目录
包装类
基本数据类型(Primitive Types):
包装类(Wrapper Classes):
装箱和拆箱
自动装箱和自动拆箱
泛型
泛型的编译——很重要的擦除机制:
泛型的上界:
泛型方法:
裸类型
List
包装类
基本数据类型和包装类是Java中处理数据的两种不同方式。
基本数据类型(Primitive Types):
Java的基本数据类型是直接存储数据的原始类型,包括以下8种类型:
byte:1字节,用于表示整数
short:2字节,用于表示整数
int:4字节,用于表示整数
long:8字节,用于表示长整数
float:4字节,用于表示单精度浮点数
double:8字节,用于表示双精度浮点数
char:2字节,用于表示字符
boolean:1位,用于表示布尔值(true或false)
包装类(Wrapper Classes):
为了方便在基本数据类型和对象之间进行转换,Java提供了对应的包装类。每个基本数据类型都有对应的包装类,命名规则是将首字母大写,例如:
Byte:对应byte
Short:对应short
Integer:对应int
Long:对应long
Float:对应float
Double:对应double
Character:对应char
Boolean:对应boolean
包装类提供了许多有用的方法来处理基本数据类型,例如进行转换、比较、解析等。它们还允许将基本数据类型作为对象使用,在集合类中存储和操作。
基本数据类型和包装类的区别:
- 存储方式:基本数据类型直接存储数据值,而包装类是将数据值封装在对象中。
- 空值表示:基本数据类型没有空值,但包装类可以表示空值通过null。
- 默认值:基本数据类型有各自的默认值(如0、0.0、false等),而包装类的默认值是null。
- 内存占用:基本数据类型占用的内存比包装类少,因为基本数据类型直接存储数据值,而包装类需要额外的空间用于存储对象的引用。
- 包装类提供了许多实用的方法来处理基本数据类型,例如类型转换、数学运算等,而基本数据类型没有这些方法。
在Java中,自动装箱(Autoboxing)和拆箱(Unboxing)机制允许基本数据类型和包装类之间的自动转换。这使得在需要使用对象的情况下可以直接使用基本数据类型,而无需手动进行类型转换。
装箱和拆箱
又称“显示装箱”。
int i = 10;
// 装箱操作,新建一个 Integer 类型对象,将 i 的值放入对象的某个属性中
Integer ii = Integer.valueOf(i);//是手动装箱
Integer ij = new Integer(i);//是手动装箱
// 拆箱操作,将 Integer 对象中的值取出,放到一个基本数据类型中
int j = ii.intValue();
Integer a = new Integer(10);
//显示拆箱 拆箱为自己指定的元素
int c = a.intValue();
System.out.println(c);
double d = a.doubleValue();
System.out.println(d);
自动装箱和自动拆箱
自动装箱,又称“隐式装箱”,是指在编译阶段,Java编译器会自动将基本类型转换为对应的包装类型,而不需要显式地调用构造函数来完成装箱操作。
nt i = 10;
Integer ii = i; // 自动装箱
Integer ij = (Integer)i; // 自动装箱
int j = ii; // 自动拆箱
int k = (int)ii; // 自动拆箱严格来说,int k = (int)ii; 不是自动装箱,而是强制类型转换,将基本数据类型int转换为包装类型Integer。在这种情况下,需要注意i的值不能超出Integer类型的取值范围,否则会抛出NumberFormatException异常。
易错题:
1、下列代码输出什么,为什么?
public static void main(String[] args) {
Integer a = 127;
Integer b = 127;
Integer c = 128;
Integer d = 128;
System.out.println(a == b);
System.out.println(c == d);
}
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer cache[];
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
try {
int i = parseInt(integerCacheHighPropValue);
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
} catch( NumberFormatException nfe) {
// If the property cannot be parsed into an int, ignore it.
