1.日志收集场景分析与说明
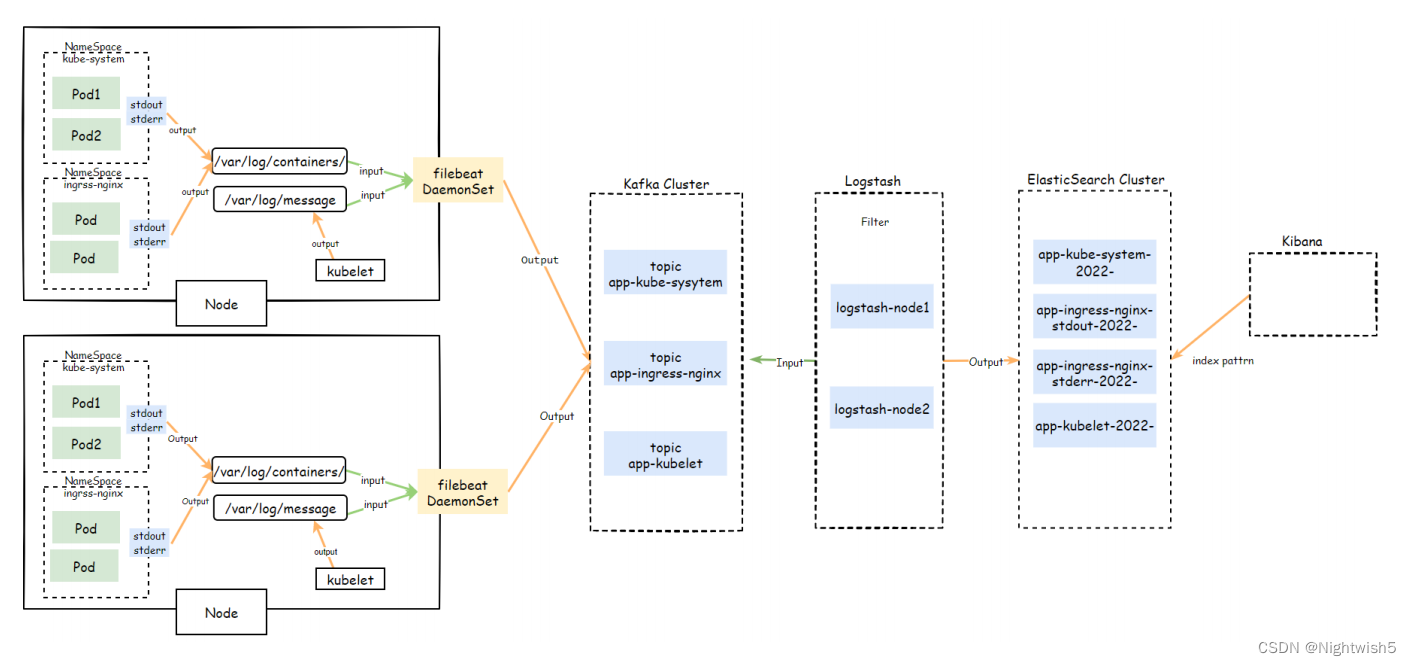
部署架构说明
对于那些将日志输出到,stdout与stderr的Pod,
可以直接使用DaemonSet控制器在每个Node节点上运行一个 <font color=red>filebeat、logstash、fluentd </font>容器进行统一的收集,而后写入到日志存储系统。
2.filebeat部署
#创建ServiceAccount
kubectl create serviceaccount filebeat -n logging
#创建ClusterRole
kubectl create clusterrole filebeat \
--verb=get,list,watch \
--resource=namespace,pods,nodes
#创建ClusterRolebinding
kubectl create clusterrolebinding filebeat \
--serviceaccount=logging:filebeat \
--clusterrole=filebeat
#下载镜像 ,推送
docker pull docker.elastic.co/beats/filebeat:7.17.6
docker tag docker.elastic.co/beats/filebeat:7.17.6 harbor.oldxu.net/base/filebeat:7.17.6
docker push harbor.oldxu.net/base/filebeat:7.17.6
2.1 交付filebeat
1、从ConfigMap中挂载filebeat.yaml配置文件;
2、挂载 /var/log、/var/lib/docker/containers 日志相关目录;
3、使用 hostPath 方式挂载 /usr/share/filebeat/data 数据目录,该目录下有一个registry文件,里面记录了filebeat采集日志位置的相关
内容,比如文件offset、source、timestamp等,如果Pod发生异常后K8S自动将Pod进行重启,不挂载的情况下registry会被重置,将导致日志文件又从offset=0开始采集,会造成重复收集日志。这点非常重要.
