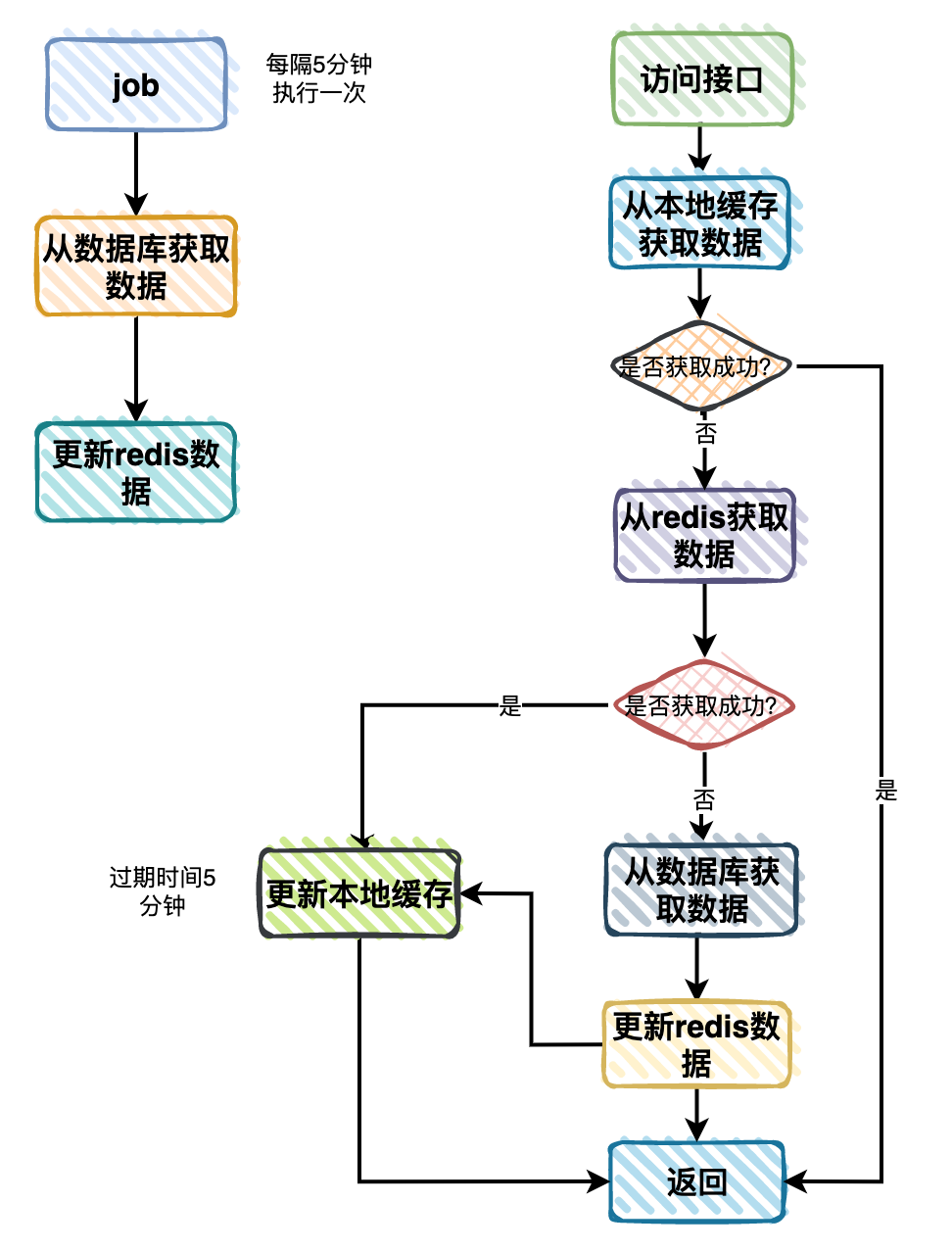
很多机器学习数据集是从网页上抓取过来的。
网页数据抓取与网页爬虫的区别:数据抓取:特定的数据, 网页爬虫:将整个网页获取
数据科学家主要进行网页数据抓取,对网页上的特定数据感兴趣。
网页数据获取工具
- curl 通常不起作用
- 通常使用headless 浏览器,没有头,没有界面的浏览器。

如果要大量爬取,需要使用IP代理池。
案例-房价预测
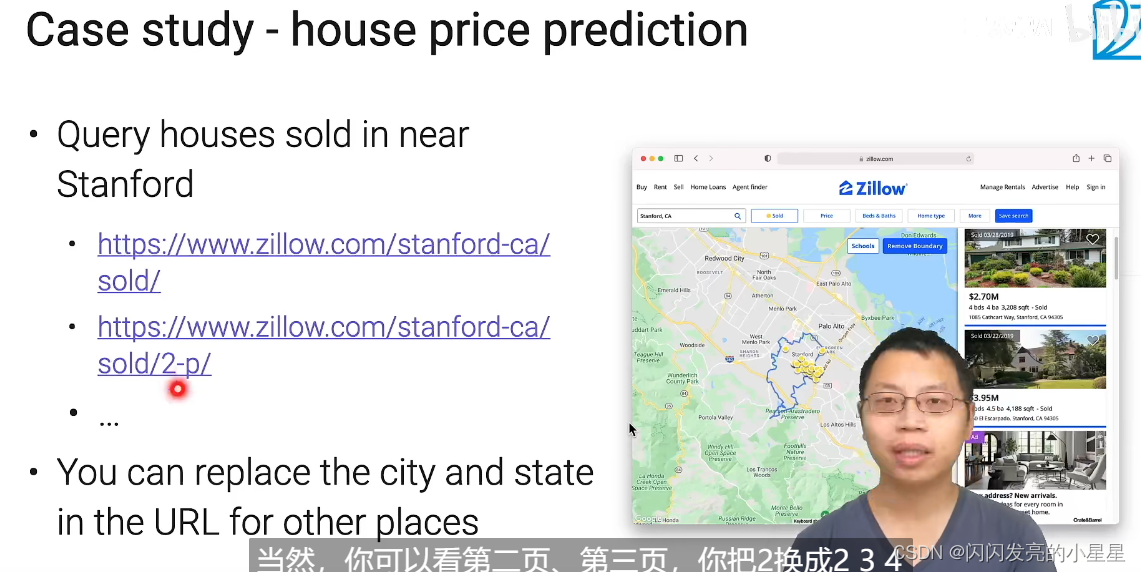
