简介
1、GPT-1 是什么?它是基于什么模型的?
GPT-1 是一种用于自然语言处理的机器学习模型,它是基于 Transformer 架构的。它是 OpenAI 在 2018 年发布的第一个 GPT 模型,有 1.17 亿个参数,比之前的语言模型有了显著的提升¹²。GPT-1 的一个优点是它能够根据给定的提示或上下文生成流畅和连贯的语言¹²。GPT-1 的训练数据是两个数据集的组合:Common Crawl,一个包含数十亿单词的网页数据集,和 BookCorpus 数据集,一个包含超过 11000 本不同类型的书籍的数据集。这些多样化的数据集使得 GPT-1 能够发展出强大的语言建模能力²。
Source: Conversation with Bing, 2023/5/12
(1) GPT-1 to GPT-4: Each of OpenAI’s GPT Models Explained … https://www.makeuseof.com/gpt-models-explained-and-compared/.
(2) Generative pre-trained transformer - Wikipedia. https://en.wikipedia.org/wiki/Generative_pre-trained_transformer.
(3) GitHub - akshat0123/GPT-1: Pytorch implementation of GPT-1. https://github.com/akshat0123/GPT-1.
2、GPT-1 的主要特点和优势是什么?
GPT-1 的主要特点和优势是:
- 它是第一个基于 Transformer 架构的生成式预训练语言模型¹²,使用自注意力机制进行训练³。
- 它有 1.17 亿个参数,比之前的语言模型有了显著的提升¹²。
- 它能够根据给定的提示或上下文生成流畅和连贯的语言¹²。
- 它的训练数据是两个数据集的组合:Common Crawl,一个包含数十亿单词的网页数据集,和 BookCorpus 数据集,一个包含超过 11000 本不同类型的书籍的数据集。这些多样化的数据集使得 GPT-1 能够发展出强大的语言建模能力²。
- 它能够在没有领域特定训练的情况下,在多种任务上实现零样本性能²³,例如问答、语言翻译和文本摘要等。
Source: Conversation with Bing, 2023/5/12
(1) GPT-1 to GPT-4: Each of OpenAI’s GPT Models Explained … https://www.makeuseof.com/gpt-models-explained-and-compared/.
(2) OpenAI GPT-n models: Shortcomings & Advantages in 2023 … https://research.aimultiple.com/gpt/.
(3) GPT-1, GPT-2 & GPT-3: Learn the Evolution of AI Language … https://360digitmg.com/blog/types-of-gpt-in-artificial-intelligence.
(4) What is GPT (GUID Partition Table) Disk and Advantage of It?. https://www.diskpart.com/gpt-mbr/gpt-guid-partition-table-disk-1203.html.
3、GPT-1 的主要局限和缺点是什么?
GPT-1 的主要局限和缺点是:
- 它的参数数量相对较少,只有 1.17 亿个,比后续的 GPT 模型小很多¹²。
- 它的训练数据相对较少,只有 Common Crawl 和 BookCorpus 两个数据集,没有包含其他类型的文本,如社交媒体、新闻、科学论文等¹²。
- 它容易生成重复的文本,尤其是当给定的提示或上下文超出了它的训练数据的范围时¹²。
- 它不能很好地处理多轮对话和长期依赖的文本,缺乏逻辑推理和常识知识¹²³。
- 它的连贯性和流畅性只限于较短的文本序列,当生成较长的段落时,会出现不一致和不相关的内容¹²。
Source: Conversation with Bing, 2023/5/12
(1) GPT-1 to GPT-4: Each of OpenAI’s GPT Models Explained … https://www.makeuseof.com/gpt-models-explained-and-compared/.
(2) ChatGPT: A comprehensive review on background … https://www.sciencedirect.com/science/article/pii/S266734522300024X.
(3) OpenAI GPT-n models: Shortcomings & Advantages in 2023 … https://research.aimultiple.com/gpt/.
Source: Conversation with Bing, 2023/5/12
(1) GPT-1 to GPT-4: Each of OpenAI’s GPT Models Explained … https://www.makeuseof.com/gpt-models-explained-and-compared/.
(2) Generative pre-trained transformer - Wikipedia. https://en.wikipedia.org/wiki/Generative_pre-trained_transformer.
(3) GPT models explained. Open AI’s GPT-1,GPT-2,GPT-3 … https://medium.com/walmartglobaltech/the-journey-of-open-ai-gpt-models-32d95b7b7fb2.
4、GPT-1 和其他语言模型(如 LSTM,BERT,GPT 2/3 等)有什么区别和联系?
GPT-1 和其他语言模型有以下一些区别和联系:
- GPT-1 是第一个基于 Transformer 架构的生成式预训练语言模型¹,使用自注意力机制进行训练²。Transformer 架构是一种新的神经网络架构,可以处理序列数据,如文本和语音,而不需要使用循环神经网络(RNN)或长短期记忆网络(LSTM)³。
- GPT-1 和 BERT 都是基于 Transformer 架构的预训练语言模型,但它们有不同的目标和方法。BERT 是一个双向的编码器模型,它可以理解文本的上下文,但不能生成新的文本。GPT-1 是一个单向的解码器模型,它可以生成新的文本,但不能很好地理解文本的上下文 。
- GPT-1 和 GPT 2/3 都是基于 Transformer 架构的生成式预训练语言模型,但它们有不同的规模和性能。GPT 2/3 比 GPT-1 有更多的参数,更大的训练数据,更好的生成质量和多样性。GPT 2/3 也能够在没有领域特定训练的情况下,在更多的任务上实现零样本或少样本性能¹ 。
Source: Conversation with Bing, 2023/5/12
(1) GPT-1 to GPT-4: Each of OpenAI’s GPT Models Explained … https://www.makeuseof.com/gpt-models-explained-and-compared/.
(2) Models - OpenAI API. https://platform.openai.com/docs/models.
(3) ChatGPT vs. Other AI Language Models: A Comparative Analysis. https://www.linkedin.com/pulse/chatgpt-vs-other-ai-language-models-comparative-analysis-smith.
5、GPT-1 可以用于什么应用场景?
