目录
- 1.常用数据结构,区别及使用场景
- 2.数组和链表在内存中数据的分布情况
- 3.HashMap底层数据结构
- 4.put操作
- 5.JVM内存区域
- 6.各个区域存放什么东西
- 7.创建一个对象,内存怎么分配的
- 8.堆中内存怎么划分,gc怎么回收
- 9.IOC 原理
- 10.Bean存放在哪里
- 11.AOP原理
- 12.动态代理实现方式
- 13.BeanFactory和FactoryBean的区别
- 14.事务的隔离级别
- 15.脏读场景,幻读场景
- 16.介绍一下分布式锁,分布式锁用过吗 ?redis为什么可以作为分布式锁?
- 17.哪些场景用过redis
- 18.redis 数据结构
- 19.redis过期策略
- 20.怎么理解序列化
- 21.知道哪些序列化协议
- 22.怎么分析慢sql
- 23.写sql 学生姓名科目成绩表,求平均分90分以上的
- 24.讲一下ThreadLocal原理
1.常用数据结构,区别及使用场景
以下是一些常用的数据结构,它们的区别以及适用场景:
数组 (Array): 区别:数组是一种连续内存空间的数据结构,具有固定的大小,用于存储相同类型的元素。数组支持随机访问,访问速度快。 使用场景:当需要快速查找和访问元素时,使用数组是一个好选择。不过,在插入和删除操作方面,数组的性能较差,因为需要移动大量元素。
链表 (LinkedList): 区别:链表是一种非连续内存空间的数据结构,由一系列节点组成,每个节点包含数据元素和指向下一个节点的指针。链表支持快速的插入和删除操作。 使用场景:当需要在数据结构中频繁地插入和删除元素时,链表是一个好选择。不过,链表不支持随机访问,访问速度较慢。
栈 (Stack): 区别:栈是一种遵循“后进先出”(LIFO)原则的线性数据结构。栈只允许在其顶部进行插入和删除操作。 使用场景:栈适用于需要执行撤销操作、解析表达式、实现函数调用等场景。
队列 (Queue): 区别:队列是一种遵循“先进先出”(FIFO)原则的线性数据结构。队列只允许在一端(队尾)进行插入操作,而在另一端(队首)进行删除操作。 使用场景:队列适用于需要按照元素进入顺序进行处理的场景,如任务调度、消息传递等。
哈希表 (HashTable): 区别:哈希表是一种基于键值对存储数据的数据结构。通过哈希函数将键映射到数组的索引,以实现快速查找、插入和删除操作。 使用场景:哈希表适用于需要高效查找、插入和删除操作的场景,如数据库、缓存等。
树 (Tree): 区别:树是一种非线性层次数据结构,由节点和连接节点的边组成。每个节点只有一个父节点,可以有多个子节点。树的常见类型有二叉树、平衡树和搜索树等。 使用场景:树适用于需要表示层次关系和实现高效查找的场景,如文件系统、搜索引擎等。
图 (Graph): 区别:图是一种非线性数据结构,由节点(顶点)和连接节点的边组成。图可以表示多对
2.数组和链表在内存中数据的分布情况
数组和链表在内存中的数据分布情况有显著差异。以下是它们在内存中的主要特点:
数组:
- 连续内存空间:数组中的元素在内存中是连续分布的。这意味着数组的每个元素都紧挨着前一个元素,占据连续的内存地址。
- 固定大小:数组在创建时分配固定大小的内存空间,因此在内存中占据连续且固定大小的区域。数组大小在创建后无法更改。
- 随机访问:由于数组元素在内存中连续存储,可以通过基地址和索引直接计算出元素的内存地址。这使得数组支持高效的随机访问。
链表:
- 非连续内存空间:链表中的元素在内存中是非连续分布的。链表的每个节点包含数据元素和指向下一个节点的指针。这些节点可以分散在内存的不同区域。
- 动态大小:链表在创建时不需要分配固定大小的内存空间。链表的大小可以在运行时动态更改,因为添加和删除节点只需修改相应指针。
- 顺序访问:由于链表元素在内存中非连续存储,无法直接通过索引访问特定元素。访问链表中的元素需要从头节点开始,按顺序遍历链表,直到找到所需元素。
总之,数组在内存中以连续的方式存储数据,支持高效的随机访问。而链表则将数据分散在内存的各个区域,需要通过指针进行顺序访问。
3.HashMap底层数据结构
在 JDK 1.7 中,HashMap 使用的是数组 + 链表实现。
在 JDK 1.8 中使用的是数组 + 链表或红黑树实现的。
4.put操作
如果不熟悉可以看这篇
HashMap中put的实现原理
(1)先判断当前Node[]数组是不是为空,为空就新建,不为空就对hash值与容量-1做与运算得到数组下标
(2)然后会判断当前数组位置有没有元素,没有的话就把值插到当前位置,有的话就说明遇到了哈希碰撞
