CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
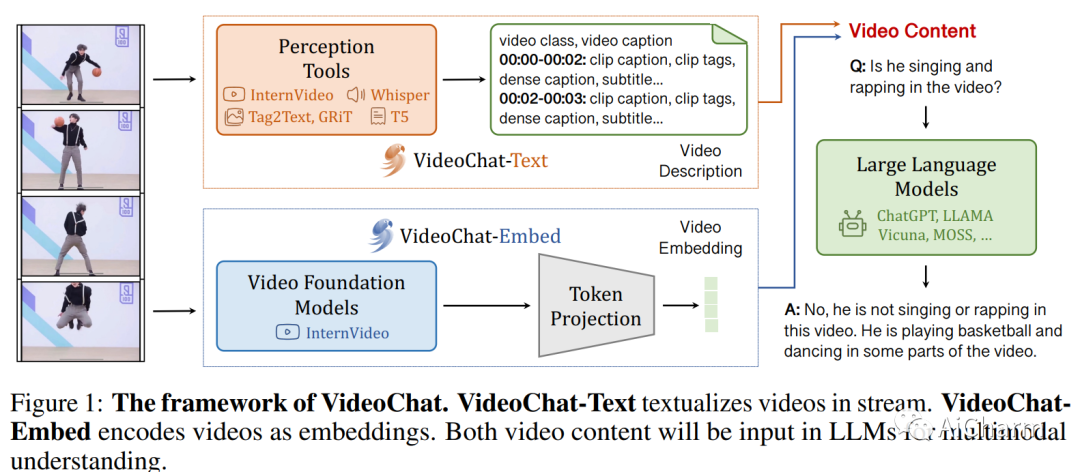
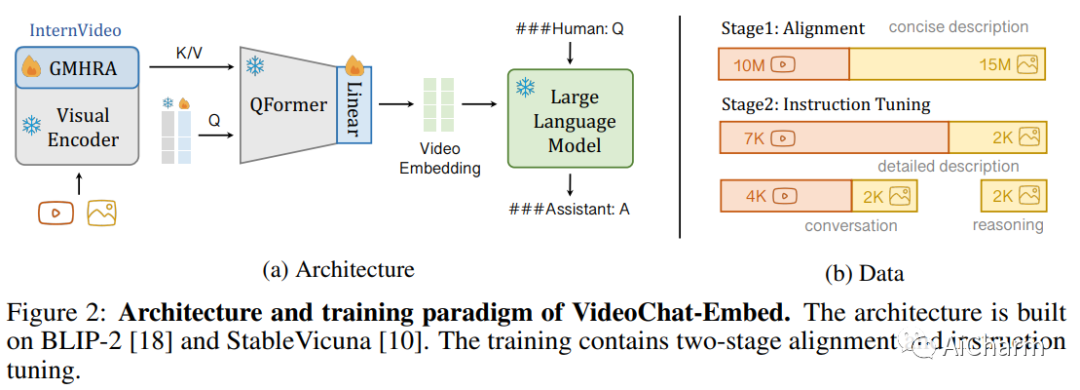
1.VideoChat: Chat-Centric Video Understanding

标题:VideoChat:以聊天为中心的视频理解
作者:KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, Yu Qiao
文章链接:https://arxiv.org/abs/2305.06355
项目代码:https://rl-at-scale.github.io/



