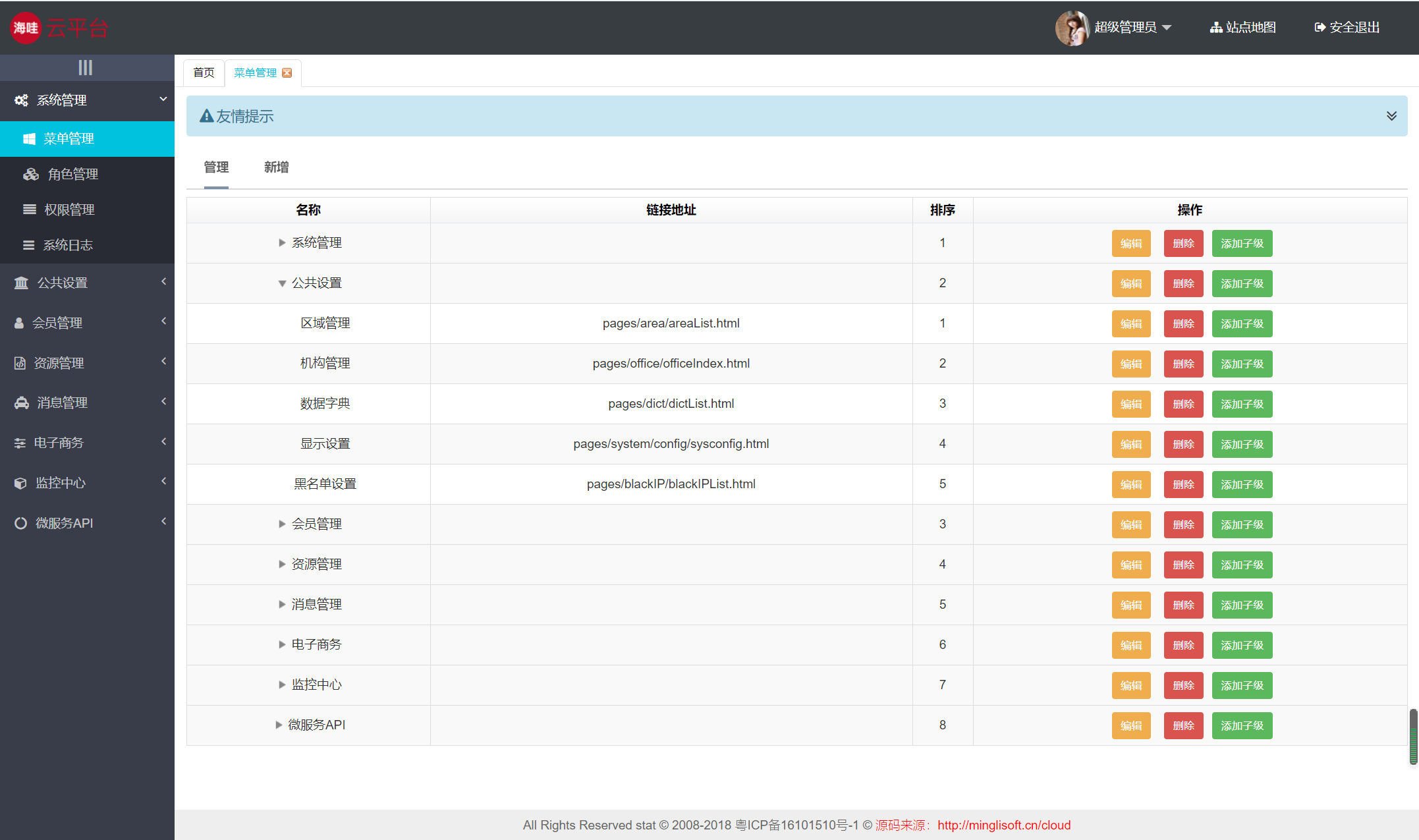
Java面试知识点(全)
导航: https://nanxiang.blog.csdn.net/article/details/130640392
注:随时更新
从数据传输方式理解IO流
从数据传输方式或者说是运输方式角度看,可以将 IO 类分为:
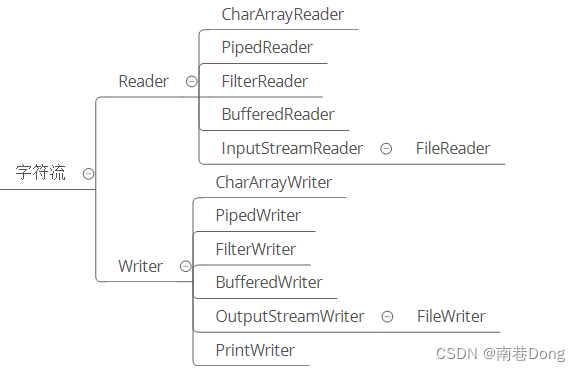
字节流, 字节流读取单个字节,字符流读取单个字符(一个字符根据编码的不同,对应的字节也不同,如 UTF-8 编码中文汉字是 3 个字节,GBK编码中文汉字是 2 个字节。)
字符流, 字节流用来处理二进制文件(图片、MP3、视频文件),字符流用来处理文本文件(可以看做是特殊的二进制文件,使用了某种编码,人可以阅读)。
字节是给计算机看的,字符才是给人看的
- 字节流

- 字符流
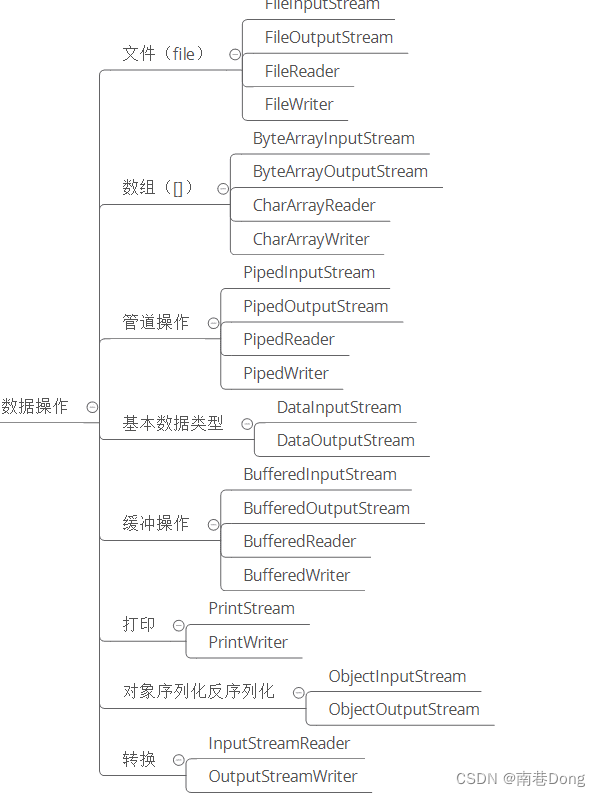
从数据操作上理解IO流
从数据来源或者说是操作对象角度看,IO 类可以分为:
Java IO设计上使用了什么设计模式
装饰者模式: 所谓装饰,就是把这个装饰者套在被装饰者之上,从而动态扩展被装饰者的功能。
装饰者举例:设计不同种类的饮料,饮料可以添加配料,比如可以添加牛奶,并且支持动态添加新配料。每增加一种配料,该饮料的价格就会增加,要求计算一种饮料的价格。
以 InputStream 为例
InputStream 是抽象组件;FileInputStream 是 InputStream 的子类,属于具体组件,提供了字节流的输入操作;FilterInputStream 属于抽象装饰者,装饰者用于装饰组件,为组件提供额外的功能。例如 BufferedInputStream 为 FileInputStream 提供缓存的功能。
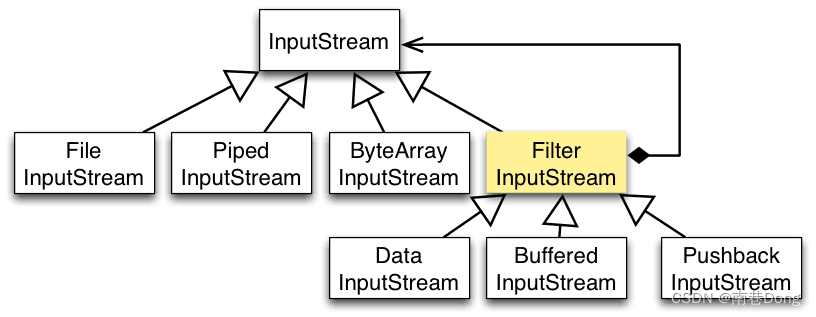
实例化一个具有缓存功能的字节流对象时,只需要在 FileInputStream 对象上再套一层 BufferedInputStream 对象即可
FileInputStream fileInputStream = new FileInputStream(filePath);