filebeat-daemonset.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: filebeat
namespace: logging
spec:
selector:
matchLabels:
app: filebeat
template:
metadata:
labels:
app: filebeat
spec:
serviceAccountName: "filebeat"
tolerations:
- key: node-role.kubernetes.io/master
operator: "Exists"
effect: "NoSchedule"
imagePullSecrets:
- name: harbor-admin
containers:
- name: filebeat
image: harbor.oldxu.net/base/filebeat:7.17.6
args: [
"-c","/etc/filebeat.yml",
"-e"
]
securityContext:
runAsUser: 0
resources:
limits:
memory: 200Mi
volumeMounts:
- name: config
mountPath: /etc/filebeat.yml
subPath: filebeat.yml
- name: varlog
mountPath: /var/log
readOnly: true
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
- name: data
mountPath: /usr/share/filebeat/data
volumes:
- name: config
configMap:
name: filebeat-config
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: data
hostPath:
path: /var/lib/filebeat-data
type: DirectoryOrCreate
2.2 收集kube-system名称空间
日志位置: /var/log/containers/${pod_name}_${pod_namespace}_${container_name}-${container_id}
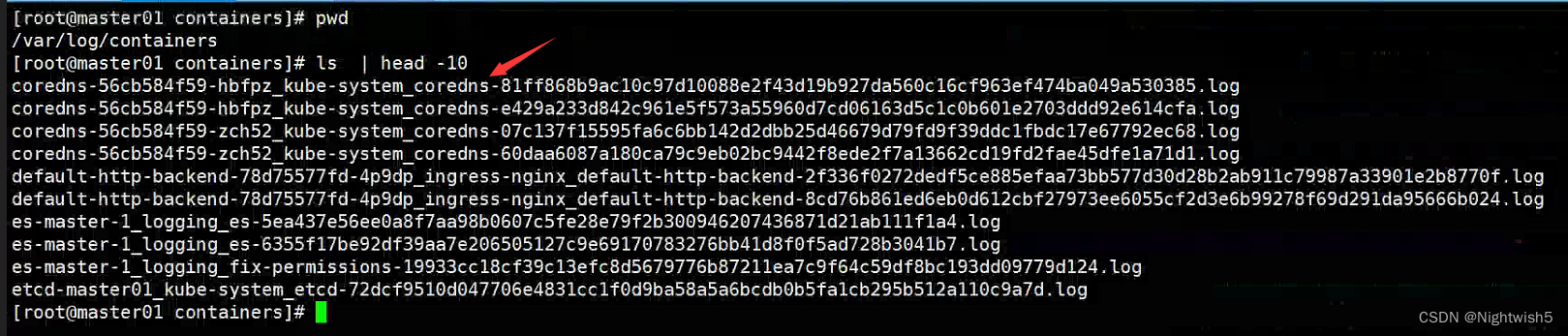
filebeat-cm.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
namespace: logging
data:
filebeat.yml: |-
#===Filebeat autodiscover
providers:
- type: kubernetes
templates:
- condition: #匹配kube-system名称空间下所有日志
equals:
kubernetes.namespace: kube-system
config:
- type: container
stream: all #收集stdout、stderr类型日志,all是所有
encoding: utf-8
paths: /var/log/containers/*-${data.kubernetes.container.id}.log
exclude_lines: ['info']
#=== Kafka Output
output.console:
pretty: true
enable: true
下面是 正确的filebeat-cm.yaml ,上面留着做错误参考
[root@master01 02-DaemonSet-agent-log]# cat 02-filebeat-cm.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
namespace: logging
data:
filebeat.yml: |-
filebeat.autodiscover:
providers:
- type: kubernetes
templates:
- condition:
equals:
kubernetes.namespace: kube-system
config:
- type: container
stream: all
encoding: utf-8
paths: /var/log/containers/*-${data.kubernetes.container.id}.log
exclude_lines: ['info']
output.console:
pretty: true
enable: true
备注:要写对 filebeat.yml的配置内容,否则报错:
错误1:
2023-05-15T08:45:51.149Z INFO instance/beat.go:328 Setup Beat: filebeat; Version: 7.17.6
