Image-to-Image Translation Using Conditional Adversarial Networks
1:
pix2pix也是CGAN的一种,pix2pix可以学习输入到输出的映射,同时也学习了损害函数去训练这个映射。这是一个大一统的方法去实现从标签合成图像,从边界图重建物体,给图片上色等。
传统的方法对每一个上述任务都有一个特定的模型设计,损失函数设计等。本文设计的commom framwork可以实现所有的从像素预测像素的问题。
模型设计也借助了CNN这个工具,并且希望CNN可以按我们希望的那样来做,本文使用CGAN的思想,给输入添加条件,产生一个相应的输出。pix2pix生成器采用U-Net,辨别器采用PatchGAN。
2:
CGAN的目标函数:

将辨别器D的条件去掉后,目标函数就变为:
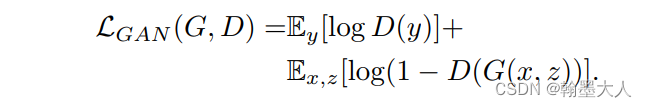
之前方法发现GAN和一个传统的损失结合效果更好,比如L2,辨别器的作用不变,生成器不仅要骗过辨别器还要尽可能接近GT。L1损失相比于L2损失可以产生更少的模糊:
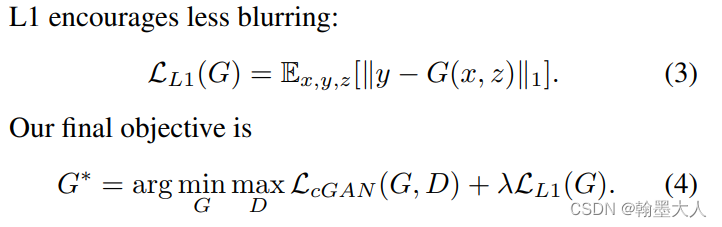
如果没有z,那么网络就会产生确定的输出,就不能匹配数据的任意分布了。CGAN使用的噪声z输入到G中,但是在作者实验中发现这种策略并不是很有效。生成器会忽略这个噪声,因此作者使用dropout在训练和测试应用于生成器的前几层。
3:
网络结构:
3.1:带有跳跃连接生成器
输入和输出尽管在表面不相同但是他们都共享内在的结构,因此输入结构和和输出结构大致是对齐的。多数方法采用的encoder-decoder结构使信息流过所有的层,作者还添加了跳连接,可以将encoder的细节等信息引入到decoder中。
3.2:PatchGAN:
L2损失和L1损失在图像生成时产生模糊的结果,尽管这些损失不能够恢复高频细节,但是却能够捕捉低频细节。

因此需要限制GAN辨别器不仅可以建模高频结构,而且需要依赖L1矫正低频。为了建模高频,我们需要将注意力放在局部图像块,因此我们设计了辨别器PatchGAN,辨别器尝试分类每一个NXN的块是否是真或假。平均每一个patch的结果产生最终的输出。
4:
优化和推理:
在推理阶段使用和训练一样的方法,使用batchnorm,如果batchsize为1,那么bn就变为instancenorm。测试/推理设置在测试时候不能使用model.eval,因为那样会固定所有神经元就无法随机dropout来增加随即性。
5:
实验:

5.1评价指标:
AMT
FCN-score:用于lable-photo映射,将映射的图片输入到FCN中,产生的labelmap和真实的GT进行计算。

5.2:目标函数分析:

