系列文章目录
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
例如:第一章 Python 机器学习入门之pandas的使用
文章目录
- 系列文章目录
- 前言
- 一、CPU相关知识
- 1.CPU核心架构
- 大小核架构
- 2.绑核
- 3.锁频
- 4.CPU状态
- 二、线程状态
- 1.Runnable 状态说明
- Runnable 过长的原因和优化思路
- 1.优先级设置错误
- 2.绑核不合理
- 3.软件架构设计不合理
- 4.应用自己或系统整体负载高导致排队的任务非常多
- 5.CPU 算力限制、锁频、锁核、状态异常
- 6.调度器异常
- 2.Running 状态说明
- 1.代码本身复杂度高,执行耗时久
- 2.代码以解释方式执行
- 3.线程跑小核,导致执行时间长
- 4.线程所跑的大核运行频率太低
- 5.温升导致 CPU 关核、限频
- 6.CPU 算力弱
- 3.Sleep状态说明
- 耗时过长的常见原因
- IOWait 常见原因与优化方法
- 1.主动IO 操作
- 2.低内存导致的 IO 变多
- Non-IOWait 常见原因
- 总结
前言
一、CPU相关知识
1.CPU核心架构
简单来说目前的手机 CPU 按照核心数和架构来说,可以分为下面三类:
- 大小核架构
- 非大小核架构
- 大中小核架构
大小核架构
现在的 CPU 一般采用 8 核心,八个核心中,CPU 0-3 一般是小核心,CPU 4-7一般是大核心。如下图为Systrace中展示的CPU核心信息:

-
小核心一般来说主频低,功耗也低,使用的一般是 arm A5X 系列,比如高通骁龙 845,小核心是由四个 A55 (最高主频 1.8GHz ) 组成
-
大核心一般来说最高主频比较高,功耗相对来说也会比较高,使用的一般是 arm A7X 系列,比如高通骁龙 845,大核心就是由四个 A75(最高主频 2.8GHz)组成
2.绑核
绑核,顾名思义就是把某个任务绑定到某个或者某些核心上,来满足这个任务的性能需求:
- 任务本身负载比较高,需要在大核心上面才能满足时间要求
- 任务本身不想被频繁切换,需要绑定在某一个核心上面
- 任务本身不重要,对时间要求不高,可以绑定或者限制在小核心上面运行
上面是一些绑核的例子,目前 Android 中绑核操作一般是由系统来实现的。厂商可以针对不同的 CPU 架构进行定制,目前默认划分:
- system-background 一些低优先级的任务会被划分到这里,只能跑到小核心里面
- foreground 前台进程
- top-app 目前正在前台和用户交互的进程
- background 后台进程
- foreground/boost 前台 boost 进程,通常是用来联动的,现在已经没有用到了,之前的时候是应用启动的时候,会把所有 foreground 里面的进程都迁移到这个进程组里面
每个任务跑在哪个组里面,是动态的,并不是一成不变的,有权限的进程就可以改。大部分 App 进程是根据状态动态去变化的,在 Process 这个类中有详细的定义:
/**
* Default thread group -
* has meaning with setProcessGroup() only, cannot be used with setThreadGroup().
* When used with setProcessGroup(), the group of each thread in the process
* is conditionally changed based on that thread's current priority, as follows:
* threads with priority numerically less than THREAD_PRIORITY_BACKGROUND
* are moved to foreground thread group. All other threads are left unchanged.
* @hide
*/
public static final int THREAD_GROUP_DEFAULT = -1;
/**
* Background thread group - All threads in
* this group are scheduled with a reduced share of the CPU.
* Value is same as constant SP_BACKGROUND of enum SchedPolicy.
* @hide
*/
public static final int THREAD_GROUP_BACKGROUND = 0;
/**
* Foreground thread group - All threads in
* this group are scheduled with a normal share of the CPU.
* Value is same as constant SP_FOREGROUND of enum SchedPolicy.
* Not used at this level.
* @hide
**/
private static final int THREAD_GROUP_FOREGROUND = 1;
/**
* System thread group.
* @hide
**/
public static final int THREAD_GROUP_SYSTEM = 2;
/**
* Application audio thread group.
* @hide
**/
public static final int THREAD_GROUP_AUDIO_APP = 3;
/**
* System audio thread group.
* @hide
**/
public static final int THREAD_GROUP_AUDIO_SYS = 4;
/**
* Thread group for top foreground app.
* @hide
**/
public static final int THREAD_GROUP_TOP_APP = 5;
/**
* Thread group for RT app.
