传统目标检测
任务目标
从图像中找出相应的物体位置

目标检测的核心目的在于,估计出目标在图像中的坐标。
问题定义
目标检测的结果是什么?
预测出目标在图像中的位置。
位置如何表示?
通常采用水平矩形框的形式估计目标。
在opencv中的水平矩形框的定义为:
rect=[x,y,ℎ,w]
其中,(x, y)为矩形框的左上角坐标,ℎ,w为矩形框的高和宽。
因此,目标检测的最终目的在于,得到目标在图像中的矩形框。
核心问题
-
目标位置不确定--目标有可能出现在图像的任何位置(求x, y)
-
目标尺度不确定--由于成像距离不同,目标的尺度也不一致 (求 ℎ,w)
-
目标状态不确定--目标存在多样性,状态多样化。(判断矩形框中是否为目标)
传统方法的解决思路
传统目标检测的方法很多(如关键点检测),但更主流的方法大多是基于滑动窗口来实现的。主要包含以下步骤:
- 滑动窗口
定义一个固定尺寸的滑动窗口以及滑动步长,在图像中从左到右从上到下的滑动。
每次滑动后,都可以截取出固定大小的图像区域,用于判断这些内容是否为目标。
滑动窗口解决了目标位置不确定的问题
- 图像金字塔
图像金字塔的主流方式是通过将图像变换为不同的尺度,进行滑动窗口式的检测。
或者用不同尺度的窗口对图像进行滑动。
涉及的参数包括:矩形框的大小和比例
图像金字塔解决了目标尺度不确定的问题
- 特征提取与分类器
从目标区域提取特征,将图像内容映射到特征空间,实现目标更加泛化的分类。
特征提取包括sift、surf、orb,或者hog、lbp等等传统手工特征。
结合svm等分类器,来判断图像区域是否包含目标。
该步骤解决了目标多样性问题。
传统方法与深度方法的不同
在深度学习刚刚被提出的时候,你会如何利用深度学习来进行目标检测?
换句话说,深度学习能够替代传统方法中的那些步骤?
- 特征提取与分类器
特征提取与分类器是最直观想到的替换步骤。利用深度学习强大的泛化性能,来实现更加准确的区域图像分类。
- 图像金字塔
深度学习的强大特征归纳能力,可以在特征层面进行金字塔处理,从而极大地减少了图像金字塔的目标检测计算量
- 滑动窗口
深度学习可以完美的绕开滑动窗口的限制,通过对全图进行特征提取,可以从特征图上看到不同的对目标的响应状态。
这种响应状态可以使得我们无需遍历窗口,只需要选择有较高响应的区域进行深度识别即可。
目标检测的数据集
PASCAL VOC 2012
11530张图像,检测任务有27450个物体。
包含背景,共21类,包括
人
鸟、猫、牛、够、马、羊
飞机、自行车、船、公交车、汽车、摩托车、火车
瓶子、椅子、桌子、盆栽、沙发、显示器

MS COCO
328000张图像,2500000个标记
目标检测有80个类别。
包含pascal voc数据
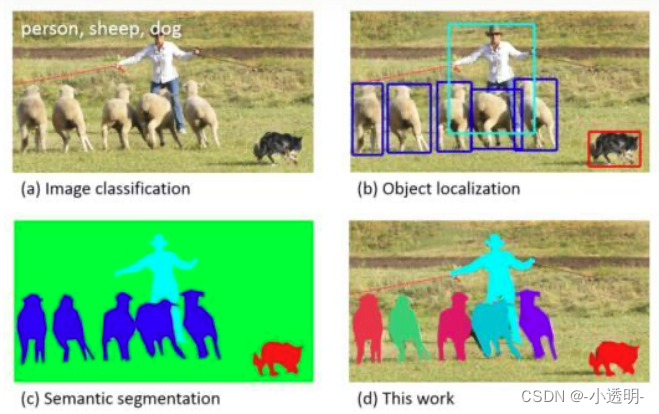
深度学习的目标检测方法的大致分类和介绍
深度学习方法开启了目标检测的新世界。
早期的检测方法虽然用深度学习进行目标检测,但是仍然拘泥于滑动窗口方式,用深度学习作为特征提取器和目标分类器使用
之后,随着发展,目标检测分出了两种流派:
- 流派一:两阶段目标检测。首先从图像中初步筛选出可能存在目标的区域(不用确定目标是什么),然后再使用分类器对目标进行进一步的分类;
- 流派二:一阶段目标检测。不用出不筛选,直接对图像中的物体进行定位和分类。比二阶段更快,但没有二阶段准确。
以上两类模型都被称为Anchor-based方法。
Anchor是一组被筛选出来的目标框。从这些目标框中找出最好的那一个,就是anchorbased的方法。
本质上,anchor based的方法还有着滑动窗口方式的时代印记。(yolo、rcnn系列、ssd等)
随着时代进步,逐渐发展出anchor free的方法。
anchor free把问题进行了升级,不再纠结候选框,而是直接对目标的关键点进行预测。
预测出目标的左上角和右下角,即可得到目标框。(cornernet)
本章内容简介
本章主要聚焦anchor based的方法,内容包括
- rcnn系列
- yolo系列
- ssd
同时,也会介绍一些anchor free的方法,如
- corner net