切片与Map
文章目录
- 切片与Map
- 一、切片 Slice
- 1.定义切片
- 2.make 函数创建切片
- 3.切片扩容与遍历
- 4.在已有数组上创建切片
- 5.切片是引用类型
- 7.深拷贝、浅拷贝
- 二、Map
- 1.Map 初始化
- 2.map 的使用
- 3.map 的遍历
- 4.map 结合 slice

一、切片 Slice
1.定义切片
Go 语言切片是对数组的抽象。
Go数组的长度不可改变,在特定场景中这样的集合就不太适用,Go中提供了一种灵活,功能强悍的内置类型切片(“动态数组”),与数组相比切片的长度是不固定的,可以追加元素,在追加时可能使切片的容量增大。
切片是一种方便、灵活且强大的包装器,切片本身没有任何数据,他们只是对现有数组的引用。
切片与数组相比,不需要设定长度,在 [ ] 中不用设定值,相对来说比较自由
从概念上面来说 slice 像一个结构体,这个结构体包含了三个元素:
- 指针:指向数组中 slice 指定的什始位置
- 长度:即slicc的长度
- 最大长度:也就是 slice 刀始位置到数组的最后位置的长度
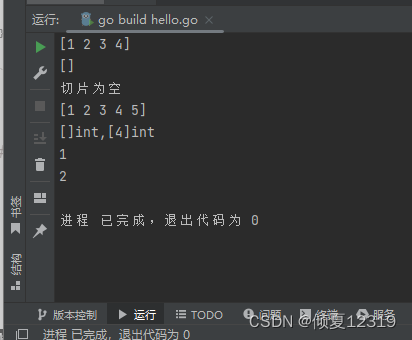
package main
import "fmt"
func main() {
// 数组的长度一旦定义就是不可改变的
arr := [4]int{1, 2, 3, 4}
fmt.Println(arr)
// 定义切片、长度就是可变的
var c1 []int
fmt.Println(c1)
if c1 == nil {
fmt.Println("切片为空")
}
c2 := []int{1, 2, 3, 4, 5}
fmt.Println(c2)
fmt.Printf("%T,%T\n", c1, arr) // []int,[4]int
fmt.Println(c2[0])
fmt.Println(c2[1])
}
2.make 函数创建切片
- 使用 make( ) 函数来创建切片
- make( [ ] T,length,capacity)
- 切片是可索引的,并且可以由 len( ) 方法获取长度。
- 切片提供了计算容量的方法 cap( ) 可以测量切片最长可以达到多少。
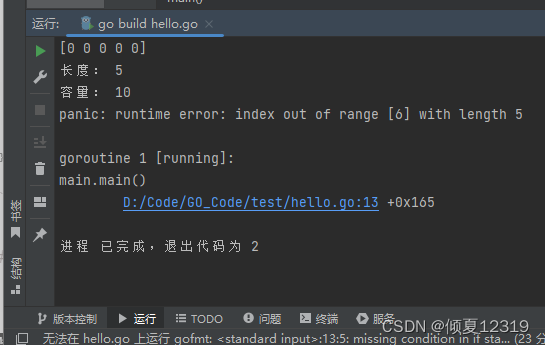
package main
import "fmt"
func main() {
// make( [ ] T,length,capacity)
a1 := make([]int, 5, 10)
fmt.Println(a1)
fmt.Println("长度:", len(a1))
fmt.Println("容量:", cap(a1))
//容量 10 长度5
//虽然容量为10,但是可以进行操作的取决于长度5
a1[1] = 66
a1[6] = 99
fmt.Println(a1)
}
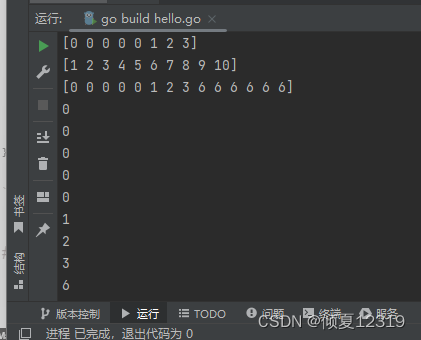
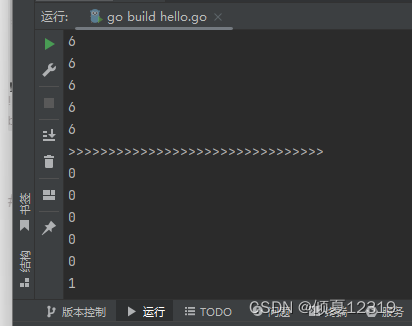
3.切片扩容与遍历
package main
import "fmt"
func main() {
// 扩容
a1 := make([]int, 5, 10)
a1 = append(a1, 1, 2, 3)
fmt.Println(a1)
// 如果切片中的数据超过了规定的容量,那么他就会自动扩容
a2 := make([]int, 0, 5)
a2 = append(a2, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
fmt.Println(a2)
a3 := []int{6, 6, 6, 6, 6, 6}
// 将切片a3追加到切片a1
a1 = append(a1, a3...)
