文章目录
- 基本概念
- 定义一棵树
- 前序遍历
- 中序遍历
- 后序遍历
- BFS广度优先遍历
- DFS深度优先遍历
基本概念
树是一个有n个有限节点组成一个具有层次关系的集合,每个节点有0个或者多个子节点,没有父节点的节点称为根节点,也就是说除了根节点以外每个节点都有父节点,并且有且只有一个。
树的种类比较多,有二叉树,红黑树,AVL树,B树,哈夫曼树,字典树等等。
同时,树有比较多的需要掌握的概念
结点的度:一个结点含有的子结点的个数称为该结点的度;
叶结点或终端结点:度为0的结点称为叶结点;
非终端结点或分支结点:度不为0的结点;
双亲结点或父结点:若一个结点含有子结点,则这个结点称为其子结点的父结点;
孩子结点或子结点:一个结点含有的子树的根结点称为该结点的子结点;
兄弟结点:具有相同父结点的结点互称为兄弟结点;
树的度:一棵树中,最大的结点的度称为树的度;
结点的层次:从根开始定义起,根为第1层,根的子结点为第2层,以此类推;
树的高度或深度:树中结点的最大层次;
堂兄弟结点:双亲在同一层的结点互为堂兄弟;
结点的祖先:从根到该结点所经分支上的所有结点;
子孙:以某结点为根的子树中任一结点都称为该结点的子孙。
森林:由m(m>=0)棵互不相交的树的集合称为森林;
无序树:树中任意节点的子结点之间没有顺序关系,这种树称为无序树,也称为自由树;
有序树:树中任意节点的子结点之间有顺序关系,这种树称为有序树;
二叉树:每个节点最多含有两个子树的树称为二叉树;
完全二叉树:若设二叉树的深度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第 h
层所有的结点都连续集中在最左边,这就是完全二叉树满二叉树:除最后一层无任何子节点外,每一层上的所有结点都有两个子结点的二叉树。
哈夫曼树:带权路径最短的二叉树称为哈夫曼树或最优二叉树;
定义一棵树
public class TreeNode {
public int val;
public TreeNode left;
public TreeNode right;
public TreeNode(int x) {
val = x;
}
public TreeNode() {
}
前序遍历
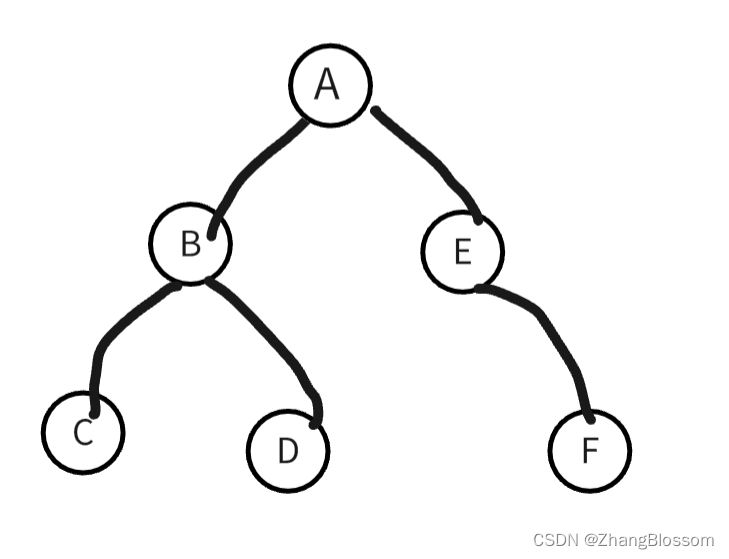
他的访问顺序是:根节点→左子树→右子树
访问顺序为:A-B-C-D-E-F
//递归写法
public static void preOrder(TreeNode tree) {
if (tree == null)
return;
System.out.printf(tree.val + "");
preOrder(tree.left);
preOrder(tree.right);
}
//非递归写法
public static void preOrder(TreeNode tree) {
if (tree == null)
return;
Stack<TreeNode> q1 = new Stack<>();
q1.push(tree);//压栈
while (!q1.empty()) {
TreeNode t1 = q1.pop();//出栈