2023-05-15T08:45:51.149Z INFO instance/beat.go:361 No outputs are defined. Please define one under the output section.
2023-05-15T08:45:51.149Z INFO instance/beat.go:461 filebeat stopped.
2023-05-15T08:45:51.149Z ERROR instance/beat.go:1014 Exiting: No outputs are defined. Please define one under the output section.
Exiting: No outputs are defined. Please define one under the output section.
错误2:
2023-05-15T09:03:09.492Z INFO [publisher] pipeline/module.go:113 Beat name: filebeat-62ql6
2023-05-15T09:03:09.493Z INFO instance/beat.go:461 filebeat stopped.
2023-05-15T09:03:09.493Z ERROR instance/beat.go:1014 Exiting: no modules or inputs enabled and configuration reloading disabled. What files do you want me to watch?
Exiting: no modules or inputs enabled and configuration reloading disabled. What files do you want me to watch?
错误3:
当master节点,内存还剩200MB的时候,部署daemonSet,他副本数会是0个, Events: <none>
正常运行后的情况:
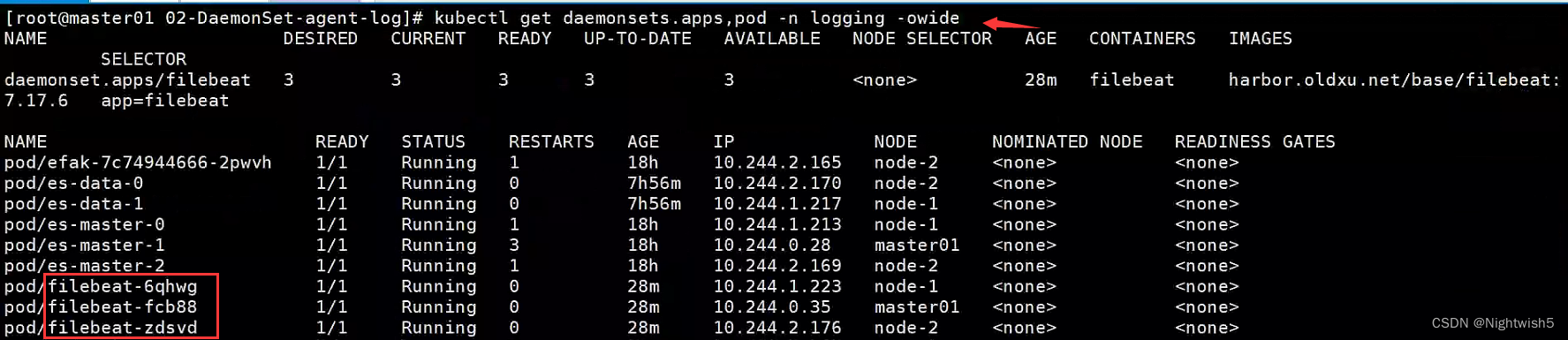
模拟产生日志,并查看日志
删除node01节点上kube-system名称空间中的Pod,模拟产生日志
kubectl delete pod -n kube-system kube-proxy-6ks5b
kubectl logs -n logging filebeat-6qhwg
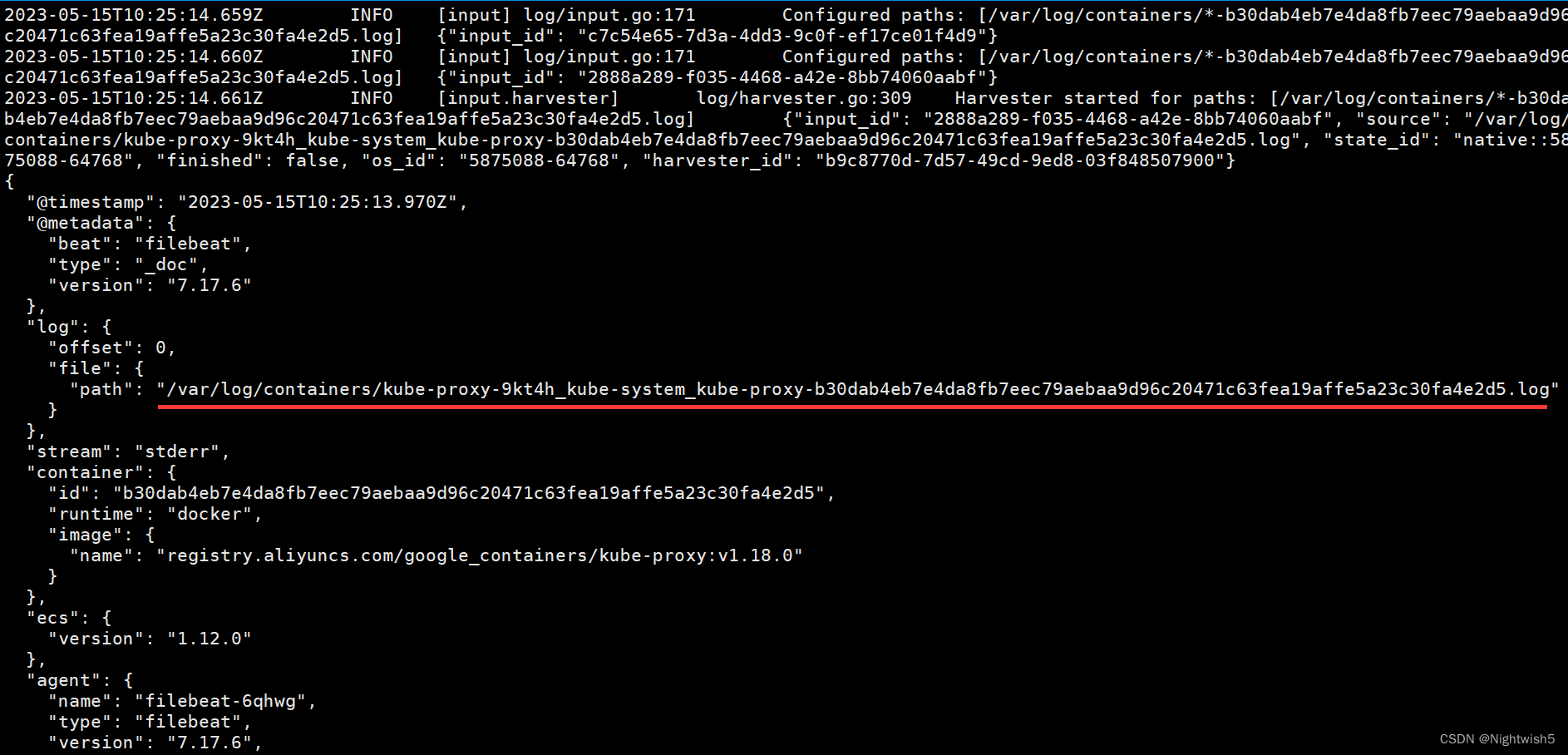
2.3 收集ingress-nginx名称空间
1、修改Ingress日志输出格式
kubectl edit configmaps -n ingress-nginx ingress-controller-leader-nginx
#加上data内容
log-format-upstream:'{"timestamp":"$time_iso8601","domain":"$server_name","hostname":"$hostname","remote_user":"$remote_user","clientip":"$remote_addr","proxy_protocol_addr":"$proxy_protocol_addr","@source":"$server_addr","host":"$http_host","request":"$request","args":"$args","upstreamaddr":"$upstream_addr","status":"$status","upstream_status":"$upstream_status","bytes":"$body_bytes_sent","responsetime":"$request_time","upstreamtime":"$upstream_response_time","proxy_upstream_name":"$proxy_upstream_name","x_forwarded":"$http_x_forwarded_for","upstream_response_length":"$upstream_response_length","referer":"$http_referer","user_agent":"$http_user_agent","request_length":"$request_length","request_method":"$request_method","scheme":"$scheme","k8s_ingress_name":"$ingress_name","k8s_service_name":"$service_name","k8s_service_port":"$service_port"}'
2、为filebeat增加如下内容(注意保留此前kube-system相关的配置)
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