(3)遇到哈希碰撞后,如果Hash值相同且equals内容也相同,直接覆盖,就会看下当前链表是不是以红黑树的方式存储,是的话,就会遍历红黑树,看有没有相同key的元素,有就覆盖,没有就执行红黑树插入
(4)如果是普通链表,则按普通链表的方式遍历链表的元素,判断p.next = null的情况下,直接存放追加在next后面,然后我们要检查一下如果链表长度大于8且数组容量>=64链表转换成红黑树,否则查找到链表中是否存在该key,如果存在直接修改value值,如果没有继续遍历
(5)如果++size > threshold(阈值)就扩容
5.JVM内存区域

6.各个区域存放什么东西
Java虚拟机(JVM)的内存区域主要分为以下几个部分:
-
堆(Heap): 堆是JVM内存区域中最大的一部分,用于存储所有对象实例和数组。堆内存是在所有线程间共享的,堆的大小可以通过JVM参数进行调整。堆分为年轻代(Young Generation)和老年代(Old Generation),年轻代进一步细分为Eden区、Survivor 0区和Survivor 1区。对象首先在Eden区创建,经过一定次数的垃圾回收后,存活的对象会逐渐晋升到老年代。
-
方法区(Method Area): 方法区用于存储已加载的类信息、常量、静态变量以及编译后的代码。方法区是所有线程共享的内存区域。在HotSpot虚拟机中,方法区被实现为永久代(PermGen)或元空间(Metaspace),取决于JVM版本。
-
栈(Stack): 每个线程在创建时都会创建一个私有的栈。栈用于存储局部变量、操作数栈、动态链接和方法返回地址。每个方法的调用都会在栈上创建一个栈帧,用于存储该方法的局部变量和操作数。当方法返回时,其对应的栈帧会被弹出。
-
程序计数器(Program Counter Register): 程序计数器是线程私有的内存区域,用于存储当前线程正在执行的字节码指令的地址。当线程执行方法时,程序计数器会逐行更新以指向下一条指令。如果线程执行的是本地方法(native method),则程序计数器的值为undefined。
-
本地方法栈(Native Method Stack): 本地方法栈类似于Java栈,但它主要用于本地方法的调用。每个线程都有一个私有的本地方法栈。与Java栈类似,本地方法栈也会为每个方法调用创建栈帧。
总的来说,JVM内存区域包括堆(用于存储对象实例和数组)、方法区(用于存储类信息、常量和静态变量)、栈(用于存储局部变量和操作数)、程序计数器(用于指示当前执行的字节码指令)和本地方法栈(用于本地方法的调用)。这些内存区域在JVM运行时起到了重要作用。
7.创建一个对象,内存怎么分配的
- 类加载: 在创建对象之前,首先需要确保对象所属的类已经被加载到JVM中。类加载器负责从类路径中查找并加载类的字节码,然后在方法区中存储类的元数据信息。
- 在堆中分配内存: 创建对象时,JVM会在堆内存中为其分配空间。对象的内存大小取决于其实例变量的数量和类型。在大多数情况下,对象会在年轻代的Eden区创建。Eden区是年轻代的主要区域,用于存放新创建的对象。
- 初始化对象: 为新创建的对象分配内存后,JVM会将其内存空间初始化为零(null或0)。接着,JVM会调用构造函数来初始化对象的实例变量,为它们赋予初始值。
- 分配引用: 创建对象后,JVM会为对象分配一个引用,该引用存储在栈中的局部变量表。通过这个引用,您可以在程序中访问和操作对象。
以下是一个简单的Java代码示例,用于创建一个对象:
class MyClass {
int x;
int y;
MyClass(int x, int y) {
this.x = x;
this.y = y;
}
}
public class Main {
public static void main(String[] args) {
MyClass obj = new MyClass(1, 2);
}
}
在这个示例中,当执行new MyClass(1, 2)时,JVM首先检查MyClass是否已经被加载。接着,JVM在堆的Eden区为MyClass对象分配内存,并初始化其实例变量。然后,JVM调用构造函数为实例变量赋初始值。最后,JVM为创建的对象分配一个引用,将其存储在局部变量表中的obj变量中。
8.堆中内存怎么划分,gc怎么回收
堆(Heap)内存在Java虚拟机(JVM)中用于存储对象实例和数组。堆内存分为以下几个部分:
-
年轻代(Young Generation):年轻代用于存放新创建的对象。它分为以下三个区域:
- Eden区:新创建的对象首先分配在这里。当Eden区满时,会触发一次Minor GC。