System.out.println(t1.val);
if (t1.right != null) {
q1.push(t1.right);
}
if (t1.left != null) {
q1.push(t1.left);
}
}
}
中序遍历
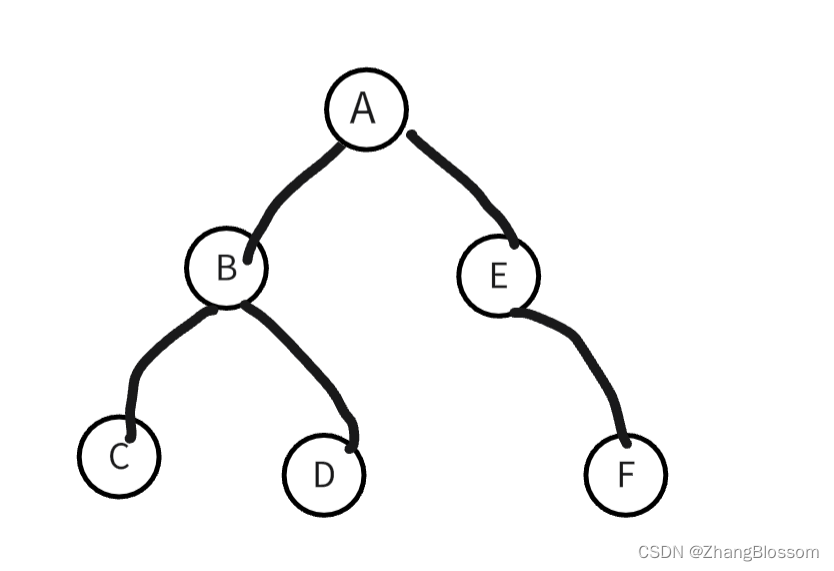
他的访问顺序是:左子树→根节点→右子树
所以下图中序遍历的结果是:C-B-D-A-E-F
访问顺序如下
//递归写法
public static void inOrderTraversal(TreeNode node) {
if (node == null)
return;
inOrderTraversal(node.left);
System.out.println(node.val);
inOrderTraversal(node.right);
}
//非递归的写法
public static void inOrderTraversal(TreeNode tree) {
Stack<TreeNode> stack = new Stack<>();
while (tree != null || !stack.isEmpty()) {
while (tree != null) {
stack.push(tree);
tree = tree.left;
}
if (!stack.isEmpty()) {
tree = stack.pop();
System.out.println(tree.val);
tree = tree.right;
}
}
}
后序遍历
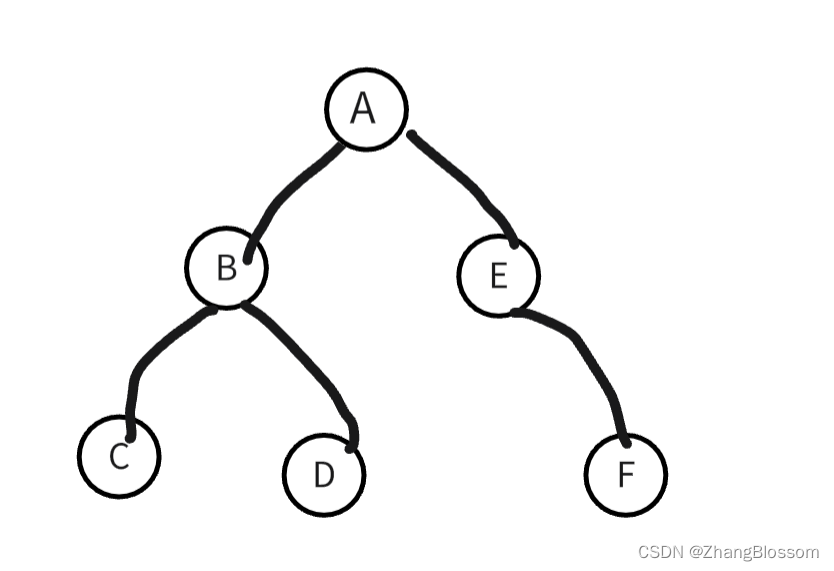
他的访问顺序是:左子树→右子树→根节点
所以上图前序遍历的结果是:C-D-B-F-E-A
//递归写法
public static void postOrder(TreeNode tree) {
if (tree == null)
return;
postOrder(tree.left);
postOrder(tree.right);
System.out.println(tree.val);
}
//非递归的写法
public static void postOrder(TreeNode tree) {
if (tree == null)
return;
Stack<TreeNode> s1 = new Stack<>();
Stack<TreeNode> s2 = new Stack<>();
s1.push(tree);
while (!s1.isEmpty()) {
tree = s1.pop();
s2.push(tree);
if (tree.left != null) {
s1.push(tree.left);
}
if (tree.right != null) {
s1.push(tree.right);
}
}
while (!s2.isEmpty()) {
System.out.print(s2.pop().val + " ");
}
}
// 或者
public static void postOrder(TreeNode tree) {
