Content
- MNIST数据集基本介绍
- 下载MNIST数据集到本地
- 解析MNIST数据集
- 显示MNIST数据集中训练集的前9张图片和标签
随着图像处理、计算机视觉、机器学习,甚至深度学习的蓬勃发展,一个良好的数据集作为学习和测试相关算法非常重要。MNIST数据集对于想要学习和测试相关算法,同时又不想花费大量的时间收集和整理数据集的人们来说,这是一个很好的数据库。MNIST数据集官方地址为:http://yann.lecun.com/exdb/mnist/😆😆😆
MNIST数据集基本介绍
MNIST 数据库是一个大型手写数字数据库(包含0~9十个数字),包含 60,000 张训练图像和 10,000 张测试图像,通常用于训练各种图像处理系统。训练数据集取自美国人口普查局员工,而测试数据集取自美国高中生。所有的手写数字图片的分辨率为28*28。
MNIST训练集图像、训练集标签、测试集图像和测试及标签如下表:
| 数据集 | MNIST中的文件名 | 下载地址 | 文件大小 |
|---|---|---|---|
| 训练集图像 | train-images-idx3-ubyte.gz | http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz | 9912422字节 |
| 训练集标签 | train-labels-idx1-ubyte.gz | http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz | 28881字节 |
| 测试集图像 | t10k-images-idx3-ubyte.gz | http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz | 1648877字节 |
| 测试集标签 | t10k-labels-idx1-ubyte.gz | http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz | 4542字节 |
下载MNIST数据集到本地
-
方法一:直接进入http://yann.lecun.com/exdb/mnist/点击对应的数据集下载。

-
方法二:使用Python脚本下载(推荐😄😄⭐️⭐️🚀🚀)
使用wget.download(url, out=None, bar=bar_adaptive)下载。
首先确保自己的Python环境安装有wget这个第三方库,否则pip install wget安装。使用下面脚本会自动下载MNIST数据集的四个文件到download_minst(save_dir: str = None)所传入的保存路径save_dir中。
"""
下载MNIST数据集脚本
"""
import os
from pathlib import Path
import logging
import wget
logging.basicConfig(level=logging.INFO, format="%(message)s")
def download_minst(save_dir: str = None) -> bool:
"""下载MNIST数据集
输入参数:
save_dir: MNIST数据集的保存地址. 类型: 字符串.
返回值:
全部下载成功返回True, 否则返回False
"""
save_dir = Path(save_dir)
train_set_imgs_addr = save_dir / "train-images-idx3-ubyte.gz"
train_set_labels_addr = save_dir / "train-labels-idx1-ubyte.gz"
test_set_imgs_addr = save_dir / "t10k-images-idx3-ubyte.gz"
test_set_labels_addr = save_dir / "t10k-labels-idx1-ubyte.gz"
try:
if not os.path.exists(train_set_imgs_addr):
logging.info("下载train-images-idx3-ubyte.gz")
filename = wget.download(url="http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz", out=str(train_set_imgs_addr))
logging.info("\tdone.")
else:
logging.info("train-images-idx3-ubyte.gz已经存在.")
if not os.path.exists(train_set_labels_addr):
logging.info("下载train-labels-idx1-ubyte.gz.")
filename = wget.download(url="http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz", out=str(train_set_labels_addr))
logging.info("\tdone.")
else:
logging.info("train-labels-idx1-ubyte.gz已经存在.")
if not os.path.exists(test_set_imgs_addr):
logging.info("下载t10k-images-idx3-ubyte.gz.")
filename = wget.download(url="http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz", out=str(test_set_imgs_addr))
logging.info("\tdone.")
else:
logging.info("t10k-images-idx3-ubyte.gz已经存在.")
if not os.path.exists(test_set_labels_addr):
logging.info("下载t10k-labels-idx1-ubyte.gz.")
filename = wget.download(url="http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz", out=str(test_set_labels_addr))
logging.info("\tdone.")
else:
logging.info("t10k-labels-idx1-ubyte.gz已经存在.")
