目录
- 1.说说重载和重写
- 2.内连接和外连接
- 3.如果有一个任务来了,线程池怎么运行
- 5.hashset怎么判断重复
- 6.list和set说说
- 7.说说有哪些list
- 8.单例模式的饿汉式和懒汉式,怎么样可以防止反射。
- 9.volatile关键字说说
1.说说重载和重写
1、重载发生在本类,重写发生在父类与子类之间;
2、重载的方法名必须相同,重写的方法名相同且返回值类型必须相同;
3、重载的参数列表不同,重写的参数列表必须相同。
4、重写的访问权限不能比父类中被重写的方法的访问权限更低。
5、构造方法不能被重写
2.内连接和外连接
- left join (左连接):返回包括左表中的所有记录和右表中连接字段相等的记录。
- right join (右连接):返回包括右表中的所有记录和左表中连接字段相等的记录。
- inner join (等值连接或者叫内连接):只返回两个表中连接字段相等的行。
- full join (全外连接):返回左右表中所有的记录和左右表中连接字段相等的记录。
3.如果有一个任务来了,线程池怎么运行
-
1.在创建了线程池后,等待提交过来的任务请求
-
2.当调用execute()方法添加一个请求任务时,线程池会做出如下判断
- 如果正在运行的线程池数量小于corePoolSize,那么马上创建线程运行这个任务
- 如果正在运行的线程数量大于或等于corePoolSize,那么将这个任务放入队列
- 如果这时候队列满了,并且正在运行的线程数量还小于maximumPoolSize,那么还是创建非核心线程立刻运行这个任务;
- 如果队列满了并且正在运行的线程数量大于或等于maximumPoolSize,那么线程池会启动饱和拒绝策略来执行
-
3.当一个线程完成任务时,它会从队列中取下一个任务来执行
-
4.当一个线程无事可做操作一定的时间(keepAliveTime)时,线程池会判断:
- 如果当前运行的线程数大于corePoolSize,那么这个线程就被停掉
- 所以线程池的所有任务完成后,它会最终收缩到corePoolSize的大小
5.hashset怎么判断重复
为了保证HashSet中的对象不会出现重复值,在被存放元素的类中必须要重写hashCode()和equals()这两个方法。
查看了JDK源码,发现HashSet竟然是借助HashMap来实现的,利用HashMap中Key的唯一性,来保证HashSet中不出现重复值。具体参见代码:
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, Serializable
private transient HashMap<E,Object> map; // hashmap
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
public HashSet() {
map = new HashMap<E,Object>();
}
public boolean contains(Object o) {
return map.containsKey(o);
}
public boolean add(E e) {
return map.put(e, PRESENT) == null; // hashset中的元素就是hashmap中的key :-)
由此可见,HashSet中的元素实际上是作为HashMap中的Key存放在HashMap中的。下面是HashMap类中的put方法:
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode()); // 计算hash值
int i = indexFor(hash, table.length); // 根据hash值,找到对应的索引
// 遍历链表中每个结点
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
// 如果hash值相等,并且== or equals也相等,
// 那么就用新值覆盖老值
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue; // 然后返回老值(不能是null)
6.list和set说说
list和set都是接口collection的子接口,list代表有序的可重复的集合,每个元素都有对应的顺序索引,可以通过索引来访问指定位置的集合元素。而set表示无序,不可重复的集合元素。但是它有支持排序的实现类treeset,treeset可以确保元素处于排序状态,并支持自然排序和定制排序两种方式,treeset是非线程安全的,内部元素的值不能为null
7.说说有哪些list
ArrayList、LinkedList、Vector
8.单例模式的饿汉式和懒汉式,怎么样可以防止反射。
在 Java 中,可以使用反射机制来获取类的构造器,然后使用构造器来创建该类的对象。如果一个类是单例模式,并且使用了默认的构造器,则可以通过反射创建该类的多个对象,破坏单例模式的设计。
为了防止这种情况的发生,可以在单例模式的类中添加一个私有的构造器,将其设为抛出异常。这样,当通过反射调用该构造器时,就会抛出异常,从而防止创建多个对象。
列举:饿汉式
public class Singleton {
private static Singleton instance = new Singleton();
private Singleton() {
if (instance != null) {
throw new IllegalStateException("Singleton instance already exists.");
}
}
public static Singleton getInstance() {
return instance;
}
}
9.volatile关键字说说
1.说说volatile关键字的特性
可见性(保证了不同线程对该变量操作的内存可见性;)
有序性(禁止指令重排序)
2.什么是内存可见性?能否举例说明?