摘要:
我们在这项研究中,我们通过引入以端到端聊天为中心的视频理解系统 VideoChat,开始对视频理解的探索。它通过可学习的神经接口集成了视频基础模型和大型语言模型,在时空推理、事件定位和因果关系推理方面表现出色。为了指导性地调整该系统,我们提出了一个以视频为中心的指令数据集,该数据集由数千个与详细描述和对话相匹配的视频组成。该数据集强调时空推理和因果关系,为训练以聊天为中心的视频理解系统提供了宝贵的资产。初步的定性实验揭示了我们的系统在广泛的视频应用中的潜力,并为未来的研究设定了标准。通过此 https URL 访问我们的代码和数据
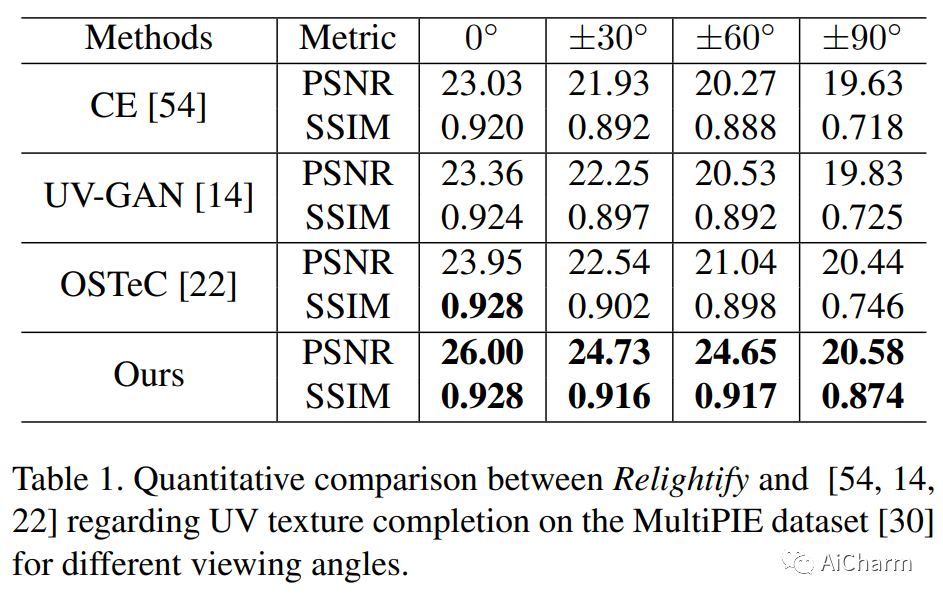
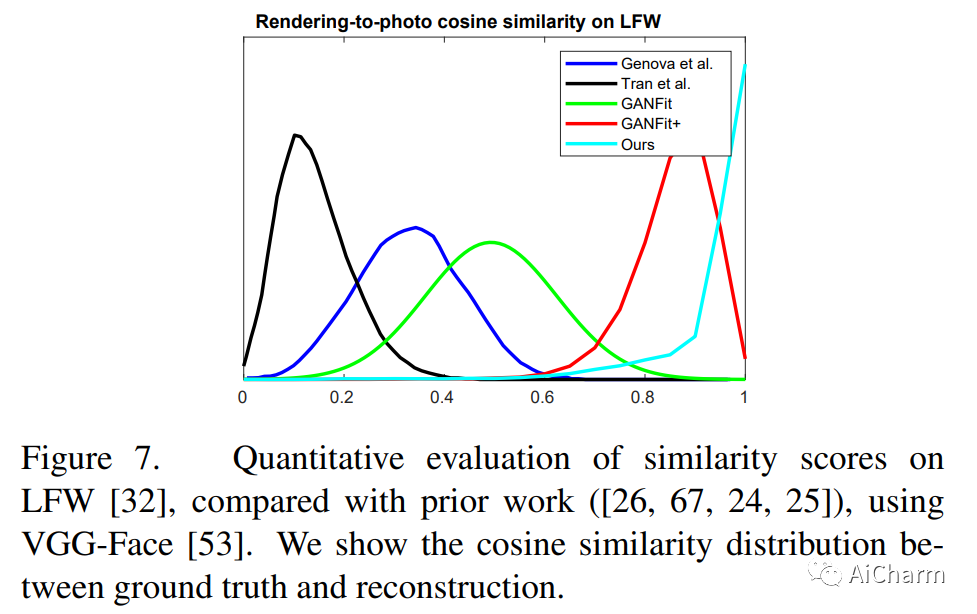
2.Relightify: Relightable 3D Faces from a Single Image via Diffusion Models