GPT-1 可以用于多种自然语言处理的任务,例如问答、语言翻译、文本摘要、文本生成等¹²。它可以根据给定的提示或上下文生成合理和相关的语言输出¹²。例如,它可以生成故事、诗歌、对话等¹²。
6、GPT-1 与其他基于 Transformer 的语言模型(如 BERT 和 XLNet)有什么区别和联系?
GPT-1,BERT 和 XLNet 都是使用 Transformer 架构的生成式预训练语言模型,它们都利用了大量的无标注文本数据来学习语言的统计规律,并且可以在特定的 NLP 任务上进行微调。
GPT-1 是第一个使用 Transformer 的生成式预训练语言模型,它只使用了 Transformer 的解码器部分,采用了自回归(Autoregressive)的方式来生成语言,即根据已经生成的单词来预测下一个单词。GPT-1 只能从左到右地看到输入序列的信息,因此无法利用右侧的上下文信息。
BERT 是在 GPT-1 的基础上提出的一种改进的模型,它使用了 Transformer 的编码器部分,采用了自编码(Autoencoding)的方式来生成语言,即根据输入序列中的部分单词来预测被遮盖(Masked)的单词。BERT 能够从左到右和从右到左地看到输入序列的信息,因此能够利用双向的上下文信息。
XLNet 是在 BERT 的基础上提出的一种更先进的模型,它结合了 GPT-1 的自回归方式和 BERT 的自编码方式,采用了置换语言模型(Permutation Language Model)的方式来生成语言,即根据输入序列中的任意顺序的部分单词来预测剩余的单词。XLNet 通过随机排列输入序列中的单词顺序,能够克服 BERT 中使用掩码带来的预训练和微调不一致(Pretrain-Finetune Discrepancy)的问题,并且能够利用更丰富的上下文信息。
Source: Conversation with Bing, 2023/5/13
(1) How XLNet combines the best of GPT and BERT. https://towardsdatascience.com/understanding-the-difference-of-gpt-bert-and-xlnet-in-2-min-8aa917330ad1.
(2) tensorflow - Which model (GPT2, BERT, XLNet and etc … https://stackoverflow.com/questions/57845439/which-model-gpt2-bert-xlnet-and-etc-would-you-use-for-a-text-classification.
(3) What are the differences in Pre-Trained Transformer-base … https://medium.com/mlearning-ai/what-are-the-differences-in-pre-trained-transformer-base-models-like-bert-distilbert-xlnet-gpt-4b3ea30ef3d7.
(4) spaCy meets Transformers: Fine-tune BERT, XLNet and GPT-2. https://explosion.ai/blog/spacy-transformers/.
网络结构
7、GPT-1 的网络结构是什么?请用文字详细描述出来。
GPT-1 网络结构图 1:
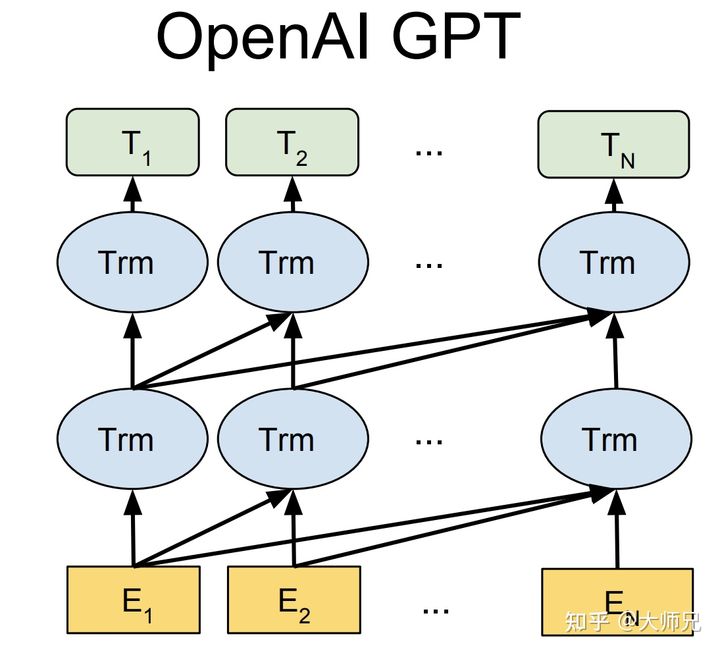
GPT-1 网络结构图 2:
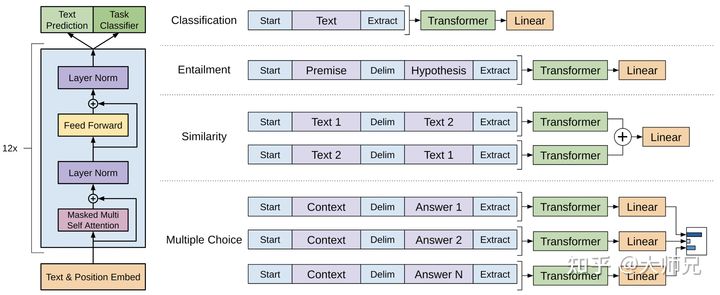
GPT-1 的网络结构基于 Transformer 的 Decoder 部分,它只使用了 Masked Multi-Head Attention 和 Feed Forward 层,并将层数扩展到 12 层,Attention 的维数扩大到 768,Attention 的头数增加到 12 个,Feed Forward 层的隐层维数增加到 3072,总参数达到 1.17 亿¹³。
GPT-1 的训练分为两个阶段:无监督预训练和有监督微调。无监督预训练的目标是最大化给定上文的条件概率,有监督微调的目标是最大化给定输入的标签概率,并加入无监督预训练的目标作为正则项¹。GPT-1 使用了 BooksCorpus 数据集进行预训练,这个数据集包含了约 5GB 的未发布的书籍¹²。
GPT-1 可以处理多种下游任务,包括文本分类、文本蕴含、语义相似度、问答等。对于不同的任务,GPT-1 有不同的输入变换方式,例如在自然语言推理任务中,它会将前提和假设用分隔符隔开,在问答任务中,它会将每个选项分别和内容拼接等¹。
Source: Conversation with Bing, 2023/5/12
(1) OpenAI ChatGPT(二):十分钟读懂 GPT-1 - 知乎. https://zhuanlan.zhihu.com/p/604625917.
