目录
- 1. selenium的安装配置
- 2. 为什么使用selenium?它的优势和缺点是什么?
- 3. selenium的基本使用
- 4. selenium实战之csdn搜索python博文
- 4.1 点击选择文章
- 4.2 搜索栏输入搜索关键词
- 4.3 实现代码
- 总结
欢迎关注 『python爬虫』 专栏,持续更新中
欢迎关注 『python爬虫』 专栏,持续更新中
1. selenium的安装配置
需要下载对应你谷歌浏览器版本的驱动,详情可看我的博文
配置selenium库的浏览器驱动,解决selenium.common.exceptions.SessionNotCreatedException 报错(保姆级图文)
2. 为什么使用selenium?它的优势和缺点是什么?
- selenium是⼀个⾃动化测试的⼯具,可以模拟真人启动一个浏览器访问网页,并从中提取到你想要的内容。
- selenium的独特优点:真正模拟真人,有谷歌官方支持研发推动。随着各种⽹站的反爬机制的出现,比如我们之前遇到过的各种加密解密、各种请求响应,知道他加密的方法后爬虫不困难,但是如何研究出他的加密方式很困难。
- selenium最⼤的缺点:慢。他要启动⼀个(浏览器),请求一些可能我们不需要的资源,(比如我们只要爬取文字,但是他本身也会顺带请求图片的信息)还要让浏览器把数据渲染后才开始爬虫,这大大增加了资源占用和消耗的时间。
3. selenium的基本使用
从一个驱动对象开始,寻找节点,进行各种操作。
- web = Chrome() #创建一个selenium对象
- web.get(“http://lagou.com”) #模拟浏览器打开一个网页
- el = web.find_element_by_xpath(‘//*[@id=“changeCityBox”]/ul/li[1]/a’) #xpath的解析方式寻找元素节点
- el.click() # 元素节点.click() 表示点击元素节点