BufferedInputStream bufferedInputStream = new BufferedInputStream(fileInputStream);
阻塞?同步?概念
- 阻塞IO 和 非阻塞IO
这两个概念是程序级别的。
主要描述的是程序请求操作系统IO操作后,如果IO资源没有准备好,那么程序该如何处理的问题: 前者等待;后者继续执行(并且使用线程一直轮询,直到有IO资源准备好了) - 同步IO 和 非同步IO
这两个概念是操作系统级别的。主要描述的是操作系统在收到程序请求IO操作后,如果IO资源没有准备好,该如何响应程序的问题: 前者不响应,直到IO资源准备好以后;后者返回一个标记(好让程序和自己知道以后的数据往哪里通知),当IO资源准备好以后,再用事件机制返回给程序。
Linux的IO模型
网络IO的本质是socket的读取,socket在linux系统被抽象为流,IO可以理解为对流的操作。刚才说了,对于一次IO访问(以read举例),数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。所以说,当一个read操作发生时,它会经历两个阶段
- 第一阶段:等待数据准备 (Waiting for the data to be ready)。
- 第二阶段:将数据从内核拷贝到进程中 (Copying the data from the kernel to the process)。
对于socket流而言,
- 第一步:通常涉及等待网络上的数据分组到达,然后被复制到内核的某个缓冲区。
- 第二步:把数据从内核缓冲区复制到应用进程缓冲区。
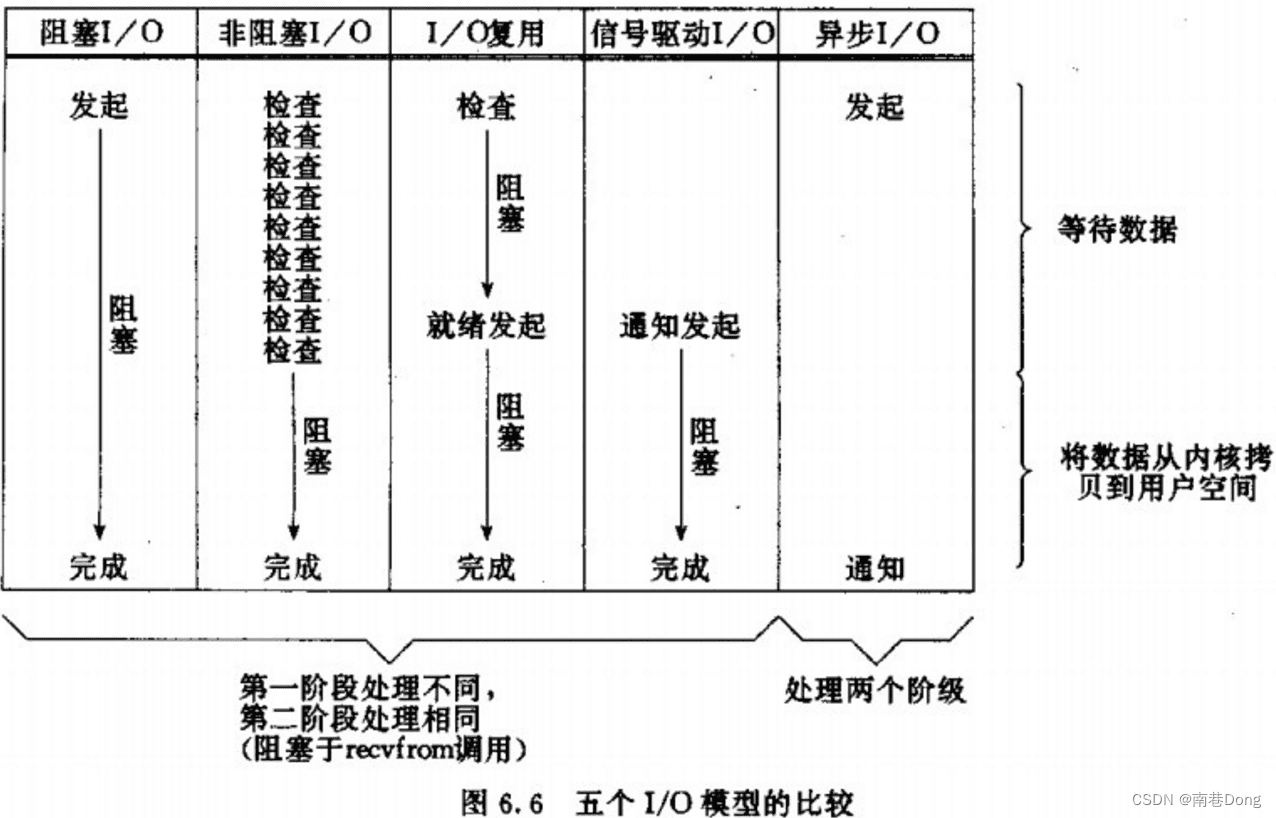
5种网络IO的模型
同步阻塞IO(bloking IO)
同步非阻塞IO(non-blocking IO)
多路复用IO(multiplexing IO)
信号驱动式IO(signal-driven IO)
异步IO(asynchronous IO)
如图:
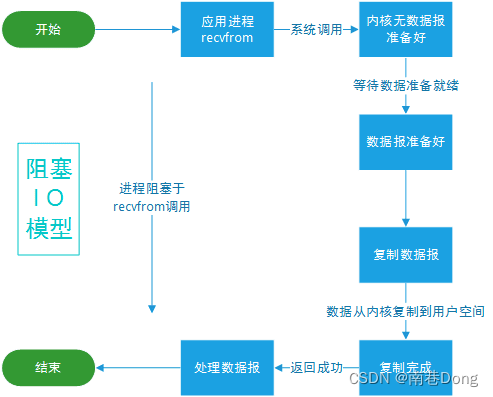
同步阻塞IO
应用进程被阻塞,直到数据复制到应用进程缓冲区中才返回
