文章目录
- 概述
- 实现步骤:
- 应用场景
- 代码实操:
- 前端:
- 文件切片:
- 分片上传:
- 后端:
- 校验和保存:
- 合并文件片段:
- 完成上传:
- 总结
- 优点:
- 缺点:
- 升华
概述
文件分片上传又叫文件切片上传,是将大文件切分成小的文件片段,分别上传到服务器,并在服务器端将这些文件片段合并成完整的文件。
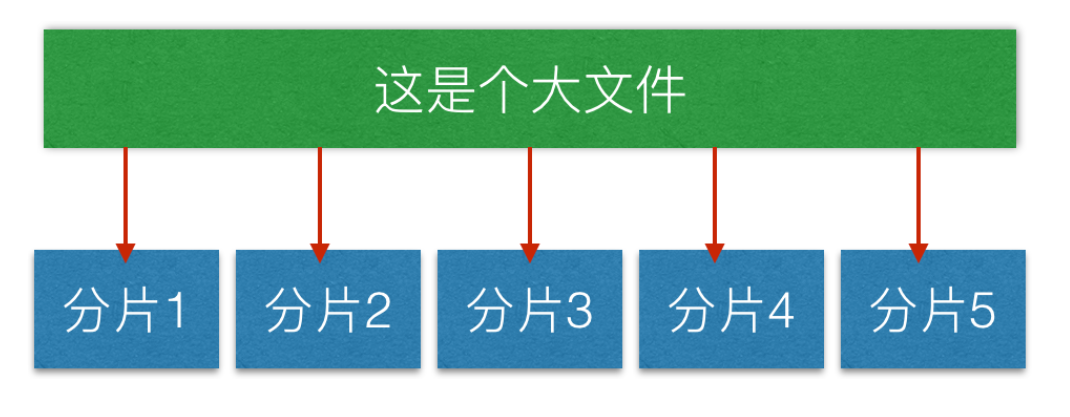
实现步骤:
假设有一个需要上传的文件 “example.jpg”,大小为 102 MB。我们将其切分为大小为 5 MB 的文件片段进行上传,要进行下面几个步骤:
-
客户端将 “example.jpg” 切分成 21 个文件片段,每个文件片段大小为 5 MB,最后一个分片大小不足5MB。
-
客户端逐个将文件片段上传到服务器,按顺序依次上传。每个文件片段都携带对应的分片索引,例如:第一个文件片段携带索引 1,第二个文件片段携带索引 2,依此类推。
-
服务器端接收到文件片段后,对每个文件片段进行校验和保存。校验和算法如 MD5 或 SHA1 可以用于校验文件片段的完整性。服务器将每个文件片段保存到临时存储区。
-
当所有文件片段上传完成后,服务器根据文件片段的顺序或索引,将这些文件片段按照正确的顺序合并,生成完整的文件 “example.jpg”。
-
服务器将完整的文件保存到指定的目标位置,并通知客户端上传成功。
应用场景
-
大文件上传:在上传大文件时,文件分片可以减小每个请求的数据量,降低传输失败率,同时可以在上传失败后,只需重新上传丢失的分片,而不需要重新上传整个文件。
-
视频直播:直播时,需要将视频实时传输到服务器,但由于网络传输不稳定,可能导致视频传输中断。通过将视频分片上传,可以减小每个请求的数据量,降低视频传输失败率。
-
CDN 分发:CDN 分发中使用文件分片上传可以提高文件上传速度和分发速度。CDN 节点会缓存文件的分片,然后在 CDN 节点之间进行分发,以加速文件的传输。
代码实操:
前端:
文件切片:
将要上传的大文件按照固定大小或指定的分片大小进行切片。通常使用二进制流方式切割,确保每个文件片段的大小相同或接近。
分片上传:
将每个文件片段逐个上传到服务器。上传可以通过HTTP协议的POST请求或者其他上传协议进行,每个文件片段都携带对应的分片索引或标识信息。
代码如下:
// 设置每个分片的大小(字节)
const CHUNK_SIZE = 1 * 1024 * 1024; // 1MB
// 获取文件的MD5码
function getMD5(file) {
// 在这里实现获取文件的MD5码的逻辑
// 返回文件的MD5码
// 可以使用第三方库或自己实现MD5算法来计算文件的MD5码
}
// 分片上传文件
function uploadFile(file) {
const totalChunks = Math.ceil(file.size / CHUNK_SIZE);
let currentChunk = 0;
// 递归上传分片
function uploadChunk() {
const start = currentChunk * CHUNK_SIZE;
const end = Math.min(start + CHUNK_SIZE, file.size);
const chunk = file.slice(start, end);
const formData = new FormData();
formData.append('file', chunk);//文件块
formData.append('chunkIndex', currentChunk); //当前块号
formData.append('totalChunks', totalChunks); //总块数
formData.append('chunkMD5', getMD5(chunk)); //当前块的MD5
formData.append('fileName', file.name); //文件名
// 使用axios发送分片数据到服务器
axios.post('/upload', formData)
.then(response => {
// 分片上传成功
currentChunk++;
if (currentChunk < totalChunks) {
// 继续上传下一个分片
uploadChunk();
} else {
// 所有分片上传完成
console.log('文件上传完成');
