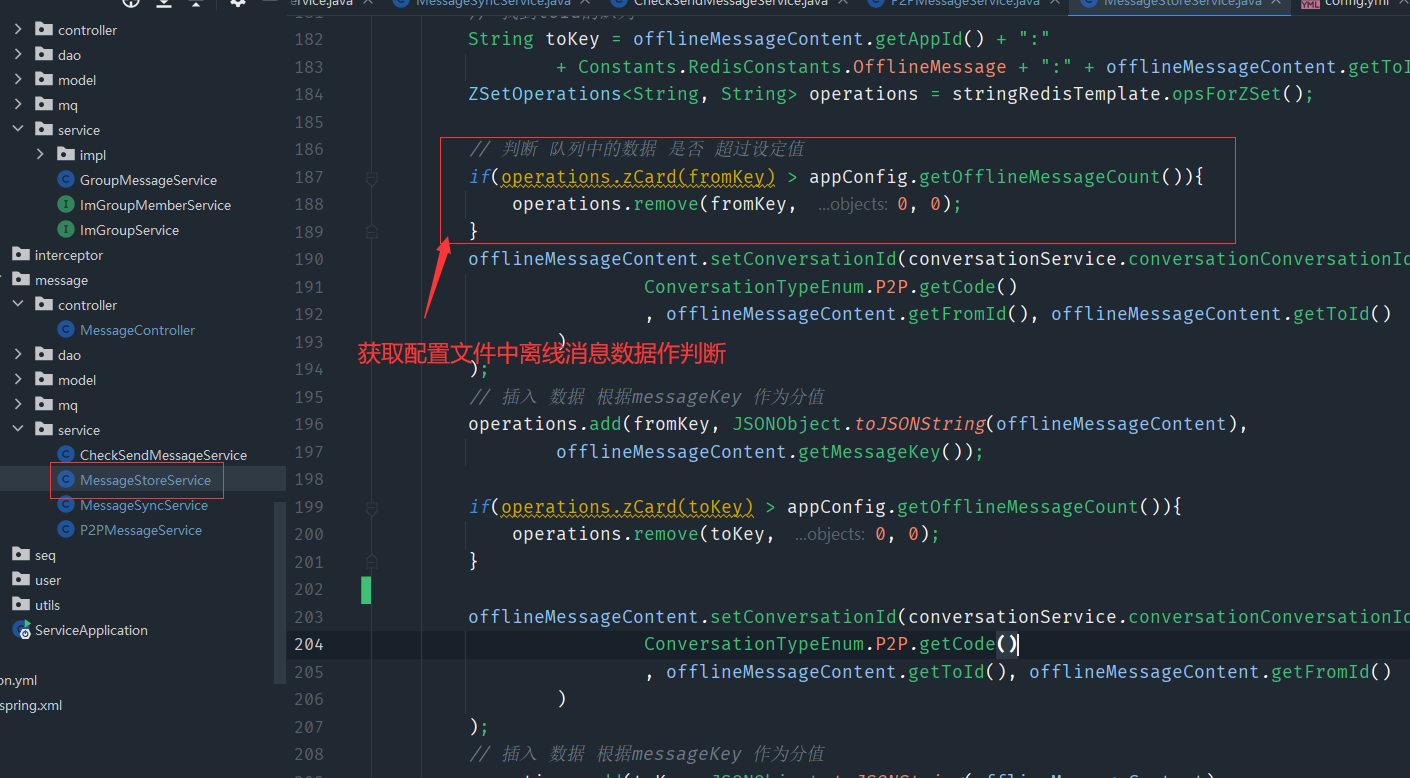
if(operations.zCard(fromKey) > appConfig.getOfflineMessageCount()){
operations.remove(fromKey, 0, 0);
}
offlineMessageContent.setConversationId(conversationService.conversationConversationId(
ConversationTypeEnum.P2P.getCode()
, offlineMessageContent.getFromId(), offlineMessageContent.getToId()
)
);
// 插入 数据 根据messageKey 作为分值
operations.add(fromKey, JSONObject.toJSONString(offlineMessageContent),
offlineMessageContent.getMessageKey());
if(operations.zCard(toKey) > appConfig.getOfflineMessageCount()){
operations.remove(toKey, 0, 0);
}
offlineMessageContent.setConversationId(conversationService.conversationConversationId(
ConversationTypeEnum.P2P.getCode()
, offlineMessageContent.getToId(), offlineMessageContent.getFromId()
)
);
// 插入 数据 根据messageKey 作为分值
operations.add(toKey, JSONObject.toJSONString(offlineMessageContent),
offlineMessageContent.getMessageKey());
}
// 存储群组离线消息(Redis)
// 存储策略是数量
public void storeGroupOfflineMessage(OfflineMessageContent offlineMessageContent,
List<String> memberIds){
ZSetOperations<String, String> operations = stringRedisTemplate.opsForZSet();