JMM(Java内存模型Java Memory Model,简称JMM)本身是一种抽象的概念并不真实存在
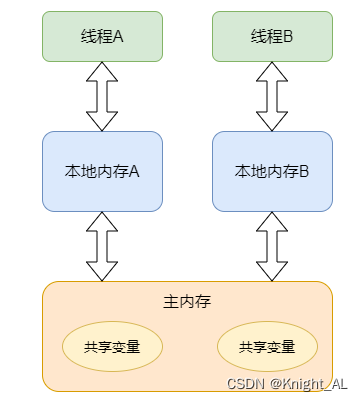
使用volatile修饰共享变量,就可以达到上面的效果,被volatile修改的变量有以下特点:
线程中读取的时候,每次读取都会去主内存中读取共享变量最新的值,然后将其复制到工作内存
线程中修改了工作内存中变量的副本,修改之后会立即刷新到主内存
3.指令重排,能举例说明吗?
在单线程程序中,重排序并不会影响程序的运行结果,而在多线程场景下就不一定了。
class ReorderExample{
int a = 0;
boolean flag = false;
public void writer(){
a = 1; // 操作1
flag = true; // 操作2
}
public void reader(){
if(flag){ // 操作3
int i = a + a; // 操作4
}
}
}
假设线程1先执行writer()方法,随后线程2执行reader()方法,最后程序一定会得到正确的结果吗?
答案是不一定的,如果代码按照下图的执行顺序执行代码则会出现问题。
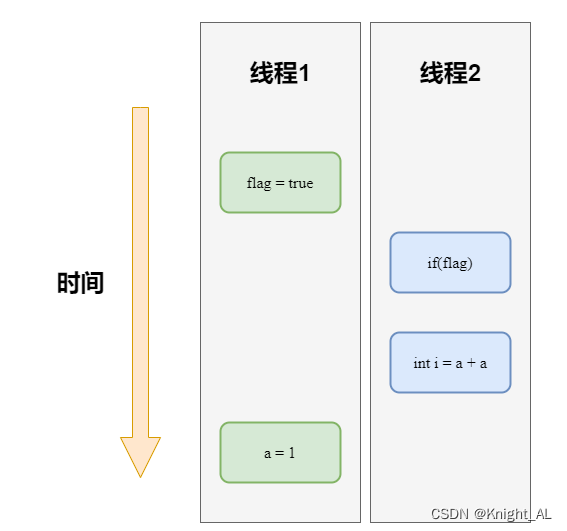
操作1和操作2进行了重排序,线程1先执行flag=true,然后线程2执行操作3和操作4,线程2执行操作4时不能正确读取到a的值,导致最终程序运行结果出问题。这也说明了在多线程代码中,重排序会破坏多线程程序的语义。

1.当第一个操作为volatile读时,不论第二个操作是什么,都不能重排序。这个操作保证了volatile读之后的操作不会被重排到volatile读之前。
2.当第二个操作为volatile写时,不论第一个操作是什么,都不能重排序。这个操作保证了volatile写之前的操作不会被重排到volatile写之后。
3.当第一个操作为volatile写时,第二个操作为volatile读时,不能重排。
4.volatile能保证原子性吗?