- Survivor 0区(S0)和Survivor 1区(S1):这两个区域用于存放在Minor GC后仍然存活的对象。每次Minor GC后,存活的对象会在两个Survivor区之间来回复制。
-
老年代(Old Generation):经过一定次数Minor GC后仍然存活的对象会被晋升到老年代。老年代用于存放长时间存活的对象。当老年代满时,会触发一次Full GC。
垃圾回收(GC)过程主要分为两种:
-
Minor GC:当Eden区满时,会触发一次Minor GC。在这个过程中,垃圾回收器会清理Eden区和一个Survivor区(例如S0)中的无用对象,并将仍然存活的对象复制到另一个Survivor区(例如S1)。Minor GC只涉及年轻代的内存回收,因此它的回收速度相对较快。
-
Full GC:当老年代满时,会触发一次Full GC。在Full GC过程中,垃圾回收器会清理整个堆内存(包括年轻代和老年代)。Full GC通常比Minor GC耗时更长,因为它需要清理整个堆内存。在Full GC过程中,应用程序的执行可能会暂停,导致系统吞吐量下降。
垃圾回收的基本原理是通过追踪和标记存活的对象,然后回收未标记(不再使用)的对象所占用的内存。常见的垃圾回收算法有标记-清除(Mark-Sweep)、标记-整理(Mark-Compact)、复制(Copying)等。在实际应用中,垃圾回收器通常会结合多种算法来提高内存回收效率。
需要注意的是,Java虚拟机中的垃圾回收器有多种实现,如串行回收器(Serial)、并行回收器(Parallel)、CMS回收器(Concurrent Mark Sweep)和G1回收器(Garbage-First)。这些回收器在实现细节上有所不同,但它们的基本原理和目标都是提高内存回收效率,减少应用程序的暂停时间。
9.IOC 原理
IOC(Inversion of Control,控制反转)是一种设计原则,用于减少模块之间的耦合度。在Spring框架中,IOC容器负责管理对象之间的依赖关系。IOC容器通过依赖注入(DI,Dependency Injection)的方式将依赖对象注入到目标对象中,使得开发者不需要手动创建和管理对象之间的关系。
以下是Spring IOC的主要原理和过程:
-
配置Bean定义:在Spring中,每个对象称为一个Bean。开发者需要在Spring配置文件(XML文件)或使用Java注解的方式定义Bean。这些定义包括Bean的类名、作用域、构造函数参数、属性值等信息。
-
初始化IOC容器:当应用程序启动时,Spring会根据提供的配置文件或注解创建一个IOC容器。IOC容器负责解析配置文件或注解,创建Bean实例并管理它们的生命周期。
-
注册Bean实例:IOC容器会将创建的Bean实例注册到容器中。每个Bean都有一个唯一的ID,可以通过ID在容器中查找Bean实例。
-
解析依赖关系:IOC容器会根据Bean定义解析它们之间的依赖关系。容器会分析每个Bean所需的依赖对象,并将这些依赖对象注入到目标Bean中。
-
依赖注入:依赖注入是IOC的核心过程。IOC容器会在运行时将依赖对象注入到目标Bean中,使得开发者不需要手动创建和管理对象之间的关系。依赖注入可以通过以下几种方式实现:
- 构造函数注入:容器通过调用目标Bean的构造函数并传入依赖对象来实现依赖注入。
- Setter方法注入:容器通过调用目标Bean的setter方法并传入依赖对象来实现依赖注入。
- 注解注入:容器根据目标Bean上的注解(如@Autowired)来实现依赖注入。
-
使用Bean:在应用程序中,开发者可以通过IOC容器获取Bean实例并使用它们。由于IOC容器负责管理Bean的生命周期和依赖关系,开发者可以专注于业务逻辑而不需要关心对象之间的关系。
总之,Spring IOC原理是通过控制反转和依赖注入来实现对象之间的解耦。IOC容器负责解析配置文件或注解,创建Bean实例,解析依赖关系并将依赖对象注入到目标Bean中。这使得开发者能够更轻松地管理对象之间的关系,提高代码的可维护性和可测试性。
10.Bean存放在哪里
在Spring框架中,Bean实例被存放在IOC容器(即应用程序上下文,ApplicationContext)中。IOC容器负责管理Bean的创建、初始化、依赖注入和生命周期。每个Bean在容器中都有一个唯一的ID,可以通过这个ID获取对应的Bean实例。
IOC容器是一个运行时数据结构,它在内存中维护了一个Bean实例的注册表。这个注册表是一个键值对集合,其中键是Bean的ID,值是对应的Bean实例。当需要获取或使用某个Bean时,可以通过IOC容器的API(如getBean方法)根据Bean的ID来查找和访问对应的实例。
