文章目录
- 8.2、pandas
- 8.2.1、为什么用 pandas ?
- 8.2.2、pandas Series 类型
- 8.2.3、pandas 自定义索引
- 8.2.4、pandas 如何判断数据缺失?
- 8.2.5、pandas DataFrame 类型
- 8.2.6、pandas 筛选
- 8.2.7、pandas 重新索引
- 8.2.8、pandas 算数运算和数据对齐
- 8.2.9、pandas 排序
- 8.2.10、pandas 层次索引
- 8.2.11、 pandas 文本格式数据处理
- 8.2.12、pandas 画图
- 一、引言
- 二、网络安全与隐私保护的挑战
- 三、保护网络隐私的方法与策略
- 四、结论
8.2、pandas
8.2.1、为什么用 pandas ?
pandas 是基于 numpy 数组构建的,
但二者最大的不同是 pandas 是专门为处理表格和混杂数据设计的,比较契合统计分析中的表结构,而 numpy 更适合处理统一的数值数组数据。pandas数组结构有一维 Series 和二维 DataFrame 。
8.2.2、pandas Series 类型
可以将 Series 类型看作一维数组,
字典类型转为 Series 类型/pandas 一维数组,更适合科学计算
from pandas import Series,DataFrame res = Series([1,2,3])print(res)Out:
0 1 1 2 2 3 dtype: int64
怎么得到和 numpy.array 类似的矩阵?
print(res.values)Out:
[1 2 3]
8.2.3、pandas 自定义索引
怎么用?
举个例子,定义从1开始的索引,
obj = Series(['a','b','c','d','e'],index = [1,2,3,4,5]) print(obj.index)Out:
Int64Index([1, 2, 3, 4, 5], dtype='int64')
怎么取值?
通过索引取值,沿用上面例子
obj[1]Out:
a
结论:
Series() 可传入的参数与返回对象索引的关系:
Series()传入列表,得到的对象,有默认索引,可自定义;
Series()传入字典【key:value】,得到的对象,key为索引。
怎么选取特定的键值对,并返回 obj【Series对象】?
举个例子,数据来源:data【字典类型】:
data = {"a":1,"b":2,"c":3} keys = ["a","c"]obj = Series(data, index = keys)Out:
a 1 c 3 dtype: int64
8.2.4、pandas 如何判断数据缺失?
以 obj 对象为例,判断是否有缺失值:
pd.notnull(obj)
pd.isnull(obj)
8.2.5、pandas DataFrame 类型
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不用的类型,数值、字符串、布尔值都可以
DataFrame 本身也有行索引,列索引,字典转 DataFrame 再转置表格才一致。
举个行索引例子
data = { "60年代":[1,2,3], "70年代":[4,5,6], "80年代":[7,8,9], } res = DataFrame(data) res = res.T#转置1)只查找60年代这组,全部列
res['60年代':'60年代']Out:
0 1 2 60年代 1 2 32)查找60-70年代,全部列
res["60年代":"70年代"]Out:
0 1 2 60年代 1 2 3 70年代 4 5 6举个列索引的例子
1)查找全部年份,第一列,第二列
print(res.loc[:,[0,1]])#使用 loc函数行列同时筛选,也使用 loc 函数。
为什么 DataFrame 可以理解成 Series 组成的字典 ?
DataFrame 的数据源可以是字典,Series,也可以是 DataFrame,还可以是 numpy 数组。
8.2.6、pandas 筛选
以 res 对象为例,
data = {
"60年代":[1,2,3],
"70年代":[4,5,6],
"80年代":[7,8,9],
}
df = DataFrame(data)
1)行、列筛选
见 8.2.5
2)头部筛选
例如,取前两行
df.head(2)
3)尾部筛选
例如,取后两行
df.tail(3)
8.2.7、pandas 重新索引
reindex 函数,就是重新定义索引。
举个例子:
obj = Series([1,2,3],index=['a','b','c']) print(obj)Out:
a 1 b 2 c 3 dtype: int64重新定义索引:
obj_1 = obj.reindex(['a','b','c','d','e']) print(obj_1)Out:
a 1.0 b 2.0 c 3.0 d NaN e NaN dtype: float64
重新定义索引时,如何填充缺失值/NaN?