fmt.Println(a1)
for i := 0; i < len(a1); i++ {
fmt.Println(a1[i])
}
fmt.Println(">>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>")
for _, v := range a1 {
fmt.Println(v)
}
}
扩容的内存分析
package main
import "fmt"
func main() {
a1 := []int{1, 2, 3}
fmt.Println(a1)
fmt.Printf("len:%d,cap:%d\n", len(a1), cap(a1)) //len:3,cap:3
fmt.Printf("%p\n", a1)
a1 = append(a1, 4, 5, 6)
fmt.Println(a1)
fmt.Printf("len:%d,cap:%d\n", len(a1), cap(a1)) //len:6,cap:6
fmt.Printf("%p\n", a1)
a1 = append(a1, 7, 8, 9, 10)
fmt.Println(a1)
fmt.Printf("len:%d,cap:%d\n", len(a1), cap(a1)) //len:6,cap:6
fmt.Printf("%p\n", a1)
a1 = append(a1, 10, 11, 12, 13)
fmt.Println(a1)
fmt.Printf("len:%d,cap:%d\n", len(a1), cap(a1)) //len:6,cap:6
fmt.Printf("%p\n", a1)
}
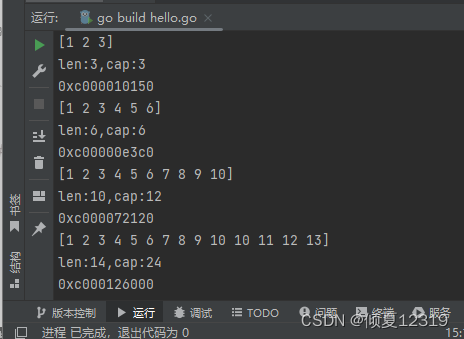
- 每个切片引用了一个底层数组
- 切片本身不存储任何数据,都是这个底层数组存储,所以修改切片也就是修改这个数组中的数据
- 当向切片中添加数据时,如果没有超过容量,直接添加。如果超过了容量,自动扩容,容量成倍增加。
实现原理是使用 Copy 方法
package main
import "fmt"
func main() {
nums := []int{1, 2, 3}
fmt.Printf("len:%d,cap:%d slice=%v\n", len(nums), cap(nums), nums) //len:3,cap:3
/* 创建切片 nums1 是之前切片的两倍容量 */
nums1 := make([]int, len(nums), (len(nums))*2)
/* 拷贝 nums 的内容到 nums1 */
copy(nums1, nums)
fmt.Printf("len:%d,cap:%d slice=%v\n", len(nums1), cap(nums1), nums1)
}

- 切片一旦扩容,就重新指向一个新的底层数组
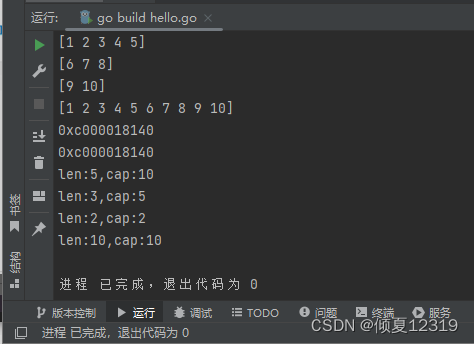
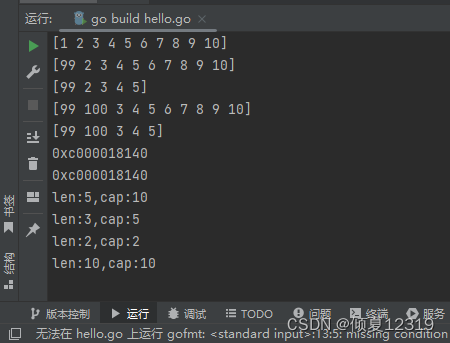
4.在已有数组上创建切片
从已有的数组上,直接创建切片,该切片的底层数组就是当前的数组,长度是从 start 带 end 切割的数据量,但是容量是从start 到数组的末尾。
package main
import "fmt"
func main() {
arr := [10]int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
fmt.Println("通过数组创建切片")
// arr[start,end] 包含start:end不包含
a1 := arr[:5] // 1~5
a2 := arr[5:8] // 6~8
a3 := arr[8:10] // 8~10
a4 := arr[:] // 1~10
fmt.Println(a1)
fmt.Println(a2)
fmt.Println(a3)