* @hide
**/
public static final int THREAD_GROUP_RT_APP = 6;
/**
* Thread group for bound foreground services that should
* have additional CPU restrictions during screen off
* @hide
**/
public static final int THREAD_GROUP_RESTRICTED = 7;
在 OomAdjuster 中会动态根据进程的状态修改其对应的 CPUset 组, 详细可以自行查看 OomAdjuster 中 computeOomAdjLocked、updateOomAdjLocked、applyOomAdjLocked 的执行逻辑(Android 10)
3.锁频
正常情况下,CPU 的调度算法都可以满足日常的使用,但是在 Android 中的部分场景里面,单纯依靠调度器,可能会无法满足这个场景对性能的要求。比如说应用启动场景,如果让调度器去拉频率迁核,可能就会有一定的延迟,比如任务先在小核跑,发现小核频率不够,那就把小核频率往上拉,拉上去之后发现可能还是不够,经过几次一直拉到最高发现还是不够,然后把这个任务迁移到中核,频率也是一次一次拉,拉到最高发现还是不够,最好迁移到大核去做。这样一套下来,时间过去不少不说,启动速度也不是最快的。
基于这种情况的考虑,系统中一般都会在这种特殊场景直接暴力拉核,将硬件资源直接拉到最高去运行,比如 CPU、GPU、IO、BUS 等;另外也会在某些场景把某些资源限制使用,比如发热太严重的时候,需要限制 CPU 的最高频率,来达到降温的目的;有时候基于功耗的考虑,也会限制一些资源在某些场景的使用。
目前 Android 系统一般会在下面几个场景直接进行锁频(不同厂家也会自己定制)
- 应用启动
- 应用安装
- 转屏
- 窗口动画
- List Fling
- Game
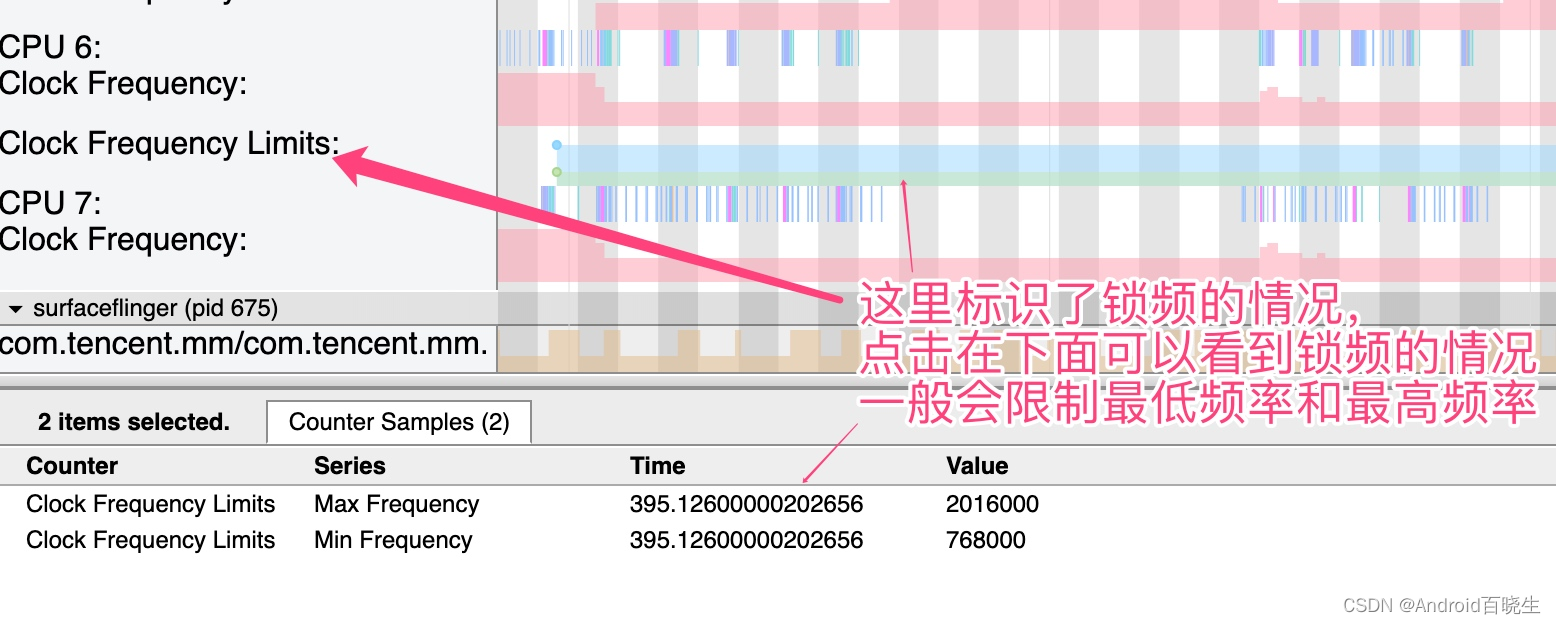
以 高通平台为例,在 Systrace中CPU Info 一项我们也可以看到锁频的情况:
4.CPU状态
CPU 状态有 0 ,1,2,3 这四种,如下图为Systrace中CPU info 标识的 CPU 状态标记:
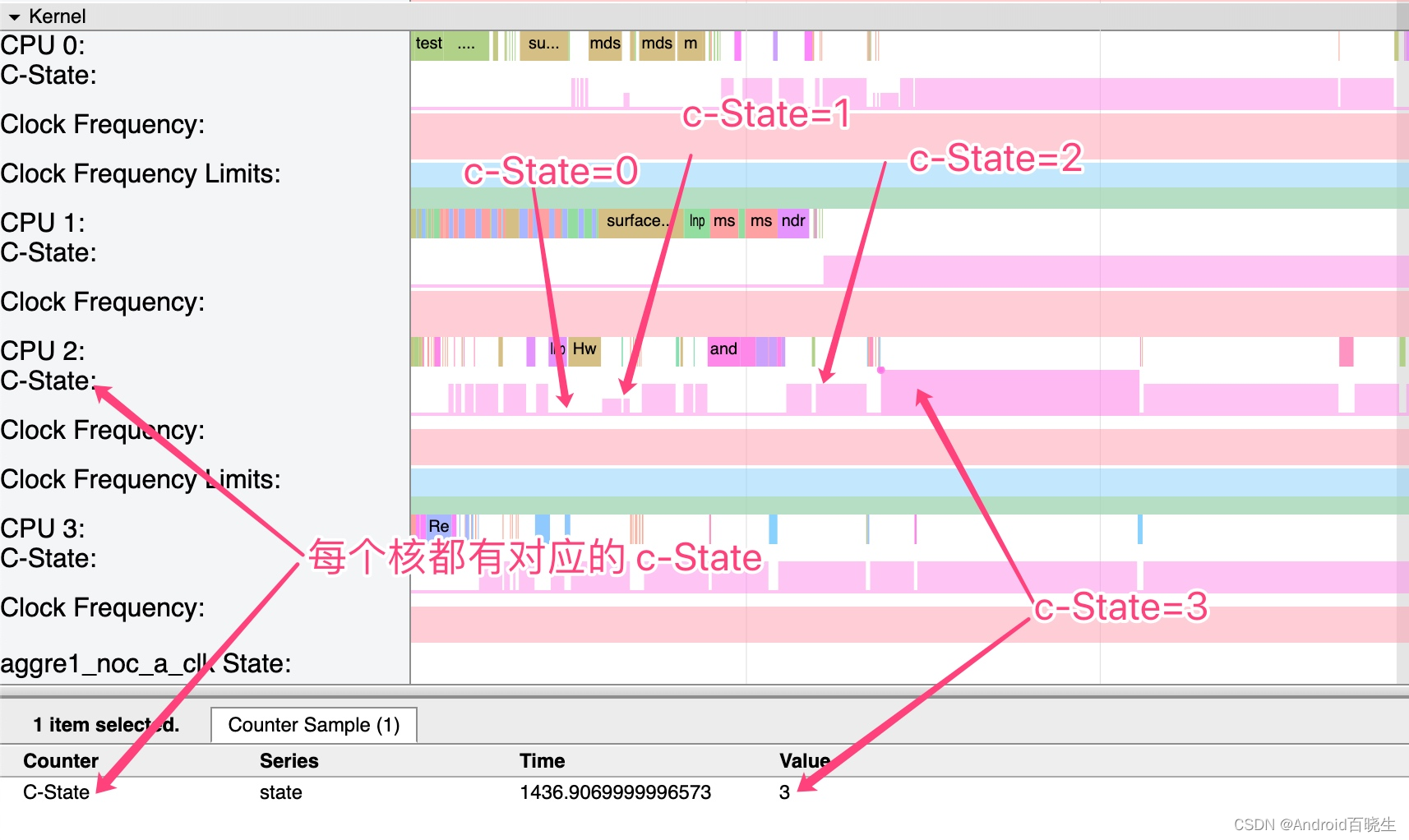
之前的 CPU 支持热插拔,即不用的时候可以直接关闭,不过目前的 CPU 都不支持热插拔,而是使用 C-State
下面是摘抄的其他平台的支持 C0-C4 的处理器的状态和功耗状态,Android 中不同的平台表现不一致,大家可以做一下参考
- C0 状态(激活)
- 这是 CPU 最大工作状态,在此状态下可以接收指令和处理数据
- 所有现代处理器必须支持这一功耗状态
- C1 状态(挂起)
- 可以通过执行汇编指令“ HLT (挂起)”进入这一状态
- 唤醒时间超快!(快到只需 10 纳秒!)