namespace: logging
data:
filebeat.yml: |-
filebeat.autodiscover:
providers:
- type: kubernetes
templates:
- condition: # 1 匹配kube-system名称空间下所有日志
equals:
kubernetes.namespace: kube-system
config:
- type: container
stream: all
encoding: utf-8
paths: /var/log/containers/*-${data.kubernetes.container.id}.log
exclude_lines: ['info']
- condition: # 2 收集ingress-nginx命名空间下stdout日志
equals:
kubernetes.namespace: ingress-nginx
config:
- type: container
stream: stdout
encoding: utf-8
paths: /var/log/containers/*-${data.kubernetes.container.id}.log
json.keys_under_root: true #默认将json解析存储至messages,true则不存储至message
json.overwrite_keys: true #覆盖默认message字段,使用自定义json格式的key
- condition: # 3 收集ingress-nginx命名空间下stderr日志
equals:
kubernetes.namespace: ingress-nginx
config:
- type: container
stream: stderr
encoding: utf-8
paths:
- /var/log/containers/*-${data.kubernetes.container.id}.log
output.console:
pretty: true
enable: true
3、访问ingress,模拟产生日志
先看ingress-nginx部署在那个节点上,然后logs -f那个节点上filebeat日志
curl kibana.oldxu.net:30080
kubectl logs -f -n logging filebeat-fqp84
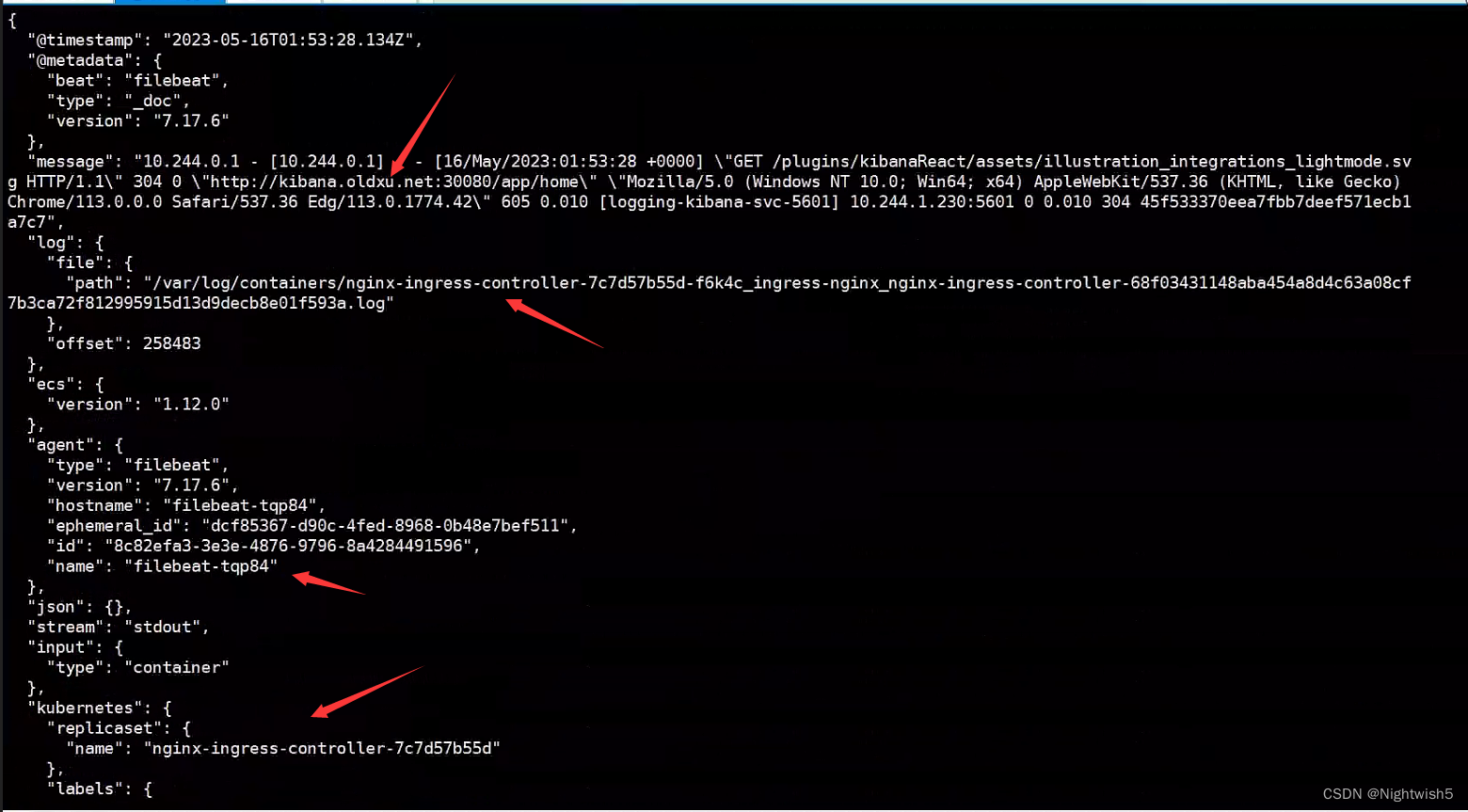
2.4 收集kubelet本地应用程序日志
1、kubelet应用日志存储至每个节点 /var/log/messages中,所以直接追加如下一段静态方式收集即可;
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
namespace: logging
data:
filebeat.yml: |-
# ======= Filebeat inputs 静态方式收集
logging.level: warning
filebeat.inputs:
- type: log
enable: true
encoding: utf-8
paths: /var/log/messages
include_lines: ['kubelet'] # 4 获取与kubelet相关的日志
fields:
namespace: kubelet
fields_under_root: true
# ======= Filebeat autodiscover 动态方式收集
filebeat.autodiscover:
providers:
- type: kubernetes
templates:
- condition: # 1 匹配kube-system名称空间下所有日志
equals:
kubernetes.namespace: kube-system
config:
- type: container
stream: all
encoding: utf-8
paths: /var/log/containers/*-${data.kubernetes.container.id}.log
exclude_lines: ['info']
- condition: # 2 收集ingress-nginx命名空间下stdout日志
equals:
kubernetes.namespace: ingress-nginx
config:
- type: container
stream: stdout
encoding: utf-8
paths: /var/log/containers/*-${data.kubernetes.container.id}.log
json.keys_under_root: true #默认将json解析存储至messages,true则不存储至message
json.overwrite_keys: true #覆盖默认message字段,使用自定义json格式的key
