多模态:InstructBLIP
- Introduction
- Method
- dataset
- Instruction-aware 视觉提取架构
- Dataset Balance
- 实验
- 参考
Introduction
作者表示,与nlp任务不同,多模态任务由于引入额外的视觉输入,它的任务更加多样化,这似的联合多个模型是一个有挑战性的工作。
以前的方法大多要依靠LLM的生成能力,LLM在微调text- only instruction比微调Vision- language 的表现要更让人满意。
为了解决上述问题,作者提出了Instruct BLIP,一个多模态微调框架。
它由BLIP-2初始化,在微调期间,只微调Q- former保持LLM与image encoder frozen。
这篇文章的贡献主要是:
- 合并了当前的多模态数据集,并转换成指令微调的形式。
- 提出了新的 instruction-aware 视觉提取架构。
- 验证了有效性。
Method
dataset
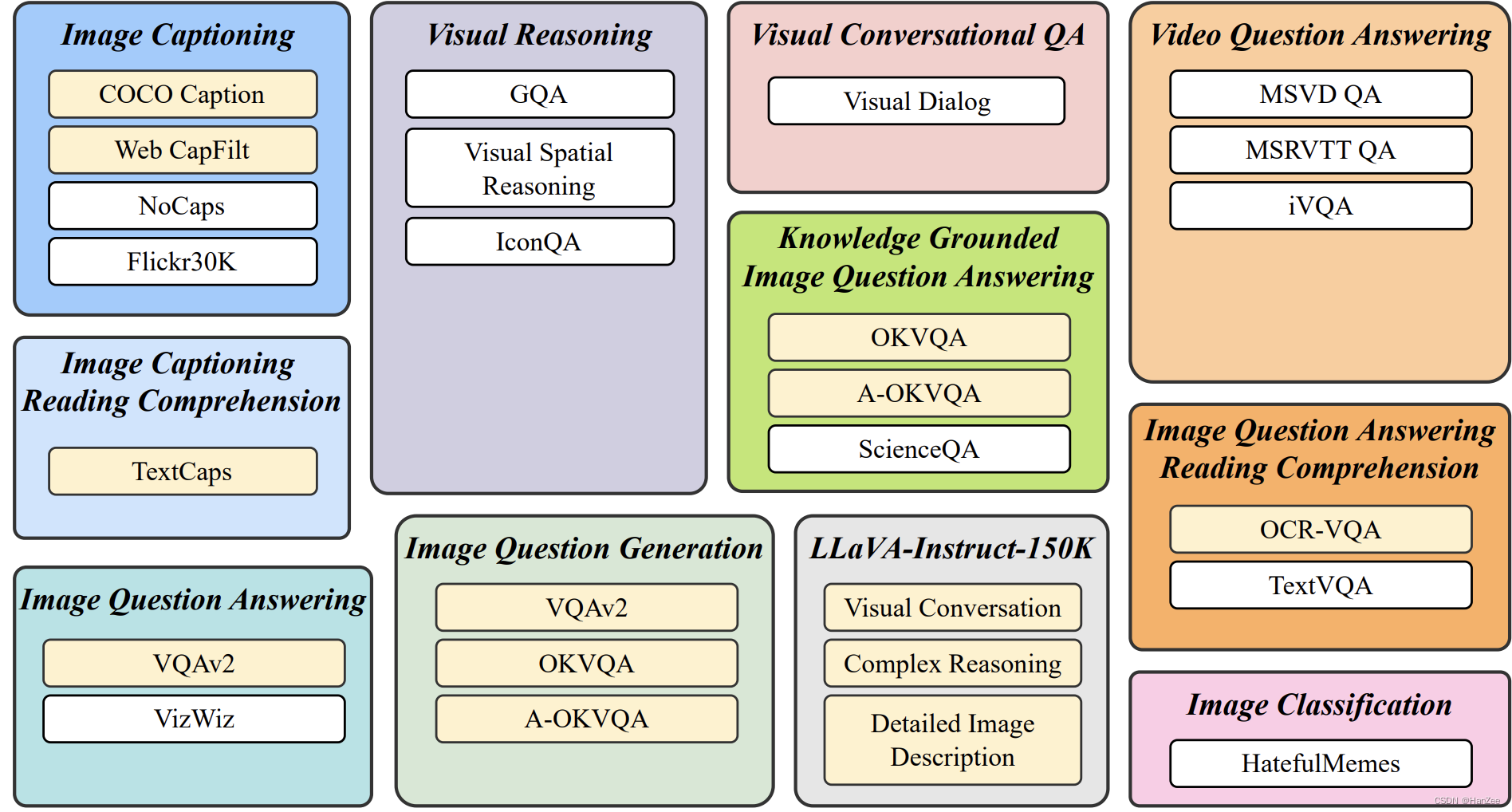
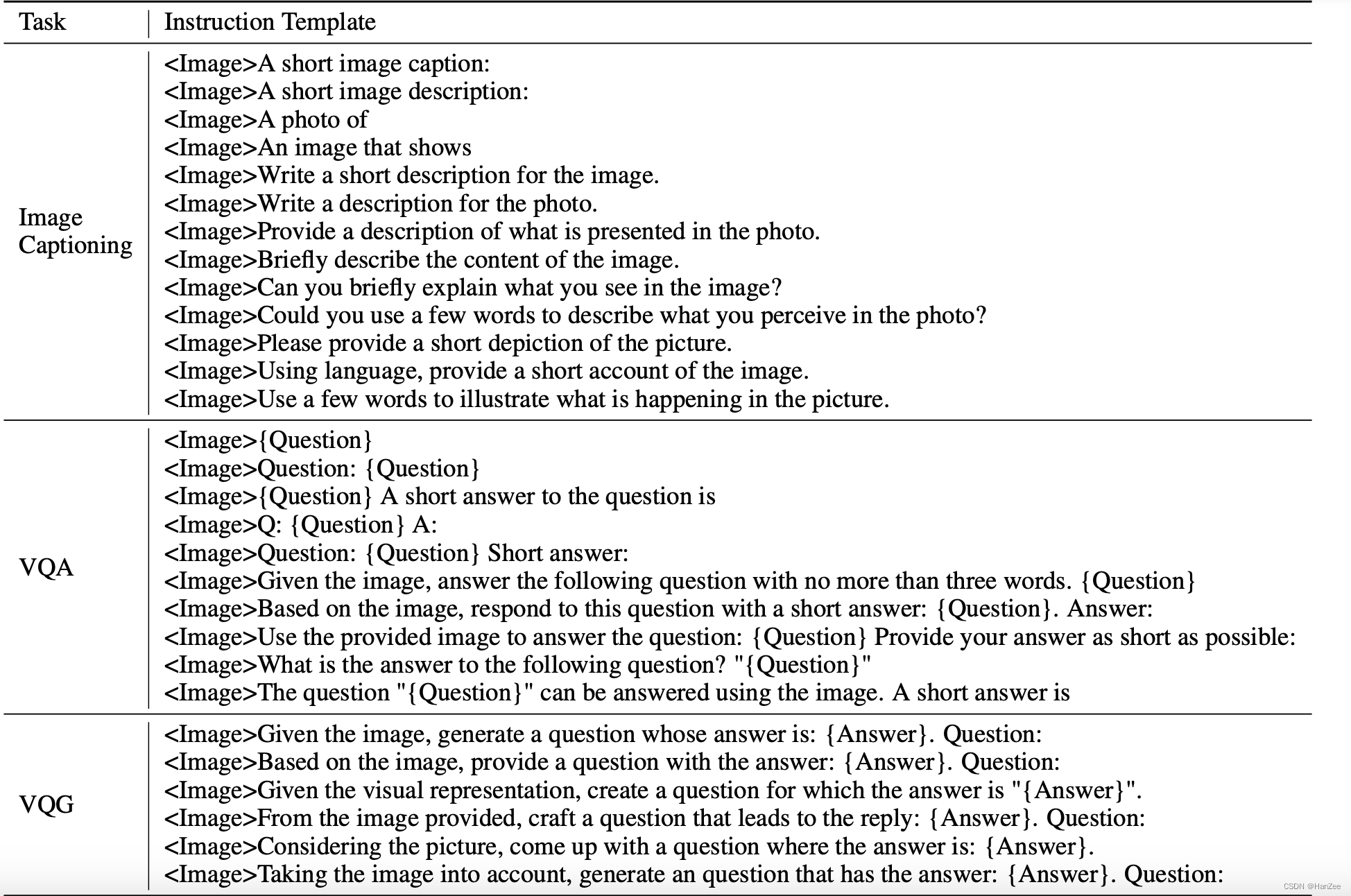
联合上面的数据集,为不同的任务设置了不同的prompt template。
为了更好的验证性能,把验证集分割为两部分:
训练中见过此类任务,但是没见过这个样本,用于测试在相同任务unseen数据的性能。