- 可以节省 70% 的 CPU 功耗
- 所有现代处理器都必须支持这一功耗状态
- C2 状态(停止允许)
- 处理器时钟频率和 I/O 缓冲被停止
- 换言之,处理器执行引擎和 I/0 缓冲已经没有时钟频率
- 在 C2 状态下也可以节约 70% 的 CPU 和平台能耗
- 从 C2 切换到 C0 状态需要 100 纳秒以上
- C3 状态(深度睡眠)
- 总线频率和 PLL 均被锁定
- 在多核心系统下,缓存无效
- 在单核心系统下,内存被关闭,但缓存仍有效可以节省 70% 的 CPU 功耗,但平台功耗比 C2 状态下大一些
唤醒时间需要 50 微妙
二、线程状态
1.Runnable 状态说明
Runnable 是指在 CPU 核上的排队耗时,按常识可可知道排队长、频繁排队时出问题概率也就越高。一个绘制任务所依赖的线程数量越多,出问题的概率也越高,因为排队次数变多了嘛。
Linux 内核是通过赋予不同线程执行时间片并通过轮转的方式来达到同时执行多个线程的效果,因此当一个 Running 中的线程的时间片用完时(通常是 ms 级别)将此线程置为 Runnable,等待下一次被调度。也有比较特殊的情况,那就是抢占。有些高优先级的线程可以抢占当前执行的线程,而不必等到此线程的时间片到期。
Android中一帧绘制是经过 UI Thread → Render Thread → SurfaceFlinger → HWC(参考 下图),其中任何一个线程被 Runnable 阻塞导致没有在规定时间内完成渲染任务,都将会导致界面的卡顿(也就是掉帧)
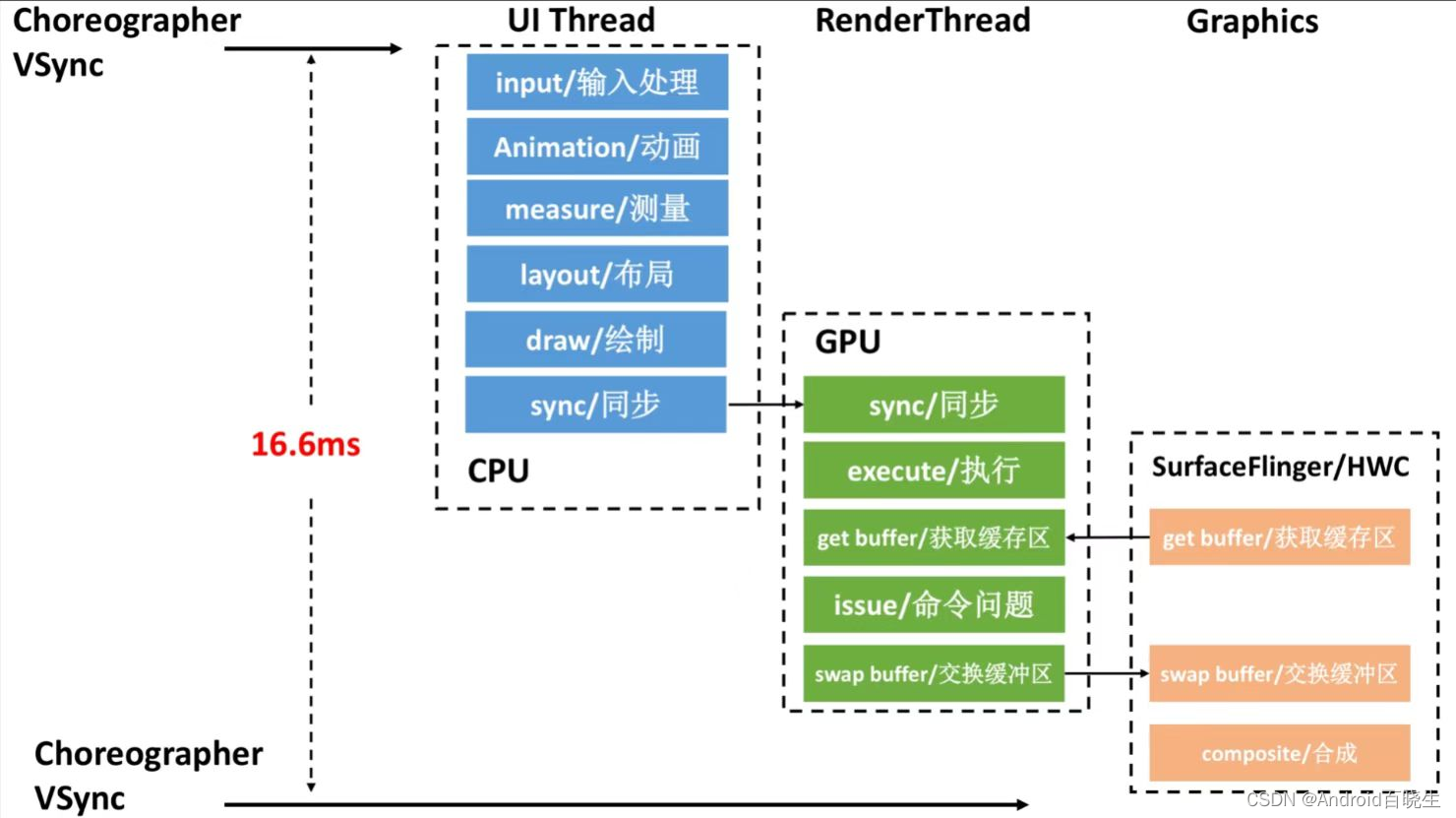
Runnable 过长的原因和优化思路
我们从实践中总结出以下几大门类,系统层面出异常的原因较多,但也见过应用自身逻辑导致 Runnable 过长情况:
1.优先级设置错误
- 应用设置了过高的优先级:至于抢占了其他线程的任务,对后者来说显得自己优先级太低了。
- 应用设置了过低的优先级:当此线程处于「关键链路」时,以 Runnable 执行的概率就越高,导致卡顿概率也高。
- 系统出 Bug 时把线程优先级设为过高或者过低。
优化思路:
- 应用视情况调整线程优先级,可从 Trace 中可以看到是被哪个线程抢占了。
- 系统将关键线程调度策略设置成 FIFO。
我们在实践中见到过不少应用因为设置错了优先级反而导致更卡。原因比较复杂,可能开发者所使用的机器用当时的优先级策略没问题,但是在别的厂商的调度器(头部大厂基本都有自己改动调度器)下就会出现水土不兼容的情况。一般情况下,三方应用开发者不建议直接调用这类 API,弄巧成拙,屡见不鲜。
长远看来更靠谱的方式是合理安排自己的任务模型,不要把对实时性要求很高的任务放到 worker 线程上。
2.绑核不合理
有时候为了让线程运行得更快,会把线程绑定到大核,在前面解决 Running 时间长时也有建议绑大核,但是绑核一定要谨慎,因为一旦把线程绑定在某个核,表示线程只能运行在这个核上即使其它核很空闲。如果多个线程都绑定在某个核,当这个核很繁忙调度不过来时,这些线程就会出现 Runnable 时间很长的情况。所以绑核一定要谨慎!下面是绑核需要注意的一些事项:
- 线程绑核不要绑定在单个核上,这样容错率会特别低,因为一旦这个核被其它线程抢占绑定这个核的线程就要等着,所以尽量以 CPU 簇为单位进行绑核,比如线程要绑定大核,可以指定 4-7 大核而不是指定某个一大核。