你早上去买有现炸油条,你点单,之后一直等店家做好,期间你啥其它事也做不了。(你就是应用级别,店家就是操作系统级别, 应用被阻塞了不能做其它事)
Linux 中IO图例
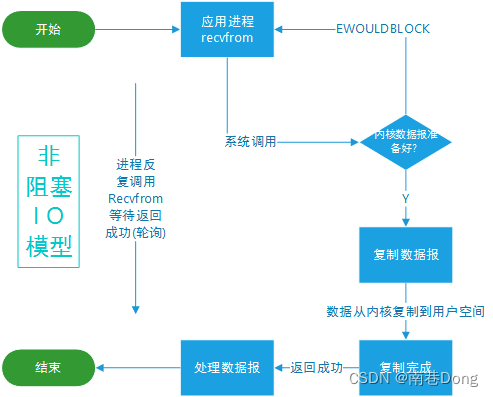
同步非阻塞IO
应用进程执行系统调用之后,内核返回一个错误码。应用进程可以继续执行,但是需要不断的执行系统调用来获知 I/O 是否完成,这种方式称为轮询(polling)
举例理解
你早上去买现炸油条,你点单,点完后每隔一段时间询问店家有没有做好,期间你可以做点其它事情。(你就是应用级别,店家就是操作系统级别,应用可以做其它事情并通过轮询来看操作系统是否完成)
Linux 中IO图例
多路复用IO
系统调用可能是由多个任务组成的,所以可以拆成多个任务,这就是多路复用。
举例理解
你早上去买现炸油条,点单收钱和炸油条原来都是由一个人完成的,现在他成了瓶颈,所以专门找了个收银员下单收钱,他则专注在炸油条。(本质上炸油条是耗时的瓶颈,将他职责分离出不是瓶颈的部分,比如下单收银,对应到系统级别也时一样的意思)
Linux 中IO图例
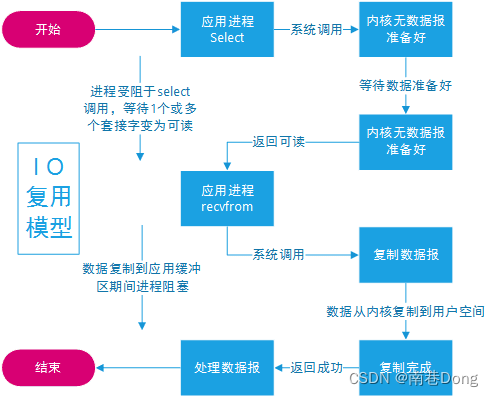
使用 select 或者 poll 等待数据,并且可以等待多个套接字中的任何一个变为可读,这一过程会被阻塞,当某一个套接字可读时返回。之后再使用 recvfrom 把数据从内核复制到进程中。它可以让单个进程具有处理多个 I/O 事件的能力。又被称为 Event Driven I/O,即事件驱动 I/O。
有哪些多路复用IO
目前流程的多路复用IO实现主要包括四种: select、poll、epoll、kqueue。下表是他们的一些重要特性的比较
如图:

多路复用IO技术最适用的是“高并发”场景,所谓高并发是指1毫秒内至少同时有上千个连接请求准备好。其他情况下多路复用IO技术发挥不出来它的优势。另一方面,使用JAVA NIO进行功能实现,相对于传统的Socket套接字实现要复杂一些,所以实际应用中,需要根据自己的业务需求进行技术选择。
信号驱动IO
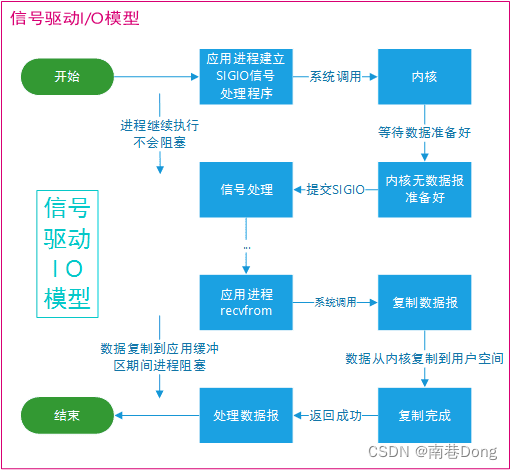