仍以 obj 为例,
1)缺失值填充为0。
obj_2 = obj.reindex(['a','b','c','d','e'],fill_value=0) print(obj_2)Out:
a 1 b 2 c 3 d 0 e 0 dtype: int642)向前填充
缺失值与它前一个位置数值保持一致,向前看齐。
obj = Series([1,2,3],index=[0,2,4]) obj = reindex(range(6),method='ffill')Before:
0 1 2 2 4 3 dtype: int64Out:
0 1 1 1 2 2 3 2 4 3 5 3 dtype: int643)向后填充
向后看齐。
obj = Series([1,2,3],index=[0,2,4]) obj = reindex(range(6),method='bfill')Before:
0 1 2 2 4 3 dtype: int64Out:
0 1.0 1 2.0 2 2.0 3 3.0 4 3.0 5 NaN dtype: float64
是否可以反复重新定义索引?
不可以。
若在 obj_1 基础上重新索引,没有效果,举例过程中发现,无论多少次重新定义索引,结果都与第一次重新索引结果一致。
obj_2 = obj_1.reindex(['a','b','c','d','e'],fill_value=0) print(obj_2)Out:
a 1.0 b 2.0 c 3.0 d NaN e NaN dtype: float64
8.2.8、pandas 算数运算和数据对齐
加法(add),举个例子
1)Series 相加
obj_a = Series([1,2,3],index=[0,1,2]) obj_b = Series([1,2,3,4],index=[0,1,2,3]) obj_a + obj_bOut:
0 2.0 1 4.0 2 6.0 3 NaN dtype: float642)DataFrame 相加
df1 = DataFrame(np.arange(12).reshape(4,3),index=[0,1,2,3],columns=['b','c','d']) df2 = DataFrame(np.arange(12).reshape(3,4),index=[0,1,2],columns=['a','b','c','d']) df1 + df2Out:
a b c d 0 NaN 1.0 3.0 5.0 1 NaN 8.0 10.0 12.0 2 NaN 15.0 17.0 19.0 3 NaN NaN NaN NaN结论:对象加法,没有对应项的结果为 NaN。
加法补充:
填补0,只要有一个对象有这一项,另一项 NaN 值做补0处理。
df1.add(df2,fill_value = 0)Out:
a b c d 0 0.0 1.0 3.0 5.0 1 4.0 8.0 10.0 12.0 2 8.0 15.0 17.0 19.0 3 NaN 9.0 10.0 11.0结果中的 NaN 指的是两对象中均不存在的项。
减法(sub)、乘法(mul)、除法(div)
8.2.9、pandas 排序
举几个例子:
1)Series 排序
data = Series([0,2,1],index=list('cba'))原本序列:
c 0 b 2 a 1 dtype: int64按照索引排序**【字典序】**:
print(data.sort_index())#有返回,返回有序Out:
a 1 b 2 c 0 dtype: int64按照 value 排序:
print(data.sort_values())#有返回,返回有序Out:
c 0 a 1 b 2 dtype: int64
2)DataFrame 排序
同理,但
DataFrame 相比 Series 排序不再是一维,按索引排序是需要说明是行排序【默认,axis=0】,还是列排序【axis=1】
按照索引排序:
df = DataFrame(np.arange(6).reshape(2,3),index=['two','one'],columns=['first','third','second'])print(df.sort_index()) print(df.sort_index(axis=1))Out:
first third second two 0 1 2 one 3 4 5 first third second one 3 4 5 two 0 1 2 first second third two 0 2 1 one 3 5 4按照 value 排序:
df = DataFrame(np.array([9,6,5,7,3,2]).reshape(2,3),index=['two','one'],columns=['first','third','second'])Out:
first third second two 9 6 5 one 7 3 2这里希望按照 first这一列对整个表格排序,
print(df.sort_values(by ='first'))Out:
first third second one 7 3 2 two 9 6 5上面给的是按照列排序,怎么按照行 value 排序?