(2) 预训练语言模型之GPT-1,GPT-2和GPT-3 - 知乎. https://zhuanlan.zhihu.com/p/350017443.
(3) GPT-1の仕組みを解説! | AGIRobots. https://agirobots.com/gpt-1/.
8、GPT-1 的核心机制是什么?
GPT-1是OpenAI在2018年提出的一种生成式预训练语言模型,它的核心机制是利用Transformer的Decoder部分进行无监督的语言模型预训练,然后在具体的下游任务上进行有监督的微调¹²。GPT-1使用了Masked Multi-Head Attention和Feed Forward Network组成的12层Transformer Block,以及词向量和位置向量作为输入和输出的Embedding层²³。GPT-1的总参数量达到了1.17亿,是当时最大的语言模型之一³。
Source: Conversation with Bing, 2023/5/12
(1) OpenAI ChatGPT(二):十分钟读懂 GPT-1 - 知乎. https://zhuanlan.zhihu.com/p/604625917.
(2) GPT-1の仕組みを解説! | AGIRobots. https://agirobots.com/gpt-1/.
(3) GPT-1 to GPT-4: Each of OpenAI’s GPT Models Explained … https://www.makeuseof.com/gpt-models-explained-and-compared/.
9、GPT-1 的输入层、中间层、输出层分别是什么?
GPT-1的输入层是词向量和位置向量的加和,表示为E=UW_e+W_p,其中U是当前单词的上文单词向量,W_e是词向量矩阵,W_p是位置向量矩阵。
GPT-1的中间层是由12个Transformer Block组成的堆叠结构,每个Transformer Block包含一个Masked Multi-Head Attention层和一个Feed Forward Network层,以及残差连接和层归一化。
GPT-1的输出层根据预训练和微调的不同而不同。在预训练阶段,输出层是一个线性变换加上一个softmax函数,用于预测下一个单词的概率,表示为P(u)=softmax(h_nW_e^T),其中h_n是最后一个Transformer Block的输出,W_e是词向量矩阵的转置。在微调阶段,输出层是一个任务特定的分类器或回归器,用于解决下游任务。
10、GPT-1 的位置向量是怎么学习的?
GPT-1的位置向量是一个512×768的矩阵,其中512是输入序列的最大长度,768是词向量的维度。位置向量的每一行表示一个位置的Embedding,用于捕捉文本中的顺序信息。GPT-1的位置向量是随机初始化的,并在预训练和微调的过程中进行更新,与词向量一起学习。这与Transformer原论文中使用的正弦和余弦函数生成的位置编码不同,后者是固定的,不参与学习。
11、GPT-1 的掩码机制是什么?
输入层是把整个序列输入到中间层的,但是中间层中的Masked Multi-Head Attention会使用一个掩码矩阵,来遮挡掉当前位置后面的单词的信息,从而实现只看前面的序列的效果。这个掩码矩阵是一个上三角形的矩阵,它的对角线和下方都是0,上方都是负无穷。当这个矩阵和注意力得分矩阵相加时,会使得当前位置后面的单词的注意力得分变成负无穷,然后经过softmax函数后变成0,从而忽略掉它们的影响。这样就可以保证只有前面的序列对当前位置的预测有贡献。
例如:
| 0 | -∞ | -∞ | -∞ |
|---|---|---|---|
| 0 | 0 | -∞ | -∞ |
| 0 | 0 | 0 | -∞ |
| 0 | 0 | 0 | 0 |
12、GPT-1的位置向量可以扩展到更长的序列吗?
GPT-1的位置向量是固定大小的,不能直接扩展到更长的序列。如果输入序列超过512个单词,GPT-1会截断多余的部分,导致信息的丢失。如果要处理更长的序列,GPT-1需要增加位置向量矩阵的行数,或者使用其他方法来表示位置信息,比如相对位置编码或者分层注意力机制。
13、分层注意力机制是什么?
分层注意力机制是指将输入序列分成几段,然后分别输入到多个注意力机制层,然后将输出结果拼接到一起。
14、GPT1 如何处理不同长度的输入序列?
GPT-1如何处理不同长度的输入序列,取决于输入序列的长度是否超过了最大长度。GPT-1的最大长度是512个单词,如果输入序列的长度小于或等于512,那么GPT-1可以直接处理,不需要做任何特殊的处理。如果输入序列的长度大于512,那么GPT-1会截断多余的部分,只保留前512个单词,然后再进行处理。这样做会导致信息的丢失,所以一般不建议输入过长的序列。
激活函数、损失函数、优化器
15、GPT-1 的激活函数是什么?