offlineMessageContent.setConversationType(ConversationTypeEnum.GROUP.getCode());
for (String memberId : memberIds) {
// 找到toId的队列
String toKey = offlineMessageContent.getAppId() + ":"
+ Constants.RedisConstants.OfflineMessage + ":" + memberId;
offlineMessageContent.setConversationId(conversationService.conversationConversationId(
ConversationTypeEnum.GROUP.getCode()
, memberId, offlineMessageContent.getToId())
);
// 判断 队列中的数据 是否 超过设定值
if(operations.zCard(toKey) > appConfig.getOfflineMessageCount()){
operations.remove(toKey, 0, 0);
}
// 插入 数据 根据messageKey 作为分值
operations.add(toKey, JSONObject.toJSONString(offlineMessageContent),
offlineMessageContent.getMessageKey());
}
}
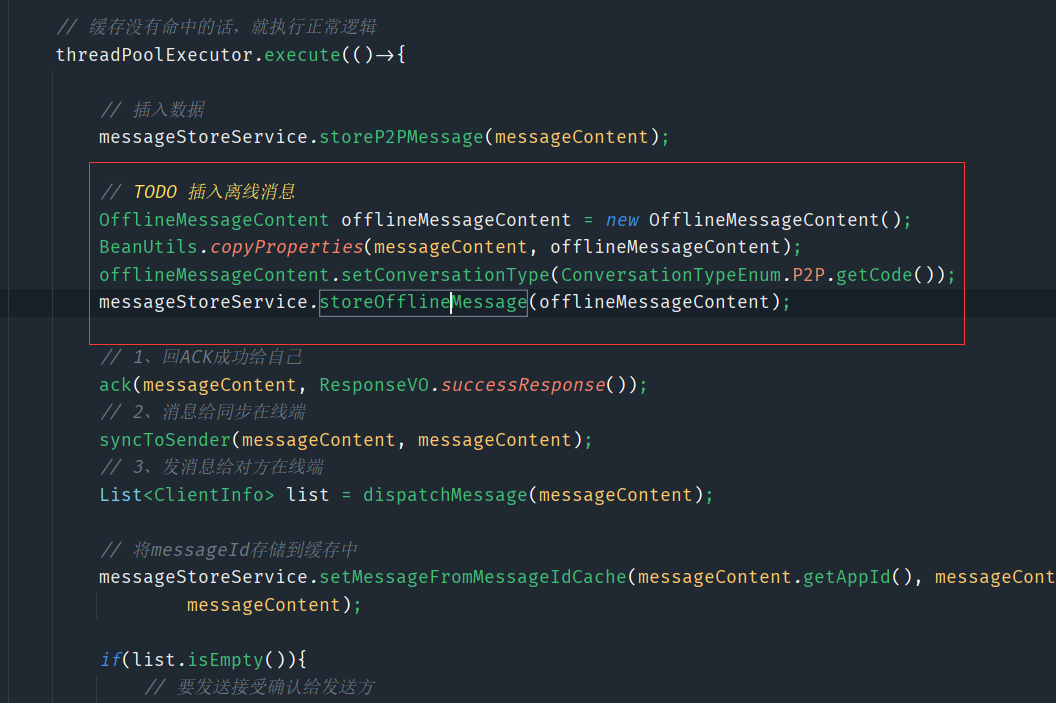

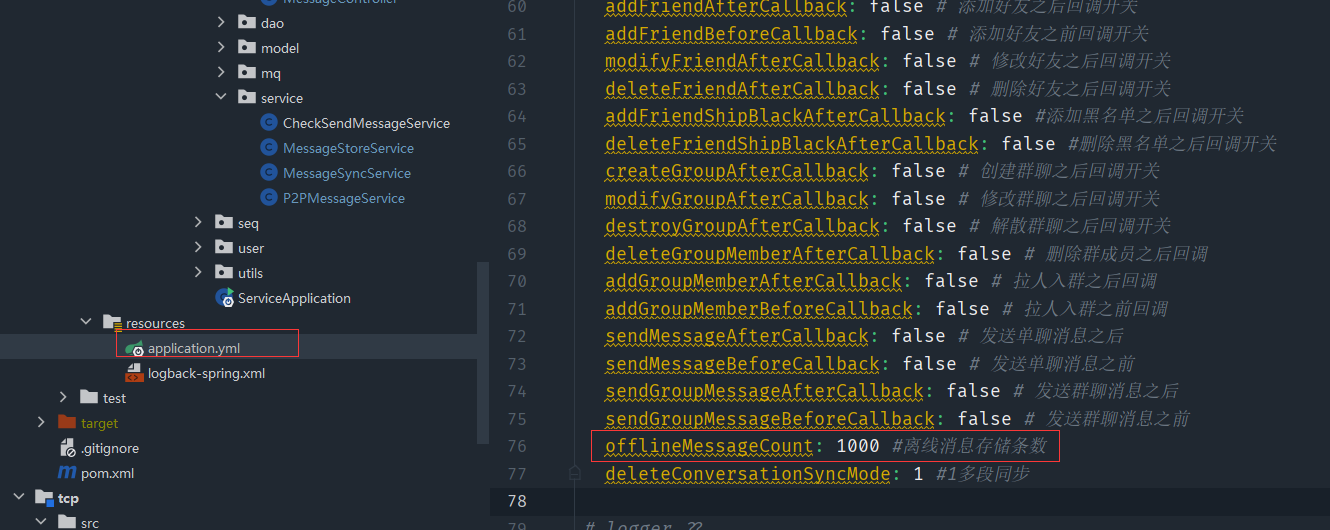
我们可以把离线消息多少条数据维护在配置文件中
十、揭秘QQ、微信数据同步的演进
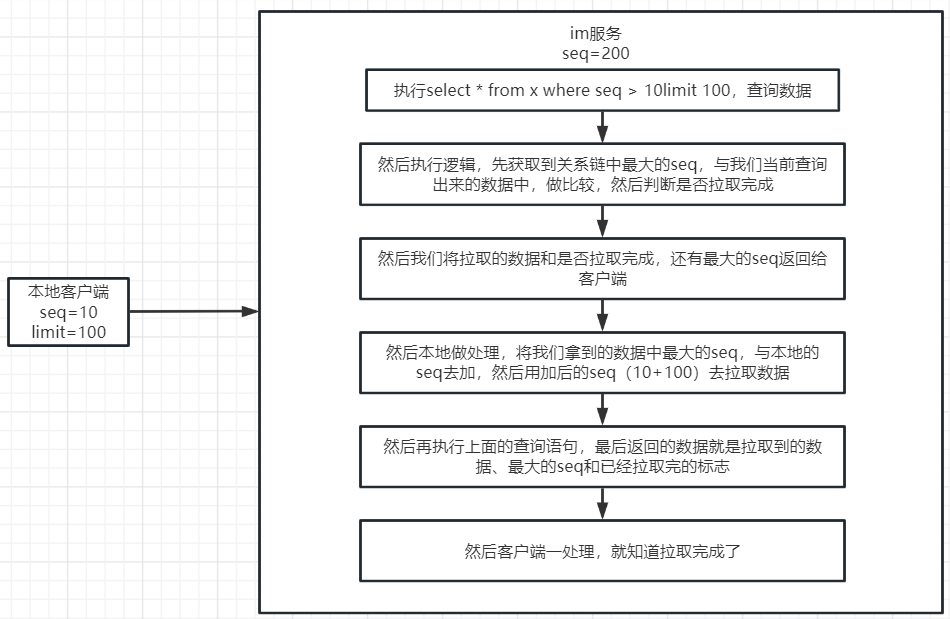
1、剖析qq和微信背后数据同步的完整过程
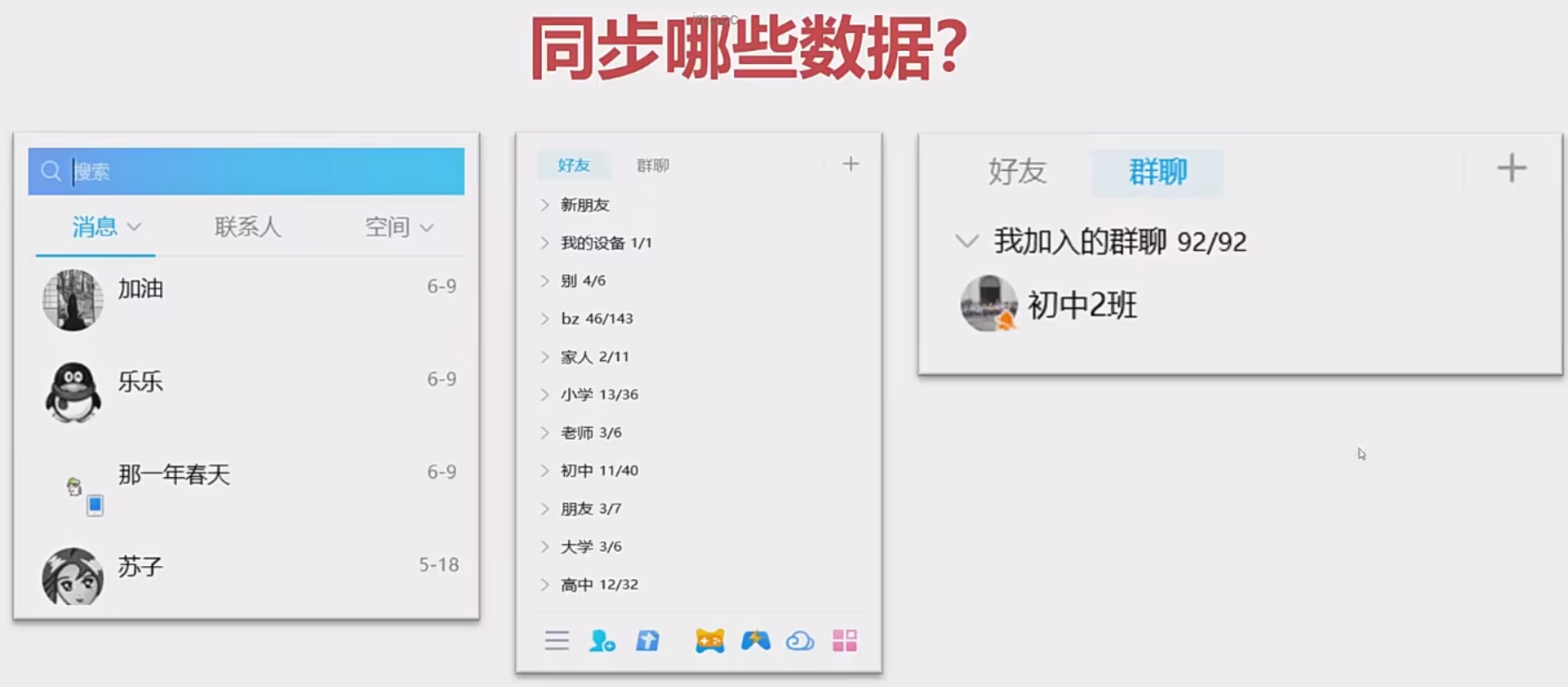
为什么我们第一次登录进入微信啥的,要等待好久,这是因为要进行同步会话、分组、群聊等等的数据。而且这个还是全量拉取,等待时间很长
优化一
- 延迟拉取:不是从一开始就去拉取所用数据,而是在用到的时候才去拉取,延迟拉取的本质是分摊时间,而不是分摊时间,该等待还要等待
- 按需拉取:第一次拉取所有数据后存储到本地空间中,后面的拉取的数据都是根据第一次拉取的数据进行增量更新的。
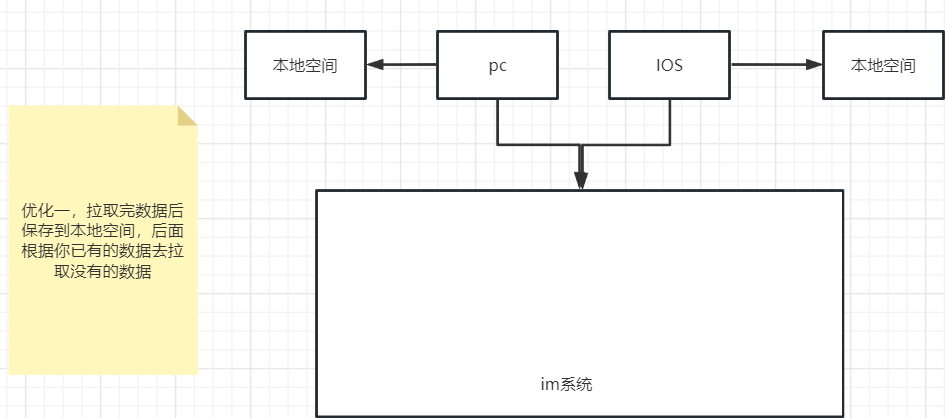
优化二:
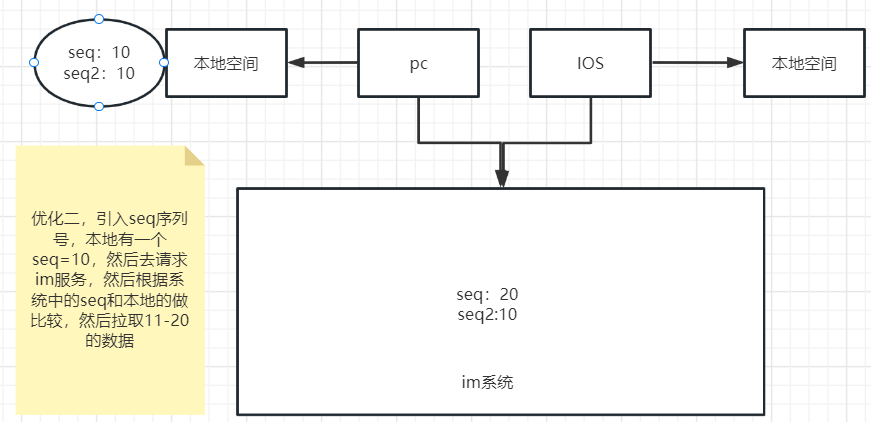
