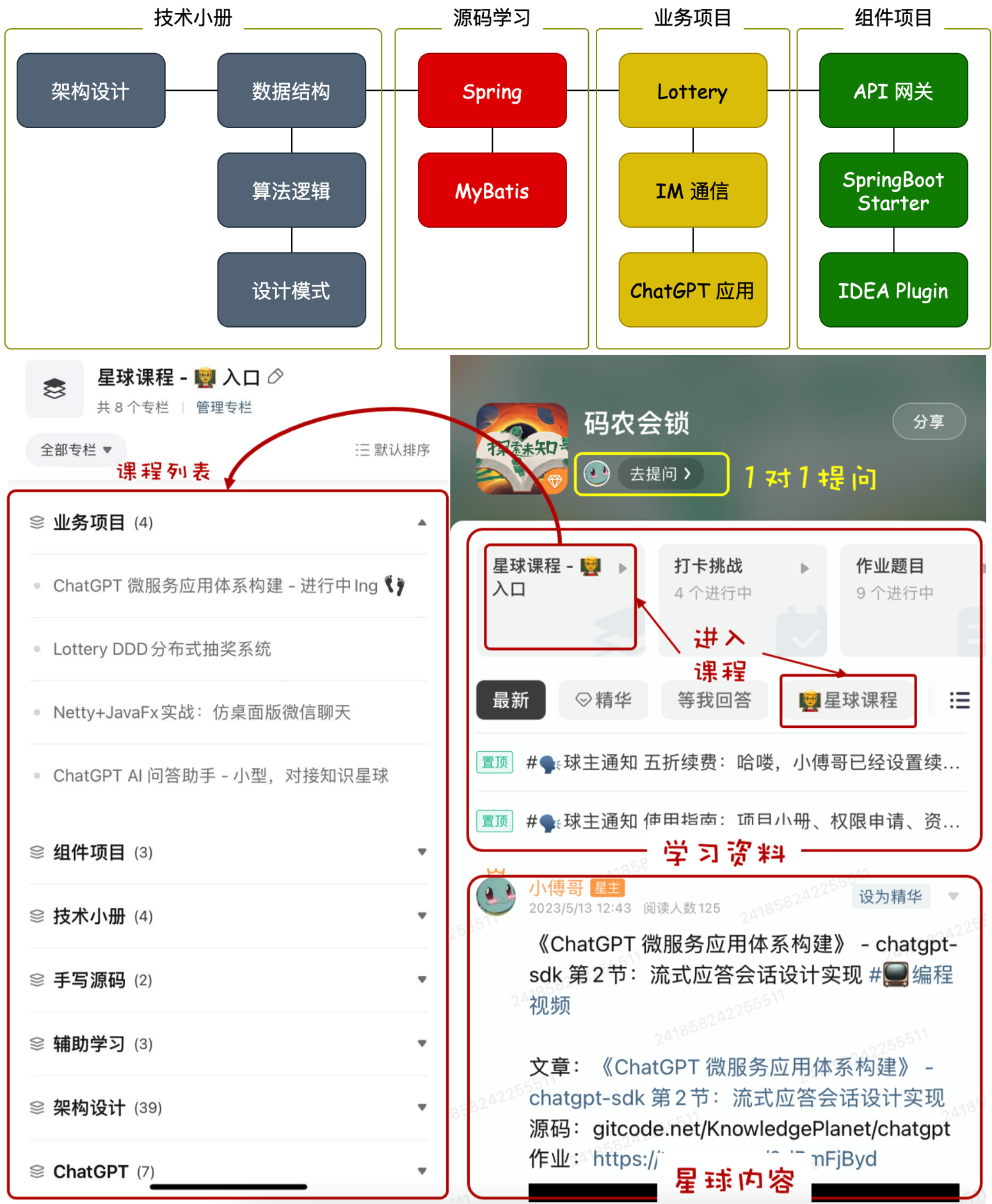
Towards Open-Set Object Detection and Discovery
摘要
随着人类对知识的不断追求,开集目标检测(OSOD)被设计用于识别动态世界中的未知目标。然而,当前设置的一个问题是,所有预测的未知对象共享相同的类别为“未知”,这需要通过人在环方法的增量学习来标记新的类别。为了解决这个问题,我们提出了一个新的任务,即开放集对象检测和发现(OSODD)。这项新任务旨在扩展开集对象检测器的能力,以进一步发现基于视觉外观的未知对象的类别,而无需人工努力。我们提出了一个两阶段的方法,首先使用一个开放集对象检测器来预测已知和未知的对象。然后,我们研究预测对象的表示在一个无监督的方式,并发现新的类别从未知对象的集合。通过这种方法,检测器能够检测属于已知类的对象,并以最小的监督为未知类的对象定义新的类别。我们展示了我们的模型在一个彻底的评估协议下的MS-COCO数据集的性能。我们希望我们的工作将促进进一步的研究,以实现更强大的现实世界的检测系统。
1.介绍
目标检测是对图像中的目标进行定位和分类的任务。近年来,深度学习方法改进了检测模型[3,4,15,21,40,41,48],并取得了显着进展。然而,这些方法在所有对象类在训练阶段已知的强烈假设下工作。由于这种假设,对象检测器将不正确地将未知类别的对象视为背景或将其分类为属于已知类别的集合[11](见图1(a))。
为了放松上述闭集条件,开集对象检测(OSOD)[11,26,34]考虑了一种现实的场景,其中测试图像可能包含在训练期间未出现的新类。OSOD的目的是从已知类的集合中联合检测对象并定位属于未知类的对象。尽管OSOD能够通过检测未知类的实例来提高对象检测的实用性,但是仍然存在未知类的所有识别的对象共享与“未知”相同的类别的问题(参见图1(b))。需要额外的人类注释来增量学习新的对象类别[26]。

图1.物体检测任务的视觉比较。在闭集检测中,来自看不见的类的对象被忽略或被错误地分类到已知类的集合中。而在开集对象检测中,未知对象被定位但共享相同的类别。我们的任务旨在检测已知类的对象,并为未知类的已识别对象发现新的视觉类别,这提供了更好的场景理解和可扩展的学习范式。
假设一个孩子第一次去动物园。孩子可以认出一些以前见过和学过的动物,例如“兔子”或“鸟”,而孩子可能不认识许多其他罕见动物的物种,如“斑马”和“长颈鹿”。在观察之后,孩子的感知系统将从这些以前没见过的动物的外观中学习,并将它们归类为不同的类别,即使没有被告知它们是什么物种。
在这项工作中,我们考虑了一个新的任务,其中我们的目标是定位已知和未知类别的对象,为已知对象分配预定义的类别标签,并为未知类别的对象发现新的类别(见图1(c))。我们将此任务称为开放集对象检测和发现(OSODD)。我们促进了我们提出的任务,OSODD,建议它更适合从图像中提取信息。新的类别发现提供了属于以前未见过的类别的数据的额外知识,帮助基于视觉的智能系统处理更真实的用例。