fmt.Println(a4)
// 改数组中的元素,则切片中元素也会改,因为他们指向同一存储空间
arr[0] = 99
fmt.Println(arr)
fmt.Println(a1)
a1[1] = 100
fmt.Println(arr)
fmt.Println(a1)
fmt.Printf("%p\n", a1)
// arr 是一个数组,所以需要用 & 取出地址
fmt.Printf("%p\n", &arr)
fmt.Printf("len:%d,cap:%d\n", len(a1), cap(a1))
fmt.Printf("len:%d,cap:%d\n", len(a2), cap(a2))
fmt.Printf("len:%d,cap:%d\n", len(a3), cap(a3))
fmt.Printf("len:%d,cap:%d\n", len(a4), cap(a4))
// 进行扩容,如果超过了容量,则赋值生成新的一个数组
a1 = append(a1, 1, 1, 1, 1, 1, 1, 1)
fmt.Println(arr)
fmt.Println(a1)
// 切片改了数组没有发生变化
a1[0] = 1000
fmt.Println(arr)
fmt.Println(a1)
fmt.Printf("%p\n", a1)
// arr 是一个数组,所以需要用 & 取出地址
fmt.Printf("%p\n", &arr)
}

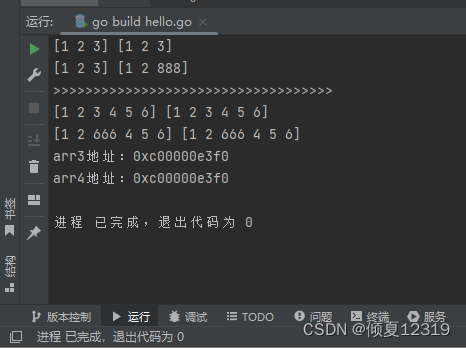
5.切片是引用类型
package main
import "fmt"
func main() {
// 数组:值类型——拷贝
arr1 := [3]int{1, 2, 3} // 数组
arr2 := arr1
fmt.Println(arr1, arr2)
// 修改arr2不会影响arr1
arr2[2] = 888
fmt.Println(arr1, arr2)
fmt.Println(">>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>")
// 切片:引用类型——地址
arr3 := []int{1, 2, 3, 4, 5, 6}
arr4 := arr3
fmt.Println(arr3, arr4)
// 修改arr4会对arr4也进行修改
arr4[2] = 666
fmt.Println(arr3, arr4)
}
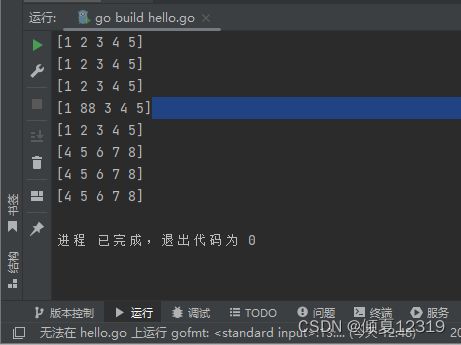
7.深拷贝、浅拷贝
深拷贝:拷贝的是数据本身
- 值类型的数据,默认都是
- 深拷贝:array、int、 float、string、 bool、sturct
- 浅拷贝:拷贝的是数据的地址,会导致多个变量指向同一块内存。
- 引用类型的数据,默认都是浅拷贝: slice、map
- 因为切片是引用类型的数据,直接拷贝的是地址
package main
import "fmt"
func main() {
s1 := []int{1, 2, 3, 4, 5}
s2 := make([]int, 0, 0)
// 通过 赋值的方式实现切片的深拷贝
for i := 0; i < len(s1); i++ {
s2 = append(s2, s1[i])
}
fmt.Println(s1)
fmt.Println(s2)
s2[1] = 88
fmt.Println(s1)
fmt.Println(s2)
// copy
s3 := []int{4, 5, 6, 7, 8}
fmt.Println(s1)
fmt.Println(s3)
copy(s1, s3)
fmt.Println(s1)
fmt.Println(s3)
}
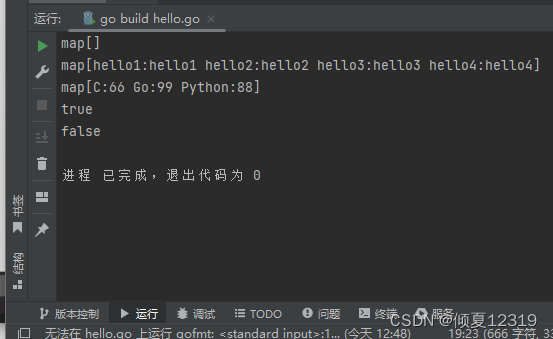
二、Map
-
Map是一种无序的键值对的集合。Map最重要的一点是通过 key来快速检索数据, key类似于索引,指向数据的值。
