1 索引和搜索流程图
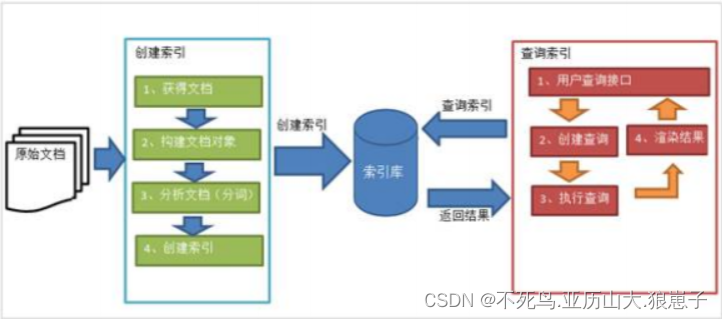
(1)绿色表示索引过程,对要搜索的原始内容进行索引构建一个索引库,索引过程包括:
确定原始内容即要搜索的内容
- 获得文档
- 创建文档
- 分析文档
- 索引文档
(2)红色表示搜索过程,从索引库中搜索内容,搜索过程包括:
- 用户通过搜索界面
- 创建查询
- 执行搜索,从索引库搜索
- 渲染搜索结果
2 索引流程
对文档索引的过程,将用户要搜索的文档内容进行索引,索引存储在索引库(index)中。
2.1 原始内容
原始内容是指要索引和搜索的内容。
原始内容包括互联网上的网页、数据库中的数据、磁盘上的文件等。
2.2 获得文档(采集数据)
从互联网上、数据库、文件系统中等获取需要搜索的原始信息,这个过程就是信息采集,采集数据的目的是为了对原始内容进行索引。
采集数据分类:
- 对于互联网上网页,可以使用工具将网页抓取到本地生成html文件。
- 数据库中的数据,可以直接连接数据库读取表中的数据。
- 文件系统中的某个文件,可以通过I/O操作读取文件的内容。
在Internet上采集信息的软件通常称为爬虫或蜘蛛,也称为网络机器人,爬虫访问互联网上的每一个网页,将获取到的网页内容存储起来。
2.3 创建文档
获取原始内容的目的是为了索引,在索引前需要将原始内容创建成文档(Document),文档中包括一个一个的域(Field),域中存储内容。
这里我们可以将磁盘上的一个文件当成一个document,Document中包括一些Field,如下图:

注意:每个Document可以有多个Field,不同的Document可以有不同的Field,同一个Document可以有相同的Field(域名和域值都相同)
2.4 分析文档
将原始内容创建为包含域(Field)的文档(document),需要再对域中的内容进行分析,分析成为一个一个的单词。
比如下边的文档经过分析如下:
原文档内容:
vivo X23 8GB+128GB 幻夜蓝 全网通4G手机
华为 HUAWEI 麦芒7 6G+64G 亮黑色 全网通4G手机
分析后得到的词:
vivo, x23, 8GB, 128GB, 幻夜, 幻夜蓝, 全网, 全网通, 网通, 4G, 手机, 华为, HUAWEI, 麦芒7。。。。
2.5 索引文档
对所有文档分析得出的语汇单元进行索引,索引的目的是为了搜索,最终要实现只搜索被索引的语汇单元从而找到Document(文档)。
创建索引是对语汇单元索引,通过词语找文档,这种索引的结构叫倒排索引结构。
倒排索引结构是根据内容(词汇)找文档,如下图:

倒排索引结构也叫反向索引结构,包括索引和文档两部分,索引即词汇表,它的规模较小,而文档集合较大。
2.6 Lucene底层存储结构

3 搜索流程
搜索就是用户输入关键字,从索引中进行搜索的过程。根据关键字搜索索引,根据索引找到对应的文档,从而找到要搜索的内容。
3.1 用户
就是使用搜索的角色,用户可以是自然人,也可以是远程调用的程序。
3.2 用户搜索界面
全文检索系统提供用户搜索的界面供用户提交搜索的关键字,搜索完成展示搜索结果。如下图:
Lucene不提供制作用户搜索界面的功能,需要根据自己的需求开发搜索界面。
3.3 创建查询
用户输入查询关键字执行搜索之前需要先构建一个查询对象,查询对象中可以指定查询要查询关键字、要搜索的Field文档域等,查询对象会生成具体的查询语法,比如:
name:手机 : 表示要搜索name这个Field域中,内容为“手机”的文档。
name:华为 AND 手机 : 表示要搜索即包括关键字“华为” 并且也包括“手机”的文档。
3.4 执行搜索
搜索索引过程:
1、根据查询语法在倒排索引词典表中分别找出对应搜索词的索引,从而找到索引所链接的文档链表。
例如搜索语法为 “name:华为 AND 手机 ” 表示搜索出的文档中既要包括"华为"也要包括"手机"。
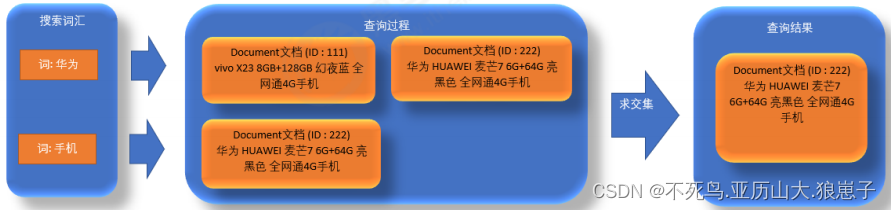
2、由于是AND,所以要对包含 华为 和 手机 词语的链表进行交集,得到文档链表应该包括每一个搜索词语
3、获取文档中的Field域数据。
3.5 渲染结果
以一个友好的界面将查询结果展示给用户,用户根据搜索结果找自己想要的信息,为了帮助用户很快找到自己的结果,提供了很多展示的效果,比如搜索结果中将关键字高亮显示,百度提供的快照等。