volatile不能保证原子性,它只是对单个volatile变量的读/写具有原子性,但是对于类似i++这样的复合操作就无法保证了。
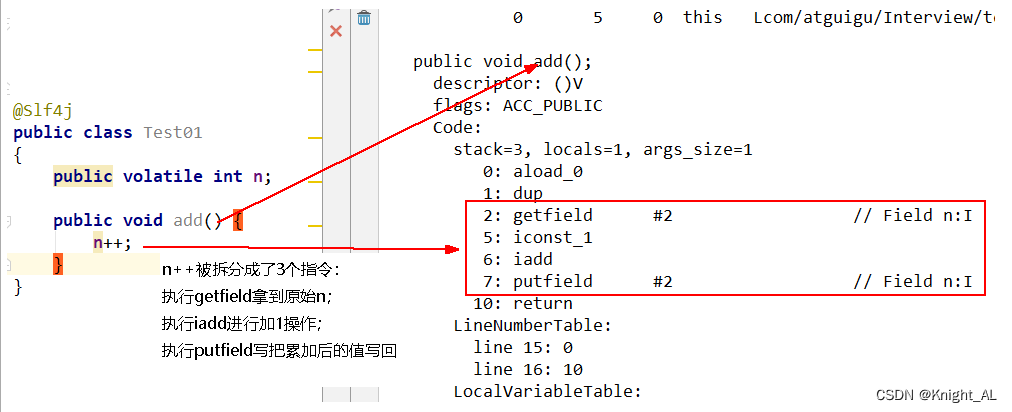
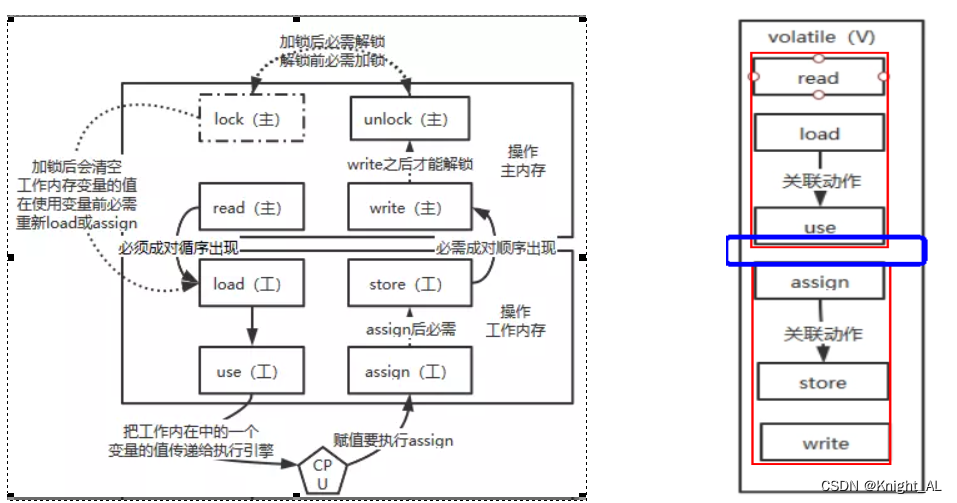
volatile变量的读写过程
read(读取)→load(加载)→use(使用)→assign(赋值)→store(存储)→write(写入)→lock(锁定)→unlock(解锁)
read: 作用于主内存,将变量的值从主内存传输到工作内存,主内存到工作内存
load: 作用于工作内存,将read从主内存传输的变量值放入工作内存变量副本中,即数据加载
use: 作用于工作内存,将工作内存变量副本的值传递给执行引擎,每当JVM遇到需要该变量的字节码指令时会执行该操作
assign: 作用于工作内存,将从执行引擎接收到的值赋值给工作内存变量,每当JVM遇到一个给变量赋值字节码指令时会执行该操作
store: 作用于工作内存,将赋值完毕的工作变量的值写回给主内存
write: 作用于主内存,将store传输过来的变量值赋值给主内存中的变量
由于上述只能保证单条指令的原子性,针对多条指令的组合性原子保证,没有大面积加锁,所以,JVM提供了另外两个原子指令:
lock: 作用于主内存,将一个变量标记为一个线程独占的状态,只是写时候加锁,就只是锁了写变量的过程。
unlock: 作用于主内存,把一个处于锁定状态的变量释放,然后才能被其他线程占用