一、前言
Ms CoCo数据集是一个非常大型且常用的数据集,可以做的任务有目标检测、图像分割、图像描述等
数据集地址:链接
描述数据集的论文地址:链接
有一点需要注意:数据集的物体类别分为80类和91类两种,其中object80类是stuff91类的子集,stuff类别中不属于object的是指没有明确边界的材料和对象例如天空、草地等。

在学习目标检测时,我们把object80作为分类类别即可
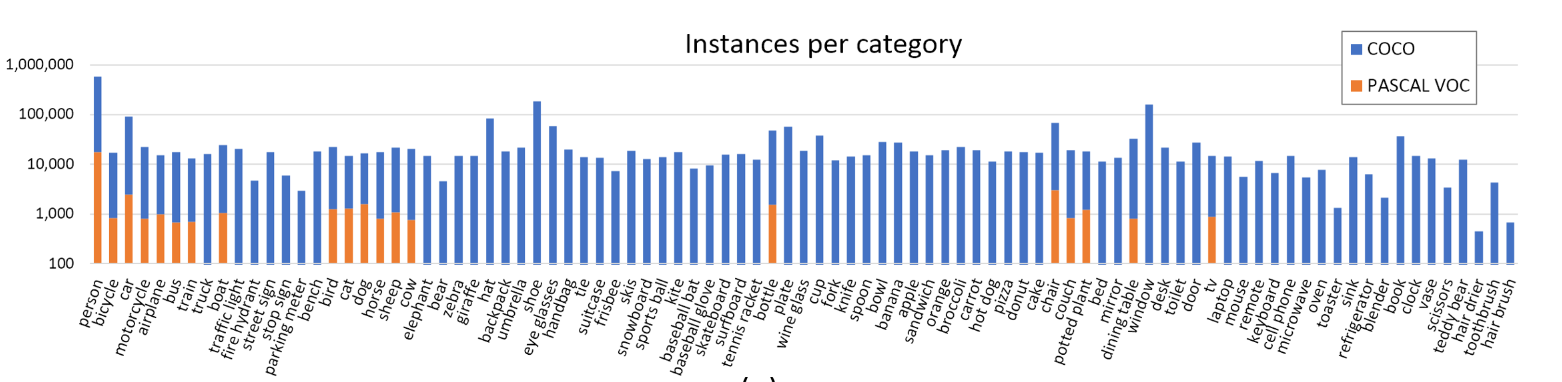
MS coco与PASCAL VOC的对比,可以看到CoCo数据集数量明显更大,相同类别的真实值也更多,因此往往会使用CoCo数据集的预训练模型来作为自己模型的初始化。(在CoCo数据集上预训练耗时比较长)
二、数据集下载

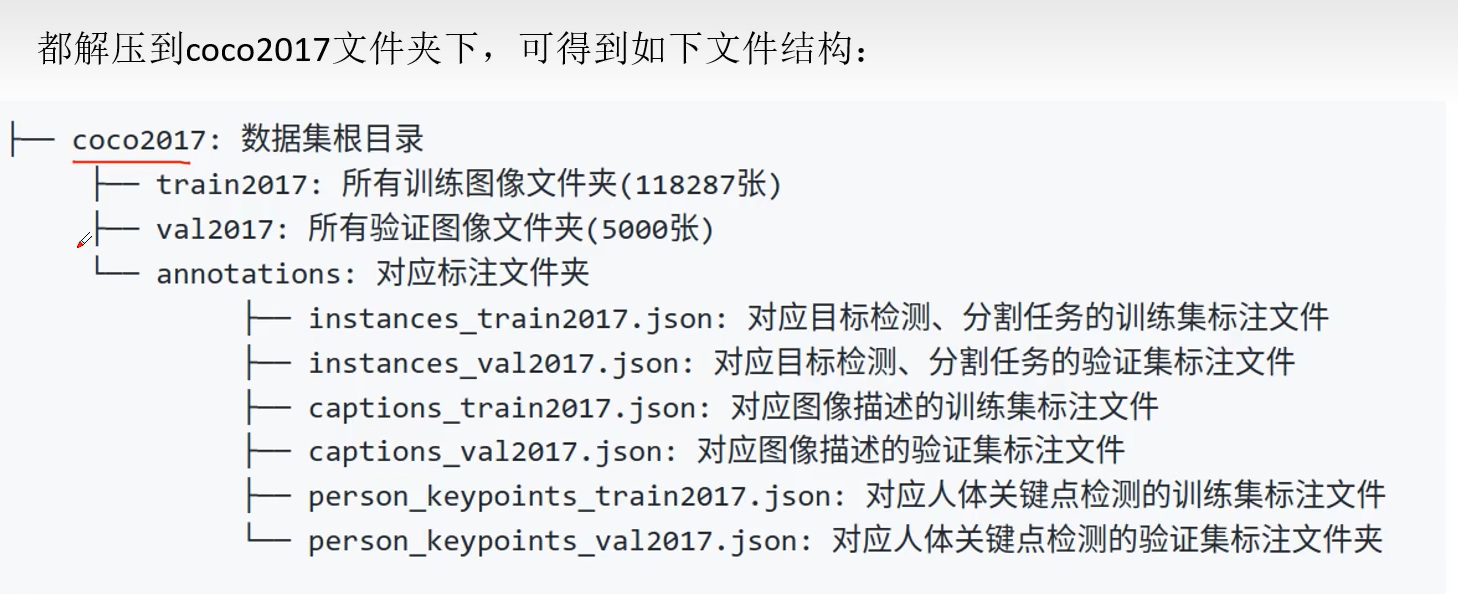
这里没有划分测试集,是因为其实测试集划分其实和验证集的划分的文件结构是一样的,所以可以不划分测试集来测试,使用验证集就可以达到测试的目的。
三、验证集与标注文件的查看
3.1使用python的json库查看
训练集比较大就没有下载,这里主要查看测试集与标注文件
import json
json_path = "./annotations/instances_val2017.json"
with open(json_path, "r") as f:
json_file = json.load(f)
print(json_file["info"])
设置断点,我们可以得到如下:
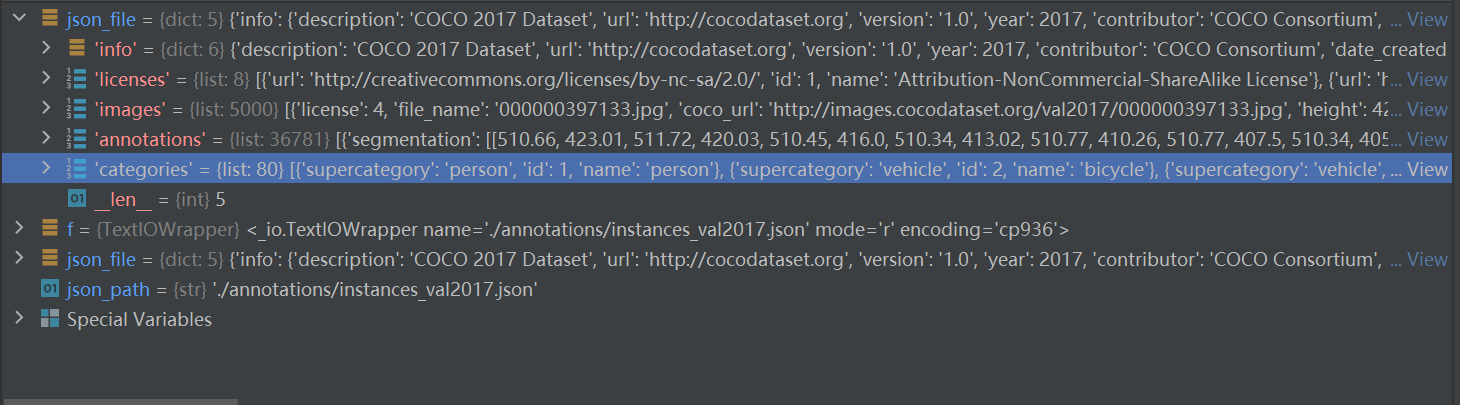
json_file是一个字典,包括:info、licences、images、annotations、categories五个关键字
| key | value type | value |
| info | dict | description、url、version、year、contribute、data_created |
| licences | list | len = 8 |
| images | list | include 5000 dicts every dict = {licences、filename、coco_url、height、width、date_captured、flickr_url、id} |
| annotations | list | include 36871dicts every dict = {segmentation、area、iscrowd、image_id、bbox、categoriy_id、id} |
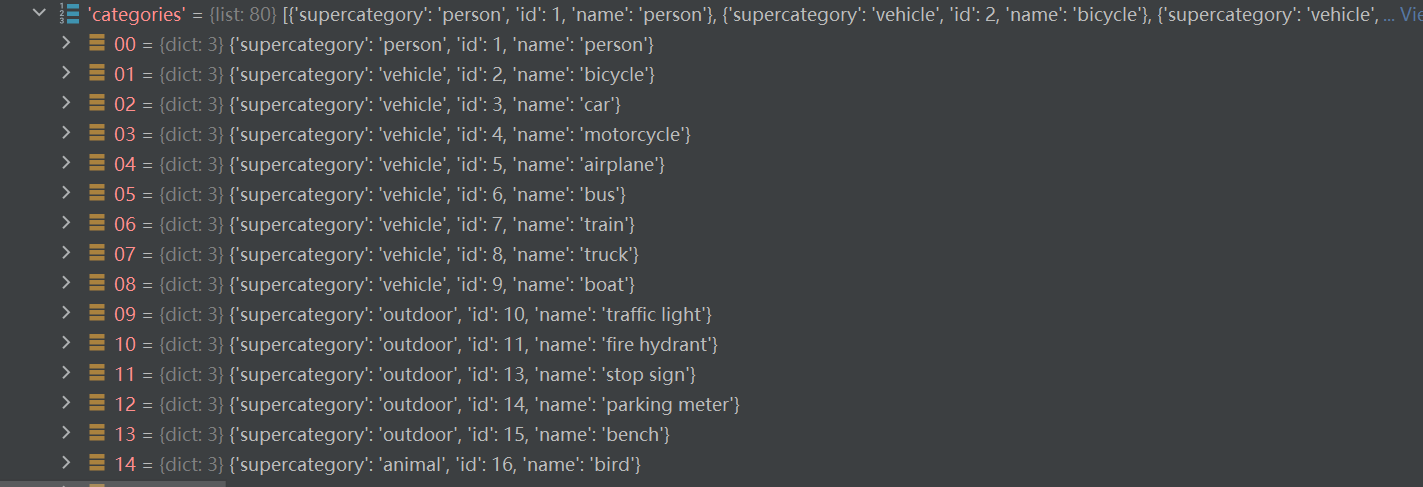
| categories | list | len = 80 include supercategory name id |
其中:
images是一个列表(元素个数对应图像的张数),列表中每个元素都是一个dict,对应一张图片的相关信息。包括对应图像名称、图像宽度、高度等信息。
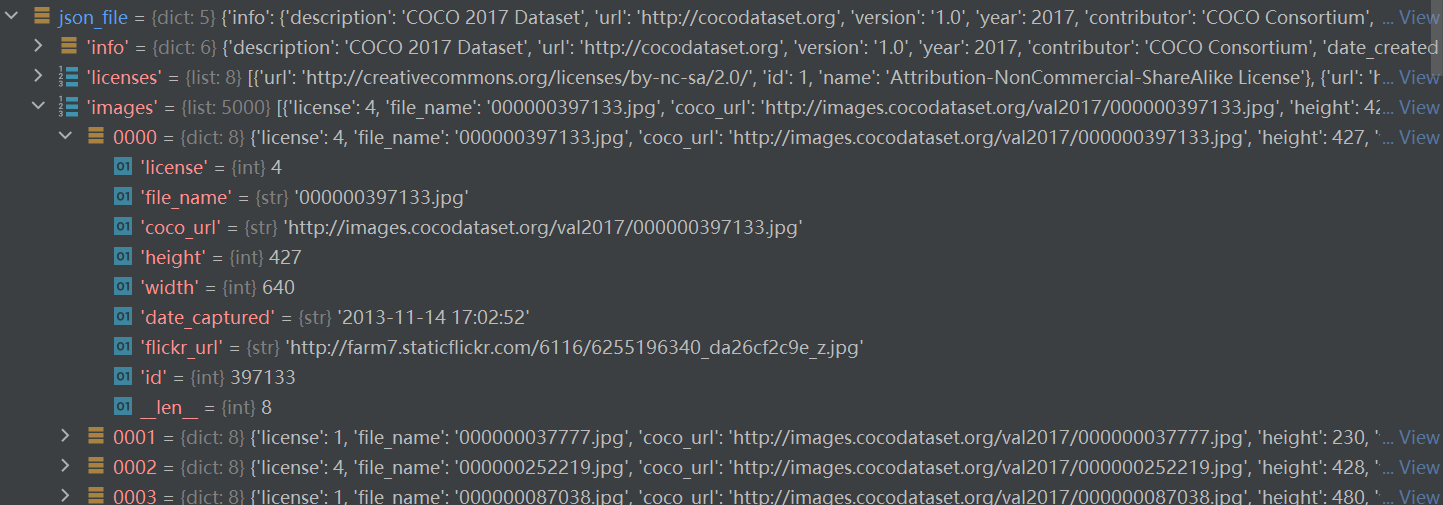
annoatations是一个列表(元素个数对应图片中的对象个数),列表每一个元素都是一个dict,表示每一个对象的标注信息。包括分割信息,目标检测的框(框的四个数字分别代表左上角点的x,y坐标,后面两个数字为框的宽和高。id是对应的图像id,category_id是对象类型的种类id。iscrowd表示这是否是一个单目标对象,0表示单个对象,1表示对象集合)
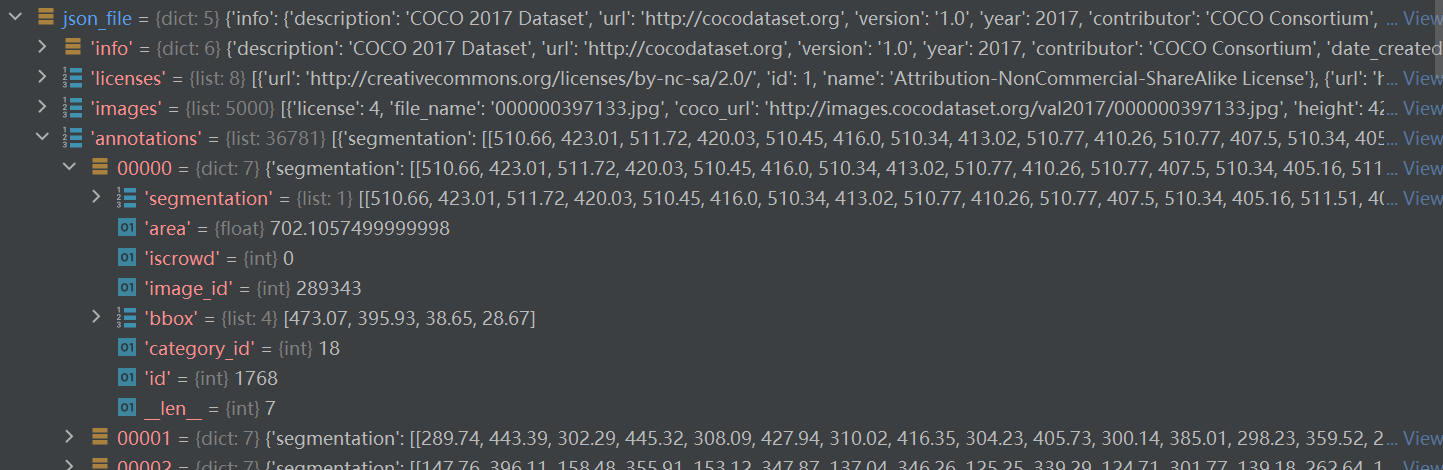
categories是一个列表(元素个数对应检测目标的类别数)列表中每个元素都是一个dict对应一个类别的目标信息。包括类别id、类别名称和所属超类(也即父类的意思)
3.2.使用官方API查看
3.2.1查看目标检测标注信息
import os
from pycocotools.coco import COCO
from PIL import Image, ImageDraw
import matplotlib.pyplot as plt
json_path = "./annotations/instances_val2017.json"
img_path = "./val2017"
# load coco data
coco = COCO(annotation_file=json_path)
# get all image index info
ids = list(sorted(coco.imgs.keys()))
print("number of images: {}".format(len(ids)))
# get all coco class labels
coco_classes = dict([(v["id"], v["name"]) for k, v in coco.cats.items()])
# 遍历前三张图像
for img_id in ids[:3]:
# 获取对应图像id的所有annotations idx信息
ann_ids = coco.getAnnIds(imgIds=img_id)
# 根据annotations idx信息获取所有标注信息
targets = coco.loadAnns(ann_ids)
# get image file name
path = coco.loadImgs(img_id)[0]['file_name']
# read image
img = Image.open(os.path.join(img_path, path)).convert('RGB')
draw = ImageDraw.Draw(img)
# draw box to image
for target in targets:
x, y, w, h = target["bbox"]