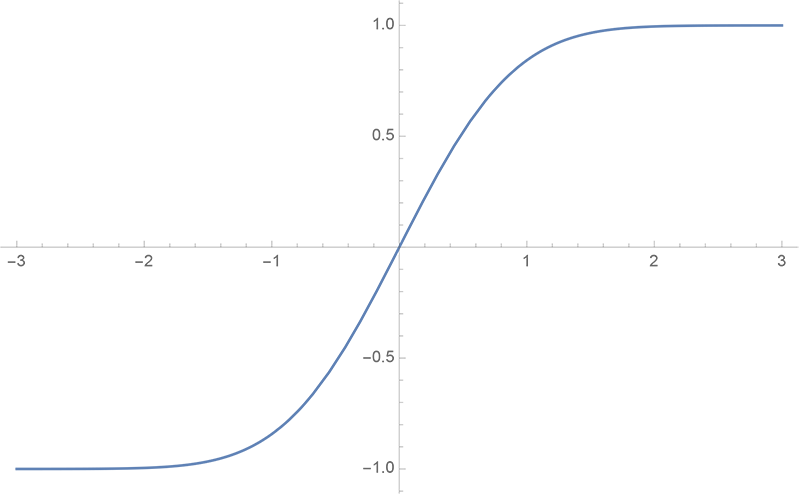
GPT-1的激活函数是GeLU,即高斯误差线性单元。¹² 它的数学表达式是:
GeLU ( x ) = x Φ ( x ) = x 1 2 [ 1 + erf ( x 2 ) ] \text{GeLU}(x) = x \Phi(x) = x \frac{1}{2} \left[1 + \text{erf}\left(\frac{x}{\sqrt{2}}\right)\right] GeLU(x)=xΦ(x)=x21[1+erf(2x)]
其中
Φ
(
x
)
\Phi(x)
Φ(x)是标准正态分布的累积分布函数,
erf
(
x
)
\text{erf}(x)
erf(x)是误差函数。其中,erf是误差函数,其图像如下:
GeLU 的曲线图如下:
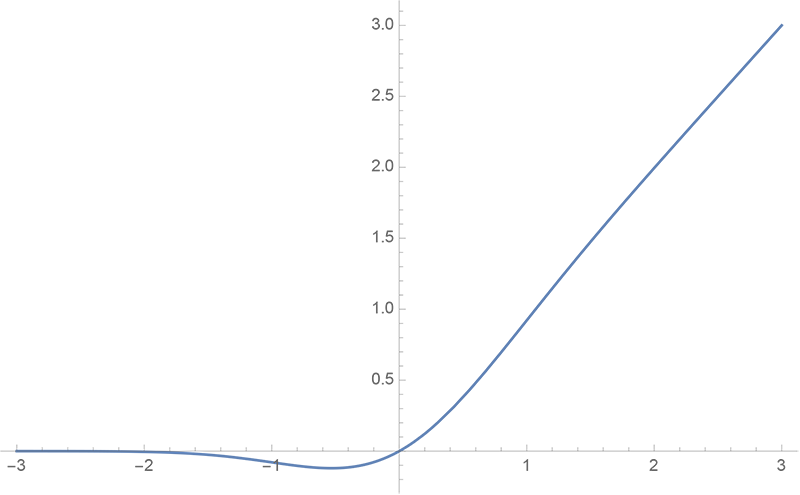
GeLU的特点是它是一个平滑的非线性函数,它可以近似模拟ReLU的性质,但是又避免了ReLU的一些缺点,比如梯度消失和死亡神经元。³ GeLU也可以更好地适应Transformer的结构,因为它可以保持输入和输出的均值和方差不变。
GPT-1使用GeLU作为中间层和输出层的激活函数,以提高模型的表达能力和学习效率。
Source: Conversation with Bing, 2023/5/12
(1) GPT models explained. Open AI’s GPT-1,GPT-2,GPT-3 … https://medium.com/walmartglobaltech/the-journey-of-open-ai-gpt-models-32d95b7b7fb2.
(2) Activation function and GLU variants for Transformer models. https://medium.com/@tariqanwarph/activation-function-and-glu-variants-for-transformer-models-a4fcbe85323f.
(3) OpenAI peeks into the “black box” of neural networks with … https://arstechnica.com/information-technology/2023/05/openai-peeks-into-the-black-box-of-neural-networks-with-new-research/.
GeLU的导数图像如下:
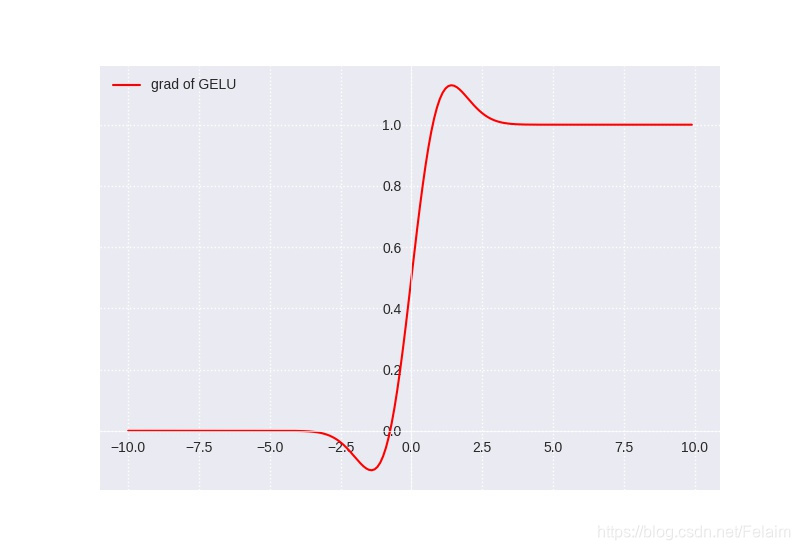
可以看到,当x越大时,导数越接近1,当x越小时,导数越接近0,而在零点附近是一个平滑的曲线,没有ReLU的尖锐变化。
GeLU的缺点有以下几点:
- GeLU的计算复杂度较高,因为它涉及到误差函数和累积分布函数的计算,这些函数没有简单的解析形式,需要近似或者数值方法。¹
- GeLU的导数也没有简单的解析形式,需要额外的计算,这会增加反向传播的开销。¹
- GeLU的输出不是零均值的,这可能会影响模型的收敛速度和稳定性。²
Source: Conversation with Bing, 2023/5/12
(1) relu, GeLU , swish, mish activation function comparison. https://chadrick-kwag.net/relu-GeLU-swish-mish-activation-function-comparison/.
(2) [1606.08415] Gaussian Error Linear Units (GeLUs) - arXiv.org. https://arxiv.org/abs/1606.08415.
(3) GeLU activation explained | Towards AI. https://pub.towardsai.net/is-GeLU-the-relu-successor-deep-learning-activations-7506cf96724f.
(4) GeLU Explained | Papers With Code. https://paperswithcode.com/method/GeLU.
16、GPT-1 的损失函数是什么?
GPT-1的损失函数是标准的语言模型损失函数,即通过上文预测当前词的对数似然,表示如下:
L 1 ( U ) = ∑ i log P ( u i ∣ u i − k , . . . , u i − 1 ; θ ) L_1(\mathcal{U})=\sum_i \text{log}P(u_i|u_{i-k},...,u_{i-1};\theta) L1(U)=i∑logP(ui∣ui−k,...,ui−1;θ)
其中 k k k 是窗口大小, U \mathcal{U} U 是输入文本, θ \theta θ 是模型参数。
Source: Conversation with Bing, 2023/5/12
(1) OpenAI ChatGPT(二):十分钟读懂 GPT-1 - 知乎. https://zhuanlan.zhihu.com/p/604625917.
(2) GitHub - akshat0123/GPT-1: Pytorch implementation of GPT-1. https://github.com/akshat0123/GPT-1.