- condition: # 3 收集ingress-nginx命名空间下stderr日志
equals:
kubernetes.namespace: ingress-nginx
config:
- type: container
stream: stderr
encoding: utf-8
paths:
- /var/log/containers/*-${data.kubernetes.container.id}.log
output.console:
pretty: true
enable: true
报错处理:
[root@master01 02-DaemonSet-agent-log]# kubectl logs -n logging filebeat-5kznt
Exiting: error loading config file: yaml: line 3: mapping values are not allowed in this context

2、检查filebeat,查看日志收集情况
/var/log/messages的kubelet相关内容:

filebeat的显示:
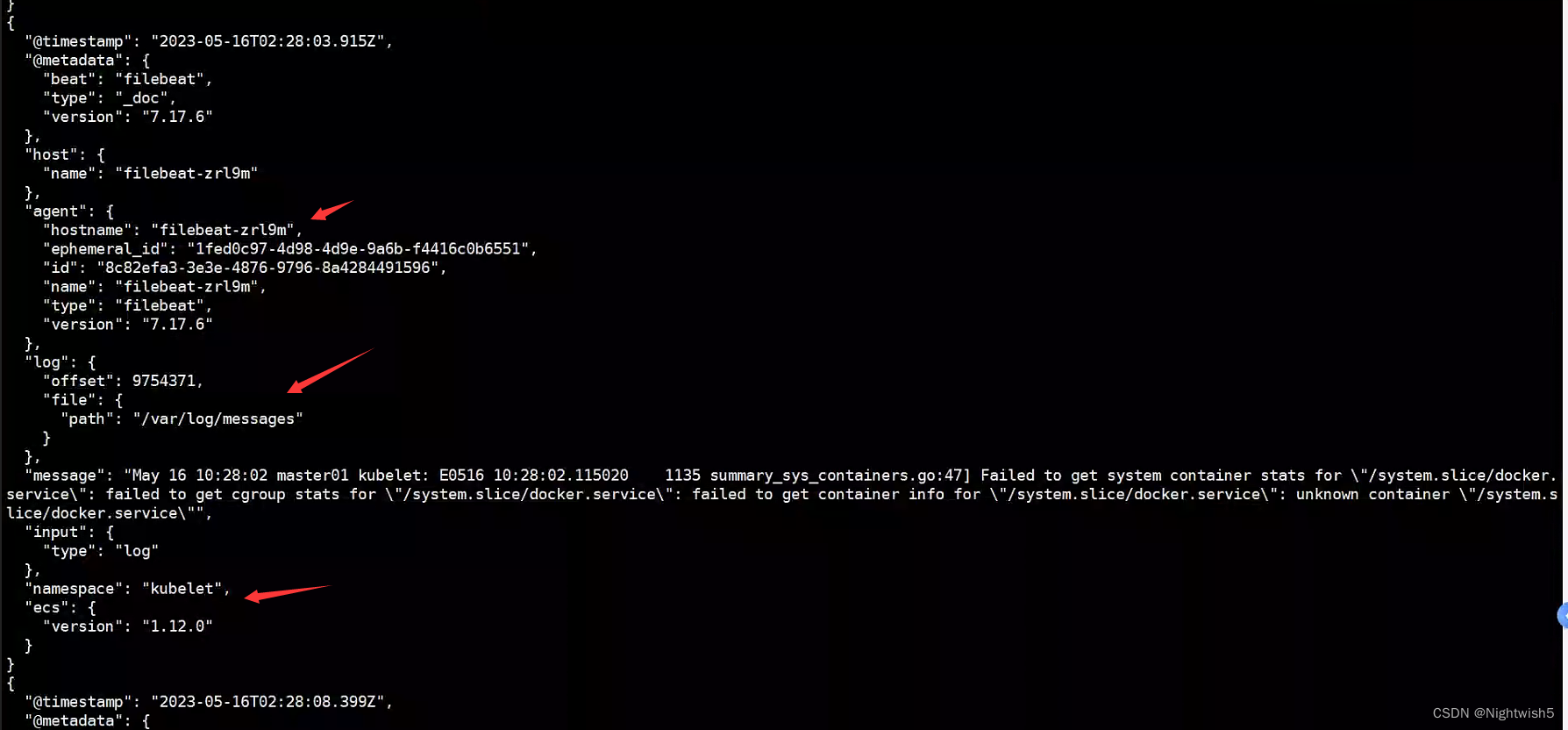
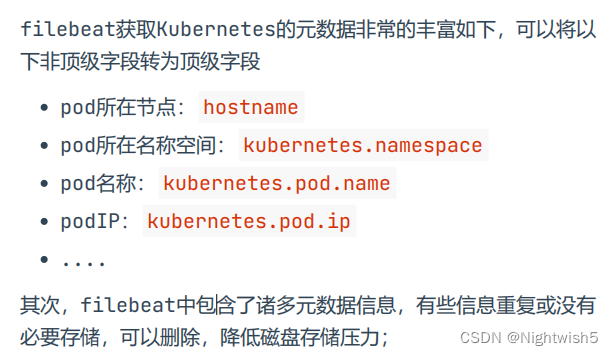
3.filebeat配置文件优化
3.1 优化filebeat输出段 与 修改配置输出至Kafka
优化filebeat输出段 :
当控制面板得到的信息符合预期时,需要将信息输出至Kafka,将output修改为如下内容即可;
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
namespace: logging
data:
filebeat.yml: |-
# ======= Filebeat inputs 静态方式收集
logging.level: warning
filebeat.inputs:
- type: log
enable: true
encoding: utf-8
paths: /var/log/messages
include_lines: ['kubelet'] # 4 获取与kubelet相关的日志
fields:
namespace: kubelet
fields_under_root: true
# ======= Filebeat autodiscover 动态方式收集
filebeat.autodiscover:
providers:
- type: kubernetes
templates:
- condition: # 1 匹配kube-system名称空间下所有日志
equals:
kubernetes.namespace: kube-system
config:
- type: container
stream: all
encoding: utf-8
paths: /var/log/containers/*-${data.kubernetes.container.id}.log
exclude_lines: ['info']
- condition: # 2 收集ingress-nginx命名空间下stdout日志
equals:
kubernetes.namespace: ingress-nginx
config:
- type: container
stream: stdout
encoding: utf-8
paths: /var/log/containers/*-${data.kubernetes.container.id}.log
json.keys_under_root: true #默认将json解析存储至messages,true则不存储至message
json.overwrite_keys: true #覆盖默认message字段,使用自定义json格式的key
- condition: # 3 收集ingress-nginx命名空间下stderr日志
equals:
kubernetes.namespace: ingress-nginx
config:
- type: container
stream: stderr
encoding: utf-8
paths:
- /var/log/containers/*-${data.kubernetes.container.id}.log
# ===== Filebeat Processors
processors:
- rename:
fields:
- from: "kubernetes.namespace"
to: "namespace"
- from: "kubernetes.pod.name"
to: "podname"
- from: "kubernetes.pod.ip"
to: "podip"
- drop_fields:
fields: ["host","agent","ecs","input","container","kubernetes"]
# ===== kafka output
output.kafka:
hosts: ["kafka-0.kafka-svc:9092","kafka-1.kafka-svc:9092","kafka-2.kafka-svc:9092"]
topic: "app-%{[namespace]}" # %{[namespace]} 会自动将其转换为namespace对应的值
required_acks: 1 #保证消息可靠,0不保证,1等待写入主分区(默认)-1等待写入副本分区
compression: gzip
max_message_bytes: 1000000
3.2 检查kafka对应Topic
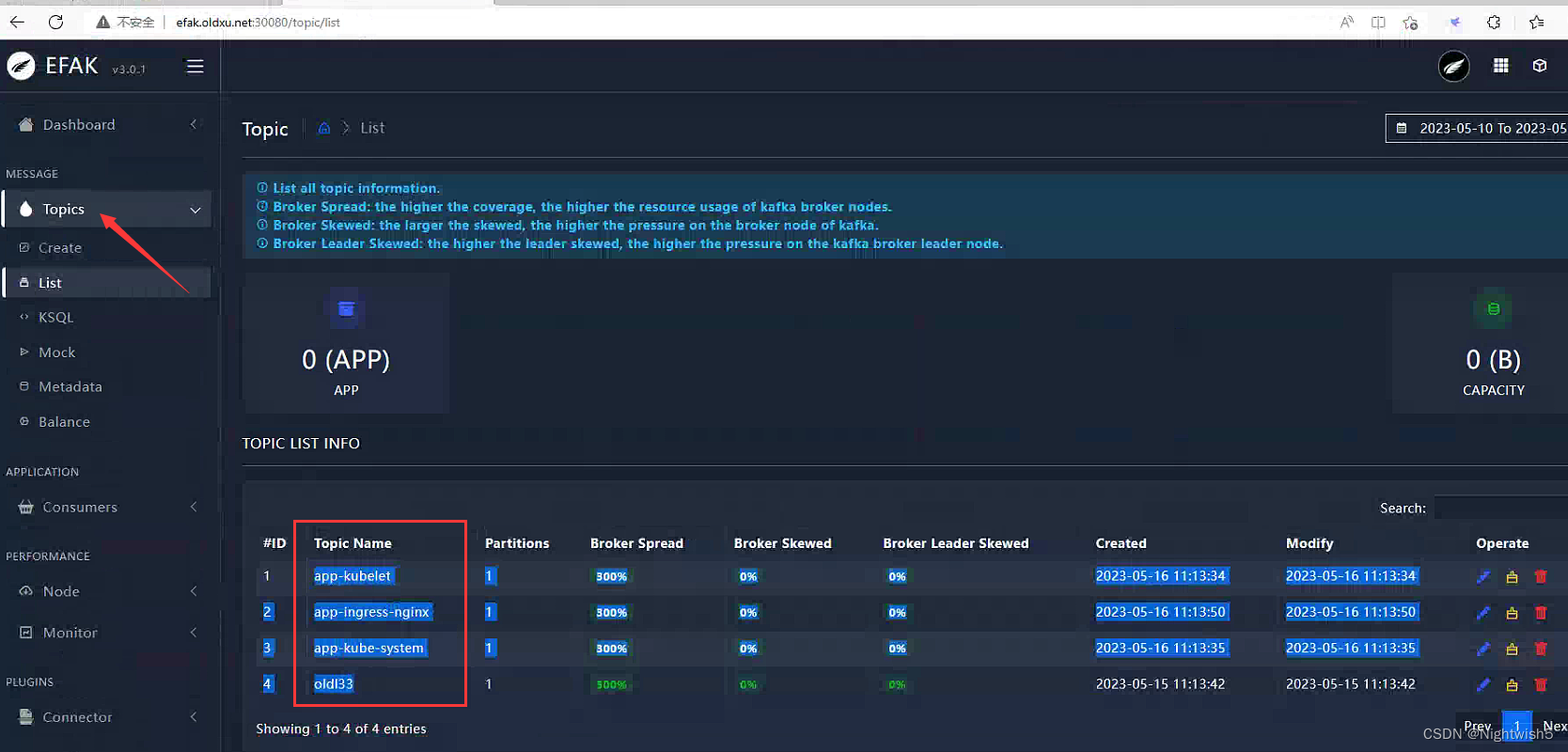
4、交付Logstash
#下载镜像 推送
docker pull docker.elastic.co/logstash/logstash-oss:7.17.6
docker tag docker.elastic.co/logstash/logstash-oss:7.17.6 harbor.oldxu.net/base/logstash-oss:7.17.6
docker push harbor.oldxu.net/base/logstash-oss:7.17.6
4.1 如何交付Logstash
1、Logstash需要设定环境变量来调整主配置文件参数,比如:worker运行数量,以及批量处理的最大条目是多少;
2、Logstash需要调整JVM堆内存使用的范围,没办法传参调整,但可以通过 postStart 来修改其文件对应的jvm参数;
3、Logstash需要配置文件,读取Kafka数据,而后通过filter处理,最后输出至ES
# /usr/share/logstash/config/logstash.yml
# 可通过变量传参修改
pipeline.workers: 2
pipeline.batch.size: 1000
# /usr/share/logstash/config/jvm.options
-Xms512m
-Xmx512m
# /usr/share/logstash/config/logstash.conf
input {
kafka
}
filter {
}
output {
}
准备logstash配置
input段含义
1、所有数据都从kafka集群中获取;
2、获取kafka集群中topic,主要有 app-kube-system、app-ingress-nginx、app-kubelet
filter段含义
1、判断namespace等于kubelet,则为其添加一个索引字段名称;
1、判断namespace等于kube-system,则为其添加一个索引字段名称;
2、判断namespace等于ingress-nginx,并且stream等于stderr,则为其添加一个索引字段名称;
3、判断namespace等于ingress-nginx,并且stream等于stdout,则使用geoip获取地址来源,使用
useragent模块分析来访客户端设备,使用date处理时间,使用mutate转换对应字段格式,最后添加一个索引字段名称;
logstash-node.conf
input{
kafka{
bootstrap_servers => "kafka-0.kafka-svc:9092,kafka-1.kafka-svc:9092,kafka-2.kafka-svc:9092"
group_id => "logstash-node" # 消费者组名称
consumer_threads => "3" #设置与分区数一样多的线程
topics => ["app-kube-system","app-ingress-nginx","app-kubelet"]
codec => json
}
} #input end
filter{
###
if "kubectl" in [namespace] {
mutate{
add_field => { "target_index" => "app-%{[namespace]}-%{+YYYY.MM.dd}" }
}
}
###
if "kube-system" in [namespace] {
mutate {
add_field => { "target_index" => "app-%{[namespace]}-%{+YYYY.MM.dd}" }
}
}
###
if [namespace] == "ingress-nginx" and [stream] == "stdout" {
geoip{
source => "clientip"
}
useragent {
source => "user_agent"
target => "user_agent"
}
date {
# 2022-10-08T13:13:20.000Z
match => ["timestamp","ISO8601"]
target => "@timestamp"
timezone => "Asia/Shanghai"
}
mutate {