x1, y1, x2, y2 = x, y, int(x + w), int(y + h)
draw.rectangle((x1, y1, x2, y2))
draw.text((x1, y1), coco_classes[target["category_id"]])
# show image
plt.imshow(img)
plt.show()

3.2.2查看分割标注
代码:
import os
import random
import numpy as np
from pycocotools.coco import COCO
from pycocotools import mask as coco_mask
from PIL import Image, ImageDraw
import matplotlib.pyplot as plt
random.seed(0)
json_path = "./annotations/instances_val2017.json"
img_path = "./val2017"
# random pallette
pallette = [0, 0, 0] + [random.randint(0, 255) for _ in range(255*3)]
# load coco data
coco = COCO(annotation_file=json_path)
# get all image index info
ids = list(sorted(coco.imgs.keys()))
print("number of images: {}".format(len(ids)))
# get all coco class labels
coco_classes = dict([(v["id"], v["name"]) for k, v in coco.cats.items()])
# 遍历前三张图像
for img_id in ids[:3]:
# 获取对应图像id的所有annotations idx信息
ann_ids = coco.getAnnIds(imgIds=img_id)
# 根据annotations idx信息获取所有标注信息
targets = coco.loadAnns(ann_ids)
# get image file name
path = coco.loadImgs(img_id)[0]['file_name']
# read image
img = Image.open(os.path.join(img_path, path)).convert('RGB')
img_w, img_h = img.size
masks = []
cats = []
for target in targets:
cats.append(target["category_id"]) # get object class id
polygons = target["segmentation"] # get object polygons