增加数据序列号(版本号):比如是单聊的中客户端的最大的seq是10,服务端最大seq是20,那么客户端发起增量拉取,拉取的就是11-20的数据
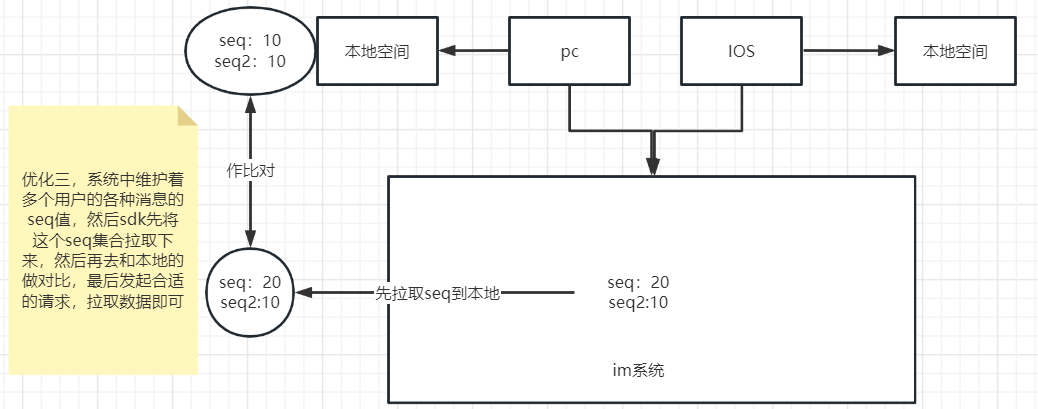
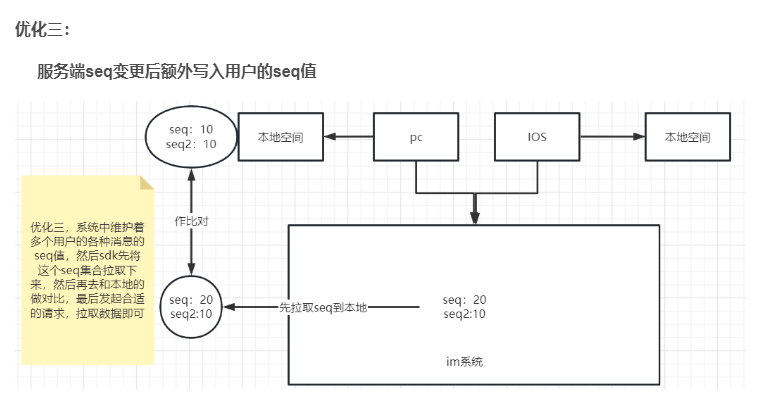
优化三:
服务端seq变更后额外写入用户的seq值
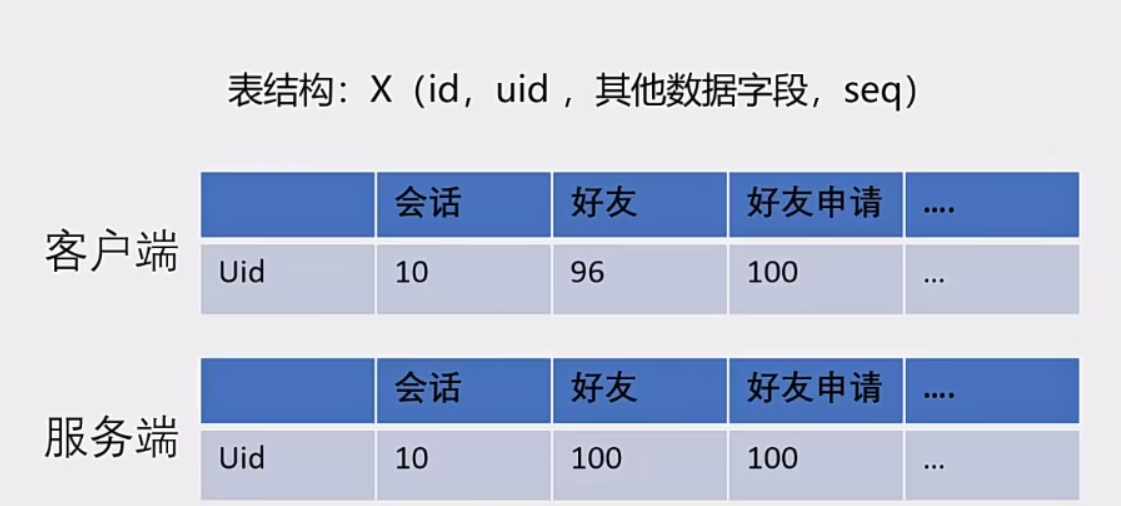
2、如何将好友关系链、会话、群组全量拉取改为增量拉取
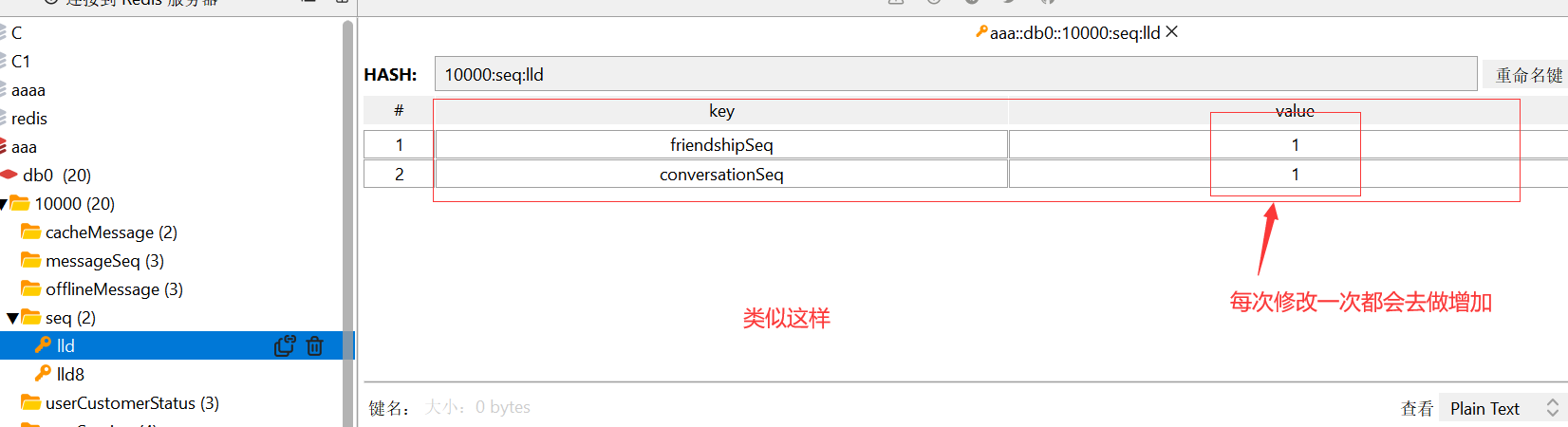
我们可以使用redis的hash结构去存储一个用户的所有类型(消息、群聊、关系链、分组等等)的seq
@Service
public class WriteUserSeq {
// redis
// uid friend group conversation
@Autowired
private RedisTemplate redisTemplate;
// 修改消息的seq值
public void writeUserSeq(Integer appId, String userId, String type, Long seq){
String key = appId + ":" + Constants.RedisConstants.SeqPrefix + ":" + userId;
redisTemplate.opsForHash().put(key, type, seq);
}
}
上面这个类就是用来存储seq的类,这里我们举几个例子表示一下(其他的也和下面的差不多,也就是当那个地方做出了修改,那么我们就要生成对应模块的seq值然后记录起来,以便于后期的客户端直接拉取该用户的各个模块的seq集合,和自己本地数据的seq做对比,然后进行增量拉取做铺垫)
这里的模块有会话、群聊、关系链,群聊不用存储redis中,这个因为是比较特殊,一个群里可能好多好多的人,如果群里一个人发消息,其他群友的seq都要发生改变,这太离谱了所以说就不存储到redis中去
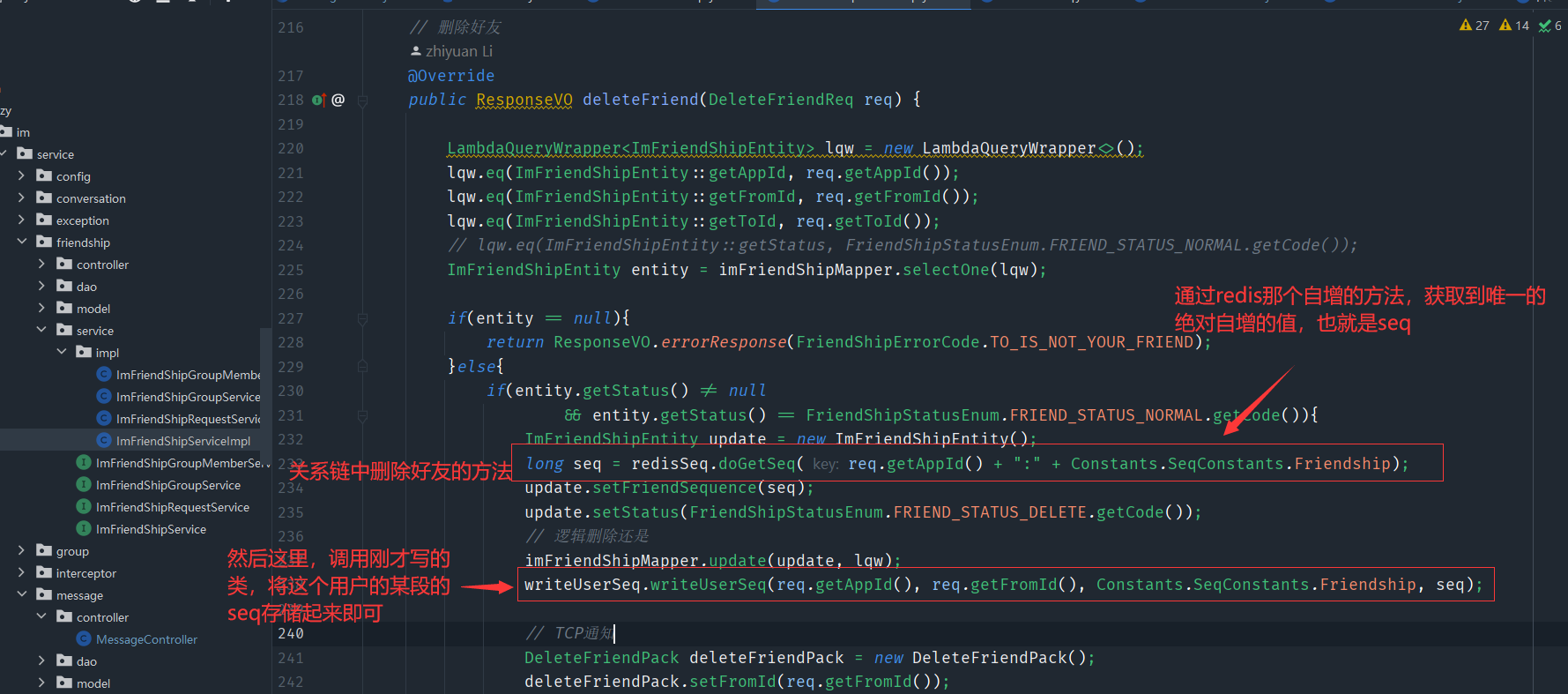
3、手把手带你实现增量同步接口
这里用那个好友关系链来举个例子

// 同步好友列表信息 增量拉取
@Override
public ResponseVO syncFriendShipList(SyncReq req) {
// 单次最大拉取数量
if(req.getMaxLimit() > 100){
req.setMaxLimit(100);
}
// 返回体
SyncResp<ImFriendShipEntity> resp = new SyncResp<>();
