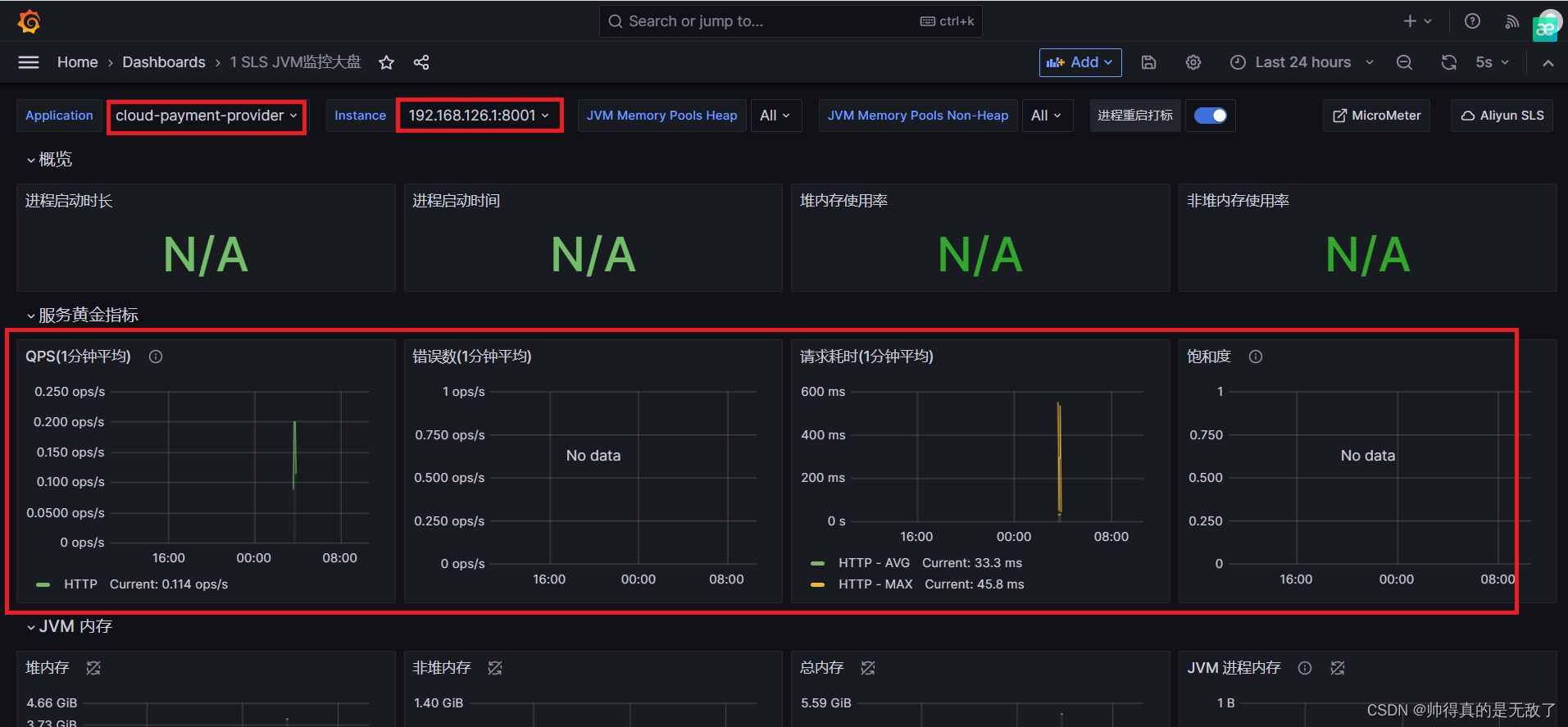
文献阅读(52)—— Integration self-attention and convolution
文章目录
- 文献阅读(52)—— Integration self-attention and convolution
- 先验知识/知识拓展
- 文章结构
- 背景
- 文章方法
- 1. Relating Self-Attention with Convolution
- 文章结果
- 1.分类
- 2. 分割
- 3. 物体检测
- 4. 消融实验
- (1)combination block compared with single block
- (2)group convolution kernels
- (3)超参数
- Contributions
- 总结
- 可借鉴点/学习点?
