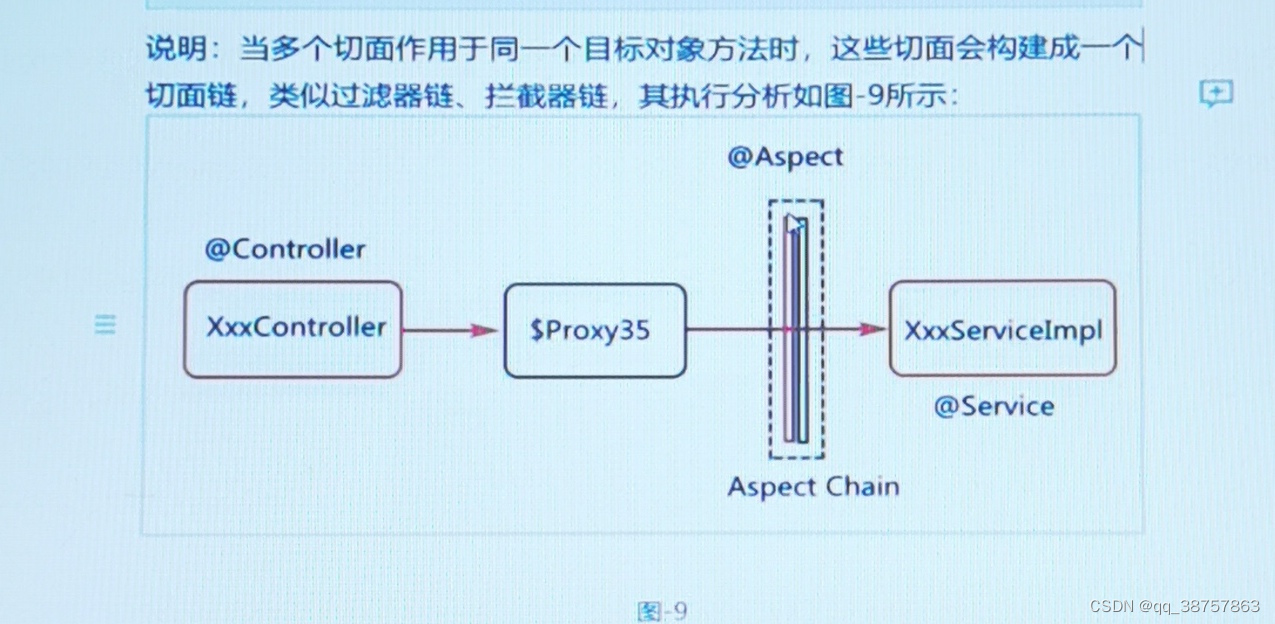
作者:京东零售 刘慧卿
一、数据库发展史
起初,数据的管理方式是文件系统,数据存储在文件中,数据管理和维护都由程序员完成。后来发展出树形结构和网状结构的数据库,但都存在着难以扩展和维护的问题。直到七十年代,关系数据库理论的提出,以表格形式组织数据,数据之间存在关联关系,具有了良好的结构化和规范化特性,成为主流数据库类型。
先来看一张数据库发展史图鉴:

随之高并发大数据时代的来临,数据库按照各种应用场景进行了更细粒度的拆分和演进,数据库细分领域的典型代表:
| 类型 | 产品代表 | 适用场景 |
|---|---|---|
| 层次数据库(NDB) | IMS/IDMS | 以树形结构组织数据,数据之间存在父子关系,查询速度快,但难以扩展和维护 |
| 关系型数据库(RDBMS) | Oracle/MySQL | 事务的一致性需求场景 |
| 键值数据库(KVDB) | Redis/Memcached | 针对高性能并发读写场景 |
| 文档数据库(DDB) | MongoDB/CouchDB | 针对海量复杂数据访问场景 |
| 图数据库(GDB) | Neo4j | 以点、边为基础存储单元,高效存储、查询图数据场景 |
| 时序数据库(TSDB) | InfluxDB/OpenTSDB | 针对时序数据的持久化和多维度的聚合查询等场景 |
| 对象数据库(ODB) | Db4O | 支持完整的面向对象(OO)概念和控制机制,目前使用场景较少 |
| 搜索引擎(SE) | ElasticSearch/Solr | 适合于以搜索为主的业务场景 |
| 列数据库(WCDB) | HBase/ClickHouse | 分布式存储的海量数据存储和查询场景 |
| XML数据库(NXD) | MarkLogic | 支持对XML格式文档进行存储和查询等操作场景 |
| 内容仓库(CDB) | Jackrabbit | 大规模高性能的内容仓库 |
二、数据库名词概念
RDBS
1970年的6月,IBM 公司的研究员埃德加·考特 (Edgar Frank Codd) 发表了那篇著名的《大型共享数据库数据的关系模型》(A Relational Model of Data for Large Shared Data Banks)的论文,拉开了关系型数据库(Relational DataBase Server)软件革命的序幕(之前是层次模型和网状模型数据库为主)。直到现在,关系型数据库在基础软件应用领域仍是最主要的数据存储方式之一。
关系型数据库建立在关系型数据模型的基础上,是借助于集合代数等数学概念和方法来处理数据的数据库。在关系型数据库中,实体以及实体间的联系均由单一的结构类型来表示,这种逻辑结构是一张二维表。关系型数据库以行和列的形式存储数据,这一系列的行和列被称为表,一组表组成了数据库。
NoSQL
NoSQL(Not Only SQL) 数据库也即非关系型数据库,它是在大数据的时代背景下产生的,它可以处理分布式、规模庞大、类型不确定、完整性没有保证的“杂乱”数据,这是传统的关系型数据库远远不能胜任的。NoSQL数据库并没有一个统一的模型,是以牺牲事务机制和强一致性机制,来获取更好的分布式部署和横向扩展能力,使其在不同的应用场景下,对特定业务数据具有更强的处理性能。常用数据模型示例如下:
| 类型 | 产品代表 | 应用场景 | 数据模型 | 优缺点 |
|---|---|---|---|---|
| 键值数据库 | Redis/Memcached | 内容缓存,如会话,配置文件等; 频繁读写,拥有简单数据模型的应用; | 键值对,通过散列表来实现 | 优点: 扩展性和灵活性好,性能高; 缺点: 数据无结构化,只能通过键来查询 |
| 列簇数据库 | HBase/ClickHouse | 分布式数据存储管理 | 以列簇存储,将同一列存在一起 | 优点: 简单,扩展性强,查询速度快 缺点: 功能局限,不支持事务的强一致性 |
| 文档数据库 | MongoDB/CouchDB | Web应用,存储面向文档或半结构化数据 | 键值对,value是JSON结构文档 | 优点: 数据结构灵活 缺点: 缺乏统一查询语法 |
| 图形数据库 | Neo4j/InfoGrid | 社交网络,应用监控,推荐系统等专注构建关系图谱 | 图结构 | 优点: 支持复杂的图形算法 缺点: 复杂性高,支持数据规模有限 |
NewSQL
NewSQL 是一类新的关系型数据库, 是各种新的可扩展和高性能的数据库的简称。它不仅具有 NoSQL 数据库对海量数据的存储管理能力,同时还保留了传统数据库支持的 ACID 和 SQL 特性,典型代表有TiDB和OceanBase。
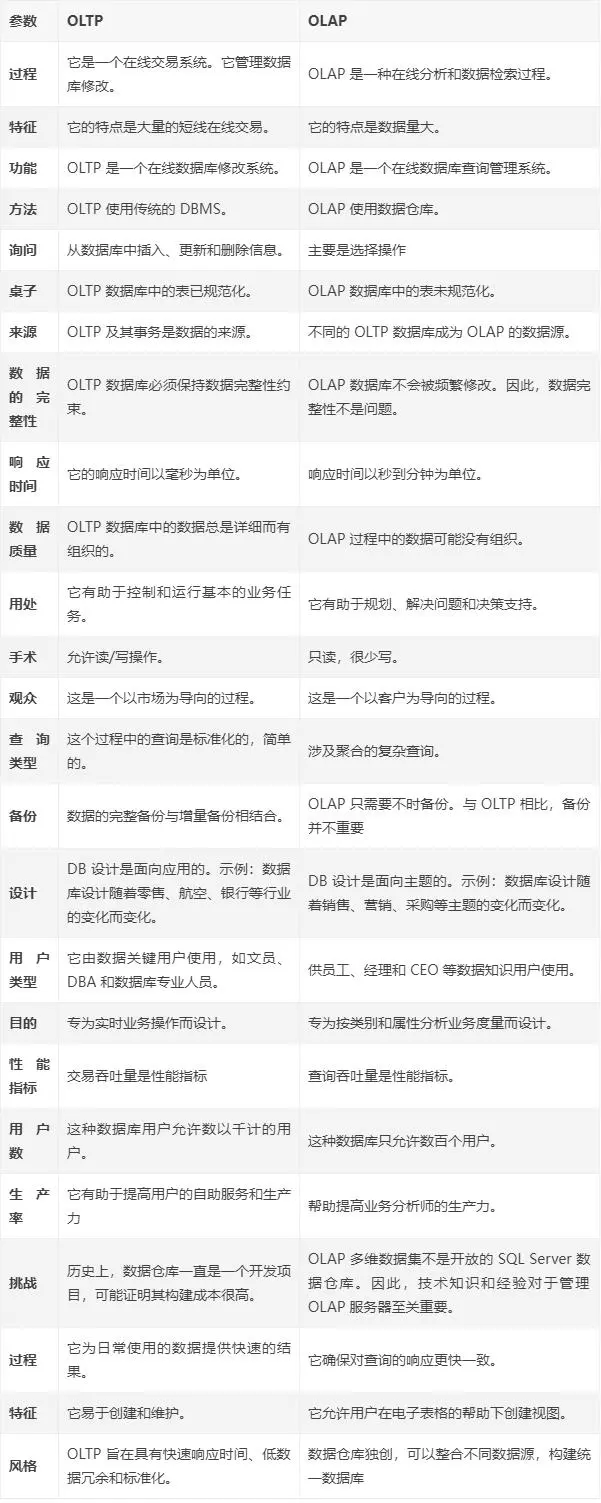
OLTP
联机事务处理过程(On-Line Transaction Processing):也称为面向交易的处理过程,其基本特征是前台接收的用户数据可以立即传送到计算中心进行处理,并在很短的时间内给出处理结果,是对用户操作快速响应的方式之一。
OLAP
联机分析处理(On-Line Analytical Processing)是一种面向数据分析的处理过程,它使分析人员能够迅速、一致、交互地从各个方面观察信息,以达到深入理解数据的目的。它具有FASMI(Fast Analysis of Shared Multidimensional Information),即共享多维信息的快速分析的特征。
关于OLTP和OLAP的区别,借用一张表格对比如下:
HTAP
HTAP (Hybrid Transactional/Analytical Processing) 混合型数据库基于新的计算存储框架,能够同时支撑OLTP和OLAP场景,避免传统架构中大量数据交互造成的资源浪费和冲突。
三、领域数据库
列式数据库
传统的以行形式保存的数据主要满足OLTP应用,列形式保存的数据主要满足以查询为主的OLAP应用。在列式数据库中,数据按列存储,而每个列中的数据类型相同。这种存储方式使列式数据库能够更高效地处理大量的数据,特别是需要进行大规模的数据分析和处理时(如金融、医疗、电信、能源、物流等行业)。
两种存储结构的区别如下图:
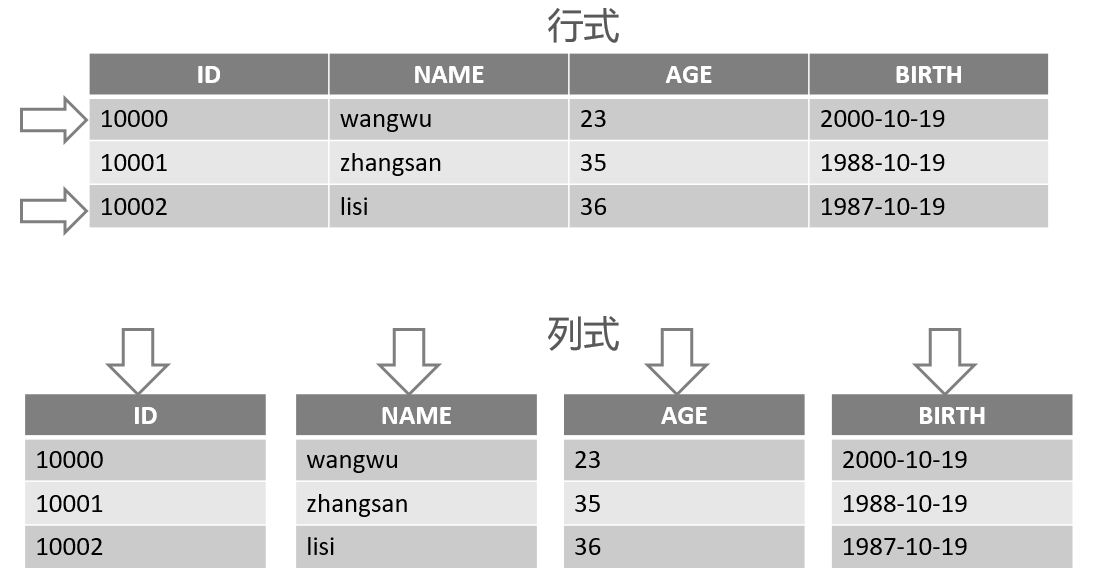
列式数据库的主要优点:
•更高的压缩比率:由于每个列中的数据类型相同,列式数据库可以使用更高效的压缩算法来压缩数据(压缩比可达到5~20倍),从而减少存储空间的使用。
•更快的查询速度:列式数据库可以只读取需要的列,而不需要读取整行数据,从而加快查询速度。