应用进程使用 sigaction 系统调用,内核立即返回,应用进程可以继续执行,也就是说等待数据阶段应用进程是非阻塞的。内核在数据到达时向应用进程发送 SIGIO 信号,应用进程收到之后在信号处理程序中调用 recvfrom 将数据从内核复制到应用进程中
相比于非阻塞式 I/O 的轮询方式,信号驱动 I/O 的 CPU 利用率更高。
举例理解
你早上去买现炸油条,门口排队的人多,现在引入了一个叫号系统,点完单后你就可以做自己的事情了,然后等叫号就去拿就可以了。(所以不用再去自己频繁跑去问有没有做好了)
Linux 中IO图例
异步IO
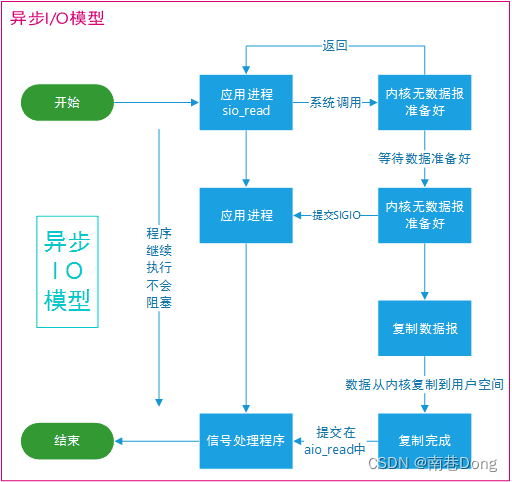
相对于同步IO,异步IO不是顺序执行。用户进程进行aio_read系统调用之后,无论内核数据是否准备好,都会直接返回给用户进程,然后用户态进程可以去做别的事情。等到socket数据准备好了,内核直接复制数据给进程,然后从内核向进程发送通知。IO两个阶段,进程都是非阻塞的。
举例理解
你早上去买现炸油条, 不用去排队了,打开美团外卖下单,然后做其它事,一会外卖自己送上门。(你就是应用级别,店家就是操作系统级别, 应用无需阻塞,这就是非阻塞;系统还可能在处理中,但是立刻响应了应用,这就是异步)
Linux 中IO图例
(Linux提供了AIO库函数实现异步,但是用的很少。目前有很多开源的异步IO库,例如libevent、libev、libuv)
Reactor模型
大多数网络框架都是基于Reactor模型进行设计和开发,Reactor模型基于事件驱动,特别适合处理海量的I/O事件
传统的IO模型
这种模式是传统设计,每一个请求到来时,大致都会按照:请求读取->请求解码->服务执行->编码响应->发送答复 这个流程去处理。
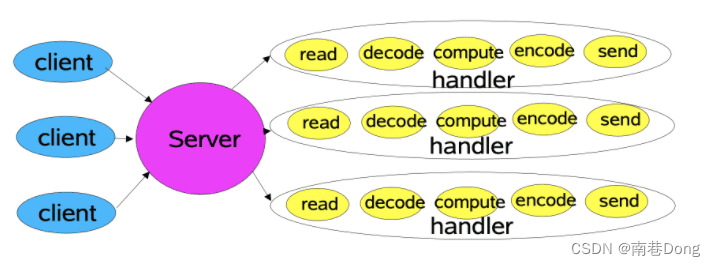
服务器会分配一个线程去处理,如果请求暴涨起来,那么意味着需要更多的线程来处理该请求。
若请求出现暴涨,线程池的工作线程数量满载那么其它请求就会出现等待或者被抛弃。若每个小任务都可以使用非阻塞的模式,然后基于异步回调模式。这样就大大提高系统的吞吐量,这便引入了Reactor模型。
Reactor模型
中定义的三种角色:
Reactor:负责监听和分配事件,将I/O事件分派给对应的Handler。新的事件包含连接建立就绪、读就绪、写就绪等。
Acceptor:处理客户端新连接,并分派请求到处理器链中。
Handler:将自身与事件绑定,执行非阻塞读/写任务,完成channel的读入,完成处理业务逻辑后,负责将结果写出channel。可用资源池来管理。
单Reactor单线程模型
Reactor线程负责多路分离套接字,accept新连接,并分派请求到handler。Redis使用单Reactor单进程的模型
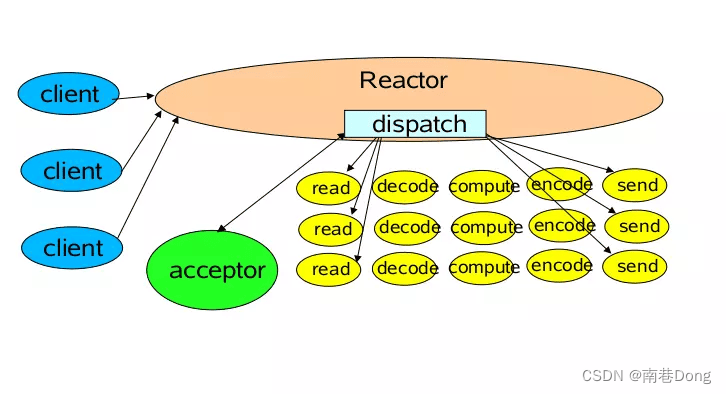
消息处理流程:
Reactor对象通过select监控连接事件,收到事件后通过dispatch进行转发。
如果是连接建立的事件,则由acceptor接受连接,并创建handler处理后续事件。
如果不是建立连接事件,则Reactor会分发调用Handler来响应。
handler会完成read->业务处理->send的完整业务流程。
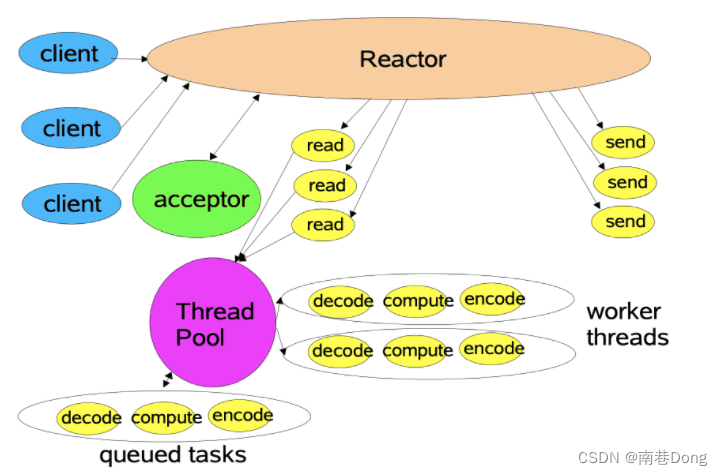
单Reactor多线程模型
将handler的处理池化
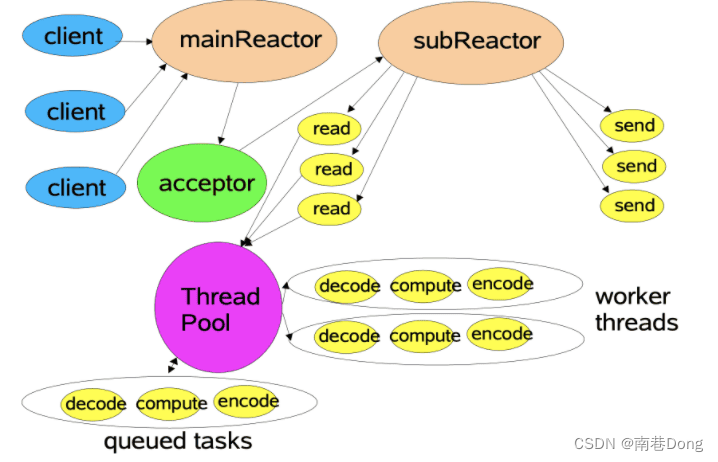
多Reactor多线程模型
主从Reactor模型: 主Reactor用于响应连接请求,从Reactor用于处理IO操作请求,读写分离了。
Java NIO
NIO主要有三大核心部分:Channel(通道),Buffer(缓冲区), Selector。
传统IO基于字节流和字符流进行操作,而NIO基于Channel和Buffer(缓冲区)进行操作,数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中。
Selector(选择区)用于监听多个通道的事件(比如:连接打开,数据到达)。因此,单个线程可以监听多个数据通道
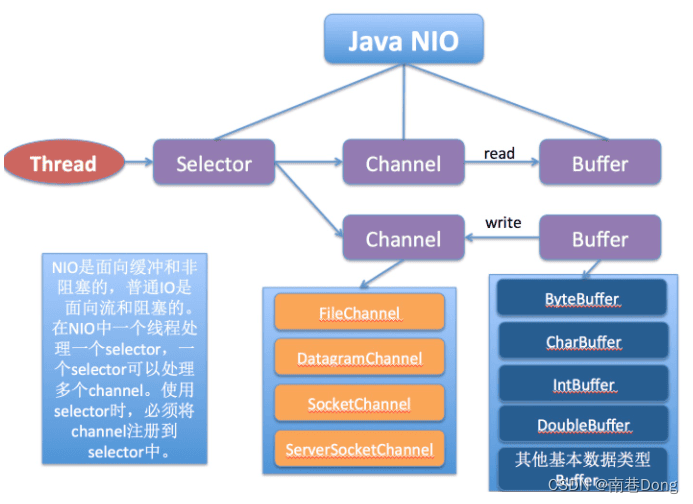
NIO和传统IO(一下简称IO)之间第一个最大的区别是,IO是面向流的,NIO是面向缓冲区的。
零拷贝
传统的IO存在什么问题?为什么引入零拷贝的?