On the Integration of Self-Attention and Convolution

CVPR
先验知识/知识拓展
-
卷积网络
-
优点
- 参数共享:卷积核在整个图像上移动,共享参数可以减少模型的参数数量,从而大大降低了训练时间和内存消耗。
- 局部感知性:卷积操作只关注局部区域的特征,不受全局噪声的影响,提高了特征的鲁棒性。
- 空间不变性:卷积操作在整个图像上平移具有相同的效果,因此CNN在处理图像时具有一定的空间不变性。
-
缺点
- 大规模卷积核:CNN需要大规模卷积核来捕获更复杂的特征,这会导致模型参数过多,容易出现过拟合。
- 固定感受野:由于卷积核大小和步长是固定的,CNN只能感知固定大小的区域,可能无法捕获所有的特征
-
-
自注意力机制
-
优点
- 动态性:注意力机制可以根据输入数据的不同部分调整权重,使模型可以针对不同的任务集中于不同的特征。
- 灵活性:注意力机制可以与各种神经网络结构集成,如CNN、RNN和Transformer等
-
缺点
- 计算复杂度:由于需要计算每个特征的重要性,注意力机制增加了一定的计算负担,可能导致模型训练时间过长。
- 对抗样本:注意力机制可能降低模型对抗样本的鲁棒性,因为它可能太过集中于某些重要的特征,而忽略其他的特征。
-
-
两者之间
- 卷积操作是一种固定的操作,它在整个图像上提取特征。而注意力机制是一种动态的操作,它可以根据输入数据的不同部分为模型分配不同的权重。此外,卷积操作只能处理局部信息,而注意力机制可以捕获全局信息。