rles = coco_mask.frPyObjects(polygons, img_h, img_w)
mask = coco_mask.decode(rles)
if len(mask.shape) < 3:
mask = mask[..., None]
mask = mask.any(axis=2)
masks.append(mask)
cats = np.array(cats, dtype=np.int32)
if masks:
masks = np.stack(masks, axis=0)
else:
masks = np.zeros((0, height, width), dtype=np.uint8)
# merge all instance masks into a single segmentation map
# with its corresponding categories
target = (masks * cats[:, None, None]).max(axis=0)
# discard overlapping instances
target[masks.sum(0) > 1] = 255
target = Image.fromarray(target.astype(np.uint8))
target.putpalette(pallette)
plt.imshow(target)
plt.show()

3.2.3查看关键点标注
代码:
import numpy as np
from pycocotools.coco import COCO
json_path = "./annotations/person_keypoints_val2017.json"
coco = COCO(json_path)
img_ids = list(sorted(coco.imgs.keys()))
# 遍历前5张图片中的人体关键点信息(注意,并不是每张图片里都有人体信息)
for img_id in img_ids[:5]:
idx = 0
img_info = coco.loadImgs(img_id)[0]
ann_ids = coco.getAnnIds(imgIds=img_id)
anns = coco.loadAnns(ann_ids)
for ann in anns:
xmin, ymin, w, h = ann['bbox']
# 打印人体bbox信息
print(f"[image id: {img_id}] person {idx} bbox: [{xmin:.2f}, {ymin:.2f}, {xmin + w:.2f}, {ymin + h:.2f}]")
keypoints_info = np.array(ann["keypoints"]).reshape([-1, 3])
visible = keypoints_info[:, 2]
keypoints = keypoints_info[:, :2]
