CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CL
1.Not All Languages Are Created Equal in LLMs: Improving Multilingual Capability by Cross-Lingual-Thought Prompting

标题:并非所有语言在 LLM 中都是平等的:通过跨语言思维提示提高多语言能力
作者:Haoyang Huang, Tianyi Tang, Dongdong Zhang, Wayne Xin Zhao, Ting Song, Yan Xia, Furu Wei
文章链接:https://arxiv.org/abs/2305.07004



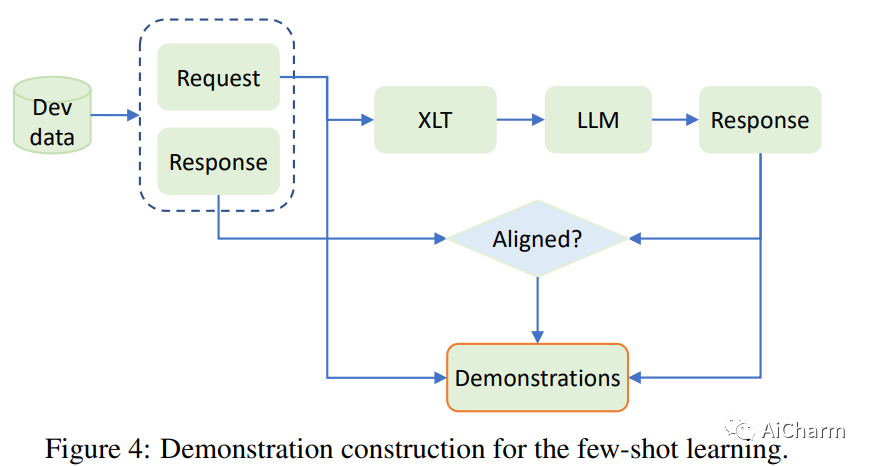


摘要:
大型语言模型 (LLM) 展示了令人印象深刻的多语言能力,但它们的性能在不同语言之间差异很大。在这项工作中,我们介绍了一种简单而有效的方法,称为跨语言思维提示 (XLT),以系统地提高 LLM 的多语言能力。具体来说,XLT 是一种通用模板提示,可激发跨语言和逻辑推理技能,以提高跨语言的任务绩效。我们对与推理、理解和生成任务相关的 7 个典型基准进行综合评估,涵盖高资源和低资源语言。实验结果表明,XLT 不仅显着提升了各种多语言任务的性能,而且显着缩小了不同语言中每个任务的平均性能和最佳性能之间的差距。值得注意的是,XLT 在算术推理和开放域问答任务中带来了 10 多个点的平均改进。
2.Active Retrieval Augmented Generation
标题:主动检索增强生成
作者:Zhengbao Jiang, Frank F. Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, Graham Neubig
文章链接:https://arxiv.org/abs/2305.06983
项目代码:https://github.com/jzbjyb/FLARE
摘要:
尽管大型语言模型 (LM) 具有非凡的理解和生成语言的能力,但它们往往会产生幻觉并产生与事实不符的输出。通过从外部知识资源中检索信息来增强 LM 是一种很有前途的解决方案。大多数现有的检索增强 LM 都采用检索和生成设置,该设置仅根据输入检索一次信息。然而,在涉及生成长文本的更一般情况下,这是有限制的,在这种情况下,在整个生成过程中不断收集信息是必不可少的。过去曾有一些尝试在生成输出时多次检索信息,这主要是使用先前的上下文作为查询以固定间隔检索文档。在这项工作中,我们提供了主动检索增强生成的通用视图,这些方法主动决定在整个生成过程中何时检索和检索什么内容。我们提出了前瞻性主动检索增强生成(FLARE),这是一种通用的检索增强生成方法,它迭代地使用对即将到来的句子的预测来预测未来的内容,然后将其用作查询来检索相关文档以重新生成句子如果它包含低置信度标记。我们在 4 个长期知识密集型生成任务/数据集上全面测试 FLARE 和基线。FLARE 在所有任务上都取得了优异或有竞争力的表现,证明了我们方法的有效性。
3.FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance

标题:FrugalGPT:如何在降低成本和提高性能的同时使用大型语言模型
作者:Lingjiao Chen, Matei Zaharia, James Zou
文章链接:https://arxiv.org/abs/2305.05176
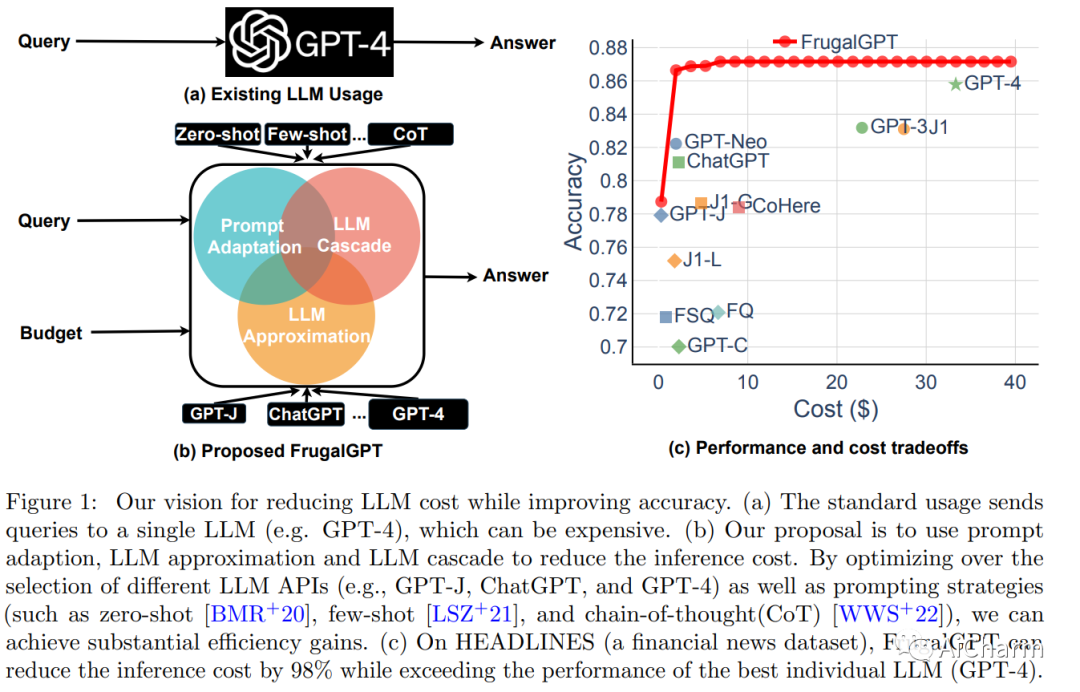



摘要:
用户可以付费查询的大型语言模型 (LLM) 数量迅速增加。我们审查了与查询流行的 LLM API 相关的成本,例如GPT-4、ChatGPT、J1-Jumbo,并发现这些模型具有异构的定价结构,费用可能相差两个数量级。特别是,在大量查询和文本上使用 LLM 可能会很昂贵。受此启发,我们概述并讨论了三种类型的策略,用户可以利用这些策略来降低与使用 LLM 相关的推理成本:1) 提示适应,2) LLM 近似,以及 3) LLM 级联。例如,我们提出了 FrugalGPT,这是一种简单而灵活的 LLM 级联实例,它学习将哪些 LLM 组合用于不同的查询,以降低成本并提高准确性。我们的实验表明,FrugalGPT 可以与最好的单个 LLM(例如 GPT-4)的性能相媲美,成本降低高达 98%,或者在成本相同的情况下比 GPT-4 的准确度提高 4%。这里提出的想法和发现为可持续和高效地使用 LLM 奠定了基础。
更多Ai资讯:公主号AiCharm



![Midjourney|文心一格prompt教程[基础篇]:注册使用教程、风格设置、参数介绍、隐私模式等](https://img-blog.csdnimg.cn/img_convert/087449f33ed9c01f6835eb10c0008631.png)