// seq > req.getseq limit maxlimit
LambdaQueryWrapper<ImFriendShipEntity> lqw = new LambdaQueryWrapper<>();
lqw.eq(ImFriendShipEntity::getFromId, req.getOperater());
lqw.gt(ImFriendShipEntity::getFriendSequence, req.getLastSequence());
lqw.eq(ImFriendShipEntity::getAppId, req.getAppId());
lqw.last("limit " + req.getMaxLimit());
lqw.orderByAsc(ImFriendShipEntity::getFriendSequence);
List<ImFriendShipEntity> dataList = imFriendShipMapper.selectList(lqw);
if(!CollectionUtils.isEmpty(dataList)){
ImFriendShipEntity maxSeqEntity = dataList.get(dataList.size() - 1);
resp.setDataList(dataList);
// 设置最大seq
Long friendShipMaxSeq = imFriendShipMapper.getFriendShipMaxSeq(req.getAppId(), req.getOperater());
resp.setMaxSequence(friendShipMaxSeq);
// 设置是否拉取完毕
resp.setCompleted(maxSeqEntity.getFriendSequence() >= friendShipMaxSeq);
return ResponseVO.successResponse(resp);
}
resp.setCompleted(true);
return ResponseVO.successResponse(resp);
}
其他的贴一下代码得行了
群组
// 增量同步群组成员列表
@Override
public ResponseVO syncJoinedGroupList(SyncReq req) {
// 单次拉取最大
if(req.getMaxLimit() > 100){
req.setMaxLimit(100);
}
SyncResp<ImGroupEntity> resp = new SyncResp<>();