# 打印关键点信息以及可见度信息
print(f"[image id: {img_id}] person {idx} keypoints: {keypoints.tolist()}")
print(f"[image id: {img_id}] person {idx} keypoints visible: {visible.tolist()}")
idx += 1
输出:
| 1 2 3 4 5 6 7 8 9 10 | loading annotations into memory... Done (t=0.34s) creating index... index created! [image id: 139] person 0 bbox: [412.80, 157.61, 465.85, 295.62] [image id: 139] person 0 keypoints: [[427, 170], [429, 169], [0, 0], [434, 168], [0, 0], [441, 177], [446, 177], [437, 200], [430, 206], [430, 220], [420, 215], [445, 226], [452, 223], [447, 260], [454, 257], [455, 290], [459, 286]] [image id: 139] person 0 keypoints visible: [1, 2, 0, 2, 0, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2] [image id: 139] person 1 bbox: [384.43, 172.21, 399.55, 207.95] [image id: 139] person 1 keypoints: [[0, 0], [0, 0], [0, 0], [0, 0], [0, 0], [0, 0], [0, 0], [0, 0], [0, 0], [0, 0], [0, 0], [0, 0], [0, 0], [0, 0], [0, 0], [0, 0], [0, 0]] [image id: 139] person 1 keypoints visible: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] |
3.3.CoCo官方代码API解读
上面三段代码分别可视化bbox,segmentation,keypoint,主要使用了官方的一系列API,接下来解读官方API的代码(以bbox可视化为例)
coco = COCO(annotation_file=json_path)
这一句代码创建一个CoCo对象,annotation_file作为json文件的路径传入,主要用来读取json文件和可视化注释
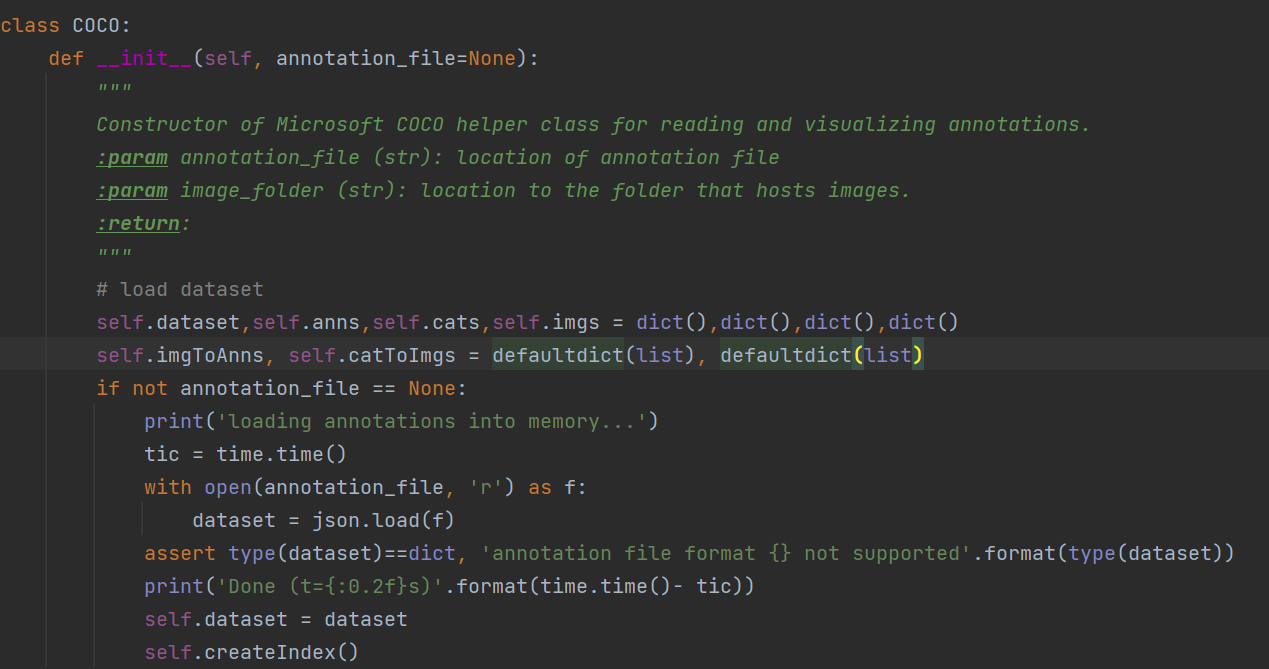
在初始化函数中:
创建四个空字典分别是dataset、anns、cats、imgs,同时创建两个默认字典(默认字典的学习笔记)默认字典CSDN链接
再判断路径是否为空,不为空时使用json库方法下载标注文件,下载下来的dataset格式为dict
再调用创建索引函数
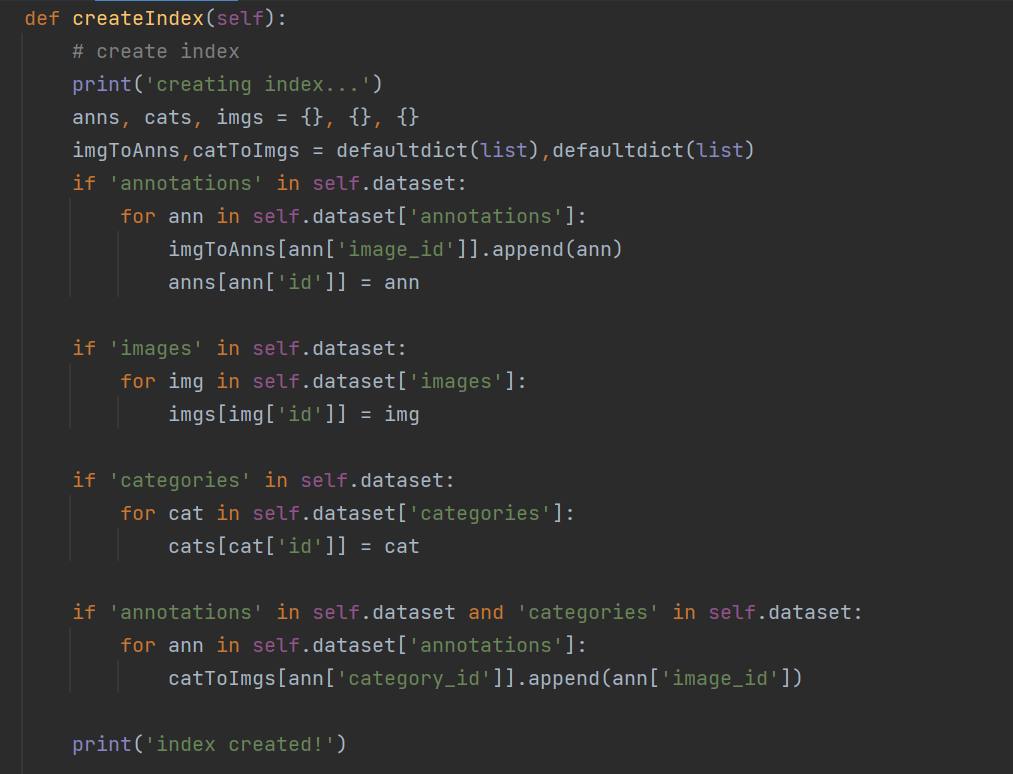
在这个方法中,创建三个空字典anns, cats, imgs,然后分别判断字典中是否有annotation、images、categories的关键字
对于dataset["annotation"]是有一个所有对象的列表,每一元素都是一个字典,imgToAnns字典里面的每一个图像名称id列表记录这张图象的所有对象
anns字典每一个图像序号id关键字记录标注的对象信息字典
对于dataset["images"]是包含所有图片的字典,imgs字典记录每一张图像名称id的图片信息字典
对于dataset["categories"]是一个字典列表,cats字典记录每一种类别id的类别信息
catToImgs字典记录每一个类别id的图像名称id
ids = list(sorted(coco.imgs.keys()))
ids为图片的名称id排序列表
coco_classes = dict([(v["id"], v["name"]) for k, v in coco.cats.items()])
coco_classes实际上为categories字典列表中每一个字典抽取出来类别id和类别名称构成字典
再下面感觉有点水平不够,等以后变强了再回来看
四、验证目标检测任务MAP
4.1预测结果输出格式
目标检测预测格式

假设我们有预测结果如下(原文博主训练得到的预测结果)
我们将其保存为predict_results.json文件
再执行下面代码比较预测值与ground_truth
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOeval
# accumulate predictions from all images
# 载入coco2017验证集标注文件
coco_true = COCO(annotation_file="./annotations/instances_val2017.json")
# 载入网络在coco2017验证集上预测的结果
coco_pre = coco_true.loadRes('./predict/predict_results.json')
coco_evaluator = COCOeval(cocoGt=coco_true, cocoDt=coco_pre, iouType="bbox")
coco_evaluator.evaluate()
coco_evaluator.accumulate()
coco_evaluator.summarize()
得到输出结果:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | loading annotations into memory... Done (t=0.71s) creating index... index created! Loading and preparing results... DONE (t=0.79s) creating index... index created! Running per image evaluation... Evaluate annotation type *bbox* DONE (t=19.72s). Accumulating evaluation results... DONE (t=3.82s). Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.233 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.415 Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.233 Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.104 Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.262 Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.323 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.216 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.319 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.327 Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.145 Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.361 Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.463 |
下一篇记录目标检测的评估指标:CoCo数据集-目标检测指标MAP_SL1029_的博客-CSDN博客
五、学习的博客与视频
MS COCO数据集介绍以及pycocotools简单使用_太阳花的小绿豆的博客-CSDN博客
COCO数据集介绍以及pycocotools简单使用_哔哩哔哩_bilibili
CoCo数据集官方网站:COCO - Common Objects in Context (cocodataset.org)
CoCo官方API地址:cocodataset/cocoapi: COCO API - Dataset @ http://cocodataset.org/ (github.com)