文章目录
- 1. 收集数据
- 2. 准备数据
- 3. 选择模型
- 4. 训练模型
- 5. 评估模型
- 6. 参数调整
- 7. 进行预测
- 在Python中实现机器学习模型
机器学习是一种人工智能的分支,它使用算法和统计模型来让计算机系统自动地从数据中学习,并根据学习结果做出预测或决策。机器学习的目标是让计算机系统通过学习数据中的模式和规律,从而能够自主地进行分类、预测、识别、优化等任务,并不断地改进自己的性能。机器学习应用广泛,包括自然语言处理、计算机视觉、语音识别、推荐系统、金融风险管理等领域。
将智能赋予机器的任务似乎是艰巨而不可能的。但实际上,它非常容易。它可以分为7个主要步骤
1. 收集数据
机器是从我们提供的数据中学习的。收集可靠的数据非常重要,以便我们的机器学习模型可以找到正确的模式。我们提供给机器的数据的数量和质量将决定模型的准确性。如果我们有不正确或过时的数据,我们将得到不靠谱的结果,甚至是错误结果或预测。
确保使用来自可靠来源的数据,因为它将直接影响我们的模型的结果。好的数据是相关的,包含非常少的缺失和重复值,并且具有各种子类别/类别的良好表示。
2. 准备数据
在获得数据之后,我们必须准备数据。我们可以通过以下方式完成
- 将我们拥有的所有数据放在一起并进行随机化。这有助于确保数据均匀分布,而排序不会影响学习过程。
- 清理数据以删除不需要的数据、缺失值、行和列、重复值、数据类型转换等。我们甚至可能需要重构数据集并更改行和列或行和列的索引。
- 可视化数据以了解其结构并了解各种变量和类别之间的关系。
- 将清理后的数据分成两个集合-训练集和测试集。训练集是模型学习的集合。测试集用于在训练后检查模型的准确性。

3. 选择模型
机器学习模型确定了在收集的数据上运行机器学习算法后获得的输出。选择与手头任务相关的模型非常重要。多年来,科学家和工程师开发了适用于不同任务的各种模型,如语音识别、图像识别、预测等。除此之外,我们还必须看看我们的模型是否适用于数值或分类数据,并相应选择。

4. 训练模型
训练是机器学习中最重要的步骤。在训练中,我们将准备好的数据传递给机器学习模型以查找模式并进行预测。模型从数据中学习,随着时间的推移,通过训练,模型变得更好地进行预测。

5. 评估模型
在训练模型后,我们必须检查其性能。这是通过测试模型在先前未见过的数据上的性能来完成的。使用的未见过的数据是我们之前将数据分成的测试集。如果在用于训练的相同数据上进行测试,则不会得到准确的度量结果,因为模型已经习惯了数据,并在其中找到了相同的模式。这将给我们不成比例的高准确性。
在测试数据上使用,我们将获得有关模型性能及其速度的准确度度量。

6. 参数调整
一旦我们创建并评估了模型,请查看其准确性是否可以以任何方式改进。这是通过调整模型中存在的参数来完成的。参数是程序员通常决定的模型中的变量。在参数的特定值下,准确度将达到最大值。参数调整是指查找这些值。

7. 进行预测
最后,我们可以使用我们的模型在未见过的数据上进行准确的预测。
在Python中实现机器学习模型
现在,我们将看到如何使用Python实现机器学习模型。
在此示例中,收集的数据来自一家保险公司,告诉我们设置保险金额时发挥作用的变量。使用此数据,我们将必须预测某个人的保险金额。此数据是从Kaggle.com下载的。
我们需要从导入所需的任何模块开始,如下所示。

接下来,我们将导入数据。

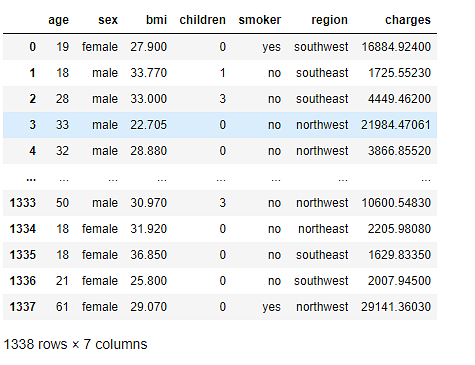
现在,通过删除重复值并将列转换为数字值以使其更易于处理来清理数据。
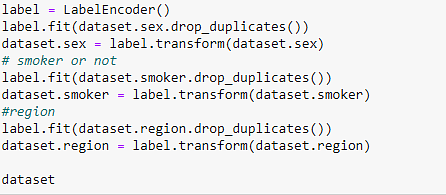
最终数据集如下所示。
现在,将数据集拆分为训练集和测试集。

由于我们需要基于某些参数预测数字值,因此必须使用线性回归。模型需要在训练集上进行学习。这是通过使用“.fit”命令完成的。

现在,预测我们的测试数据集并查找我们的预测的准确性。
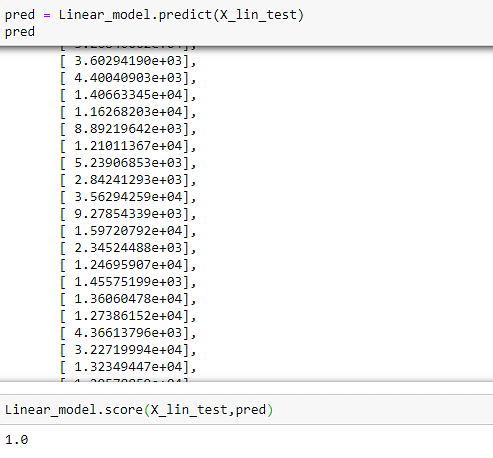
1.0是我们可以获得的最高准确度级别。现在,获取我们的参数。
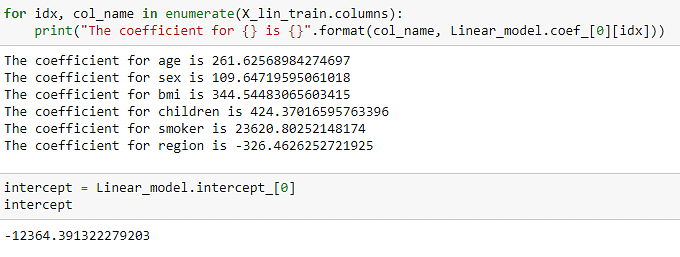
上图显示了影响数据集中各个变量的超参数。