1、什么是读写分离?
读写分离,基本的原理是让主数据库处理事务性增、删、改操作(insert、update、delete),而从数据库处理select查询操作。数据库复制被用来把事务性操作导致的变更同步到集群中的从数据库。
2、为什么要读写分离?
数据库的“写”(写10000条数据可能要三分钟)操作时比较耗时的。
数据库的“读”(读10000条数据可能只要5秒钟)。
所以读写分离,解决的是数据库写入时影响了查询的效率。
3、什么时候要读写分离?
数据库不是一定要读写分离,如果程序使用数据库较多时,而更新少,查询多的情况下会考虑使用。利用数据库主从同步,再通过读写分离可以分担数据库压力,提高性能。
4、主从复制与读写分离
在实际生产中,对数据库的读和写都在同一数据库服务器中,是不能满足实际需求的。无论是在安全性、高可用性还是高并发等各个方面都是完全不能满足实际需求的。因此,通过主从复制的方式来同步数据,再通过读写分离来提升数据库的并发负载能力。有点类似于rsync,但是不同的是rsync是对磁盘文件做备份,而mysql主从复制是对数据库中的数据、语句做备份。
5、mysql支持的复制类型
(1)statement:基于语句的复制。在服务器上执行sql语句,在从服务器上执行同样的语句,mysql默认采用基于语句的复制,执行效率高。
(2)row:基于行的复制。把改变的内容复制过去,而不是把命令在从服务器上执行一遍。
(3)mixed:混合类型的复制。默认采用基于语句的复制,一旦发现基于语句无法精确复制时,就采用基于行的复制。
6、主从复制的工作过程
(1)master节点将数据的改变记录成二进制日志(bin log),当master节点数据发生变化时,会将数据写入bin log日志当中。
(2)slave节点会定时向master节点bin log日志进行探测,当其发生改变时,slave会发送一个i/o线程请求master节点发送其二进制事件。
(3)master会对每一个i/o线程启动一个对应的dump线程,并向其发送二进制事件,slave接受到master发送的二进制事件后会将其保存在salve的中继日志当中(realy log),salve会启动sql线程,读取realy log中的二进制事件,并在本地重放,即解析成sql语句并逐条执行,使本地数据与master节点的数据保持一致,最后i/o、sql线程会进入休眠,等待下一次被唤醒。
注:
●中继日志通常会位于 OS 缓存中,所以中继日志的开销很小。
●复制过程有一个很重要的限制,即复制在 Slave上是串行化的,也就是说 Master上的并行更新操作不能在 Slave上并行操作。
mysql主从复制搭建
master节点:192.168.142.10
slave1节点:192.168.142.20
salve2节点:192.168.142.30
----Mysql主从服务器时间同步----
主服务器(10):



从服务器(20、30)
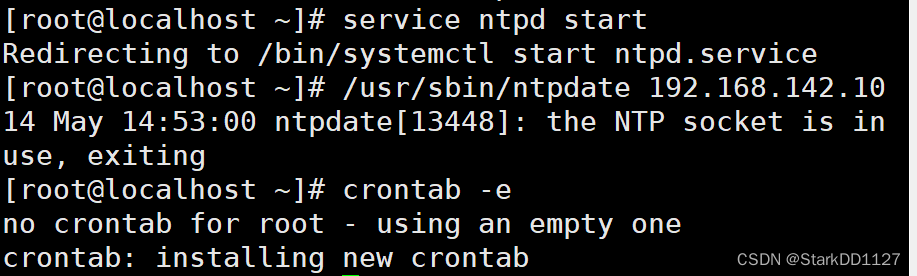

----主服务器的mysql配置-----


![]()

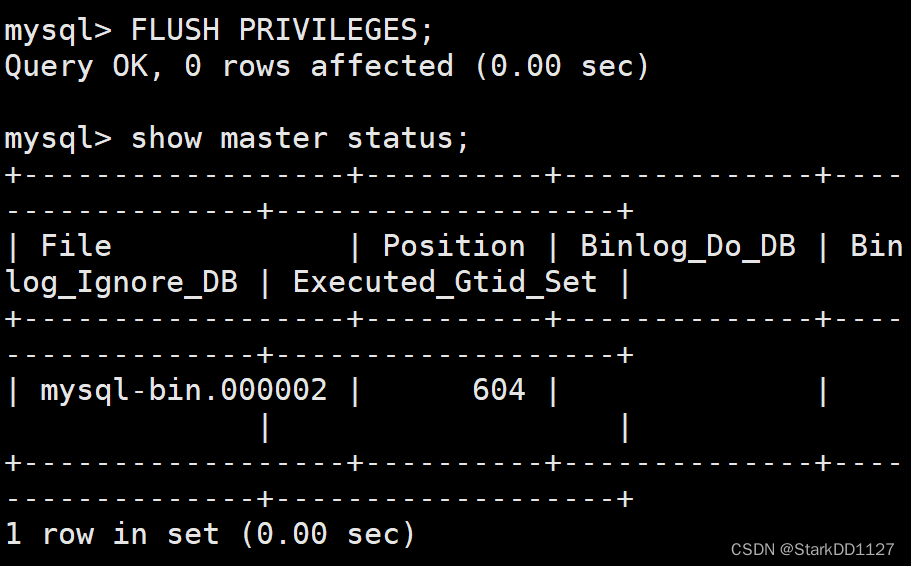
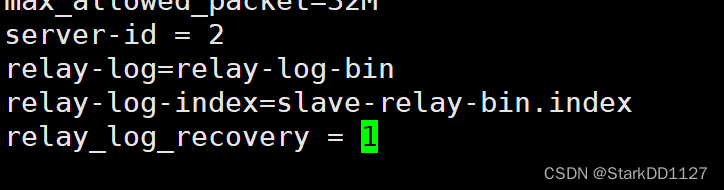
----从服务器的mysql配置----