- 2 个大核平台尽可能减少绑定大的核线程数目,不然会使得大核很容易繁忙,把绑核会变成「负优化」。
- 要正确区分大小核,比如 8 个核的平台,4-7 不一定就是大核,有的平台可能 0-3 才是大核。
- 只能在 CPUSET 允许范围内绑核,如果 CPUSET 只允许进程跑 0-3,如果进程试图绑定在 4-7 会绑核失败,甚至会有一些意料之外的致命错误。
3.软件架构设计不合理
重申下,Runnable 是指在 CPU 核上的排队耗时,按常识可可知道排队长、频繁排队时出问题概率也就越高。一个绘制任务所依赖的线程数量越多,出问题的概率也越高,因为排队次数变多了嘛。
软件架构不止要满足业务需求,也要在性能、扩展性方面上做思考,从上面推导可知,如果你程序编程模型需要大量线程协同运行来完成关键操作,如绘制,那出问题的概率就越高。
最常见的有,两个线程之间有频繁的有通讯与等待(线程 A 把任务转移到线程 B 执行,A 等待 B 任务执行完后被唤醒), CPU 繁忙时很容易打出 Runnable 等待状态,CPU 越忙概率越高。
优化思路:
- 应用调整线程优先级,见「原因 1」。
- 优化代码架构/逻辑,免频繁等待其他线程的唤醒,在 Trace 中可以看到线程的依赖关系。可借助 CPU Profiler 探查代码执行逻辑,提高分析唤醒关系的效率。
- 平台通过修改调度器来识别有关系链的线程组,优先调度这个组里的线程。
4.应用自己或系统整体负载高导致排队的任务非常多
如果大量任务挤在一个核的「可执行队列」上,显然越是后面,优先级越低的任务排队时间就越长。
排查的时候你可以在 Perfetto/Systrace 的 CPU 核维度任务上,即使在放大后的界面看到排满了密密麻麻的任务,这基本上就意味着系统整体负载较高了。通过计算,可算出 CPU 每时刻的使用量,基本上都会在 90%以上。 你可以通过选择一个区间,以时间来排序,看看都在执行什么任务,以此来逐个排查同时执行大量程序的原因是什么。
简单总结就是,同时执行的任务太多了,主要原因来自两方面:
1.应用自身高占用
应用自身就把 CPU 资源都给占满了,狂开十来个线程来做事情,即使是头部大厂也会做这种事。
优化建议:
- 找出应用所有占用高的线程,看看各线程此刻跑起来的行为是否异常,如果异常则要优化它。
- 优化线程负载本身,可使用 simpleperf 等工具进行函数级别的定位。
- 调整优先级,使用比 CFS 更高优先级的调度器,如设置为 RT。不过它带来的隐患也较多,需要慎重。
- 优化软件架构,区分关键与非关键线程,通过合理设置「绑核 & 优先级」来为关键线程让出资源。 如,不重要线程绑到小核运行或设置低优先级、渲染相关线程设置高优先级等,让渲染线程相关的线程能占用到更多的 CPU 资源。设计架构的时候一定要考虑运行环境恶劣的情况,因为安卓从设计上就不敢保证所有资源都优先供给你,肯定有别人跟你抢资源。
2.系统服务高占用
有的厂商 ROM 自己本身就有很多任务,设计不合理的话自己家程序就吃满了大量资源,导致留给应用运行的资源较少。还有些是管控措施设计的一般,以至于留给了大量流氓应用可乘之机,各路神仙利用自己的「黑科技」在后台保活后进行各种拉活同步操作。
5.CPU 算力限制、锁频、锁核、状态异常
