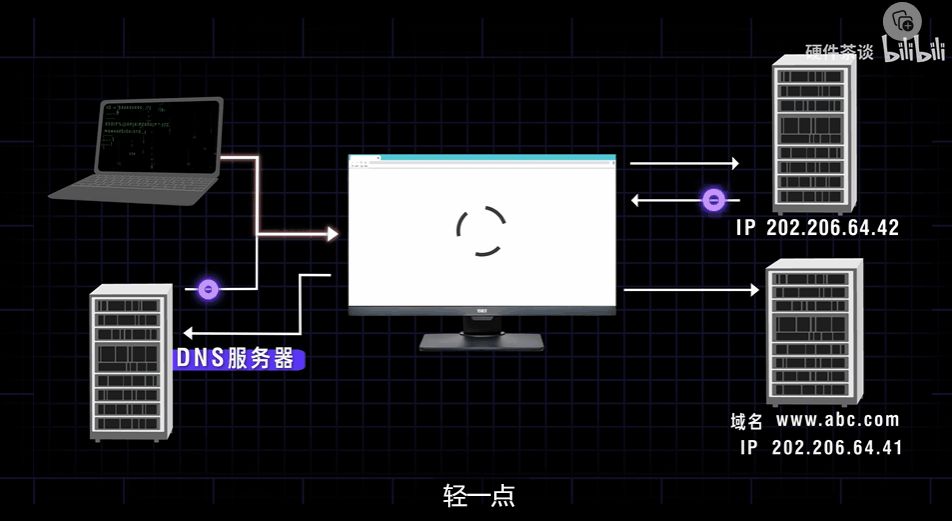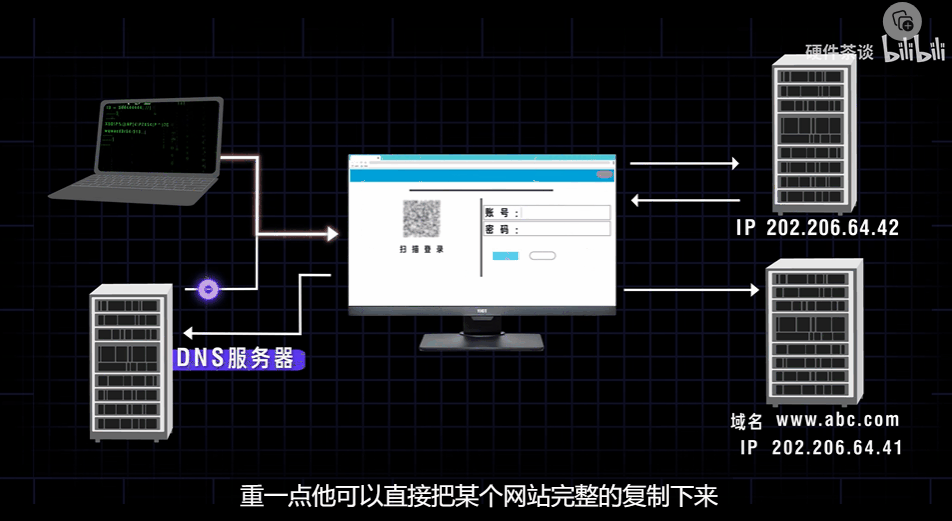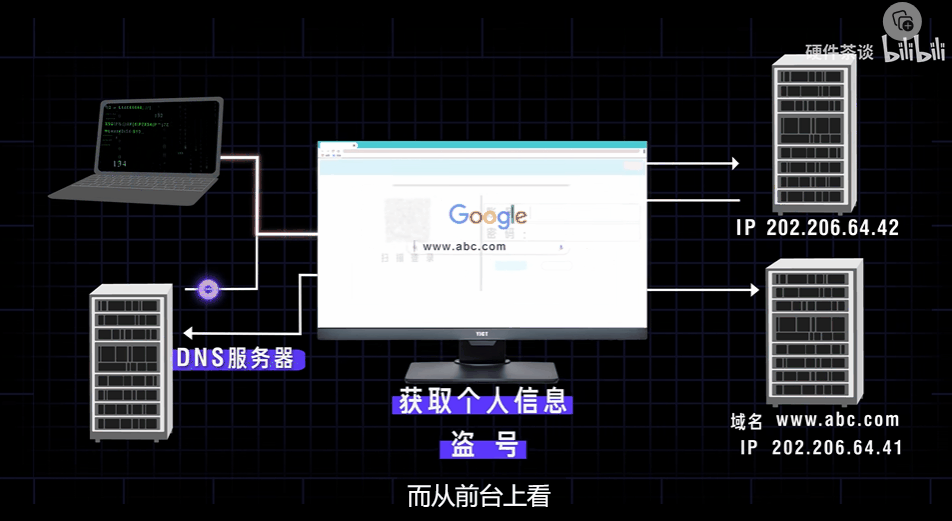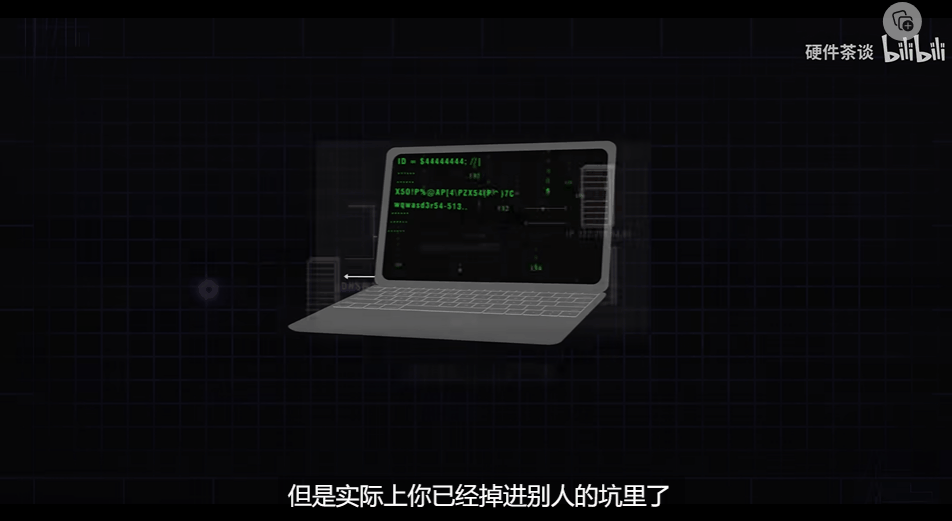
1 网页的构成
一般来说,日常看到的网站的网页的组成内容有如下
- html 结构的代码
- css 结构的代码
- 资源(文字,图片,音乐,视频等等)
html 网页结构描述的语言
比如这种写法的文件
<html>
<body>
</body>
</html>
CSS,外部格式
比如这种写法的文件 <head> <link rel="stylesheet" type="text/css" href="mystyle.css"> </head>
2 传输协议
![]()
- http:超文本传输协议
- https:即带有安全套接字层的超本文传输协,
- 超文本:是指超过文本,不仅限于文本;还包括图片、音频、视频等文件
- 传输协议:是指使用约定的格式来传递信息,转换成字符串的超文本内容
- https:HTTP + SSL(安全套接字层)
- SSL对传输的内容(超文本,也就是请求体或响应体)进行加密