我们提出了一个两阶段的框架来解决OSODD的问题。首先,我们利用开集对象检测器的能力来检测已知类的对象并识别未知类的对象。 将已知类和未知类对象的预测建议框保存到内存缓冲区;其次,我们探索所有对象的循环模式,并从未知类的对象中发现新的类别。具体来说,我们开发了一种自监督的对比学习方法与域不可知的数据增强和半监督k均值聚类类别发现。
我们的贡献:
- 我们正式定义任务,开放集对象检测和发现(OSODD),这使得更丰富的理解在现实世界中的检测系统。
- 我们提出了一个两阶段的框架来解决这个问题,我们提出了一个全面的协议来评估对象检测和类别发现的性能。
- 我们提出了一个类别发现方法在我们的框架中使用:域不可知的增强,对比学习和半监督聚类。在实验中,新方法优于其他基线方法。
2.相关工作
开集识别
与闭集学习相比,闭集学习假设在测试期间仅存在先前已知的类,开集学习假设已知类和未知类共存。Scheirer等人[43]首先介绍在训练时具有不完整知识的开集识别问题,即,在测试期间可能出现未知类。他们开发了一种分类器,在一对多设置中,该分类器能够拒绝未知样本。[24,44]将[43]中的框架扩展到使用具有极值理论的概率模型的多类分类器,以最小化分类器的衰落置信度。最近,Liu et al.[33]提出了一种深度度量学习方法来识别不平衡数据集的不可见类。自我监督学习[14,38,46]方法已经被探索以最小化外部监督。
Miller等人(2018)的第一项研究探讨了在开放条件下使用标签不确定性进行物体检测的问题。他们使用一种称为丢失采样的技术来识别难以分类且标签不确定的物体。Dhamija等人(2018年)的第二项研究定义了OSOD问题,并评估了传统物体探测器在避免将未知物体错误分类为已知类别方面的性能。他们还提出了一项评估指标,用于评估开放条件下物体探测器的性能。
开放世界识别
开放世界环境是一种持续学习范例,它通过假设在每个递增的时间步中逐步引入新的语义类来扩展开放集合条件。这意味着模型需要能够处理随着时间的推移而引入的未知类。Bendale 等人首先正式确定了图像识别的开放世界设置,并提出了一种使用最接近的非异常值算法的开放集分类器。当通过重新校准类别概率为未知事物提供新标签时,模型就会演变。
Joseph等人[26]将开放世界设置转移到对象检测系统,并提出开放世界对象检测(OWOD)的任务。该模型使用的样本重放方法,使开放集检测器学习新的类增量,而不会忘记以前的。OWOD或OSOD模型不能探索所识别的未知对象的语义,并且需要额外的人工注释来增量地学习新的类。相比之下,我们的OSODD模型可以发现新的类别标签未知类的对象,而无需人工努力。
新类发现:
这项新颖的类别发现任务旨在识别未标记数据集中类似的重复模式。在图像识别中,此任务以前被视为无监督聚类问题。Xie等人提出了一种深度嵌入网络,该网络可以对数据进行聚类,同时学习数据表示形式。Han等人制定了新类别发现(NCD)的任务,该任务使用深度转移聚类将未标记的图像聚类到新类别中。NCD 设置假设训练集包含带标签的数据和未标记的数据,并且从标签数据上学到的知识可以转移到有针对性的未标记数据中进行类别发现。