convert => {
"bytes" => "integer"
"responsetime" => "float"
"upstreamtime" => "float"
}
add_field => { "target_index" => "app-%{[namespace]}-%{[stream]}-%{+YYYY.MM.dd}" }
}
}
###
if [namespace] == "ingress-nginx" and [stream] == "stderr" {
mutate{
add_field => { "target_index" => "app-%{[namespace]}-%{[stream]}-%{+YYYY.MM.dd}" }
}
}
} #filter end
output{
stdout{
codec => rubydebug
}
elasticsearch{
hosts => ["es-data-0.es-svc:9200","es-data-1.es-svc:9200"]
index => "%{[target_index]}"
template_overwrite => true
}
} #output end
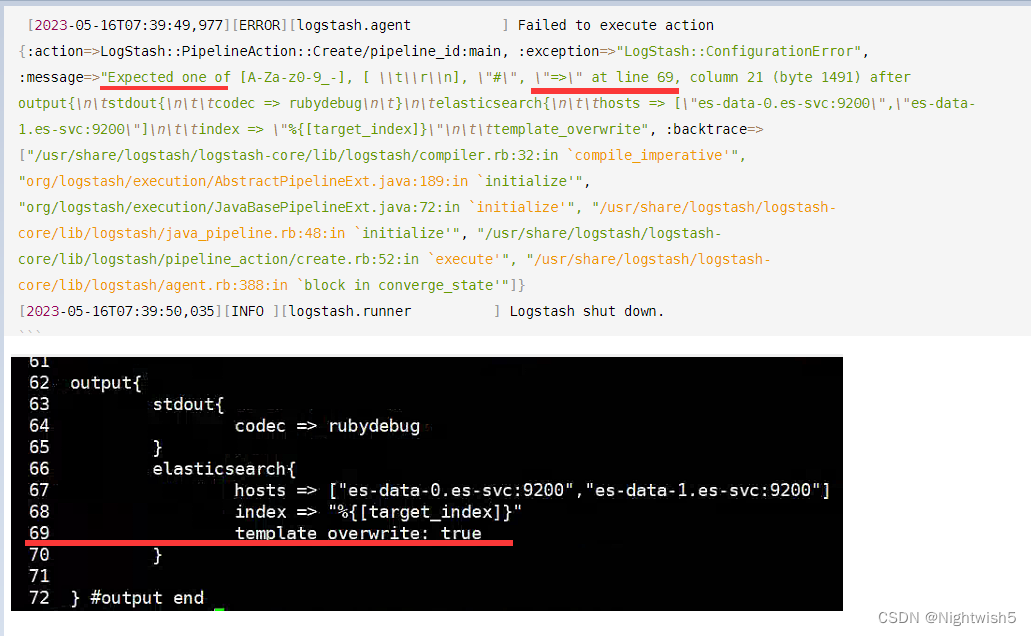
之前conf的最后 错误写成:template_overwrite: true
正确的是 template_overwrite => true
报错:
[2023-05-16T07:39:49,977][ERROR][logstash.agent ] Failed to execute action {:action=>LogStash::PipelineAction::Create/pipeline_id:main, :exception=>"LogStash::ConfigurationError", :message=>"Expected one of [A-Za-z0-9_-], [ \\t\\r\\n], \"#\", \"=>\" at line 69, column 21 (byte 1491) after output{\n\tstdout{\n\t\tcodec => rubydebug\n\t}\n\telasticsearch{\n\t\thosts => [\"es-data-0.es-svc:9200\",\"es-data-1.es-svc:9200\"]\n\t\tindex => \"%{[target_index]}\"\n\t\ttemplate_overwrite", :backtrace=>["/usr/share/logstash/logstash-core/lib/logstash/compiler.rb:32:in `compile_imperative'", "org/logstash/execution/AbstractPipelineExt.java:189:in `initialize'", "org/logstash/execution/JavaBasePipelineExt.java:72:in `initialize'", "/usr/share/logstash/logstash-core/lib/logstash/java_pipeline.rb:48:in `initialize'", "/usr/share/logstash/logstash-core/lib/logstash/pipeline_action/create.rb:52:in `execute'", "/usr/share/logstash/logstash-core/lib/logstash/agent.rb:388:in `block in converge_state'"]}
[2023-05-16T07:39:50,035][INFO ][logstash.runner ] Logstash shut down.
如果理解英文再好点,那就checkmate了。 (粗心 抄得抄歪来。 唉 )
logstash-configmap
[root@master01 logstash]# mv logstash-node.conf conf/
[root@master01 logstash]#
[root@master01 logstash]# ls conf/
logstash-node.conf
[root@master01 logstash]#
[root@master01 logstash]# kubectl create configmap logstash-node-conf \
> --from-file=logstash.conf=./conf/logstash-node.conf -n logging
configmap/logstash-note-conf created
#TMD 注意这里的 --from-file=logstash.conf ,上面的写法,会导致sts创建的pod报错
