开头还是介绍一下群,如果感兴趣polardb ,mongodb ,mysql ,postgresql ,redis 等有问题,有需求都可以加群群内有各大数据库行业大咖,CTO,可以解决你的问题。加群请联系 liuaustin3 ,在新加的朋友会分到2群(共790人左右 1 + 2)
最近我们接到一个需求,在数据库内,无准确目标的寻找每个表中的字里面包含某些 特殊字符的列。工作了快半辈子了,也是第一次听说这样的“奇葩”的需求。经过和需求提出者的沟通,原因是在软件设计之初因为使用到图片,所以将图片的地址都塞到了数据库的各个与之有关的表的字段里面,凡是调用图片的地方,所以开发到现在,也不知道哪个表,哪个列用了这个部分,同时因为要更换图片的存储的位置,所以要“大海捞针的” 去改 。Interesting !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
咋办,凉拌,DBA 需要帮助一下,传统的思维模式,通过系统表把所有表的varchar ,text 字段都弄出来,在自动化的进行select 字段 from 表 where 字段 like %字符% or like %字符 or like 字符% 的方式把匹配的列找到。你真的要这么干,N个物理的INSTANCE 都要这样!!!!

OMG ,这么多年这么奇葩的要求我也是第一次听说,咋地让小伙伴们去人肉数据库表列,这可不是我的作风。
那么怎么办,既然是8.025的MYSQL,那么不用直方图来解决这个问题,就真的太挫了,因为我从来不希望自己就是一个操作机器。在CHART GPT 的世界,甘心做机器,最终都会被替代。比如 用新奇的点子来给 CHART GPT 上一课。
这个直方图是在MYSQL 8.03 提出的,他可以解决每个表,每个列的值的分布和DISTINCT 的问题。直方图是对列数据分布的一种近似。它可以以相当准确的方式告诉您数据是否偏斜,这反过来又有助于数据库服务器了解其包含的数据性质。直方图有许多不同类型,在MySQL中我们选择支持两种不同的类型:“单例”直方图和“等高”直方图。所有直方图类型的共同点是它们将数据集划分为一组“桶”,MySQL会自动将值划分到各个桶中,并自动决定要创建哪种类型的直方图。
顺便吐槽一句,MYSQL在这个方面和PG 比,人家甩你可不是几条街的问题。
言归正传,怎么这个方式就可以解决这个问题,我们做一个实验
ANALYZE TABLE actor update histogram on first_name,last_name with 100 buckets;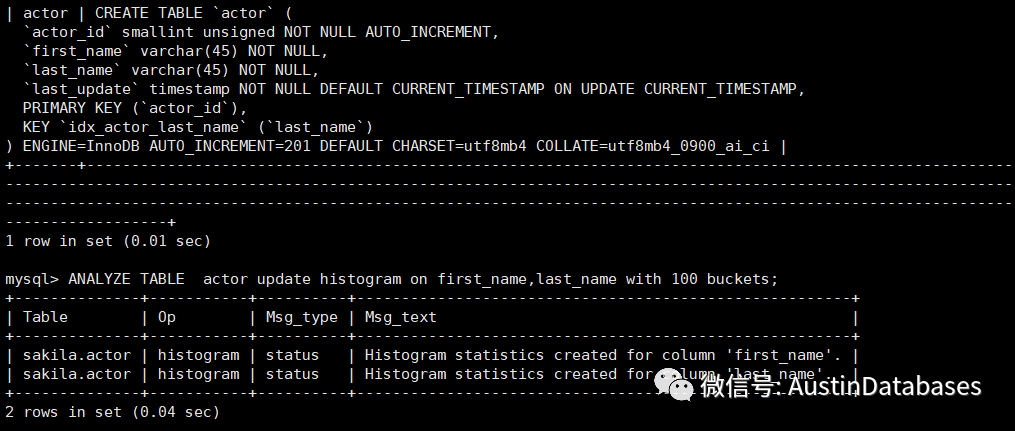
需要注意的是,桶的个数必须指定,取值范围为1 ~ 1024。你应该为你的数据集选择多少个桶取决于几个因素;你有多少不同的值,你的数据集有多倾斜,你需要多高的精度等等。然而,在一定数量的桶之后,增加的精度相当低。所以我们建议从一个较低的数字开始,比如32,如果你发现它不符合你的需求,就增加它。
当指定要构建直方图时,服务器将把所有数据读入内存并在内存中完成所有工作(包括排序)。然后,如果您想要在一个非常大的表上生成直方图,您可能会冒着将数百兆字节的数据读入内存的风险,这可能不太合适。因此,为了解决这个问题,MySQL将计算在系统变量histogram_generation_max_mem_size指定的内存量下可以容纳多少行数据。如果它意识到只能在给定的内存限制内容纳部分行,它将采用抽样方法。这可以通过查看属性“sampling-rate”来观察。
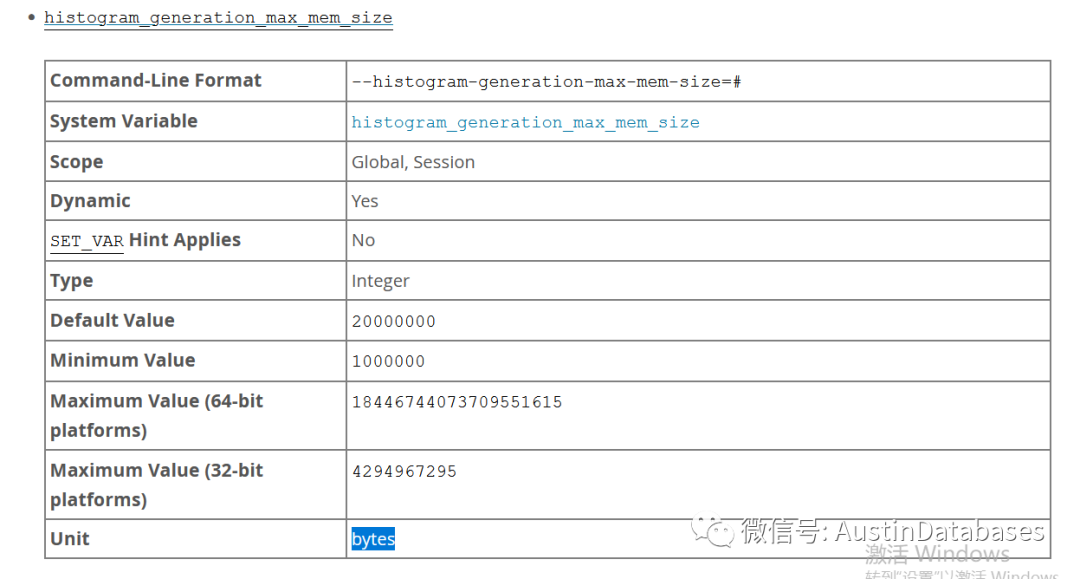
运行对表列分析的产生直方图后,根据表中的标识的schema_name,table_name,column_name, Histogram 来对表的列进行一个标识,其中可以看下图中histogram中的buckedts 并不是你认识的文字,而是base64 type254 ,在MYSQL中这些字符是为了减少存储的,直接MYSQL可以将这些全部转换为,原来的字符,方式为