(3) GPT-1/GPT-2/GPT-3简介 - 知乎. https://zhuanlan.zhihu.com/p/473001104.
17、对数似然函数跟交叉熵函数有什么联系和区别?
对数似然函数和交叉熵函数的联系和区别如下:
- 对数似然函数是指给定一个概率模型和一组观测数据,计算数据在该模型下出现的对数概率,表示为:
log P ( D ∣ θ ) \text{log}P(D|\theta) logP(D∣θ)
其中 D D D 是观测数据, θ \theta θ 是模型参数。
- 交叉熵函数是指用来衡量两个概率分布之间的差异,表示为:
H ( P , Q ) = − ∑ x P ( x ) log Q ( x ) H(P,Q)=-\sum_x P(x)\text{log}Q(x) H(P,Q)=−x∑P(x)logQ(x)
其中 P P P 和 Q Q Q 是两个概率分布。
- 对数似然函数和交叉熵函数的联系是,当用一个概率分布 Q Q Q 来近似另一个概率分布 P P P 时,可以通过最小化交叉熵来实现。此时,交叉熵可以分解为两部分:
H ( P , Q ) = H ( P ) + D K L ( P ∣ ∣ Q ) H(P,Q)=H(P)+D_{KL}(P||Q) H(P,Q)=H(P)+DKL(P∣∣Q)
其中 H ( P ) H(P) H(P) 是 P P P 的香农熵,表示 P P P 的不确定性,是一个常数; D K L ( P ∣ ∣ Q ) D_{KL}(P||Q) DKL(P∣∣Q) 是 P P P 和 Q Q Q 之间的相对熵(KL散度),表示两个分布的差异,是非负的。因此,最小化交叉熵等价于最大化对数似然函数。
- 对数似然函数和交叉熵函数的区别是,对数似然函数只涉及一个概率分布,而交叉熵函数涉及两个概率分布;对数似然函数是一种最大化方法,而交叉熵函数是一种最小化方法;对数似然函数通常用于无监督学习中的概率模型拟合,而交叉熵函数通常用于监督学习中的分类问题。
Source: Conversation with Bing, 2023/5/12
(1) 【损失函数】交叉熵损失函数简介 - 知乎. https://zhuanlan.zhihu.com/p/124309304.
(2) 损失函数 | 负对数似然 - 知乎. https://zhuanlan.zhihu.com/p/35709139.
(3) 如何理解似然函数? - 知乎. https://www.zhihu.com/question/54082000.
18、GPT-1 的优化器是什么?
GPT-1的优化器是Adam,它是一种基于梯度下降的优化算法,可以自适应地调整学习率和动量。
Source: Conversation with Bing, 2023/5/13
(1) OpenAI ChatGPT(二):十分钟读懂 GPT-1 - 知乎. https://zhuanlan.zhihu.com/p/604625917.
(2) GPT-1の仕組みを解説! | AGIRobots. https://agirobots.com/gpt-1/.
(3) 预训练语言模型之GPT-1,GPT-2和GPT-3 - 知乎. https://zhuanlan.zhihu.com/p/350017443.
评估标准
19、GPT1 如何评估语言模型的性能?请列举几个常用的评价指标,并说明它们的优缺点。
语言模型的性能评估通常有两个方面:困惑度(perplexity)和下游任务的表现。
困惑度是语言模型对测试集的预测能力的度量,它反映了语言模型对未知文本的不确定性。困惑度越低,说明语言模型越准确,越能够预测下一个词。困惑度的计算公式是:
P P L = exp ( − 1 N ∑ i = 1 N log P ( w i ∣ w < i ) ) PPL = \exp(-\frac{1}{N}\sum_{i=1}^N \log P(w_i|w_{<i})) PPL=exp(−N1i=1∑NlogP(wi∣w<i))
其中, N N N是测试集的词数, P ( w i ∣ w < i ) P(w_i|w_{<i}) P(wi∣w<i) 是语言模型给出的第 i i i个词的条件概率。
困惑度的优点是它是一个客观的指标,可以用来比较不同的语言模型。缺点是它不能直接反映语言模型在具体任务上的效果,比如机器翻译、文本生成、问答等。
下游任务的表现是指将语言模型作为预训练模型,然后在特定的任务上进行微调,得到的任务指标,比如准确率、召回率、BLEU分数等。这些指标可以反映语言模型在实际应用中的价值和能力。下游任务的表现的优点是它更贴近实际需求,可以评估语言模型的泛化能力和迁移能力。缺点是它受到任务本身和微调方法的影响,可能不能完全体现语言模型本身的质量。
GPT-1是一种生成式预训练语言模型,它使用了Transformer解码器作为网络结构,在大规模无标注文本上进行自回归语言建模预训练,然后在不同的下游任务上进行微调。GPT-1在12个自然语言理解和生成任务上都取得了当时最好或接近最好的结果¹²³。
Source: Conversation with Bing, 2023/5/13
(1) 预训练语言模型之GPT-1,GPT-2和GPT-3 - 知乎. https://zhuanlan.zhihu.com/p/350017443.
(2) GPT系列论文阅读笔记 - 知乎. https://zhuanlan.zhihu.com/p/412351920.
(3) OpenAI ChatGPT(二):十分钟读懂 GPT-1 - 知乎. https://zhuanlan.zhihu.com/p/604625917.
20、什么是BLEU?
BLEU分数是一种用来评估机器翻译质量的指标,它基于参考翻译和机器翻译之间的n-gram匹配程度来计算。BLEU分数的取值范围是0到1,越接近1表示机器翻译越接近参考翻译¹²。
BLEU分数的计算公式是:
B L E U = B P ⋅ exp ( ∑ n = 1 N w n log p n ) BLEU = BP \cdot \exp(\sum_{n=1}^N w_n \log p_n) BLEU=BP⋅exp(n=1∑Nwnlogpn)
其中, B P BP BP是简短惩罚因子,用来防止过短的机器翻译得到高分, w n w_n wn是n-gram的权重, p n p_n pn是n-gram的精确度,即机器翻译中的n-gram有多少在参考翻译中出现过³⁴。
BLEU分数的优点是它简单、快速、客观,可以用来比较不同的机器翻译系统。缺点是它不能考虑语言表达的流畅性、语法正确性、语义一致性等方面,也不能反映不同领域和任务的特点。
Source: Conversation with Bing, 2023/5/13
(1) Metric评价指标-机器翻译指标之BLEU - 知乎. https://zhuanlan.zhihu.com/p/350596071.