如果服务端要提供文件传输的功能,我们能想到的最简单的方式是:将磁盘上的文件读取出来,然后通过网络协议发送给客户端。
传统 I/O 的工作方式是,数据读取和写入是从用户空间到内核空间来回复制,而内核空间的数据是通过操作系统层面的 I/O 接口从磁盘读取或写入。代码通常如下,一般会需要两个系统调用:
read(file, tmp_buf, len);
write(socket, tmp_buf, len);
代码很简单,虽然就两行代码,但是这里面发生了不少的事情。
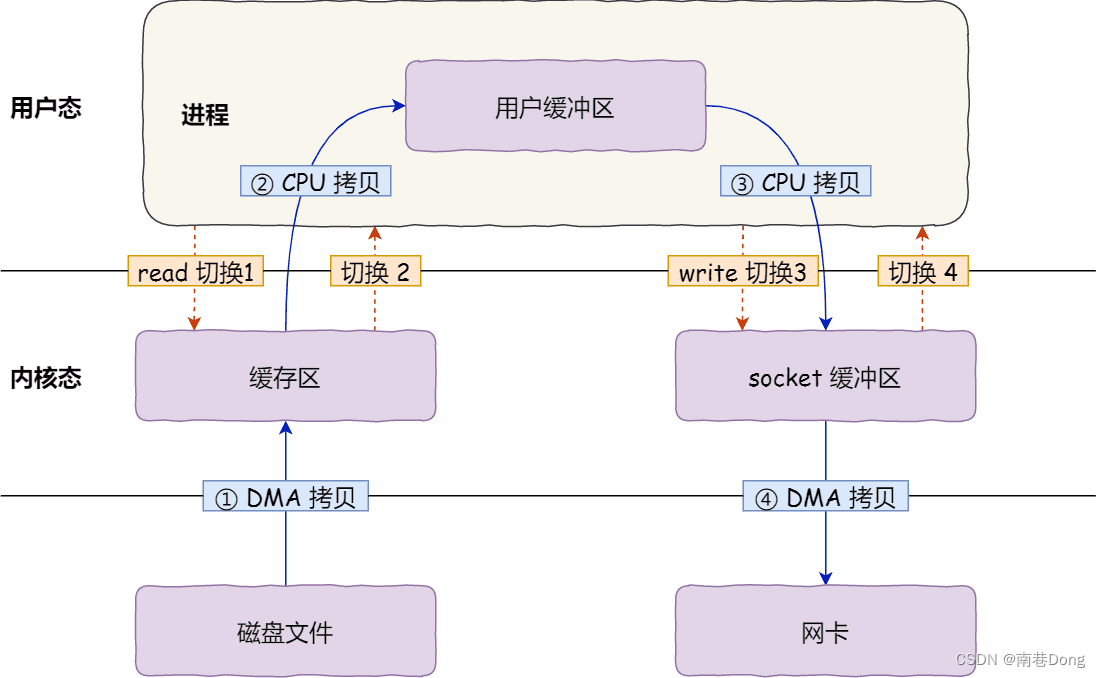
首先,期间共发生了 4 次用户态与内核态的上下文切换,因为发生了两次系统调用,一次是 read() ,一次是 write(),每次系统调用都得先从用户态切换到内核态,等内核完成任务后,再从内核态切换回用户态。
上下文切换到成本并不小,一次切换需要耗时几十纳秒到几微秒,虽然时间看上去很短,但是在高并发的场景下,这类时间容易被累积和放大,从而影响系统的性能。
其次,还发生了 4 次数据拷贝,其中两次是 DMA 的拷贝,另外两次则是通过 CPU 拷贝的,下面说一下这个过程:
第一次拷贝,把磁盘上的数据拷贝到操作系统内核的缓冲区里,这个拷贝的过程是通过 DMA 搬运的。
第二次拷贝,把内核缓冲区的数据拷贝到用户的缓冲区里,于是我们应用程序就可以使用这部分数据了,这个拷贝到过程是由 CPU 完成的。
第三次拷贝,把刚才拷贝到用户的缓冲区里的数据,再拷贝到内核的 socket 的缓冲区里,这个过程依然还是由 CPU 搬运的。
第四次拷贝,把内核的 socket 缓冲区里的数据,拷贝到网卡的缓冲区里,这个过程又是由 DMA 搬运的。
我们回过头看这个文件传输的过程,我们只是搬运一份数据,结果却搬运了 4 次,过多的数据拷贝无疑会消耗 CPU 资源,大大降低了系统性能。这种简单又传统的文件传输方式,存在冗余的上文切换和数据拷贝,在高并发系统里是非常糟糕的,多了很多不必要的开销,会严重影响系统性能。
所以,要想提高文件传输的性能,就需要减少「用户态与内核态的上下文切换」和「内存拷贝」的次数。
mmap + write怎么实现的零拷贝