①字典转为DF类型后,键/key 也默认成为了列索引,与排序不谋而合,
②目前学到的只有列转置,可以用学过的转置,再排序。
8.2.10、pandas 层次索引
在一个轴上拥有多个索引级别,低维度形式处理高维度数据。
怎么理解低维度形式处理高维度数据?
通过几个维度定义成一个“新维度”,实现减少维度数量。
举个 Serie 层次索引例子:
data = Series(np.random.rand(10),index=[['A','B','C','D','E','F','G','H','I','J'],['a','b','c','a','a','b','c','d','d','e']]) print(data)Out:
A a 0.149330 B b 0.629922 C c 0.260399 D a 0.252584 E a 0.486334 F b 0.822967 G c 0.056135 H d 0.511725 I d 0.089320 J e 0.264031 dtype: float64我的理解:

data.indexMultiIndex([('A', 'a'), ('B', 'b'), ('C', 'c'), ('D', 'a'), ('E', 'a'), ('F', 'b'), ('G', 'c'), ('H', 'd'), ('I', 'd'), ('J', 'e')], )
筛选
data = Series(np.random.rand(10),index=[['A','A','A','B','C','C','G','H','I','J'],['a','b','c','a','a','b','c','d','d','e']])1)筛选从A到C:
print(data['A':'C'])Out:
A a 0.023985 b 0.555995 c 0.422598 B a 0.715328 C a 0.931982 b 0.949591 dtype: float642)既然多层,筛选具体到第二层,筛选第二层索引为a的数据,第一层不做要求
这里和视频中有出入,视频中 data.index 得到的返回值和我的也不一致,并没有出现 levels、codes 这些关键字,使用数字筛选第二层报错。
print(data[:,'a'])Out:
A 0.694404 B 0.162430 C 0.260433 dtype: float64
能保证层次索引的唯一性吗?
data = Series(np.random.rand(10),index=[['A','A','C','D','E','F','G','H','I','J'],['a','a','c','a','a','b','c','d','d','e']])Out:
A a 0.849224 #一对多? a 0.359825 #一对多? C c 0.116364 D a 0.316153 E a 0.847800 F b 0.029664 G c 0.476278 H d 0.561757 I d 0.407979 J e 0.830286 dtype: float64貌似是不能的。
举个 DF 层次索引的例子进一步理解:
data = DataFrame(np.random.rand(12).reshape(4,3),index=[['A','A','B','B'],['a','b','a','b']] ,columns=[['col-1','col-2','col-3'],['ccl-11','col-22','col-33']]) print(data)Out:
col-1 col-2 col-3 ccl-11 col-22 col-33 A a 0.833527 0.577264 0.802922 b 0.804280 0.629228 0.761563 B a 0.997186 0.556085 0.387777 b 0.231312 0.375912 0.749231我目前的理解:
用 x、y 轴去解释,
x轴:每层索引数量为4, 层数不限
y轴:每层索引数量为3,层数不限
若 x、y 轴层数都限制为1,退化为一般的 DataFrame / 表格 / 二维数组。
给层次索引的这个层,定义名字:
data.index.names=['行-第1层','行-第2层'] data.columns.names=['列-第1层','列-第2层']Out:
列-第1层 👉 col-1 col-2 col-3 列-第2层 👉 ccl-11 col-22 col-33 行-第1层 行-第2层 👇 👇 A a 0.570352 0.880968 0.149804 b 0.191035 0.381349 0.440291 B a 0.252567 0.214825 0.434361 b 0.121341 0.462958 0.369168给层次指定名字后的索引,
data.index data.columnsOut:
MultiIndex([('A', 'a'), ('A', 'b'), ('B', 'a'), ('B', 'b')], names=['行-第1层', '行-第2层']) MultiIndex([('col-1', 'ccl-11'), ('col-2', 'col-22'), ('col-3', 'col-33')], names=['列-第1层', '列-第2层'])
给层定义名字的意义?