跟排队做核酸检测一样,检测窗口多的队列排队时间少。CPU 算力差、关核、限频,导致 Runnable 的概率也更高。通常的原因有:
- 场景控制
- 不同场景模式下的不同频率、核心策略
- 高温下的锁频锁核
- CPU 省电模式:如高通的 Low Power Mode。
- CPU 状态切换:如 C2/C1 切换到 C0 耗时久。
- CPU 损坏,概率小但也有可能会出现。
- 低端机 :安卓上的低端机。
其中:
- 原因 1 场景控制, 考验厂家的能力与各自的标准,应用程序能做的还是那句名言 → 降低自己负载,少惹平台。 厂家为了设计好「场景控制」,需要有精细化的场景识别与合理的控制能力,将功耗与性能的平衡做到全局最优化,不同场景下应突出不同的业务能力,而不是一杆子拍死。
- 高温下的优化建议请参考Running 状态中的「原因 5: 温升导致 CPU 关核、限频」。
- 原因 3 CPU 状态切换 是芯片固有的特性,出现的概率小,但也不是不可能,每个芯片架构升级换代的时候就时不时遇到「妥协」版的 CPU 产品。厂家对芯片的评估是个比较隐性的能力,很少会被大众提及,但是非常重要的一个能力。电子消费品历史中,也总是重演关键器件选错了,导致厂家走入万劫不复境地的真实案例。
- 原因 5,安卓上的低端机,真的就指配备里低算力的 CPU,这与苹果的做法不一样,它的 CPU 至少跟当期旗舰是一样的。同样参考 Running状态中的「原因 6: 算力弱」。
6.调度器异常
几乎所有的厂家都做了调度器优化方面的工作,虽然概率小,但也有可能会出异常。场景锁频锁核机制有问题、内核各种 governor 的出问题的时候,会出现明明 CPU 的其他核都很闲,但任务都挤在某几个核上。
系统开发者能做的就是把基础「可观测性技术」建好,出问题时可以快速诊断,因为这类问题一是不好复现,二是现象出现时机较短,可能立马就恢复了。
2.Running 状态说明
Running 时间长主要有以下几方面原因:
1.代码本身复杂度高,执行耗时久
这是最常见的一种方式,当然不排除平台有bug,有时候厂商在libc、syscal等高频核心函数,加了一些逻辑导致了代码运行时间长。
优化建议: 优化逻辑、算法,降低复杂度。为了进一步判断具体是哪个函数耗时,可使用 AS CPU Profiler、simpleperf,或者自己通过 Trace.begin/end() API 添加更多 tracepoint 点
当然不排除有的时候平台有bug,在关键的libc或内核函数加了一些逻辑
2.代码以解释方式执行
使用了编程语言的某种特性,如频繁的调用 JNI,反复性反射调用。除了通过积攒经验方式之外,通过工具解决的方法就是通过 CPU Profiler、simpleperf 等工具进行诊断
3.线程跑小核,导致执行时间长
对 CPU Bound 的操作来说跑在小核可能没法满足性能需求,因为小核的定位是处理非UX 强相关的线程。不过 Android 没办法保证这一点,有时候任务就是会安排在小核上执行。
优化建议:线程绑核、SchedBoost 等操作,让线程跑尽量跑更高算力的核上,比如大核。有时候即使迁核了也不见效,这时候要看看频率是否拉得足够高,见“原因 4”
4.线程所跑的大核运行频率太低
优化建议:
- 优化代码逻辑,主动降低运行负载,CPU 频率低也能流畅运行
- 修改调度器升频相关的参数,让 CPU 根据负载提频更激进
- 用平台提供的接口锁定 CPU 频率(俗称的「锁频」)
