文章目录
- 前言
- 文献阅读
- 摘要
- 介绍
- 方法
- 模型框架
- 评价指标
- 结果
- 结论
- 时间序列预测
- 总结
前言
本周阅读文献《A Hybrid Model for Water Quality Prediction Based on an Artificial Neural Network, Wavelet Transform, and Long Short-Term Memory》,文献主要提出了基于人工神经网络、小波变换和长短期记忆网络的ANN-WT-LSTM模型进行预测分析。针对水质缺失数据,利用人工神经网络,根据水质数据的时间序列信息填充缺失值。然后,利用小波变换对水质时间序列进行分解和重构,消除噪声的影响,提高模型对样本外数据的预测精度,有效地预测水质时间序列数据的短期和长期动态趋势。另外,主要阅读了两篇文献,总结文献中用到的提高预测能力的方法,通过优化技术优化超参数以及通过变分模态分解(VMD)对输入数据进行降噪。
This week,I read an article which proposes the ANN-WT-LSTM model based on an artificial neural network, wavelet transform, and long short-term memory network, using the water quality data for prediction analysis. For missing water quality data caused by instrument failure, this study used an artificial neural network to fill in the missing values based on the time-series information of water quality data. Then, we used wavelet transform to decompose and reconstruct the water quality time series, in order to remove the impact of short-term random disturbance noise, improve the prediction accuracy of the model on out-of-sample data, and the ability to predict future dynamic trends, so that it can more effectively predict the short-term as well as long-term dynamic trends in water quality time-series data.In addition, I mainly read two articles which improve the prediction ability by optimizing the hyperparameters through optimization techniques and variational mode decomposition to denoise the input data.
文献阅读
题目:A Hybrid Model for Water Quality Prediction Based on an Artificial Neural Network, Wavelet Transform, and Long Short-Term Memory