训练集没见过此类任务,用于测试在unseen task 的unseen sample 的 迁移能力。
如果涉及到文本 图像,增加OCR token。
Instruction-aware 视觉提取架构
首先是 数据上的变化:
- 用相同的图像采取不同的instruction
- 不同的图像采取相同的instruction
这应该是增加泛化的一种方式。
然后是结构上的变化:
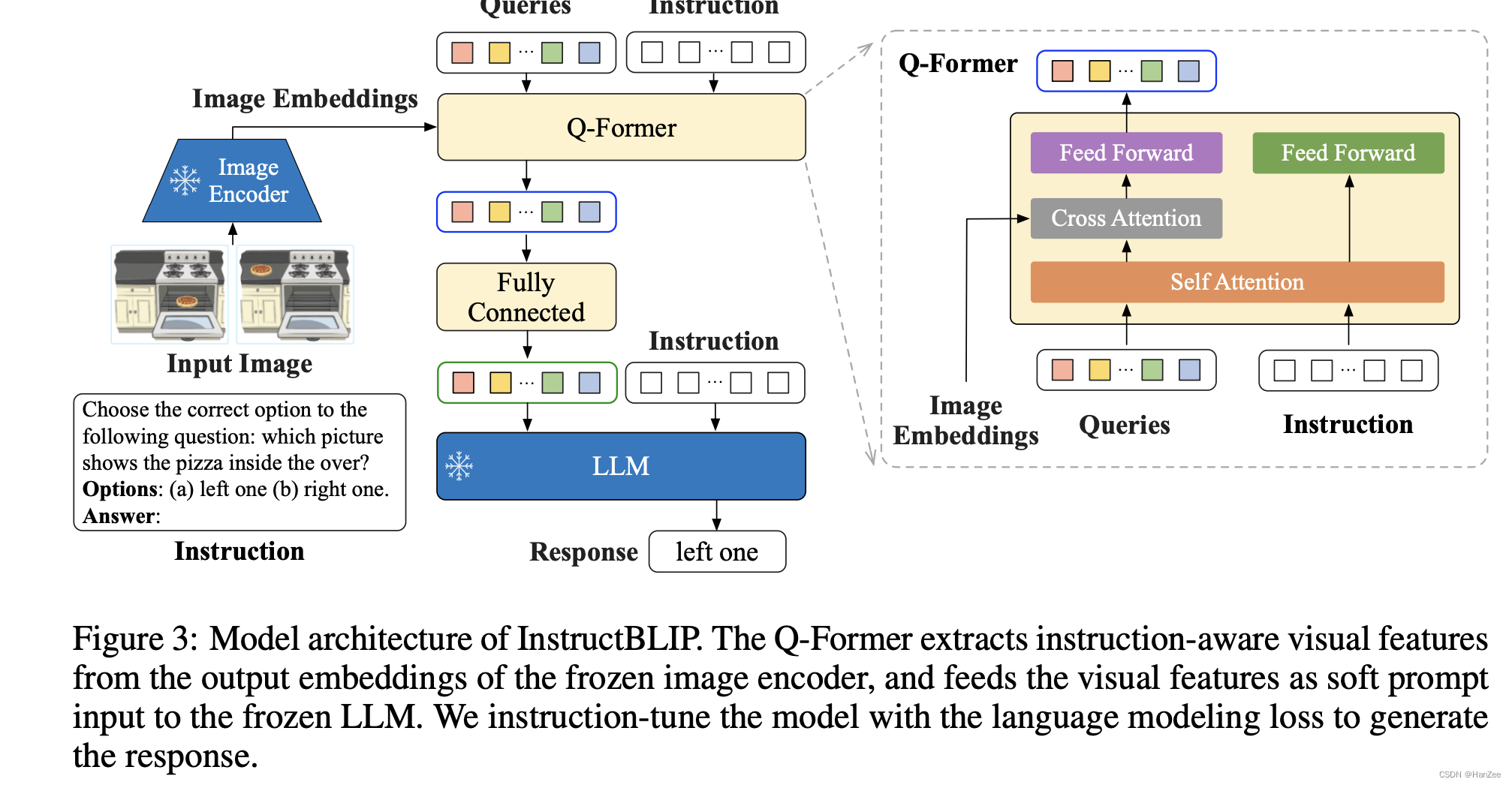
Image - Coder、LLM都被冻结,只微调Q- former。MiniGPT4则是微调Q- former与LLm之间 projection linear。
与BLIP2不同的是作者在Q- former阶段与LLM阶段都输入了Instruction。