if (tree == null)
return;
Stack<TreeNode> stack = new Stack<>();
stack.push(tree);
TreeNode c;
while (!stack.isEmpty()) {
c = stack.peek();
if (c.left != null && tree != c.left && tree != c.right) {
stack.push(c.left);
} else if (c.right != null && tree != c.right) {
stack.push(c.right);
} else {
System.out.print(stack.pop().val + " ");
tree = c;
}
}
}
BFS广度优先遍历
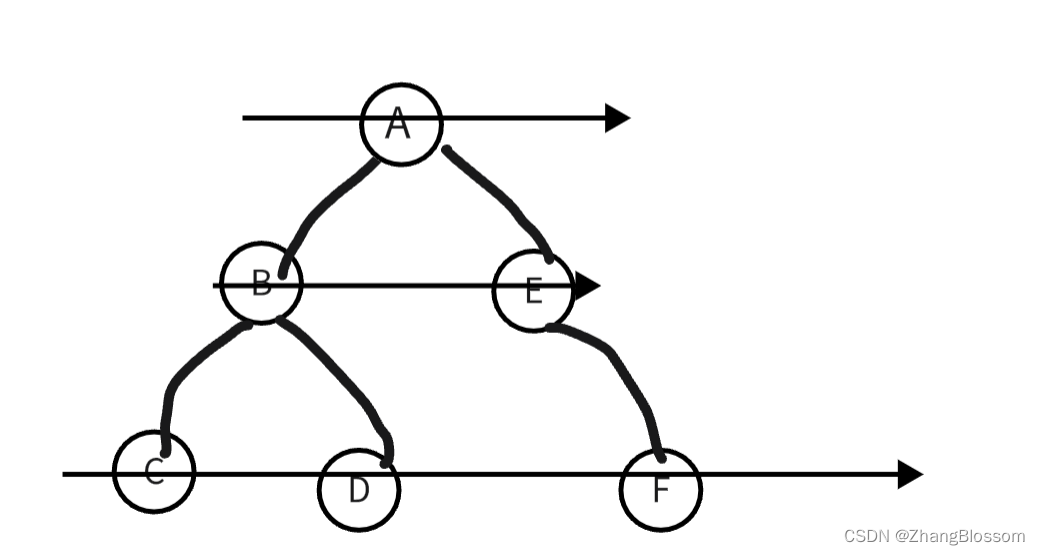
他的访问顺序是:先访问上一层,在访问下一层,一层一层的往下访问
所以上图前序遍历的结果是:A→B→E→C→D→F
// 代码如下
public static void levelOrder(TreeNode tree) {
if (tree == null)
return;
LinkedList<TreeNode> list = new LinkedList<>();//链表,这里我们可以把它看做队列
list.add(tree);//相当于把数据加入到队列尾部
while (!list.isEmpty()) {
TreeNode node = list.poll();//poll方法相当于移除队列头部的元素
System.out.println(node.val);
if (node.left != null)
list.add(node.left);
if (node.right != null)
list.add(node.right);
}
}
// 递归的写法
public static void levelOrder(TreeNode tree) {
int depth = depth(tree);
for (int level = 0; level < depth; level++) {
printLevel(tree, level);
}
}
private static int depth(TreeNode tree) {
if (tree == null)
return 0;
int leftDepth = depth(tree.left);
int rightDepth = depth(tree.right);
return Math.max(leftDepth, rightDepth) + 1;
}
private static void printLevel(TreeNode tree, int level) {
if (tree == null)
return;
if (level == 0) {
System.out.print(" " + tree.val);
} else {
printLevel(tree.left, level - 1);
printLevel(tree.right, level - 1);