-
Map是一种集合,所以我们可以像迭代数组和切片那样迭代它。不过,Map是无序的,我们无法决定它的返回顺序。
-
Map 也是引用类型.
1.Map 初始化
package main
import "fmt"
func main() {
/*
声明变量,默认 map 是 nil
var map_variable map[key_data_type]value_data_type
使用 make 函数
map_variable := make(map[key_data_type]value_data_type)
*/
// map 类型的定义: map[key]value nil
// 第一种方法:通过声明变量
var map1 map[int]string // 为 true,则为未创建
// 第二种:使用make
var map2 = make(map[string]string) // true nil 为创建 //map[] 创建
// 第三种:创建时直接赋值
var map3 = map[string]int{"Go": 99, "Python": 88, "C": 66}
map2["hello1"] = "hello1"
map2["hello2"] = "hello2"
map2["hello3"] = "hello3"
map2["hello4"] = "hello4"
fmt.Println(map1)
fmt.Println(map2)
fmt.Println(map3)
fmt.Println(map1 == nil)
fmt.Println(map2 == nil)
}
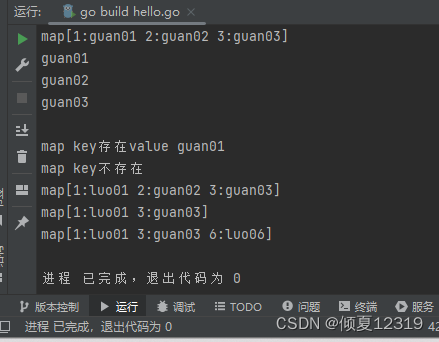
2.map 的使用
package main
import "fmt"
func main() {
// 创建 map
var map1 map[int]string //nil
map1 = make(map[int]string)
// 存储键值对,给键值对赋值
map1[1] = "guan01"
map1[2] = "guan02"
map1[3] = "guan03"
fmt.Println(map1)
// 获取 map 的数据
// 根据 key,来获取 value
// key 不存在,则获取默认的零值
fmt.Println(map1[1])
fmt.Println(map1[2])
fmt.Println(map1[3])
fmt.Println(map1[4])
// 可以通过 ok-idiom 来判断 key value 是否存在
value, ok := map1[1]
if ok == true {
fmt.Println("map key存在value", value)
} else {
fmt.Println("map key不存在")
}
value1, ok := map1[4]
if ok == true {
fmt.Println("map key存在value", value1)
} else {
fmt.Println("map key不存在")
}
// 修改数据
map1[1] = "luo01"
fmt.Println(map1)
// map 删除 delete
delete(map1, 2)
fmt.Println(map1)
// 如果 key 不存在就是新增,存在就是修改
map1[6] = "luo06"
fmt.Println(map1)
}
3.map 的遍历
使用map过程中需要注意的几点:
- map是无序的,每次打印出来的map都会不一样,它不能通过index获取,而必须通过key获取
- map的长度是不固定的,也就是和 slice 一样,也是 一种引用类型
- 内置的 len 函数同样适用于 map,这回 map 拥有的 key 的数量
- map的key可以是所有可比较的类型,如布尔型、整数型、浮点型、宁符串….