对象发现和定位 (ODL) 是一项任务,旨在以无人监督的方式共同发现和定位具有多个对象类别的图像集合中的主要物体。Lee 和 Grauman 使用对象图和外观特征进行无监督发现,而 Rambhat 等人则假设对类标签有部分了解,并利用双内存模块进行了发现。与 ODL 相比,提议的 OSODD 任务对先前已知的类别进行检测,并发现未知物体的新类别,从而提供全面的场景理解。
请参阅表1,查看我们的设置与物体检测问题中其他类似设置之间的差异汇总。
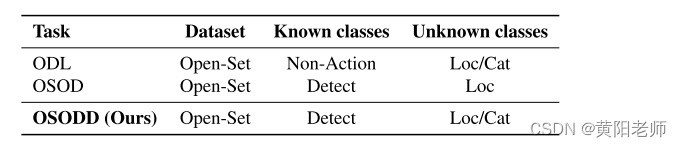
表1.比较不同的目标检测和发现任务。OSOD:开集对象检测; ODL:对象发现和定位。Loc:意味着定位感兴趣的对象; Cat:意思是发现新的类别。
3.任务形式
在 OSODD 中,假设已知类为 Ck = {C1, C21,…,Cm};未知类为 Cu = {Cm+1, Cm+2, … Cm+n},Ck 和 Cu 没有交集。训练集只包含 Ck,而测试集是 Ck 和 Cu 的合集。模型的任务就是对所有物体进行定位和分类 I = [c, x, y, w, h],对象实例I由I = [c,x,y,w,h]表示,分别表示类标签(c ∈ Ck或Cu)、左上方的x、y坐标以及距对象边界框中心的宽度和高度。已知物体归于Ck,未知物体则归于 Cu。
4.方法
本节描述了作者提出的解决OSODD的方法,该方法涉及一个由两个主要模块组成的通用框架:对象检测和检索(ODR)和对象类别发现(OCD)。该框架如图 2 所示。ODR 模块负责检测已知和未知物体,而 OCD 模块则以无人监督的方式研究预测物体的表示,以从未知物体集合中发现新的类别。所提出的方法旨在检测属于已知类的对象,并在最少的监督下为未知类别的对象定义新类别。
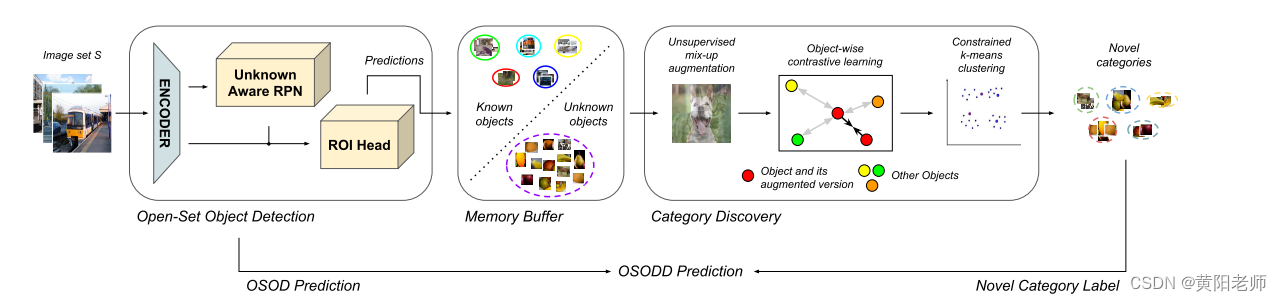
图 2 说明了开放集对象检测和发现 (OSODD) 的两阶段方法。第一阶段涉及检测已知类别的物体,并使用开放式物体探测器识别未知类别的物体。未知类的实例保存到工作内存中以进行类别发现,而已知类的实例与其预测的语义类别一起保存到已知内存中,以帮助表示学习和聚类。第二阶段以无人监督的方式预处理来自内存缓冲区的对象。这些保存的对象的表示法首先是在潜在空间中通过对比学习来学习的,然后是约束的 k 均值聚类,用于查找已知类别之外的新类别。最后,使用新类别标签更新开放式检测预测,以生成最终的 OSODD 预测。该过程的可视化如图 3 和图 4 所示。
拟议框架中的 ODR 模块使用带有双内存缓冲区的开放式对象检测器来检测和检索对象实例。该探测器使用来自 Ck 的语义标签和位置信息预测已知类别的物体,其中未知物体已定位,但没有可用的语义信息。预测的对象存储在内存缓冲区中,内存缓冲区分为两部分:已知内存和工作内存。已知内存包含带有语义标签的已知类的预测对象,而工作内存存储未知类的所有当前已识别对象,不包含类别信息。该模型研究了内存缓冲区中对象的重复模式,并在工作内存中发现了新的类别。使用发现的类别,为来自探测器的未知类别的预测物体分配了新的类别标签。可视化如图 4 所示。