except:
return False
return True
if __name__ == "__main__":
download_minst(save_dir="./")
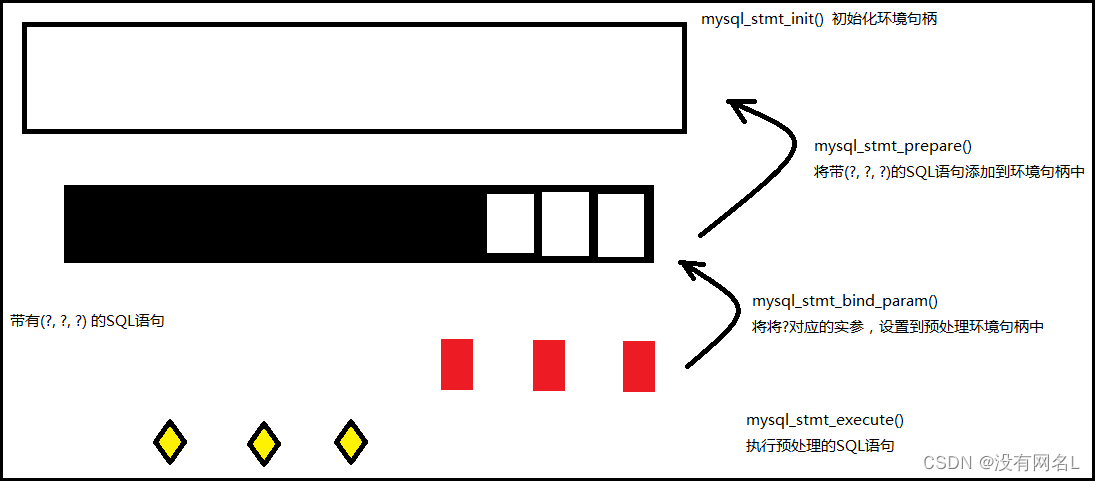
解析MNIST数据集
不同于我们常见到的数据集图片通过jpg这样的图片格式保存,标签通过txt、xml、json等常规文本文件保存。MNIST的图片和标签均通过二进制文件进行保存,也就是我们无法直接在Windows中查看手写数字的图片和标签,必须要先解码。
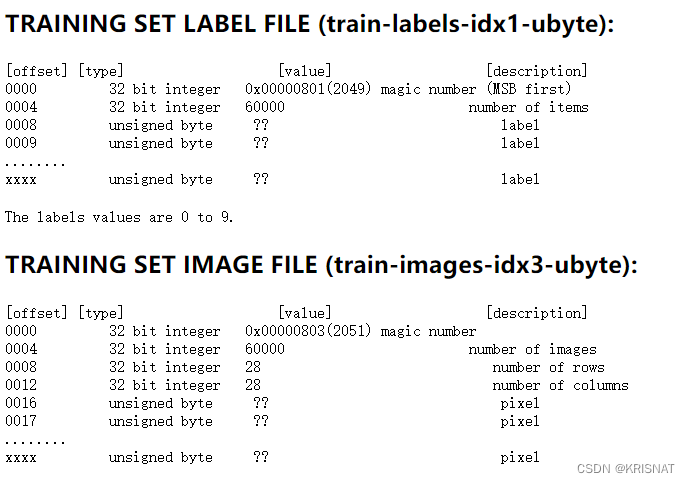
MNITS的编码格式如下:
-
训练集
-
测试集
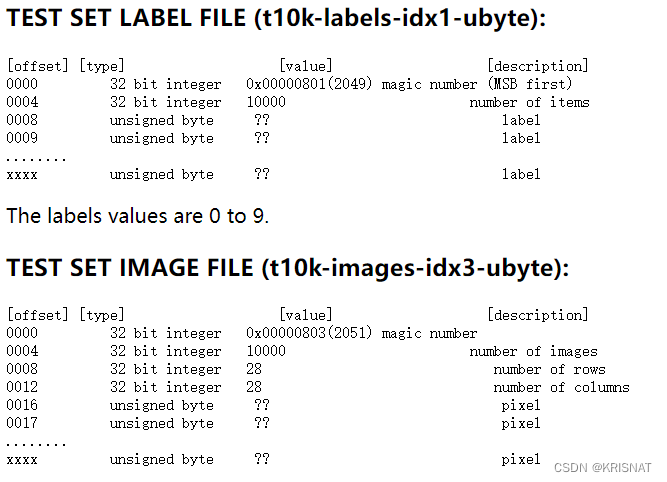
从上面官方提供的编码格式可以看出,MNIST的图片和标签均采用二进制编码,图片二进制编码文件的前16个字节(Byte)为描述性内容,我们可以不管,因为我们已经知道MNIST训练集60000张图片、测试集10000张图片,所有图片分辨率为28*28,因此可以直接通过Python自带的gzip工具读取MNIST数据集的图片和标签二进制编码文件,在通过numpy.frombuffer()方法解析读取到的二进制信息,解析MNIST二进制文件的Python脚本如下:
"""
通过gzip和numpy解析MNIST数据集的二进制文件
"""
import os
import gzip
import logging
import numpy as np
logging.basicConfig(format="%(message)s", level=logging.DEBUG) # 设置Python日志管理工具的消息格式和显示级别
def parse_mnist(minst_file_addr: str = None) -> np.array:
"""解析MNIST二进制文件, 并返回解析结果
输入参数:
minst_file: MNIST数据集的文件地址. 类型: 字符串.