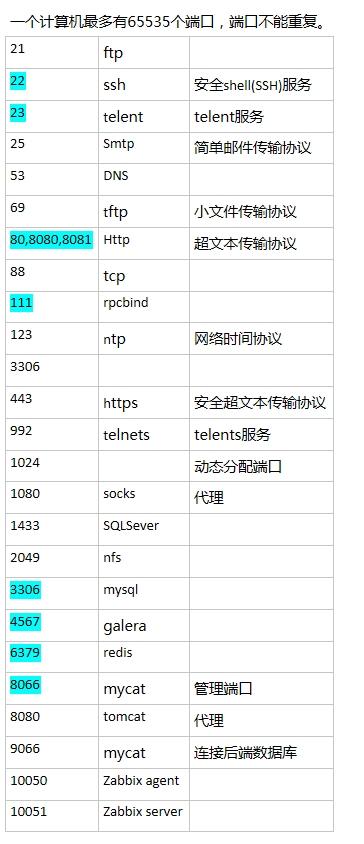
3 端口号
- HTTP: 默认端口号: 80
- HTTPS:默认端口号: 443
- 站点A-------协议名:端口号----------站点B
- 其中 http的80 和 https 的443 可以缺省不写
- 但是如果http里用8080 就必须带上 :8080
- 8080 还经常用于代理proxy
4 网页返回的状态码
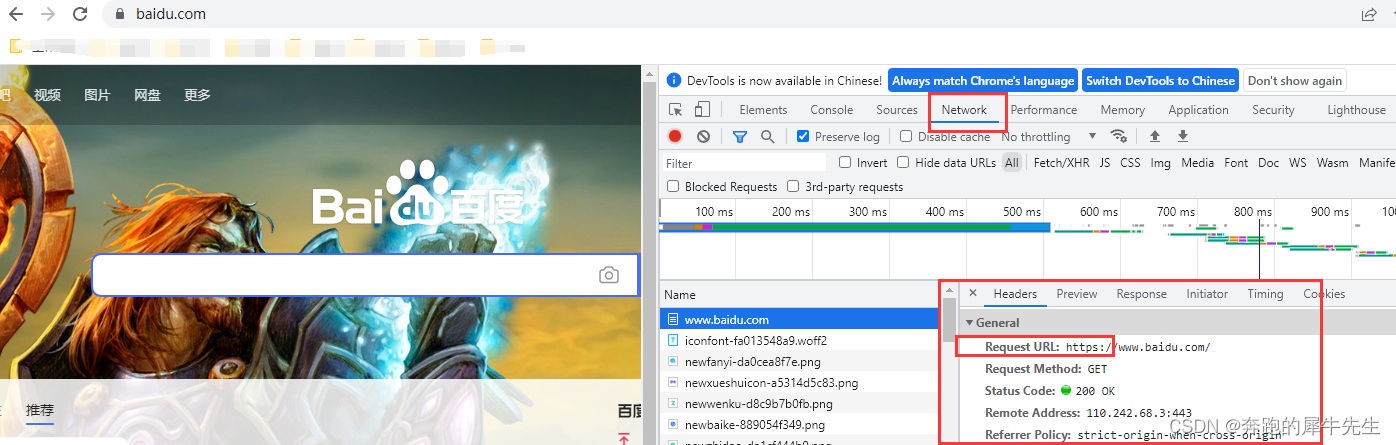
- 比如上面得到的 Status Code:200 OK
- 而且这些可以作假,网页服务器端可以故意欺骗爬虫,正确的时候给你返回404,错误的时候给你返回200
| 200 | 成功 |
| 302 | 跳转,新的url在响应的Location头中给出 |
| 303 | 浏览器对于POST的响应进行重定向至新的url |
| 307 | 浏览器对于GET的响应重定向至新的url |
| 403 | 资源不可用;服务器理解客户的请求,但拒绝处理它(没有权限) |
| 404 | 找不到该页面 |
| 500 | 服务器内部错误 |
