主要为了讲解Mybatis中如何用dom4j解析XML,这里当作dom4j解析.XML文件的练习
引入mybatis配置文件和一个.xml文件 都是.xml

<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"https://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!--
定义一些键值对,可以在当前文件中通过${}来使用,也可以在当前项目任意的mapper.xml文件中使用(就是下面指定的mapper文件)
resource:指定外部文件
-->
<!-- <properties resource="jdbc.properties">-->
<!-- <property name="aaaa" value="bbbb"/>-->
<!-- </properties>-->
<!-- <settings>-->
<!--
默认开启一级缓存,默认是SESSION 可选值:SESSION|STATEMENT
如果value配置成STATEMENT,去掉一级缓存,每次都会去查,一般不配置这个
-->
<!-- <setting name="localCacheScope" value="true"/>-->
<!--
开启日志
SLF4J:需要引入SLF4J logback 如果用这个,想自己配置配置文件的话必须叫logback.xml或logback-test.xml
LOG4J log4j
LOG4J2:以上三种,同一个作者 log4j2
STDOUT_LOGGING:标准日志,Mybatis本身实现
-->
<!-- <setting name="logImpl" value="SLF4J"/><!–如果用STDOUT_LOGGING需要配置一下,如果用其他的不用配置,引入依赖即可–>-->
<!-- 开启驼峰,开启后,只要数据库字段和对象属性名字母相同,无论中间加多少下划线都可以识别 -->
<!-- <setting name="mapUnderscoreToCamelCase" value="true" />-->
<!-- <!–开启二级缓存–>-->
<!-- <setting name="cacheEnabled" value="true"/>-->
<!-- <!–默认false 配置返回为null的列–>-->
<!-- <setting name="callSettersOnNulls" value="true"/>-->
<!-- <!–默认false 配置当查询的列为null值时候 返回的user为null–>-->
<!-- <setting name="returnInstanceForEmptyRow" value="true"/>-->
<!-- <!–默认是true 使用编译参数–>-->
<!-- <setting name="useActualParamName" value="true"/>-->
<!--
默认SIMPLE 可以选择REUSE BATCH 如果全局配置的话显然不是很好,因此,在需要批量的时候通过其他方式修改
还是让它保持默认的SIMPLE,不去修改它
-->
<!-- <setting name="defaultExecutorType" value="BATCH"/>-->
<!-- </settings>-->
<!--
environments:数据库环境配置
default:默认使用哪个库
id:指定使用的数据库id
-->
<environments default="development">
<environment id="development">
<!--
mybatis提供了两种事务管理机制
1.JDBC(可小写)事务管理器:mybatis框架自己管理事务,实际就是采用原生JDBC代码管理事务
好比写JDBC时: conn.setAutoCommit(false);
......业务处理......
conn.commit();手动提交
2.MANAGED(可小写)事务管理器
mybatis不再管理事务,事务交给其他容器负责:例如Spring
但是这里用MANAGED,因为没有容器好比事务没有开启,就会变成没有事务这回事,直接干了
-->
<transactionManager type="JDBC"/>
<!--
dataSource:数据源
type="POOLED",使用连接池
type="UNPOOLED",不使用连接池
type="JNDI",JNDI – 这个数据源实现是为了能在如 EJB 或应用服务器这类容器中使用,容器可以集中或在外部配置数据源,然后放置一个 JNDI 上下文的数据源引用。这种数据源配置只需要两个属性
-->
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://xxxxxxxxxxxxxxxxxxxxxxx"/>
<property name="username" value="xxxxx"/>
<property name="password" value="xxxxxx"/>
</dataSource>
</environment>
</environments>
<mappers>
<!--resource属性会自动从类的根路径下开始查找资源-->
<!--
1.<package name="包名"> 标签用于自动扫描指定包下的映射文件,要求映射文件名和接口名保持一致,并且映射文件(.xml)和接口需要在同一个包中,否则会报错。