在前面我们知道,read() 系统调用的过程中会把内核缓冲区的数据拷贝到用户的缓冲区里,于是为了减少这一步开销,我们可以用 mmap() 替换 read() 系统调用函数。
buf = mmap(file, len);
write(sockfd, buf, len);
mmap() 系统调用函数会直接把内核缓冲区里的数据「映射」到用户空间,这样,操作系统内核与用户空间就不需要再进行任何的数据拷贝操作
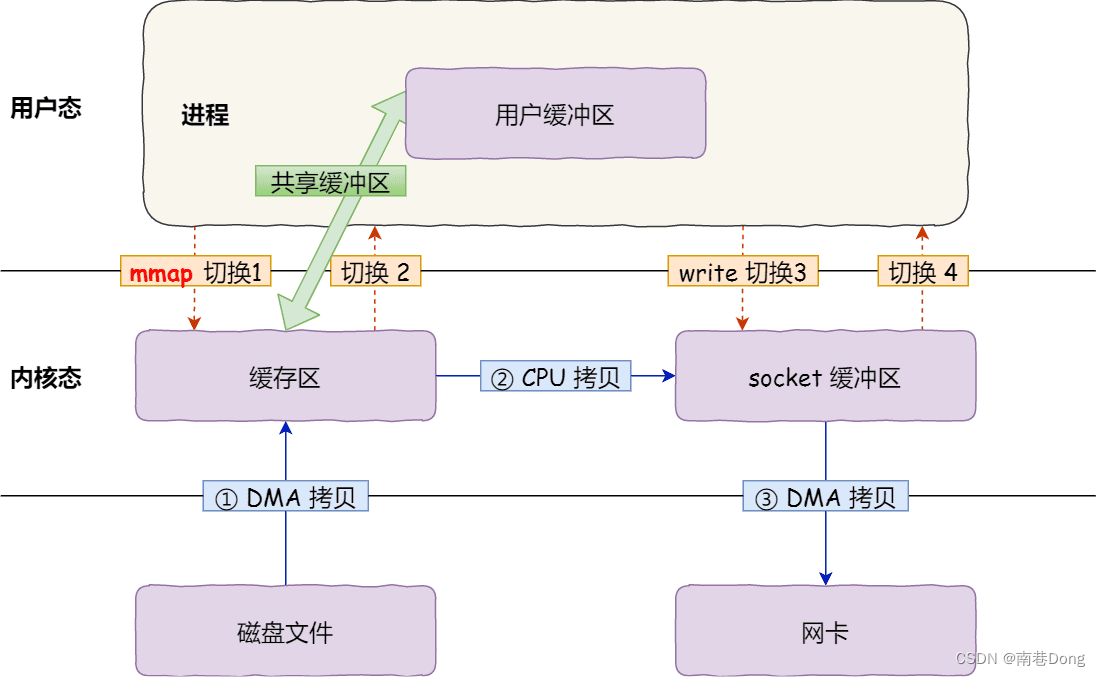
具体过程如下:
应用进程调用了 mmap() 后,DMA 会把磁盘的数据拷贝到内核的缓冲区里。接着,应用进程跟操作系统内核「共享」这个缓冲区;
应用进程再调用 write(),操作系统直接将内核缓冲区的数据拷贝到 socket 缓冲区中,这一切都发生在内核态,由 CPU 来搬运数据;
最后,把内核的 socket 缓冲区里的数据,拷贝到网卡的缓冲区里,这个过程是由 DMA 搬运的。
我们可以得知,通过使用 mmap() 来代替 read(), 可以减少一次数据拷贝的过程。
但这还不是最理想的零拷贝,因为仍然需要通过 CPU 把内核缓冲区的数据拷贝到 socket 缓冲区里,而且仍然需要 4 次上下文切换,因为系统调用还是 2 次。
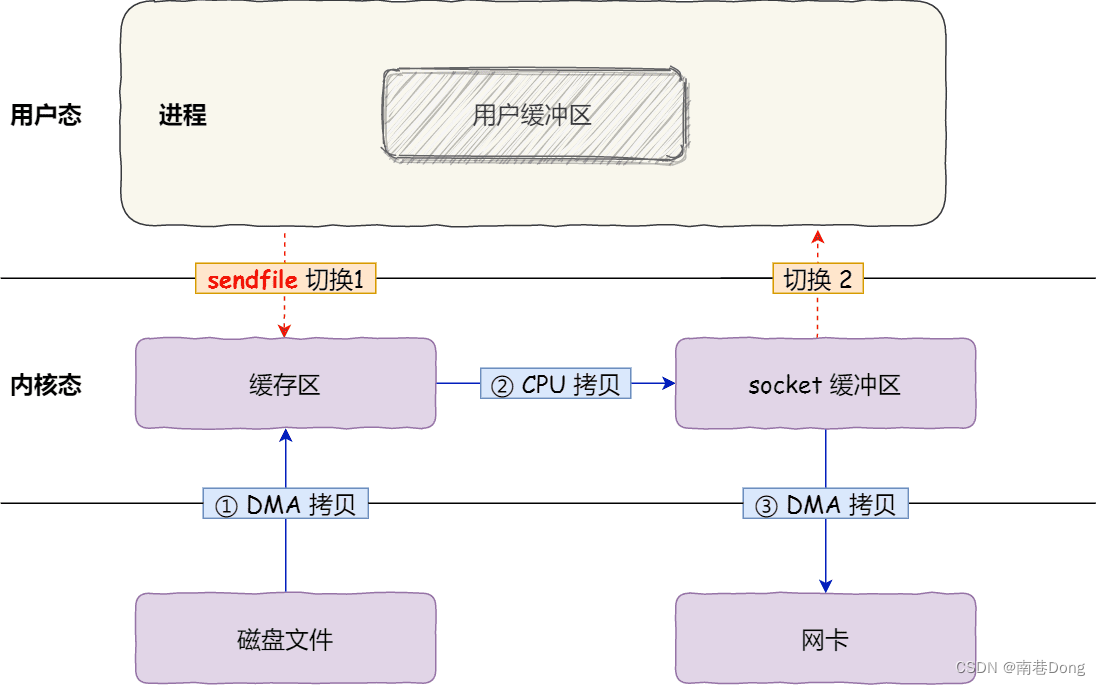
sendfile怎么实现的零拷贝
在 Linux 内核版本 2.1 中,提供了一个专门发送文件的系统调用函数 sendfile(),函数形式如下:
#include <sys/socket.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
它的前两个参数分别是目的端和源端的文件描述符,后面两个参数是源端的偏移量和复制数据的长度,返回值是实际复制数据的长度。
首先,它可以替代前面的 read() 和 write() 这两个系统调用,这样就可以减少一次系统调用,也就减少了 2 次上下文切换的开销。
其次,该系统调用,可以直接把内核缓冲区里的数据拷贝到 socket 缓冲区里,不再拷贝到用户态,这样就只有 2 次上下文切换,和 3 次数据拷贝。