需要注意的是,IOC容器并不会一开始就创建所有的Bean实例。根据Bean的作用域和配置,容器可能在第一次请求时才创建Bean实例,或者每次请求时都创建一个新的实例。在单例作用域(singleton)中,容器会为每个Bean创建一个唯一的实例,并在整个应用程序的生命周期中重用这个实例。在原型作用域(prototype)中,容器会为每次请求创建一个新的Bean实例。
11.AOP原理
AOP(Aspect-Oriented Programming,面向切面编程)是一种编程范式,旨在将横切关注点(cross-cutting concerns)从业务逻辑中分离出来。横切关注点是在多个模块或功能中重复出现的代码,如日志记录、事务管理、权限控制等。通过使用AOP,开发者可以将这些横切关注点与核心业务逻辑分离,提高代码的可维护性和可重用性。
在Spring框架中,AOP的实现主要依赖于动态代理技术。以下是Spring AOP的主要原理和组成部分:
-
切面(Aspect):切面是封装横切关注点的模块。一个切面可以包含多个通知(Advice)和切入点(Pointcut)的定义。切面可以使用Java类和注解(如@Aspect)来实现。
-
通知(Advice):通知是切面中的具体行为,表示在某个连接点(Joinpoint)执行的操作。通知可以有以下几种类型:
- 前置通知(Before):在连接点执行之前执行的通知。
- 后置通知(After):在连接点执行之后(无论成功还是异常)执行的通知。
- 返回通知(AfterReturning):在连接点正常返回后执行的通知。
- 异常通知(AfterThrowing):在连接点抛出异常后执行的通知。
- 环绕通知(Around):在连接点执行前后都执行的通知,可以控制连接点的执行。
切入点(Pointcut):切入点定义了通知应该在哪些连接点执行。切入点使用表达式(如AspectJ表达式)来描述匹配的连接点。开发者可以根据类名、方法名、参数类型等条件来定义切入点。
-
连接点(Joinpoint):连接点表示在程序执行过程中的某个点,如方法调用、异常抛出等。通知会在与切入点匹配的连接点处执行。
-
代理(Proxy):在Spring AOP中,通常使用动态代理技术(如JDK动态代理或CGLIB代理)来实现AOP。代理对象是目标对象的一个封装,它可以在目标方法执行前后插入通知的逻辑。当调用代理对象的方法时,实际上会先执行通知,然后执行目标方法。
以下是Spring AOP的基本过程:
-
定义切面:开发者需要定义一个切面,包括通知和切入点的定义。切面可以使用Java类和注解来实现。
-
配置AOP:在Spring配置文件或使用注解的方式配置AOP,包括切面、代理策略等。配置告诉Spring框架如何创建代理对象以及如何将通知应用到目标对象。
-
创建代理对象:在应用程序启动时,Spring AOP会根据配置创建代理对象。代理对象是目标对象的一个封装,它可以在目标方法执行前后插入通知的逻辑。根据配置,Spring AOP可以使用JDK动态代理或CGLIB代理来创建代理对象。
-
执行通知:当调用代理对象的方法时,代理对象会先根据切入点匹配相应的通知。根据通知类型(前置、后置、返回、异常、环绕),代理对象会在目标方法执行前后插入通知的逻辑。
-
调用目标方法:在通知执行完毕后,代理对象会调用目标方法。如果是环绕通知,通知中可以控制目标方法的执行时机。
通过这个过程,Spring AOP实现了将横切关注点从业务逻辑中分离出来,提高了代码的可维护性和可重用性。同时,由于AOP使用了动态代理技术,开发者无需修改目标对象的代码,就可以轻松地应用和修改横切关注点。
需要注意的是,尽管Spring AOP提供了强大的功能,但它并不适用于所有场景。在某些情况下,使用AOP可能导致性能下降或代码复杂性增加。因此,在使用AOP时,应充分考虑其优缺点,以确保代码的可维护性和可读性。
12.动态代理实现方式
JDK动态代理:
JDK动态代理是Java官方提供的代理实现方式,主要依赖于java.lang.reflect.Proxy类和java.lang.reflect.InvocationHandler接口。JDK动态代理要求目标对象必须实现一个或多个接口。
实现步骤:
- 创建一个实现InvocationHandler接口的类,重写invoke方法。这个方法将在代理对象调用目标方法时被执行,包含代理逻辑。
- 使用Proxy类的newProxyInstance方法创建代理对象。这个方法接收三个参数:目标对象的类加载器、目标对象实现的接口列表和InvocationHandler实现类的实例。
- 调用代理对象的方法。当代理对象的方法被调用时,InvocationHandler的invoke方法会被执行,插入代理逻辑。