}
}
high = h;
cache = new Integer[(high - low) + 1];
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
// range [-128, 127] must be interned (JLS7 5.1.7)
assert IntegerCache.high >= 127;
}
private IntegerCache() {}
}
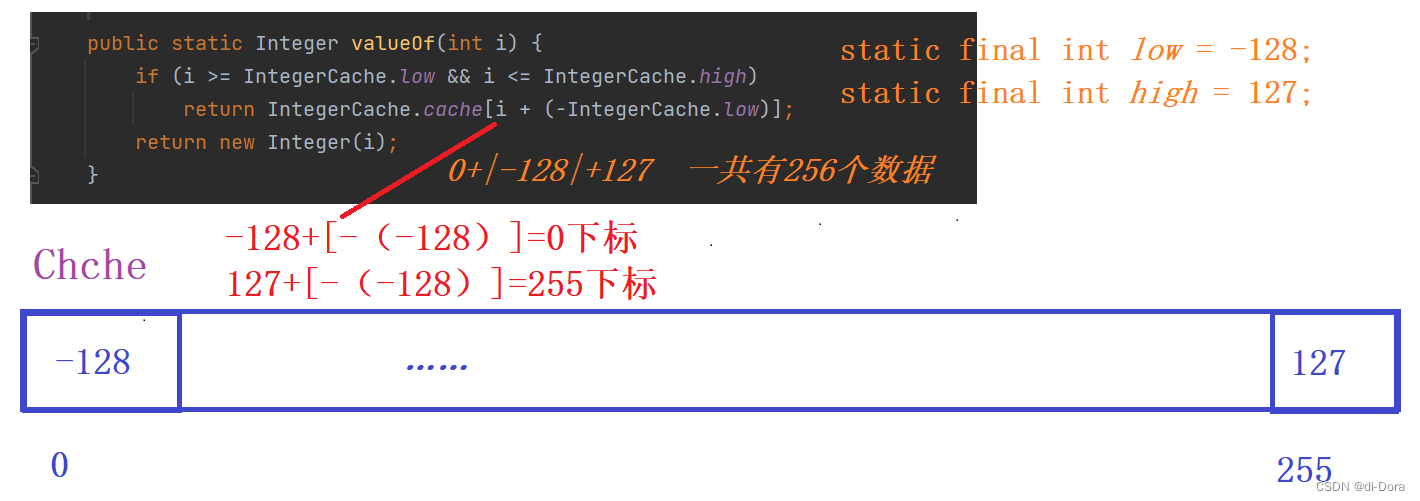
这段代码主要是对Java中自动装箱的缓存机制进行测试。Java中对于byte、short、int类型的自动装箱,如果值在[-128, 127]之间,则会将其缓存起来,重复使用同一个对象。
在这段代码中,首先声明了两个Integer类型的变量a和b,并将它们赋值为127,然后声明了两个Integer类型的变量c和d,并将它们赋值为128。
在输出语句中,通过"=="运算符比较a和b、c和d的值是否相等,如果相等则输出true,否则输出false。
由于a和b的值都在[-128, 127]之间,因此它们会被缓存起来,重复使用同一个对象,所以a和b指向的是同一个对象,因此a==b的结果为true。
而c和d的值都不在[-128, 127]之间,因此它们不会被缓存起来,每次自动装箱时都会创建一个新的Integer对象,所以c和d指向的不同对象,因此c==d的结果为false。
因此,这段代码的输出结果为:
true
false
2、下列在Java语言中关于数据类型和包装类的说法,正确的是()
A.基本(简单)数据类型是包装类的简写形式,可以用包装类替代基本(简单)数据类型
B. long和double都占了64位(64bit)的存储空间。
C.默认的整数数据类型是int,默认的浮点数据类型是float。
D.和包装类一样,基本(简单)数据类型声明的变量中也具有静态方法,用来完成进制转化等
答案:B
A. 错误。基本数据类型和包装类是不同的。基本数据类型是直接存储数据的原始类型,而包装类是对基本数据类型进行封装的类。虽然在某些情况下,基本数据类型可以自动转换为对应的包装类,但它们并不是同一概念。
C.默认的浮点数据类型是double。
D. 错误。基本数据类型声明的变量不具有静态方法。只有包装类才有静态方法,用于提供一些辅助功能,如进制转换等。基本数据类型的变量只能访问与其对应的基本数据类型的功能和操作,无法调用静态方法。
泛型
在编程中,泛型(Generic)是一种通用的编程概念,它可以用于定义能够适用于多种类型的函数、类或数据结构。泛型允许在编写代码时不指定具体的类型,而是使用类型参数来表示待定的类型。
1. 泛型是将数据类型参数化,进行传递
2. 使用 <T> 表示当前类是一个泛型类。
3. 泛型目前为止的优点:数据类型参数化,编译时自动进行类型检查和转换
泛型只能接受类,所有的基本数据类型必须使用包装类!