图4 .显示了 Task-1 的 OSODD 预测的可视化。网球拍、停车标志、消防栓、时钟、长颈鹿和斑马是现阶段尚未引入的新颖类别。相同的边界框颜色表示属于相同类别或新类别的对象。最后一列演示了一个失败案例,即未检测到长颈鹿,其中一只斑马被分配到错误的视觉类别。补充材料中提供了更多可视化结果。
拟议框架中的OCD模块负责通过探索工作内存来发现新的视觉类别。它由作为特征提取器的编码器组件和用于聚类对象表示的鉴别器组成。为了训练编码器,检索保存在已知内存中的已知类的预测对象和保存在工作内存中的未知类的已识别对象。使用与类别无关的增强对这些实例进行转换,以创建对数据的通用视图。无监督对比学习用于忽略已知类对象的预测标签,成对比损失会惩罚相同对象在不同视图中的差异,无论语义信息如何。对比学习使编码器能够在潜在空间中学习更具辨别性的特征表示。最后,利用从编码器学到的特征空间,鉴别器使用约束的 k 均值聚类算法,将嵌入的对象聚类到新的类别中。
4.1.目标检测与检索
开放集对象检测器。开集对象检测器预测所有感兴趣对象的位置。然后,它将对象分类到语义类中,并将看不见的对象识别为未知的(参见图3中的“OSOD”)。

图3.OSOD和OSODD预测的比较。OSODD(右图)通过为未知类的实例分配新的类别标签来扩展OSOD(左图)预测。
本文使用Faster RCNN架构作为基准模型,遵循ORE,并利用RPN的类无关特性,使用未知感知的RPN识别未知对象。具有未知感知的RPN将分数较高但不与任何GT边界框重叠的proposals标记为潜在的未知对象。为了学习每个类别的更具辨别性的表示方法,我们使用原型的基于压缩损失的特征向量fc,通过一个中间层在ROI池化层的头部产生。通过类实例表示的移动平均来计算类原型pi,并且对象的特征fc将在潜在空间中保持接近其类原型。目标表述为:
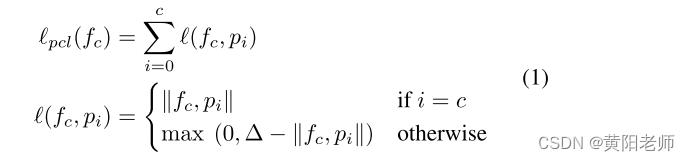
其中fc是类别c的特征向量,pi是类别i的原型,||f,p||测量特征向量之间的距离,∆是定义不相似对的最大距离的固定值。ROI池的总损失定义为:
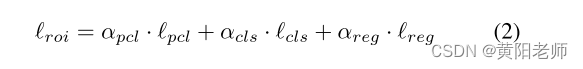
其中αpcl、αcls和αreg为正调整比。lcls,lreg是常规的分类和回归损失。
给定编码特征fc,我们使用具有基于能量的模型的开集分类器[27]来区分已知和未知类的对象。训练模型能够将低能量值分配给已知数据,从而为已知和未知类别的对象创建不同的分布表示。当新的已知类标注信息可用时,我们利用示例重放来减轻忘记以前的类。
内存模块:如上所述,我们提出使用双存储器模块来存储用于类别发现的预测实例。开集检测器检测感兴趣的对象的位置和预测标签。已知类Ik的对象被保存到已知存储器Mk中,其中它们的语义标签c ∈ Ck。这些对象被视为用于类别发现的标记数据集。所识别的未知类别Iu的对象被存储在工作存储器Mw中。我们执行类别发现的Mw,其目的是分配在Mw所有实例一个新的类别标签c ∈ Cu。我们使用新的类别标签更新开集对象检测器的预测,并产生我们最终的OSODD预测。
4.2. 对象类别发现