优点: JDK动态代理是官方提供的代理实现,无需引入额外的依赖
缺点: JDK动态代理要求目标对象必须实现一个或多个接口。如果目标对象没有实现接口,无法使用JDK动态代理。此外,JDK动态代理只能为接口创建代理对象,不能针对类进行代理。
CGLIB代理:
CGLIB(Code Generation Library)是一个第三方库,可以在运行时动态生成代理对象。CGLIB代理基于继承机制,要求目标对象不能是final类。
实现步骤:
- 创建一个实现MethodInterceptor接口的类,重写intercept方法。这个方法将在代理对象调用目标方法时被执行,包含代理逻辑。
- 使用CGLIB的Enhancer类创建代理对象。需要设置目标对象的类、回调方法(MethodInterceptor实现类的实例)等属性。
- 调用代理对象的方法。当代理对象的方法被调用时,MethodInterceptor的intercept方法会被执行,插入代理逻辑。
优点: CGLIB代理可以针对没有实现接口的类进行代理,功能更加强大。
缺点: CGLIB代理需要引入额外的依赖(cglib.jar),而且性能相对较低。另外,CGLIB代理不能针对final类进行代理,因为它使用继承机制实现代理。
总结:
动态代理在Java中主要有两种实现方式:JDK动态代理和CGLIB代理。JDK动态代理是官方提供的代理实现,性能较好,但要求目标对象实现接口。CGLIB代理是第三方库实现的代理,可以针对没有实现接口的类进行代理,功能更强大,但性能较低。在选择动态代理实现时,需要根据具体场景和需求进行权衡。
13.BeanFactory和FactoryBean的区别
BeanFactory和FactoryBean是Spring框架中两个重要的接口,它们的职责和用途各不相同。
BeanFactory:
BeanFactory是Spring框架中最基本的IoC容器,负责管理Bean的创建、配置、依赖注入和生命周期管理。它提供了基本的容器功能,如根据Bean的ID获取Bean实例、注册单例Bean等。在实际应用中,开发者通常使用BeanFactory的子接口ApplicationContext,它提供了更高级的功能,如事件发布、AOP支持等。
BeanFactory主要方法:
- Object getBean(String name): 根据Bean的ID获取Bean实例。
- boolean containsBean(String name): 判断容器中是否包含指定ID的Bean。
- boolean isSingleton(String name): 判断指定ID的Bean是否是单例。
- boolean isPrototype(String name): 判断指定ID的Bean是否是原型。
FactoryBean:
FactoryBean是一种特殊的Bean,它允许开发者控制Bean的创建过程。当一个Bean的实例化逻辑复杂或需要进行额外配置时,可以使用FactoryBean来创建这个Bean。FactoryBean本身也是一个Bean,需要在Spring配置中定义。
FactoryBean主要方法:
- T getObject(): 返回由FactoryBean创建的Bean实例。
- Class<?> getObjectType(): 返回FactoryBean创建的Bean的类型。
- boolean isSingleton(): 判断FactoryBean创建的Bean是否是单例。
区别:
- BeanFactory是Spring框架中的IoC容器,负责管理Bean的创建、配置、依赖注入和生命周期管理。而FactoryBean是一种特殊的Bean,用于创建其他Bean,允许开发者控制Bean的创建过程。
- BeanFactory是一个容器接口,主要关注整个容器的操作,如获取Bean实例、判断Bean是否存在等。FactoryBean是一个创建Bean的工厂接口,主要关注单个Bean的创建过程。
- 在实际使用中,开发者通常与ApplicationContext(BeanFactory的子接口)交互,而不是直接使用BeanFactory。而FactoryBean通常用于创建复杂或需要额外配置的Bean。
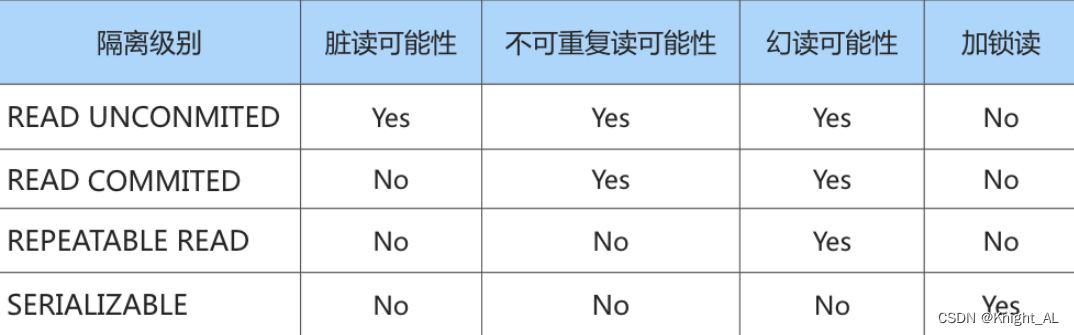
14.事务的隔离级别
1.读未提交
2.读已提交
3.可重复读
4.序列化
侧重于RR和RC来解释

15.脏读场景,幻读场景
脏读场景(Dirty Read):
脏读是指一个事务读取到了另一个事务尚未提交的数据。如果那个事务最后回滚,那么这个读取操作就读到了错误的数据。脏读主要发生在事务隔离级别为“读未提交”的情况下。