SELECT convert(FROM_BASE64('Q1JVWg==')using utf8) as words;

通过这样的方式就可以将字符转换成原来的字符。
SELECT convert(FROM_BASE64('Q1JVWg==')using utf8) as decoded_data;
在JAVA 中可以通过如下的方式来进行转换
在 Java 程序中,如果需要将 Base64 编码的数据 (Type 254) 转换成 UTF-8 字符串,请遵循以下步骤:
导入所需库:
java
import java.nio.charset.StandardCharsets;
import java.util.Base64;
使用 Base64.getDecoder().decode() 方法对 Base64 编码的字符串进行解码,返回一个字节数组:
java
String base64String = "Q2hhdEdQVA=="; // 示例 Base64 编码字符串
byte[] decodedBytes = Base64.getDecoder().decode(base64String);
将解码后的字节数组转换为 UTF-8 字符串:
java
String utf8String = new String(decodedBytes, StandardCharsets.UTF_8);
现在,utf8String 变量包含了解码后的 UTF-8 字符串。完整示例如下:
java
import java.nio.charset.StandardCharsets;
import java.util.Base64;
public class Base64ToUTF8 {
public static void main(String[] args) {
String base64String = "Q2hhdEdQVA=="; // 示例 Base64 编码字符串
byte[] decodedBytes = Base64.getDecoder().decode(base64String);
String utf8String = new String(decodedBytes, StandardCharsets.UTF_8);
System.out.println("Decoded UTF-8 String: " + utf8String);
通过这样的方式DBA 快速的获取所有表中的字段的distinct值,然后让程序员读入histogram 字段,通过JAVA 程序快速解码和分析,找出本列是否有他们要的 值, 问题解决。
当然说到这里,肯定有人说,不对你这个是采样的,不准确,怎么办,呵呵,怎么办,我热炒,这里有一个值是 sampling_rate,只要在采样后,他的值是1 即可,那么我们我的采样率一定是百分之百的正确。(采样时)
至于怎么想出这个法子的,呵呵 回来再说。