类别数量评估:我们的类别发现方法需要估计潜在类别的数量。我们使用[19]中的类估计方法,这是图像类别发现最常用的技术之一。该模型使用k-means方法来估计目标数据集中的类别数,而无需任何参数学习。对我们的问题的方法的泛化能力进行了评估。在6.2.1.部分。
表示学习: 表示学习旨在学习输入样本的更多区分特征。我们采用对比学习[35]并利用已知和工作记忆中的对象来帮助网络学习嵌入空间的信息。学习以无监督的方式进行。在[20]之后,我们构建了一个动态字典来存储样本。该网络被训练最大化正对(对象及其增强版本)的相似性,同时最小化嵌入空间中负对(不同对象实例)的相似性。对于对象表示,对比损失被公式化为[8]:
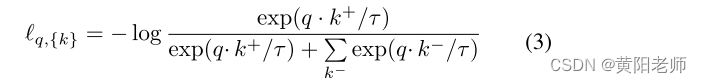
其中q是查询对象表示,{k}是关键对象样本的队列,k+是q的增强版本,称为正关键,并且k-是其他样本的表示,称为负关键。τ是温度参数。在对比学习头部之上,我们采用了一种无监督增强策略[28],用混合样本替换所有样本。它最大限度地降低了邻域风险[5],从而区分具有非常不同的模式分布的类别并创建更多的训练样本[50]。对于队列{k}中的每个样本,我们通过线性插值将其与查询对象表示q组合,并生成新视图km,i。相应地,用于第i个混合样本xm,i的新虚拟标签vi被定义为:

其中q和k+是正样本对,如果混合对来自相同的对象实例,则虚拟标签被分配为1。
新类的类别标签: 使用对象的编码表示,我们使用约束k-mean聚类[47]执行标签分配,这是一种非参数半监督聚类方法。约束kmeans聚类将来自已知和工作记忆的对象编码作为其输入。它将标准的kmeans聚类转换为约束算法,通过强制将标记的对象表示硬分配到GT类。特别地,我们将来自已知存储器Mk的对象实例视为标记样本。我们手动计算每个标记类的质心。来自Mk的这些质心用作k均值算法的第一组初始质心。然后,我们使用k-mean++算法随机初始化新类别的其余质心[1]。对于每次迭代,标记的对象实例被分配给预定义的聚类,而来自Mw的未知对象实例被分配给具有聚类质心和对象嵌入之间的最小距离的聚类。通过这样做,我们有效地避免了错误预测的对象(即,属于被预测为未知的语义类之一的对象)影响质心更新。我们只使用新的质心运行最后一个聚类分配步骤,以确保在最终预测中将来自工作内存的所有未知对象分配到所发现的视觉类别。新类质心从算法表示所发现的新类别。
5.实验设置
我们提供了一个全面的评估协议,研究我们的模型在检测对象从已知的类和发现未知类的新类别在我们的目标数据集的性能。
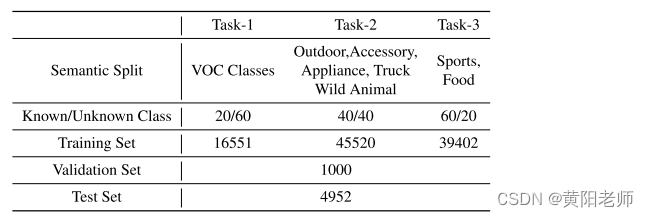
在表2中。基准类拆分详细信息。任务1、任务2和任务3具有已知和未知类的不同数据集分割。
5.1.基准数据集
