MapReduce是Hadoop系统核心组件之一,它是一种可用于大数据并行处理的计算模型、框架和平台,主要解决海量数据的计算,是目前分布式计算模型中应用较为广泛的一种。
练习:计算a.txt文件中每个单词出现的次数
hello world hello hadoop hello 51doit hadoop mapreduce mapreduce spark
public class WordCount {
public static void main(String[] args) throws IOException {
//获取到resource文件夹下a.txt的路径
URL resource = WordCount.class.getClassLoader().getResource("a.txt");
String path = resource.getPath();
//使用FileUtils将文件读取成字符串
String s = FileUtils.readFileToString(new File(path),"utf-8");
//将文件使用空格进行切割 \s可以切割 空格 tab键
String[] arr = s.split("\\s+");
//创建Map集合
Map<String,Integer> map = new HashMap<>();
//遍历数组
for (String s1 : arr) {
//判断集合是否包含指定键
if(!map.containsKey(s1)){
//如果不包含 添加 单词 1
map.put(s1,1);
}else{
//如果包含 获取当前键的次数 +1 在添加回集合
Integer count = map.get(s1);
map.put(s1,count+1);
}
}
System.out.println(map);
}
}
通过以上的方式 计算出来了a.txt文件中每个单词出现的次数,但是我们想一下 ,如果a.txt文件非常大,怎么办?
比如有一个a.txt文件10个T的大小。这时一台计算机就没有办法计算了,因为我们根本存储不了,计算不了,那么一台计算机无法计算,就使用多台计算机来进行计算!
1.1 MapReduce核心思想
MapReduce的核心思想是“分而治之”。所谓“分而治之”就是把一个复杂的问题,按照一定的“分解”方法分为等价的规模较小的若干部分,然后逐个解决,分别找出各部分的结果,把各部分的结果组成整个问题的结果,这种思想来源于日常生活与工作时的经验,同样也完全适合技术领域。
为了更好地理解“分而治之”思想,我们光来举一个生活的例子。例如,某大型公司在全国设立了分公司,假设现在要统计公司今年的营收情况制作年报,有两种统计方式,第1种方式是全国分公司将自己的账单数据发送至总部,由总部统一计算公司今年的营收报表:第2种方式是采用分而治之的思想,也就是说,先要求分公司各自统计营收情况,再将统计结果发给总部进行统一汇总计算。这两种方式相比,显然第2种方式的策略更好,工作效率更高效。
MapReduce 作为一种分布式计算模型,它主要用于解决海量数据的计算问题。使用MapReduce操作海量数据时,每个MapReduce程序被初始化为一个工作任务,每个工作任务可以分为Map 和l Reducc两个阶段,具体介绍如下:
Map阶段::负责将任务分解,即把复杂的任务分解成若干个“简单的任务”来行处理,但前提是这些任务没有必然的依赖关系,可以单独执行任务。