5.温升导致 CPU 关核、限频
优化建议:
手机因结构原因导致散热能力差或温升参数过于激进时,为了保护体验跟不烫伤人,几乎所有手机厂家的系统会限制 CPU 频率或者直接关核。排查思路是首先需要找到触发温升的原因。
温升的排查的第一步,首先要看是外因导致还是内因导致。外因是指是否由外部高温导致,如太阳底下,火炉边;往往夏天的时候导致手机发热的情况越严重
内因主要由 CPU、Modem、相机模组或者其他发热比较厉害的器件导致的。以 CPU 为例,如果后台某个线程吃满 CPU,那就首先要解决它。如果是前台应用负载高导致大电流消耗,同样道理,那就降低前台本身的负载。其他器件也是同样道理,首先要看是否是无意义的运行,其次是优化业务逻辑本身
除此之外,温升参数过于激进的话导致触发限频关核的概率也会提高,因此通过与竞品对比等方式调优温升参数本身来达到优化目的
6.CPU 算力弱
优化建议:
ARM 处理器在相同频率下不同微架构的配置导致的性能差异是非常明显的,不同运行频率、L1/L2 Cache 的容量均能影响 CPU 的 MIPS(Million Instructions Per Second) 执行结果。
优化思路有两条:
- 编译器参数
- 优化代码逻辑
第一条比较难,大部分应用开发者来说也不太现实,系统厂商如华为,方舟编译器优化 JNI 的思路本质是不改应用代码情况下提高代码执行效率来达到性能上的提升
第二条可以通过 simpleperf 等工具,找到热点代码或者观察 CPU 行为后做进一步的改善,如:
- Cache miss 率过高导致执行耗时,就要优化内存访问相关逻辑
- 代码复杂指令过多导致耗时,就要优化代码逻辑,降低代码复杂度
- 设计好业务缓存,尽量提高缓存命中率,避免抖动(反复地申请与释放)
3.Sleep状态说明
一个线程的状态不属于 Running 或者 Runnable 的时候,那就是 Sleep 状态了(严谨来说,还有其他状态,不过对性能分析来说不常见)
Sleep状态本质上是处于睡眠状态,拿不到 CPU的时间片,只有满足某些条件时才会拿到时间片,即变为 Runnable,随后是 Running。
Sleep状态常见有如下几种场景。
耗时过长的常见原因
- Binder 操作 → 通过打开 Binder 对应的 trace,可方便地观察到调用到远端的 Binder 执行线程。如果 Binder 耗时长,要分析远端的 Binder 执行情况,是否是锁竞争?得不到CPU 时间片?要具体问题具体分析
- Java\futex锁竞争等待 → 最常见也是最容易引起性能问题,当负载较高时候特别容易出现,特别是在 SystemServer 进程中。这是 Binder 多线程并行化或抢占公共资源导致的弊端。
- 主动等待 → 线程主动进入 Sleep 状态,等待其它线程的唤醒,比如等待信号量的释放。优化建议:需要看代码逻辑分析等待是否合理,不合理就要优化掉。
- 等待 GPU 执行完毕 → 等 GPU 任务执行完毕,Trace 中可以看到等 GPU fence 时间。常见的原因有渲染任务过重、 GPU 能力弱、GPU 频率低等。优化建议:提升 GPU 频率、降低渲染任务复杂度,比如精简 Shader、降低渲染分辨率、降低Texture 画质等。
IOWait 常见原因与优化方法
IOWait:IO 等待,就是程序执行了 IO 操作。