•更好的扩展性:列式数据库可以更容易地进行水平扩展,即增加更多的节点和服务器来处理更大规模的数据。
•更好的数据分析支持:由于列式数据库可以处理大规模的数据,它可以支持更复杂的数据分析和处理操作,例如数据挖掘、机器学习等。
列式数据库的主要缺点:
•更慢的写入速度:由于数据是按列存储,每次写入都需要写入整个列,而不是单个行,因此写入速度可能较慢。
•更复杂的数据模型:由于数据是按列存储,数据模型可能比行式数据库更复杂,需要更多的设计和开发工作。
列式数据库的应用场景:
•金融:金融行业的交易数据和市场数据,例如股票价格、外汇汇率、利率等。列式数据库可以更快速地处理这些数据,并且支持更复杂的数据分析和处理操作,例如风险管理、投资分析等。
•医疗:医疗行业的病历数据、医疗图像和实验数据等。列式数据库可以更高效地存储和处理这些数据,并且支持更复杂的医学研究和分析操作。
•电信:电信行业的用户数据和通信数据,例如电话记录、短信记录、网络流量等。列式数据库可以更快速地处理这些数据,并且支持更复杂的用户行为分析和网络优化操作。
•能源:能源行业的传感器数据、监测数据和生产数据等。列式数据库可以更高效地存储和处理这些数据,并且支持更复杂的能源管理和控制操作。
•物流:物流行业的运输数据、库存数据和订单数据等。列式数据库可以更快速地处理这些数据,并且支持更复杂的物流管理和优化操作。
总之,列式数据库是一种高效处理大规模数据的数据库管理系统,但需要权衡写入速度、数据模型复杂度和成本等因素。 随着传统关系型数据库与新兴的分布式数据库不断的发展,列式存储与行式存储会不断融合,数据库系统呈现双模式数据存放方式。
时序数据库
时序数据库全称为时间序列数据库 ( Time Series Database),用于存储和管理时间序列数据的专业化数据库,是优化用于摄取、处理和存储时间戳数据的数据库。其跟常规的关系数据库SQL相比,最大的区别在于:时序数据库是以时间为索引的规律性时间间隔记录的数据库。
时序数据库在物联网和互联网应用程序监控(APM)等场景应用比较多,以监控数据采集来举例,如果数据监控数据采集时间间隔是1s,那一个监控项每天会产生86400个数据点,若有10000个监控项,则一天就会产生864000000个数据点。在物联网场景下,这个数字会更大,整个数据的规模,是TB甚至是PB级的。
时序数据库发展史:
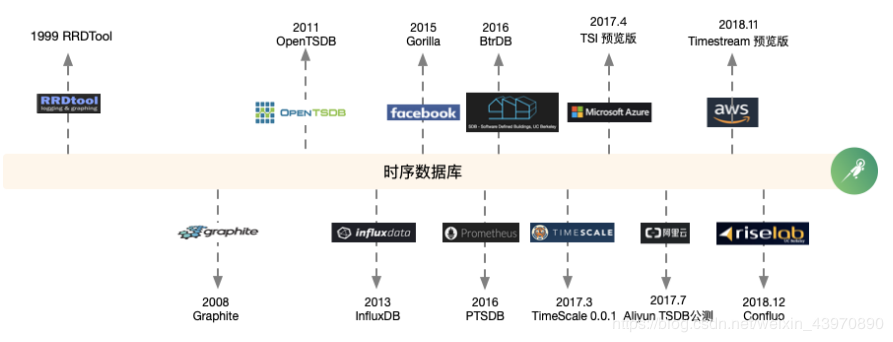
当下最常见的Kubernetes容器管理系统中,通常会搭配普罗米修斯(Prometheus)进行监控,Prometheus就是一套开源的监控&报警&时间序列数据库的组合。
图数据库
图数据库(Graph Database)是基于图论实现的一种新型NoSQL数据库。它的数据存储结构和数据的查询方式都是以图论为基础的。图论中图的基本元素为节点和边,在图数据库中对应的就是节点和关系。
图数据库在反欺诈多维关联分析场景,社交网络图谱,企业关系图谱等场景中可以做一些非常复杂的关系查询。这是由于图数据结构表现的是实体联系本身,它表现了现实世界中事物联系的本质,它的联系在节点创建时就已经建立,所以在查询中能以快捷的路径返回关联数据,从而表现出非常高效的查询性能。
目前市面上较为流行的图数据库产品有以下几种:

与传统的关系数据库相比,图数据库具有以下优点:
1.更快的查询速度:图数据库可以快速遍历图数据,找到节点之间的关联和路径,因此查询速度更快。
2.更好的扩展性:图数据库可以轻松地扩展到大规模的数据集,因为它们可以分布式存储和处理数据。
3.更好的数据可视化:图数据库可以将数据可视化为图形,使用户更容易理解和分析数据。
4.更好的数据一致性:图数据库可以确保数据的一致性,因为它们可以在节点和边之间建立强制性的关系。
四、数据结构设计
前面简单介绍了数据库相关的基础知识,下面再介绍几种我们常见的数据结构设计相关的应用实践:拉链表,位运算和环形队列。
4.1 拉链表
拉链表是一种数据仓库中常用的数据模型,用于记录维度数据的变化历史。我们以一个人员变动的场景举例,假设有一个员工信息表,其中包含了员工的姓名、工号、职位、部门、入职时间等信息。如果需要记录员工的变动情况,就可以使用拉链表来实现。
首先,在员工信息表的基础上新增两个字段:生效时间和失效时间。当员工信息发生变动时,不再新增一条记录,而是修改原有记录的失效时间,同时新增一条新的记录。如下表所示:
| 姓名 | 工号 | 职位 | 部门 | 入职时间 | 生效时间 | 失效时间 |
|---|---|---|---|---|---|---|
| 张三 | 001 | 经理 | 技术 | 2010-01-01 | 2010-01-01 | 2012-12-31 |
| 张三 | 001 | 总监 | 技术 | 2013-01-01 | 2013-01-01 | 2015-12-31 |
| 张三 | 001 | 总经理 | 技术 | 2016-01-01 | 2016-01-01 | 9999-12-31 |
这里的生效时间指的是该记录生效的时间,失效时间指的是该记录失效的时间。例如,张三最初是技术部经理,生效时间为入职时间,失效时间为2012年底,之后晋升为技术部总监,生效时间为2013年初,失效时间为2015年底,最后又晋升为技术部总经理,生效时间为2016年初,失效时间为9999年底。
通过这种方式,可以记录员工变动的历史信息,并能够方便地查询某个时间点的员工信息。例如,如果需要查询张三在2014年的职位和部门信息,只需查询生效时间小于2014年且失效时间大于2014年的记录即可。
拉链表通常包括以下几个字段:
1.主键:唯一标识每个记录的字段,通常是一个或多个列的组合。
2.生效时间:记录的生效时间,即该记录开始生效的时间。
3.失效时间:记录的失效时间,即该记录失效的时间。
4.版本号:记录的版本号,用于标识该记录的版本。
5.其他维度属性:记录的其他维度属性,如客户名、产品名、员工名等。
当一个记录的维度属性发生变化时,不再新增一条记录,而是修改原有记录的失效时间,同时新增一条新的记录。新记录的生效时间为变化的时间,失效时间为9999年底。这样就能够记录每个维度属性的历史变化信息,同时保证查询时能够正确获取某个时间点的维度属性信息。
拉链表与传统的流水表相比,它们的主要区别在于:
1.数据结构不同:流水表是一张只有新增和更新操作的表,每次更新都会新增一条记录,记录中包含了所有的历史信息。而拉链表则是一张有新增、更新和删除操作的表,每个记录都有一个生效时间段和失效时间段,记录的历史信息通过时间段的变化来体现。