作者:Junhao Wu 1 andZhaocai Wang 2,*ORCID
摘要
清洁水是人类和其他生物赖以生存的不可或缺的基本资源。因此,建立水质预测模型来预测未来水质状况具有重要的社会和经济价值。本研究基于人工神经网络(ANN)、离散小波变换(DWT)和长短期记忆(LSTM)构建了晋江水质预测模型。首先,利用多层感知器神经网络,根据本研究水质数据集中的时间序列处理缺失值;其次,利用Daubechies wavelet5 (Db5)将水质数据分为低频信号和高频信号;然后,将信号用作LSTM的输入,并将LSTM用于训练,测试和预测。最后,将预测结果与非线性自回归(NAR)神经网络模型、ANN-LSTM模型、ARIMA模型、多层感知器神经网络、LSTM模型和CNN-LSTM模型进行了对比。结果表明,本研究提出的ANN-WT-LSTM模型在许多评价指标上的表现优于以前的模型。因此,本研究的研究方法可为晋江等流域水质监测与治理提供技术支持和实践参考。
介绍
目前,尽管学者们在水质预测领域提出了大量的研究方法,但传统统计模型的预测结果对于波动较大、长期趋势较大的时间序列并不令人满意。例如,回归分析模型比较简单,但对统计数据的要求较高,要求样本量大,数据分布模式好;时间序列模型具有比较完善的理论基础,但其预测精度较差;灰色预测模型适用于历史数据较小且不连续的情况,但该模型容易受到不稳定数据的影响,导致预测误差较大;支持向量机适用于小样本,但对参数和核函数的选择更敏感。此外,传统的单一深度学习模型,如反向传播神经网络(BPNN)和RBFNN,缺乏对历史信息的记忆能力。此外,大多数缺失数据填充方法无法有效处理数据集中的时间序列信息,导致缺失值估计误差较大。因此,本研究尝试利用人工神经网络填充水质缺失信息,将小波变换和LSTM模型综合应用于水质预测领域,并将预测结果与ANN-LSTM、ARIMA、NARNN、CNN-LSTM和DWT-CNN-LSTM模型进行比较,以证明所提模型的有效性。
方法
数据集:本研究使用的数据集选自晋江流域石龙段水质自动监测周报。在众多水质评价指标中,我们选择了溶解氧(DO)、高锰酸盐指数(CODMn)、氨氮(NH3-N)和TP(总磷),这是研究对象最具代表性的四个指标。然后,分析数据集并找到缺失值。
使用皮尔逊相关系数来分析每个数据集的相关性。
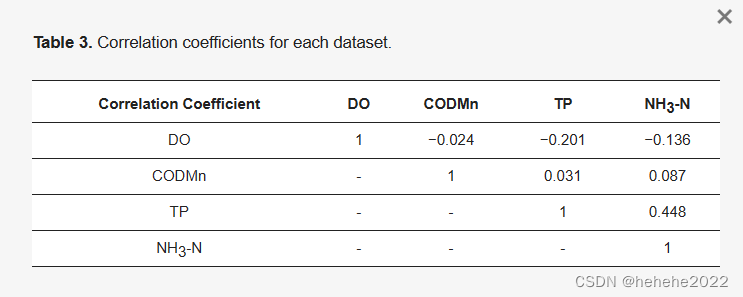
从上面的相关性分析表中可以看出,
DO数据集与CODMn、TP和NH3-N 呈负相关;CODMn数据集与TP呈弱正相关,与NH3-N呈显著正相关;TP数据集与NH3-N呈显著正相关。
模型框架
本研究引入用于水质数据预处理的信号时间和频率分解方法,构建基于“分解-预测-重构”的混合预测模型,以提高整体预测精度。
混合模型由五个组件组成:
1.数据预处理:首先对采集到的水质数据进行描述性分析,找到缺失值,通过人工神经网络估计缺失值,然后归一化以消除维度的影响。
2.离散小波变换:采用db5小波技术对水质时间序列数据集进行分解。
3.模型训练、检测:将db5小波分解得到的每个数据集的高频和低频信号按照固定的比例拆分为训练集和测试集。在这项研究中,我们将每个数据集的前 421 个集合设置为训练集,将最后 22 个集合设置为测试集。随后,我们使用 LSTM 训练每个训练集并调整 LSTM 的相关参数,例如学习率和最大迭代次数。
4.将各子序列分解测试集得到的预测叠加,得到最终的预测结果。
5.模型评估:本研究使用四个指标——MSE、RMSE、MAE 和 MAPE——来评估模型的性能。