(2) BLEU score评估模型 - 知乎. https://zhuanlan.zhihu.com/p/338488036.
(3) 机器翻译与自动文摘评价指标 BLEU 和 ROUGE - 简书. https://www.jianshu.com/p/0afb93fda403.
(4) 机器学习笔记 - 什么是BLEU分数?_坐望云起的博客-CSDN博客. https://blog.csdn.net/bashendixie5/article/details/125055325.
21、PPL 和 BLEU 的比较
BLEU和PPL是两种不同的指标,它们衡量的是不同的方面。BLEU是用来评估机器翻译的输出质量,PPL是用来评估语言模型的预测能力。它们不能直接比较,也没有绝对的好坏之分。一般来说,BLEU更适合评估生成式任务,如机器翻译、文本摘要等,PPL更适合评估建模任务,如语言理解、文本分类等。
超参数
22、GPT-1 的超参数分别有哪些?
GPT-1的超参数分别有以下几种:
- 学习率:GPT-1使用了Adam优化器,初始学习率设置为6.25e-5,并在训练过程中线性衰减到0。
- 批量大小:GPT-1的批量大小设置为32,即每次输入32个句子进行训练。
- 训练步数:GPT-1的训练步数设置为800000,即总共训练了800000个批量。
- 滑动窗口大小:GPT-1的滑动窗口大小设置为512,即每个句子最多包含512个单词。
- 词嵌入维度:GPT-1的词嵌入维度设置为768,即每个单词用一个768维的向量表示。
- 位置嵌入维度:GPT-1的位置嵌入维度也设置为768,即每个位置用一个768维的向量表示。
- Transformer层数:GPT-1使用了12层的Transformer模块作为解码器,每层包含一个Masked Multi-Head Attention和一个Feed Forward网络。
- Attention头数:GPT-1的Attention头数设置为12,即每层的Masked Multi-Head Attention由12个子Attention组成。
- Attention维度:GPT-1的Attention维度设置为64,即每个子Attention的输入和输出都是64维的向量。
- Feed Forward隐层维度:GPT-1的Feed Forward隐层维度设置为3072,即每层的Feed Forward网络由一个3072维的隐层组成。
Source: Conversation with Bing, 2023/5/13
(1) 预训练语言模型之GPT-1,GPT-2和GPT-3 - 知乎. https://zhuanlan.zhihu.com/p/350017443.
(2) OpenAI ChatGPT(二):十分钟读懂 GPT-1 - 知乎. https://zhuanlan.zhihu.com/p/604625917.
(3) GPT-1/GPT-2/GPT-3/GPT-3.5 语言模型详细介绍 - 知乎. https://zhuanlan.zhihu.com/p/620494604.
23、GPT1 的参数数量是多少?它相比于之前的语言模型有多大的提升?
GPT-1的参数数量是1.17亿,它相比于之前的语言模型有很大的提升。例如,在文本蕴含任务上,GPT-1的准确率达到了82.1%,超过了当时的最佳模型ESIM²的81.5%。在问答任务上,GPT-1的准确率达到了59.4%,超过了当时的最佳模型BiDAF³的58.0%。在语义相似度任务上,GPT-1的皮尔逊相关系数达到了0.884,超过了当时的最佳模型InferSent的0.877。这些结果表明,GPT-1通过在大规模无标注数据上进行预训练,可以有效地提高语言理解能力,并在多个下游任务上取得优异的性能。
Source: Conversation with Bing, 2023/5/13
(1) OpenAI ChatGPT(二):十分钟读懂 GPT-1 - 知乎. https://zhuanlan.zhihu.com/p/604625917.
(2) 预训练语言模型之GPT-1,GPT-2和GPT-3 - 知乎. https://zhuanlan.zhihu.com/p/350017443.
(3) GPT-1の仕組みを解説! | AGIRobots. https://agirobots.com/gpt-1/.
训练
24、GPT-1 是如何训练的?
GPT-1的训练分为两个阶段:无监督预训练和有监督微调。无监督预训练是基于语言模型进行训练的,给定一个无标签的序列,语言模型的优化目标是最大化下面的似然值:
L 1 ( U ) = ∑ i log P ( u i ∣ u i − k , … , u i − 1 ; Θ ) L_1 (\mathcal {U}) = \sum_i \log P (u_i | u_ {i-k}, \dots, u_ {i-1}; \Theta) L1(U)=i∑logP(ui∣ui−k,…,ui−1;Θ)
其中 k 是滑动窗口的大小, P 是条件概率, Θ \Theta Θ 是模型的参数。GPT-1使用了12个变体的Transformer块作为解码器,每个Transformer块只包含Masked Multi-Head Attention和Feed Forward层。
有监督微调是在具体任务上对预训练模型进行调整,以解决具体的下游任务,如文本分类、文本蕴含、语义相似度、问答等。对于一个有标签的数据集,每个实例有 m 个输入token和一个标签 y 组成。首先将这些token输入到预训练模型中,得到最终的特征向量 h l m h_l^m hlm 。然后再通过一个全连接层得到预测结果 y :
P ( y ∣ x 1 , … , x m ) = softmax ( h l m W y ) P (y|x^1, \dots, x^m) = \text {softmax} (h^m_l W_y) P(y∣x1,…,xm)=softmax(hlmWy)
其中 W y W_y Wy 为全连接层的参数。有监督的目标则是最大化下面的值:
L 2 ( C ) = ∑ x , y log P ( y ∣ x 1 , … , x m ) L_2 (\mathcal {C}) = \sum_ {x,y} \log P (y|x^1, \dots, x^m) L2(C)=x,y∑logP(y∣x1,…,xm)
作者并没有直接使用 L 2 L_2 L2 ,而是向其中加入了 L 1 L_1 L1 ,并使用 λ \lambda λ 进行两个任务权值的调整, λ \lambda λ 的值一般为 0.5 :
L 3 ( C ) = L 2 ( C ) + λ L 1 ( C ) L_3 (\mathcal {C}) = L_2 (\mathcal {C}) + \lambda L_1 (\mathcal {C}) L3(C)=L2(C)+λL1(C)
当进行有监督微调的时候,作者只训练输出层的 W y W_y Wy 和分隔符(delimiter)的嵌入值。
Source: Conversation with Bing, 2023/5/13
(1) OpenAI ChatGPT(二):十分钟读懂 GPT-1 - 知乎. https://zhuanlan.zhihu.com/p/604625917.