返回值:
解析后的numpy数组
"""
if minst_file_addr is not None:
minst_file_name = os.path.basename(minst_file_addr) # 根据地址获取MNIST文件名字
with gzip.open(filename=minst_file_addr, mode="rb") as minst_file:
mnist_file_content = minst_file.read()
if "label" in minst_file_name: # 传入的为标签二进制编码文件地址
data = np.frombuffer(buffer=mnist_file_content, dtype=np.uint8, offset=8) # MNIST标签文件的前8个字节为描述性内容,直接从第九个字节开始读取标签,并解析
else: # 传入的为图片二进制编码文件地址
data = np.frombuffer(buffer=mnist_file_content, dtype=np.uint8, offset=16) # MNIST图片文件的前16个字节为描述性内容,直接从第九个字节开始读取标签,并解析
data = data.reshape(-1, 28, 28)
else:
logging.warning(msg="请传入MNIST文件地址!")
return data
if __name__ == "__main__":
data = parse_mnist(minst_file_addr="./t10k-labels-idx1-ubyte.gz") # t10k-images-idx1-ubyte.gz文件应该和本脚本在同一个目录下,否则应该修改地址
print(len(data)) # 10000
print(data[0:10]) # [7 2 1 0 4 1 4 9 5 9]
显示MNIST数据集中训练集的前9张图片和标签
通过上一步解析后的MNIST数据已经是numpy.narray数据类型,可以直接通过pillow、opencv和matplotlib库直接可视化了。此处博主通过matplotlib库可视化MNIST训练集的前9张图片及其标签,代码和效果如下:
"""
通过gzip和numpy解析MNIST数据集的二进制文件, 并可视化训练集前10张图片和标签
"""
import os
import gzip
import logging
import numpy as np
import matplotlib.pyplot as plt
logging.basicConfig(format="%(message)s", level=logging.DEBUG) # 设置Python日志管理工具的消息格式和显示级别
plt.rcParams["font.sans-serif"] = "SimHei" # 确保plt绘图正常显示中文
plt.rcParams["figure.figsize"] = [9, 10] # 设置plt绘图尺寸
def parse_mnist(minst_file_addr: str = None) -> np.array:
"""解析MNIST二进制文件, 并返回解析结果
输入参数:
minst_file: MNIST数据集的文件地址. 类型: 字符串.
返回值:
解析后的numpy数组
"""
if minst_file_addr is not None:
minst_file_name = os.path.basename(minst_file_addr) # 根据地址获取MNIST文件名字
with gzip.open(filename=minst_file_addr, mode="rb") as minst_file:
mnist_file_content = minst_file.read()
if "label" in minst_file_name: # 传入的为标签二进制编码文件地址
data = np.frombuffer(buffer=mnist_file_content, dtype=np.uint8, offset=8) # MNIST标签文件的前8个字节为描述性内容,直接从第九个字节开始读取标签,并解析
else: # 传入的为图片二进制编码文件地址
data = np.frombuffer(buffer=mnist_file_content, dtype=np.uint8, offset=16) # MNIST图片文件的前16个字节为描述性内容,直接从第九个字节开始读取标签,并解析
data = data.reshape(-1, 28, 28)
else:
logging.warning(msg="请传入MNIST文件地址!")
return data
if __name__ == "__main__":
train_imgs = parse_mnist(minst_file_addr="train-images-idx3-ubyte.gz") # 训练集图像
train_labels = parse_mnist(minst_file_addr="train-labels-idx1-ubyte.gz") # 训练集标签
# 可视化
fig, ax = plt.subplots(ncols=3, nrows=3)
ax[0, 0].imshow(train_imgs[0], cmap=plt.cm.gray)
ax[0, 0].set_title(f"标签为{train_labels[0]}")
ax[0, 1].imshow(train_imgs[1], cmap=plt.cm.gray)
ax[0, 1].set_title(f"标签为{train_labels[1]}")
ax[0, 2].imshow(train_imgs[2], cmap=plt.cm.gray)
ax[0, 2].set_title(f"标签为{train_labels[2]}")
ax[1, 0].imshow(train_imgs[3], cmap=plt.cm.gray)
ax[1, 0].set_title(f"标签为{train_labels[3]}")
ax[1, 1].imshow(train_imgs[4], cmap=plt.cm.gray)
ax[1, 1].set_title(f"标签为{train_labels[4]}")
ax[1, 2].imshow(train_imgs[5], cmap=plt.cm.gray)
ax[1, 2].set_title(f"标签为{train_labels[5]}")
ax[2, 0].imshow(train_imgs[6], cmap=plt.cm.gray)
ax[2, 0].set_title(f"标签为{train_labels[6]}")
ax[2, 1].imshow(train_imgs[7], cmap=plt.cm.gray)
ax[2, 1].set_title(f"标签为{train_labels[7]}")
ax[2, 2].imshow(train_imgs[8], cmap=plt.cm.gray)
ax[2, 2].set_title(f"标签为{train_labels[8]}")
plt.show() # 显示绘图
print(plt.rcParams.keys())

创作不易,若觉得此篇博文有用的观众老爷,不妨点赞👍➕收藏🌟💯🚀