}
})
.catch(error => {
// 分片上传失败
console.error('分片上传失败:', error);
});
}
// 开始上传第一个分片
uploadChunk();
}
// 选择文件并触发上传
const fileInput = document.getElementById('file-input');
fileInput.addEventListener('change', (event) => {
const file = event.target.files[0];
if (file) {
uploadFile(file);
}
});
后端:
校验和保存:
在服务器端接收到文件片段后,对每个文件片段进行校验,使用校验和算法如MD5或SHA1计算校验和,确保文件片段的完整性。同时,将每个文件片段保存到临时存储区,通常是磁盘或内存。
合并文件片段:
在所有文件片段上传完毕后,服务器端根据文件片段的顺序或标识,将这些文件片段按照正确的顺序进行合并,生成完整的文件。
完成上传:
当文件合并完成后,将生成的完整文件保存到指定的目标位置,并返回上传成功的标识或信息给客户端,表示文件上传完成。
代码如下:
@Controller
public class UploadController {
private final static String utf8 ="utf-8";
@RequestMapping("/upload")
@ResponseBody
public void upload(HttpServletRequest request, HttpServletResponse response) throws Exception {
//分片
response.setCharacterEncoding(utf8);//向浏览器输出 统一用该编码输出
Integer schunk = null;//当前是哪个分片
Integer schunks = null;//总分片数
String name = null;//文件名
String uploadPath = "E:\\ceshi";//文件临时存储目录,存储文件片
BufferedOutputStream os = null;//文件合并时用的流
try{
DiskFileItemFactory factory = new DiskFileItemFactory();//设计文件上传参数
factory.setSizeThreshold(1024);//缓冲区大小1024字节(文件先读到内存中,在往硬盘里写,中间需要缓存区)
factory.setRepository(new File(uploadPath));//设置临时目录
ServletFileUpload upload = new ServletFileUpload(factory);//upload帮助解析request
upload.setFileSizeMax(5l *1024l *1024l*1024l);//设置参数,多文件上传,限制限制单个文件大小最大为5G
upload.setSizeMax(10l *1024l *1024l*1024l);//限制所有文件最大为10G
List<FileItem> items = upload.parseRequest(request);
//解析文件
for(FileItem item : items){
//判断是否是文件对象
if(item.isFormField()){
//取出分片信息
if("chunkIndex".equals(item.getFieldName())){
schunk = Integer.parseInt(item.getString(utf8));//当前是哪个分片
}
if("totalChunks".equals(item.getFieldName())){
schunks = Integer.parseInt(item.getString(utf8));//总分片数
}
if("chunkMD5".equals(item.getFieldName())){
fileMD5 = item.getString(utf8);//文件块MD5
}
if("fileName".equals(item.getFieldName())){
name = item.getString(utf8);//文件名
}
}
}
for(FileItem item : items){