pix2pix
news2026/2/15 13:50:47
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/531726.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
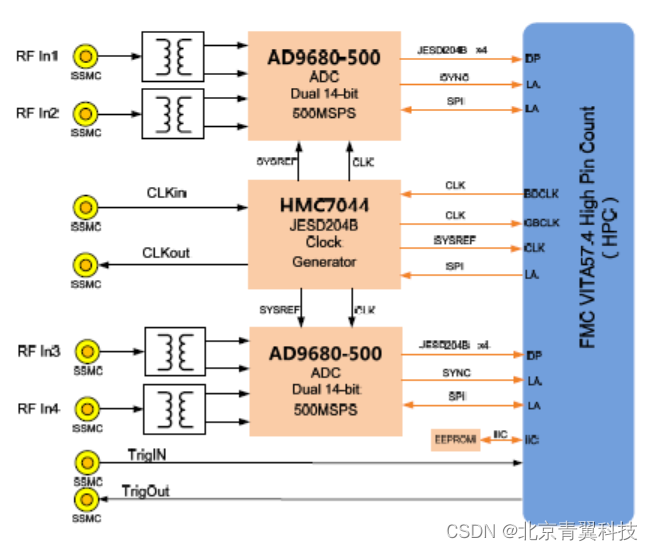
【FMC139】多通道采集--基于 VITA57.1 标准的4 路500MSPS/1GSPS 14 位AD 采集子卡模块(AD9680/HMC7044)
板卡概述
FMC139 是一款基于VITA57.1 标准规范的JESD204B 接口FMC 子卡模块,该模块可以实现4 路14-bit、500MSPS/1GSPSADC采集功能。该板卡ADC 器件采用ADI 公司的AD9680 芯片,全功率-3dB 模拟输入带宽可达2GHz。该ADC 与FPGA 的主机接口通过8通道的高速串行GTX 收…
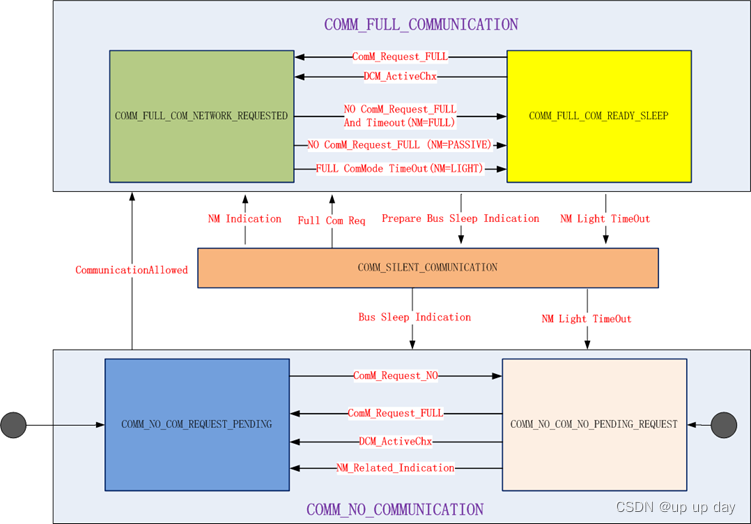
AutoSAR PNC和ComM
文章目录 PNC和ComMPNC管理NM PDU结构及PNC信息位置如何理解节点关联PNCPNC状态管理 ComM 通道状态管理 PNC和ComM
PNC 和 ComM层的Channel不是一个概念,ComM的Channel对应具体的物理总线数。
在ComM模块中,一个Channel可以对应一个PNC,也可…

AIGC产业研究报告2023——语言生成篇
易观:今年以来,随着人工智能技术不断实现突破迭代,生成式AI的话题多次成为热门,而人工智能内容生成(AIGC)的产业发展、市场反应与相应监管要求也受到了广泛关注。为了更好地探寻其在各行业落地应用的可行性…