场景示例:
假设有两个事务,T1 和 T2。
- T1:将用户 A 的银行账户余额从 1000 更新为 1200。
- T2:查询用户 A 的银行账户余额。
事务执行顺序如下: - T1 开始执行,将用户 A 的银行账户余额更新为 1200。
- T2 开始执行,查询用户 A 的银行账户余额,得到 1200。
- T1 发生错误,回滚操作,将用户 A 的银行账户余额恢复为 1000。
在这个例子中,T2 读到了 T1 尚未提交的数据。由于 T1 最后发生回滚,T2 读取到的数据是错误的。这就是脏读。
幻读场景(Phantom Read):
幻读是指在同一个事务中,多次查询某个范围的数据,可能会得到不同的结果,因为其他事务可能在此期间插入或删除了数据并提交。幻读主要发生在事务隔离级别为“可重复读”的情况下。
场景示例:
假设有两个事务,T1 和 T2。
- T1:查询年龄在 20-30 岁之间的用户数量。
- T2:插入一个年龄为 25 岁的新用户。
事务执行顺序如下: - T1 开始执行,查询年龄在 20-30 岁之间的用户数量,得到 10 人。
- T2 开始执行,插入一个年龄为 25 岁的新用户,然后提交。
- T1 再次查询年龄在 20-30 岁之间的用户数量,得到 11 人。
在这个例子中,T1 在同一个事务中两次查询年龄在 20-30 岁之间的用户数量,得到了不同的结果。这是因为 T2 在此期间插入了一个新用户并提交,导致了幻读。
16.介绍一下分布式锁,分布式锁用过吗 ?redis为什么可以作为分布式锁?
分布式锁是一种在分布式系统中实现多个节点对共享资源互斥访问的同步机制。在分布式环境下,不同的服务或进程可能同时访问或修改同一个资源,分布式锁可以确保在任意时刻只有一个节点可以访问该资源,从而避免数据不一致或其他并发问题。
Redis作为分布式锁的选择有以下原因:
-
性能:Redis是一个内存数据库,具有高性能的读写能力。这使得Redis在获取和释放锁时具有较低的延迟,从而提高了分布式锁的性能。
-
原子性操作:Redis提供了原子性操作,如SETNX(SET if Not eXists)和GETSET等命令。这些命令可以确保在多个客户端竞争获取和释放锁时,锁的状态不会出现不一致的情况。
-
锁过期机制:Redis支持为键设置过期时间,这可以用于实现锁的自动释放,防止死锁的发生。当客户端在获取锁时设置过期时间,即使客户端在执行业务逻辑时崩溃或无法释放锁,锁也会在过期时间后自动释放,从而避免死锁。
-
脚本支持:Redis支持Lua脚本,可以用于实现复杂的原子性操作。例如,在释放锁时,可以使用Lua脚本来确保只有锁的持有者才能释放锁,避免误解锁的情况。
-
可扩展性:Redis具有良好的可扩展性,可以通过主从复制、哨兵和集群等机制来实现高可用性和负载均衡。这使得Redis分布式锁可以在大规模的分布式系统中使用。
17.哪些场景用过redis
String
应用场景
- 比如抖音无限点赞某个视频或者商品,点一下加一次
- 是否喜欢的文章(阅读数:只要点击了rest地址,直接可以使用incr key命令增加一个数字1,完成记录数字。)
Hash
应用场景
- JD购物车早期
List
应用场景 - 微信公众号订阅的消息
- 商品评论列表
Set
应用场景
- 微信抽奖小程序
- 微博好友关注社交关系
- QQ内推可能认识的人
Zset
应用场景
- 抖音热搜
18.redis 数据结构
如果不熟悉可以看这篇
redis经典五种数据类型及底层实现

String
采用的int,embstr,raw
Redis为什么重新设计一个 SDS 数据结构?
C语言没有Java里面的String类型,只能是靠自己的char[]来实现,字符串在 C 语言中的存储方式,想要获取 「Redis」的长度,需要从头开始遍历,直到遇到 ‘\0’ 为止。所以,Redis 没有直接使用 C 语言传统的字符串标识,而是自己构建了一种名为简单动态字符串 SDS(simple dynamic string)的抽象类型,并将 SDS 作为 Redis 的默认字符串。
Hash
采用的ziplist,hashtable
Ziplist 压缩列表是一种紧凑编码格式,总体思想是多花时间来换取节约空间,即以部分读写性能为代价,来换取极高的内存空间利用率,
因此只会用于 字段个数少,且字段值也较小 的场景。压缩列表内存利用率极高的原因与其连续内存的特性是分不开的。
ziplist什么样
ziplist是一个经过特殊编码的双向链表,它不存储指向上一个链表节点和指向下一个链表节点的指针,而是存储上一个节点长度和当前节点长度,通过牺牲
明明有链表了,为什么出来一个压缩链表?