2.<mapper class=""> 标签的class属性用于注册映射文件,同样要求映射文件名和接口名保持一致,并且映射文件(.xml)和接口需要在同一个包中,否则会报错。
3.<mapper resource="org/xx/demo/mapper/xx.xml"/> 标签用于注册映射文件,与上述两种方式不同,这种方式不要求映射文件名和接口名一致。这里是通过命名空间(namespace)和mapper接口对应的,命名空间要与接口的全限定名保持一致。
4.<mapper url="file:///d:/CarMapper.xml" />是绝对路径加载映射文件的,而且 .xml 文件的名称并不需要和接口名称相同。通过命名空间指定和接口关系
-->
<mapper resource="CarMapper.xml"/>
</mappers>
</configuration>另外一个
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"https://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="asdsds">
<insert id="insertCar">
insert into t_car(id,car_num,brand,guide_price,produce_time,car_type)
values(null,#{carNum},#{brand},#{guidePrice},#{produceTime},#{carType})
</insert>
</mapper>
/**
* @author hrui
* @date 2023/5/15 0:40
*/
public class ParseXMLByDom4jTest {
@Test
public void testParseMyBatisConfigXML() throws DocumentException {
//创建SAXReader对象
SAXReader saxReader=new SAXReader();
//获取输入流
InputStream in=ClassLoader.getSystemClassLoader().getResourceAsStream("mybatisConfig.xml");
//读XML,返回document对象.document对象是文档对象,代表整个XML文件
//可以用同一个saxReader读不同输入流获取Document
Document document=saxReader.read(in);
//Document document2 = saxReader.read(Thread.currentThread().getContextClassLoader().getResourceAsStream("mybatisConfig.xml"));
System.out.println(document);
//System.out.println(document2);
//获取文档当中的跟标签
Element rootElement = document.getRootElement();
String name = rootElement.getName();
System.out.println(name);
}
}

现在我们一个个去获取,比如现在我需要获取的是
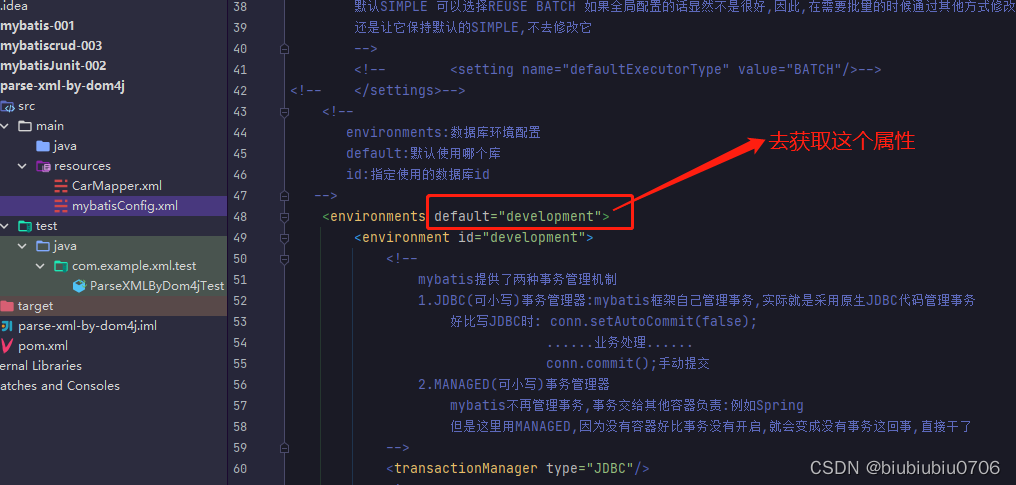
这样就可以拿到属性值了
public class ParseXMLByDom4jTest {
@Test
public void testParseMyBatisConfigXML() throws DocumentException {
//创建SAXReader对象
SAXReader saxReader=new SAXReader();
//获取输入流
InputStream in=ClassLoader.getSystemClassLoader().getResourceAsStream("mybatisConfig.xml");
//读XML,返回document对象.document对象是文档对象,代表整个XML文件
//可以用同一个saxReader读不同输入流获取Document
Document document=saxReader.read(in);
//Document document2 = saxReader.read(Thread.currentThread().getContextClassLoader().getResourceAsStream("mybatisConfig.xml"));
System.out.println(document);
//System.out.println(document2);
//获取文档当中的跟标签
Element rootElement = document.getRootElement();
String name = rootElement.getName();
System.out.println(name);
//获取enviroments标签中 default默认的环境id
//以下的xpath代表了:从根下开始找configuration标签,然后找configuration标签下的子标签environments(注意:需要有层级关系)
String xpath="/configuration/environments";//xpath是做标签路径匹配的.能够让我们快速定位XML文件中的元素