| 503 | 服务器由于维护或者负载过重未能应答,在响应中可能可能会携带Retry-After响应头;有可能是因为爬虫频繁访问url,使服务器忽视爬虫的请求,最终返回503响应状态码 |
| 403 | 资源不可用;服务器理解客户的请求,但拒绝处理它(没有权限) |
5 爬虫和客户端网页的差别
- 客户端无论是pc 还是 phone ,客户端一般展示位一个网页
- 而网页里,会综合展示 html, css,资源等等,综合处理效果
- 而爬虫只是模仿 客户端,一般只一次次的进行求和和响应的解析,不综合处理最后效果,
6 这些网页知识(待学习)
Content-Type
Host (主机和端口号)
Connection (链接类型)
Upgrade-Insecure-Requests (升级为HTTPS请求)
User-Agent (浏览器名称)
Referer (页面跳转处)
Cookie (Cookie)
Authorization(用于表示HTTP协议中需要认证资源的认证信息,如前边web课程中用于jwt认证)
加粗的请求头为常用请求头,在服务器被用来进行爬虫识别的频率最高,相较于其余的请求头更为重要,但是这里需要注意的是并不意味这其余的不重要,因为有的网站的运维或者开发人员可能剑走偏锋,会使用一些比较不常见的请求头来进行爬虫的甄别