- 传统的卷积利用卷积滤波器权值利用局部感受野上的聚合函数,这在整个特征图中共享。其内在特征对图像处理施加了重要的归纳偏差。相比之下,自注意模块采用基于输入特征上下文的加权平均操作,其中注意权值通过相关像素对之间的相似性函数动态计算。这种灵活性使注意力模块能够自适应地关注不同的区域,并捕获更多的信息特征。
文章结构
- abstract
- related work
- revisiting convolution and self-attention
- method★
- experiments
- conclusion
背景
提出问题:
- 卷积更多在考虑局部信息是一种固态的权重,注意力机制是一种动态的权重。但是两者间是有潜在联系的
- 通过分解可以发现他们均依赖相同的 1*1卷积操作
基于这个样的发现,作者开发了一个混合模型,用最小的计算成本巧妙的整合了自注意力和卷积
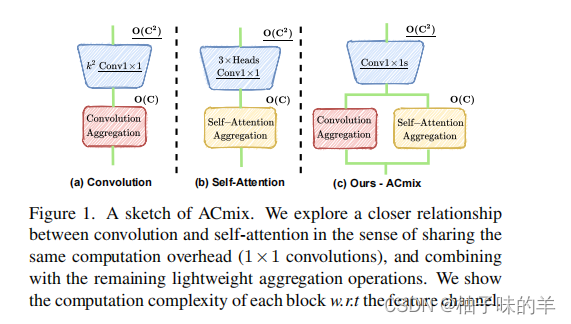
文章方法
ACmix
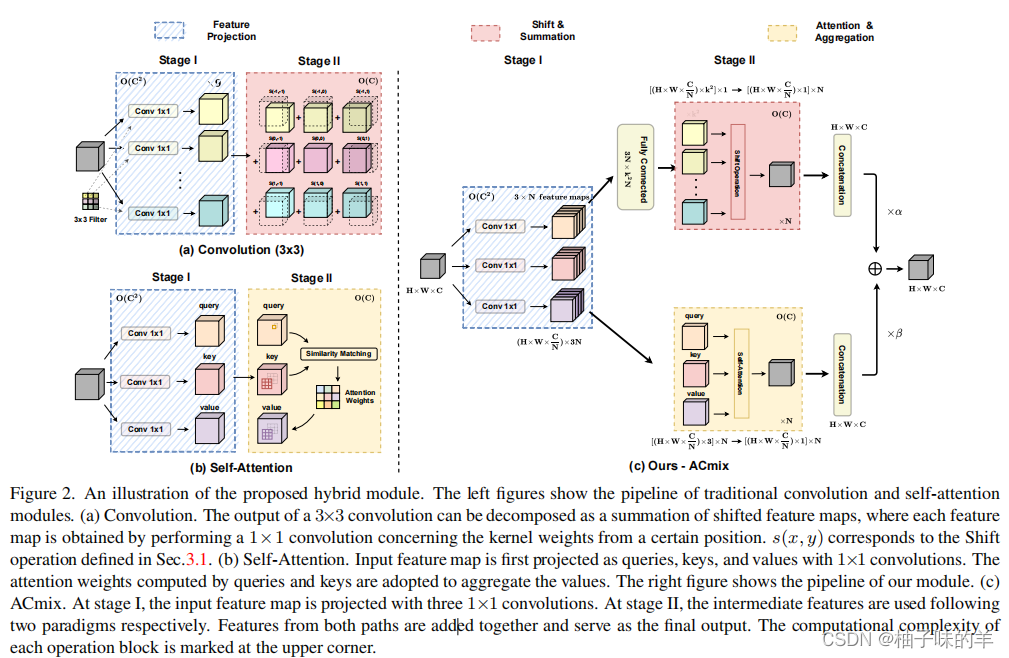
1. Relating Self-Attention with Convolution
-
卷积过程
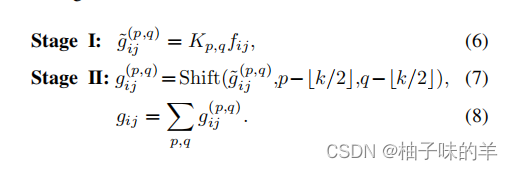
-
自注意力过程
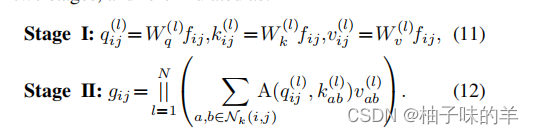
由上面的推断可以看出: -
卷积和自注意力在通过1*1卷积map输入特征时,实际是相同的操作,也是这一步骤开销最大。
-
两者的stage2对于捕获语义特征至关重要,但是其实是轻量级的,没有额外的学习参数。
整体设计
最终两者学到的特征是两者的和(其权重是可学习的):
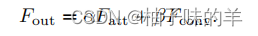
