目录
准备
操作
上传数据数据
训练进度
推理
验证
异常处理
总结
参考资料
ChatGLM微调 ptuning
准备
接上文https://blog.csdn.net/dingsai88/article/details/130639365
部署好ChatGLM以后,对它进行微调
操作
如果已经使用过 API 或者web模式的应该已经下载过,不用再下载
pwd
/mnt/workspace/
git clone https://github.com/THUDM/ChatGLM-6B
上传数据数据
pwd
/mnt/workspace/ChatGLM-6B/ptuning
方法1自己的数据:
mkdir AdvertiseGen
cd AdvertiseGen
上传 dev.json 和 train.json 到
/mnt/workspace/dev.json /mnt/workspace/ChatGLM-6B/ptuning/AdvertiseGen/
数据内容都是:数据量太多训练太慢
{"content": "你是谁", "summary": "你好,我是赛赛的朋友晨晨,江湖人称细哥。"}
{"content": "晨晨", "summary": "帅的一批"}
方法2:官网提供的方法:
准备训练的数据:下载地址会变
从 Google Drive 或者 Tsinghua Cloud 下载处理好的 ADGEN 数据集,将解压后的 AdvertiseGen 目录放到本目录下。
https://github.com/THUDM/ChatGLM-6B/blob/main/ptuning/README.md
https://cloud.tsinghua.edu.cn/f/b3f119a008264b1cabd1/?dl=1
https://cloud.tsinghua.edu.cn/f/b3f119a008264b1cabd1/?dl=1
curl -O https://cloud.tsinghua.edu.cn/seafhttp/files/xxxxxx/AdvertiseGen.tar.gz
tar -zxvf AdvertiseGen.tar.gz训练
P-Tuning v2
pwd
/mnt/workspace/ChatGLM-6B/ptuning
安装依赖
pip install fastapi uvicorn
vi train.sh
删除(走128默认值) --quantization_bit 4
开始训练
bash train.sh训练进度
查看GPU使用
watch -n 0.5 nvidia-smi

查看进度

推理
pwd
/mnt/workspace/ChatGLM-6B/ptuning
vi evaluate.sh
删除(走128默认值) --quantization_bit 4
bash evaluate.sh验证
pwd
/mnt/workspace/ChatGLM-6B/ptuning
路径:
/mnt/workspace/ChatGLM-6B/ptuning/output/adgen-chatglm-6b-pt-128-2e-2/checkpoint-3000Python
import os
import torch
from transformers import AutoConfig, AutoModel, AutoTokenizer
CHECKPOINT_PATH = "./output/adgen-chatglm-6b-pt-128-2e-2/checkpoint-3000"
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
config = AutoConfig.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True, pre_seq_len=128)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", config=config, trust_remote_code=True).cuda()
prefix_state_dict = torch.load(os.path.join(CHECKPOINT_PATH, "pytorch_model.bin"))
new_prefix_state_dict = {}
for k, v in prefix_state_dict.items():
if k.startswith("transformer.prefix_encoder."):
new_prefix_state_dict[k[len("transformer.prefix_encoder."):]] = v
model.transformer.prefix_encoder.load_state_dict(new_prefix_state_dict)
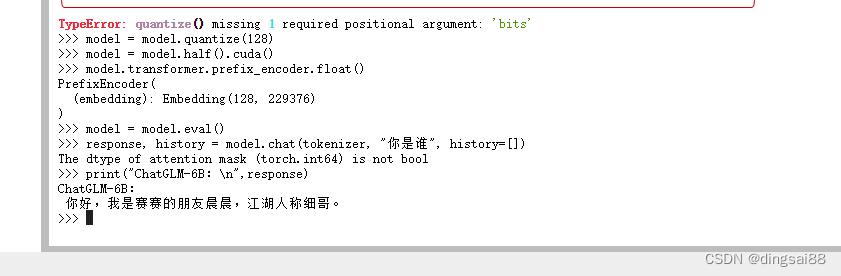
print(f"Quantized to 128 bit")
model = model.quantize(128)
model = model.half().cuda()
model.transformer.prefix_encoder.float()
model = model.eval()
response, history = model.chat(tokenizer, "你是谁", history=[])
print("ChatGLM-6B:\n",response)
问题:你是谁
标准答案:
我是一个名为 ChatGLM 的人工智能助手,是清华大学 KEG 实验室和智谱 AI 公司于 2023 年共同训练的语言模型。我的任务是针对用户的问题和要求提供适当的答复和支持。

微调后的答案
你好,我是赛赛的朋友晨晨,江湖人称细哥。
异常处理
异常1:
RuntimeError: CUDA Error: no kernel image is available for execution on the device
RuntimeError: CUDA Error: no kernel image is available for execution on the device
>>> model = model.quantize()
╭─────────────────────────────── Traceback (most recent call last) ────────────────────────────────╮
│ in <module>:1 │
╰──────────────────────────────────────────────────────────────────────────────────────────────────╯
TypeError: quantize() missing 1 required positional argument: 'bits'
model = model.quantize(4)
改成
model = model.quantize(128)
异常2:
root@eais-bjtryzm9xivr28qvprxr-7c8cfdfd44-2j4rx:/mnt/workspace/ChatGLM-6B/ptuning# bash train.sh
Traceback (most recent call last):
File "main.py", line 29, in <module>
from rouge_chinese import Rouge
ModuleNotFoundError: No module named 'rouge_chinese'
安装依赖解决 : pip install rouge_chinese nltk jieba datasets异常3:
RuntimeError: CUDA Error: no kernel image is available for execution on the device
“调整 quantization_bit 来被原始模型的量化等级,不加此选项则为 FP16 精度加载”
bash train.sh
cp train.sh train_bak.sh
vi train.sh
删除 --quantization_bit 4异常4:
pip install cpm_kernels
ImportError: This modeling file requires the following packages that were not found in your environment: cpm_kernels. Run `pip install cpm_kernels`
pip install cpm_kernels总结
- 官网写的都很清楚了。
- GPU特别影响计算时间,算力不够的小伙伴先训练几条看看流程是否通畅。
参考资料
ChatGLM-6B/README.md at main · THUDM/ChatGLM-6B · GitHub
https://blog.csdn.net/dingsai88/article/details/130639365
https://betheme.net/dashuju/127318.html