数据规范化
数据规范化是机器学习中挖掘数据的基本任务。在实际研究中,不同的方法和评价指标往往有不同的尺度和单位,会产生不同的数据分析结果。为了减少数量之间的相对关系,消除指标之间维度的影响,必须对数据进行规范化,以实现数据指标之间的可比性,并实现数据优化的期望。对原始数据进行归一化,使指标处于同一数量级,便于综合比较和评估。常用的归一化方法包括min-max normalization、Z-score normalization。最小-最大归一化(也称为异常值归一化)是原始数据的线性变换,使得结果值映射到 0 到 1 之间。
本研究中使用的最小-最大归一化变换函数如下:

ANN
在采集时间序列数据的过程中,由于采集、存储、人为错误等原因,会导致最终数据集中某些数据的单个或多个属性丢失或单个或多个记录的丢失。这些数据称为缺失数据。数据的缺失或不完整给数据挖掘带来了许多困难,会导致分析结果的偏差,误导用户决策,造成不良后果。有几种方法可以处理缺失数据,例如the deletion method删除方法,missing value filling method based on a statistical model基于统计模型的缺失值填充方法或the method based on parameter estimation基于参数估计的方法。随着机器学习的发展,研究人员可以逐渐将各种机器学习算法应用于缺失值填充领域,可以在一定程度上解决传统方法无法处理的非线性问题。用于缺失值估计的机器学习方法包括KNN方法,人工神经网络等。
本研究采用MLP神经网络对晋江水质数据缺失值进行估算。输出层的激活函数是恒定的。单层感知器是最简单的神经网络,由输入层和输出层组成,输入层和输出层直接连接。MLP神经网络包含输入层、输出层和若干隐藏层,是一种基于BP算法训练的多层前馈神经网络。输入信号通过输入层向前传递到隐藏层,随后对隐藏层中的神经元进行计算处理,然后传递到输出层,这是一个前向传输过程,其中MLP神经网络的输出仅依赖于当前输入,而不依赖于过去或未来的输入;因此,MLP神经网络也被称为多层前馈神经网络。在众多神经网络架构中,MLP 神经网络结构简单、易于实现,具有良好的容错性、鲁棒性和出色的非线性映射能力。
评价指标
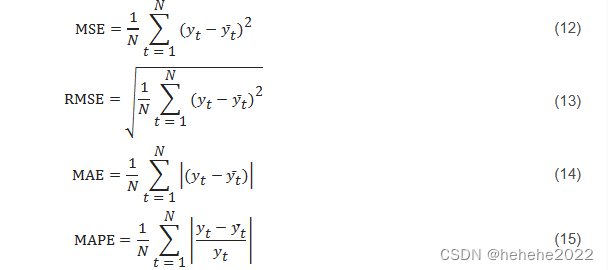
MAE用于测量预测值和实际值之间的平均绝对误差,RMSE用于测量预测值和实际值之间的偏差(对异常值敏感),MAPE用于测量预测值和实际值之间的平均相对误差。
结果
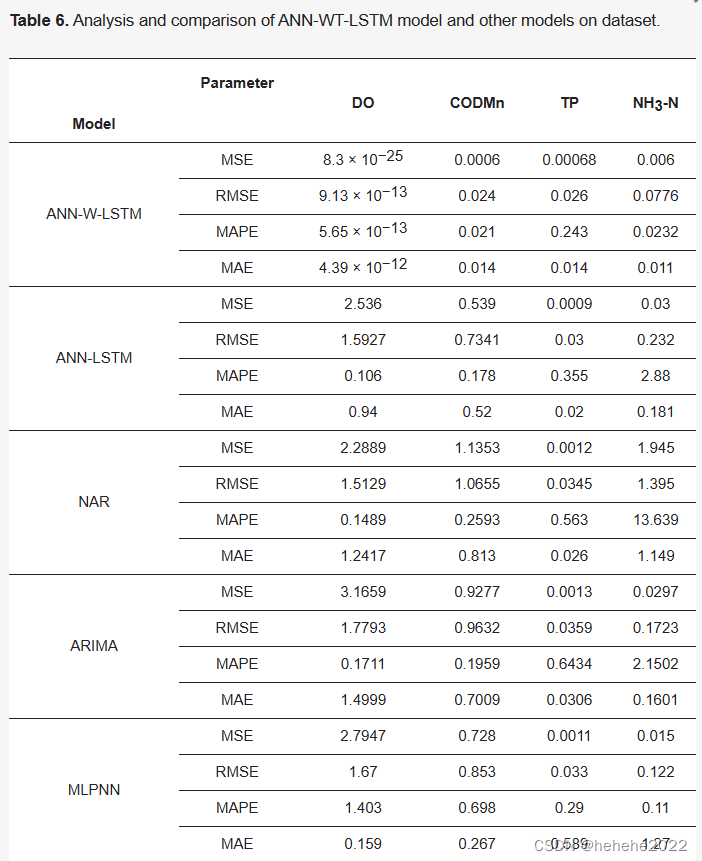
从以上结果和误差图像可以看出,与MLPNN模型、ANN-LSTM模型、NAR神经网络模型、CNN-LSTM模型、SSA-LSTM、SSA-BPNN模型和ISSA-BPNN模型相比,ANN-WT-LSTM模型在DO数据集上的预测精度有了显著提高。
结论
本文以我国晋江流域水质数据为研究对象,提出了基于人工神经网络、小波变换和长短期记忆网络的ANN-WT-LSTM模型进行预测分析。针对仪器故障导致的水质缺失数据,本研究利用人工神经网络,根据水质数据的时间序列信息填充缺失值。然后,利用小波变换对水质时间序列进行分解和重构,以消除短期随机扰动噪声的影响,提高模型对样本外数据的预测精度和预测未来动态趋势的能力,从而更有效地预测水质时间序列数据的短期和长期动态趋势。随后,与ANN-LSTM模型和NAR神经网络模型相比,结果表明,本研究提出的ANN-WT-LSTM在所有评价指标上均优于其他模型,有效提高了水质预测的准确性,
时间序列预测