由于在blip2预训练Q- former时,它就可以提取文本特征,然而到了推理阶段,就把这个Instruction放到了LLM侧。
在Q-fomer 阶段引入Instruction可以在计算self- attention的时候,query也考虑了instruction来抽取image- encoder的特征。
作者也通过实验证明了这样做的有效性。
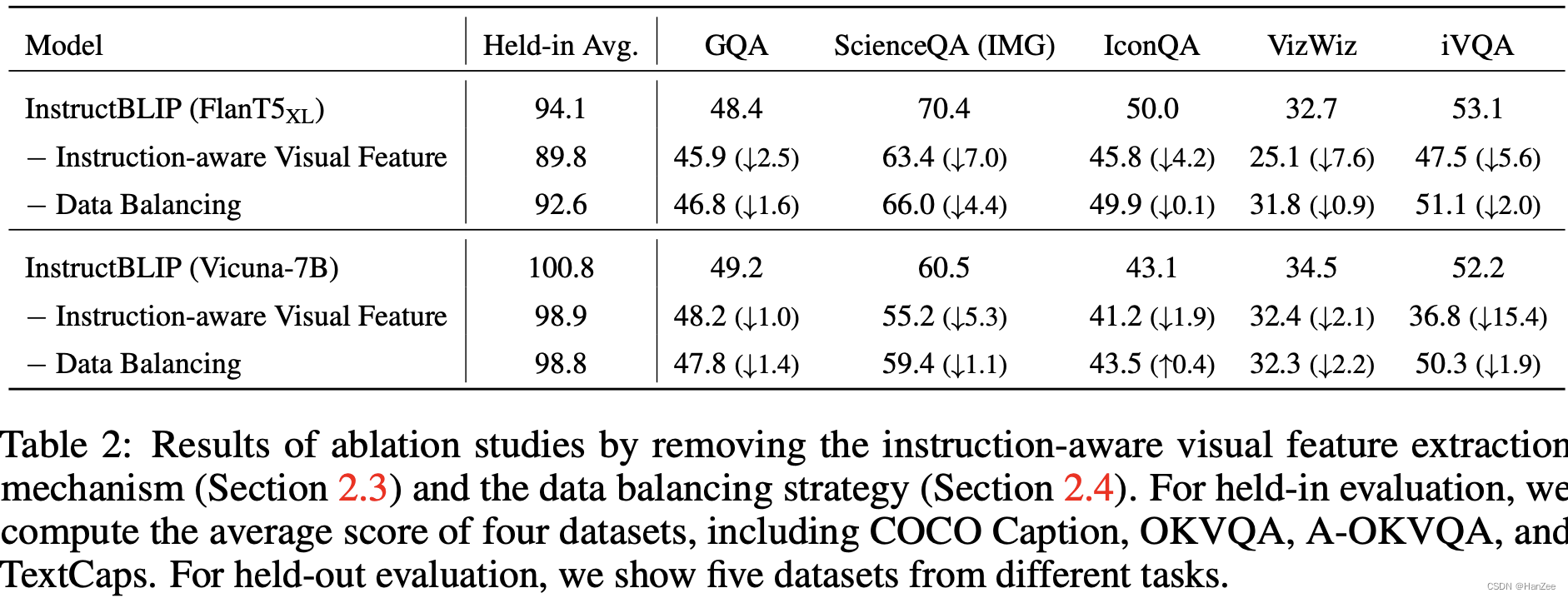
Dataset Balance
由于作者混合多个数据集,每个数据集的大小不同,如果采用均匀采样,可能会造成大数据集underfitting,小数据集overfitting。所以作者对不同的数据集采取不同的sample比例。