// 获取该用户加入的所有的群 的 groupId
ResponseVO<Collection<String>> collectionResponseVO
= imGroupMemberService.syncMemberJoinedGroup(req.getOperater(), req.getAppId());
if(collectionResponseVO.isOk()){
Collection<String> data = collectionResponseVO.getData();
LambdaQueryWrapper<ImGroupEntity> lqw = new LambdaQueryWrapper<>();
lqw.eq(ImGroupEntity::getAppId, req.getAppId());
lqw.in(ImGroupEntity::getGroupId, data);
lqw.gt(ImGroupEntity::getSequence, req.getLastSequence());
lqw.last("limit " + req.getMaxLimit());
lqw.orderByAsc(ImGroupEntity::getSequence);
List<ImGroupEntity> list = imGroupMapper.selectList(lqw);
if(!CollectionUtils.isEmpty(list)){
ImGroupEntity maxSeqEntity = list.get(list.size() - 1);
resp.setDataList(list);
// 设置最大seq
Long maxSeq = imGroupMapper.getGroupMaxSeq(data, req.getAppId());
resp.setMaxSequence(maxSeq);
// 设置是否拉取完毕
resp.setCompleted(maxSeqEntity.getSequence() >= maxSeq);
return ResponseVO.successResponse(resp);
}
}
resp.setCompleted(true);
return ResponseVO.successResponse(resp);
}
// 动态获取群组列表中最大的seq
@Override
public Long getUserGroupMaxSeq(String userId, Integer appId) {
// 该用户加入的groupId
ResponseVO<Collection<String>> memberJoinedGroup