}
}
// 如果想把遍历的结果存放到list中,我们还可以这样写
public static List<List<Integer>> levelOrder(TreeNode tree) {
if (tree == null)
return null;
List<List<Integer>> list = new ArrayList<>();
bfs(tree, 0, list);
return list;
}
private static void bfs(TreeNode tree, int level, List<List<Integer>> list) {
if (tree == null)
return;
if (level >= list.size()) {
List<Integer> subList = new ArrayList<>();
subList.add(tree.val);
list.add(subList);
} else {
list.get(level).add(tree.val);
}
bfs(tree.left, level + 1, list);
bfs(tree.right, level + 1, list);
}
DFS深度优先遍历
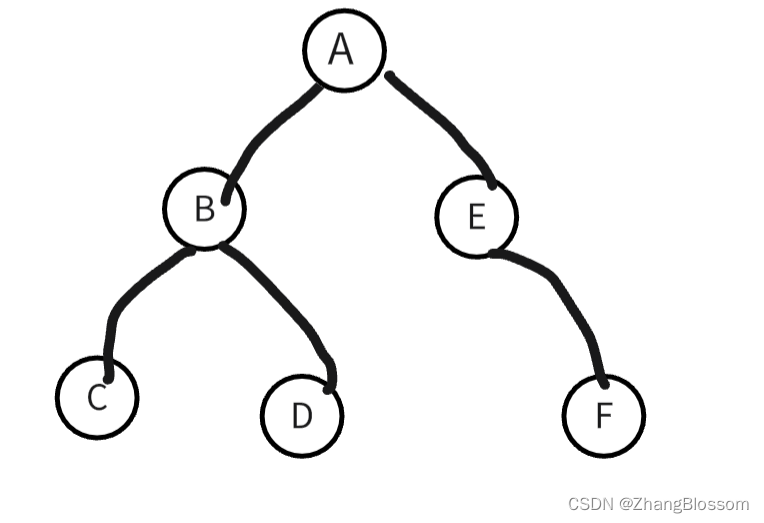
他的访问顺序是:先访根节点,然后左结点,一直往下,直到最左结点没有子节点的时候然后往上退一步到父节点,然后父节点的右子节点在重复上面步骤……
所以上图前序遍历的结果是:A→B→C→D→E→F
// 代码如下
public static void treeDFS(TreeNode root) {
Stack<TreeNode> stack = new Stack<>();
stack.add(root);
while (!stack.empty()) {
TreeNode node = stack.pop();
System.out.println(node.val);
if (node.right != null) {
stack.push(node.right);
}
if (node.left != null) {
stack.push(node.left);
}
}
}
// 递归的写法
public static void treeDFS(TreeNode root) {
if (root == null)
return;
System.out.println(root.val);
treeDFS(root.left);
treeDFS(root.right);
}

![如何使用单片机点亮LED灯,并使用按键控制[51单片机]](https://img-blog.csdnimg.cn/84f6c2c344da47019b624fdb69c0f96a.png)








![[PCIE703]FPGA实时处理器-XCKU060+ARM(华为海思视频处理器-HI3531DV200)高性能综合视频图像处理平台设计资料及原理图分享](https://img-blog.csdnimg.cn/f62c233b747e4d968d03c33ceffb7bec.png)