当编译器可以根据上下文推导出类型实参时,可以省略类型实参的填写:
MyArray<Integer> list = new MyArray<>(); // 可以推导出实例化需要的类型实参为 Integer泛型的编译——很重要的擦除机制:
泛型的编译中,擦除(Erasure)机制是一项重要的步骤。它是指在编译阶段将泛型类型信息从生成的字节码中擦除的过程。擦除机制是为了保持与Java早期版本的向后兼容性,并允许泛型代码与不使用泛型的代码进行交互。
通过命令:javap -c 查看字节码文件,所有的T都变成了Object。
原来,当使用泛型时,编译器会在编译过程中执行以下操作:
- 类型擦除:编译器将泛型类型参数替换为其上界或Object类型。例如,一个泛型类List<T>在擦除后会变成List<Object>。
- 类型转换:由于擦除导致类型信息丢失,编译器会插入必要的类型转换操作来保证代码的类型安全性。这些类型转换在编译时进行。
- 插入桥方法:当泛型类或接口涉及继承或实现时,编译器会插入桥方法来确保泛型类型的正确转换。桥方法是编译器生成的方法,用于在泛型类型和非泛型类型之间进行桥接。
现在,我们只需要知道:
在编译的过程当中,将所有的T替换为Object这种机制,我们称为:擦除机制。 Java的泛型机制是在编译级别实现的。编译器生成的字节码在运行期间并不包含泛型的类型信息。
这里是一篇有关泛型擦除机制的文章介绍:Java泛型擦除机制之答疑解惑 - 知乎 (zhihu.com)
好了,下面是需要格外注意的一点:
擦除机制导致泛型类型在运行时丢失了具体的类型信息,这就是为什么在运行时无法检测泛型类型的实际参数类型。例如,对于一个List<String>对象,在运行时它只是一个普通的List对象,无法知道其元素类型是String。
数组是很特殊的,不可以整体强制类型转换。
不可以实例化泛型。
public Object[] array = new Object[10];
//public T[] array = new T[10]; 不允许 实例化一个泛型数组
//public T[] array = (T[])new Object[10];//这样写也不好!!
public T[] array = (T[])new Object[10];
public static void main3(String[] args) {
//泛型是如何编译的
MyArray<String> myArray = new MyArray<>();
myArray.set(0,"hello");
//String[] ret = (String) myArray.getArray();
//没意义,已经强制转换过了!本质它是一个 Object数组,
//啥都能放,你怎么确定放的就是字符串?
//String[] ret = myArray.getArray();也还是不行
/*总的来说,就是我们返回的Object数组里面,可能存放的是任何的数据类型,
可能是String,可能是Person,运行的时候,
直接转给String类型的数组,编译器认为是不安全的。*/
Object[] ret = myArray.getArray();
System.out.println(Arrays.toString(ret));
}
public Object[] getArray() {
return array;
}
/* public T[] getArray() {
return array;
}*/
//那我就要有这个方法呢?