1 普通的双向链表会有两个指针,在存储数据很小的情况下,我们存储的实际数据的大小可能还没有指针占用的内存大,得不偿失。ziplist 是一个特殊的双向链表没有维护双向指针:prev next;而是存储上一个 entry的长度和 当前entry的长度,通过长度推算下一个元素在什么地方。牺牲读取的性能,获得高效的存储空间,因为(简短字符串的情况)存储指针比存储entry长度更费内存。这是典型的“时间换空间”。
2 链表在内存中一般是不连续的,遍历相对比较慢,而ziplist可以很好的解决这个问题,普通数组的遍历是根据数组里存储的数据类型找到下一个元素的(例如int类型的数组访问下一个元素时每次只需要移动一个sizeof(int)就行),但是ziplist的每个节点的长度是可以不一样的,而我们面对不同长度的节点又不可能直接sizeof(entry),所以ziplist只好将一些必要的偏移量信息记录在了每一个节点里,使之能跳到上一个节点或下一个节点。
3 头节点里有头节点里同时还有一个参数 len,和string类型提到的 SDS 类似,这里是用来记录链表长度的。因此获取链表长度时不用再遍历整个链表,直接拿到len值就可以了,这个时间复杂度是 O(1)
List
在低版本的Redis中,list采用的底层数据结构是ziplist+linkedList;
高版本的Redis中底层数据结构是quicklist(它替换了ziplist+linkedList),而quicklist也用到了ziplist
Set
intset或hashtable
ZSet
ziplist
skiplist
skiplist跳表面试题
1.是什么
跳表是可以实现二分查找的有序链表
- skiplist是一种以空间换取时间的结构。
- 由于链表,无法进行二分查找,因此借鉴数据库索引的思想,提取出链表中关键节点(索引),先在关键节点上查找,再进入下层链表查找。
- 提取多层关键节点,就形成了跳跃表
总结来讲 跳表 = 链表 + 多级索引
2.说说链表和数组的优缺点?为什么引出跳表


3.优缺点
跳表是一个最典型的空间换时间解决方案,而且只有在数据量较大的情况下才能体现出来优势。而且应该是读多写少的情况下才能使用,所以它的适用范围应该还是比较有限的
维护成本相对要高 - 新增或者删除时需要把所有索引都更新一遍;
最后在新增和删除的过程中的更新,时间复杂度也是O(log n)
19.redis过期策略
如果不熟悉可以看这篇
Redis过期删除策略和内存淘汰策略
立即删除
Redis不可能时时刻刻遍历所有被设置了生存时间的key,来检测数据是否已经到达过期时间,然后对它进行删除。
立即删除能保证内存中数据的最大新鲜度,因为它保证过期键值会在过期后马上被删除,其所占用的内存也会随之释放。但是立即删除对cpu是最不友好的。因为删除操作会占用cpu的时间,如果刚好碰上了cpu很忙的时候,比如正在做交集或排序等计算的时候,就会给cpu造成额外的压力,让CPU心累,时时需要删除,忙死。。。。。。。
这会产生大量的性能消耗,同时也会影响数据的读取操作。
总结:对CPU不友好,用处理器性能换取存储空间
惰性删除
数据到达过期时间,不做处理。等下次访问该数据时,
如果未过期,返回数据 ;
发现已过期,删除,返回不存在。
惰性删除策略的缺点是,它对内存是最不友好的。
如果一个键已经过期,而这个键又仍然保留在redis中,那么只要这个过期键不被删除,它所占用的内存就不会释放。
在使用惰性删除策略时,如果数据库中有非常多的过期键,而这些过期键又恰好没有被访问到的话,那么它们也许永远也不会被删除(除非用户手动执行FLUSHDB),我们甚至可以将这种情况看作是一种内存泄漏–无用的垃圾数据占用了大量的内存,而服务器却不会自己去释放它们,这对于运行状态非常依赖于内存的Redis服务器来说,肯定不是一个好消息
定期删除
定期删除策略是前两种策略的折中:
定期删除策略每隔一段时间执行一次删除过期键操作,并通过限制删除操作执行的时长和频率来减少删除操作对CPU时间的影响。
周期性轮询redis库中的时效性数据,采用随机抽取的策略,利用过期数据占比的方式控制删除频度
特点1:CPU性能占用设置有峰值,检测频度可自定义设置
特点2:内存压力不是很大,长期占用内存的冷数据会被持续清理
总结:周期性抽查存储空间 (随机抽查,重点抽查)
总结