package main
import "fmt"
func main() {
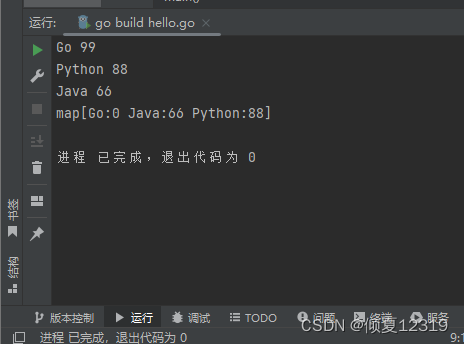
var map1 = map[string]int{"Go": 99, "Python": 88, "Java": 66}
map2 := map1
// 多运行几次发现每次遍历的结果都不同,map是无序的
for k := range map1 {
fmt.Println(k, map1[k])
}
// 修改map2,发现map1 被修改了
map2["Go"] = 0
fmt.Println(map1)
}
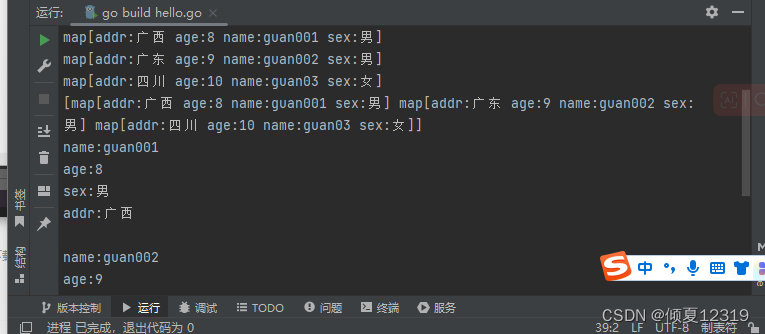
4.map 结合 slice
需求:
- 1.创建 map 来存储人的信息,如name、age、sex、addr
- 2.每个 map 存一个人的信息
- 3.将这些 map 存入到 slice 中
- 4.打印遍历输出
package main
import "fmt"
func main() {
user1 := make(map[string]string)
user1["name"] = "guan001"
user1["age"] = "8"
user1["sex"] = "男"
user1["addr"] = "广西"
user2 := make(map[string]string)
user2["name"] = "guan002"
user2["age"] = "9"
user2["sex"] = "男"
user2["addr"] = "广东"
user3 := map[string]string{"name": "guan03", "age": "10", "sex": "女", "addr": "四川"}
fmt.Println(user1)
fmt.Println(user2)
fmt.Println(user3)
userDatas := make([]map[string]string, 0, 3) //[]map[string]string为类型,0为长度,3为容量
userDatas = append(userDatas, user1)
userDatas = append(userDatas, user2)
userDatas = append(userDatas, user3)
fmt.Println(userDatas)
for _, v := range userDatas {
fmt.Printf("name:%s\n", v["name"])
fmt.Printf("age:%s\n", v["age"])
fmt.Printf("sex:%s\n", v["sex"])
fmt.Printf("addr:%s\n", v["addr"])
fmt.Println()
}
}