Reduce阶段:负责将任务合并,即把Map阶段的结果进行全局汇总。下面通过一个图来描述上述MapReduce 的核心思想。
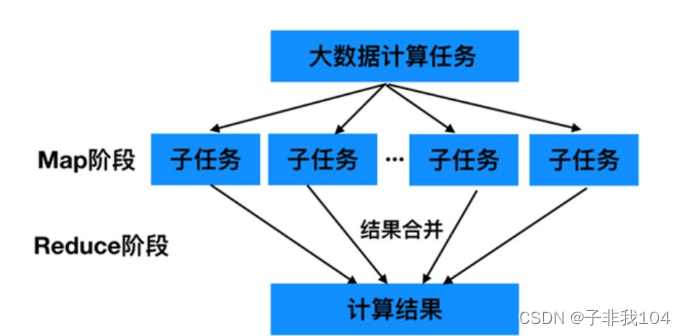
MapReduce就是“任务的分解与结和的汇总”。即使用户不懂分布式计算框架的内部运行机制,但是只要能用Map和 Reduce思想描述清楚要处理的问题,就能轻松地在Hadoop集群上实现分布式计算功能。
1.2 MapReduce编程模型
MapReduce是一种编程模型,用于处理大规模数据集的并行运算。使用MapReduce执行计算任务的时候,每个任务的执行过程都会被分为两个阶段,分别是Map和Reduce,其中Map阶段用于对原始数据进行处理,Reduce阶段用于对Map阶段的结果进行汇总,得到最终结果。
MapReduce简易模型
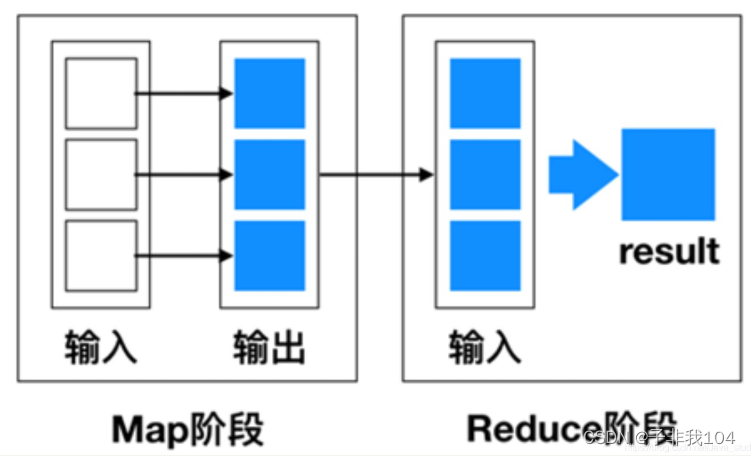
MapReduce编程模型借鉴了函数式程序设计语言的设计思想,其程序实现过程是通过map()和l reduce()函数来完成的。从数据格式上来看,map()函数接收的数据格式是键值对,生的输出结果也是键值对形式,reduce()函数会将map()函数输出的键值对作为输入,把相同key 值的 value进行汇总,输出新的键值对。接下来,通过一张图来描述MapReduce的简易数据流模型。
(1)将原始数据处理成键值对<K1,V1>形式。
(2)将解析后的键值对<K1,V1>传给map()函数,map()函数会根据映射规则,将键值对<K1,V1>映射为一系列中间结果形式的键值对<K2,V2>。
(3)将中间形式的键值对<K2,V2>形成<K2,{V2,....>形式传给reduce()函数处理,把具有相同key的value合并在一起,产生新的键值对<K3,V3>,此时的键值对<K3,V3>就是最终输出的结果。
这里需要说明的是,对于某些任务来说,可能不一定需要Reduce过程,也就是说,MapReduce 的数据流模型可能只有Map 过程,由 Map产生的数据直接被写入HDFS中。但是,对于大多数任务来说,都是需要Reduce 过程的,并且可能由于任务繁重,需要设定多个 Reduce,例如,下面是一个具有多个Map 和Reduce的 MapReduce模型.
1.3 WorldCount词频统计案例
1.3.1 序列化知识点补充
因为我们的数据都存储在不同的计算机中,那么将对象中的数据从网络中传输,就一定要用到序列化!
/*
JDK序列化对象的弊端
我们进行序列化 其实最主要的目的是为了 序列化对象的属性数据
比如如果序列化一个Person对象 new Person("柳岩",38); 其实我们想要的是 柳岩 38
但是如果直接序列化一个对象的话 JDK为了反序列化方便 会在文件中加入其他的数据 这样
序列化后的文件会变的很大,占用空间
*/
public class Test {
public static void main(String[] args) throws Exception {
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("d:\\person.txt"));
//JDK序列化对象
Person p = new Person();
p.setName("柳岩");
p.setAge(38);
oos.writeObject(p);
oos.close();
}
}
本来其实数据就占几个字节,序列化后,多占用了很多字节,这样如果序列化多的话就会浪费很多空间.