在之前阅读的文献中,改进提高模型的预测能力基本是通过对输入数据进行降噪,常用到的降噪方法是小波变换;下面几篇文献是通过变分模态分解(VMD)对输入数据进行降噪。
A water quality prediction model based on variational mode decomposition and the least squares support vector machine optimized by the sparrow search algorithm (VMD-SSA-LSSVM) of the Yangtze River, China
文献实现:
1.应用VMD方法对水质参数监测数据进行分解和重构,实现自适应信号分解和降噪;
2.将SSA引入LSSVM(支持向量机的变体)中,计算LSSVM模型的最优参数值,构建SSA-LSSVM模型;
3.提出一种VMD-SSA-LSSVM混合方法作为水质预测的替代框架,该方法可以同时考虑多个输入变量和不同时间尺度的信息。
A hybrid deep learning technology for PM2.5 air quality forecasting
文献实现:
1.采用变分模态分解(VMD)来分解PM2.5频域中的非周期信号。通过将复数信号分解为多个谐波子序列来降低输入信号频域的复杂性。
2.提出前沿的双向长短期记忆神经网络(BiLSTM)预测PM2.5的时间序列数据。
总结
超参数优化技术
超参数搜索有几种方法,即手动搜索、网格搜索、随机搜索、贝叶斯优化和元启发式算法。在手动搜索方法中,根据试错过程选择超参数值集,直到模型产生最低的训练误差。同时,在网格搜索中,为每个超参数选择一组值,并训练所选值的所有组合,然后进行测试以找到最佳选择。除此之外,随机搜索是一种随机训练和测试已设置的搜索空间或网格内超参数组合的方法。贝叶斯优化是一种全局优化方法,它构建概率模型来近似目标函数,即代理函数。
神经网络中超参数的选择对算法的稳定性和准确性有很大影响,正是关键参数选择不当导致当前许多预测模型的精度较低。解决方法是通过元启发式优化算法优化目标参数,一些常见的包括SSA、粒子群优化算法、蝙蝠算法、灰狼优化算法、蜻蜓算法、鲸鱼优化算法、蝗虫优化算法等。
数据分解
水质监测数据可以看作是带有噪声的非线性和非平稳信号序列。噪声会对水质数据预测中的非线性变化分析产生负面影响。有效分离信号与噪声的任务是研究非线性变化的前提。目前,常用的非线性信号去噪方法包括小波变换,经验模态分解(EMD)和集合经验模态分解(EEMD)等。 小波变换广泛用于信号降噪,但由于不同的小波基具有不同的降噪效果,因此需要选择合适的小波基数以达到更好的降噪效果。EMD方法是一种自适应信号处理方法,但它缺乏严格的数学基础,并且存在模态混叠和端点效应等问题。针对EMD方法的缺点,EEMD方法虽然可以在一定程度上抑制混模现象,但需要较大的计算负载,并且该算法在信号中加入高斯噪声以克服EMD方法的缺点,因此每种降噪效果都不同。VMD是一种自适应非递归信号分解方法,旨在克服EMD和EEMD的缺点。与EMD和EEMD相比,VMD具有坚实的理论基础,克服了递归分解算法中模态混叠和计算效率低的缺点。VMD自提出以来在非线性信号降噪方面得到了广泛的应用,但基于VMD的水质短期预测比较少。
这周有两门课程结课,要交课程报告和考试,所以周报的内容写的比较少,之后会补上。


![[笔记]深入解析Windows操作系统《四》管理机制](https://img-blog.csdnimg.cn/5634f75679d54482ad127c9eb485108d.png)