Pascal VOC 2007 [12]包含10 k个图像和20个标记类。MS-COCO [32]包含大约80 k个训练和5 k个验证图像,其中包含80个标记类。这两个对象检测数据集用于构建我们的基准。在开放世界对象检测的设置[52]之后,对于三个任务T = {T1,T2,T3},类被分成已知和未知。对于任务Tt ∈ T,来自{Ti| i < t}被视为Tt的已知类,而其余类被视为未知类。对于第一任务T1,我们将20个VOC类视为已知类,并且将MS-COCO中剩余的不重叠的60个类视为未知类。新的类被添加到连续任务中的已知集合,即,T2和T3。为了进行评估,我们使用MS-COCO的验证集,除了48个未完全标记的图像[52]。我们在表2中总结了基准测试的详细信息。
5.2. 评估指标
目标检测指标: 合格的开集对象检测器需要准确区分未知对象[11]。UDR(未知检测召回率)[52]被定义为未知对象的定位率,UDP(未知检测精度)[52]被定义为未知类别对象的正确拒绝率。令真阳性(TPu)是在联合IoU > 0.5上与真实未知对象具有交集的预测的未知对象proposals。半假阴性(FN* u)是具有IoU > 0.5的预测的已知对象proposals,其中具有真实未知对象。假阴性(FNu)是错过的真实未知对象。UDR和UDP计算如下:
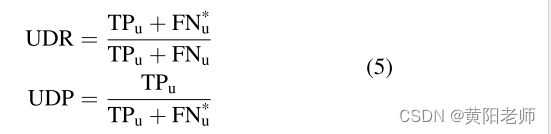
在我们的任务中,另一个重要的方面是从已知的类中定位和分类感兴趣的对象。我们评估了闭集检测表现使用标准的平均精度(mAP),当IoU阈值为0.5时。为了显示增量学习能力,我们分别为新引入的已知类和先前已知类提供mAP测量[26,37]。
类别发现指标 类别发现可以使用聚类度量进行评估,我们采用了三个最常用的聚类指标来评价我们的基本对象的类别发现性能。假设未知类别的对象的预测proposals已经匹配到真实未知对象。假设对象proposal的预测类别标签为(yi),对象的真值框标签表示为yi。我们通过以下公式计算聚类准确度(ACC)[19]:

其中N是簇的数量,Py是未知类标签的所有排列的集合。
互信息I(X,Y)量化了两个随机变量X和Y之间的相关性。I(X,Y)的范围是从0(独立)到+∞。归一化互信息(NMI)[45]在范围[0,1]内有界。设Cl是基础真值类的集合,并且Cl是预测聚类的集合。NMI公式为:

其中I(Cl,Cl)是每个类-聚类对之间的互信息之和。H(Cl)和H(Cl)使用最大似然估计来计算熵。簇的纯度定义为:

这里,N是集群的数量,max是每个集群内单个类的对象的最高计数。
6.结果和分析
6.1基线
目标检测基线。我们的框架使用了一个开放集对象检测已知和未知的实例检测。我们比较了两种最近的方法:FasterRCNN+ [26]和ORE [26]。Faster-RCNN+是一种流行的两阶段对象检测方法,它是从Faster RCNN [41]修改而来的,通过额外调整未知感知区域建议来定位未知类的对象。ORE使用对比聚类和基于能量的分类器来区分已知和未知数据的表示。我们的通用框架可以与任何开集对象检测器合作,因此它是高度灵活的
类别发现基线 我们将我们的新方法与三种基线方法进行比较,包括k-means,FINCH [42]和一个修改的方法从DTC [19]。
K-means聚类是一种非参数聚类方法,它可以最小化聚类内方差。在每次迭代中,算法首先将数据点分配到样本与质心之间的两两平方偏差最小的聚类中;然后用属于该簇的当前数据点更新簇质心。