Node node = document.selectSingleNode(xpath);
System.out.println(node);
//强转成Element
Element e=(Element)node;
System.out.println(e.attributeValue("default"));
}
} 

现在要做的就是获取环境,虽然我的配置文件里就一个环境,这里只为演示和了解Mybatis作者读取.XML时的思路
我们需要获取环境id为development的环境

下面一步一步获取各个节点和各个属性

public class ParseXMLByDom4jTest {
@Test
public void testParseMyBatisConfigXML() throws DocumentException {
//创建SAXReader对象
SAXReader saxReader=new SAXReader();
//获取输入流
InputStream in=ClassLoader.getSystemClassLoader().getResourceAsStream("mybatisConfig.xml");
//读XML,返回document对象.document对象是文档对象,代表整个XML文件
//可以用同一个saxReader读不同输入流获取Document
Document document=saxReader.read(in);
//Document document2 = saxReader.read(Thread.currentThread().getContextClassLoader().getResourceAsStream("mybatisConfig.xml"));
System.out.println(document);
//System.out.println(document2);
//获取文档当中的跟标签
Element rootElement = document.getRootElement();
String name = rootElement.getName();
System.out.println(name);
//获取enviroments标签中 default默认的环境id
//以下的xpath代表了:从根下开始找configuration标签,然后找configuration标签下的子标签environments(注意:需要有层级关系)
String xpath="/configuration/environments";//xpath是做标签路径匹配的.能够让我们快速定位XML文件中的元素
Node node = document.selectSingleNode(xpath);
System.out.println(node);
//强转成Element
Element e=(Element)node;
System.out.println(e.attributeValue("default"));
//获取具体的环境environment,并且id是development的环境 xpath的语法[@属性名='属性值']
xpath="/configuration/environments/environment[@id='development']";
Element environment=(Element)document.selectSingleNode(xpath);
System.out.println(environment);
//获取指定环境environment节点下的transactionManager节点(Element的element()方法用来获取孩子节点)
Element transactionManager = environment.element("transactionManager");
//获取transactionManager中的type属性
String type = transactionManager.attributeValue("type");
System.out.println(type);//事务管理器的类型
//获取DataSource节点
Element dataSource = environment.element("dataSource");
//获取DataSource节点 的type
String dataSourceType = dataSource.attributeValue("type");
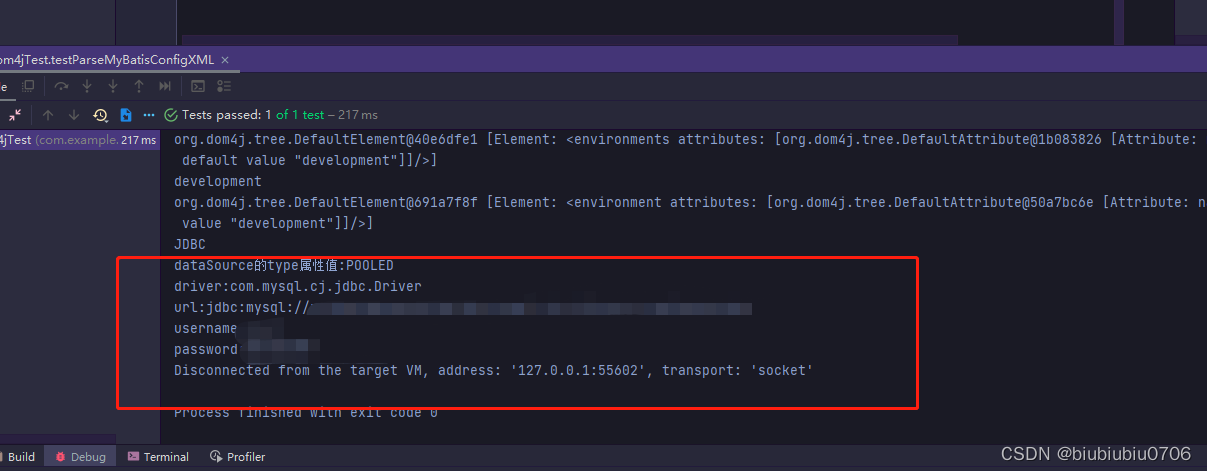
System.out.println("dataSource的type属性值:"+dataSourceType);
//获取dataSource下所有property节点
List<Element> elements = dataSource.elements();
//遍历
elements.forEach(property->{
String name1 = property.attributeValue("name");
String value1 = property.attributeValue("value");
System.out.println(name1+":"+value1);
});
}
} 
下面解析mappers

public class ParseXMLByDom4jTest {
@Test
public void testParseMyBatisConfigXML() throws DocumentException {