= imGroupMemberService.syncMemberJoinedGroup(userId, appId);
if(!memberJoinedGroup.isOk()){
throw new ApplicationException(500,"");
}
// 获取他加入的群组列表中最大的seq
Long maxSeq =
imGroupMapper.getGroupMaxSeq(memberJoinedGroup.getData(),
appId);
return maxSeq;
}
会话
// 增量拉取会话
public ResponseVO syncConversationSet(SyncReq req) {
// 单次拉取最大数
if(req.getMaxLimit() > 100){
req.setMaxLimit(100);
}
SyncResp<ImConversationSetEntity> resp = new SyncResp<>();
LambdaQueryWrapper<ImConversationSetEntity> lqw = new LambdaQueryWrapper<>();
lqw.eq(ImConversationSetEntity::getFromId, req.getOperater());
lqw.gt(ImConversationSetEntity::getSequence, req.getLastSequence());
lqw.eq(ImConversationSetEntity::getAppId, req.getAppId());
lqw.last("limit " + req.getMaxLimit());
lqw.orderByAsc(ImConversationSetEntity::getReadedSequence);
List<ImConversationSetEntity> list = imConversationSetMapper.selectList(lqw);
if(!CollectionUtils.isEmpty(list)){
ImConversationSetEntity maxSeqEntity = list.get(list.size() - 1);
resp.setDataList(list);
// 设置最大seq
Long maxSeq
= imConversationSetMapper.getConversationSetMaxSeq(req.getAppId(), req.getOperater());
resp.setMaxSequence(maxSeq);