(2) 预训练语言模型之GPT-1,GPT-2和GPT-3 - 知乎. https://zhuanlan.zhihu.com/p/350017443.
25、在微调时,不是只应该计算微调任务的损失函数吗?为什么还要加上预训练的损失函数?
在微调时,加上预训练的损失函数是为了防止过拟合,保持模型的泛化能力。因为有些下游任务的数据集可能很小或者很不平衡,如果只计算微调任务的损失函数,可能会导致模型忘记预训练时学到的语言知识,或者过度适应特定任务的数据分布。通过加上预训练的损失函数,可以让模型在微调时仍然考虑到语言模型的目标,从而提高模型的鲁棒性和可迁移性。
26、那 BERT 为什么不在微调时,在损失函数里加入预训练的损失函数?
可能有以下几个原因:
- BERT的预训练任务已经足够强大,可以捕捉到丰富的语言知识,不需要在微调时再考虑预训练的目标。
- BERT的预训练任务和下游任务可能存在一定的冲突或不一致,比如Masked Language Modeling会掩盖一些重要的信息,而下游任务可能需要这些信息。
- BERT的预训练任务和下游任务的损失函数可能不容易进行权衡或组合,比如预训练任务是多分类问题,而下游任务是回归问题。
- BERT的预训练任务和下游任务的数据分布可能有较大差异,如果在微调时再加入预训练的损失函数,可能会导致模型过度适应预训练数据,而忽略下游数据。
27、GPT1 如何生成文本?请介绍它使用的采样策略和温度参数。
GPT-1是一个基于Transformer的自回归语言模型,它可以生成文本的方式是根据给定的上下文,预测下一个词的概率分布,并从中采样一个词作为输出。GPT-1使用的采样策略有两种:
- 贪婪采样(Greedy Sampling):每次选择概率最大的词作为输出,这种方式生成的文本通常比较流畅,但也容易陷入重复或无意义的循环。
- 核采样(Nucleus Sampling):每次选择概率累积达到一定阈值(比如0.9)的词作为候选集合,并从中随机采样一个词作为输出,这种方式生成的文本通常比较多样化,但也可能出现一些不合逻辑或不连贯的情况。
GPT-1还使用了一个温度参数(Temperature Parameter)来调节采样的随机性。温度参数是一个正数,它可以影响概率分布的形状。当温度参数接近0时,概率分布趋向于一个狭窄的尖峰,这时候采样的结果接近于贪婪采样;当温度参数接近无穷大时,概率分布趋向于一个平坦的均匀分布,这时候采样的结果接近于随机采样。温度参数可以根据不同的任务和需求进行调节,一般来说,温度参数越大,生成的文本越多样化,但也越不稳定;温度参数越小,生成的文本越流畅,但也越单调。
Source: Conversation with Bing, 2023/5/13
(1) GPT系列论文阅读笔记 - 知乎. https://zhuanlan.zhihu.com/p/412351920.
(2) 预训练语言模型之GPT-1,GPT-2和GPT-3 - 知乎. https://zhuanlan.zhihu.com/p/350017443.
(3) OpenAI ChatGPT(二):十分钟读懂 GPT-1 - 知乎. https://zhuanlan.zhihu.com/p/604625917.
微调
28、GPT1 如何进行下游任务的微调?请举例说明一个下游任务,并描述其输入和输出格式。
GPT-1是一种生成式预训练语言模型,它的微调过程是在无监督预训练的基础上,针对特定的下游任务,添加一层全连接层,并使用语言模型的目标函数作为辅助目标函数来增强学习效果¹²。
一个下游任务的例子是文本分类,它的目的是判断输入文本属于哪个类别。它的输入格式是在原始文本的两端添加起始和终止token,然后输入到预训练好的GPT-1模型中,得到最后一个token对应的特征向量。它的输出格式是一个类别标签或者一个概率分布,它是通过将特征向量输入到添加的全连接层并经过softmax得到的¹³。
Source: Conversation with Bing, 2023/5/13
(1) 预训练语言模型之GPT-1,GPT-2和GPT-3 - 知乎. https://zhuanlan.zhihu.com/p/350017443.
(2) GPT-1 & 2: 预训练+微调带来的奇迹 - 知乎. https://zhuanlan.zhihu.com/p/99953380.
(3) OpenAI ChatGPT(二):十分钟读懂 GPT-1 - 知乎. https://zhuanlan.zhihu.com/p/604625917.
改进
29、在 GPT-1 中引入知识图谱的研究
- 一篇论文¹,介绍了如何使用知识图谱和 GPT-1 来生成对话,作者使用了 ConceptNet 和 Wikidata 作为知识图谱,使用了图神经网络和注意力机制来融合知识和文本,实验结果表明,这种方法可以提高对话的质量和多样性。
- 一个项目²,是一个基于 GPT-1 的 Pytorch 实现,作者在预训练阶段使用了 Freebase 作为知识图谱,使用了一个简单的查询机制来获取相关的知识,然后将知识向量和文本向量进行拼接,作为 GPT-1 的输入。
- 一篇论文³,介绍了如何使用知识图谱和 GPT-1 来生成摘要,作者使用了 Wikidata 作为知识图谱,使用了一个双向注意力机制来融合知识和文本,实验结果表明,这种方法可以提高摘要的准确性和流畅性。
Source: Conversation with Bing, 2023/5/13
(1) OpenAI ChatGPT(二):十分钟读懂 GPT-1 - 知乎. https://zhuanlan.zhihu.com/p/604625917.
(2) Generative pre-trained transformer - Wikipedia. https://en.wikipedia.org/wiki/Generative_pre-trained_transformer.
(3) 预训练语言模型之GPT-1,GPT-2和GPT-3 - 知乎. https://zhuanlan.zhihu.com/p/350017443.