2.查询方式不同:流水表的查询方式是基于时间点的查询,即查询某个时间点的记录信息。而拉链表的查询方式是基于时间段的查询,即查询某个时间段内的记录信息。
3.存储空间不同:由于流水表需要记录所有历史信息,所以存储空间相对较大。而拉链表只记录生效时间段和失效时间段,所以存储空间相对较小。
4.数据更新方式不同:流水表只有新增和更新操作,每次更新都会新增一条记录,不会对原有记录进行修改。而拉链表有新增、更新和删除操作,每次更新会修改原有记录的失效时间,同时新增一条新的记录。
4.2 巧用位运算
借助于计算机位运算的特性,可以巧妙的解决某些特定问题,使实现更加优雅,节省存储空间的同时,也可以提高运行效率,典型应用场景:压缩存储、位图索引、数据加密、图形处理和状态判断等,下面介绍几个典型案例。
4.2.1 位运算
•使用位运算实现开关和多选项叠加(资源权限)等应用场景。一个int类型有32个位,理论上可以表示32个开关状态或业务选项;以用户每个月的签到场景举例:用一个int字段来表示用户一个月的签到情况,0表示未签到,1表示签到。想知道某一天是否签到,则只需要判断对应的比特位上是否为1。计算一个月累计签到了多少次,只需要统计有多少个比特位为1就可以了。这种设计巧妙的数据存储结构在后面的位图(BitMap)中,还会进行更为详细的介绍。
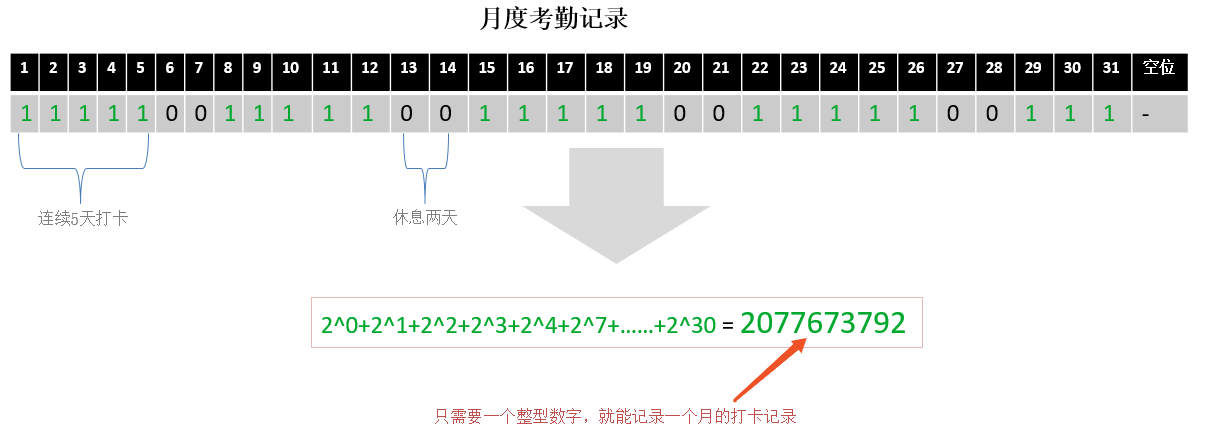
•使用位运算实现业务优先级计算:
public abstract class PriorityManager {
// 定义业务优先级常量
public static final int PRIORITY_LOW = 1; // 二进制:001
public static final int PRIORITY_NORMAL = 2; // 二进制:010
public static final int PRIORITY_HIGH = 4; // 二进制:100
// 定义用户权限常量
public static final int PERMISSION_READ = 1; // 二进制:001
public static final int PERMISSION_WRITE = 2; // 二进制:010
public static final int PERMISSION_DELETE = 4;// 二进制:100
// 定义用户权限和业务优先级的组合值
public static final int PERMISSION_LOW_PRIORITY = PRIORITY_LOW | PERMISSION_READ; // 二进制:001 | 001 = 001
public static final int PERMISSION_NORMAL_PRIORITY = PRIORITY_NORMAL | PERMISSION_READ | PERMISSION_WRITE; // 二进制:010 | 001 | 010 = 011
public static final int PERMISSION_HIGH_PRIORITY = PRIORITY_HIGH | PERMISSION_READ | PERMISSION_WRITE | PERMISSION_DELETE; // 二进制:100 | 001 | 010 | 100 = 111
// 判断用户权限是否满足业务优先级要求