Redis服务器实际使用的是惰性删除和定期删除两种策略:通过配合使用这两种删除策略,服务器可以很好地在合理使用CPU时间和避免浪费内存空间之间取得平衡。
20.怎么理解序列化
Java序列化是一种将Java对象转换为字节流的过程,以便在网络上进行传输或将其存储到持久化存储(如文件或数据库)中。序列化的主要目的是在不同的环境(例如,从一个JVM到另一个JVM)之间传输对象的状态,或者在程序的不同运行时实例之间保存和恢复对象的状态。
21.知道哪些序列化协议
有许多序列化协议可用于在不同系统和环境之间传输数据。以下是一些常见的序列化协议:
- JSON(JavaScript Object Notation):JSON是一种轻量级的数据交换格式,易于阅读和编写。它是一种基于文本的格式,支持多种编程语言。JSON在Web应用程序中非常流行,用于在客户端和服务器之间传输数据。
- XML(eXtensible Markup Language):XML是一种标记语言,用于编码文档中的数据。它具有严格的语法规则,易于阅读和编写。XML在许多企业应用程序中使用,但由于其较大的开销,逐渐被JSON和其他轻量级格式所取代。
22.怎么分析慢sql
如果不熟悉可以看这篇
Mysql查询截取分析_慢查询日志
开启慢查询
set global slow_query_log=1
设置慢查询的时间
SET GLOBAL long_query_time=0.1;
假如运行时间正好等于long_query_time的情况,并不会被记录下来。也就是说,在mysql源码里是判断大于long_query_time,而非大于等于。
使用mysqldumpslow去分析,查找sql,然后在使用explain进行分析

23.写sql 学生姓名科目成绩表,求平均分90分以上的
假设学生姓名科目成绩表名为grades,表中有以下列:student_name(学生姓名)、subject(科目)和score(成绩)。可以使用以下SQL语句查询平均分在90分以上的学生记录:
SELECT student_name, AVG(score) AS average_score
FROM grades
GROUP BY student_name
HAVING AVG(score) > 90;
这个SQL语句首先使用GROUP BY子句将成绩表按照学生姓名分组,然后使用聚合函数AVG()计算每个学生的平均分。HAVING子句用于过滤平均分大于90的记录。最后,查询结果中包含学生姓名(student_name)和平均分(average_score)
在这个查询中,HAVING子句是必需的,因为它过滤了分组后的结果集。如果使用WHERE子句,它会在分组之前过滤数据,这可能会导致结果不正确。
24.讲一下ThreadLocal原理
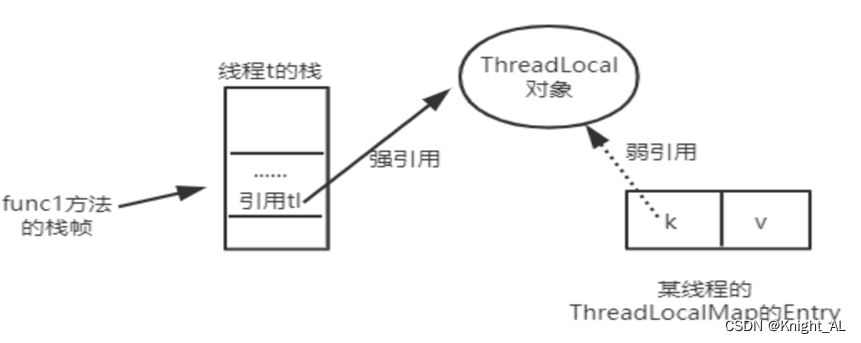
ThreadLocal的实现原理是每一个Thread维护一个ThreadLocalMap映射表,映射表的key是ThreadLocal实例,并且使用的是ThreadLocal的弱引用 ,value是具体需要存储的Object。下面用一张图展示这些对象之间的引用关系,实心箭头表示强引用,空心箭头表示弱引用。

https://donglin.blog.csdn.net/article/details/126905449
使用ThreadLocal有什么问题吗?如何解决?
内存泄漏问题
当function01方法执行完毕后,栈帧销毁强引用 tl 也就没有了。但此时线程的ThreadLocalMap里某个entry的key引用还指向这个对象
若这个key引用是强引用,就会导致key指向的ThreadLocal对象及v指向的对象不能被gc回收,造成内存泄漏;
若这个key引用是弱引用就大概率会减少内存泄漏的问题(还有一个key为null的雷)。使用弱引用,就可以使ThreadLocal对象在方法执行完毕后顺利被回收且Entry的key引用指向为null。
我们调用get,set或remove方法时,就会尝试删除key为null的entry,可以释放value对象所占用的内存。
https://donglin.blog.csdn.net/article/details/126905449


![[GUET-CTF2019]encrypt 题解](https://img-blog.csdnimg.cn/1cb211f47e674b5f9a32553ad3d2578e.png)