public T[] getArray() {
return (T[])array;
}
我们来谈一谈:
- 为什么不可以这样写:public T[] array = new T[10];
- 为什么这样写也不好?:public T[] array = (T[])new Object[10];
- 写成这样:public T[] array = (T[])new Object[10];
Java中不允许直接实例化泛型数组的原因与类型擦除机制有关。在泛型的擦除过程中,泛型类型参数被替换为其上界或Object类型,因此在编译时无法确定具体的泛型类型。这就导致无法直接实例化一个泛型数组。
让我们看看为什么以下两种写法都不被允许:
1、public T[] array = new T[10];
这种写法是不被允许的,因为在编译时无法确定泛型类型参数T的具体类型。编译器无法实例化一个未知类型的数组。例如,如果T是一个类的类型参数,那么new T[10]将无法确定要实例化哪个具体类的数组。2、public T[] array = (T[])new Object[10];
这种写法使用了类型转换将一个Object数组转换为泛型类型数组。尽管编译器允许这种写法,但是需要注意的是,这会引发潜在的运行时类型转换错误。由于类型擦除,编译器无法检查类型转换的正确性,因此可能会导致ClassCastException或其他类型相关的异常。为了解决这个问题,可以采用以下方式来实例化泛型数组:
public class GenericArray<T> { private T[] array; public GenericArray(int size) { // 使用反射创建泛型数组 array = (T[]) new Object[size]; } public T[] getArray() { return array; } public static void main(String[] args) { GenericArray<String> genericArray = new GenericArray<>(10); String[] array = genericArray.getArray(); System.out.println(Arrays.toString(array)); } }在上述示例中,我们通过使用反射来创建泛型数组。尽管编译器会发出未经检查的警告,但是我们可以安全地使用泛型数组,并在运行时避免类型转换错误。
所以不管怎么样,返回什么,我们都用Object来接收。源码里面也是这么写的。
现在,你可以回答以下两个问题了吗:
1、为什么,T [ ] ts = new T[5]; 是不对的,编译的时候,替换为Object,不是相当于:Object [ ] ts = new Object[5]吗?
2、类型擦除,一定是把T变成Object吗?
解析:
1、在Java中,泛型数组的创建是受到限制的。T [ ] ts = new T[5];这样的语法是不被允许的,因为在泛型的擦除过程中,数组的实际类型信息是丢失的。编译器无法确定如何创建一个泛型数组,因为它无法确定擦除后的具体类型。
为了解释这一点,让我们假设编译器允许这样的语法,并将其替换为Object [ ] ts = new Object[5];然后考虑以下情况:
ts[0] = new T();这里的问题是,编译器无法确定T的具体类型是什么,因为类型信息已经被擦除了。如果T代表某个类或接口的子类型,那么使用new T()无法确定具体实例化哪个类。
为了避免这种类型不确定性,Java禁止直接创建泛型数组。相反,可以使用通配符类型或者使用Object数组,并进行类型转换来实现类似的效果。
2、类型擦除并不一定将类型参数替换为Object。在泛型的擦除过程中,类型参数被替换为它们的上界(或者如果没有指定上界,则被替换为Object)。(我们马上就要提到“泛型的上界”了)。
例如,对于 List <T>,在类型擦除后会变为 List <Object>。但是,如果我们指定了上界,例如List<T extends Number>,在类型擦除后,T将被替换为Number,而不是Object。
总结起来,类型擦除会将类型参数替换为上界或Object,具体取决于类型参数是否有指定的上界。这样做是为了在擦除后仍然保持代码的类型安全性,并且与不使用泛型的代码进行兼容。
尽管泛型的擦除机制限制了在运行时访问具体的泛型类型信息,但在编译时它仍然提供了类型安全性和编译时类型检查的好处。擦除机制使得泛型代码可以与不使用泛型的旧代码进行交互,并允许在编译时捕获一些类型错误。尽管存在一些局限性,但擦除机制仍然是Java泛型实现的核心特性之一。
泛型的上界:
泛型的上界(Upper Bound)是一种约束,用于限制泛型类型参数的范围。上界指定了一个类型参数必须是某个特定类型或特定类型的子类型。