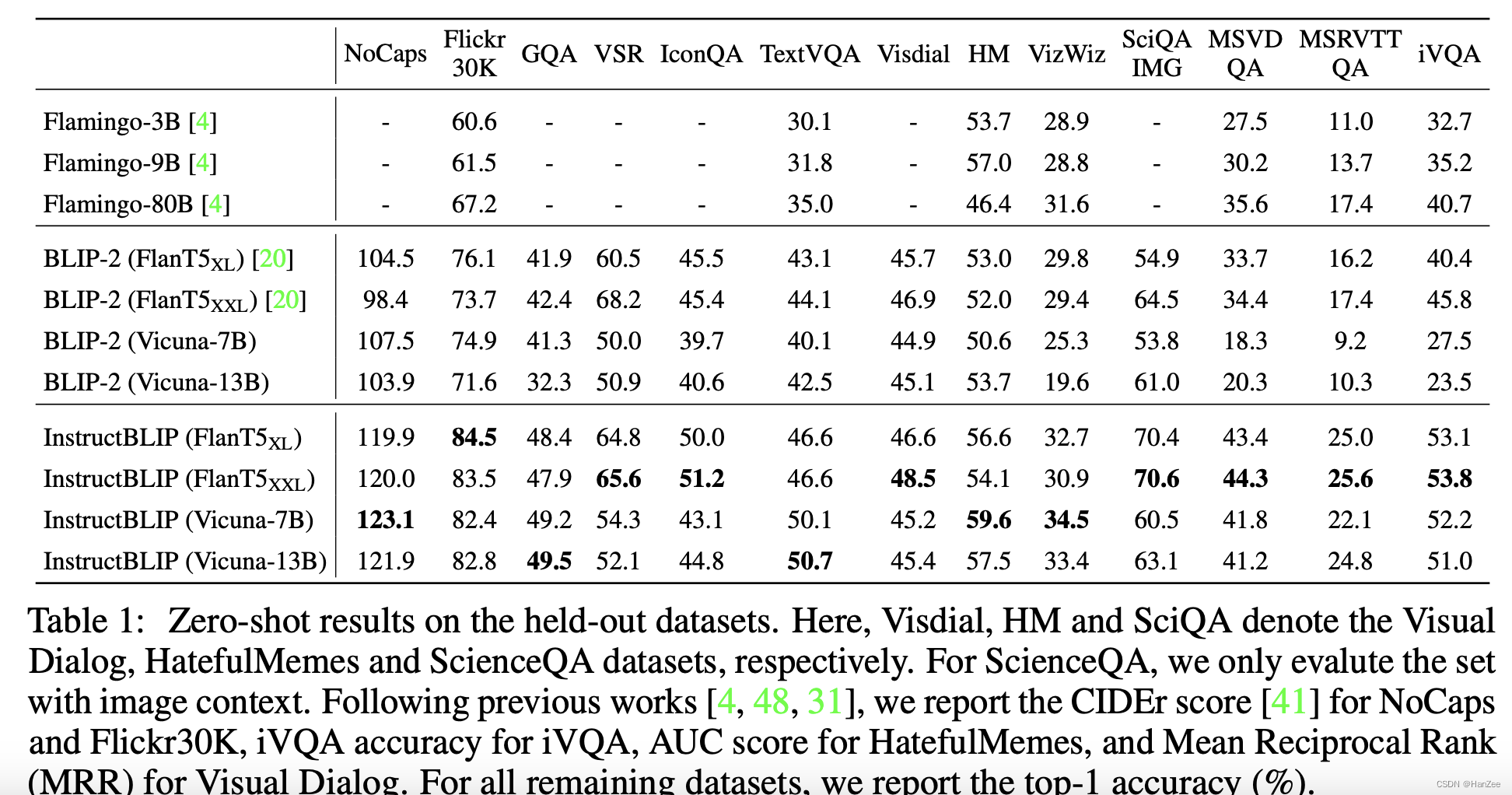
实验
参考
https://arxiv.org/pdf/2305.06500.pdf





![[GYCTF2020]EasyThinking](https://img-blog.csdnimg.cn/19da4de9723c42cf991bd97cad52e353.png)


![[golang gin框架] 33.Gin 商城项目- 集成支付宝微信支付、生成支付二维码、监听处理异步通知跳转到订单页面](https://img-blog.csdnimg.cn/img_convert/a096f06a112c19ae4ae3fbc0eb11ccdf.png)