- web.find_element_by_xpath(‘//*[@id=“search_input”]’).send_keys(“python”, Keys.ENTER) #搜索栏输入关键词
- 注意操作延时等待的问题,有固定等待时间/隐式等待/显式等待三种方法。
4. selenium实战之csdn搜索python博文
我的博客主页
https://blog.csdn.net/u011027547
4.1 点击选择文章
切换到文章的选项卡,这里就复制一下文章的xpath//*[@id="userSkin"]/div[2]/div/div[2]/div[1]/div[1]/ul/li[2]
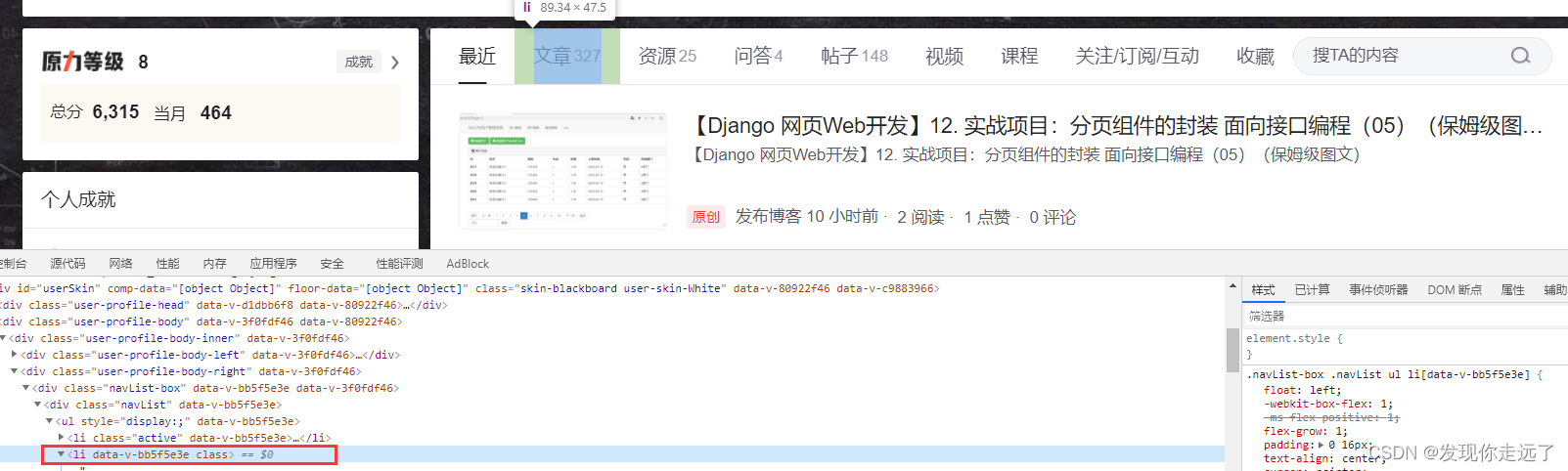
注意点击后会有一个加载的时间,注意要留一点等待的时间,防止加载过慢,我们就进行下一步的操作。(细心的你也许会发现url变成了https://blog.csdn.net/u011027547?type=blog就是在原来的基础上增加了?type=blog其实切换到文章这种步骤如果没有防盗链限制访问来源refer的url的话,后期可以直接省略,url参数加上就行,这里是为了给大家演示点击的操作。)
4.2 搜索栏输入搜索关键词

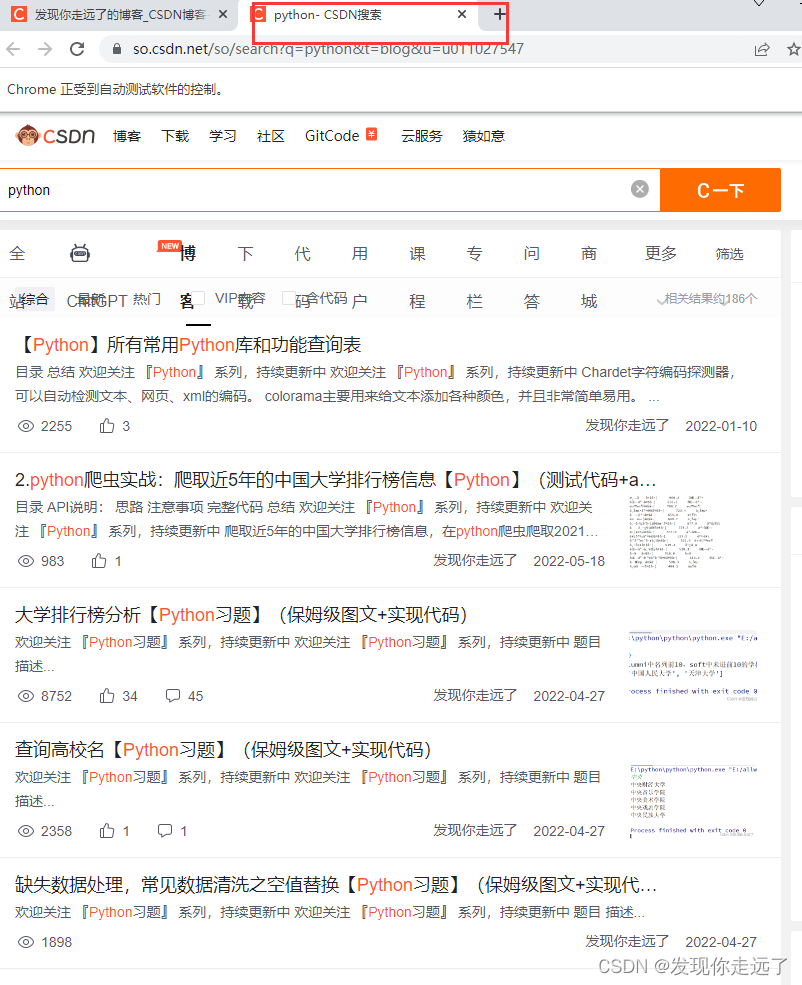
csdn的搜索需要先点击一下搜TA的内容 xpath为//*[@id="userSkin"]/div[2]/div/div[2]/div[1]/div[1]/div/div[1]/span,然后才会激活搜索关键词输出进而搜索
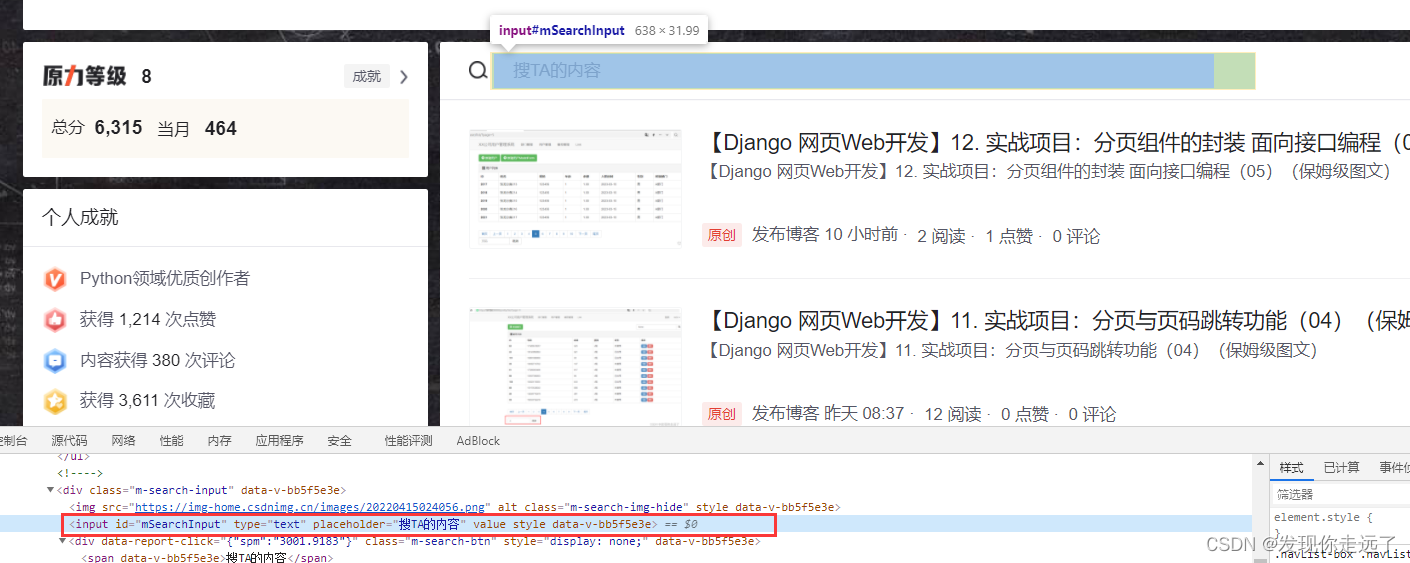
得到搜索栏xpath //*[@id="mSearchInput"],节点使用 send_keys("python", Keys.ENTER)输入关键词后回车,等级搜索结束就可以爬取数据了
4.3 实现代码
因为搜索会打开一个新的窗口,这部分内容放在下一篇文章详细说明。本次代码截止到出现待爬取数据的页面
from selenium.webdriver import Chrome