在Java中,可以使用extends关键字来指定泛型的上界。例如,假设我们有一个泛型类或泛型方法,使用类型参数T。我们可以使用extends关键字来限制T必须是某个特定类或接口的子类型。下面是一个简单的示例:
public class ExampleClass<T extends Number> {
private T value;
public ExampleClass(T value) {
this.value = value;
}
public T getValue() {
return value;
}
// 其他方法和逻辑
}在上面的示例中,类型参数 T 被限制为Number类的子类型。这意味着我们只能在ExampleClass中使用Number及其子类型作为T的具体类型。例如,可以使用Integer、Double或其他继承自Number的类型来实例化ExampleClass。
通过指定上界,我们可以在编写泛型代码时对类型参数进行更精确的控制,并在编译时捕获一些类型错误。这可以提高代码的安全性和可读性,并允许更好地利用静态类型检查的好处。
泛型方法:
泛型方法是指在方法声明中使用了泛型类型参数的方法。泛型方法具有以下两种类型:
可类型推导的泛型方法(Generic Method with Type Inference):这种泛型方法可以根据方法参数的类型推导出泛型类型参数的具体类型,而不需要显式地指定类型参数。编译器能够根据方法调用时提供的参数类型来推断泛型类型参数。这种类型的泛型方法可以更简洁地调用,因为编译器会自动推断类型。
以下是一个可类型推导的泛型方法的示例:
public <T> void printArray(T[] array) {
for (T element : array) {
System.out.println(element);
}
}在上面的示例中,泛型类型参数T并没有显式地指定类型,而是根据方法参数array的类型进行推导。例如,如果调用printArray(new Integer[]{1, 2, 3}),编译器会自动推断T为Integer类型。
不可类型推导的泛型方法(Generic Method without Type Inference):这种泛型方法在方法调用时需要显式地指定泛型类型参数的具体类型。无法根据方法参数的类型自动推断类型参数。需要手动指定泛型类型参数,这在某些情况下可能是必需的,特别是当类型推断无法正常工作或需要显式控制类型时。
以下是一个不可类型推导的泛型方法的示例:
public <T> void printArray(T[] array, Class<T> type) {
for (T element : array) {
System.out.println(element);
}
}在上面的示例中,我们需要在方法调用时显式地指定泛型类型参数T的具体类型,例如printArray(new Integer[]{1, 2, 3}, Integer.class)。
总而言之,可类型推导的泛型方法允许编译器根据方法参数的类型自动推断泛型类型参数,而不可类型推导的泛型方法需要显式地指定泛型类型参数的具体类型。可类型推导的泛型方法通常更简洁易用,但在某些情况下不可类型推导的泛型方法是必需的。
裸类型
裸类型(Raw Type)是指在泛型代码中使用泛型类型参数而没有指定具体类型实参的情况。当使用裸类型时,泛型的类型安全性检查被绕过,可能导致编译器无法捕获潜在的类型错误。
裸类型主要出现在以下两种情况下:
- 在旧版本的Java代码中:在引入泛型之前的旧代码中,没有使用泛型的概念。当将这些代码与使用泛型的新代码进行交互时,编译器会发出未经检查的警告,并将泛型类型参数擦除为裸类型。
- 显式使用裸类型:在泛型代码中,可以显式地指定裸类型,即省略泛型的具体类型实参。这通常是为了与不使用泛型的代码进行兼容或避免繁琐的类型参数指定。
使用裸类型存在以下风险和问题:
- 编译时类型安全性缺失:裸类型绕过了泛型的类型检查机制,编译器无法对其进行类型安全性检查。这可能导致在运行时出现类型转换错误或其他类型相关的异常。
- 运行时类型错误:由于裸类型丢失了具体的类型信息,可能导致在运行时发生ClassCastException等类型错误。
- 代码可读性和维护性下降:使用裸类型会降低代码的可读性和可维护性,因为泛型的意图和约束没有明确表达出来,代码的含义变得模糊。
当使用裸类型时,编译器会发出未经检查的警告。下面是一个使用裸类型的例子:
import java.util.ArrayList;
import java.util.List;
public class RawTypeExample {
public static void main(String[] args) {
List list = new ArrayList(); // 使用裸类型
list.add("Hello");
list.add(123);
// 从列表中获取元素时,无法保证类型的安全性