// 设置是否拉取完
resp.setCompleted(maxSeqEntity.getReadedSequence() >= maxSeq);
return ResponseVO.successResponse(resp);
}
resp.setCompleted(true);
return ResponseVO.successResponse(resp);
}
4、获取某个用户的req
这个就是在开篇的那个优化三中的实现,这个加上我们上面实现的增量接口,就可以去做完整的增量拉取了
// 获取用户的seq
@Override
public ResponseVO getUserSequence(GetUserSequenceReq req) {
// 这里的map中有 好友关系的 好友申请的 会话的,没有群组的,因为之前设计的时候,
// 就考虑到如果一个群组里面的任何成员,发生了修改都会去修改
// 该群的seq值,每次修改都要去redis中去更新seq,太繁琐了
// 但是我觉得可以用那个Redis绝对自增序列的那个,不用非得从数据库中获取最新的,可能是数据库的比redis中的更加精准,
// 我这个想法有待考量
Map<Object, Object> map = stringRedisTemplate.opsForHash().entries(
req.getAppId() + ":" + Constants.RedisConstants.SeqPrefix + ":" + req.getUserId());
Long groupSeq = imGroupService.getUserGroupMaxSeq(req.getUserId(), req.getAppId());
map.put(Constants.SeqConstants.Group, groupSeq);
return ResponseVO.successResponse(map);
}
5、如何实现增量拉取离线消息
离线消息是不可避免的,所以一上线就要拉取离线消息,看看有没有离线消息要获取
// 增量拉取离线消息
public ResponseVO syncOfflineMessage(SyncReq req) {
SyncResp<OfflineMessageContent> resp = new SyncResp<>();
String key = req.getAppId() + ":" + Constants.RedisConstants.OfflineMessage + ":" + req.getOperater();
// 获取最大的seq
Long maxSeq = 0L;
// 获取到有序集合