文章结果
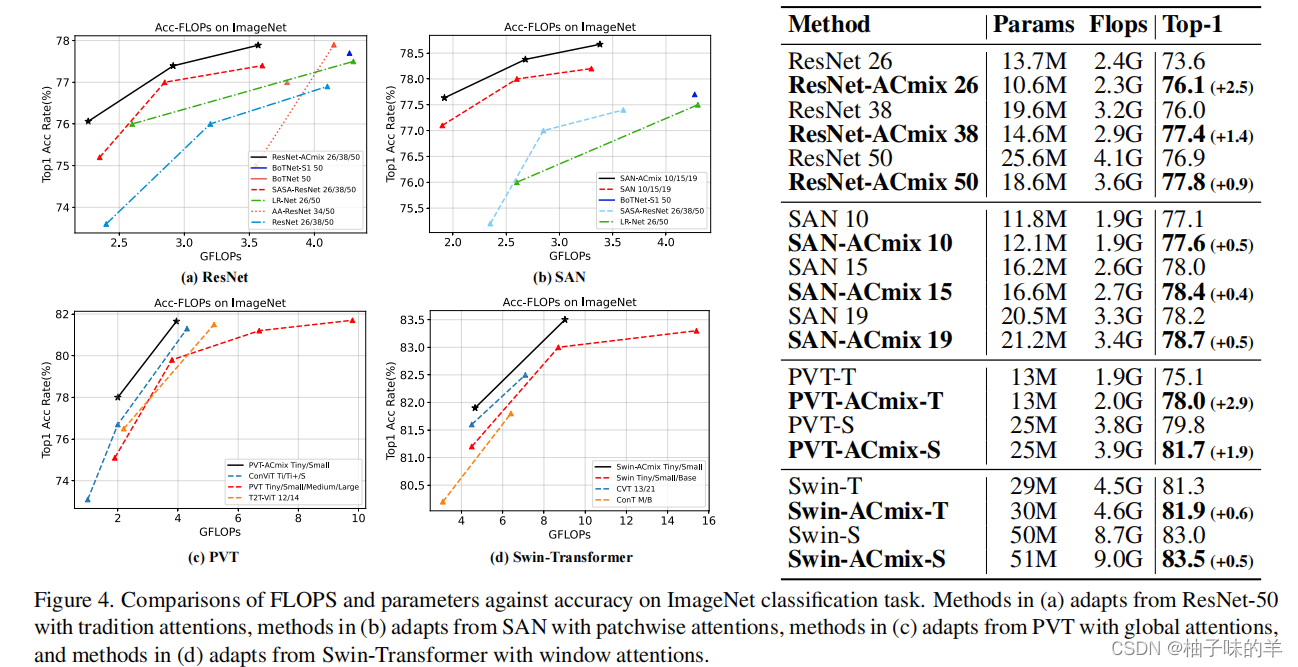
1.分类
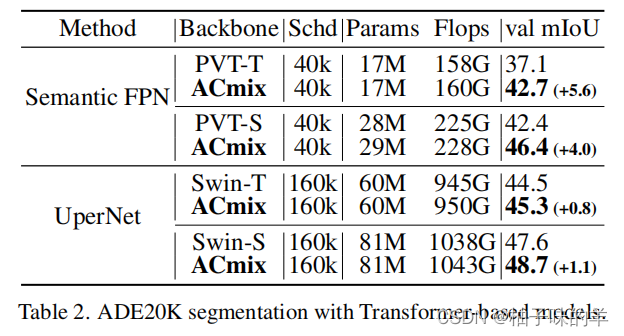
2. 分割
3. 物体检测
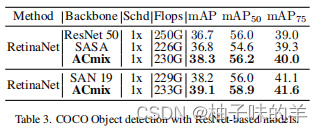
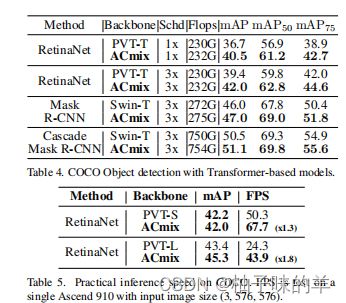
4. 消融实验
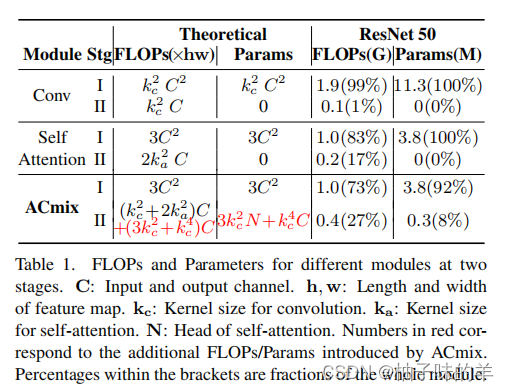
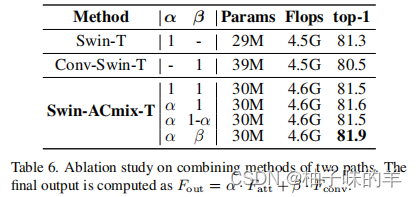
(1)combination block compared with single block
作者比较了只使用attention,只使用convolution,以及将两者组合的参数量,Flops已经模型的性能。
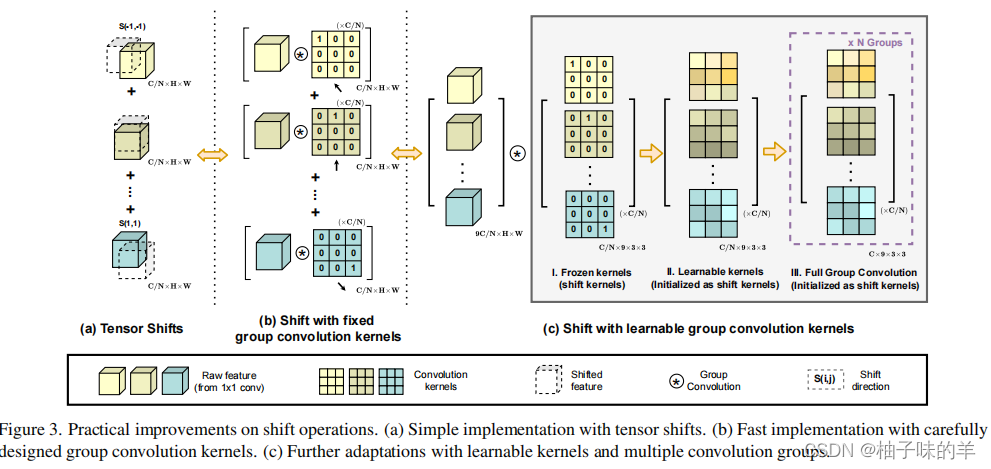
(2)group convolution kernels

(3)超参数
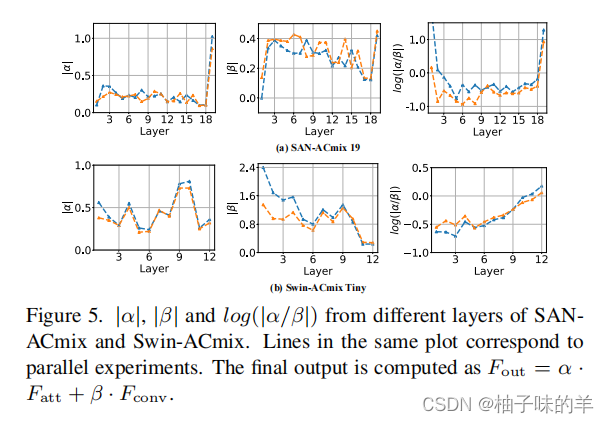
可以看到在transformer 模型的早期阶段,卷积可以提取更好的特征。在最后的阶段,注意力机制可以提供更好的特征。
Contributions
- 揭示了自注意力和卷积之间强烈的潜在关系,为深入理解两者提供了新的视角
- 提出了一种很好的结合两者优点的模块。消融实验也表明混合模型的效果比单个用其中任意一个效果更加。
总结
从作者的消融实验,效果还是蛮喜人的,是一个新视角,值得学习!
可借鉴点/学习点?
都给我去看!