电脑无法安装软件?不用慌,这样做可以快速解决!
案例:为什么我的电脑不能下载软件?
【在学习的过程中,需要下载一些软件工具。按照老师给的软件步骤,电脑还是无法安装软件,有小伙伴知道怎么回事吗?】
在使用电脑的过程中,很多小伙伴都会遇到…
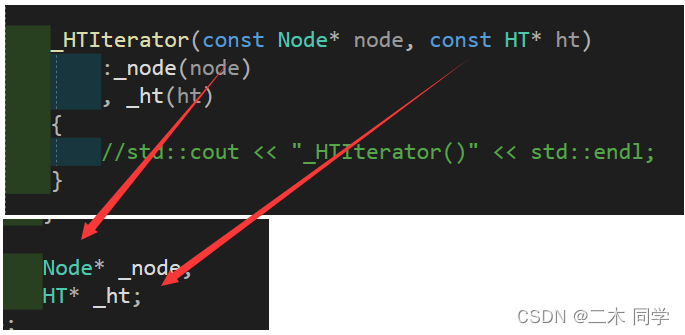
【C++】unordered_map和unordered_set的模拟实现
一、改造HashTable
实现了哈希表(开散列),再将其封装为unordered_map和unordered_set。
HashTable的改造与RBTree的改造大致相同:
改造节点
template<class T>
struct HashNode
{//std::pair<K, V> _kv;//HashNod…
【AI思维空间】ChatGPT纵横编程世界,点亮智慧火花 | 京东云技术团队
作者:京东零售 王英杰
概述
该文档记录云交易开发小伙伴儿们在开发过程中的实际应用案例,记录典型案例,以解决开发过程中的实际问题为主,涵盖设计方案、编码、测试、集成、部署等等。 目的:贡献最佳实践,…
案例6:Java社区志愿者服务系统设计与实现开题报告
博主介绍:✌全网粉丝30W,csdn特邀作者、博客专家、CSDN新星计划导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专…

全面升级:知否AI问答场景导航功能震撼登场
今日,知否AI问答平台推出全新的场景功能,为用户提供更全面、高效的智能问答服务,再也不用担心找不到适合自己的场景入口了。
此次升级涵盖了50多个场景,包括论文助手、公司文案、营销文案、多语言翻译、行政公文、科研课题、招投…

bat脚本、dos命令
bat脚本
bat脚本就是DOS批处理脚本,就是将一系列DOS命令按照一定顺序排列而形成的集合,运行在windows命令行环境上。这个文件的每一行都是一条DOS命令
在命令提示下键入批处理文件的名称,或者双击该批处理文件,系统就会调用Cmd.…

浅谈Gradle构建工具
一、序言
常见的项目构建工具有Ant、Maven、Gradle,以往项目常见采用Maven进构建,但随着技术的发展,越来越多的项目采用Gradle进行构建,例如 Spring-boot。Gradle站在了Ant和Maven构建工具的肩膀上,使用强大的表达式语…

千万不要乱操作了!医院机房这么做真高级
各类中心数据机房广泛分布于银行、库房、交通、电信、医院、教育等行业。系统故障和人为操作不当可能导致各种业务中断或数据丢失,进而影响企业业务的停滞和运行。 医院管理3大难题和挑战
01.缺乏预警、告警机制
医院在使用自动化监控系统之前,主要靠人…
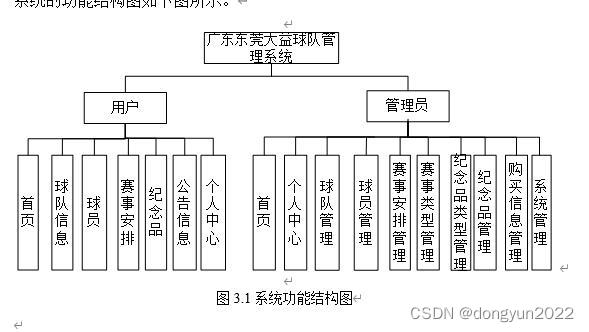
springboot足球赛事安排球队管理系统
系统主要有球队赛程安排,包括比赛数据,球员信息,球员实时数据,球队纪念品售卖 Spring Boot 是 Spring 家族中的一个全新的框架,它用来简化Spring应用程序的创建和开发过程。也可以说 Spring Boot 能简化我们之前采用SS…