利用层做计算
仍以上述 data 为例:
列-第1层 👉 col-1 col-2 col-3
列-第2层 👉 ccl-11 col-22 col-33
行-第1层 行-第2层
👇 👇
A a 0.570352 0.880968 0.149804
b 0.191035 0.381349 0.440291
B a 0.252567 0.214825 0.434361
b 0.121341 0.462958 0.369168
依据 行-第1层进行求和,
print(data.groupby(level='行-第1层').sum())
Out:
列-第1层 col-1 col-2 col-3
列-第2层 ccl-11 col-22 col-33
行-第1层
A 0.58706 0.875382 0.258519
B 1.26823 1.486146 1.127393
(求和结果由于是随机数求和,求和结果就不细究了)
8.2.11、 pandas 文本格式数据处理
就是处理csv文件,涉及到索引的使用。
以 demo.CSV 为例,
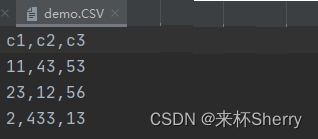
1)全部读取
data = pd.read_csv('demo.CSV')Out:
c1 c2 c3 0 11 43 53 1 23 12 56 2 2 433 13CSV文件得到的DF 原本缺少行索引,默认用 0123… 填充。
和数据源为字典的DF对象很像,转 DataFrame 的格式数据 除了前面提到的(8.2.2),现在又多了 CSV文件。
2)去掉索引,
header=None第一行也当作 value,填充 0123…作为默认列索引,不是将第一行给去掉
data = pd.read_csv('demo.CSV' , header=None)Out:
0 1 2 0 c1 c2 c3 1 11 43 53 2 23 12 56 3 2 433 13
3)指定索引,
index_colCSV文件得到的DF 原本缺少行索引,下面指定 c3这一列 成为指定行索引。
data = pd.read_csv('demo.CSV' , index_col='c3')Out:
c1 c2 c3 53 11 43 56 23 12 13 2 433
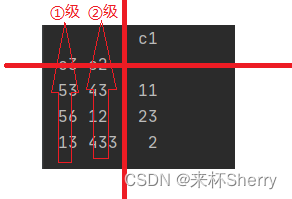
4)指定多级索引
data = pd.read_csv('demo.CSV' , index_col=['c3','c2'])Out:
c1 c3 c2 53 43 11 56 12 23 13 433 2对这个结果的个人理解:
5)跳过第一行,
skiprowsdata = pd.read_csv('demo.CSV',skiprows=[1])Before:
c1 c2 c3 0 11 43 53 1 23 12 56 2 13 433 2After:
c1 c2 c3 0 23 12 56 1 13 433 2跳过第0行会怎样?
会跳过索引所在行。
一共三行,跳过第四行会怎样?
无效。
不加中括号会怎么样?
data = pd.read_csv('demo.CSV',skiprows=3)Out:
Empty DataFrame Columns: [13, 433, 2] Index: []不加中括号,跳过了三行(从索引所在行开始算起,超过四行空了,报错。)
6)指定读取行数【读大文件预览用】
这里指定读取2行,
data = pd.read_csv('demo.CSV',nrows=2)
7)转存为
data.CSV文件,且替换默认分隔符为’|‘data = pd.read_csv('demo.CSV',nrows = 2) data.to_csv('data.CSV',sep='|')
8)查看工作簿
.xlsx文件data = pd.read_excel('d.xlsx') print(data)若存在多张工作表,如何读工作簿第二张表?
data = pd.read_excel('d.xlsx',sheet_name='Sheet2')
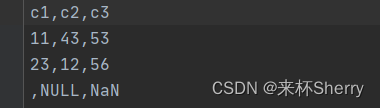
CSV文件中空的单元格显示什么?