/*
我们可以通过序列化属性的方式解决问题
只序列化属性 这样可以减小序列化后的文件大小
*/
public class Test {
public static void main(String[] args) throws Exception {
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("d:\\person.txt"));
Person p = new Person();
p.setName("柳岩");
p.setAge(38);
//只序列化属性
oos.writeUTF(p.getName());
oos.writeInt(p.getAge());
oos.close();
}
}
/*
需要注意
反序列化时 需要按照序列化的顺序来反序列化
*/
public class Test {
public static void main(String[] args) throws Exception {
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("d:\\person.txt"));
//先反序列化name 在反序列化age
String name = ois.readUTF();
int age = ois.readInt();
System.out.println(name + " "+age);
ois.close();
}
}
Hadoop对java的序列化又进行了优化,对一些类型进行了进一步的封装,方便按照自己的方式序列化
Integer ----> IntWritable Long ----> LongWritable String ----> Text Double ----> DoubleWritable Boolean ----> BooleanWritable
1.3.2 WorldCount代码编写
map函数定义
/*
KEYIN: K1
VALUIN: V1
KEYOUT:K2
VALUEOUT:V2
*/
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
protected void map(KEYIN key, VALUEIN value, Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {
}
}
我们只需要继承Mapper类,重写map方法就好
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/*
K1 : 行起始位置 数字 Long ---- > LongWritable
V1 : 一行数据 字符串 String -----> Text
K2 : 单词 字符串 String -----> Text
V2 : 固定数字1 数组 Long -----> LongWritable
*/
public class WordCountMapper extends Mapper<LongWritable, Text,Text,LongWritable> {
/**
*
* @param key K1
* @param value V1
* @param context 上下文对象 将map的结果 输出给reduce
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//将一行数据 转换成字符串 按照空格切割
String[] arr = value.toString().split("\\s+");
for (String k2 : arr) {
//将单词输出给reduce
context.write(new Text(k2),new LongWritable(1));
}
}
}
reduce函数定义
/*
KEYIN:K2
VALUEIN:V2
KEYOUT:K3
VALUEOUT:V3
*/
public class Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
protected void reduce(KEYIN key, Iterable<VALUEIN> values, Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {
}
}
我们只需要继承Reducer类型重写reduce方法就好
/*
K2:单词 String ----> Text
V2:固定数字 1 Long ----> LongWritable
K3:单词 String ----> Text
V3:相加后的结果 Long ----> LongWritable
*/
public class WordCountReducer extends Reducer<Text,LongWritable,Text,LongWritable> {
/**
*
* @param key K2
* @param values V2的集合 {1,1,1,1}
* @param context 上下文对象 输出结果
*/
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
//将次数相加
for (LongWritable value : values) {
count+=value.get();
}
//写出 k3 v3
context.write(key,new LongWritable(count));
}
}
最后编写启动程序
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class Test {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//创建配置对象
Configuration conf = new Configuration();
//创建工作任务
Job job = Job.getInstance(conf, "wordCount");
//设置Map类
job.setMapperClass(WordCountMapper.class);
//设置Reduce类
job.setReducerClass(WordCountReducer.class);
//设置map的输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置reduce的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//设置读取文件位置 可以是文件 也可以是文件夹
FileInputFormat.setInputPaths(job,new Path("d:\\work\\abc"));
//设置输出文件位置
FileOutputFormat.setOutputPath(job,new Path("d:\\work\\abc\\out_put"));
//提交任务 并等待任务结束
job.waitForCompletion(true);
}
}
如果抛这个异常 需要查看windows环境
Exception in thread "main"java.lang .UnsatisfiedLinkError: org.apache .hadoop.io.nativeio.NativeIO$windows.access0(Ljava/lang/string;1) .
如果已经配置了环境 还不行 在src新建包 org.apache.hadoop.io.nativeio
然后hadoop02文件夹中的 NativeIO.java添加到这个包下 重新运行尝试