代码
30、使用 pytorch 来实现 GPT-1 的代码
可以参考以下的链接:
- ¹ GitHub - akshat0123/GPT-1: Pytorch implementation of GPT-1
- ² GitHub - karpathy/minGPT: A minimal PyTorch re-implementation of the OpenAI GPT (Generative Pretrained Transformer) training
- ³ GPT-1 | Paper Explained & PyTorch Implementation - YouTube
这些代码都是基于 GPT-1 的论文来实现的,你可以根据自己的需要进行修改和调整。
Source: Conversation with Bing, 2023/5/13
(1) GitHub - akshat0123/GPT-1: Pytorch implementation of GPT-1. https://github.com/akshat0123/GPT-1.
(2) GitHub - karpathy/minGPT: A minimal PyTorch re … https://github.com/karpathy/minGPT.
(3) GPT-1 | Paper Explained & PyTorch Implementation - YouTube. https://www.youtube.com/watch?v=Vmqy3VP6DFk.
31、在 GPT-1 中引入知识图谱
假设我们使用 ConceptNet 作为知识图谱,使用图神经网络和注意力机制来融合知识和文本,使用 GPT-1 来生成对话,那么伪代码可能是这样的:
# 导入相关的库
import torch
import transformers
import dgl
# 加载预训练的 GPT-1 模型和分词器
model = transformers.AutoModelForCausalLM.from_pretrained("gpt")
tokenizer = transformers.AutoTokenizer.from_pretrained("gpt")
# 加载 ConceptNet 的知识图谱
kg = dgl.data.ConceptNet()
# 定义一个函数,根据输入的文本,查询知识图谱中的相关实体和关系
def query_kg(text):
# 使用分词器将文本转换为 token
tokens = tokenizer.tokenize(text)
# 初始化一个空的列表,用于存储查询到的知识
knowledge = []
# 遍历每个 token
for token in tokens:
# 如果 token 是一个实体,即在知识图谱中有对应的节点
if token in kg.nodes:
# 获取该实体的邻居节点和边的类型
neighbors = kg.successors(token)
edge_types = kg.edata["type"][token]
# 遍历每个邻居节点和边的类型
for neighbor, edge_type in zip(neighbors, edge_types):
# 将实体、关系和邻居实体组成一个三元组,添加到知识列表中
triple = (token, edge_type, neighbor)
knowledge.append(triple)
# 返回知识列表
return knowledge
# 定义一个函数,根据输入的文本和知识,使用图神经网络和注意力机制来融合知识和文本,得到融合后的向量
def fuse_knowledge(text, knowledge):
# 使用分词器将文本转换为 token,并添加起始和结束符号
tokens = [tokenizer.bos_token] + tokenizer.tokenize(text) + [tokenizer.eos_token]
# 使用分词器将 token 转换为 id,并转换为张量
input_ids = torch.tensor(tokenizer.convert_tokens_to_ids(tokens))
# 使用 GPT-1 模型对输入 id 进行编码,得到文本向量
text_vector = model(input_ids)[0]
# 初始化一个空的图,用于存储知识图谱中的节点和边
g = dgl.DGLGraph()
# 遍历每个知识三元组
for head, relation, tail in knowledge:
# 将头实体和尾实体作为节点添加到图中,如果已经存在则跳过
g.add_nodes(head)
g.add_nodes(tail)
# 将关系作为边的类型添加到图中,连接头实体和尾实体
g.add_edge(head, tail, data={"type": relation})
# 使用预训练的实体嵌入矩阵,将图中的每个节点转换为向量
entity_embedding = torch.load("entity_embedding.pt")
node_features = entity_embedding[g.nodes]
# 使用图卷积网络,对图中的节点向量进行更新,得到知识向量
gcn = dgl.nn.GCNConv(in_feats, out_feats)
knowledge_vector = gcn(g, node_features)
# 使用注意力机制,计算文本向量和知识向量之间的相似度,并进行加权求和,得到融合后的向量
attention = torch.nn.MultiheadAttention(embed_dim, num_heads)
fused_vector, _ = attention(text_vector, knowledge_vector, knowledge_vector)
# 返回融合后的向量
return fused_vector
# 定义一个函数,根据输入的融合向量,使用 GPT-1 模型来生成对话
def generate_dialogue(fused_vector):
# 初始化一个空的列表,用于存储生成的 token
generated_tokens = []
# 初始化一个结束标志,用于判断是否停止生成
stop_flag = False
# 循环生成 token,直到达到最大长度或者遇到结束符号
while len(generated_tokens) < max_length and not stop_flag:
# 使用 GPT-1 模型对融合向量进行解码,得到下一个 token 的概率分布
logits = model(fused_vector)[0]
# 使用 softmax 函数将 logits 转换为概率值
probs = torch.nn.functional.softmax(logits, dim=-1)
# 使用 multinomial 函数从概率分布中采样一个 token 的 id
token_id = torch.multinomial(probs, 1)
# 使用分词器将 token 的 id 转换为 token
token = tokenizer.convert_ids_to_tokens(token_id)
# 将 token 添加到生成的列表中
generated_tokens.append(token)
# 如果 token 是结束符号,设置结束标志为真
if token == tokenizer.eos_token:
stop_flag = True
# 使用分词器将生成的 token 列表转换为文本
generated_text = tokenizer.convert_tokens_to_string(generated_tokens)
# 返回生成的文本
return generated_text
# 调用上面定义的函数,根据输入的文本和知识,生成对话
text = "你喜欢什么颜色?"
knowledge = query_kg(text)
fused_vector = fuse_knowledge(text, knowledge)
generated_text = generate_dialogue(fused_vector)
print(generated_text)
代码可能有以下一些问题:
- 这个伪代码没有考虑知识图谱中的实体和关系的权重,可能会导致一些不相关或者不重要的知识被融合进来,影响生成的质量。
- 这个伪代码没有考虑文本和知识之间的上下文关系,可能会导致一些不一致或者不合理的生成结果,比如对话中的指代消解或者逻辑推理。
- 这个伪代码没有考虑生成过程中的多样性和连贯性,可能会导致一些重复或者跳跃的生成结果,比如对话中的话题转换或者情感表达。