Out:
c1 c2 c3 0 11.0 43.0 53.0 1 23.0 12.0 56.0 2 NaN NaN NaN显示 NaN ,但显示 NaN 的也可能是非空,填入了关键字 NULL、NaN。
判空方式,详见8.2.4
读取处理 CSV文件,excel文件有无性能差异?
df = pd.read_excel('data.xlsx')
df = pd.read_csv('data.CSV')
博客文章上的解释:
pandas读取excel文件时如果要将内容转为数组需要使用values属性值,而读取csv时生成的直接就是一个数组。
因此,CSV 文件更快。
pandas 还可以读取 json,db 文件
df = pd.read_json('data.json')
import sqlite3
conn = sqlite3.connect('database.db')
df = pd.read_sql('SELECT * FROM table', conn)
通过前面几个例子,很明显有这么几个默认:
①在读取 CSV文件/excel文件都是默认第一行是索引。
②pandas CSV文件处理方法中谈到的索引默认指的是列索引【不是绝对的,Dataframe 有些方法既 有index、又有 columns 时,index 表示行】。
③读取的表格会默认添加行索引,且默认用012345…填充。
8.2.12、pandas 画图
pandas 内部集成了一部分 matplotlib 绘画功能,随查随用。
一、引言
在当前数字化时代,隐私泄露和数据安全问题变得越来越重要。随着越来越多的个人信息和敏感数据被存储在互联网上,这些数据的安全性和隐私保护变得至关重要。隐私泄露和数据安全问题可能导致个人信息被盗用、身份被冒用、财务损失、信用评级下降等问题。此外,企业和政府机构也需要保护其敏感数据,以避免商业机密泄露、知识产权侵犯、网络攻击等问题。因此,隐私保护和数据安全已经成为数字化时代下的重要议题,需要得到越来越多的关注和重视。
二、网络安全与隐私保护的挑战
网络攻击和数据泄露的危害影响包括但不限于以下几点:
1、个人隐私泄露:网络攻击和数据泄露可能导致个人信息被盗用、身份被冒用、财务损失、信用评级下降等问题。
2、商业机密泄露:企业和政府机构的敏感数据可能被窃取或泄露,导致商业机密泄露、知识产权侵犯等问题。
3、社会稳定受到威胁:网络攻击和数据泄露可能导致社会稳定受到威胁,例如黑客攻击可能导致电力、交通等基础设施瘫痪,影响社会正常运转。
互联网公司的数据采集和隐私售卖风险如下:
1、数据采集范围过大:互联网公司可能收集用户的大量个人信息,包括但不限于姓名、地址、电话号码、电子邮件地址、社交媒体账号等,这些信息可能被用于广告投放、用户画像等目的。
2、隐私售卖:互联网公司可能将用户的个人信息出售给第三方,这些第三方可能会将这些信息用于不良用途,例如垃圾邮件、诈骗等。
3、数据泄露:互联网公司的数据可能会被黑客攻击窃取或泄露,导致用户个人信息泄露。
三、保护网络隐私的方法与策略
1、 加强网络安全意识:用户应该加强网络安全意识,不轻易泄露个人信息,不随意点击陌生链接,不使用不安全的公共Wi-Fi等。
2、使用安全软件和工具:用户可以使用安全软件和工具,例如杀毒软件、防火墙、VPN等,以提高网络安全性。
3、加强密码管理:用户应该加强密码管理,使用强密码、定期更换密码、不重复使用密码等。
四、结论
1、隐私泄露和数据安全问题在当前数字化时代变得越来越重要,可能导致个人信息被盗用、身份被冒用、财务损失、信用评级下降等问题,也可能导致企业和政府机构的商业机密泄露、知识产权侵犯等问题,甚至威胁社会稳定。
2、互联网公司的数据采集和隐私售卖风险主要表现在数据采集范围过大、隐私售卖和数据泄露等方面。
3、公民隐私保护的难点和底线界定的争议主要表现在个人隐私权与公共利益的平衡、数据使用的透明度和法律法规的制定和执行等方面。
4、针对网络攻击和数据泄露,可以加强网络安全意识、使用安全软件和工具、加强密码管理等预防和应对措施;针对隐私保护,可以使用隐私保护浏览器、加密通讯工具、关注隐私政策和条款等技巧和工具。同时,分享有用的经验和案例也可以帮助其他用户更好地保护个人隐私和网络安全。