09——path的使用
一、path 是 svg 中最强大的图形
用于定义一个 路径所有命令均允许小写字母。大写 表示绝对定位,小写 表示 相对定位 (相对于上一个结束的坐标)d 属性中包含所有路径的点,可根据命令缩写 自由组合 命令 名称 …
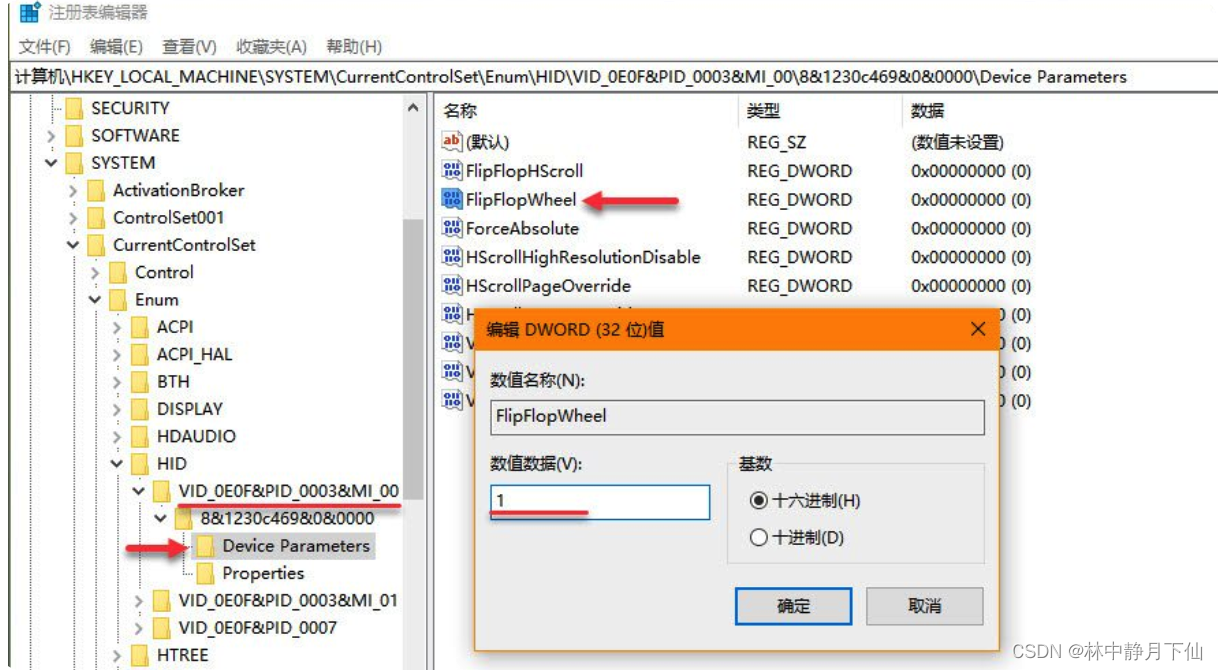
Windows 11 反转鼠标和触摸板滚动方向
如果在使用 Windows 10 设备时不喜欢鼠标或触摸板的「下滚上移,上滚下移」方式,可以通过调整「Windows 设备」或更改注册表 2 种方式来反转滚动方向。
下面就为大家介绍详细步骤。
Windows 11反转触摸板滚动方向
要通过调整「Windows 设置」反转触摸板…

企业为什么需要一套CRM系统进行销售管理
随着市场竞争的日益激烈和消费者的日益挑剔,企业要想在市场中取得优势地位,就需要通过有效的销售管理来提高销售业绩。而CRM系统作为企业实现销售管理的最佳选择,越来越受到企业的重视和关注。 一、CRM系统的优势 1. 提高销售流程管理效率
C…

车载AUTOSAR和OSEK关系及网络管理的异同(NM)
AUTOSAR和OSEK关系及网络管理比较 AUTOSAR和OSEK关系及网络管理比较 AUTOSAR和OSEK关系及网络管理比较AUTOSAR与OSEK的关系AUTOSARAUTOSAR架构和标准的目标是:AUTOSAR架构的主要特点是:AUTOSAR标准有四个核心内容: OSEK其特点主要有以下几个方…
基于SSM+JSP的高校学生健康档案管理系统
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:采用JSP技术开发 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目&#x…

【ChatGPT】ChatGPT-5 到底有多强?
目录 1、ChatGPT-5 到底有多强2、技术方向3、系统特点4、系统应用5、ChatGPT-5为什么停止训练? 1、ChatGPT-5 到底有多强
OpenAI 最新的自然语言处理技术 ChatGPT-5 近期发布,拥有过去版本的一系列升级和改进。那么,在 ChatGPT-4 强大的基础…