from selenium.webdriver.common.keys import Keys
import time
from selenium.webdriver.support.wait import WebDriverWait
web = Chrome()#创建一个selenium对象
web.get("https://blog.csdn.net/u011027547")#模拟浏览器打开一个网页
# 最大化浏览器的窗口
# web.maximize_window()
# 找到某个元素. 点击文章选项卡
el = web.find_element_by_xpath('//*[@id="userSkin"]/div[2]/div/div[2]/div[1]/div[1]/ul/li[2]')#xpath的解析方式寻找元素节点
el.click() # 元素节点.click() 表示点击元素节点
time.sleep(2)
# 让浏览器缓一会儿,注意这个时长一定要大于网页渲染的时间
# 否则可能我们点击后的网页新出现的节点没有出现,程序就继续执行下去了,找不到我们要点击的新节点
# 找到输入框. 输入python => 输入回车/点击搜索按钮
web.find_element_by_xpath('//*[@id="userSkin"]/div[2]/div/div[2]/div[1]/div[1]/div/div[1]/span').click()
time.sleep(2)
web.find_element_by_xpath('//*[@id="mSearchInput"]').send_keys("python", Keys.ENTER)
总结
大家喜欢的话,给个👍,点个关注!给大家分享更多计算机专业学生的求学之路!
版权声明:
发现你走远了@mzh原创作品,转载必须标注原文链接
Copyright 2023 mzh
Crated:2023-3-1
欢迎关注 『python爬虫』 专栏,持续更新中
欢迎关注 『python爬虫』 专栏,持续更新中
『未完待续』