标题:Relightify:通过扩散模型从单个图像中重新照明 3D 人脸
作者:Foivos Paraperas Papantoniou, Alexandros Lattas, Stylianos Moschoglou, Stefanos Zafeiriou
文章链接:https://arxiv.org/abs/2305.06077
项目代码:https://foivospar.github.io/Relightify/


摘要:
继扩散模型在图像生成方面取得显着成功之后,最近的工作也展示了它们以无监督方式解决许多逆问题的令人印象深刻的能力,方法是根据条件输入适当地约束采样过程。受此启发,在本文中,我们提出了第一种使用扩散模型作为先验的方法,用于从单个图像进行高精度 3D 面部 BRDF 重建。我们首先利用高质量的面部反射率 UV 数据集(漫反射和镜面反照率和法线),我们在不同的照明设置下渲染以模拟自然 RGB 纹理,然后在串联的渲染纹理对上训练无条件扩散模型和反射成分。在测试时,我们将 3D 可变形模型拟合到给定图像,并在部分 UV 纹理中展开面部。通过从扩散模型中采样,在保持观察到的纹理部分完好无损的同时,该模型不仅修复了自遮挡区域,还修复了未知的反射分量,在一个单一的去噪步骤序列中。与现有方法相比,我们直接从输入图像中获取观察到的纹理,从而导致更忠实和一致的反射率估计。通过一系列定性和定量比较,我们在纹理完成和反射重建任务中展示了卓越的性能。
3.TidyBot: Personalized Robot Assistance with Large Language Models

标题:TidyBot:具有大型语言模型的个性化机器人协助
作者:Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, Yuxiao Dong
文章链接:https://arxiv.org/abs/2305.05658
项目代码:https://tidybot.cs.princeton.edu/




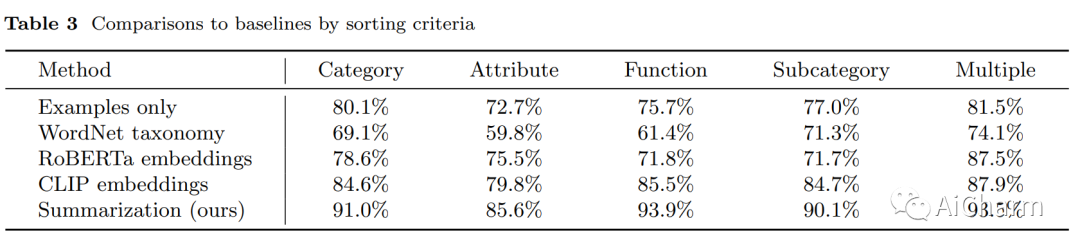
摘要:
机器人要想有效地提供个性化的物理帮助,就必须了解用户的偏好,这些偏好通常可以重新应用于未来的场景。在这项工作中,我们研究了家庭清洁的个性化,机器人可以通过拾取和放好物品来整理房间。一个关键的挑战是确定放置每个物体的合适位置,因为人们的喜好会因个人品味或文化背景而有很大差异。例如,一个人可能更喜欢将衬衫存放在抽屉中,而另一个人可能更喜欢将它们放在架子上。我们的目标是构建可以通过与特定人的先前交互从少数示例中学习此类偏好的系统。我们表明,机器人可以将基于语言的规划和感知与大型语言模型 (LLM) 的少量摘要功能相结合,以推断广泛适用于未来交互的广义用户偏好。这种方法可以实现快速适应,并在我们的基准数据集中对看不见的物体实现 91.2% 的准确率。我们还在真实世界的移动机械手 TidyBot 上展示了我们的方法,它在真实世界的测试场景中成功地放置了 85.0% 的物体。
更多Ai资讯:公主号AiCharm