换成不同的page, 或者不同的城市,将这些要获取的对象放入代码中。
原始网页
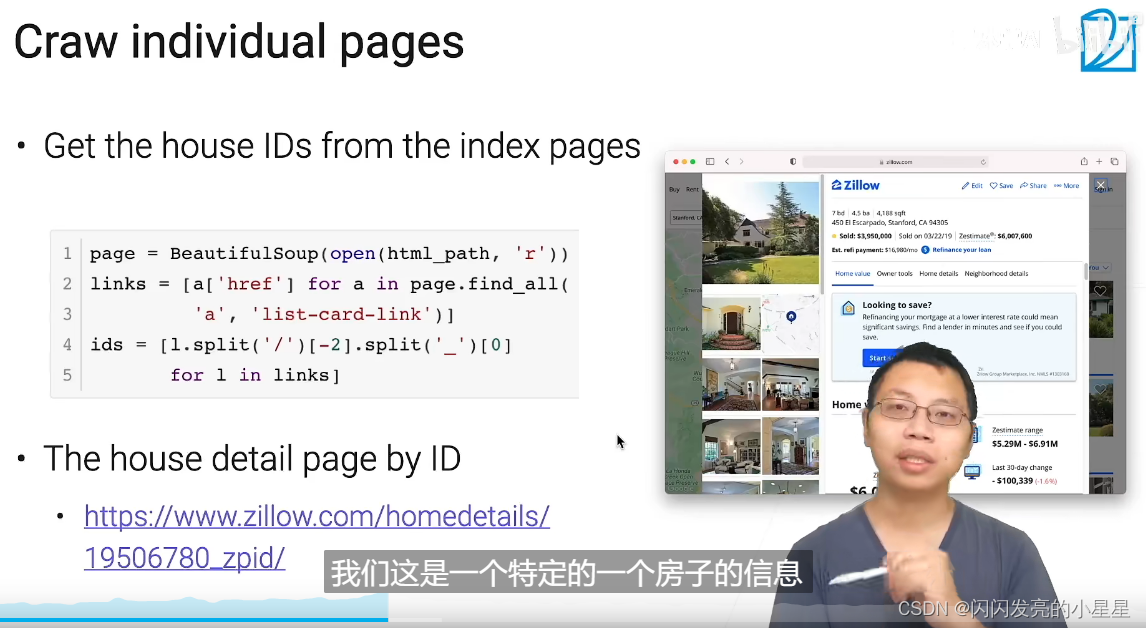
BeautifulSoup: 主要用于解析HTML
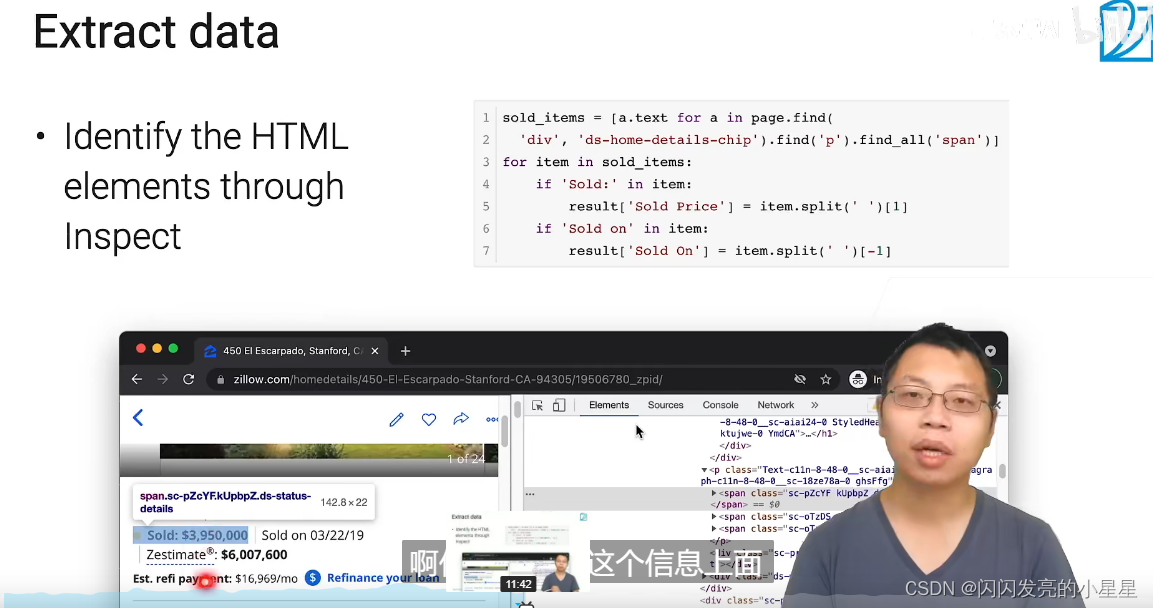
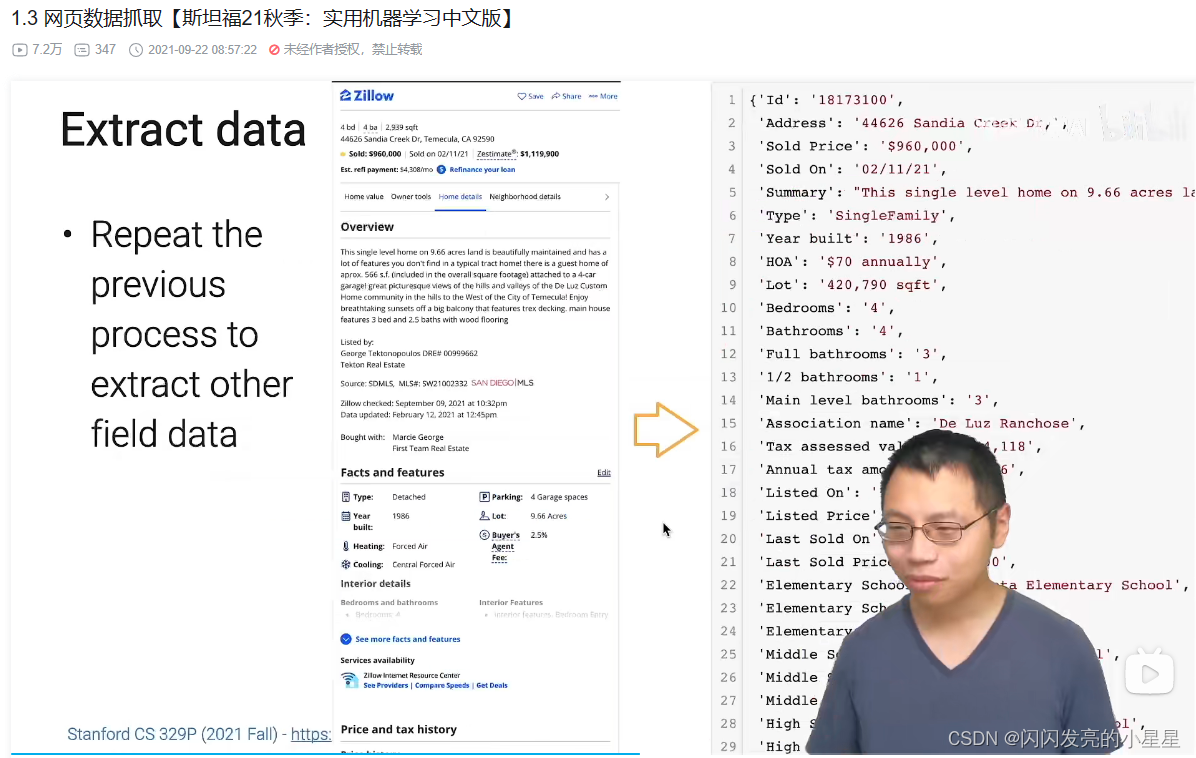
将需要的信息抽取返回保存

爬虫关键是内存,可能会同时爬多个网页,内存消耗大。
如果ip被禁,重启会重新分配ip
爬取图片

图片抓取后,将图片存在云端比较耗钱。
法律性

爬虫本身是不违法的,最好不要去爬一些需要登陆login 的信息,这些一般是隐私数据。
不要去爬一些有版权的信息,比如有版权的视频、文档等。 爬本身没有问题,但是保存下来有问题。
爬虫结果不要用于盈利。
总结
来源
https://www.bilibili.com/video/BV1JM4y137kK/?spm_id_from=333.999.0.0&vd_source=3fd64243313f29b58861eb492f248b34添加链接描述