#正确的写法: 因为这与 logstash-sts.yaml一一对应。 如果没有写,那data的名字叫logstash-node.conf,文件本名。
kubectl create configmap logstash-node-conf --from-file=logstash.conf=./conf/logstash-node.conf -n logging
[2023-05-16T07:29:22,423][WARN ][logstash.config.source.multilocal] Ignoring the 'pipelines.yml' file because modules or command line options are specified
[2023-05-16T07:29:23,145][INFO ][logstash.config.source.local.configpathloader] No config files found in path {:path=>"/usr/share/logstash/config/logstash.conf/*"}
[2023-05-16T07:29:23,149][ERROR][logstash.config.sourceloader] No configuration found in the configured sources.
01-logstash-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: logstash-svc
namespace: logging
spec:
clusterIP: None
selector:
app: logstash
ports:
- port: 9600
targetPort: 9600
02-logstash-sts.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: logstash-node
namespace: logging
spec:
serviceName: "logstash-svc"
replicas: 1
selector:
matchLabels:
app: logstash
env: node
template:
metadata:
labels:
app: logstash
env: node
spec:
imagePullSecrets:
- name: harbor-admin
containers:
- name: logstash
image: harbor.oldxu.net/base/logstash-oss:7.17.6
args: ["-f","config/logstash.conf"] # 启动时指定加载的配置文件
resources:
limits:
memory: 1024Mi
env:
- name: PIPELINE_WORKERS
value: "2"
- name: PIPELINE_BATCH_SIZE
value: "10000"
lifecycle:
postStart: # 设定JVM
exec:
command:
- "/bin/bash"
- "-c"
- "sed -i -e '/^-Xms/c-Xms512m' -e '/^-Xmx/c-Xmx512m' /usr/share/logstash/config/jvm.options"
volumeMounts:
- name: data # 持久化数据目录
mountPath: /usr/share/logstash/data
- name: conf
mountPath: /usr/share/logstash/config/logstash.conf
subPath: logstash.conf
volumes:
- name: conf
configMap:
name: logstash-node-conf
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: ["ReadWriteMany"]
storageClassName: "nfs"
resources:
requests:
storage: 28Gi
此时kibana -> stack management (左侧栏的底部)-> 索引管理
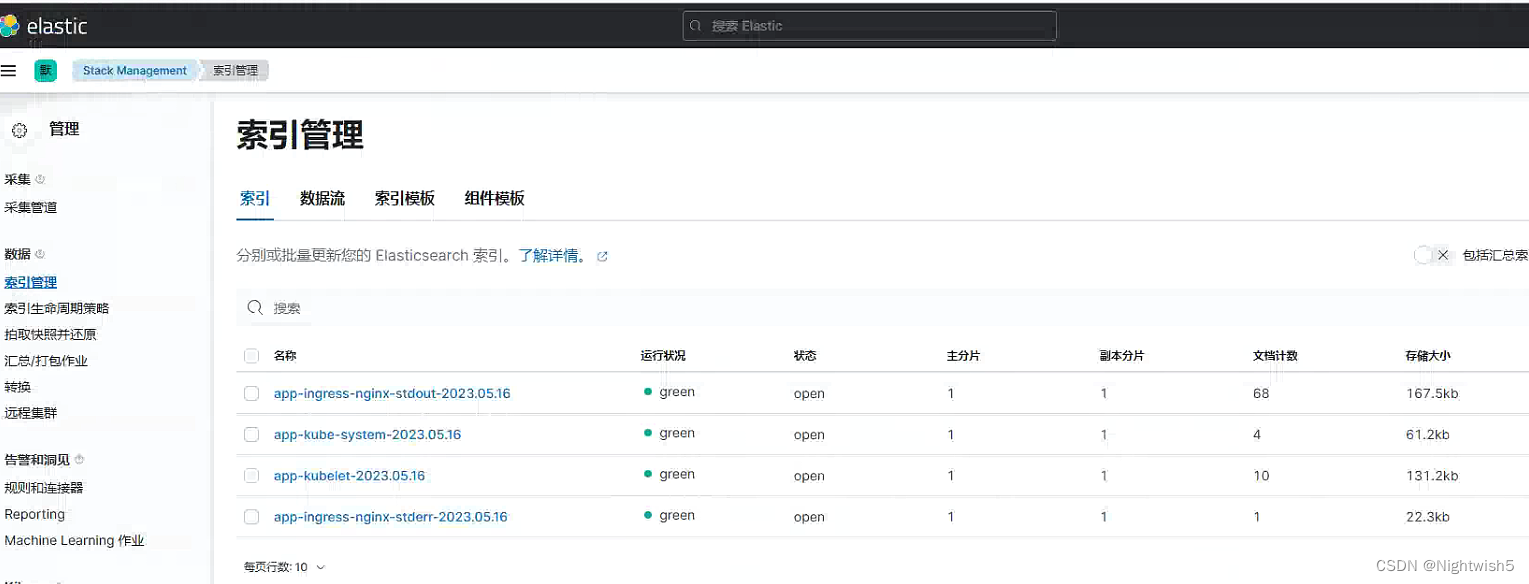
5、Kibana可视化
5.1 创建索引
http://kibana.oldxu.net:30080/app/management/kibana/indexPatterns
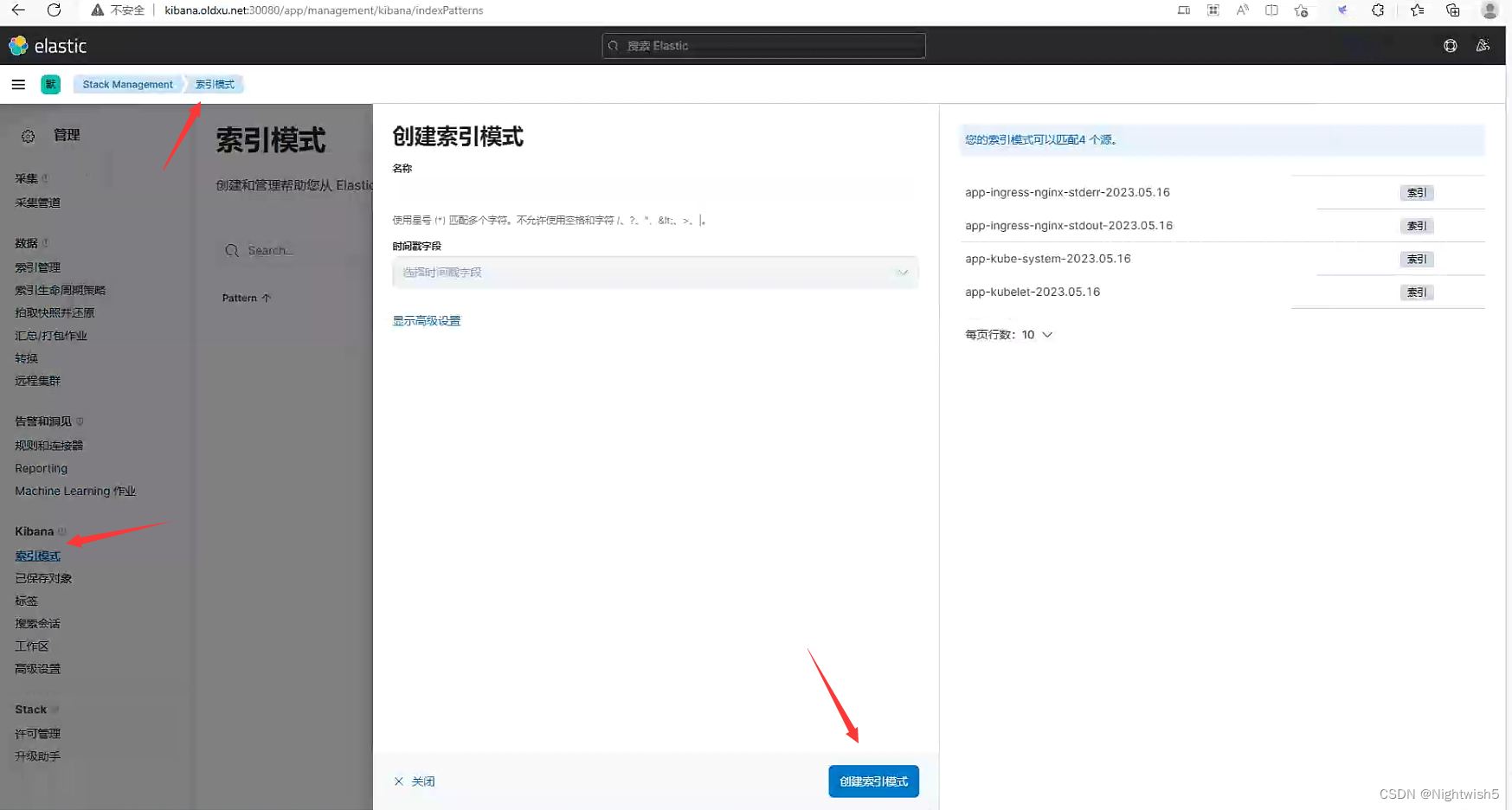
kube-system索引
ingress-stdout索引
ingress-stderr索引
kubelet索引
5.2 日志展示
app-ingress-nginx-stdout索引日志
app-ingress-nginx-stderr索引日志
app-kube-system索引日志
app-kubelet索引日志