最简单的,程序如果没法从 PageCache 缓存里快速拿到数据,那就要与设备进行 IO 操作。CPU 内部缓存的访问速度是最快的,其次是内存,最后是磁盘。它们之间的延迟差异是数量级差异,因此系统越是从磁盘中读取数据,对整体性能的影响就越大。
1.主动IO 操作
- 程序进行频繁、大量的读或者写 IO 操作,这是最常见的情况。
- 多个应用同时下发 IO 操作,导致器件的压力较大。同时执行的程序多的时候 IO 负载高的可能性也大。
- 器件本身的 IO 性能较差,可通过 IO Benchmark 来进行排查。 常见的原因有磁盘碎片化、器件老化、剩余空间较少(越是低端机越明显)、读放大、写放大等等。
- 文件系统特性,比如有些文件系统的内部操作会表现为 IO 等待。
- 开启 Swap 机制的内核下,数据从 Swap 中读取。
优化方法
- 调优 Readahead 机制
- 指定文件到 PageCache,即 PinFile 机制
- 调整 PageCache 回收策略
- 调优清理垃圾文件策略
2.低内存导致的 IO 变多
内存是个非常有意思的东西,由于它的速度比磁盘快,因此 OS 设计者们把内存当做磁盘的缓存,通过它来避免了部分IO操作的请求,非常有效的提升了整体 IO 性能。有两个极端情况,当系统内存特别大的时候,绝大部分操作都可以在内存中执行,此时整体 IO 性能会非常好。当系统内存特别低,以至于没办法缓存 IO 数据的时候,几乎所有的 IO 操作都直接与器件打交道,这时候整体性能相比内存多的时候而言是非常差的。
所以系统中的内存较少的时候 IO 等待的概率也会变高。所以,这个问题就变成了如何让系统中有足够多的内存?如何调节磁盘缓存的淘汰算法?
优化方法
- 关键路径上减少 IO 操作
- 通过Readahead 机制读数据
- 将热点数据尽量聚集在一起,使被 Readahead 机制命中的概率高
- 最后一个老生常谈的,减少大量的内存分配、内存浪费等操作
系统中的内存是被各个进程所共用。当app 只考虑自己,肆无忌惮的使用计算资源,必然会影响到其他程序。这时候系统还是会回来压制你,到头来亏损的还是自己。 不过能想到这一步的开发者比较少,也不现实。明文化的执行系统约定,可能是个终极解决方案。
Non-IOWait 常见原因
Non-IOWait:非 IO 等待。
非 IO 等待主要是指内核级别的锁等待,或者驱动程序中人为设置的等待。Linux 内核中某些路径是热点区域,因此不得不拿锁来进行保护。比如Binder 驱动,当负载大到一定程度,Binder 的内部的锁竞争导致的性能瓶颈就会呈现出来。
- 低内存导致等待 → 低内存的时候要回收其他程序或者缓存上的内存。
- Binder 等待 → 有大量 Binder 操作的时候出现概率较高。
- 各种各样的内核锁,不胜枚举。
优化方法
- 内存优化,解决内存泄漏,以及减少大对象的内存占用。
- 减少Binder调用频率,可通过变量进行缓存,实现复用(空间换时间)。
- 1)去除非必要锁;2)锁降级,轻量级锁替代重量级锁;3)锁颗粒度优化,减少锁作用范围;
总结
致谢:
线程 CPU 运行状态分析技巧 - Runnable 篇
线程 CPU 运行状态分析技巧 - Running 篇
CPU 运行状态分析技巧 - Sleep 和 Uninterruptible Sleep 篇
Android Systrace 基础知识 - CPU Info 解读