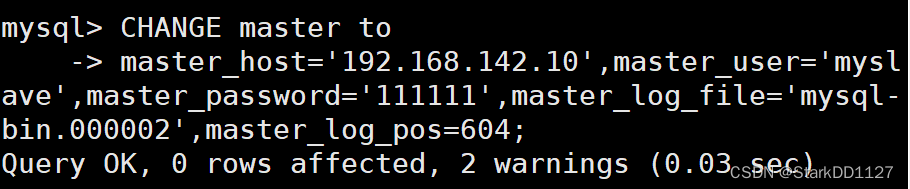
确保slave_io_running和slave_aql_running都是yes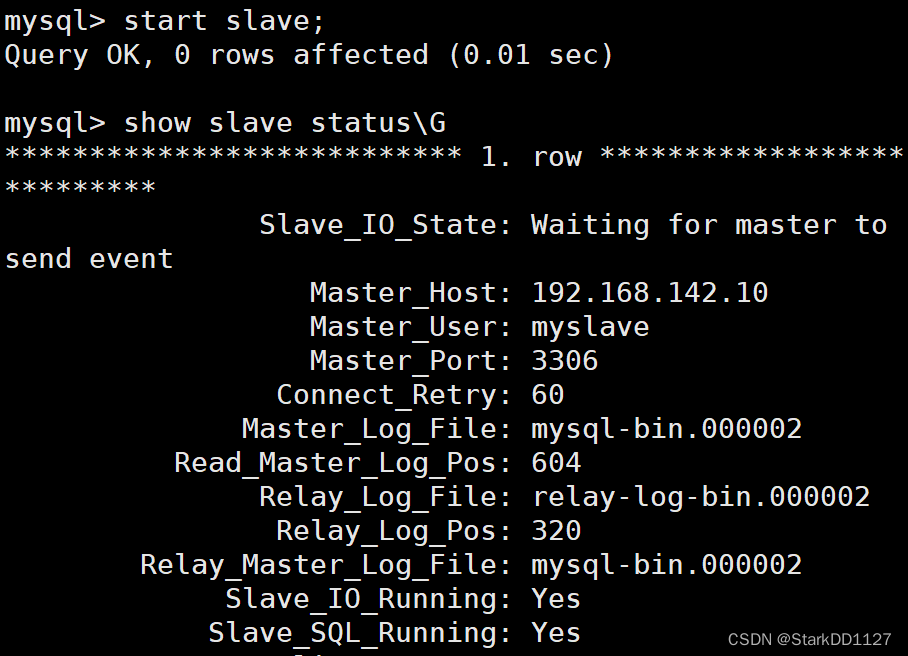
两台都是如此。
验证
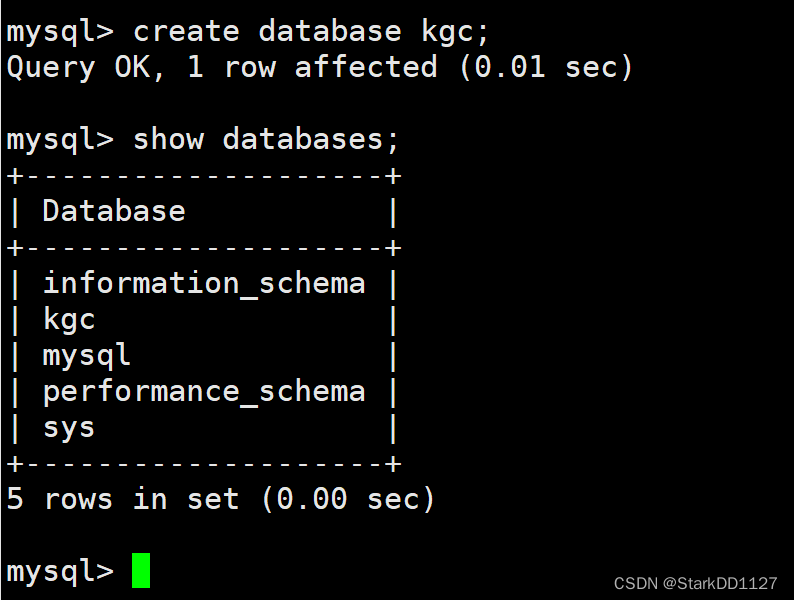
成功!
============MySQL主从复制延迟=============
1、master服务器高并发,形成大量事务
2、网络延迟
3、主从硬件设备导致
cpu主频、内存io、硬盘io
4、是同步复制、而不是异步复制
从库优化Mysql参数。比如增大innodb_buffer_pool_size,让更多操作在Mysql内存中完成,减少磁盘操作。
从库使用高性能主机。包括cpu强悍、内存加大。避免使用虚拟云主机,使用物理主机,这样提升了i/o方面性。
从库使用SSD磁盘
网络优化,避免跨机房实现同步
----验证主从复制效果----
主服务器上进入执行 create database db_test;
去从服务器上查看 show databases;