如下图:
但是这还不是真正的零拷贝技术,如果网卡支持 SG-DMA(The Scatter-Gather Direct Memory Access)技术(和普通的 DMA 有所不同),我们可以进一步减少通过 CPU 把内核缓冲区里的数据拷贝到 socket 缓冲区的过程。你可以在你的 Linux 系统通过下面这个命令,查看网卡是否支持 scatter-gather 特性:
$ ethtool -k eth0 | grep scatter-gather
scatter-gather: on
于是,从 Linux 内核 2.4 版本开始起,对于支持网卡支持 SG-DMA 技术的情况下, sendfile() 系统调用的过程发生了点变化,具体过程如下:
第一步,通过 DMA 将磁盘上的数据拷贝到内核缓冲区里;
第二步,缓冲区描述符和数据长度传到 socket 缓冲区,这样网卡的 SG-DMA 控制器就可以直接将内核缓存中的数据拷贝到网卡的缓冲区里,此过程不需要将数据从操作系统内核缓冲区拷贝到 socket 缓冲区中,这样就减少了一次数据拷贝;
所以,这个过程之中,只进行了 2 次数据拷贝,如下图:
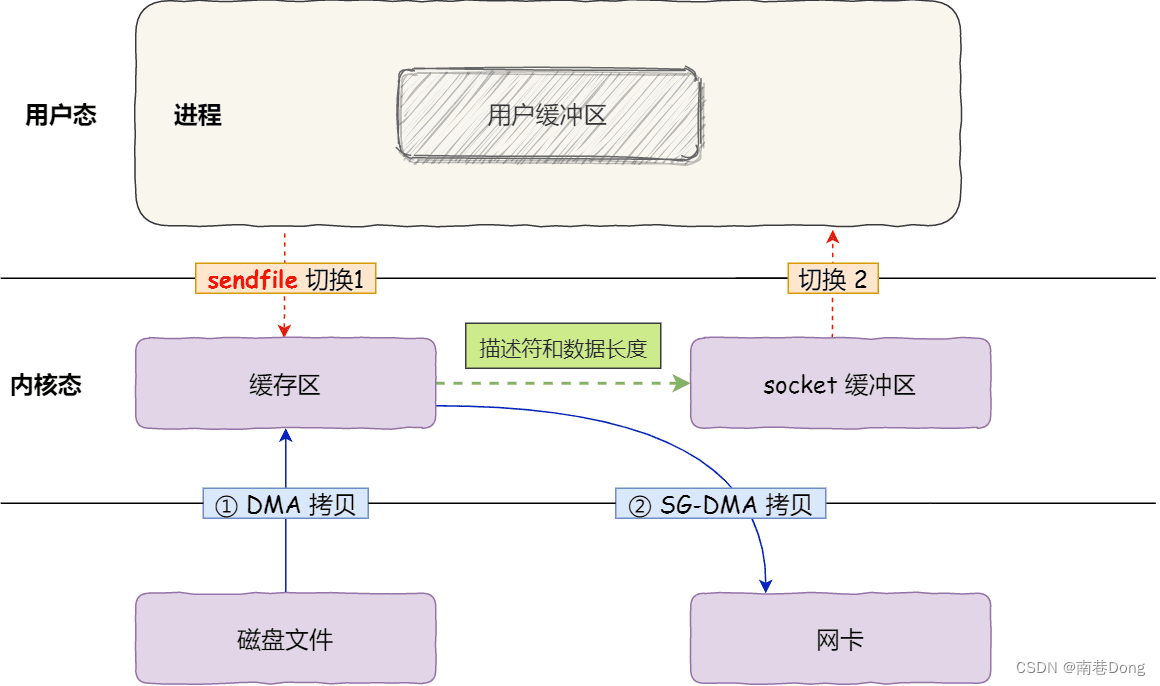
这就是所谓的零拷贝(Zero-copy)技术,因为我们没有在内存层面去拷贝数据,也就是说全程没有通过 CPU 来搬运数据,所有的数据都是通过 DMA 来进行传输的。
零拷贝技术的文件传输方式相比传统文件传输的方式,减少了 2 次上下文切换和数据拷贝次数,只需要 2 次上下文切换和数据拷贝次数,就可以完成文件的传输,而且 2 次的数据拷贝过程,都不需要通过 CPU,2 次都是由 DMA 来搬运。
注:大部分内容来自:https://www.pdai.tech/md/interview/x-interview.html#_4-3-%E9%9B%B6%E6%8B%B7%E8%B4%9D
一个非常牛的网站。
外传
😜 原创不易,如若本文能够帮助到您的同学
🎉 支持我:关注我+点赞👍+收藏⭐️
📝 留言:探讨问题,看到立马回复
💬 格言:己所不欲勿施于人 扬帆起航、游历人生、永不言弃!🔥