String str = (String) list.get(0); // 运行时可能会发生ClassCastException
int number = (int) list.get(1); // 运行时可能会发生ClassCastException
System.out.println(str);
System.out.println(number);
}
}在上面的示例中,我们创建了一个ArrayList的裸类型对象,并向其添加了一个字符串和一个整数。然后,我们尝试从列表中获取元素并进行类型转换。由于裸类型丢失了具体的类型信息,编译器无法在编译时捕获类型错误。因此,当我们运行该代码时,可能会抛出ClassCastException。
要修复这个问题,我们应该使用泛型类型参数来明确指定列表的类型。下面是一个修复后的示例:
import java.util.ArrayList;
import java.util.List;
public class GenericTypeExample {
public static void main(String[] args) {
List<String> list = new ArrayList<>(); // 使用泛型类型
list.add("Hello");
// list.add(123); // 编译错误,无法将整数添加到字符串列表中
String str = list.get(0); // 不需要进行类型转换
System.out.println(str);
}
}在这个修复后的示例中,我们使用了泛型类型参数<String>来明确指定列表的类型为字符串类型。这样,编译器会在编译时进行类型检查,并阻止将整数添加到字符串列表中。这提供了更好的类型安全性,并在编译时捕获潜在的类型错误。
为了避免使用裸类型,应该尽量遵循泛型的使用规范,为泛型类型参数指定具体类型实参,并尽量避免显式使用裸类型。这样可以确保代码的类型安全性,并使代码更易于理解和维护。同时,应该警惕编译器发出的未经检查的警告,并尽量修复这些警告,以提高代码质量。
List
List是Java集合框架中的一个接口,它表示一个有序的、可重复的元素集合。List接口继承自Collection接口,并在其基础上添加了一些与索引相关的操作方法。
这是List 的官方文档:列表 (Java Platform SE 8 ) (oracle.com)
List的特点包括:
- 有序性:List中的元素按照它们被添加的顺序进行存储,并且可以通过索引访问和操作元素。每个元素都有一个与之关联的索引,从0开始递增。
- 可重复性:List中可以存储重复的元素,即同一个元素可以出现多次。
- 动态大小:List的大小是可变的,可以根据需要动态地添加或删除元素。
List接口提供了许多常用的方法,使我们能够对集合中的元素进行增加、删除、修改、查找等操作。一些常用的List实现类包括:
- ArrayList:基于数组实现的动态数组,支持快速随机访问,但插入和删除操作可能较慢。
- LinkedList:基于链表实现的双向链表,支持快速的插入和删除操作,但随机访问较慢。
- Vector:类似于ArrayList,但是是线程安全的,适用于多线程环境。
- Stack:基于Vector实现的栈数据结构,支持先入后出的操作。
List接口提供了一系列的方法,如:
添加元素:add、addAll
获取元素:get、indexOf、lastIndexOf
删除元素:remove、removeAll、clear
修改元素:set
遍历元素:forEach、iterator、listIterator
判断元素是否存在:contains、isEmpty
获取列表大小:size
截取子列表:subList
其他:sort、reverse、shuffle等
List的灵活性和功能丰富性使得它成为Java中常用的集合类型之一,可以方便地操作和管理有序的元素集合。无论是需要保持元素顺序、支持重复元素,还是进行索引操作,List都是一个很好的选择。
注意:在编程中,一般会使用 List<String> ad = new ArrayList<>(); 的形式来创建 ArrayList 对象,因为这样代码的可读性更好,而且灵活性更高。这是因为,List 接口是 ArrayList 类的一个父接口,通过使用 List 类型的引用来指向 ArrayList 对象,可以使代码更具有通用性。这样写的好处是,以后如果需要更改为其他类型的 List(如 LinkedList),只需要改变声明的时候的类型,而不需要修改实例化的代码。
虽然直接使用 ArrayList<String> ad = new ArrayList<>(); 也是可以的,但是不够灵活,不利于后期代码的维护和扩展。当然,使用 ArrayList<String> ad = new ArrayList<>(); 也有好处,它能够调用的方法更多。