FINCH [42]是一种无参数聚类方法,通过使用第一最近邻发现数据中的链接链。该方法直接开发的数据分组,没有任何外部参数。为了进行公平的比较,我们将聚类的数量设置为与其他基线方法相同。我们讨论了FINCH的性能估计的新类的数量在6.2.1部分。
DTC+,DTC方法[19]被提出用于NCD问题[17],其中设置假设在训练阶段未标记数据的可用性。该算法修改了深度嵌入式聚类[49]以学习标记子集的知识并将其转移到未标记子集。此设置要求训练集和测试集中的未标记数据来自相同的类。然而,在开集检测设置下的训练中没有未知实例可用。因此,基于NCD的方法,如DTC不能直接应用于我们的问题。为了方便我们的设置中的方法,我们修改它的一部分,从已知的内存中的工作记忆的类在训练和治疗他们作为额外的未知类。我们评估DTC的泛化性能对我们的问题在6.2.3.部分
6.2.实验结果
我们报告的定量结果的新的类别数量估计,对象检测和新的类别发现性能在6.2.1至6.2.3部分。我们展示和讨论定性结果在图4和在补充材料中。
6.2.1新类别数估计
我们显示的结果估计的数量的新类别的标签在表3.中间两列显示了FINCH算法[42]自动发现的分组。这些数字分别被低估了30%、32.5%和40%。最后两列显示使用DTC [19]的结果。据发现,估计的数量低于真值类数,平均错误率为21%。通过探索分组中的真实标签,我们发现这两种方法都倾向于忽略样本数量较少的对象类。与图像识别任务[19,47]中的类估计相比,检测任务面临更多有偏见的数据集以及更少的可用样本。因此,它仍然是一个具有挑战性的任务对于对象类别估计。
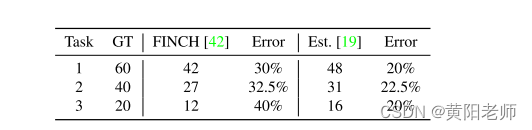
在表3中,新类别估计的结果。
6.2.2开集对象检测
我们比较了框架中对象检测部分的两个基线模型,并在表4中显示结果。对于每个任务,我们记录所有对象的mAP来评估封闭世界检测结果。UDR和UDP反映了未知对象性能和区分性能。ORE在已知类别检测上的表现优于修改后的Faster-RCNN,分别为-0.14%,+1.14%和+1.01%。当引入新的语义类时,mAP得分变低。UDR结果表明,ORE在未知对象定位方面表现更好,平均未知检测率为+0.95%。与闭集检测相反,当更多的类可用于模型时,UDR分数会提高。Faster-RCNN基线只能定位未知类的对象,但它不能从已知类中识别它们,因此没有UDP得分。

在表4中,开放集探测器的基线模型比较。记录先前/当前已知对象的平均精度(mAP),任务-1没有先前已知对象。
6.2.3新类别发现
对象类别发现的结果显示在表5和表6.测试条件与开集检测相同。我们的发现方法是能够准确地探索未知类的对象之间的新类别。
使用估计的类数,发现结果在表1中报告。5.我们观察到,我们的方法优于其他基线方法在前两个任务。在Task-3中,有60个已知类和20个未知类,我们的准确性和纯度得分略低于FINCH算法0.8%和0.1%。我们认为任务3可能包含更多有偏见的未知对象类,因此对于自监督学习学习广义表示变得具有挑战性。