ZSetOperations zSetOperations = redisTemplate.opsForZSet();
// 调用api获取到最大的那哥有序集合的set
Set set = zSetOperations.reverseRangeWithScores(key, 0, 0);
if(!CollectionUtils.isEmpty(set)){
List list = new ArrayList(set);
DefaultTypedTuple o = (DefaultTypedTuple)list.get(0);
// 获取到最大的seq
maxSeq = o.getScore().longValue();
}
resp.setMaxSequence(maxSeq);
List<OfflineMessageContent> respList = new ArrayList<>();
// 这里就像是查数据库一样
// 调用api 截取limit的数量的 满足分值区间的 set
Set<ZSetOperations.TypedTuple> querySet = zSetOperations.rangeByScoreWithScores(
key, req.getLastSequence(), maxSeq, 0, req.getMaxLimit());
for (ZSetOperations.TypedTuple<String> typedTuple : querySet) {
// 获取道符合条件的离线消息
String value = typedTuple.getValue();
// Json转换
OfflineMessageContent offlineMessageContent = JSONObject.parseObject(value, OfflineMessageContent.class);
// 放到respList中
respList.add(offlineMessageContent);
}
resp.setDataList(respList);
if(!CollectionUtils.isEmpty(respList)){
OfflineMessageContent offlineMessageContent = respList.get(respList.size() - 1);
resp.setCompleted(offlineMessageContent.getMessageKey() >= maxSeq);
}
return ResponseVO.successResponse(resp);
}
这里面好几个api都是不怎么熟悉的,还得学学