if(!item.isFormField()){
String temFileName = name;//临时目录
if(name != null){
if(schunk != null){
temFileName = schunk +"_"+name;//生成临时文件
}
File temFile = new File(uploadPath,temFileName);
//给临时文件生成MD5,和前端传来的MD5比较的代码略
//如果文件不存在就上传
if(!temFile.exists()){
item.write(temFile);
}
}
}
}
//文件合并,判断是不是传到最后一个分片了
if(schunk != null && schunk.intValue() == schunks.intValue()-1){
File tempFile = new File(uploadPath,name);//准备临时文件把分片写入文件
os = new BufferedOutputStream(new FileOutputStream(tempFile));//向流中写入文件信息
//找到所有分片
//判断所有分片是都存在
for(int i=0 ;i<schunks;i++){
File file = new File(uploadPath,i+"_"+name);
//如果有分片不存在,先休眠,直到所有分片都存在
while(!file.exists()){
Thread.sleep(100);
}
//读取分片
byte[] bytes = FileUtils.readFileToByteArray(file);
os.write(bytes);//写入到流中
os.flush();//
file.delete();//删除临时文件
}
os.flush();
}
response.getWriter().write("上传成功"+name);
}finally {
try{
if(os != null){
os.close();//关文件流
}
}catch (IOException e){
e.printStackTrace();
}
}
}
}
产生的文件片:
合并后删除了这些临时文件

总结
优点:
-
支持大文件上传:文件分片上传能够处理大文件,通过将文件切分成小片段进行上传,可以绕过上传文件大小限制。
-
断点续传:由于文件分片上传将文件拆分成多个片段,当上传过程中出现异常或中断时,只需要重新上传失败的片段,而不需要重新上传整个文件,实现了断点续传的功能。
-
提高上传效率:文件分片上传能够并行上传多个片段,从而提高上传速度。同时,由于每个片段相对较小,上传的网络延迟对整体上传时间的影响较小。
-
服务器资源优化:文件分片上传可以分散服务器的负载,由于每个片段可以在不同的服务器上处理,可以更好地利用服务器资源。
缺点:
-
处理逻辑复杂:文件分片上传需要在客户端和服务器端实现分片切割、上传顺序管理、校验和合并等复杂的逻辑,增加了开发和维护的难度。
-
需要额外存储空间:文件分片上传需要在服务器端临时存储每个文件片段,可能会占用额外的存储空间。
-
管理和维护成本:文件分片上传需要处理分片上传的逻辑,并管理临时文件的存储和清理,增加了系统管理和维护的复杂度。
升华
除了文件分片传输,还有其他类似的数据分片传输情况。
-
TCP报文分段传输:在TCP协议中,会将大的数据包分割成多个较小的报文段进行传输。这是由于TCP协议对数据包大小进行了限制,根据网络传输的情况和MTU(最大传输单元)的限制,TCP会将数据切割成适当的大小进行分段传输,以确保数据的可靠传输。
-
IP分片传输:在IP协议中,当数据包的大小超过网络的MTU(最大传输单元)时,IP层会将数据包分割成多个较小的分片进行传输。接收方会重新组装这些分片以还原原始的数据包。
-
数据库分页查询:在数据库查询中,当结果集非常大时,可以使用分页查询来分割结果集并逐页进行传输。客户端可以根据需要逐页获取数据,而不必一次性获取所有数据。
-
视频流传输:在实时视频流传输中,视频数据通常会被分割成小的数据包,然后通过网络进行传输。这样可以降低延迟,并支持实时的流媒体播放。
-
大数据处理:在大数据处理中,数据可能会被分割成小的块或分区进行并行处理。这样可以利用分布式计算框架的能力,并提高处理效率。
这些都是将大的数据切割成小的片段进行传输或处理的情况。通过分片传输,可以提高数据传输的效率、降低网络延迟,并支持更灵活的数据处理和传输方式。

觉得有用就点个赞吧!