//创建SAXReader对象
SAXReader saxReader=new SAXReader();
//获取输入流
InputStream in=ClassLoader.getSystemClassLoader().getResourceAsStream("mybatisConfig.xml");
//读XML,返回document对象.document对象是文档对象,代表整个XML文件
//可以用同一个saxReader读不同输入流获取Document
Document document=saxReader.read(in);
//Document document2 = saxReader.read(Thread.currentThread().getContextClassLoader().getResourceAsStream("mybatisConfig.xml"));
System.out.println(document);
//System.out.println(document2);
//获取文档当中的跟标签
Element rootElement = document.getRootElement();
String name = rootElement.getName();
System.out.println(name);
//获取enviroments标签中 default默认的环境id
//以下的xpath代表了:从根下开始找configuration标签,然后找configuration标签下的子标签environments(注意:需要有层级关系)
String xpath="/configuration/environments";//xpath是做标签路径匹配的.能够让我们快速定位XML文件中的元素
Node node = document.selectSingleNode(xpath);
System.out.println(node);
//强转成Element
Element e=(Element)node;
System.out.println(e.attributeValue("default"));
//获取具体的环境environment,并且id是development的环境 xpath的语法[@属性名='属性值']
xpath="/configuration/environments/environment[@id='development']";
Element environment=(Element)document.selectSingleNode(xpath);
System.out.println(environment);
//获取指定环境environment节点下的transactionManager节点(Element的element()方法用来获取孩子节点)
Element transactionManager = environment.element("transactionManager");
//获取transactionManager中的type属性
String type = transactionManager.attributeValue("type");
System.out.println(type);//事务管理器的类型
//获取DataSource节点
Element dataSource = environment.element("dataSource");
//获取DataSource节点 的type
String dataSourceType = dataSource.attributeValue("type");
System.out.println("dataSource的type属性值:"+dataSourceType);
//获取dataSource下所有property节点
List<Element> elements = dataSource.elements();
//遍历
elements.forEach(property->{
String name1 = property.attributeValue("name");
String value1 = property.attributeValue("value");
System.out.println(name1+":"+value1);
});
//获取所有mapper标签
xpath="//mapper";//不想从跟下开始获取,你想从任意位置开始,获取所有的某个标签,xpath该这样写 //开始
List<Node> mappers = document.selectNodes(xpath);
mappers.forEach(mapper->{
//将Node强转成Element
Element e1=(Element)mapper;
String resource = e1.attributeValue("resource");
System.out.println("resource:"+resource);
});
}
}下面另写个方法解析.XML SQL映射文件

@Test
public void testParseSqlMapperXML() throws DocumentException {
//创建SAXReader对象
SAXReader saxReader=new SAXReader();
//获取输入流
InputStream in=ClassLoader.getSystemClassLoader().getResourceAsStream("CarMapper.xml");