public static boolean checkPermission(int permission, int priority) {
return (permission & priority) == priority;
}
}
•其它使用位运算的典型场景:HashMap中的队列长度的设计和线程池ThreadPoolExcutor中使用AtomicInteger字段ctl,存储当前线程池状态和线程数量(高3位表示当前线程的状态,低29位表示线程的数量)。
4.2.2 BitMap
位图(BitMap)是一种常用的数据结构,在索引,数据压缩等方面有广泛应用。基本思想就是用一个bit位来标记某个元素对应的Value,而Key即是该元素。由于采用了Bit为单位来存储数据,因此可以大大节省存储空间,是少有的既能保证存储空间又能保证查找速度的数据结构(而不必空间换时间)。
举个例子,假设有这样一个需求:在20亿个随机整数中找出某个数m是否存在其中,并假设32位操作系统,4G内存,在Java中,int占4字节,1字节=8位(1 byte = 8 bit)。
•如果每个数字用int存储,那就是20亿个int,因而占用的空间约为 (2000000000*4/1024/1024/1024)≈7.45G
•如果按位存储就不一样了,20亿个数就是20亿位,占用空间约为 (2000000000/8/1024/1024/1024)≈0.233G
存储空间可以压缩节省31倍!那么它是如何通过二进制位实现数字标记的呢? 其原理是用每个二进制位(下标)表示一个真实数字,0表示不存在,1表示存在,这样我们可以很容易表示{1,2,4,6}这几个数:

计算机内存分配的最小单位是字节,也就是8位,那如果要表示{12,13,15}怎么办呢?可以另申请一个字节b[1]:
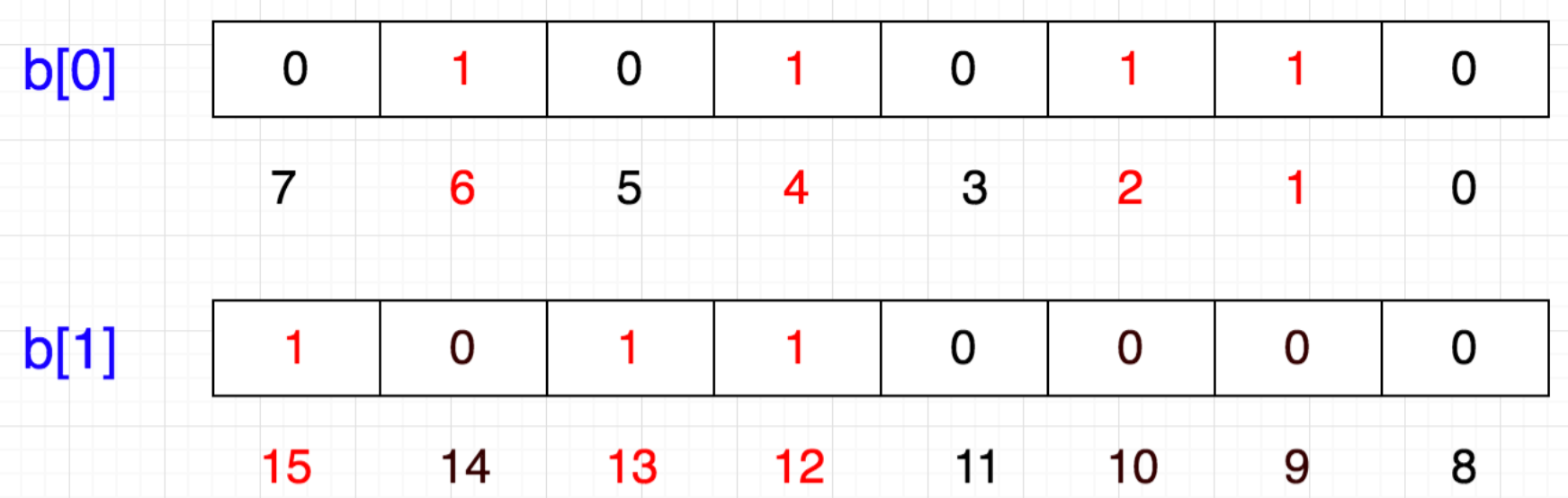
通过一个二维数组来实现位数叠加,1个int占32位,那么我们只需要申请一个int数组长度为 int index[1+N/32] 即可存储,其中N表示要存储的这些数中的最大值:
index[0]:可以表示0~31
index[1]:可以表示32~63
index[2]:可以表示64~95
以此类推…如此一来,给定任意整数M,那么M/32就得到下标,M%32就知道它在此下标的哪个位置。
BitMap数据结构通常用于以下场景:
1.压缩存储大量布尔值:BitMap可以有效地压缩大量的布尔值,从而减少内存的使用;
2.快速判断一个元素是否存在:BitMap可以快速地判断一个元素是否存在,只需要查找对应的位即可;
3.去重:BitMap可以用于去重操作,将元素作为索引,将对应的位设置为1,重复元素只会对应同一个位,从而实现去重;
4.排序:BitMap可以用于排序,将元素作为索引,将对应的位设置为1,然后按照索引顺序遍历位数组,即可得到有序的元素序列;
5.ElasticSearch和Solr等搜索引擎中,在设计搜索剪枝时,需要保存已经搜索过的历史信息,可以使用位图减小历史信息数据所占空间;
4.2.3 布隆过滤器
位图(Bitmap)这种数据存储结构,如果数据量大到一定程度,比如64bit类型的数据,简单算一下存储空间就知道,海量硬件资源要求,已经不太现实了:
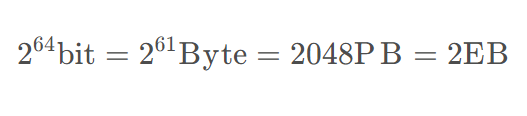
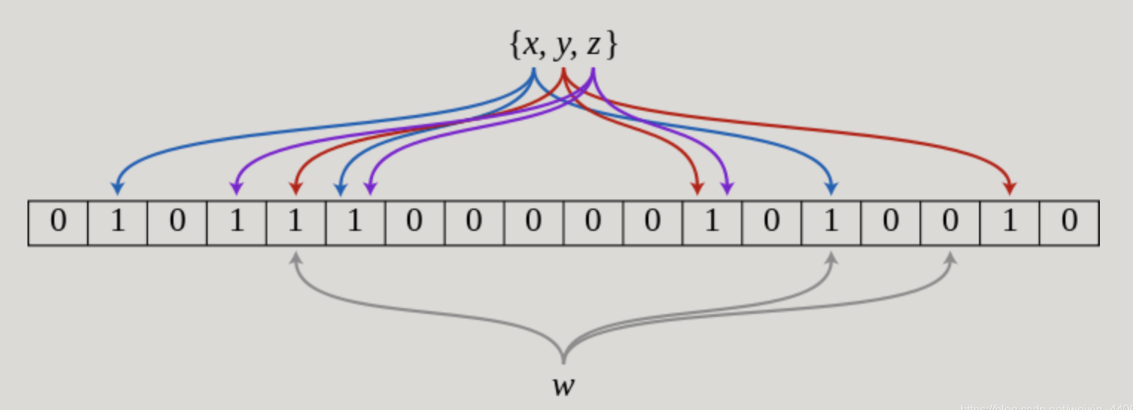
所以另一个著名的工业实现——布隆过滤器(Bloom Filter) 出现了。如果说BitMap对于每一个可能的整型值,通过直接寻址的方式进行映射,相当于使用了一个哈希函数,那布隆过滤器就是引入了k ( k > 1 )个相互独立的哈希函数,保证在给定的空间和误判率情况下,完成元素判重的过程。下图中是k = 3 时的布隆过滤器:
布隆过滤器的内部依赖于哈希算法,当检测某一条数据是否见过时,有一定概率出现假阳性(False Positive),但一定不会出现假阴性(False Negative)。也就是说,当 布隆过滤器认为一条数据出现过,那么该条数据很可能出现过;但如果布隆过滤器认为一条数据没出现过,那么该条数据一定没出现过。布隆过滤器通过引入一定错误率,使得海量数据判重在可以接受的内存代价中得以实现。
上图中,x,y,z经由哈希函数映射将各自在Bitmap中的3个位置置为1,当w出现时,仅当3个标志位都为1时,才表示w在集合中。图中所示的情况,布隆过滤器将判定w不在集合中。
常见实现
•Java中Guava工具包中实现;
•Redis 4.0开始以插件形式提供布隆过滤器功能;
适用场景
•网页爬虫对URL的去重,避免爬去相同的URL地址,比如Chrome浏览器就是使用了一个布隆过滤器识别恶意链接;
•垃圾邮件过滤,从数十亿个垃圾邮件列表中判断某邮箱是否是杀垃圾邮箱;
•解决数据库缓存击穿,黑客攻击服务器时,会构建大量不存在于缓存中的key向服务器发起请求,在数据量足够大的时候,频繁的数据库查询会导致挂机;
•谷歌Bigtable、Apache HBase、Apache Cassandra和PostgreSQL使用布隆过滤器来减少对不存在的行或列的磁盘查找;
•秒杀系统,查看用户是否重复购买;
4.3 环形队列
环形队列是一种用于表示一个固定尺寸、头尾相连的数据结构,很适合缓存数据流。在通信开发(Socket,TCP/IP,RPC开发),在内核的进程间通信(IPC),视频音频播放等各种场景中,都有其身影。日常开发过程中使用的Dubbo、Netty、Akka、Quartz、ZooKeeper 、Kafka等各种中间件,也都有环形队列的思想。下面介绍两种常用的环形数据结构:Hash环和时间轮。
4.3.1 一致性Hash环
先来看一下,典型Hash算法结构如下:
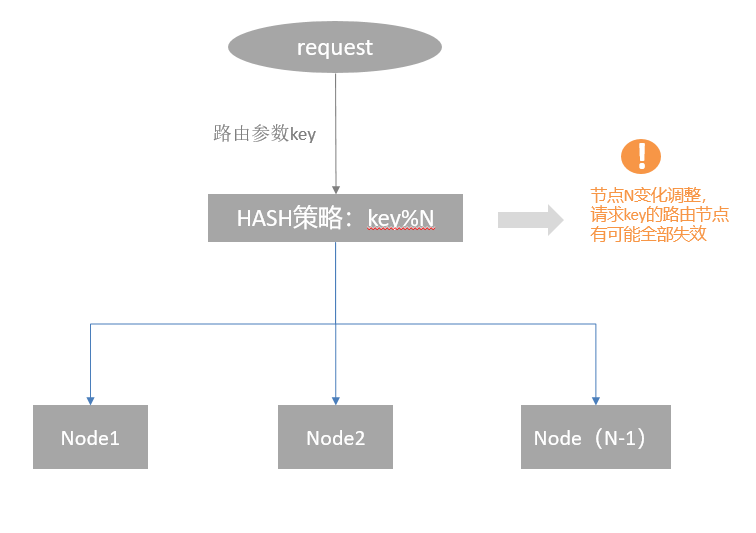
以上图Hash策略为例,当节点数N发生变化的时候 之前所有的 hash映射几乎全部失效,如果集群是无状态的服务,倒是没什么事情,但是如果是分布式缓存这种场景,就会导致比较严重的问题。比如 Key1原本是路由到Node1上,命中缓存的Value1数据。但是当N节点变化后,Key1可能就路由到了Node2节点,这就产生了缓存数据无法命中的问题。而无论是机器故障还是缓存扩容,都会导致节点数的变化。
如何解决上面场景的问题呢?就是接下来介绍的一致性Hash算法。
一致性哈希将整个哈希值空间组织成一个虚拟的圆环,假设某哈希函数H的值空间为0-2^32-1(即哈希值是一个32位无符号整型),所有的输入值都被映射到 0-2^32-1 之间,组成一个圆环。整个哈希空间环如下:
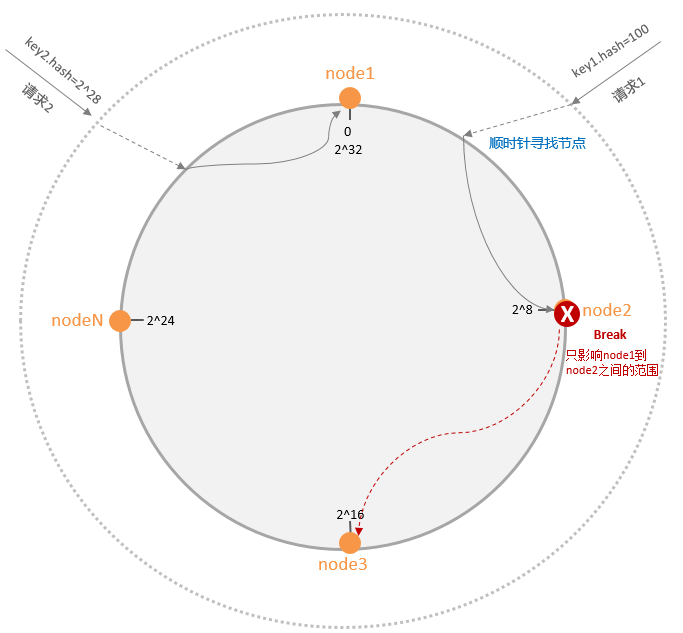
路由数据的过程如下:将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”,遇到的第一个节点就是其应该定位到的服务器。如果某个节点的服务器故障,其影响范围也不再是所有集群,而是限定在故障节点与其上游节点的部分区域。
当某个节点宕机后,原本属于它的请求都会被重新hash映射到下游节点,会突然造成下游节点压力过大有可能也会造成下游节点宕机,从而容易形成雪崩,为此引入了虚拟节点来解决这个问题。
根据Node节点生成很多的虚拟节点分布在圆环上,,一个真实节点映射对应多个虚拟节点。这样当某个节点挂了后原本属于它的请求,会被均衡的分布到其他节点上降低了产生雪崩的情况,也解决了物理节点数少,导致请求分布不均的问题。
带有虚拟节点的Hash环:
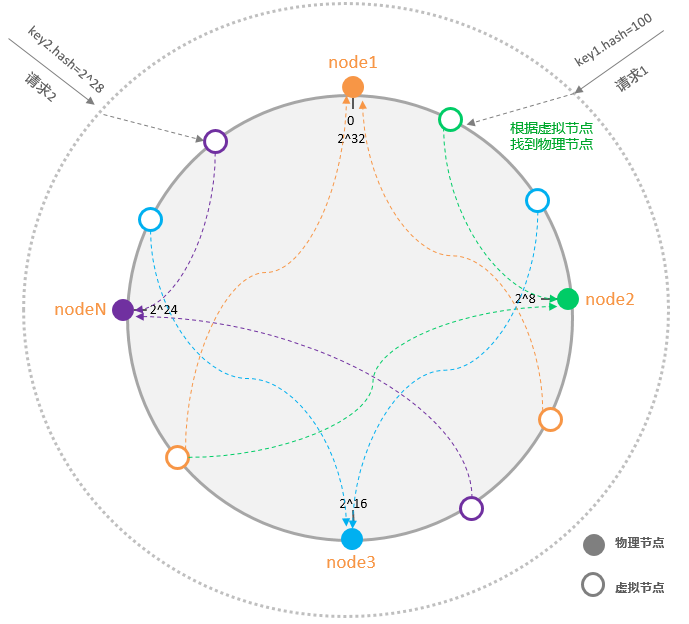
一致性Hash算法由于均衡性,持久性的映射特点被广泛应用于负载均衡领域,比如nginx、dubbo等内部都有一致性hash的实现。
4.3.2 时间轮分片
时间轮(TimeWheel)是一种实现延迟功能(定时器)的精妙的算法,可以实现高效的延时队列。以Kafka中的时间轮实现方案为例,它是一个存储定时任务的环形队列,底层采用数组实现,数组中的每个元素可以存放一个定时任务列表(TimerTaskList)。TimerTaskList是一个环形的双向链表,链表中的每一项表示的都是定时任务项(TimerTaskEntry),其中封装了真正的定时任务TimerTask。
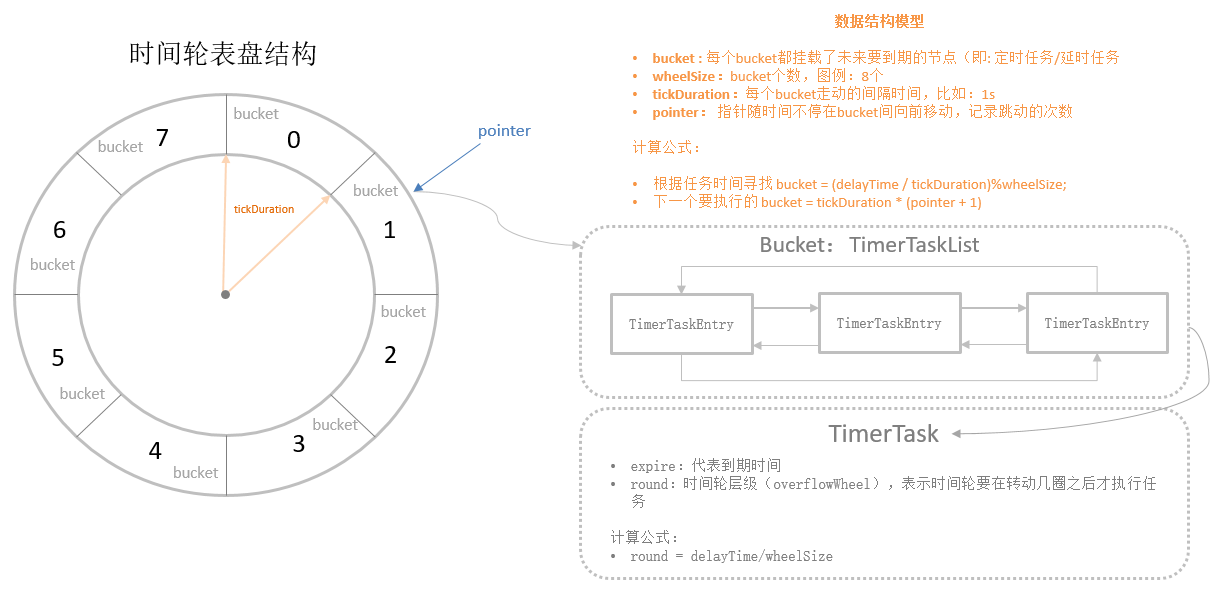
通过上图可以发现,时间轮算法不再任务队列作为数据结构,轮询线程不再负责遍历所有任务,而是仅仅遍历时间刻度。时间轮算法好比指针不断在时钟上旋转、遍历,如果一个发现某一时刻上有任务(任务队列),那么就会将任务队列上的所有任务都执行一遍。
假设相邻bucket到期时间的间隔为bucket=1s,从0s开始计时,1s后到期的定时任务挂在bucket=1下,2s后到期的定时任务挂在bucket=2下,当检查到时间过去了1s时,bucket=1下所有节点执行超时动作,当时间到了2s时,bucket=2下所有节点执行超时动作。时间轮使用一个表盘指针(pointer),用来表示时间轮当前指针跳动的次数,可以用tickDuration * (pointer + 1)来表示下一次到期的任务,需要处理此bucket所对应的 TimeWheel中的所有任务。
时间轮的优点
1.任务的添加与移除,都是O(1)级的复杂度;
2.只需要有一个线程去推进时间轮,不会占用大量的资源;
3.与其他任务调度模式相比,CPU的负载和资源浪费减少;
适用场景
时间轮是为解决高效调度任务而产生的调度模型。在周期性定时任务,延时任务,通知任务等场景都可以发挥效用。
五、总结
本文针对数据存储相关名词概念进行了解释,重点介绍了数据库技术的发展史。为了丰富文章的可读性以及实用性,又从数据结构设计层面进行了部分技术实战能力的外延扩展,阐述了拉链表,位运算,环形队列等相关数据结构在软件开发领域的应用,希望本文给你带来收获。
注:本文个别图片来自互联网