Document document=saxReader.read(in);
//开始解析
//获取namespace
//Element rootElement = document.getRootElement();//这样也可以获取
String xpath="/mapper";
Element rootElement = (Element)document.selectSingleNode(xpath);
System.out.println(rootElement);
String namespace = rootElement.attributeValue("namespace");
System.out.println(namespace);
//上面已经获取了命名空间
//下面获取mapper节点下所有的子节点
List<Element> elements = rootElement.elements();
elements.forEach(element -> {
//获取sqlid
String id = element.attributeValue("id");
System.out.println(id);
//获取resultType 没有该属性输出就是null
String resultType = element.attributeValue("resultType");
System.out.println(resultType);
//看是insert 还是delete update select
String name = element.getName();
System.out.println(name);
//获取标签中的sql
String textTrim = element.getTextTrim();
System.out.println(textTrim);
});
}这样该拿的都拿到了

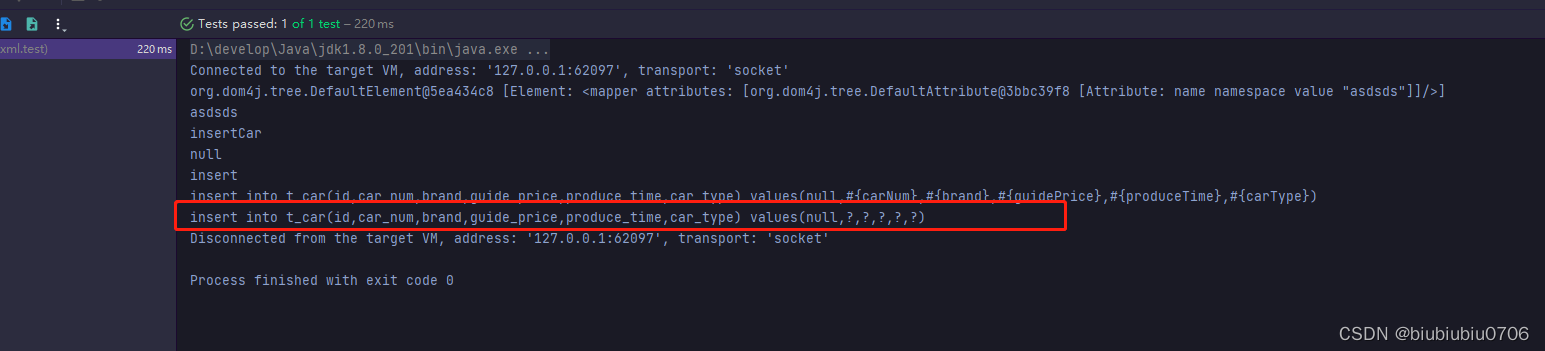
现在得到的SQL是
insert into t_car(id,car_num,brand,guide_price,produce_time,car_type) values(null,#{carNum},#{brand},#{guidePrice},#{produceTime},#{carType})
Myabtis封装了JDBC,因此以后执行语句肯定会变成
insert into t_car(id,car_num,brand,guide_price,produce_time,car_type) values(null,?,?,?,?,?)
@Test
public void testParseSqlMapperXML() throws DocumentException {
//创建SAXReader对象
SAXReader saxReader=new SAXReader();
//获取输入流
InputStream in=ClassLoader.getSystemClassLoader().getResourceAsStream("CarMapper.xml");
Document document=saxReader.read(in);
//开始解析
//获取namespace
//Element rootElement = document.getRootElement();//这样也可以获取
String xpath="/mapper";
Element rootElement = (Element)document.selectSingleNode(xpath);
System.out.println(rootElement);
String namespace = rootElement.attributeValue("namespace");
System.out.println(namespace);
//上面已经获取了命名空间
//下面获取mapper节点下所有的子节点
List<Element> elements = rootElement.elements();
elements.forEach(element -> {
//获取sqlid
String id = element.attributeValue("id");
System.out.println(id);
//获取resultType 没有该属性输出就是null
String resultType = element.attributeValue("resultType");
System.out.println(resultType);
//看是insert 还是delete update select
String name = element.getName();
System.out.println(name);
//获取标签中的sql
String textTrim = element.getTextTrim();
System.out.println(textTrim);
//insert into t_car(id,car_num,brand,guide_price,produce_time,car_type) values(null,?,?,?,?,?)将SQL转换
String s = textTrim.replaceAll("#\\{[0-9A-Za-z_$]*}", "?");//用正则将#{xxx}转成?
System.out.println(s);
});
}